基于ABiLSTM 與XGBoost 組合模型的交通時(shí)間預(yù)測(cè)
2021-08-24 08:36:34宋瑞蓉路樹(shù)華王斌君
軟件導(dǎo)刊 2021年8期
關(guān)鍵詞:模型
宋瑞蓉,路樹(shù)華,王斌君,仝 鑫
(1.中國(guó)人民公安大學(xué) 信息網(wǎng)絡(luò)安全學(xué)院,北京 100038;2.山東省日照市人民醫(yī)院,山東 日照 276800)
0 引言
交通時(shí)間預(yù)測(cè)旨在利用已有的交通時(shí)間數(shù)據(jù)對(duì)未來(lái)出行時(shí)間進(jìn)行預(yù)判。交通時(shí)間預(yù)測(cè)不僅在日常出行中具有重要意義,而且便于交通部門(mén)在交通擁堵發(fā)生之前,及時(shí)預(yù)測(cè)并采取有效的避免措施。此外,公安機(jī)關(guān)在偵破案件時(shí)利用交通時(shí)間預(yù)測(cè)能夠鎖定嫌疑車(chē)輛經(jīng)過(guò)某地點(diǎn)的時(shí)間范圍,從而縮小排查范圍,提高工作效率,減少工作量。圍繞交通時(shí)間預(yù)測(cè)開(kāi)展的研究基本可以分為兩類(lèi):時(shí)序方法和非時(shí)序方法。
時(shí)序方法重點(diǎn)考慮了交通問(wèn)題本身具有時(shí)序數(shù)據(jù)的特點(diǎn),可以借鑒時(shí)序數(shù)據(jù)處理方法及模型,因此,時(shí)序方法在交通時(shí)間預(yù)測(cè)領(lǐng)域備受青睞。ARIMA(Autoregressive In?tegrated Moving Averrage Model)是一種經(jīng)典的時(shí)序預(yù)測(cè)方法,文獻(xiàn)[1]將ARIMA 應(yīng)用到交通時(shí)間預(yù)測(cè)任務(wù)中,使得ARIMA 利用所學(xué)習(xí)到的交通時(shí)間隨時(shí)間變化關(guān)系預(yù)測(cè)未來(lái)時(shí)間段的交通時(shí)間,而不需要其它任何輔助屬性。LSTM處理序列化數(shù)據(jù)具有很好的效果,文獻(xiàn)[2]將LSTM 應(yīng)用于交通時(shí)間預(yù)測(cè)任務(wù)中,并充分考慮了相鄰時(shí)間步的結(jié)果對(duì)此刻預(yù)測(cè)結(jié)果的影響;文獻(xiàn)[3-4]將注意力機(jī)制與卷積神經(jīng)網(wǎng)絡(luò)相結(jié)合用于交通時(shí)間及交通流量預(yù)測(cè);文獻(xiàn)[5]將注意力機(jī)制與LSTM 模型相結(jié)合,對(duì)每一時(shí)間步賦予不同權(quán)重;文獻(xiàn)[6]將結(jié)合了注意力機(jī)制的LSTM 模型進(jìn)行改進(jìn),并用于解決交通時(shí)間預(yù)測(cè)任務(wù),相較于LSTM 只考慮一個(gè)方向的傳遞,雙向長(zhǎng)短期記憶網(wǎng)絡(luò)(BiLSTM)是前向LSTM 與后向LSTM 的結(jié)合,能夠充分考慮相鄰時(shí)間步對(duì)預(yù)測(cè)結(jié)果的影響;文獻(xiàn)[7-9]將注意力機(jī)制與BiLSTM 相結(jié)合,應(yīng)用于不同領(lǐng)域。
交通時(shí)間預(yù)測(cè)領(lǐng)域常見(jiàn)的非時(shí)序方法有線性回歸、隨機(jī)森林、支持向量回歸(SVR)以及K 近鄰算法(KNN)等[10]。這類(lèi)方法的優(yōu)點(diǎn)在于只需給出相關(guān)屬性即可進(jìn)行預(yù)測(cè),而不需要給出相鄰時(shí)間段的信息,在一些較為簡(jiǎn)單的數(shù)據(jù)集上有較好的表現(xiàn);缺點(diǎn)是在交通時(shí)間預(yù)測(cè)中會(huì)遺漏掉一些時(shí)序信息,并且對(duì)于一些屬性間關(guān)系較為復(fù)雜的數(shù)據(jù)集不具有很好的預(yù)測(cè)效果。在機(jī)器學(xué)習(xí)方法中,極端梯度提升(XGBoost)模型常被用于分類(lèi)和回歸任務(wù),通過(guò)多棵決策樹(shù)預(yù)測(cè)最終結(jié)果,并且每增加一棵樹(shù)都能確保目標(biāo)函數(shù)值有所下降,在多種任務(wù)中往往具有較好表現(xiàn)。文獻(xiàn)[11]將XGBoost 模型應(yīng)用于短時(shí)交通流預(yù)測(cè),采用hyperopt 方法進(jìn)行自動(dòng)調(diào)參,在所構(gòu)造的時(shí)間序列與時(shí)空序列上分別進(jìn)行實(shí)驗(yàn),均表現(xiàn)出了較好的效果;文獻(xiàn)[12]將遺傳算法與XG?Boost 模型相結(jié)合,利用遺傳算法良好的全局搜索能力為XGBoost 進(jìn)行調(diào)參,提高模型表現(xiàn)效果。
