基于置信度融合的自然場景文本檢測方法
2021-08-27 06:38:22蔣志鵬潘坤榕張國林劉玉琪孫科學
計算機技術與發展 2021年8期
蔣志鵬,潘坤榕,張國林,劉玉琪,張 瑛,孫科學,2*
(1.南京郵電大學 電子與光學工程學院,江蘇 南京 210023;2.射頻集成與微組裝技術國家地方聯合工程實驗室,江蘇 南京 210023)
0 引 言
在自然場景圖像中包含大量文本,這些文本信息可以作為圖像信息的說明和補充,因此從自然場景圖像中定位文字區域并識別文本語義已經成為計算機視覺和文檔分析領域重要的研究任務[1];該任務在圖像檢索[2]、圖像中敏感詞檢測、盲人導航[3]、輔助駕駛[4]等領域具有廣泛的應用。背景單一、顏色紋理統一的文本檢測技術已經十分成熟,并且已有廣泛的應用,例如身份證、發票單據等各種稿件中的文本檢測與識別,但是由于自然場景背景復雜、光照不均勻、模糊遮擋等不同因素,都影響了文本檢測的定位精度和召回率,給文本檢測技術帶來了新的挑戰和難點[5-8]。
隨著計算機硬件計算能力的提升和深度卷積神經網絡在計算機視覺領域的應用,深度學習技術越來越多地應用在一般目標檢測任務(SSD[9]、YOLO[10]、Faster-RCNN[11])中,促進了自然場景文本檢測任務性能的提升和應用范圍的擴大。深度卷積神經網絡[12](convolutional neural network,CNN)中的卷積和池化運算對圖像的平移、旋轉和縮放具有較強的魯棒性,其層層堆疊的結構能夠將一些低層次的圖像特征重組成一些高層次的語義特征,許多研究者將卷積神經網絡應用到自然場景文本檢測任務中進行特征提取。例如2014年,Girshick等人[13]提出了R-CNN算法,將深度學習技術應用到一般目標檢測技術中,隨后以R-CNN為基礎的Fast-RCNN[14]和Faster-RCNN[11]算法相繼問世。2015年,Jonathan等人[15]首次提出了全卷積網絡(fully convolutional networks,FCN),該網絡不包含全連接層,能夠實現逐像素級別的預測和分類,對細小目標的位置信息感知能力更強,并且可以接受任意尺寸的圖像輸入。
基于卷積神經網絡的自然場景文本檢測技術主要包括特征提取網絡、預測網絡和非極大抑制算法。在傳統的自然場景文本檢測方法[16-17]中,非極大抑制算法基于預測文本框的分類置信度對重復檢測的預測框進行篩選和合并。然而,該過程忽略了預測框的定位精度,使得一些定位更精確而分類置信度略低的預測框可能在非極大抑制步驟中被抑制,影響文本檢測的準確率。
