基于GMM 的說話人識別系統研究及其MATLAB 實現
2021-08-24 08:36:42何建軍
軟件導刊 2021年8期
何建軍
(深圳電器公司 技術中心,廣東深圳 518001)
0 引言
在現實生活中,很多情況下都需要驗證人們的身份。隨著人們交際范圍的擴大,人際關系也變得日趨復雜,人們往往需要與其他各行各業的人打交道,而這些人際交往往往又會涉及到一些金錢、個人隱私等方面的私密信息。因此,要想保障雙方正常且安全的交往,往往需要鑒定對方身份。
為此,人們進行了大量研究工作,試圖尋找一種更可靠、方便的身份驗證方法。與傳統身份驗證方式相比,生物特征認證具有更好的可靠性與安全性[1]。生物特征包括聲紋、指紋、人臉、虹膜等。聲紋(Voiceprint)是一種聲波頻譜,其中包含了相應的語言信息,查看時需用電聲學儀器進行顯示。與指紋識別、臉部識別、手指靜脈識別等生物特征識別技術一樣,聲紋信息作為人的基本生理特征,有其獨特優勢。如聲音是非接觸性的,用戶容易接受;聲紋信息不需要記憶,因此不存在被遺忘的情況;其還具有獨特性、唯一性和識別性強等特征。正因為具有以上優點,聲紋信息作為一種身份驗證方式獲得了人們重視,并得到了廣泛研究,聲紋識別也應運而生。
說話人識別(Speaker Recognition,SR)也稱為聲紋識別、話者識別,屬于生物特征識別技術的范疇,是一種通過聲紋信息識別說話人身份的技術。其以表征說話人個性的語音特征為標準及依據,自動對說話人身份進行識別。
根據識別方式的不同,說話人識別可分為說話人探測跟蹤、說話人辨認與說話人確認3 類[2]。
(1)說話人探測跟蹤。說話人探測跟蹤(Speaker Seg?mentation and Clustering)也稱為說話人切分與聚類,是指在一段多人分時講話的語音中,正確將切換到下一個人說話的時間標注出來。
(2)說話人辨認。說話人辨認(Speaker Identification)也稱為說話人鑒別,是指從給定用戶集中將測試語音所屬的說話人辨認出來,是一個一對多的分析過程。說話人辨認又可劃分為“閉集(待鑒別的說話人一定不在設定的說話人集合范圍外)”和“開集(待鑒別的說話人可以不在設定的說話人集合范圍內)”兩種[3]。
(3)說話人確認。說話人確認(Speaker Verification)也稱為說話人驗證[4-7],是指通過對聲稱者(即聲稱自己是真實說話者)所說的一段測試語音按照某種判決方式確認其是否為真實說話者,這是一個一對一的確認過程。
隨著嵌入式軟硬件技術與無線通信技術的迅猛發展,語音輸入與控制將成為手持移動設備及嵌入式系統最佳的交互方式,以聲紋信息為特征的身份鑒別技術也顯得愈加重要。
1 相關研究
目前,針對說話人識別而提出的新的識別技術層出不窮,如結合GMM-UBM 結構[8]與支持向量機(Support Vector Machine,SVM)[9-10]的技術、基于得分規整技術的HNORM、ZNORM 和TNORM 技術、潛伏因子分析(Latent Factor Anal?ysis,LFA)技術、應用于說話人識別的大詞匯表連續語音識別(Large Vocabulary Continuous Speech Recognition,LVC?SR)技術等。然而,如今最出色的說話人識別系統依然是基于GMM 模型,尤其是基于UBM-MAP 結構的系統。
本文基于TIMIT 語料庫分析研究說話人語音信號預處理,以及說話人語音特征提取原理與方法,并利用MATLAB進行美爾頻率倒譜系數(Mel Frequency Cepstrum Coeffi?cient,MFCC)[11]提取。在此基礎上詳細研究了GMM 模型基本原理,以及EM 算法和K-均值聚類算法,最后使用MATLAB 實現了基于GMM 模型的說話人識別系統,完成了GMM 模型參數訓練與識別過程。為分析該系統性能,本文通過實驗分析了不同GMM 模型階數與不同訓練語音樣本時長對系統識別性能的影響。
2 說話人識別系統
2.1 說話人識別系統基本結構
一個完整的說話人識別系統建立與應用過程可分為模型參數訓練階段和結果識別階段[12]。
模型參數訓練階段:首先對訓練語音進行預加重、分幀與加窗等預處理,然后按照所選特征的計算方法對預處理后的語音信號提取特征參數,最后用提取出的特征參數估計模型參數集并進行存儲,在識別階段作為參考模型。本文設計的說話人模型訓練框圖如圖1 所示。