此外,許多研究基于組合模型開(kāi)展。常見(jiàn)的組合模型使用時(shí)間序列方法與機(jī)器學(xué)習(xí)方法相結(jié)合。文獻(xiàn)[13]將LSTM 模型與XGBoost 模型相結(jié)合,利用誤差倒排法對(duì)不同模型賦予不同權(quán)重,由兩個(gè)模型共同決定最終預(yù)測(cè)結(jié)果;文獻(xiàn)[14]首先利用LSTM 處理時(shí)序化特征,然后將其預(yù)測(cè)結(jié)果作為一項(xiàng)新的特征與其它基礎(chǔ)特征共同用于XGBoost模型預(yù)測(cè),結(jié)果相較于單一模型有所提升;文獻(xiàn)[15]利用卷積神經(jīng)網(wǎng)絡(luò)提取特征,然后使用果蠅算法優(yōu)化XGBoost模型參數(shù),將經(jīng)過(guò)特征提取的數(shù)據(jù)投入?yún)?shù)被優(yōu)化的XG?Boost 模型中進(jìn)行預(yù)測(cè),在保證預(yù)測(cè)準(zhǔn)確度的情況下,提升了預(yù)測(cè)效率;文獻(xiàn)[16]將時(shí)序方法Holt-Winters 與線性回歸相結(jié)合用于高鐵短期客流預(yù)測(cè)。利用時(shí)間序列模型可以關(guān)注數(shù)據(jù)隨時(shí)間變化的特征,機(jī)器學(xué)習(xí)方法能夠很好地挖掘?qū)傩詴r(shí)間的依賴(lài)關(guān)系,這兩種模型結(jié)構(gòu)相差較大,因此在一定情況下可以綜合兩種模型優(yōu)勢(shì),提升預(yù)測(cè)效果。
本文將BiLSTM 模型與XGBoost 模型相結(jié)合,其中BiL?STM 模型中添加了注意力機(jī)制,使得模型能夠?qū)Σ煌瑫r(shí)間步賦予不同權(quán)重的關(guān)注,XGBoost 模型使用了兩種調(diào)參方式,分別為hyperopt 方法自動(dòng)調(diào)參和利用遺傳算法進(jìn)行調(diào)參,將兩種調(diào)參方法的結(jié)果進(jìn)行對(duì)比,選用準(zhǔn)確度更高的模型與改進(jìn)的BiLSTM 模型進(jìn)行組合,從而相較于單一模型提升了預(yù)測(cè)效果。
1 改進(jìn)的BiLSTM 模型
1.1 BiLSTM 模型
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)經(jīng)常被用于具有序列化特征的數(shù)據(jù)處理,每一個(gè)隱藏層神經(jīng)元h是由當(dāng)前輸入與上一時(shí)刻的隱藏層神經(jīng)元的輸出所組成,這使得數(shù)據(jù)能夠向后傳遞。但同時(shí)也帶來(lái)一大問(wèn)題,這種長(zhǎng)期依賴(lài)會(huì)導(dǎo)致網(wǎng)絡(luò)記住大量冗余信息,權(quán)重更新緩慢,一些重要信息會(huì)隨著節(jié)點(diǎn)的增多而被遺忘。長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)是RNN 的一種改進(jìn),可以解決RNN 存在的上述問(wèn)題。LSTM 由輸入門(mén)、輸出門(mén)、遺忘門(mén)和內(nèi)部記憶單元組成,如式(1)-式(6)所示。在設(shè)定時(shí)間步長(zhǎng)后,可以對(duì)這些時(shí)間步內(nèi)的特征進(jìn)行自適應(yīng)地關(guān)注,從而解決時(shí)間序列的交通預(yù)測(cè)問(wèn)題。
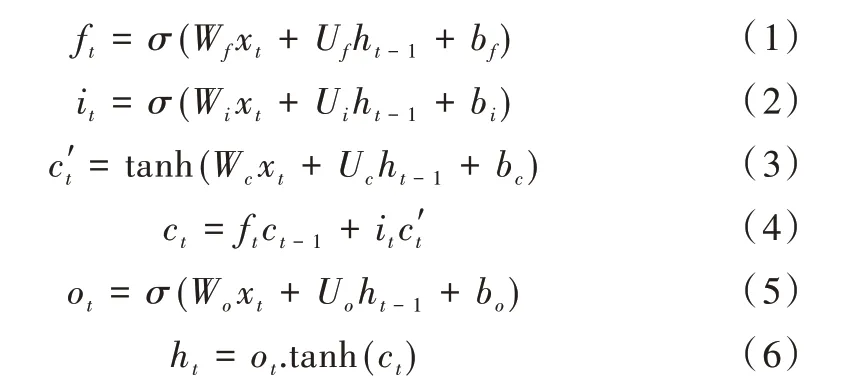
式(1)表示遺忘門(mén),可控制丟棄一些不重要的信息,減少網(wǎng)絡(luò)傳遞中大量的冗余信息;式(2)表示輸入門(mén),可用來(lái)控制輸入xt和當(dāng)前狀態(tài)ht-1更新到記憶單元的程度大小;式(3)和式(4)是內(nèi)部記憶單元,將上述遺忘門(mén)和輸入門(mén)的信息加以組合,決定哪些信息可以被更新;式(5)和式(6)是輸出門(mén),是為了計(jì)算當(dāng)前的隱藏層狀態(tài),以便網(wǎng)絡(luò)繼續(xù)向后傳遞。相較于RNN 共享同一組權(quán)重與偏置會(huì)導(dǎo)致梯度爆炸和消失問(wèn)題,LSTM 對(duì)每一個(gè)門(mén)都各自共享了一組權(quán)重與偏置,這樣能夠控制一些信息的流入和流出,從而使得整個(gè)網(wǎng)絡(luò)更好地把握序列信息之間的關(guān)系。
雙向長(zhǎng)短期記憶網(wǎng)絡(luò)(Bidirectional Long Short-Term Memory,BiLSTM)是前向LSTM 與后向LSTM 的結(jié)合,它主要處理有時(shí)間序列關(guān)系的流數(shù)據(jù),在保留數(shù)據(jù)順序性特征的同時(shí)充分地挖掘和利用上下文信息。BiLSTM 中每一個(gè)單元的結(jié)果受前后兩個(gè)單元的影響,在前向LSTM 中,此刻單元狀態(tài)At受上一單元At-1結(jié)果的影響,在后向LSTM 中受At+1狀態(tài)的影響,兩個(gè)狀態(tài)共同作用得到此時(shí)的結(jié)果[7]。前向LSTM 與后向LSTM 的結(jié)合更加充分地利用了時(shí)間序列的上下文信息,使得預(yù)測(cè)結(jié)果更加準(zhǔn)確。
