基于差分隱私的連續位置隱私保護機制
2021-08-28 10:08:28李洪濤任曉宇王潔馬建峰
通信學報 2021年8期
關鍵詞:用戶
李洪濤,任曉宇,王潔,馬建峰
(1.山西師范大學數學與計算機科學學院,山西 臨汾 041099;2.西安電子科技大學計算機科學與技術學院,陜西 西安 710071)
1 引言
移動智能設備和定位技術的快速發展給移動用戶帶來了各種類型的基于位置的應用,為人們的生活帶來諸多便捷。然而,由于移動用戶在享受便捷服務的時候需要向基于位置的服務(LBS,location based service)提供他們的位置信息,使大量用戶位置信息被不可信的第三方獲取,可能使用戶遭受嚴重的位置隱私泄露問題,危害用戶的隱私安全。針對位置隱私保護技術,相關學者進行了大量研究。目前,多數位置隱私保護技術以k-匿名或l-多樣性為基礎,此類技術是將用戶的真實位置泛化成一個區域,實現位置信息的隱私保護。其中,文獻[1]基于用戶的單一敏感屬性設計了個性化k-匿名模型與KAUP(k-anonymity algorithm for personalized quasi-identifier attributes),提高了數據發布過程中的隱私保護程度。文獻[2]提出一種基于l-多樣性大數據隱私保護方法,采用NER(named entity recognition)方法將數據表示為結構化形式,進而對數據進行匿名化,實現對隱私數據的保護。抑制和擾亂技術也是近些年使用較多的保護方法。抑制技術的主要思想是不發布用戶的敏感位置信息。文獻[3]提出了一種基于信息熵的軌跡抑制隱私保護算法,通過函數計算抑制敏感位置點的最低代價,選擇合理的抑制方式對原始數據集中包含敏感點的序列進行抑制。擾亂技術是將真實位置通過一定的變換生成假位置,達到保護真實位置的目的。文獻[4]基于假位置隱私方法,提出了一種最大最小假位置選擇(MMDS,maximum and minimum dummy selection)方案,使攻擊者很難結合邊信息過濾一些假位置,對位置信息進行隱私保護。以上幾種隱私保護技術都有一定的局限性和缺點,攻擊者可以通過長期的觀察、挖掘和分析等方法獲取用戶的位置隱私信息[5-7],因此這些技術無法抵抗相關攻擊背景知識攻擊。
Dwork 等[8]于2006 年提出了差分隱私保護模型,其因良好的隱私保護強度成為一種主流的技術,通過對原始查詢結果添加隨機噪聲,使在數據集中添加或刪除某一條數據對查詢結果不產生影響,從而讓攻擊者很難通過多次查詢反推某條真實數據,實現隱私保護。Chen 等[9]將差分隱私保護機制應用于位置數據保護,通過對位置數據加入Laplace 噪聲,實現對位置數據的隱私保護。霍崢等[10]對自由空間和路網空間分別構造了噪聲四分樹和噪聲R-樹,通過添加Laplace 噪聲保護位置數據,但沒有考慮2 個連續時刻位置數據間的相互影響。