為了改善上述不足,文中設計了置信度融合的文本檢測方法。在多任務預測網絡中設計一個新的分支預測錨框與真實文本框的交并比IOU(intersection over union)值,將該值作為預測文本框的定位置信度。在非極大抑制算法中,用分類置信度與定位置信度融合的結果取代分類置信度,保留定位更精確的預測文本框,提高文本檢測的準確率。
1 基于置信度融合的文本檢測方法
1.1 方法總體設計
置信度融合的文本檢測方法包括特征提取網絡、多任務預測網絡和非極大抑制算法等三個部分,網絡結構如圖1所示。其中特征提取網絡的作用是從輸入圖像中提取多尺度的特征圖;多任務預測網絡的作用是對特征圖上每個預定義的錨框的文本信息進行預測;非極大抑制算法的作用是對同一文本區域重復預測的預測框進行合并和篩選。研究者通常先將分類置信度低于閾值的預測框刪除,再按照分類置信度對剩下的預測框進行排序,保留分類置信度最大的預測框,剩下的預測框則會被抑制。在以上過程中,那些定位更加精確而分類置信度略低的預測框可能會被抑制。因此文中將分類置信度和定位置信度進行融合以改進非極大抑制算法。

圖1 置信度融合的文本檢測模型網絡結構
1.2 基于VGG的特征提取網絡
VGGNet基礎網絡的泛化能力強、簡潔實用,后續成為檢測和識別任務中的主干網絡。文中選擇VGGNet網絡并對其進行改進,作為特征提取網絡的主干網絡。
VGG-16一共包括13個卷積層和2個全連接層,它的網絡結構參數列于表1。
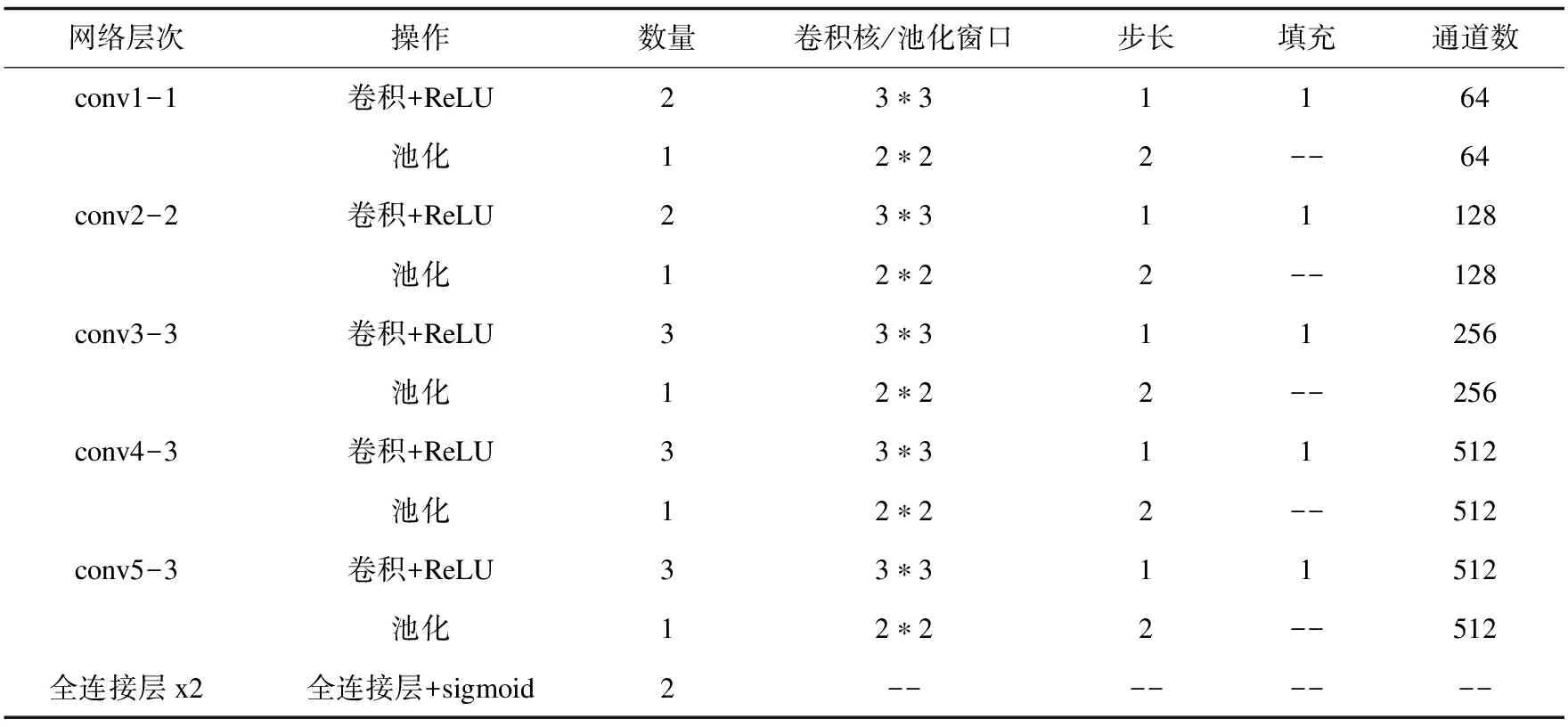
表1 VGG-16的網絡結構
特征提取網絡保留VGG-16的conv1到conv4層,將最后的兩個全連接網絡改成3*3的卷積層,為conv5,并在此基礎上增加conv6到conv11,如圖1灰色區域所示。其中conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11是文中在特征提取網絡中抽取的多尺度特征圖。
不同尺度的特征圖具有不同的感受野,提取不同層次的特征,通常越淺層的特征圖感受野越小,通常可以提取一些邊緣、局部特征,能夠檢測面積較小的文本區域,而越深層的特征圖感受野越大,通常可以提取圖像的一些語義特征,可以檢測面積較大的文本區域。
1.3 多任務預測網絡
(1)錨框設置。
多尺度特征圖從特征提取網絡輸出后,文中會在特征圖上密集采樣錨框,設特征圖的大小為N*N,將特征圖的每個像素點(i,j)視為不同橫縱比的錨框的中心坐標,那么像素點(i,j)處將會產生5種橫縱比ar的錨框,如式(1):
ar=[1,3,5,7,10]
(1)