Fig.1 Block diagram of speaker model training圖1 說話人模型訓練框圖
結果識別階段:前期處理與訓練階段相同,即首先對待識別的語音進行預加重、分幀及加窗等預處理,然后對預處理后的語音信號提取所選特征參數,接下來將這些特征參數與預先存儲在計算機模板庫中的參考模板或模型進行匹配計算,最后根據計算出的相似度,按一定準則輸出匹配結果。本文設計的說話人識別框圖如圖2 所示。

Fig.2 Block diagram of speaker recognition圖2 說話人識別框圖
2.2 語音信號預處理
2.2.1 采樣與量化
語音信號是一維模擬信號,其是一個幅度隨時間不停變化的時變信號。要想在計算機上處理語音信號,必須先對其進行采樣與量化,從而在時間和幅度上將其變成能在計算機上處理的離散的數字信號。
根據奈奎斯特定理,為使采樣后的語音信號不丟失信息,采樣頻率必須設定為高于兩倍的語音信號最大頻率,才能用采樣后的語音信號重新構造并還原出原始語音信號。在實際的語音信號處理過程中,采樣頻率一般取8~10kHz。在一些系統中為獲取更高的識別率,采樣頻率可取15~20kHz。
采樣后的語音信號因其在幅度上還保持連續,為使其幅度值也離散化,還需進行量化處理。一般用二進制表示量化值(即量化字長),倘若用B 個二進制數表示量化值,則:

式(1)表明:量化器中每個bit 對信噪比的貢獻大約為6dB,當量化字長為10 bit 時,信噪比為53dB。由于語音信號信噪比可達55dB,因此應選擇大于10 bit 的量化字長。
2.2.2 語音信號預加重
經過采樣與量化后的語音信號還要進行預加重處理,因為語音信號在高頻處會有能量損耗,為彌補這些高頻損失,須在預處理過程中進行預加重以提升高頻部分。
可在A/D 轉換之前進行預加重處理,不僅可達到預加重目的,而且可達到對語音信號動態范圍進行壓縮處理、提高語音信號信噪比的目的。也可在A/D 轉換之后進行預加重處理,即利用能對高頻特征進行提升的具備6dB/倍頻程的數字濾波器[13]進行預加重處理。該數字濾波器的Z傳遞函數如下:

式中,a為預加重系數,其值接近于1,如取a=0.937 5。
對于待處理的語音信號,可用以下公式進行預加重:
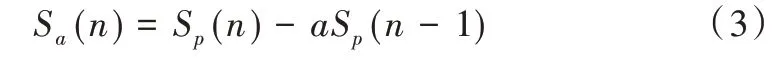
式中,Sa為預加重操作前的原始語音信號,Sp為預加重操作后的語音信號。
2.2.3 語音信號加窗分幀
語音信號幅值是隨時間變化而發生變化的,其不是一個穩態過程[14],而是屬于時變信號。但是,在短時段上可認為聲道形狀、激勵性質保持不變,因此可采用穩態過程分析方法進行語音信號分析。短時分析的前提是獲取短時語音,即對輸入語音進行劃分小段操作,也即加窗。窗函數對語音信號進行分段操作,移動窗函數即可獲得語音信號的一個個短時段。其中,一個短時段作為短時分析的一幀,一般而言,在一個短時段內語音信號基本保持穩定,聲道參數基本不發生變化。通常該短時段(也即一幀語音時長)取值范圍為10~30ms。
為從每一幀中取出含有N 個樣本的語音信號序列,可將窗函數w(n)與原來的語音信號S(m)相乘。加窗運算定義為:

設窗口長度為N,窗函數主要分為以下幾種:
(1)矩形窗。

(2)漢明窗(Hamming)。

(3)漢寧窗。

本文使用的是漢明窗。為使語音信號變化的信息盡可能不丟失,可采用相鄰兩幀之間有部分相互重疊的分段方法進行分幀(即相鄰兩幀語音信號的前一幀語音信號末端與后一幀語音信號前端相重疊),令相鄰兩幀之間可最大程度地保留語音信號變化信息,從而使相鄰兩幀的過渡更加平滑。相鄰兩幀之間的重疊塊稱為幀移,其幀移量取值范圍一般為幀長(即窗口長度)的1/3~1/2。加窗以后得到的一幀語音采樣序列為:

2.3 語音信號特征提取
實驗表明,能對說話人個性有效進行描述的特征有:短時能量、短時平均幅度、短時平均過零率、短時頻譜、短時基音周期及基音頻率、共振峰頻率及帶寬、部分相關系數(PARCOR)特征、線譜對(LSP)特征、線性預測系數(LPC)、倒譜特征、美爾頻率倒譜系數(MFCC)等。下面介紹兩種主流的表征說話人個性的線性預測系數和美爾倒譜系數特征提取過程。
2.3.1 線性預測系數(LPC)
線性預測[15]分析可這樣理解:對于一個語音信號,其某個時刻的采樣值可通過該時刻之前若干時刻的采樣值進行線性逼近。為得到一組最優的預測器系數,可在最小均方誤差上使線性預測計算得到的數值與實際語音采樣值逼近,而預測器系數就是過去若干時刻采樣值線性組合的加權系數。這種線性預測分析技術最早在語音編碼中使用,因此線性預測系數也常被人們稱為LPC(Linear Pre?diction Coding)。
可將p 階線性預測器從時域角度理解為:采用語音信號前p 個時刻采樣值的線性組合,并以最小預測誤差預測當前時刻樣本值。即的預測值為:


對上式進行Z 變換,得到具有如下形式的傳遞函數濾波器輸出:

式中,A(z)為預測誤差濾波器。
為得到一組最優的預測器系數,假設E 為語音幀上所有的預測均方誤差:

進行線性預測分析的前提是用于分析的語音信號具備短時平穩特征,也即是說必須在一段短時語音段上進行,即按幀進行。大量實踐證明:LPC 參數是一種表征語音信號特征的良好參數。
2.3.2 美爾倒譜特征(MFCC)
美爾頻率倒譜系數(MFCC)[16-18]是采用先將語音功率譜轉換成Mel 頻率對應的功率譜,再進行濾波取對數,最后進行離散余弦變換的方法求取出來的,人們對頻率在1kHz以下聲音的感知依從線性關系,而對頻率在1kHz 以上聲音的感知依從近似的對數頻率線性關系。由此劃分語音頻率,將其劃分成一系列三角形的濾波器序列(即Mel 頻率濾波器組),這組濾波器在頻率的美爾(MEL)坐標上是等帶寬的。Mel 頻率與實際頻率的轉換關系為:

式中,f為實際頻率,單位為Hz。
MFCC 系數的計算是按幀進行的,首先將語音信號進行分幀、預加重與加窗,然后進行FFT 變換,計算出該語音幀的功率譜,再將其功率譜變換為對應于Mel 頻率的功率譜。在進行Mel 功率譜變換之前,需要先設置若干個三角形帶通濾波器,且帶通濾波器必須在語音信號頻譜范圍內。該濾波器組的中心頻率f(m),m=0,1,…,M-1 均勻分布Mel 頻率坐標軸上。
三角形帶通濾波器系數在計算MFCC 系數之前必須預先計算出來,計算MFCC 系數時直接使用該系數。Mel 帶通濾波器的傳遞函數為:

(1)預處理:為了對語音信號進行短時分析,需將短時語音段時長設定在10~30ms 范圍內,即確定每個語音幀的采樣點數,進而對每個語音幀進行預加重與加窗分幀操作,并計算出其時域信號x(n)。
(2)離散FFT 變換:對于信號x(n),為了計算其頻譜X(k),需對其作離散FFT 變換,則有:

式中,N 為FFT 變換點數。
(3)計算能量譜:對頻譜取模的平方,得到其能量譜|X(k)|2,0 ≤k≤N。
(4)在頻域上對能量譜進行濾波:用M 個Mel 帶通濾波器對能量譜進行濾波,對于每個帶通濾波器,對其頻帶范圍內所有能量進行疊加處理,即可得到M 個能量譜輸出:

(5)對濾波器組輸出的能量譜取對數:對能量譜s(m)取自然對數,可得到其對數功率譜S'(m)為:

(6)離散余弦變換:在對數功率譜S'(m)上進行離散余弦變換,得到M 個MFCC 系數,即:
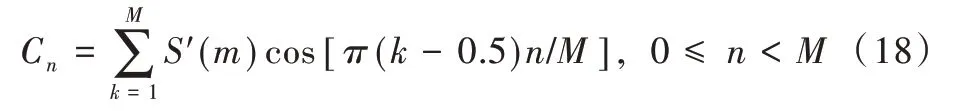
在進行MFCC 系數選擇時,可舍去代表直流成份的C0,取L 個參數作為MFCC 參數。一般L 取12~16,其計算流程如圖3 所示[19]。
本文采用MFCC 系數作為特征參數。

Fig.3 MFCC parameter calculation flow圖3 MFCC 參數計算流程
2.4 高斯混合模型
2.4.1 模型描述
高斯混合模型(GMM)本質上是一種多維概率密度函數,其核心思想為:在概率空間上,其特征向量的分布情形可用若干個單高斯概率密度函數進行線性逼近。將其用于說話人識別時,每個說話人對應一個GMM。
一個M 階的GMM 模型概率密度函數是通過對M 個高斯概率密度函數的加權求和得來的,如下所示:

式中,λ 表示模型參數集,由均值、協方差、權重組成;o表示K 維特征參量;i表示高斯分量序號。GMM 模型階數為M,表示有M 個高斯分量。P(o|q=i,λ)可簡化成P(o|i,λ)的形式,表示序號為i的高斯分量,對應分量i的概率密度函數。Ci對應于第i個高斯分量的混合權重,也即先驗概率。則有:

對于高斯分量i,常用一個維數為K 的單高斯概率密度函數進行描述,即:

式中,μi為均值矢量,Σi為協方差矩陣,i=1,…,M。
GMM 模型參數集λ 的表達形式如下:

式中,λ 由各均值矢量μi、協方差矩陣Σi及混合分量的權重組成。其中Σi可以選擇普通矩陣,也可以選擇對角矩陣,但由于后者的算法簡單且性能較好,為減少計算量,Σi通常取后者[20]。即:

將式(23)代入式(21)可得:

式中,ok、μik分別為矢量ο和矢量μi的第k個分量。
根據公式,GMM 觀察特征矢量與模型匹配的基本框架如圖4 所示。
2.4.2 模型參數估計
為說話人建立GMM 模型,實際上就是通過模型訓練對GMM 模型參數進行估計,使其能最佳地匹配訓練特征矢量分布。估計GMM 模型參數的方法有很多,本文采用最常用的最大似然(Maximum Likelihood,ML)估計法。該方法的前提條件是:給定訓練數據以估計GMM 模型參數,且使估計出模型的似然值達到最大。對于T 個訓練矢量序列ο={o1,o2,…,oT},GMM 的似然值可用下式表示:


Fig.4 Basic frame of the observation feature vector of the GMM model and the model matching圖4 GMM 觀察特征矢量與模型匹配基本框架
由于似然函數P(o|λ)與模型參數集λ是非線性函數關系,很難直接求出上式的極大值點,必須引入隱狀態參與計算。因此,為估計模型參數集λ,本文引入期望最大化算法(Expectation Maximization,EM)。EM 算法包含兩個步驟:EStep 和M-Step。E-Step 也即人們求期望(即Expectation,用E 表示)的步驟,M-Step 將E-Step 所求的期望最大化(即Maximization,用M 表示),重復E-Step和M-Step直到收斂。
EM 算法估計過程為:從一個初始模型開始,利用最大似然準則,迭代地估計模型參數,使再以作為新的模型參數開始下一輪迭代過程,直到滿足收斂條件。可引入輔助函數

這樣即可將迭代估計GMM 模型參數的過程分為Ex?pectation 和Maximization 兩 個 步 驟,即E-Step 和M-Step。E-Step 計算訓練數據落在隱狀態i的概率,M-Step 以局部最大準則估計GMM 模型參數集也即
EM 算法計算過程如下:
(1)E-Step :以Bayes 公式為依據和基礎,計算訓練數據對應于高斯分量i的概率。