吳云乘等[11]采用差分隱私位置保護模型,把已知生成位置時真實位置的后驗概率與真實位置概率的比值作為滿足差分隱私的條件提出了DPLRM(differential privacy location release mechanism)。Xiao 等[12]將地圖轉換為帶權無向圖,給位置區域分配隱私級別,在文獻[11]的基礎上,用馬爾可夫鏈表示2 個連續位置的關系,提出基于差分隱私的位置保護方案。然而,現有的差分隱私解決方法多數沒有考慮位置間的關聯,即使對用戶所有位置進行保護,攻擊者也會根據地理拓撲、時序關系等方法獲取用戶隱私信息。
針對以上問題,本文提出了一種差分隱私位置保護機制(DPLPM,differential privacy location protect mechanism),該機制能有效保護位置隱私和最大化數據可用性。本文主要貢獻如下。
1) 根據路網的拓撲關系,對敏感位置周圍路段進行隱私級別劃分,提出道路隱私級別(RPL,road privacy level)劃分算法(本文簡稱為RPL 算法)。
2) 提出DPLPM,構建位置樹結構并給位置信息分配隱私預算,為敏感路段添加符合差分隱私機制的Laplace 噪聲,實現位置信息的隱私保護。
3) 理論分析和實驗結果證明,所提機制能夠較好地保護位置隱私和最大化數據可用性。
2 相關定義及其概念
2.1 差分隱私的相關定義
定義1鄰近數據集。設數據集有相同的屬性結構,兩者僅相差一條記錄,即,則稱D和D' 為鄰近數據集。
定義2差分隱私。給定鄰近數據集D和D',并已知某查詢算法A,若算法A在數據集D和D'的任意輸出結果O滿足不等式(1),則稱算法A滿足ε-差分隱私。
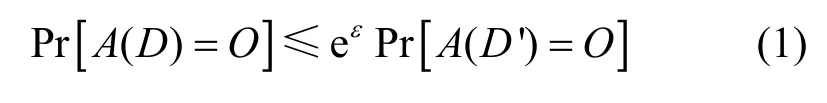
隱私預算ε用來控制算法A在2 個鄰近數據集輸出相同結果的概率比例,它表明隱私保護的程度,即ε越小,隱私保護程度越高,當ε=0 時,隱私保護程度達到最高。
定義3全局敏感度。設函數f:D→Rd,輸入一個數據集,輸出d維實數向量,對于任意臨近數據集D和D',稱GFf為函數f的全局敏感度。

2.2 Laplace 機制
Laplace 機制通過向確切的查詢結果中加入服從Laplace 分布的隨機噪聲來實現ε-差分隱私,主要面向數值型查詢結果。記初始位置下尺度參數為b的Laplace 分布為Lap(b),其概率密度函數為
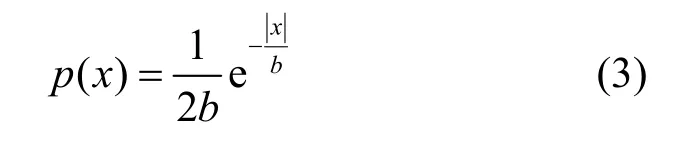
定義4Laplace 機制。給定數據集D,設有函數f:D→ed,其敏感度為Δf,那么隨機算法A(D)=f(D)=Y提供ε差分隱私,其中Y~Lap(Δf/ε)為隨機噪聲,服從尺度參數為 Δf/ε的Laplace 分布。
2.3 數據可用性