則每個N*N的特征圖中會生成N*N*5個錨框。
由于不同輸出層的特征圖尺度不一樣,每層的感受野大小也不同,因此每層特征圖對應的錨框的面積也不一樣,特征圖越淺,感受野越小,錨框的面積也就越小。文中設計的特征提取網絡一共輸出6層特征圖,將圖1中從左往右的特征圖依次記為特征圖1到6,那么第k層特征圖中的錨框面積大小如式(2):
(2)
式中,Smin表示最小錨框面積,即第一層特征圖上的錨框面積;Smax表示最大錨框面積,即第六層特征圖上的錨框面積;k表示特征圖的層數。
每個錨框的寬和高的計算方式如式(3)和式(4):
(3)
(4)

(2)文本框的預測和坐標計算。
接下來,多任務預測網絡根據設計好的錨框預測特征圖上每一個錨框的類別置信度scorecls、定位置信度scoreiou和每個錨框的坐標偏移量offsetloc,分別對應如圖2中的“預測類別”分支、“預測交并比分支”和“坐標信息”分支。
圖2中,“交并比預測”分支和“預測類別”分支分別采用兩個卷積層和兩個sigmoid激活函數,“坐標信息”分支采用兩個卷積層和ReLU激活函數。卷積核采用3*5而非3*3的尺寸,這種卷積核的尺寸是針對文本狹長的矩形特征設計的,這樣可以產生狹長的矩形感受野,有利于處理更大橫縱比的文本。
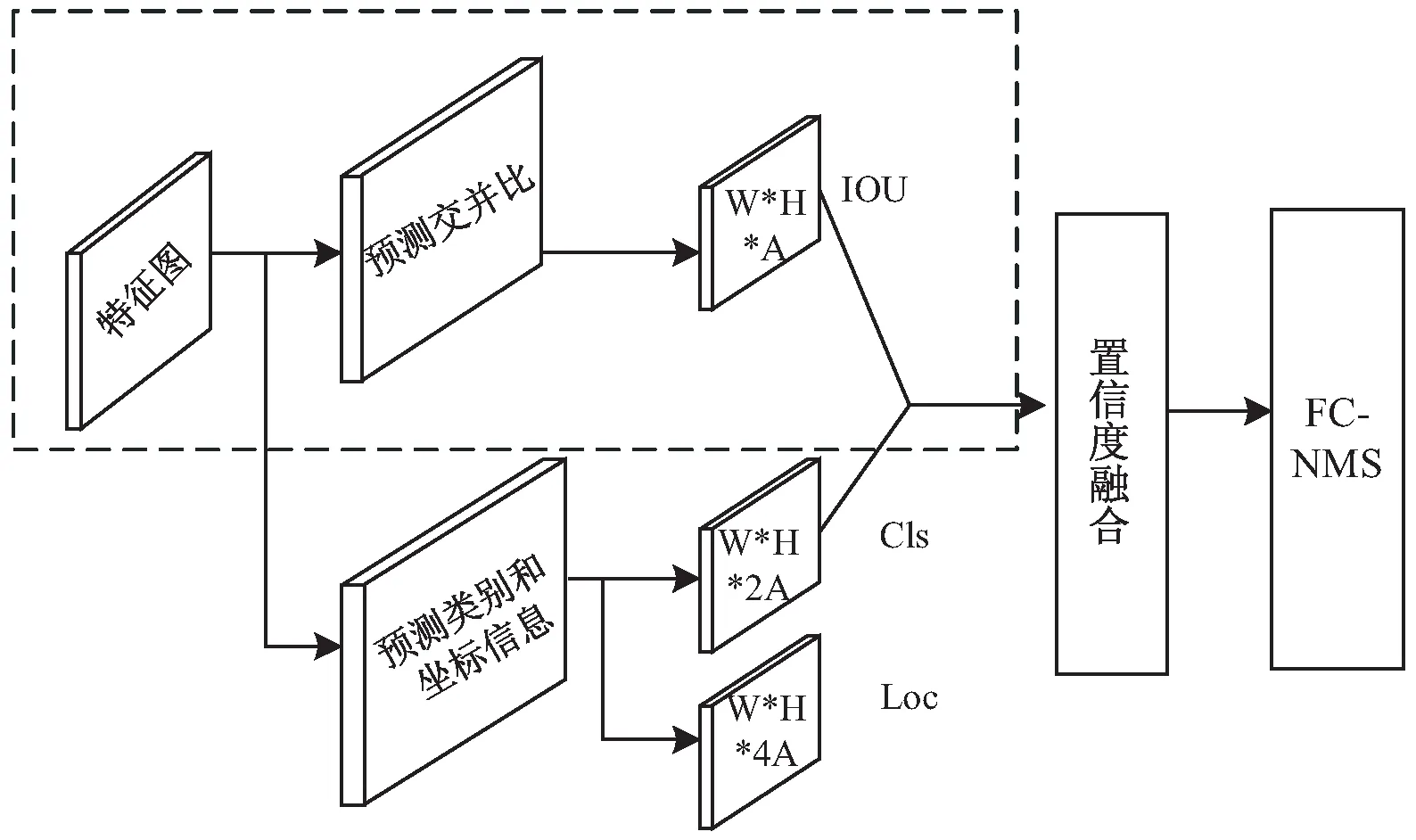
圖2 多任務預測網絡
設第k層特征圖的(i,j)位置處有一錨框b0=(x0,y0,w0,h0),多任務預測網絡在(i,j)處輸出(Δx,Δy,Δw,Δh,scorecls,scoreiou),scorecls、scoreiou為該預測文本框的分類置信度和定位置信度。假設該預測框的scorecls滿足閾值,被認為是一個文本框,那么該預測文本框的中心坐標和寬高為b=(x,y,w,h),計算方式如式(5):
(5)
式中,x0,y0,w0,h0為錨框的中心坐標、寬和高;Δx,Δy,Δw,Δh為錨框與預測文本框之間的坐標偏移量。
1.4 改進的置信度融合的非極大抑制算法
在一般非極大抑制算法(NMS)中,當一個真實文本框存在重復檢測時,分類置信度最大的那個文本框將會被保留。然而,由于分類置信度和定位置信度的不匹配,定位更準確而分類置信度偏低的文本候選框可能在NMS算法中被抑制,從而影響文本檢測性能。本小節在非極大抑制算法中,用融合的分類置信度與定位置信度取代傳統的分類置信度,改進后的NMS算法稱為置信度融合的非極大抑制算法(FC-NMS)。
