面向生物醫學檢測的拉曼光譜圖像機器學習算法研究
2021-09-03 09:38:30于鎧銘包曉棟李備洪喜劉景鑫
中國醫療設備 2021年8期
于鎧銘,包曉棟,李備,洪喜,劉景鑫
1.吉林大學中日聯誼醫院 a.手外科;b.醫學影像工程中心;c.放射科,吉林 長春 130033;2.長春長光辰英生物科學儀器有限公司,吉林 長春 130033;3.中國科學院 長春光學精密機械與物理研究所,吉林 長春 130033
引言
近年來,將拉曼光譜分析用于生物醫學檢測成為新的研究熱點,特別是新冠疫情出現后,由于核酸檢測對硬件和人員要求較高,一般醫院難以完成。因此,建立便捷快速的創新檢測方法對疫情防控具有重要意義,采用拉曼光譜進行快速生物醫學檢測成為國內外科學家探索的新方向。
拉曼光譜分析法基于拉曼散射效應,具有快速、無損、非接觸的優勢[1-3],已在有機化學、高分子材料、材料科學等研究領域應用多年[4-5]。但是由于拉曼光譜數據采集處理分析時間太長,因此在醫學檢測領域發展緩慢。近年來,隨著光學技術和計算機技術的發展,大大縮短了拉曼光譜的采集處理時間,使它應用于生物醫學檢測領域成為可能[6-8]。使用拉曼光譜檢測時,生物樣品用量很少,且無須前置處理,大大降低了操作難度,保護了樣本原始性,因而可以采集到生物樣品最真實的信息[9-11]。另外,拉曼光譜對于研究生物大分子的結構與性能,單細胞的核酸、蛋白質、脂質含量信息[12]以及細胞分子結構實時變化的信息等都具有顯著優勢[13-14]。
在使用拉曼光譜進行生物醫學檢測時,存在數據量大、數據維度高、光譜特征峰值多等問題。為此,需要通過計算機對數據進行降維和聚類分析處理,最終可以達到生物醫學檢測的效果[15-18]。
1 方法
由于生物檢測具有復雜的環境和多樣的生物,使用無監督學習在復雜乙肝血清環境中進行檢測和分析,基于t分布隨機近鄰嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)[19]非線性拉曼光譜數據壓縮,將高維拉曼光譜投影到低維平面,實現在低維空間的可視化聚類。
使用K最近鄰算法(K-Nearest Neighbor,KNN)[20],廣泛適用于增量模型下的模式識別領域。它是一種在線學習技術,新學習樣本可以直接加入訓練好的訓練集,而不需要重新進行學習訓練從而提高了模型訓練速度,且分類準確度高,對異常值的噪聲有較高的容忍度,對復雜血清樣品鑒別有著天生的優勢。