本文采用文獻[12]的定義來測量本文數據可用性。假設t時刻發布位置是Ot,其真實位置是Zt,本文采用Ot和Zt之間的歐氏距離作為誤差評價,即
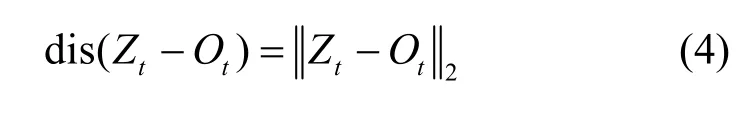
特別地,對于長度為|W|的軌跡,本文同樣以距離誤差為基礎衡量數據可用性,如式(5)所示。RMSE等于位置上處于敏感區域的真實位置與其發布位置之間的均方根誤差和。RMSE 越大,表示數據可用性越差。
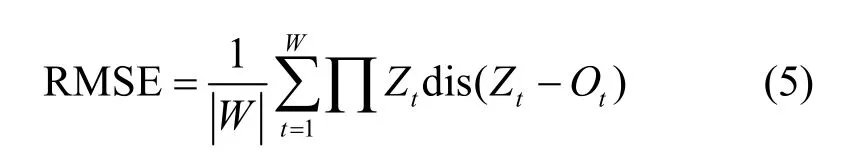
其中,∏Zt為指示函數,當Zt為敏感位置時,指示函數∏Zt的值等于1,否則該值等于0。
3 系統結構和威脅模型
3.1 系統結構
本文的系統結構如圖1 所示,主要包括三部分:客戶端、隱私保護處理器和位置服務處理器。客戶端主要通過GPS 定位模塊獲取用戶位置,并將位置存儲至數據庫中;隱私保護處理器分為數據劃分模塊、連續位置數據保護模塊和數據庫,數據劃分模塊將連續位置劃分隱私級別,并將經過隱私級別劃分的數據存儲至數據庫,連續位置數據保護模塊對數據庫中的位置提供差分隱私保護;位置服務處理器根據連續位置保護模塊提出的查詢請求,獲得位置信息查詢反饋,并將查詢結果存儲至數據庫中。

圖1 系統結構
針對用戶位置隱私泄露問題,本文提出一種基于差分隱私的連續位置保護機制。在客戶端,GPS定位模塊獲取用戶位置數據,并將其上傳至數據庫,數據劃分模塊用RPL 算法對位置數據劃分隱私級別;假設隱私保護處理器是可信任的第三方,連續位置數據保護模塊從數據庫中獲取經過隱私級別劃分的數據,通過DPLPM 添加基于差分隱私的Laplace 噪聲,并生成位置集合;位置服務處理器向連續位置數據保護模塊提出查詢請求,連續位置數據保護模塊將查詢結果反饋至位置服務提供商;位置服務提供商在提供服務之后,將數據存儲至數據庫。
3.2 威脅模型
本文假設攻擊者會不定時攻擊用戶的位置數據。很多位置服務提供商都有不同程度的安全保障,但當其服務器或數據庫受到攻擊時,用戶的位置數據等隱私信息就可能被泄露。基于這個假設,本文提出的隱私威脅模型如圖2 所示。智能手機、便攜電腦和近場通信(NFC,near field communication)等便攜設備獲取用戶位置數據,并將連續位置數據傳送至服務器端進行處理,進而從位置服務提供商處獲取服務。攻擊者可以通過攻擊服務器端或直接攻擊位置服務提供商,獲取用戶隱私信息。
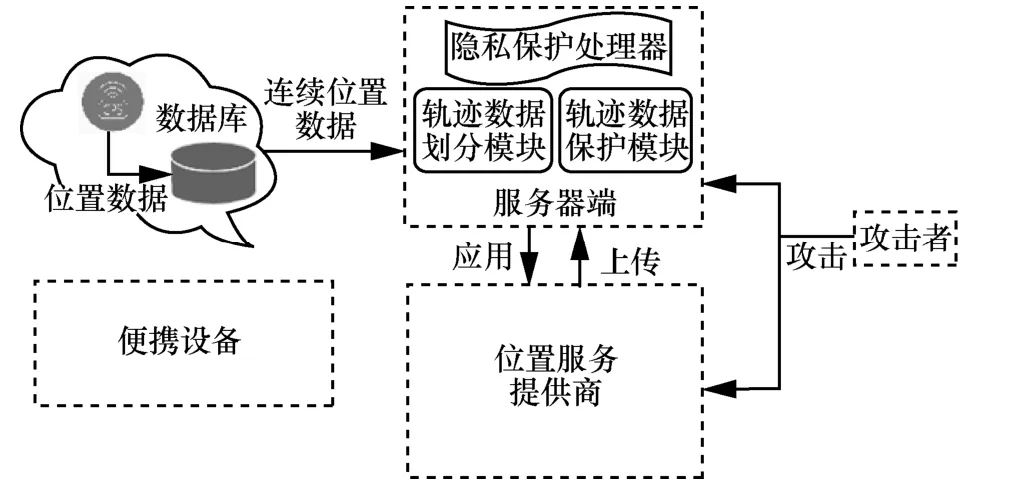
圖2 隱私威脅模型
4 本文機制描述
本文常用符號如表1 所示。

表1 常用符號
4.1 RPL 算法
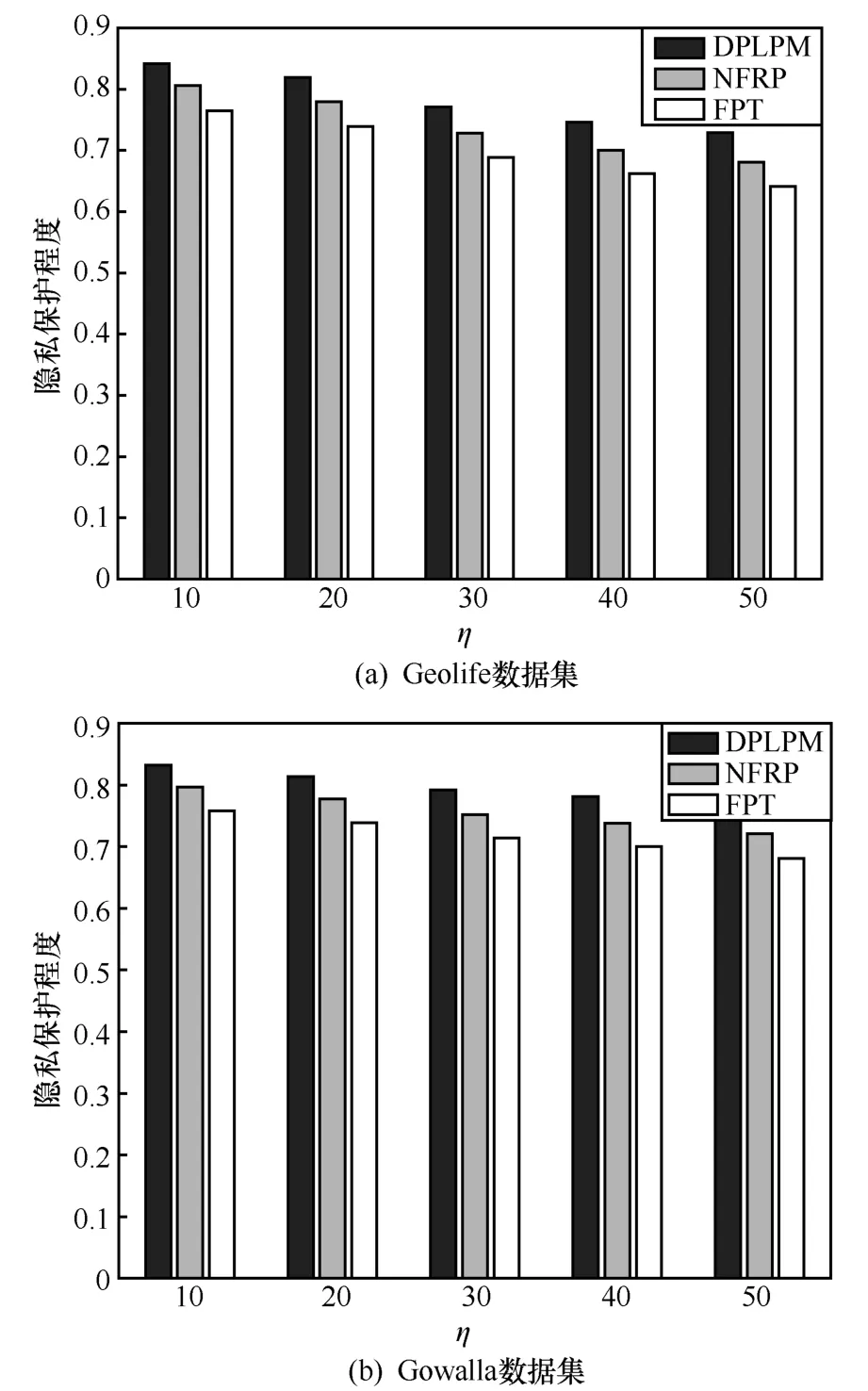