在交通時(shí)間預(yù)測(cè)任務(wù)中,一個(gè)時(shí)間點(diǎn)的交通時(shí)間和與之相鄰的前、后時(shí)間點(diǎn)都有關(guān)系,那么采用雙向預(yù)測(cè)模型便具有很強(qiáng)的可解釋性。例如,一條路在9:00 時(shí)刻發(fā)生擁堵,那么9:15 的通行時(shí)間也一定會(huì)受到影響。LSTM 利用單向傳遞的特征,通過(guò)前5 個(gè)時(shí)間步的交通時(shí)間預(yù)測(cè)當(dāng)前時(shí)刻。但這種傳遞方向并不只是單向的,如果得到9:30 的通行時(shí)間,發(fā)現(xiàn)此時(shí)道路是阻塞的,則有理由相信9:15 時(shí)刻的道路狀況也是如此,從而預(yù)測(cè)出相應(yīng)的交通時(shí)間。當(dāng)這種傳遞具有雙向性時(shí),同時(shí)考慮與預(yù)測(cè)時(shí)刻相鄰的前、后時(shí)刻對(duì)該時(shí)刻的影響,將會(huì)使結(jié)果更加具有信服力。
1.2 注意力機(jī)制
注意力模型通過(guò)神經(jīng)網(wǎng)絡(luò)模型與注意力機(jī)制的結(jié)合,提高模型對(duì)特征的關(guān)注能力。注意力機(jī)制借鑒于人類(lèi)的視覺(jué)注意力機(jī)制,人類(lèi)會(huì)在整個(gè)視覺(jué)范圍內(nèi)將注意力集中于最重要的部分,從而有效地快速篩選出對(duì)自身最有意義的信息,極大地提高了信息處理準(zhǔn)確率。神經(jīng)網(wǎng)絡(luò)中添加的注意力機(jī)制也是為了達(dá)到這樣的效果,快速關(guān)注重要信息,減少無(wú)關(guān)信息對(duì)結(jié)果的影響。
具體而言,在交通時(shí)間預(yù)測(cè)任務(wù)中,添加注意力機(jī)制是為了對(duì)每一個(gè)時(shí)間步賦予不同權(quán)重的關(guān)注,對(duì)于一些較遠(yuǎn)的時(shí)間步減少關(guān)注,對(duì)于相鄰時(shí)間步賦予更多關(guān)注,從而使預(yù)測(cè)結(jié)果更加準(zhǔn)確。式(7)—式(9)是描述注意力機(jī)制的神經(jīng)網(wǎng)絡(luò),其中,H是BiLSTM 網(wǎng)絡(luò)的輸出,W與w是注意力機(jī)制神經(jīng)網(wǎng)絡(luò)中的權(quán)重,一開(kāi)始被隨機(jī)初始化,通過(guò)模型訓(xùn)練不斷更新得到,α是注意力權(quán)重向量,r表示BiL?STM 網(wǎng)絡(luò)的輸出與注意力機(jī)制進(jìn)行加權(quán)求和,代表網(wǎng)絡(luò)最后輸出,具體網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。
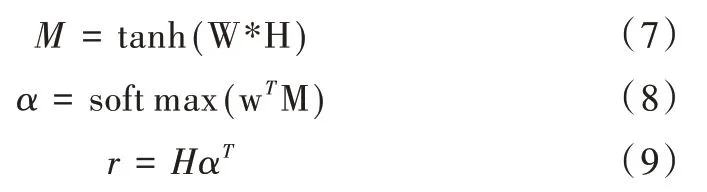

Fig.1 BiLSTM network structure with attention mechanism added圖1 添加了注意力機(jī)制的BiLSTM 網(wǎng)絡(luò)結(jié)構(gòu)
1.3 ABiLSTM 模型
某一時(shí)刻的交通時(shí)間受相鄰時(shí)間段影響,BiLSTM 網(wǎng)絡(luò)可以充分利用該時(shí)刻前后的信息預(yù)測(cè)當(dāng)前時(shí)刻的交通時(shí)間,但周?chē)鷷r(shí)刻對(duì)于此時(shí)刻的影響程度并不相同,若模型對(duì)每一時(shí)間步都進(jìn)行同等程度的關(guān)注,則將失去了焦點(diǎn)和重點(diǎn)。為解決該問(wèn)題,本文建立了結(jié)合注意力機(jī)制的BiL?STM 網(wǎng)絡(luò)(Attenton-based BiLSTM,ABiLSTM),在BiLSTM網(wǎng)絡(luò)的輸出層上添加了注意力層,依據(jù)每一時(shí)間步對(duì)待預(yù)測(cè)時(shí)間點(diǎn)的貢獻(xiàn)程度不同,為每一時(shí)間步訓(xùn)練出一組權(quán)重向量,將雙向LSTM 網(wǎng)絡(luò)的輸出與注意力權(quán)重進(jìn)行加權(quán)求和作為模型最后的輸出結(jié)果。BiLSTM 中時(shí)間步長(zhǎng)設(shè)置為5,每一個(gè)時(shí)間步中包含4 個(gè)屬性,模型經(jīng)過(guò)訓(xùn)練,會(huì)對(duì)這些特征分別計(jì)算出相應(yīng)權(quán)重。