E-Step 與M-Step 反復迭代,直至滿足收斂條件,即可得到最優的模型參數λ。
在實際訓練過程中,通常訓練數據較少,訓練環境背景噪聲較大,語音易受到噪聲污染,此時便很可能出現值過小的情況。然而,過小的方差會極大程度上影響對整體似然函數的計算。為避免該情況的發生,必須限制方差范圍。即:

采用EM 算法估計GMM 模型參數的流程如圖5 所示。

Fig.5 Flow of estimating GMM model parameters by EM algorithm圖5 EM 算法估計GMM 模型參數流程
2.4.3 模型參數初始化
EM 算法迭代過程是從一個初始模型開始的,初始模型參數集λ的選擇會影響算法迭代速度,其根本原因在于EM 算法是一個局部最優搜索算法,經過反復迭代可求出一個最佳解。GMM 模型常用的初始化方法有兩種:①在訓練數據中任意取出與M 個高斯分量相對應的M 組數據,分別計算出每組數據的均值和方差,且將其作為高斯分量的初始均值和方差,并使各分量權重相同;②通過K-均值聚類算法[21]對模型參數進行初始化,并劃分訓練數據到M 個聚類中,每個高斯分量對應一個聚類,各個高斯分量的初始均值為對應聚類的均值,且每個高斯分量方差與對應聚類方差相同,而對應聚類內的數據量與總數據量的比值即為權重。
GMM 階數M 的選擇與實際應用有關,一般由實驗結果確定。K-均值聚類算法[22]的基本思想為:對于給定的樣本集(即訓練數據特征矢量集),按照樣本之間的距離大小將樣本集劃分為M 個類別,使得類別內的樣本盡量緊密聚集在一起,而類別間的樣本距離盡可能大,并選擇M 個初始聚類中心,按最小距離原則將各特征矢量xi逐個分配到M 類中的某一類,之后不斷計算類的中心及調整各特征矢量類別,最終使各特征矢量距離其所屬類別中心的平方和最小。具體計算步驟如下:
(1)在訓練數據特征矢量集中任選M 個樣本作為初始聚類中心:令k=0。

(3)計算重新分類后的各類中心。

2.4.4 識別判決
對于一個有N 個人的說話人識別系統,用λi(i=1,2,…,N)代表第i個說話人的GMM 模型。在進行識別時,假設待識別語音的觀察特征矢量序列為ο={o1,o2,…,oT},則判定該目標說話人為第n 個說話人的后驗概率為[23]:

式中,p(O|λn)表示第n 個說話人產生O的條件概率,p(O)表示全部說話人條件下出現O的概率,p(λn)表示第n個說話人的先驗概率。

為簡化計算,通常采用對數似然函數,則閉集說話人辨認的得分公式為:

3 系統實現
3.1 實驗環境
本文主要在HP 540 筆記本電腦上實現基于GMM 的說話人識別系統,該筆記本電腦的主要軟硬件配置如下:①CPU:Intel(R)Core(TM)2 Duo CPU T5470 @ 1.60GHz;②RAM:2GB;③操作系統:Windows XP Professional;④實驗環境:MATLAB R2009a。
3.2 語音庫
本文說話人識別實驗是在部分TIMIT 語音庫基礎上進行的,美國的LDC(Linguistic Data Consortium)第一個發布了擁有大量說話人的全英文語音數據庫TIMIT,因而TIMIT被廣泛應用于說話人識別研究[24]。TIMIT 語音庫由美國麻省理工學院(MIT)、SRI 國際公司(SRI)與德州儀器公司(TI)共同設計,并在TI 完成錄音[25]。其是在低噪聲環境下使用固定麥克風錄制的,采樣頻率為16kHz,采樣位數為16位。錄音人數共有630 人,其中男性438 人,女性192 人,每人講10 句話,囊括了美式英語的八大方言。該語音庫可以很好地區分性別、年齡段和地域。
為對比中英文語音庫在識別性能方面的差異,另選部分HI-MIA 語音庫進行對比實驗。HI-MIA 語音庫為昆山杜克大學與AISHELL 共同推出的一個基于遠場文本相關的說話人認證數據庫。該數據庫使用麥克風陣列和Hi-Fi麥克風在實際家庭環境中收集數據,共包含340 個說話人,每個說話人語料包含了近場麥克風拾音和遠場麥克風陣列的多通道拾音,可用于聲紋識別、語音喚醒識別等研究。
3.3 系統在MATLAB 下的實現
本文在MATLAB 下實現了基于GMM 模型的說話人識別系統,程序運行界面如圖6 所示。該系統主要分為兩大部分:訓練部分與識別部分。