在數據劃分模塊,改進道路隱私級別劃分算法,結合岔路口位置提出RPL 算法。圖3(a)為真實區域的路網示意,○表示路口i,表示真實位置,表示用戶當前所處位置,2 個路口間的虛線表示路口可直達。假設用戶會選擇最短路徑到達目的位置。圖3(b)統計了到達不同的目的位置最少需要經過路口的個數。其中,用戶自定義初始敏感位置集合為SLinitial={sl1,sl2,…,slsl},對應的隱私級別集合為PLinitial={pl1,pl2,…,plpl}。PLinitial中元素的取值范圍為[0,1],值越大表示敏感位置隱私級別越高。
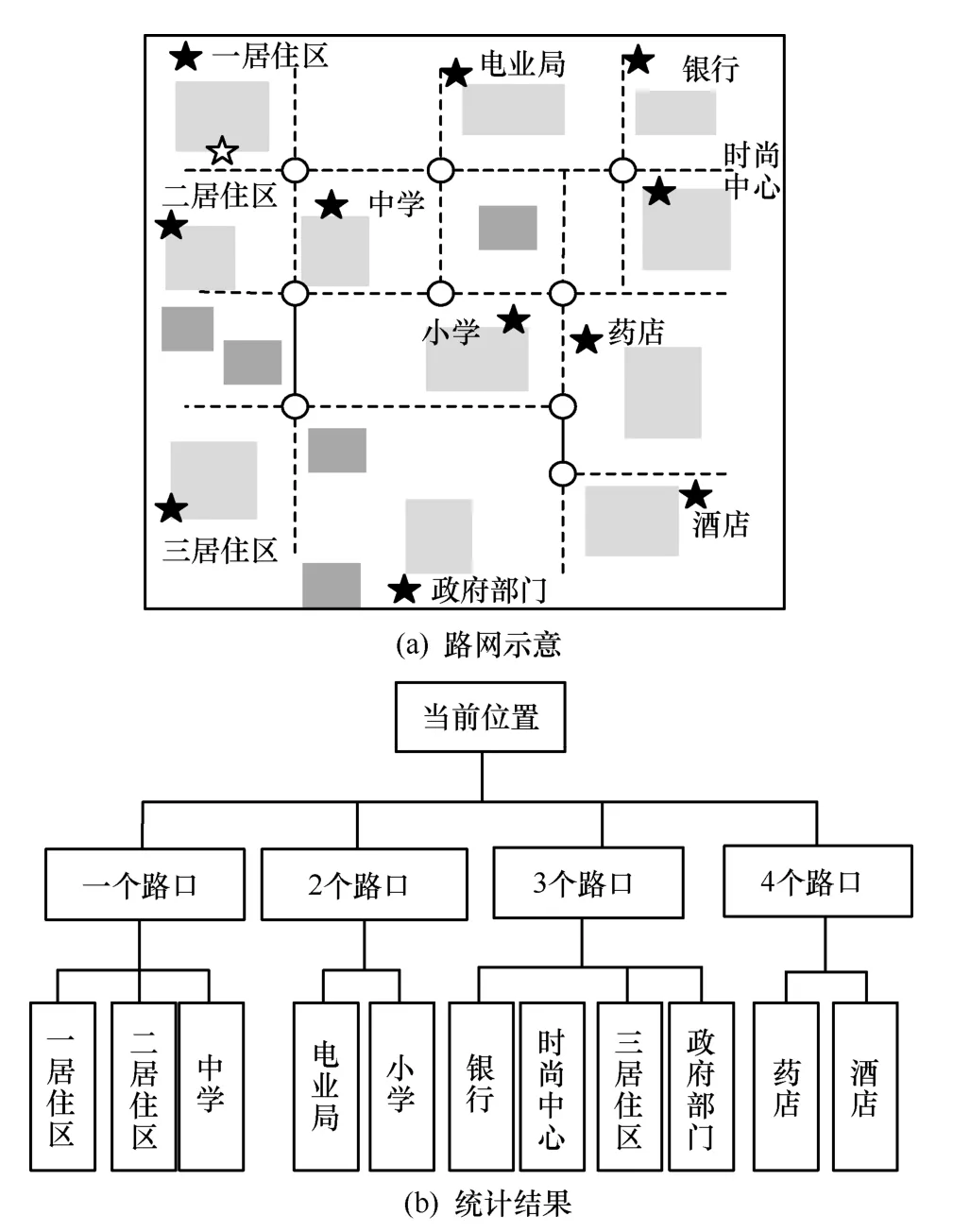
圖3 路網示意及到達不同的目的位置需要經過路口的個數
假設v為初始敏感位置,其隱私級別為v.pl,v的鄰接位置集合為neighborSet,g是neighborSet 中的一個位置,v與g的距離為g.dis,則g的隱私級別為
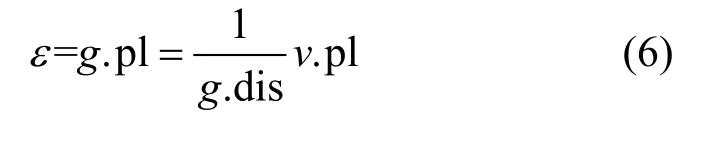
從式(6)可知,g.dis 越大,g.pl 就越小,即距離敏感位置越遠的點隱私級別越小。若g.dis=0,即g與初始敏感位置v重合,則取其本身的隱私級別和分配的隱私級別中較大者作為新的隱私級別;若g.dis≠0,即g為初始非敏感位置,則其隱私級別為g.pl。
已知用戶初始敏感位置,根據圖3(a)計算該位置的隱私級別,步驟如下。確定初始集合SLinitial中的位置v至路口i的路段上是否存在用戶的第二個敏感位置,若不存在,則計算位置v與i之間的距離dis(v,i)=R,當R<η時,輸出位置v與i的路段v→i;當R≥η時,輸出距離為η的路段。若位置v至路口i的路段上存在用戶的第二個敏感位置g,則先根據式(6)計算位置g的隱私級別,并與g的初始隱私級別進行比較,取其中較大者作為位置g的最終隱私級別,此時,輸出的敏感路段為兩段,即v至g的路段v→g,以及g至路口i的路段g→i。用戶道路隱私級別劃分算法如算法1 所示。
算法1RPL 算法
輸入路網G=
輸出敏感路段及其隱私級別


如果在初始敏感位置v到路口的路段上出現用戶自定義的另一個一級初始隱私位置,則直接輸出位置v到路口的全部路段。
4.2 差分隱私位置保護機制
在位置數據保護模塊,采用位置樹結構,基于差分隱私保護模型提出DPLPM。本文構建位置樹反映路網實際情況。v表示初始敏感位置,i表示路口。路網結構轉換為位置樹如圖4 所示。
1) 如圖4(a)所示,敏感位置周圍有2 條路通往路口i,轉換為樹結構后,包含一個根節點、2 個葉子節點。
2) 如圖4(b)所示,敏感位置周圍有3 條路通往路口i,轉換為樹結構后,包含一個根節點、3 個葉子節點。
3) 如圖4(c)所示,在敏感位置周圍的路段上,有一個敏感位置g,轉換為樹結構后,深度為2,包含一個根節點、一個子節點、2 個葉子節點。