本文所選取的實(shí)驗(yàn)數(shù)據(jù)集來(lái)自英國(guó)公路局提供和管理的路段通行時(shí)間數(shù)據(jù),每15min 為一個(gè)時(shí)段,記錄一條數(shù)據(jù)。經(jīng)過(guò)篩選共保留5 個(gè)屬性,分別為日期類(lèi)型、時(shí)間類(lèi)型、平均速度、交通流量以及通行時(shí)間。選取AL1053、AL1249、AL1253 等20 條公路在2014 年1 月份的交通數(shù)據(jù),其中每條公路有2 973 條數(shù)據(jù),其中80%劃分為訓(xùn)練集,20%為測(cè)試集。在每條公路上分別使用BiLSTM 模型與ABiLSTM 模型進(jìn)行對(duì)比實(shí)驗(yàn)。
為了評(píng)價(jià)結(jié)果,使用了兩個(gè)評(píng)價(jià)指標(biāo),分別為平均絕對(duì)誤差mae 與R 平方R_square,計(jì)算公式如式(10)、式(11)所示。
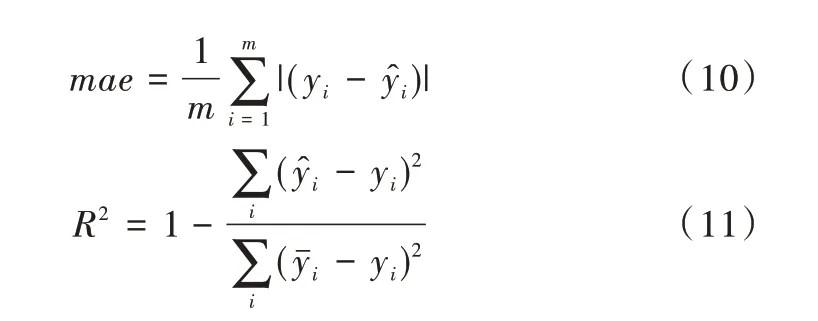
平均絕對(duì)誤差mae 是計(jì)算預(yù)測(cè)值與真實(shí)值偏差的絕對(duì)值大小,mae 值越小,表示模型預(yù)測(cè)效果越好。R平方是對(duì)模型擬合程度的打分,取值范圍為[-1,1]。如式(11)所示,分子是預(yù)測(cè)值與真實(shí)值之間的誤差,分母是真實(shí)值與目標(biāo)值y的平均數(shù)之間的誤差。由此可以得出,R平方的值越接近1,模型吻合程度越高。
實(shí)驗(yàn)結(jié)果如表1 所示。
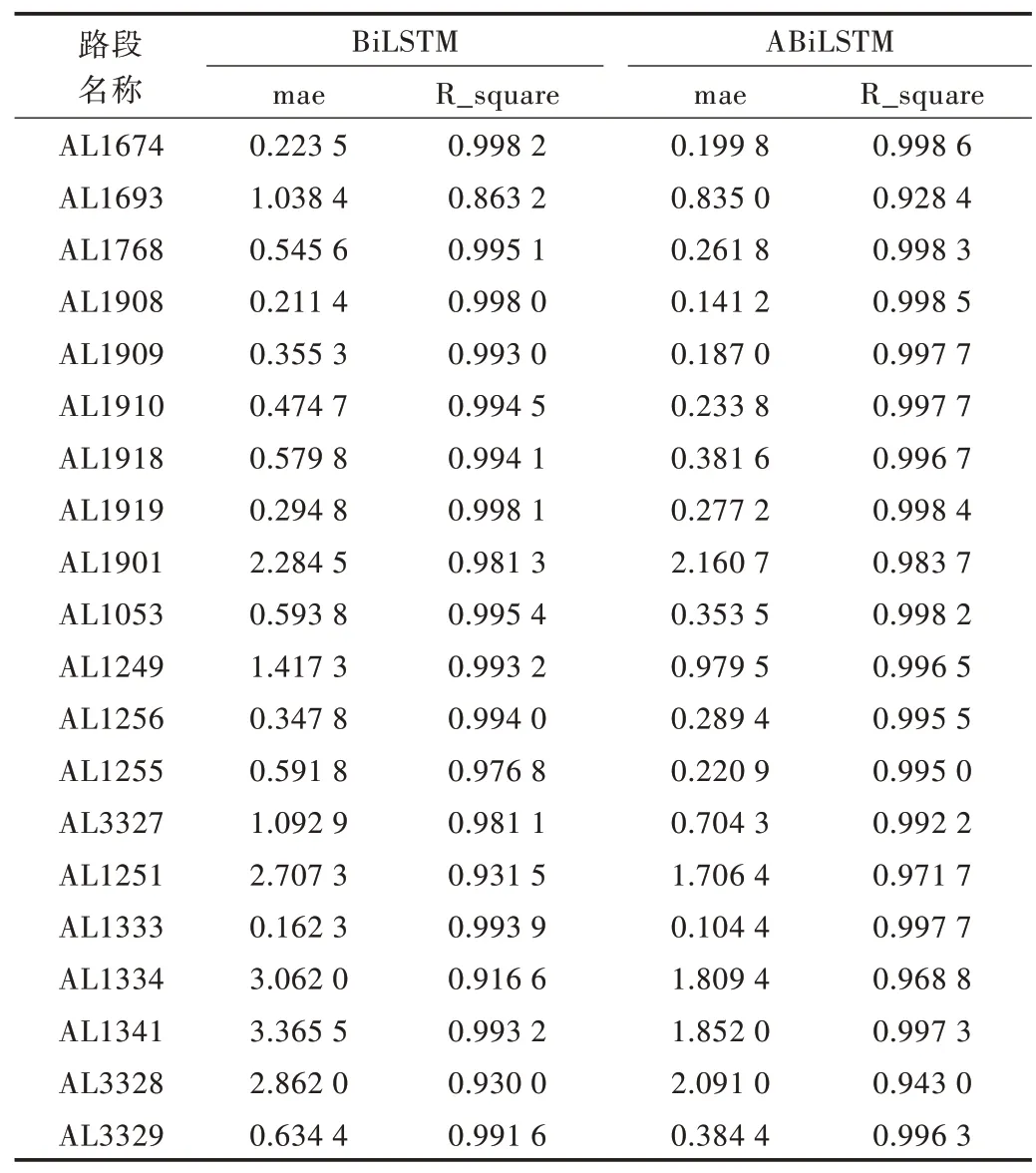
Table 1 Comparison of experimental results of ABiLSTM model表1 ABiLSTM 模型實(shí)驗(yàn)結(jié)果對(duì)比
兩種模型在平均絕對(duì)值誤差和R 平方上的對(duì)比結(jié)果如圖2 所示。
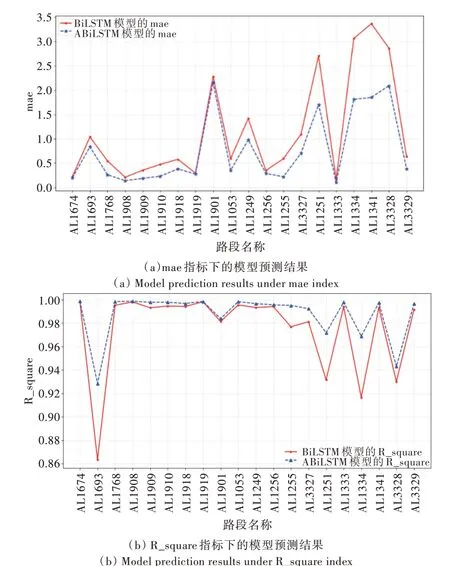
Fig.2 Comparison of experimental results of ABiLSTM model圖2 ABiLSTM 模型實(shí)驗(yàn)結(jié)果對(duì)比
由表1 和圖2 可以看出,ABiLSTM 在實(shí)驗(yàn)中的20 條路段上均表現(xiàn)出了更好的預(yù)測(cè)效果。
2 XGBoost 模型
極端梯度提升(eXtreme Gradient Boosting,XGBoost)模型是為了緩解單棵決策樹(shù)可能造成過(guò)擬合的風(fēng)險(xiǎn),對(duì)多棵決策樹(shù)進(jìn)行集成,從而使目標(biāo)函數(shù)值不斷下降[17],具體表達(dá)式如式(12)所示。
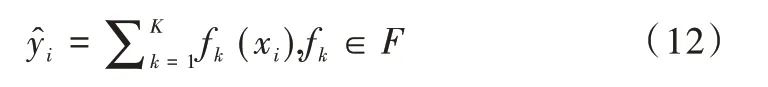
XGBoost 最核心的思路是每增加一棵決策樹(shù),整體表達(dá)效果都會(huì)有所提升,過(guò)程如式(13)所示。
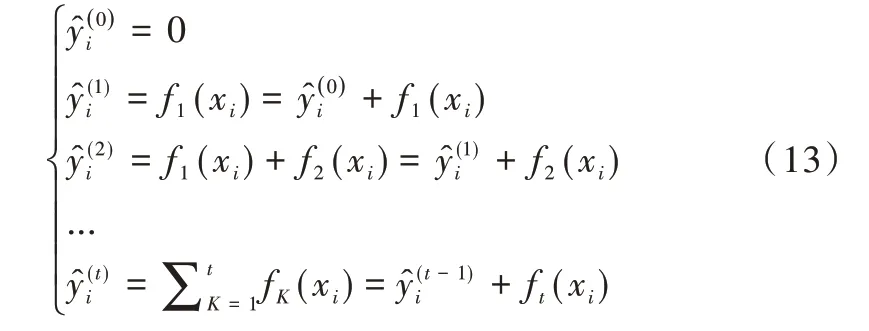
在決策樹(shù)中,葉子節(jié)點(diǎn)越多,造成過(guò)擬合的風(fēng)險(xiǎn)也就越大,所以需要限制葉子節(jié)點(diǎn)的個(gè)數(shù),可以通過(guò)懲罰項(xiàng)實(shí)現(xiàn),如式(14)所示。
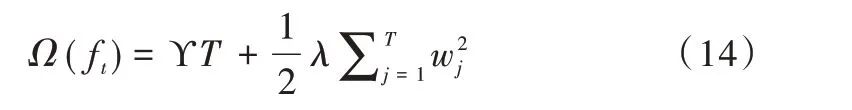
式(14)中,T為葉子節(jié)點(diǎn)個(gè)數(shù),? 為懲罰系數(shù),表示懲罰力度的大小,w表示每個(gè)葉子節(jié)點(diǎn)的權(quán)重,表示對(duì)wj做了一次L2懲罰。
將損失函數(shù)與懲罰項(xiàng)相結(jié)合可以得到目標(biāo)函數(shù)Obj(t),接下來(lái)使用泰勒展開(kāi)式處理目標(biāo)函數(shù),展開(kāi)結(jié)果如式(15)所示。
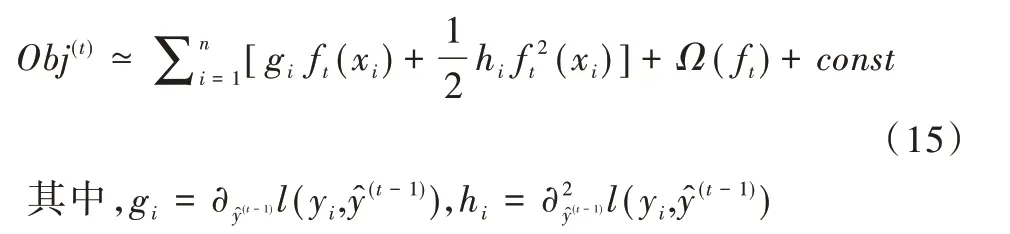
對(duì)式(15)進(jìn)行簡(jiǎn)化,為了便于合并,將懲罰項(xiàng)依據(jù)其定義進(jìn)行展開(kāi),接著將樣本上的遍歷轉(zhuǎn)化為葉子節(jié)點(diǎn)的遍歷,最終結(jié)果如式(16)所示。
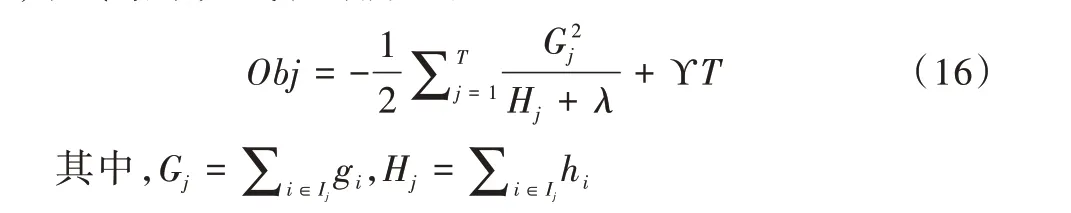
依據(jù)式(16),XGBoost 模型可以遍歷不同決策樹(shù)的劃分方案,使得目標(biāo)函數(shù)最小,即可以得到相較于上次決策樹(shù)劃分表現(xiàn)效果更好的模型。
2.1 hyperopt 方法自動(dòng)調(diào)參