根據文獻[18]中的分析,候選文本框的IOU值與定位置信度高度相關,而與分類置信度相關性較小。考慮到傳統NMS方法中分類置信度的作用,與文獻[18]中直接用定位置信度取代分類置信度作為NMS中候選框排序的依據不同,本小節將分類置信度scorecls與定位置信度scoreiou用不同的權重值進行融合,得到一個融合置信度scoreFC。將融合置信度作為NMS步驟中文本框排序的依據,scoreFC的計算方式如式(6):
scoreFC=Wcls×scorecls+Wiou×scoreiou
(6)
式中,Wcls=0.2、Wiou=0.8分別表示分類置信度和定位置信度的權重。
與傳統NMS算法類似,在候選框集合中,將融合置信度scoreFC最高的文本框記為A,計算剩下的候選框與A的交并比IOU值,計算公式如式(7):
(7)
式中,A和B表示兩個候選文本框,IOU(A,B)表示框A與框B的交集面積與并集面積之比,IOU越大,表示A與B重疊率越高。A與B的交集部分如圖3所示。
圖3中,框A與框B的交集部分是一個矩形。若框B與框A的IOU值大于閾值Qnms,表明框B與框A的重疊程度較高,將框B從候選框集合中刪除,同時更新A的分類置信度。比如要刪除框C,則框A的分類置信度重置為socreclsA,socreclsA的計算公式如式(8):

圖3 矩形框A和B的交并比示意圖
socreclsA=max(socreclsA,socreclsC)
(8)
式中,socreclsA表示框A的文本類別置信度,max表示求最大值,socreclsC表示框C的文本類別置信度。
置信度融合的非極大抑制算法(FC-NMS)的偽代碼如算法1所示。
算法1:FC-NMS。
輸入:Box={b1,b2,…,bn},cls,iou,Qnms
Box表示候選框的集合,bi表示第i個候選框
cls/iou/FC:映射每個候選框的分類置信度,定位置信度和融合置信度的函數
Qnms:FC-NMS的篩選閾值
輸出:Result_Box:最終的預測文本框
1:Result_Box = None
2:while Box!= None:
3: box = argmax(FC)
4: c = cls(box)
5: delete box from Box
6: for bjin Box:
7: if IOU(box,bj) > Qnms:
8: c =max(c, cls(bj))
9: delete bjfrom Box
10: end if
11: end for
12: Result_Box = Result_Box∪{[box,c]}
13:end while
14:return Result_Box
2 文本檢測器的訓練