1.1 t-SNE聚類算法
SNE算法可以保持數據在進行降維處理前后各數據點間遠近關系的概率,從而可以保持降維前后的數據內部結構。SNE算法的基本思想:① 利用復雜度因子,選取近鄰樣本;② 用概率的形式將近鄰樣本間的歐氏距離轉化成樣本相似度;③ 利用相對熵目標函數算得降維后的數據表達。其中,xi和xj間的相似度由條件概率表達,即為xi選取xj作為近鄰的概率;其對應的嵌入子空間yi和yj間的相似度使用相似的表達。
應用中發現,原算法存在著低維度數據擁擠和價值方程優化困難的問題,因而在原SNE算法基礎上又提出了基于t分布的t-SNE算法。t-SNE算法較原算法的優點:① xi和xj間的相似度由聯合概率表達,聯合概率具有對稱性;② 嵌入子空間yi和yj間的相似度則用t分布表達。
設X={x1,x2,…,xn},其中xi為d維向量,聯合概率pij表示數據xi和xj之間的相似度,即原空間中xi選取xj作為鄰近的概率,即式(1):
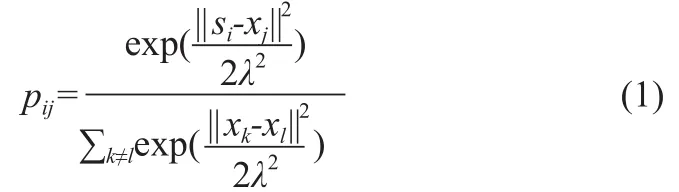
其中,λ是高斯函數的方差,pij=0數據間相似度概率總和為1。
取n個r維向量Y={y1,y2,…,yn}(r遠小于d),作為X對應的子空間數據,利用t分布qij表示子空間yi和yj間的相似度,即子空間數據間的概率,即式(2):
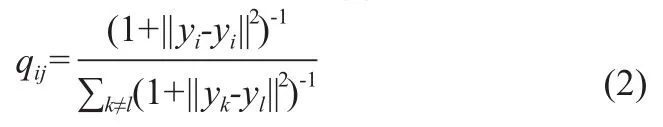
t-SNE通過最小化目標函數,即式(3):

獲取最佳子空間的向量表達,即最小化原空間和子空間兩個概率分布的相對熵,其本質就是最大限度地匹配pij和qij,再利用梯度下降法計算式(3)最優值。
求解時,最優化過程中存在振蕩現象,為了改善這個問題,并加快最優化過程,在式(3)上添加一個動量項,從而有了帶動量的梯度,見式(4):
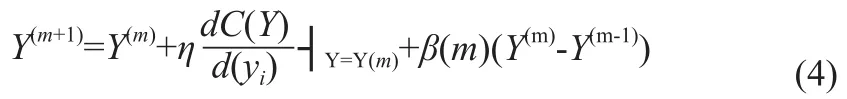
1.2 KNN分類算法
在N個訓練樣本中,找到測試樣本x的k個近鄰。設數據集中有m個訓練樣本,并有c個類別,即{ω1,…,ωc},測試樣本為x。則KNN算法可描述為:在m個訓練樣本中找到x的k個鄰域,其中x的k個近鄰中屬于類別wi的樣本數戶分別為k1,k2,…,kn則判別函數見式(5):

決策規則為式(6):

則決策x∈ωj。