XGBoost 模型含有大量超參數(shù)需要設(shè)置,無(wú)論是采用手工調(diào)參方式還是采用網(wǎng)格搜索方式,都較為復(fù)雜,不利于模型優(yōu)化,使用hyperopt 可以簡(jiǎn)化調(diào)參過(guò)程。hyperopt 有兩種搜索算法,分別是隨機(jī)搜索和TPE(Tree of Parzen Esti?mators)搜索[18]。本文使用的是TPE 搜索算法。
TPE 搜索算法相較于隨機(jī)搜索在多數(shù)情況下表現(xiàn)出更好的效果。首先,采用隨機(jī)搜索方式產(chǎn)生超參數(shù),然后將這些超參數(shù)代入模型進(jìn)行訓(xùn)練,通過(guò)目標(biāo)函數(shù)值對(duì)參數(shù)進(jìn)行評(píng)價(jià)。當(dāng)隨機(jī)產(chǎn)生的參數(shù)超過(guò)20 組時(shí)(默認(rèn)為20),使用這些參數(shù)以及訓(xùn)練后模型的目標(biāo)函數(shù)值產(chǎn)生無(wú)參數(shù)概率密度函數(shù),然后使用概率密度函數(shù)生成新的超參數(shù),對(duì)模型繼續(xù)進(jìn)行訓(xùn)練,直到產(chǎn)生相較于其它參數(shù)而言,具有較好表現(xiàn)效果的一組參數(shù)作為T(mén)PE 搜索算法的最終結(jié)果。TPE 搜索算法流程如圖3 所示[18]。

Fig.3 Workflow of hyperopt using TPE search algorithm圖3 使用TPE 搜索算法的hyperopt 工作流程
hyperopt 是一個(gè)支持自動(dòng)調(diào)參的python 庫(kù),在調(diào)參之前需要給出所要優(yōu)化的目標(biāo)函數(shù)及參數(shù)的搜索空間[18]。本文使用hyperopt 調(diào)參方式的參數(shù)搜索空間如表2 所示。

Table 2 Parameter search space of hyperopt method parameter adjustment表2 hyperopt 方法調(diào)參的參數(shù)搜索空間
以路段AL1053 為例,經(jīng)過(guò)hyperopt 調(diào)參后XGBoost 模型參數(shù)如表3 所示。

Table 3 Super parameter values after adjusting parameters with hyperopt method表3 使用hyperopt 方法調(diào)參后的超參數(shù)取值
2.2 遺傳算法調(diào)參
生物遺傳時(shí)遵循分離規(guī)律及自由組合規(guī)律,變異時(shí)遵循重組規(guī)律、基因突變規(guī)律以及染色體變異規(guī)律。遺傳算法(GA,Genetic Algorithm)受到生物進(jìn)化學(xué)說(shuō)和遺傳學(xué)說(shuō)的啟發(fā),模擬生物進(jìn)化過(guò)程,借助復(fù)制、交換、變異等方法模仿生物優(yōu)勝劣汰、適者生存的自然法則,具體而言就是在初始解的基礎(chǔ)上通過(guò)智能式搜索逐步逼近最優(yōu)解。相較于其它方法,遺傳算法可以找到全局最優(yōu)解[19]。
使用遺傳算法解決具體問(wèn)題時(shí),需要根據(jù)問(wèn)題的特性進(jìn)行編碼,確定適應(yīng)度函數(shù)。該算法具有黑箱式結(jié)構(gòu),這使得可以用來(lái)研究一些函數(shù)關(guān)系不明確的復(fù)雜關(guān)系,如模型調(diào)參。
遺傳算法具體可由以下遺傳算子組成:
選擇:計(jì)算個(gè)體適應(yīng)度,然后從第t 代群體P(t)中選擇出適應(yīng)度較好的個(gè)體遺傳到下一代群體P(t+1)中。使用輪盤(pán)賭法確定每一個(gè)體被選擇的概率計(jì)算公式如式(17)—式(18)所示。
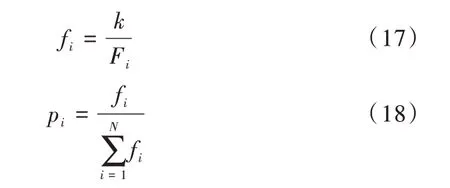
其中,F(xiàn)i為個(gè)體i所對(duì)應(yīng)的適應(yīng)度函數(shù)值,N 代表現(xiàn)有的個(gè)體數(shù)。
交叉:將群體P(t)內(nèi)的個(gè)體進(jìn)行隨機(jī)組合,選擇確定的概率交換個(gè)體之間的部分染色體,產(chǎn)生新的個(gè)體。
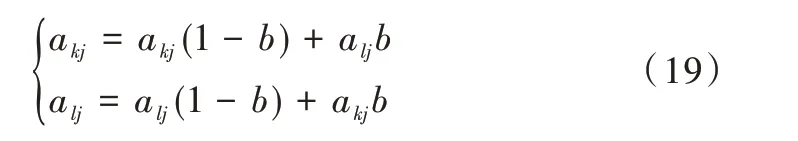
其中,b為取值在[0,1]的隨機(jī)數(shù)。
變異:以某一概率將群體P(t)中的某些基因值替換為其它的等位基因[20]。表達(dá)式如式(20)—式(21)所示。
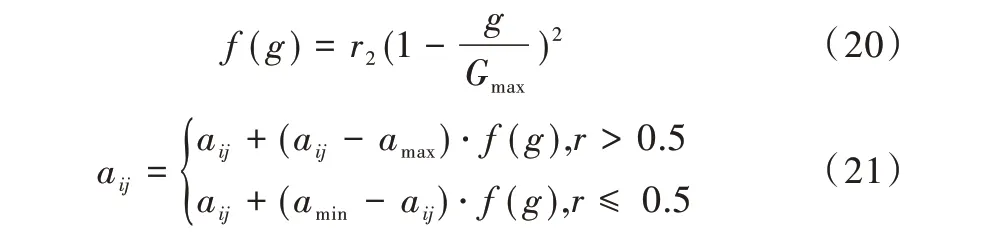
式(20)中,r2為隨機(jī)數(shù),g代表已經(jīng)進(jìn)化的次數(shù),Gmax代表最終迭代次數(shù)。式(21)中,aij代表發(fā)生變異的第i個(gè)體的第j號(hào)基因,amax和amin分別代表該基因取值范圍內(nèi)的最大值和最小值,r是取值為[0,1]的隨機(jī)數(shù)。