Fig.6 MATLAB program running interface of speaker recognition system圖6 說話人識別系統MATLAB 程序運行界面
訓練時首先設置特征向量和GMM 模型參數,然后點擊“選擇訓練語音”按鈕選擇訓練語音文件,最后點擊“建立模型”或“繼續訓練”按鈕進行模型訓練,并保存模型參數,如圖7 所示。

Fig.7 Model training flow圖7 模型訓練流程
識別時同樣需要先設置特征向量和GMM 模型參數,然后點擊“選擇測試語音”選擇待識別的語音文件,最后點擊“識別”按鈕進行識別并輸出匹配結果,如圖8 所示。

Fig.8 Speaker recognition flow圖8 說話人識別流程
3.4 訓練階段
在進行模型參數訓練之前,先建立一個GMM 模型,并為GMM 模型分配存儲空間。每個GMM 模型存儲內容包括特征矢量維數、高斯分量混合數,以及各高斯分量的權重、均值矢量與方差矩陣。
建立模型后進行模型訓練,從說話人語音中提取語音樣本,對語音信號進行預加重、分幀加窗與端點檢測處理,提取出特征參數矢量,并用K-均值聚類算法對提取出的特征矢量進行聚類,得到GMM 模型的初始化模型參數λ(均值、混合權重及協方差矩陣)。初始化后即開始進行說話人GMM 模型訓練,本文采用期望最大化(EM)算法估計GMM 模型參數,從一個初始模型參數λ開始,估計出一個新的模型參數λˉ,使得在新模型參數下的似然度P(o|λˉ)≥P(o|λ)。之后再采用新模型參數λˉ開始下一次迭代,如此反復迭代直至模型收斂(本文設置的收斂界限為1.000 0e-004)。具體實現流程如圖9 所示。

Fig.9 GMM model training flow圖9 GMM 模型訓練流程
3.5 識別階段
本文采用閉集說話人識別方式,即將所有參與的說話人構成一個集合,在識別時判斷目標說話人為集合中的哪一個說話人。
3.6 系統性能
實驗從TIMIT 語音庫中隨機選取20 人的語音作為樣本,對說話人識別系統性能進行測試。實驗條件如下:①采用部分TIMIT 語音庫,使用16 階GMM 模型;②MFCC特征階數為10、12、14、16;③測試數據為1 段語音,每段平均時長為4.5s;④測試人數為10、13、16、20;⑤訓練數據為3 段語音,每段平均時長為4.5s。
說話人識別系統平均識別率如表1 所示。從表1 可以看出,系統性能隨著特征向量維數、測試人數的變化而變化,即識別率隨著特征向量維數的增加而提高,隨著人數的增加而降低,但特征向量維數達到一定值時識別率便不再增加。當測試人數超過16 人時,特征向量維數為12 時識別率最高。

Table 1 Average recognition rate of the speaker recognition system表1 系統平均識別率
3.7 實驗結果分析
3.7.1 GMM 模型階數對系統識別性能的影響
GMM 模型階數也即高斯分量個數,是影響系統識別性能的一個重要指標。若階數過小會使量化誤差過大,導致GMM 模型無法很好地表示整個向量空間;若階數過大,則系統訓練與識別計算量會非常大,卻無法明顯提高系統性能。因此,選擇一個合適的GMM 模型階數能顯著提升系統綜合性能。本文針對GMM 模型階數對系統性能的影響作了如下實驗。實驗條件如下:從TIMIT 語音庫中選取16 人的10 段語音作為樣本數據,平均每段語音時長為4.5s,其中每人選取4 段語音作為訓練數據來訓練模型;另選1 段語音作為測試數據,選擇24 維MFCC 系數作為特征參數,采用EM 算法訓練模型,每段測試語音作為一個測試單位,取測試結果的平均值作為系統平均識別率。對不同GMM模型的階數測試結果如表2 所示。