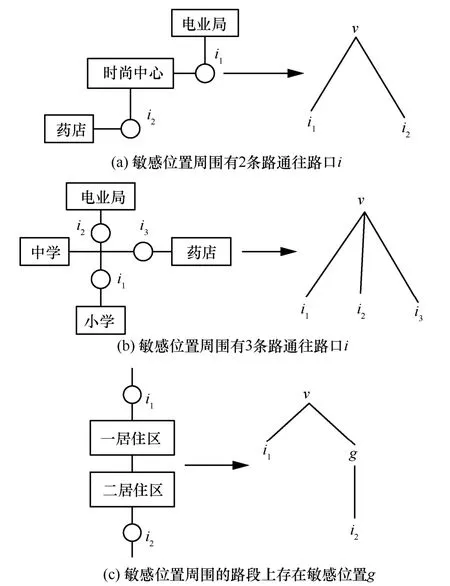
圖4 路網結構轉換為位置樹
依次類推,將路網轉換為位置樹。
根據差分隱私定義可知,隱私預算越小,對數據的隱私保護程度越大,以位置樹的高度為基礎,對隱私預算進行分配。

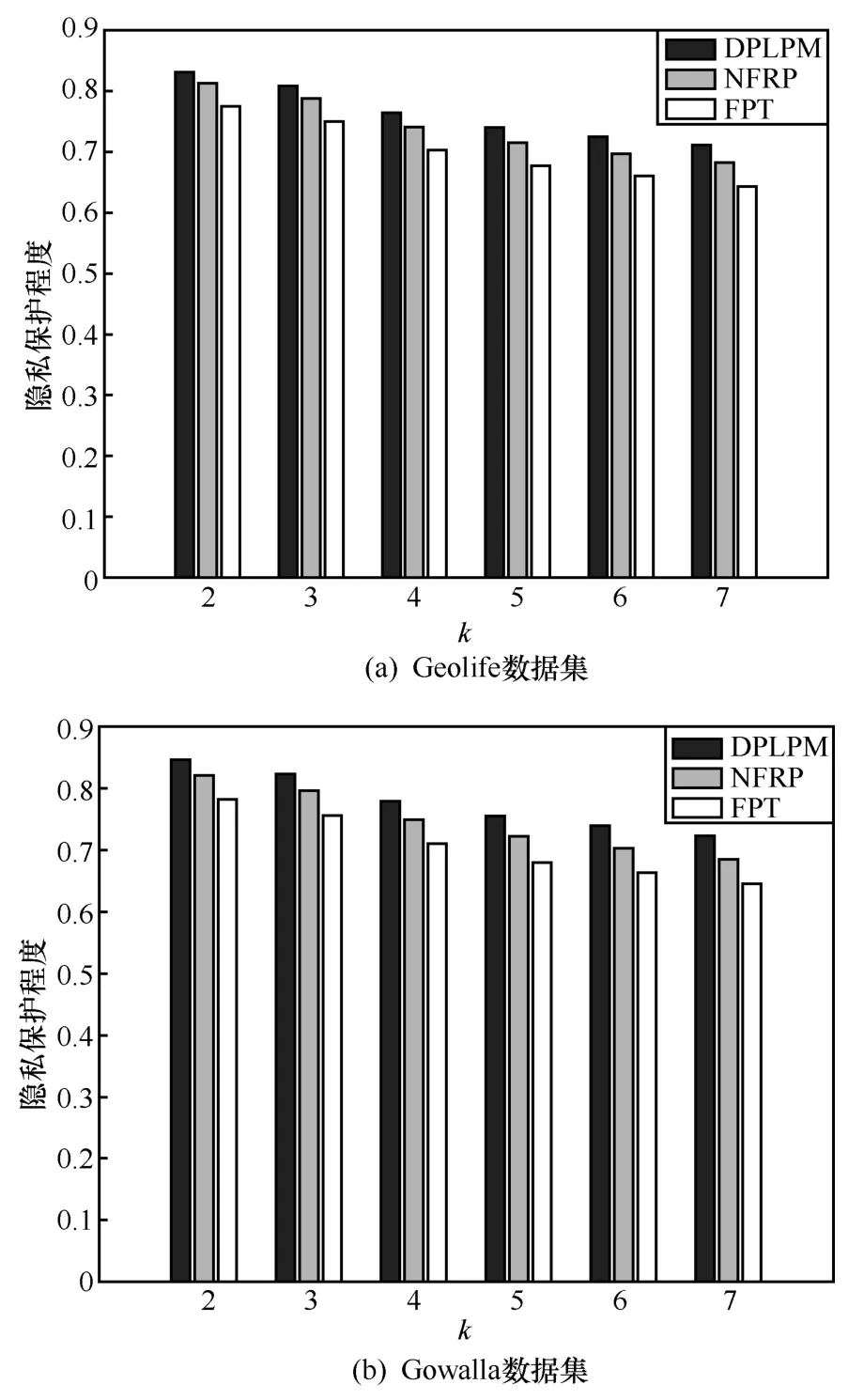
其中,q為2 個敏感位置間隱私級別比值,即其應分配隱私預算的比值。位置v為隱私級別最高的敏感位置,相應地,v.pl 最大,即g.pl 下面,根據路網示意構建位置樹結構,根據樹的高度分配隱私預算,添加Laplace 噪聲,實現對用戶位置數據的保護。首先,以位置v為根節點構建位置樹,若構建樹的高度為1,則將隱私預算ε平均分配至用戶的t個敏感位置;若樹的高度大于1,則按照式(7)分配隱私預算,并根據隱私預算為每個位置加入符合差分隱私機制的Laplace 噪聲Laplace Noisy(εt)。差分隱私位置保護機制如算法2所示。 算法2DPLPM 輸入路網G= 輸出位置集合W 給定隱私預算ε,本節證明RPL 算法和DPLPM均滿足ε-差分隱私。 RPL 算法不能以差分隱私機制中數據集的概念來定義,因為對于位置和位置隱私來說,用戶的每個位置都是需要被保護的,本文假設已知某時刻的發布位置Ot,根據已發布的位置判斷真實位置的后驗概率為Pr(Zt|Ot),即 由差分隱私定義可知,RPL 算法滿足ε-差分隱私。 在DPLPM 中,加入Laplace 噪聲,即符合ε-差分隱私,證明過程如下。 證明已知Laplace 機制的概率密度函數為,設px表示Al(x,f,ε)的概率密度函數,py表示Al(y,f,ε)的概率密度函數,則對于某個輸出值Z,有 可知,RPL 算法和DPLPM 均滿足ε-差分隱私。證畢。 1) 時間復雜度。假設連續位置數據中共有n個位置,在RPL 算法中,最耗時的部分是遍歷所有位置,其時間復雜度為O(n)=n;在DPLPM 中,最耗時的部分是將隱私預算分配給每層樹結構,再將每一層的隱私預算分配給敏感路段中的每一個位置,其時間復雜度為O(n)=ht。總體來說,本文所提算法計算消耗較小。 2) 隱私性。根據DPLPM,t時刻發布位置Ot使當前位置Zt滿足ε-差分隱私,即軌跡W中,每一個位置都滿足ε-差分隱私,可知軌跡W滿足ε-差分隱私。 3) 數據安全性。本文經過數據劃分模塊和連續位置數據保護模塊的處理后,將數據上傳至位置服務提供商,位置服務提供商不能獲得用戶原始數據,所以攻擊者不能通過位置服務提供商對用戶進行攻擊;本文采用差分隱私保護模型抵御背景知識攻擊,攻擊者無法根據用戶的行為模式和地理拓撲關系推斷出用戶的真實位置,并根據用戶的隱私級別分配不同的隱私預算,實現對用戶位置數據的保護。 4) 數據可用性。本文通過式(5)對數據可用性進行分析。由式(5)可知,影響數據可用性主要有以下3 個因素。