KNN的思想是給出一個樣本集合和一個合適的距離度量方式,對任意的一個測試樣本,找到離它最近的k個樣本,根據這k個樣本的類別統計信息決定此測試樣本的類別歸屬問題,即將待分樣本x歸類為與其k個近鄰中出現次數最多的類別。KNN算法的基本要素為:k值,距離度量方式和分類的決策規則。
KNN分類步驟:① 準備訓練樣本集X,其中包含n個訓練樣本,根據具體要求選擇一個合適的距離度量方式,用dis(xa,xb)表示樣本集中的xa、xb這兩點的距離;② 對于測試樣本x,利用距離度量公式計算測試樣本x與n個樣本的距離,得到距離集合Dis,其中Dis={dis(x,x1),dis(x,x1),…,dis(x,xn),};③ 對距離集合進行排序,從中選擇最小的k個元素,從而得到k個元素對應的k個樣本;④ 對這k個樣本所屬類別進行統計,用投票的方式得到最終分類結果。
2 結果
為驗證本研究中提出的拉曼光譜數據處理方法,我們使用乙肝感染血清及正常人血清進行了實驗驗證。驗證實驗使用了2位乙肝患者血清和2位正常人血清。每個樣品取中心位置,各測試50組拉曼數據。樣品前置處理使用離心取全血的血清(其中每組各有一份樣品有輕微溶血現象,血清偏紅色,有血紅素干擾);將血清用棉簽點樣于檢測芯片上,風干后待測。在對血清進行拉曼光譜檢測后,首先對數據進行預處理,進行宇宙射線、平滑、基線校正處理,再以最高峰為標準對所有光譜進行歸一化,生成光譜圖。
2.1 拉曼光譜測試結果
經檢測,分別得到2位正常人血清拉曼光譜測試區域及光譜圖(圖1和圖2)和2位乙肝患者血清(圖3和圖4)。
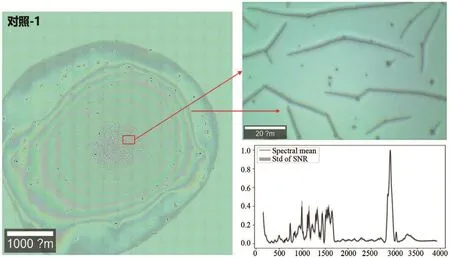
圖1 對照-1實驗拉曼光譜測試區域及光譜圖
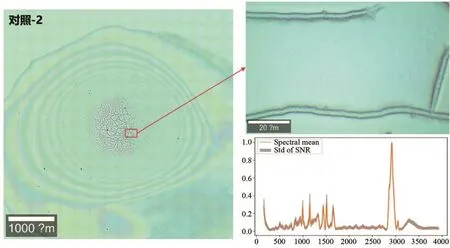
圖2 對照-2實驗拉曼光譜測試區域及光譜圖
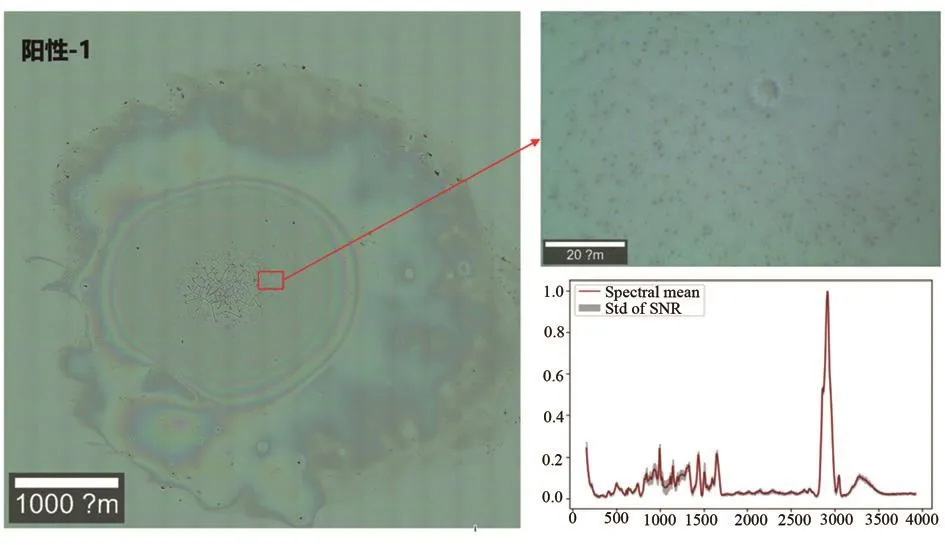
圖3 陽性-1實驗拉曼光譜測試區域及光譜圖
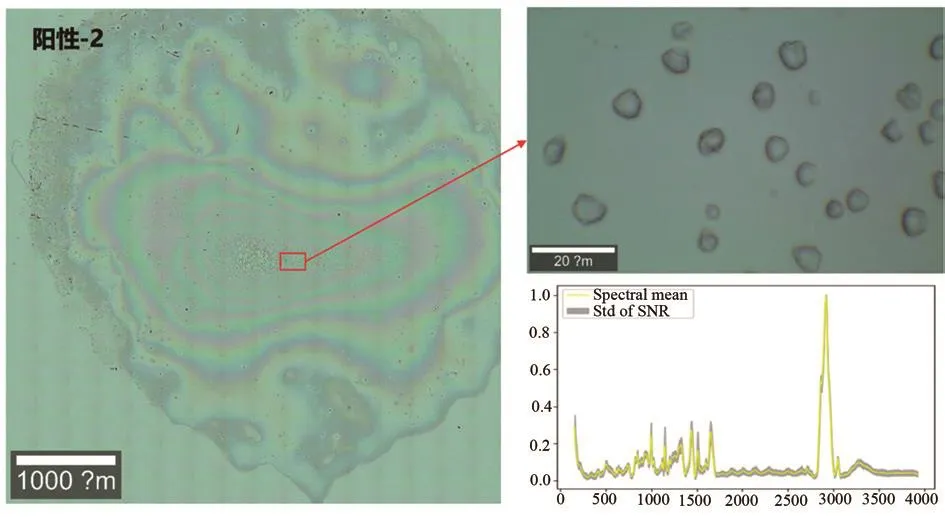
圖4 陽性-2實驗拉曼光譜測試區域及光譜圖
2.2 聚類算法分析結果
經過t-SNE算法處理后,直接可以得到聚類分析結果圖(圖5)。從圖5中可以看出,陽性組數據與對照組存在明顯差異,但對照組數據的類內聚合度較低,組內差異比較大。
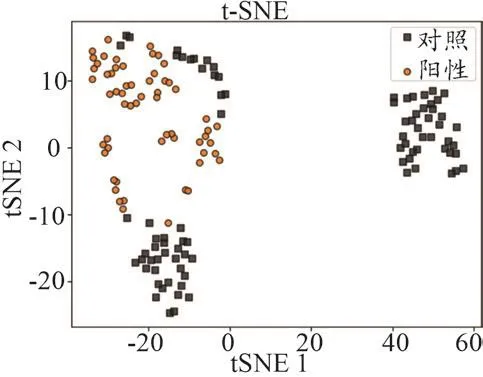
圖5 聚類分析結果圖
2.3 分類算法分析結果