Table 2 Speaker recognition rate based on different order of GMM mode(lTIMIT)表2 不同GMM 模型階數下說話人識別率(TIMIT)
從實驗結果可以看出,GMM 模型階數越高,對特征空間的描述越精確。階數較低時,識別率較低;隨著階數的增加,識別率隨之上升,系統計算量也急劇增大。但當階數達到16 附近時,識別率則不再提升,反而還出現了下降趨勢,這是符合倒譜特征性質的。因此,在綜合考慮系統總體性能的基礎上,選擇一個合適的GMM 模型階數是很重要的。一般來說,階數不能取得過高,但也不能太低,往往需要大量實驗數據來確定。
為對比GMM 模型階數對系統識別性能的影響,另選部分中文語音庫HI-MIA 中的數據進行對比實驗。實驗條件如下:從HI-MIA 語音庫中選取20 人的20 段語音作為樣本數據,平均每段語音時長為1s;任選其中一段作為測試數據,選擇24 維MFCC 系數作為特征參數,采用EM 算法訓練模型,每段測試語音作為一個測試單位,取測試結果的平均值作為系統平均識別率。對不同GMM 模型的階數測試結果如表3 所示。

Table 3 Speaker recognition rate based on different order of GMM model(HI-MIA)表3 不同GMM 模型階數下說話人識別率(HI-MIA)
3.7.2 訓練語音時長對系統識別性能的影響
對GMM 模型的訓練需要一定時長的訓練語音數據,若訓練數據太少,模型訓練不充分,則不能得到有效的GMM模型;若訓練數據太多,將浪費大量訓練時間和系統資源,且識別率也不能得到相應提升,有時還會因過訓練導致系統識別性能下降。本文針對不同訓練時長下訓練的GMM模型識別性能進行測試。
實驗條件如下:從TIMIT 語音庫中選取16 人的10 段語音作為樣本數據,平均每段語音時長為4.5s;任選其中一段作為測試數據,在GMM 模型階數為16、MFCC 系數維數為24、人數不變的情況下,分別用不同時長的語音訓練GMM模型,取測試結果的平均值作為系統平均識別率。實驗結果如表4 所示。

Table 4 Speaker recognition rate based on different training durations表4 不同訓練時長下說話人識別率
從實驗結果可以看出,增加訓練時長可從總體上提升系統識別率,但到一定程度后便很難繼續提升。因此,在訓練模型時不應過度追求訓練時長。
為對比訓練語音樣本時長對系統識別性能的影響,另選部分中文語音庫HI-MIA 中的數據進行對比實驗。實驗條件如下:從HI-MIA 語音庫中選取20 人的20 段語音作為樣本數據,平均每段語音時長為1s;任選其中一段作為測試數據,在GMM 模型階數為16、MFCC 系數維數為24、人數不變的情況下,分別用不同時長的語音訓練GMM 模型,取測試結果的平均值作為系統平均識別率。實驗結果如表5所示。

Table 5 Speaker recognition rate based on different training durations表5 不同訓練時長下說話人識別率
4 結語
說話人識別技術作為一種有效的身份識別技術,為身份確認提供了一種極佳的驗證手段。隨著嵌入式軟硬件技術與無線通信技術的迅猛發展,語音輸入與控制將成為手持移動設備及嵌入式系統最佳的交互方式,以聲紋信息為特征的身份鑒別技術也受到越來越多關注。
本文首先對語音信號預處理及特征提取進行了詳細分析,然后以高斯混合模型作為說話人模型,對模型參數估計、模型參數初始化以及GMM 模型參數訓練與識別方法進行了詳細研究,最后,基于TIMIT 語料庫使用MATLAB 實現了一個完整的說話人識別系統,并通過實驗分析不同模型參數及不同訓練時長對系統性能的影響。實驗結果表明,在GMM 模型階數不高及使用人數不多的情況下,本文實現的說話人識別系統可滿足用戶的使用需求。
未來針對該系統還有一些問題需要繼續深入研究,例如:優化特征參數,以提升系統識別性能;通過模型參數估計算法或識別算法減小計算量,以縮短訓練或識別時間;將GMM 模型與其他模型相融合,從而提高系統識別率等。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