①軌跡長度。軌跡長度越長,需要考慮的時刻越多,使發布位置與真實位置之間的距離越大,即數據可用性越差。②敏感位置Zt與發布位置Ot的歐氏距離,距離越大,RMSE 越大,數據可用性越差。③指示函數∏Zt的值,即判斷位置Zt是否為敏感位置,若為敏感位置,則∏Zt=1,否則,∏Zt=0,數據可用性最高。本文所提RPL 算法使敏感軌跡長度降到最低,同時由概率比值可得真實位置與發布位置之間的距離為eε,通過控制隱私預算減少兩者的距離,由此可知,本文在數據可用性方面是最優的。 本節測試本文所提DPLPM 的性能。實驗使用Python 實現,在3.60 GHz CPU、8 GB RAM 的Windows 10 平臺上運行,實驗數據集為真實位置數據集Geolife[13]和Gowalla[14]。將DPLPM 和FPT(final private trajectory)算法[15]、基于頻繁駐留點的加噪(NFRP,noisy of frequent resident points)算法[16]進行比較,從隱私保護程度、算法運行時間和數據可用性3 個方面判斷本文算法的優劣性。 6.2.1 隱私保護程度 本節實驗分析了本文所提DPLPM 的隱私保護程度,通過用戶自定義和式(6)計算隱私級別pl、由仿真實驗結果選出距離閾值η、初始敏感區域SLinitial大小k和隱私預算ε,比較本文算法和FPT算法、NFRP 算法在Geolife 數據集和Gowalla 數據集上的隱私保護程度。 k=4,pl=0.25 時,距離閾值η對隱私保護程度的影響如圖5 所示。 圖5 η對3 種算法隱私保護程度的影響 從圖5 可知,3 種算法的隱私保護程度都隨著η的增大而減小。根據式(5)可知,隨著輸出路段距離的不斷增大,位置的隱私級別不斷下降,即隱私保護程度減小。 pl=0.25,η=20 時,初始敏感區域SLinitial大小k對隱私保護程度的影響如圖6 所示。 圖6 k對3 種算法隱私保護程度的影響 圖6 可知,3 種算法的隱私保護程度都隨著k的增大而減小。這是因為敏感位置越多,則所需的隱私預算越多,即隱私保護程度越小。 k=4,η=20 時,隱私級別pl 對隱私保護程度的影響如圖7 所示。從圖7 可知,隨著pl 的增加,3 種算法隱私保護程度都在增加。這是因為隱私級別pl 越大,為其分配的隱私預算越小,即隱私保護程度要越大。 圖7 pl 對3 種算法隱私保護程度的影響 k=4,η=20,pl=0.25 時,隱私預算ε對隱私保護程度的影響如圖8 所示。從圖8 可知,隨著ε的增加,3 種算法隱私保護程度都在減少,由差分隱私定義可得,隱私預算越大,隱私保護程度越小。 此外,從圖5~圖8 可以看出,在不同參數下,本文所提算法的隱私保護程度都優于其他2 種算法。 