使用KNN分類算法,實驗數據進行分類分析,得到分類分析結果圖(圖6)。從圖6中可以看出,基于目前的數據,可以根據拉曼光譜對陽性組與對照組進行區分,驗證了拉曼光譜進行生物醫學檢測可行性及相關算法分析處理檢測數據的可行性。
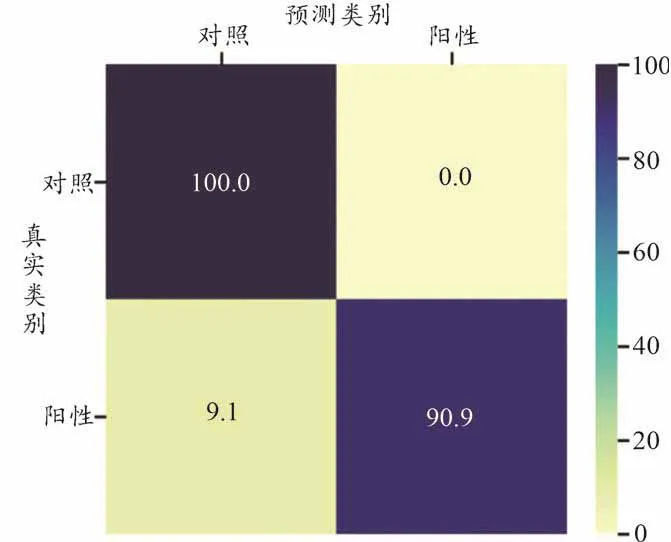
圖6 分類分析結果
3 討論
我們利用機器學習的方法,對拉曼光譜進行生物醫學檢測的數據進行處理分析,從乙肝感染血清驗證實驗的結果來看:陽性組與對照組的拉曼光譜圖像存在差異,可以進行區分;從驗證實驗的數據分析來看:對每個樣品的數據進行分析,陽性組的2個樣品數據的類內聚合度較高,而對照組的2組數據差異較大。由此可見,生物的拉曼光譜圖像數據是可以表征生物特性的,t-SNE聚類算法、KNN分類算法等機器學習算法在對生物醫學拉曼光譜數據處理方面也是可行的,特別在同類組別的區分上顯示出了算法的有效性。
然而,同組內個體間的差異也較為明顯,數據結果受樣本自身反應變化影響較多,對于此問題,后續工作將從兩個方面展開:① 優化樣本的采集、制作和保存,保證樣本的完整性和統一性;② 項目正式開展后采集更多的樣本數據,探究個體差異原因,并根據差異的特點開發相應算法,提高檢測準確率。
目前,我們對于拉曼光譜用于生物醫學檢測的數據處理分析方法研究取得了初步的結果。同時,我們也在嘗試把深度學習方法應用到拉曼光譜檢測數據的處理中,以求可以更加準確高效地完成生物醫療檢測,獲得更高的檢測結果。后續我們還需要從算法優化、樣品制備、檢測流程標準化等角度加以優化和完善,通過大量細菌、病毒微生物檢測實驗分析以提升拉曼光譜在生物醫學檢測領域的檢測范圍與檢測精度。
將拉曼光譜分析應用到生物醫學檢測中,可以形成檢測細胞、細菌甚至病毒微生物的一種新型快速便捷的檢測技術,拉曼光譜也將有希望成為快速檢測新型冠狀病毒的新方法。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年3期)2021-08-22 06:50:04
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
天津醫科大學學報(2021年2期)2021-03-29 05:31:08
現代臨床醫學(2021年1期)2021-01-26 00:56:02
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