遺傳算法運(yùn)算過(guò)程如圖4 所示。
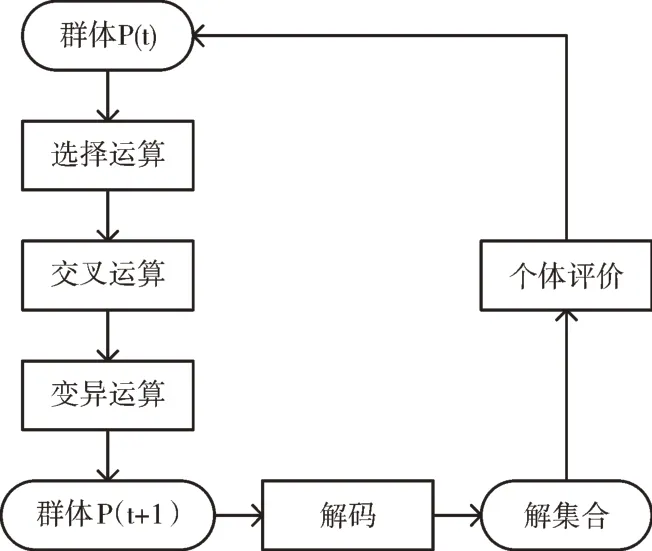
Fig.4 Operation process of genetic algorithm圖4 遺傳算法運(yùn)算過(guò)程
本文遺傳算法中所使用的適應(yīng)度函數(shù)為R 平方,表達(dá)式如式(11)所示。
利用遺傳算法對(duì)XGBoost 模型進(jìn)行調(diào)參,參數(shù)名稱(chēng)及參數(shù)搜索空間如表4 所示。
同樣以路段AL1053 為例,顯示經(jīng)過(guò)遺傳算法調(diào)參后XGBoost 模型的超參數(shù)如表5 所示。
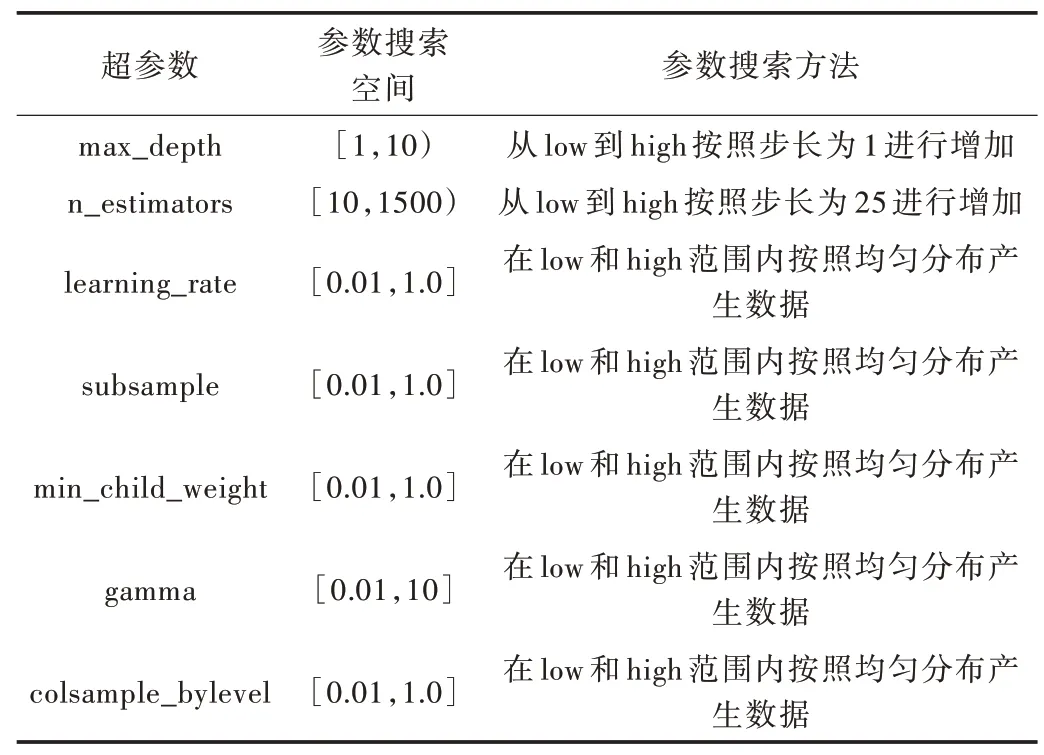
Table 4 Parameter search space of genetic algorithm parameter adjustment表4 遺傳算法調(diào)參的參數(shù)搜索空間
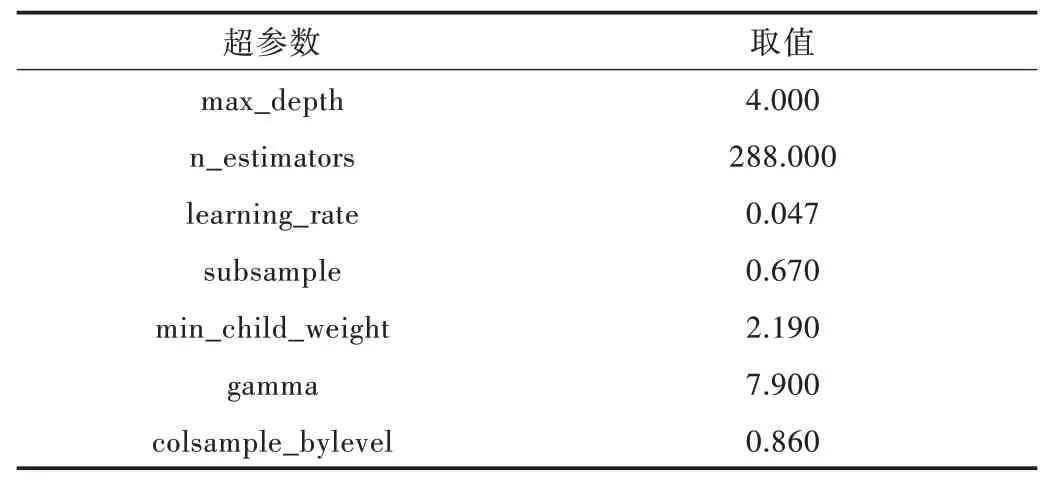
Table 5 Super parameter values after parameter adjustment using genetic algorithm表5 使用遺傳算法調(diào)參后的超參數(shù)取值
hyperopt 方法調(diào)參和遺傳算法調(diào)參具有不同的特點(diǎn),為了使組合模型具有最佳表現(xiàn)效果,本文對(duì)于每一條路的數(shù)據(jù)集都采用了兩種調(diào)參方式,選擇其中表現(xiàn)最好的模型與ABiLSTM 模型進(jìn)行組合。
3 ABiLSTM與XGBoost組合模型
ABiLSTM 擅長(zhǎng)于處理時(shí)序化數(shù)據(jù),XGBoost 模型基于決策樹(shù)對(duì)于回歸和分類(lèi)問(wèn)題有較好的表現(xiàn)。兩個(gè)模型結(jié)構(gòu)相差較大,將兩個(gè)模型進(jìn)行組合可以降低過(guò)擬合風(fēng)險(xiǎn),提高預(yù)測(cè)準(zhǔn)確度。
使用殘差表示模型預(yù)測(cè)結(jié)果的誤差情況,殘差計(jì)算如式(22)所示。

以路段AL1053為例,ABiLSTM 模型與XGBoost 模型前100個(gè)預(yù)測(cè)結(jié)果的殘差結(jié)果如圖5 所示。
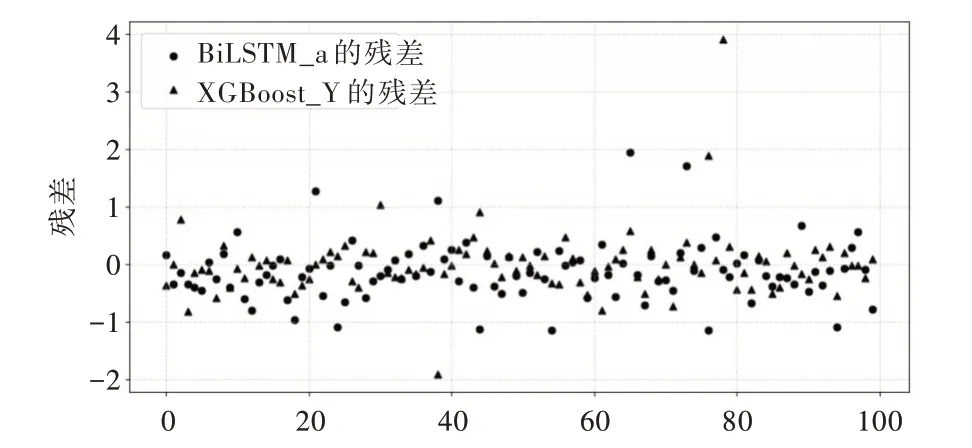
Fig.5 Residual error of traffic time prediction圖5 交通時(shí)間預(yù)測(cè)殘差
由圖5 可以看出,這兩個(gè)模型預(yù)測(cè)結(jié)果的殘差除在個(gè)別數(shù)據(jù)點(diǎn)有較大偏差外,其余數(shù)據(jù)點(diǎn)集中在[-1,1],模型預(yù)測(cè)能力相差無(wú)幾。在組合模型中,若兩個(gè)模型的預(yù)測(cè)能力有較大差別,組合之后的結(jié)果往往差于兩個(gè)模型中表現(xiàn)較好的模型。在本文實(shí)驗(yàn)中,單一模型BiLSTM 與XGBoost預(yù)測(cè)能力相近,通過(guò)將兩個(gè)模型的預(yù)測(cè)結(jié)果進(jìn)行組合,可以在一定程度上提高結(jié)果預(yù)測(cè)準(zhǔn)確度。交通時(shí)間預(yù)測(cè)領(lǐng)域一些表現(xiàn)較好的組合模型多是基于時(shí)間序列方法與機(jī)器學(xué)習(xí)方法的組合,因?yàn)檫@兩類(lèi)模型的結(jié)構(gòu)相差較大,可以減少過(guò)擬合程度,同時(shí)這兩類(lèi)模型具有不同特點(diǎn),時(shí)間序列方法可以考慮周?chē)鷷r(shí)間段的結(jié)果對(duì)此刻的影響,可以提取到時(shí)間序列的隱藏特征,機(jī)器學(xué)習(xí)方法能夠更加充分地挖掘?qū)傩蚤g的依賴(lài)關(guān)系,將兩類(lèi)模型進(jìn)行組合可以綜合這兩類(lèi)模型的優(yōu)點(diǎn),表現(xiàn)出更好的預(yù)測(cè)效果。
3.1 誤差倒排法
本文采用并列的模型組合方式,讓每個(gè)模型單獨(dú)訓(xùn)練,然后為每個(gè)模型的結(jié)果賦予不同的權(quán)重,讓其共同決定組合模型的預(yù)測(cè)結(jié)果。模型組合的關(guān)鍵在于確定不同模型的權(quán)重,關(guān)于組合模型權(quán)重的確定方法,常見(jiàn)的有誤差倒排法、等權(quán)組合預(yù)測(cè)法、方差—協(xié)方差法、最小二乘法以及最小絕對(duì)值法[21]。本文采用了誤差倒排法和最小絕對(duì)值法分別進(jìn)行試驗(yàn)。