圖8 ε對3 種算法隱私保護程度的影響 6.2.2 數據可用性 本文用RMSE 衡量數據可用性。本節實驗分別在Geolife 數據集和Gowalla 數據集上運行,對比了本文所提DPLPM、FPT 算法和NFRP 算法的數據可用性。其中,FPT 算法通過構建噪聲前綴樹實現對位置數據的保護,NFRP 算法根據統計后的流量圖中邊的流量值添加噪聲。 k=4,pl=0.25 時,距離閾值η對RMSE 的影響如圖9 所示。 圖9 η對3 種算法RMSE 的影響 從圖9 可知,3 種算法的RMSE 都隨著η的增大而增大。NFRP 算法的可用性最差,因為該算法只為某一位置的經緯度添加噪聲;FPT 算法的位置數據可用性相對較好,但FTP 算法較多地對空節點添加噪聲;DPLPM 考慮了位置連續性之間的影響,數據可用性是最好。 pl=0.25,η=20 時,初始敏感區域SLinitial大小k對DPLPM、FPT 算法和NFRP 算法RMSE 的影響如圖10 所示。 圖10 k對3 種算法RMSE 的影響 從圖10 可知,3 種算法的RMSE 都隨著k的增大而增大。這是因為位置個數的增大會導致隱私預算增多,添加的噪聲也增加,即數據可用性變差。NFRP 算法的可用性最差,DPLPM 可用性最好,而FPT 算法介于二者之間。 k=4,η=20 時,隱私級別pl 對DPLPM、FTP算法和NFRP 算法RMSE 的影響如圖11 所示。 從圖11 可知,3 種算法的RMSE 都隨著pl 的增大而增大。這是因為隨著隱私級別的增大需要添加的噪聲增加,數據可用性變差。DPLPM 的可用性最好,FPT 算法次之,NFRP 算法最差。 圖11 pl 對3 種算法RMSE 的影響 6.2.3 算法運行時間 本節實驗在Geolife數據集和Gowalla數據集上運行DPLPM、FPT 算法和NFRP 算法,對比3 種算法的運行時間。 k=4,pl=0.25 時,距離閾值η對DPLPM、FPT算法和NFRP 算法運行時間的影響如圖12 所示。 從圖12 可知,隨著η的增加,3 種算法的運行時間都隨之增加。因為DPLPM 只需要提供加噪,所以DPLPM 運行時間是最少的。 圖12 η對3 種算法運行時間的影響 pl=0.25,η=20 時,初始敏感區域SLinitial大小k對DPLPM、FPT 算法和NFRP 算法運行時間的影響如圖13 所示。 圖13 k對3 種算法運行時間的影響 從圖13 可知,隨著k的增加3 種算法的運行時間都隨之增加。FTP 算法在2 個數據集上的運行時間都是最長的,而NFRP 算法次之,DPLPM 的運行時間是最短的。 k=4,η=20 時,隱私級別pl 對DPLPM、FTP算法和NFRP 算法運行時間的影響如圖14 所示。 從圖14 可知,隨著pl 的增加,3 種算法的運行時間都在增加。