本章通過對交并比預測分支單獨訓練增強交并比網絡的兼容性;通過旋轉、平移、縮放等手段手動變換訓練集中所有的真實文本框,從而生成候選文本框集。將該候選框集合中與真實文本框交并比小于0.5的候選框去除。然后從該候選集合中抽取訓練數據對交并比網絡進行訓練。這種憑借經驗增廣的數據集為交并比網絡帶來了更好的性能和魯棒性。
對于置信度融合的文本檢測模型的初始化,文中用預訓練的VGG-16模型的權重參數初始化VGG-16部分,用預訓練的TextBoxes模型初始化卷積6~11層的權重參數。從第11層卷積開始往后的多任務網絡中所有的參數都用均值為0,標準差為0.01的高斯分布進行初始化。
定位置信度scoreiou經過標準化后的取值范圍為[-1,1]。訓練和測試圖像的大小均為700*700,訓練時的數據批量大小為16張圖像,迭代次數為12萬次,學習率的初始值設為0.001,在迭代6萬次后,學習率調整為0.000 1,權重衰減系數和動量分別設為0.000 1和0.9。優化算法采用隨機梯度下降法。本章中訓練交并比網絡用IOU損失函數[19],訓練坐標偏移量回歸任務用smooth-L1作為損失函數,而文本分類任務采用交叉熵作為損失函數。
3 實驗與結果分析
3.1 數據集與評價指標
3.1.1 數據集
文中采用ICDAR2011和ICDAR2013這兩個水平文本數據集進行實驗。ICDAR2011包括229張訓練圖像、251張測試圖像,對文本區域進行單詞級別的標注。ICDAR2013包括229張訓練圖像、233張測試圖像,對文本區域進行字符級別和單詞級別的標注。這兩種數據集中的圖像都來自于日常生活中的拍攝,數據樣本的分布充分考慮了自然場景圖像可能受到的光照不均勻、曝光過度、遮擋、模糊等影響,覆蓋了大部分復雜場景。使用這兩個數據集能夠對文中方法進行客觀公正的評價。
3.1.2 評價指標
當文本檢測器輸出一個預測文本框D時,可以利用公式(7)計算D與真實文本框G的交并比IOU(D,G),并設置一個交并比閾值0.7,如果D與G的IOU值大于該閾值,就認為預測出的D是與G匹配的檢測正確的文本框。
按照預測文本框的正例和反例、真實文本框的正例和反例,可以將檢測結果分為四種不同的組合情況,并據此對模型檢測正確的文本框數量、檢測錯誤的文本框數量、未檢測出的文本框數量進行統計,統計規則列于表2。

表2 預測框與真實文本框的匹配數量