誤差倒排法的優(yōu)點(diǎn)在于計(jì)算簡(jiǎn)便,同時(shí)考慮了不同模型之間預(yù)測(cè)效果的差異,在具有較好表現(xiàn)效果的同時(shí),也具有很強(qiáng)的可解釋性。使用誤差倒排法組合模型的方法如式(23)—式(25)所示。
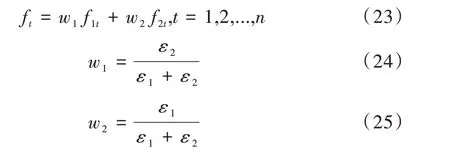
其中,ε1和ε2分別代表BiLSTM 與XGBoost 模型預(yù)測(cè)值與真實(shí)值之間的誤差,w1與w2分別代表兩個(gè)模型的權(quán)重。由權(quán)重計(jì)算公式可以看出,該方法考慮了不同模型間預(yù)測(cè)能力的差異,對(duì)于誤差較小的模型賦予較大的權(quán)重,對(duì)誤差較大模型賦予較小權(quán)重[13],這樣能夠更好發(fā)揮組合模型的優(yōu)勢(shì)。
3.2 最小絕對(duì)值法
最小絕對(duì)值法相較于誤差倒排法的優(yōu)點(diǎn)在于可以為兩個(gè)以上的單一模型確定權(quán)重參數(shù),在一些復(fù)雜場(chǎng)景中,更具實(shí)用價(jià)值。最小絕對(duì)值法是將誤差的絕對(duì)值作為目標(biāo)函數(shù),表達(dá)如式(26)所示[21]。

將預(yù)測(cè)結(jié)果記為矩陣A,真實(shí)值記為矩陣Y,權(quán)重記為W,表達(dá)式如式(27)所示。

其中,A的每一列表示一個(gè)模型所預(yù)測(cè)的n個(gè)數(shù)值,共有k個(gè)模型,表達(dá)式如式(28)所示。
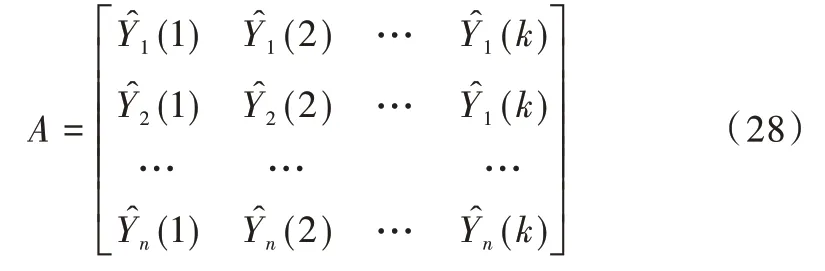
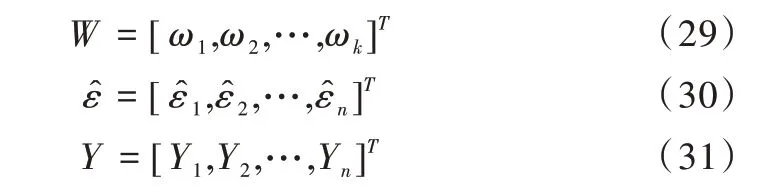
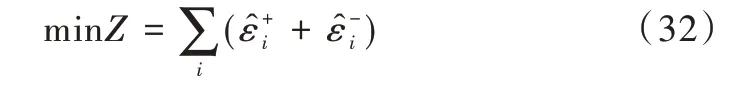
此時(shí),該數(shù)學(xué)模型轉(zhuǎn)化為一個(gè)典型的線性規(guī)劃問(wèn)題,可以使用單純性法求解,矩陣表達(dá)式如式(33)所示。
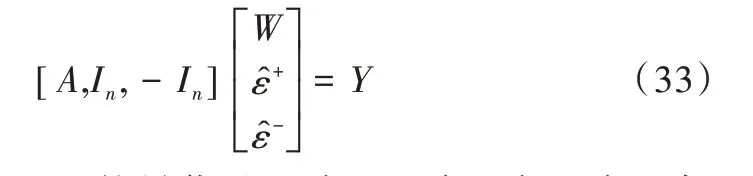
將矩陣[A,In,-In]的最優(yōu)基記為B*,則B*在不失一般性條件下的表達(dá)式如式(34)所示。
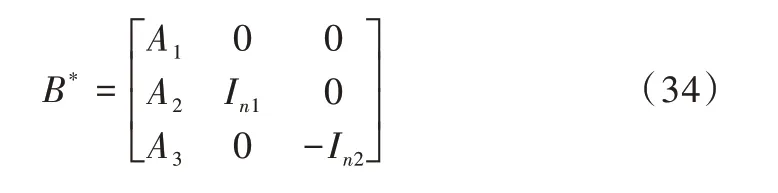

其中,W 為最終所要確定的權(quán)重系數(shù)。
4 實(shí)驗(yàn)結(jié)果及分析
本文將ABiLSTM 模型與經(jīng)過(guò)調(diào)參之后的XGBoost 模型采用誤差倒排法和最小絕對(duì)值法分別進(jìn)行組合,實(shí)驗(yàn)數(shù)據(jù)為AL1674 等20 條路段在2014 年1 月份的交通數(shù)據(jù),訓(xùn)練集與測(cè)試集劃分比例為8∶2,采用隨機(jī)劃分方式。其中,XGBoost 模型使用了兩種調(diào)參方式,選用表現(xiàn)效果最好的作為組合模型的一部分。表6 為單一模型及組合模型預(yù)測(cè)結(jié)果,使用的評(píng)價(jià)指標(biāo)為均方誤差mse,權(quán)重表示單一模型的預(yù)測(cè)結(jié)果在組合模型中所占比重。在20 條實(shí)驗(yàn)路段中,多數(shù)情況下,遺傳算法調(diào)參表現(xiàn)出較好的效果,但在某些路段中hyperopt 自動(dòng)調(diào)參表現(xiàn)出更好的效果,用*加以區(qū)分。
均方誤差的計(jì)算公式如式(36)所示。
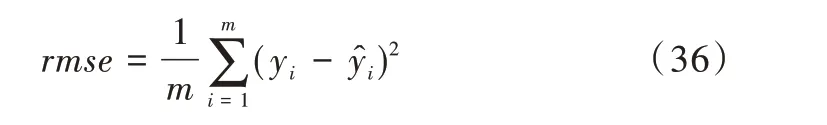
由表6 可以得出,使用誤差倒排法確定的組合模型并非在所有路段上均優(yōu)于單一模型,但使用最小絕對(duì)值法的組合模型相較于任何一個(gè)單一模型,均方誤差都有所下降且表現(xiàn)出最好的預(yù)測(cè)效果。
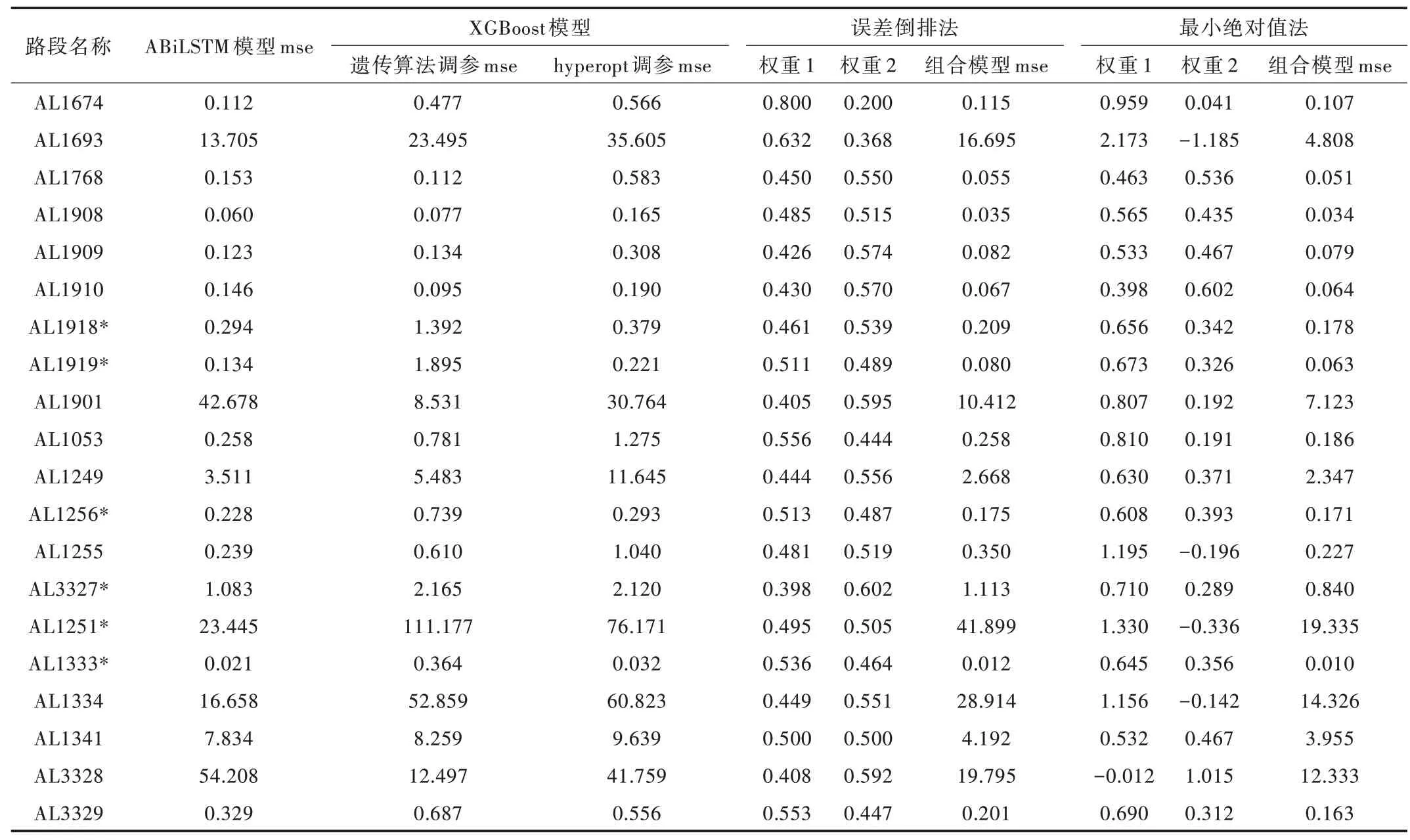
Table 6 Comparison of the prediction results of single model and combined model表6 單一模型與組合模型預(yù)測(cè)結(jié)果對(duì)比
為了顯示組合模型在某條具體路段上預(yù)測(cè)值與真實(shí)值之間的偏差,以路段AL1053 為例,將組合模型的前100個(gè)預(yù)測(cè)結(jié)果與真實(shí)值顯示在圖中,如圖6 所示。
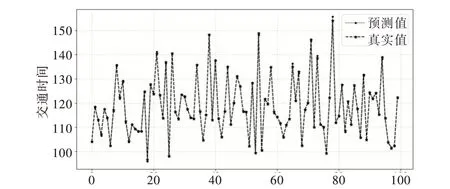
Fig.6 Predicted and actual traffic time of combined model圖6 組合模型交通時(shí)間的預(yù)測(cè)值與實(shí)際值
由圖6 可以得出,組合模型能夠很好地?cái)M合實(shí)際交通時(shí)間變化情況,具有較好的預(yù)測(cè)效果。