FPT 算法在2 個數據集上運行時間都最長,NFRP 算法次之,DPLPM 的運行時間最短。 圖14 pl 對3 種算法運行時間的影響 本文所提DPLPM 與其他方法的比較如表2 所示。文獻[17]提出一種基于隱私拆分的軌跡隱私保護方法,建立單點位置的發布對查詢軌跡的前向和后向隱私風險評估機制,通過拆分查詢軌跡,消除軌跡中位置間的相關性,但沒有控制隱私預算,同時使算法開銷增大。文獻[12]提出一種差分隱私保護方法,根據時間相關性,使用馬爾可夫鏈預測前一個位置對后一個位置的影響,考慮了路網中的位置連續性,但沒有對隱私預算進行合理分配。文獻[18]將不規則樹引入差分隱私方法中,減少連續查詢時噪聲疊加帶來的查詢精度下降問題,但沒有考慮位置間的相關性。文獻[19]提出AC-TFIDF(adaptive clustering based TFIDF)算法,根據重要位置點在不同時刻的分布狀況,選擇聚類中心代替原始位置,生成發布位置,但沒有考慮路網實際情況。 表2 相關工作比較 本文研究了連續位置隱私保護問題,基于差分隱私機制,提出了一種連續位置隱私保護機制。在位置數據劃分模塊提出了隱私級別劃分算法,根據路網關系計算其相鄰位置的隱私級別,使攻擊者無法推斷出用戶隱私位置;在位置數據保護模塊提出差分隱私位置保護機制DPLPM,根據道路關系映射位置樹,根據樹的高度為敏感路段分配隱私預算,并添加符合差分隱私機制的Laplace 噪聲,保護了用戶的位置信息。理論分析證明,本文算法均滿足ε-差分隱私。仿真實驗證明,本文所提DPLPM 有較好的隱私保護程度和較高的數據可用性。
5 差分隱私證明和算法分析
5.1 差分隱私證明
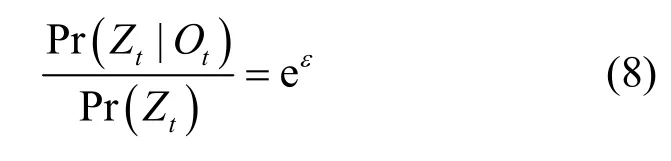
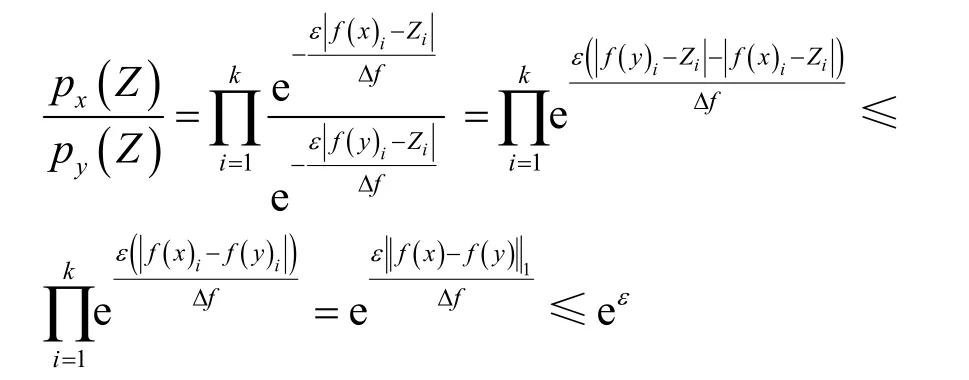
5.2 算法分析
6 實驗與分析
6.1 實驗設置
6.2 實驗結果與分析
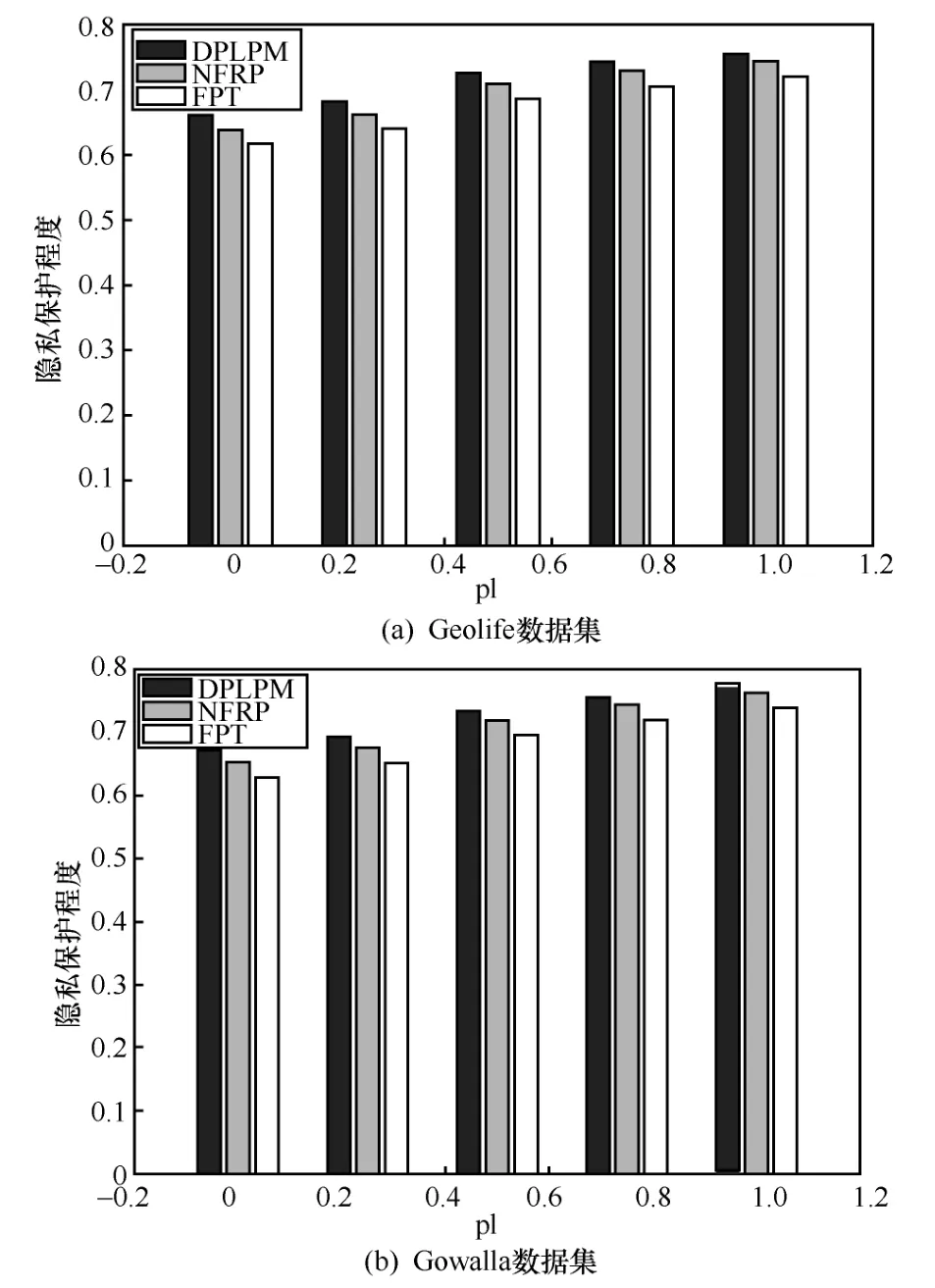

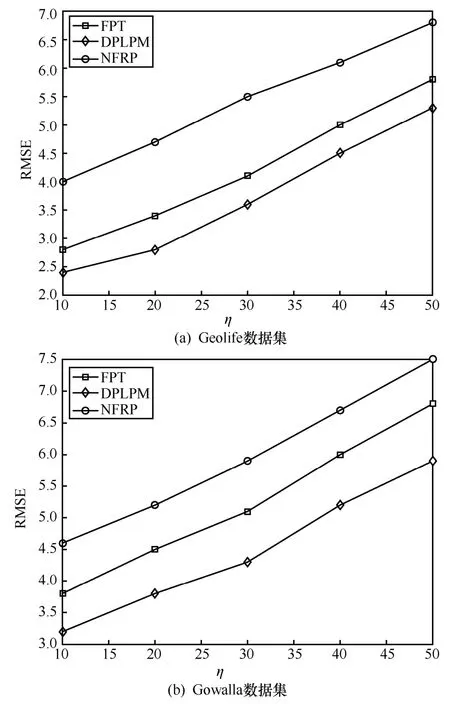
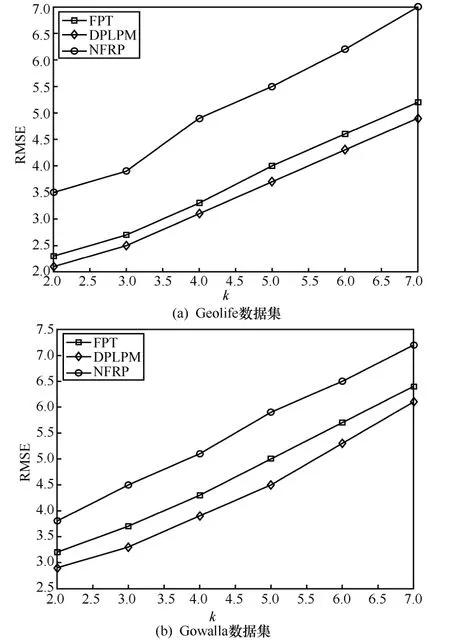
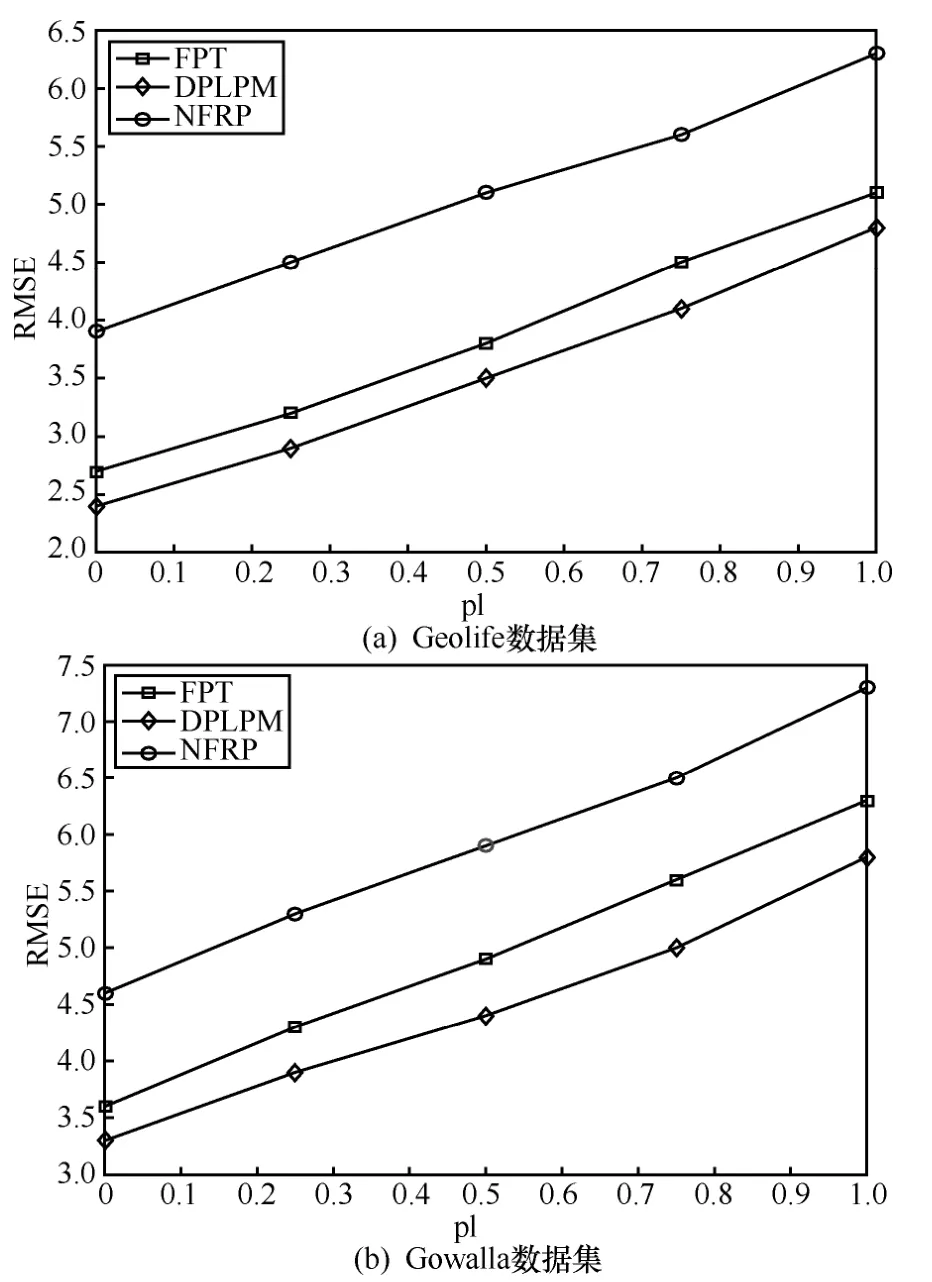
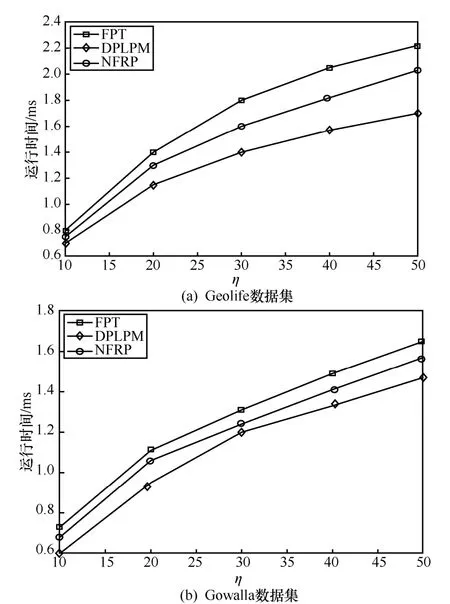
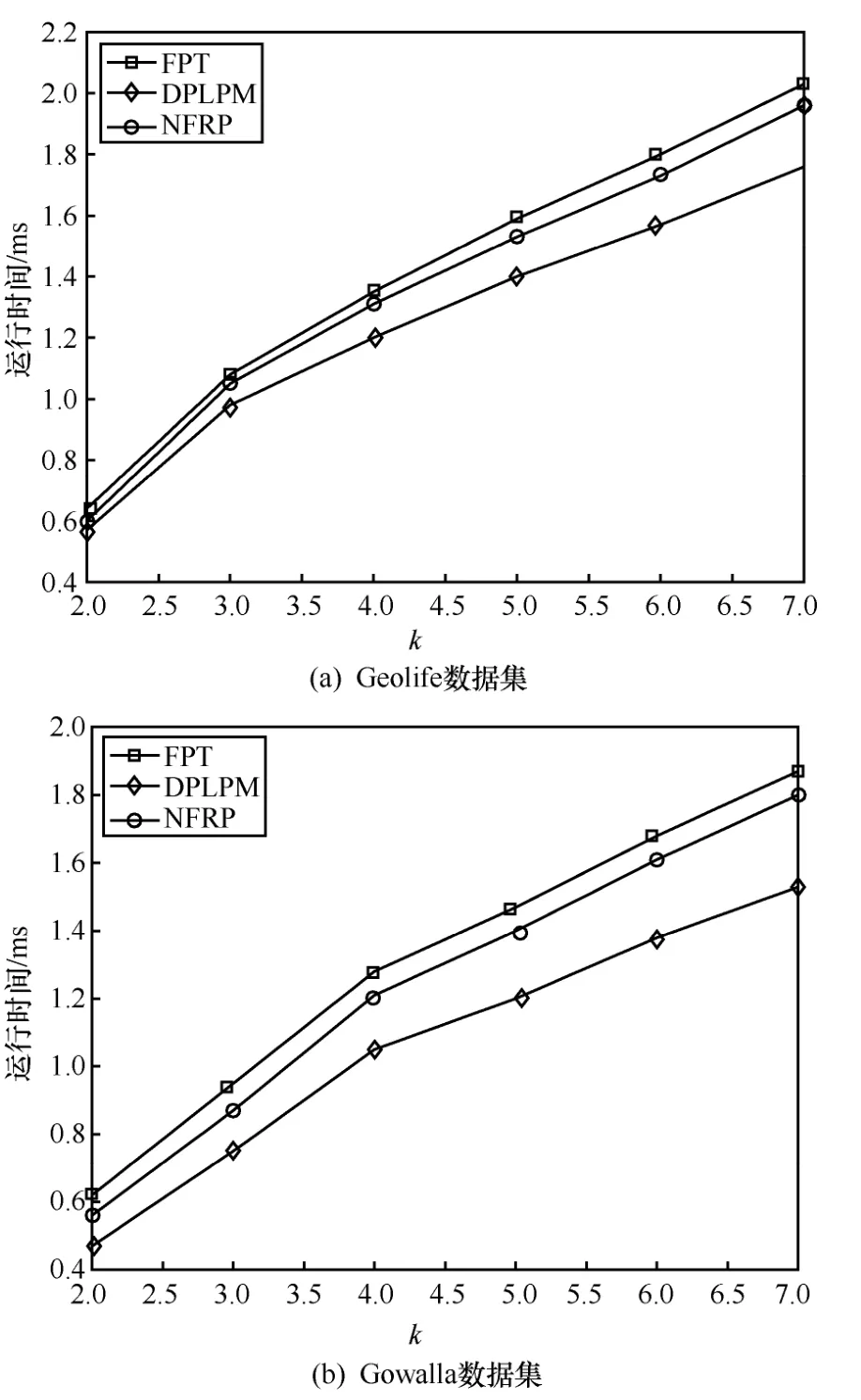
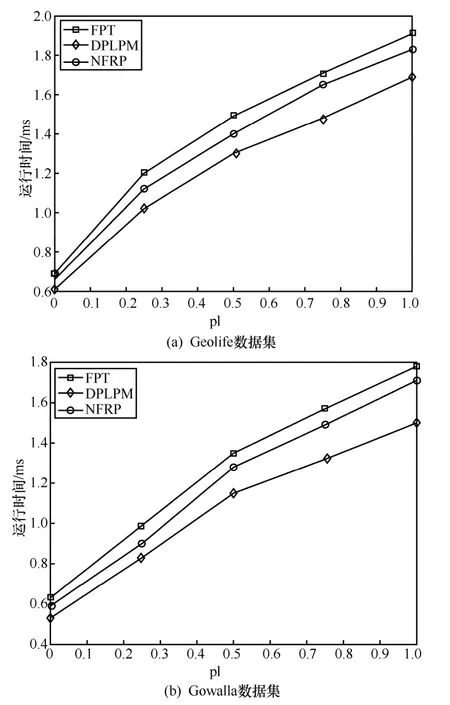
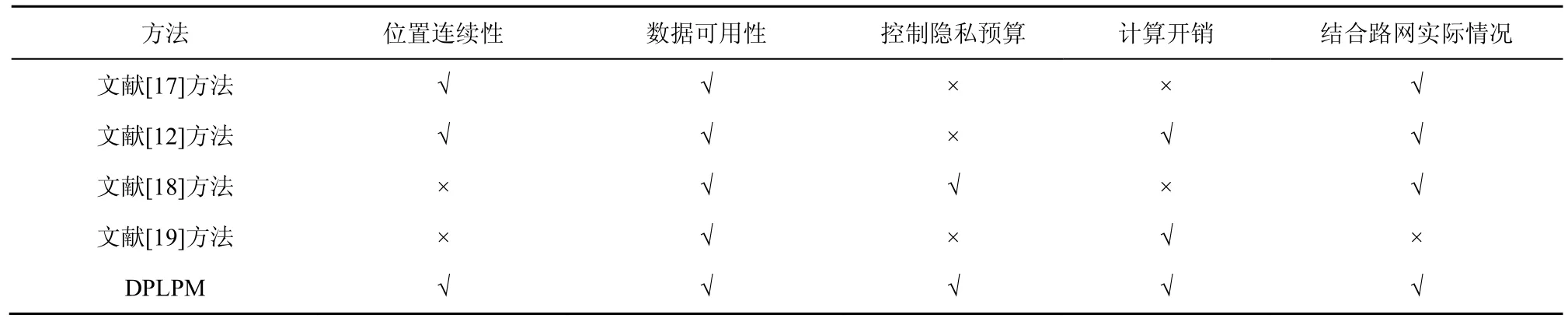
6.3 相關工作比較
7 結束語
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