表2中,第一列的中間兩行分別表示預測結果為文本框和非文本框的情況,第一行的中間兩列表示實際情況下為文本框和非文本框的情況。預測為文本框實際也為文本框的為True Positive(TP),表示預測正確的文本框數量;預測為文本框實際不是文本框的為False Positive(FP),表示誤檢的文本框數量;預測不是文本框而實際是文本框的為False Negative(FN),表示漏檢的文本框數量。所有預測出的文本框的數量記作preT,所有實際的文本框的數量記作GTT。
3.2 實驗結果分析
基于ICDAR2011數據集對候選框的分類置信度和定位置信度的融合系數作了對比實驗,實驗結果列于表3。表3中,Wcls表示分類置信度的系數,Wiou表示定位置信度的系數。第一行實驗結果表示在非極大抑制算法中僅用分類置信度作為排序依據,即原始方法。隨著定位置信度的加入和比重的增大,文本檢測的召回率逐漸提高,但是當完全用定位置信度替代分類置信度(表3最后一行)時,雖然召回率提高了,但是準確率也有所下降,這可能是因為提高召回率的過程中除了保留了許多正確的文本框也引入了一些誤檢的文本框。因此文中選取0.2作為分類置信度的系數、0.8作為定位置信度的系數。

表3 不同融合系數的實驗對比
文中提出的置信度融合非極大抑制算法(FC-NMS)的文本檢測方法(下文簡稱為文中方法)與其他方法在數據集ICDAR2011和ICDAR2013上的性能對比結果列于表4和表5。
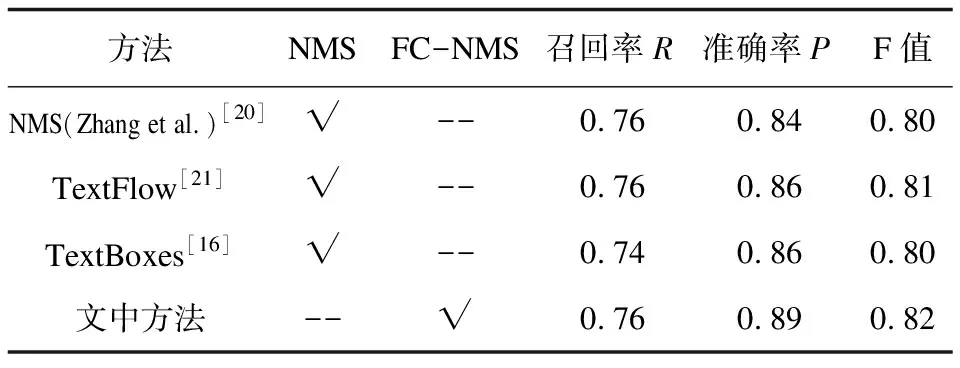
表4 基于ICDAR2011的實驗結果
由表4和表5可以看出,文中方法與基準方法(TextBoxes)相比,F值提高了1%,主要性能提升體現在準確率上;在ICDAR2011數據集上,比TextBoxes在準確率上提升了3%;在ICDAR2013數據集上,比TextBoxes在準確率上提升了2%,這主要是因為在非極大抑制算法中融合了定位置信度,使得分類置信度較低但定位置信度較高的預測框能夠保留下來。綜上所述,置信度融合的文本檢測方法可以有效提高文本檢測的準確率,改善文本檢測的性能。
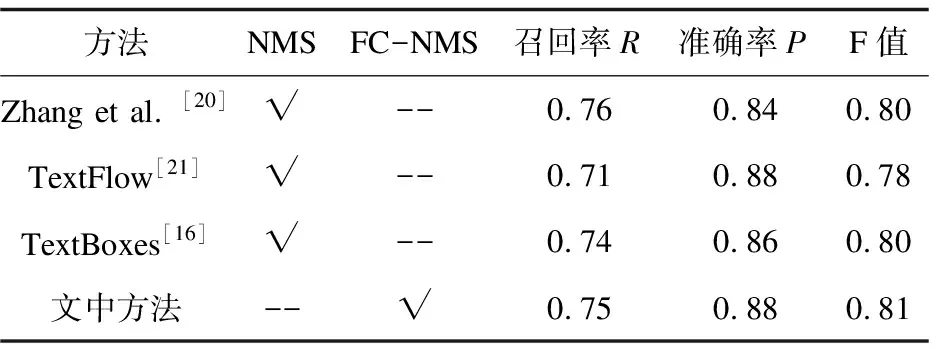
表5 基于ICDAR2013的實驗結果
4 結束語
提出了一種置信度融合的自然場景文本檢測方法,使得檢測的文本框更加緊致,包含的背景區域更少,能夠有效提高自然場景文本檢測的準確率。然而,文中對新設計的交并比分支進行單獨訓練時,需要自行準備訓練數據,并對數據翻轉、縮放等增廣操作,這種數據準備方式可能會使數據覆蓋范圍受限,從而影響模型的訓練效果,降低定位置信度預測效率。因此未來的工作可以繼續探究交并比分支訓練時對數據集的需求,滿足模型訓練需求。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