相對(duì)百分誤差絕對(duì)值的平均值MAPE 可以用來(lái)評(píng)價(jià)模型的預(yù)測(cè)能力,MAPE 值越小,代表模型預(yù)測(cè)能力越強(qiáng),計(jì)算如式(37)所示。為綜合對(duì)比本文所提到的所有模型,現(xiàn)將不同模型在20 條實(shí)驗(yàn)路段上的MAPE 進(jìn)行對(duì)比,結(jié)果如圖7 所示。其中,“xgboost_Y”代表用遺傳算法進(jìn)行調(diào)參的XGBoost 模型,“xgboost_H”代表用hyperopt 方法自動(dòng)調(diào)參的XGBoost 模型,組合1 代表用誤差倒排法確定權(quán)重的組合模型,組合2 代表用最小絕對(duì)值法確定權(quán)重的組合模型。
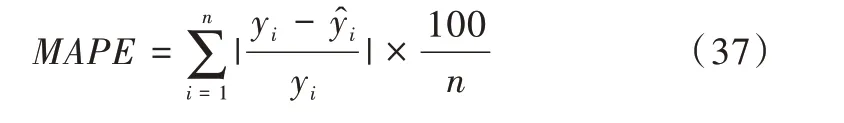
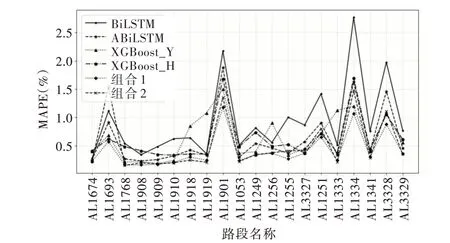
Fig.7 Comparison of broken lines of different models of MAPE圖7 不同模型MAPE 的折線對(duì)比
由圖7 可以看出,未添加注意力機(jī)制的BiLSTM 模型的預(yù)測(cè)能力相較于其它模型表現(xiàn)較差,添加了注意力機(jī)制之后,使得MAPE 指標(biāo)有較大程度的下降,模型預(yù)測(cè)能力有較為明顯的提高。并且,利用了不同調(diào)參方式進(jìn)行調(diào)參的XGBoost 模型的MAPE 指標(biāo)相近。兩種組合模型在多數(shù)路段上表現(xiàn)優(yōu)于其它單一模型,但在路段AL1693 上,使用誤差倒排法確定權(quán)重的組合模型表現(xiàn)差于任何一個(gè)單一模型。綜合而言,使用最小絕對(duì)值法確定權(quán)重的組合模型預(yù)測(cè)能力優(yōu)于任何一個(gè)單一模型,在所有模型中表現(xiàn)最優(yōu)。
箱線圖可以用來(lái)反映一組數(shù)據(jù)的中心位置和散布情況,為了更直觀統(tǒng)計(jì)不同模型在所有實(shí)驗(yàn)路段上MAPE 指標(biāo)的離散情況,現(xiàn)將不同模型在所有實(shí)驗(yàn)路段上的MAPE指標(biāo)繪制為箱線圖,如圖8 所示。
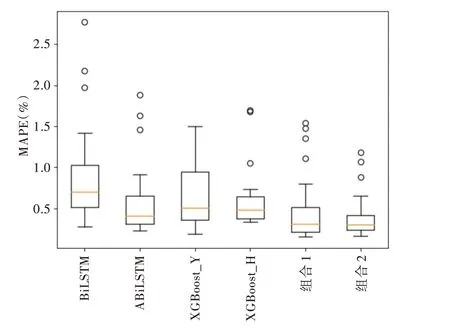
Fig.8 Comparison of MAPE box lines of different models圖8 不同模型MAPE 箱線圖對(duì)比
由圖8 可以得出,兩種組合模型MAPE 指標(biāo)的中位數(shù)低于其它所有模型,但組合2 即使用最小絕對(duì)值法確定權(quán)重的組合模型,相較于使用誤差倒排法確定權(quán)重的組合模型,其MAPE 指標(biāo)更為集中,上四分位數(shù)和上邊緣也更低,使用最小絕對(duì)值法確定權(quán)重的組合模型的異常值數(shù)量及取值也均小于使用誤差倒排法確定權(quán)重的組合模型。綜上所述,使用最小絕對(duì)值法確定權(quán)重的組合模型在所有模型中表現(xiàn)出最好的預(yù)測(cè)效果。
通過(guò)表6、圖7 及圖8 可以得出,本文提出的使用最小絕對(duì)值法確定權(quán)重的組合模型在不同指標(biāo)評(píng)價(jià)下,表現(xiàn)均優(yōu)于其它任何模型,從而說(shuō)明ABiLSTM 與XGBoost 組合模型可以提高單一模型預(yù)測(cè)準(zhǔn)確度。
5 結(jié)語(yǔ)
本文將BiLSTM 模型與注意力機(jī)制相結(jié)合,對(duì)BiLSTM模型進(jìn)行了改進(jìn)。通過(guò)實(shí)驗(yàn)證明,該模型相較于BiLSTM模型表現(xiàn)出更好的預(yù)測(cè)效果。XGBoost 模型具有大量參數(shù),本文嘗試了兩種不同的調(diào)參方法,即遺傳算法調(diào)參和hyperopt 自動(dòng)調(diào)參,為確定組合模型的權(quán)重,使用誤差倒排法和最小絕對(duì)值法分別進(jìn)行實(shí)驗(yàn),選取表現(xiàn)更好的最小絕對(duì)值法為不同模型確定權(quán)重系數(shù),進(jìn)而將模型進(jìn)行組合。通過(guò)實(shí)驗(yàn)證明,該組合模型較任何單一模型都表現(xiàn)出更好的預(yù)測(cè)效果。本文所使用的數(shù)據(jù)集考慮了時(shí)間相關(guān)性,但未考慮到空間相關(guān)性。現(xiàn)實(shí)生活中,一條路段的通行情況不僅與它相鄰時(shí)間段的路況有關(guān),還與相鄰路段的通行情況有關(guān)。因此,下一步還應(yīng)使用時(shí)空數(shù)據(jù)進(jìn)行實(shí)驗(yàn),更加全面地考慮影響交通時(shí)間的各種因素,從而提高交通時(shí)間預(yù)測(cè)準(zhǔn)確性。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
