
面向眾核處理器的水動力學CFD并行計算探索
2021-09-07 17:31:46張亞英吳乘勝王建春劉宏斌
船舶 2021年4期
關鍵詞:效果
張亞英 吳乘勝 王建春 劉宏斌
(1. 中國船舶科學研究中心 無錫 214082;2. 國家超級計算無錫中心 無錫 214072)
引 言
高性能計算已深入諸多科學與工程應用領域的數值模擬中,成為科技創新和提升核心競爭力的重要手段和支撐。具體到船舶水動力學領域,隨著CFD計算量成幾何量級增長,對計算能力的要求越來越高,在超級計算機上開展大規模計算漸趨普遍。
近年來,超級計算機架構正在發生由同構向異構發展的變革。由于“主頻墻”的限制,單核處理器計算性能趨于極限;由于“通信墻”的限制,基于分布式的并行計算無法在大規模并行中獲得優秀的加速效果;由于“功耗墻”的限制,通過大規模擴展通用處理器(CPU)提升計算能力也不太現實。因此,異構眾核逐漸成為超級計算機架構的發展趨勢。以2020年6月22日發布的超級計算機TOP500榜單為例,其中144臺都采用加速器或協處理器,也就是采用異構眾核架構;在榜單前10名中,8臺采用異構眾核架構;而近十年來登頂的超級計算機,全部采用異構眾核架構。
異構是相對于同構而言,因此先簡單介紹一下同構架構。同構架構中所有的計算核心都是由CPU構成,所有計算核心的邏輯處理能力和數據計算能力都很強,不受計算任務復雜度的影響;但其缺點是成本高、功耗大。異構與同構相比,計算核心的種類不同,一般既有CPU,也有協處理器。異構系統可以進行深層次并行,使計算任務劃分更加細化,并行程度更高。典型的異構眾核處理器架構包括CPU+GPU架構、CPU+MIC架構等,“神威·太湖之光”超級計算機的國產申威架構SW26010處理器,也屬于異構眾核架構。
異構眾核架構使得超級計算機的計算能力大幅度提升,但對CFD高性能計算也是挑戰。因為要實現對計算資源的充分利用,需要從數值算法、數據結構、計算流程等各個層面進行重構和優化。NASA的《CFD Vision 2030 Study》報告也將其列為重大技術挑戰。
國內外不少研究人員針對CPU+GPU架構、CPU+MIC架構,開展了CFD眾核并行計算研究;也有少量基于開源軟件針對國產申威架構的CFD眾核并行計算研究。總體看來,目前CFD界遠未實現對異構眾核超算能力的有效利用,有以下原因:
(1)目前常用CFD軟件的并行計算,大多數是針對MPI并行設計的,一般不適合在異構眾核平臺上運行。
(2)CFD計算通常具有全局相關性特點,并行規模的增大帶來了并行復雜度與通訊開銷的增加,導致并行效率下降;同時水動力學CFD常用的SIMPLE算法的流程相對復雜,增加了細粒度并行優化的難度,異構加速面臨巨大挑戰。
(3)CFD軟件一般具有數據結構復雜、計算流程復雜和代碼量龐大等特點,從程序移植到優化,都需要大量的重構工作,難度和工作量相當大。
本文面向異構眾核處理器,開展水動力學CFD并行計算探索研究,為自主CFD求解器與國產超級計算機硬件的有效結合進行關鍵技術攻關。針對國產申威26010異構眾核處理器,對水動力學CFD中典型的SIMPLE算法和人工壓縮算法,從數據存儲、數據分配和數據結構等多個方面入手,設計眾核并行計算方法,通過典型算例測試和驗證眾核加速效果,并針對SIMPLE算法計算熱點分散的特點,采用循環融合的方法對其計算流程進行優化,使SIMPLE算法和人工壓縮算法分別獲得11倍和24倍的最高加速。該項研究工作,初步展現眾核處理器在水動力學CFD并行計算中的應用潛力,并將為自主CFD求解器與國產超級計算機硬件的有效結合提供技術儲備。
1 水動力學CFD計算方法
水動力學CFD計算處理的通常為不可壓縮粘性流動,其無量綱化積分形式控制方程組如下:
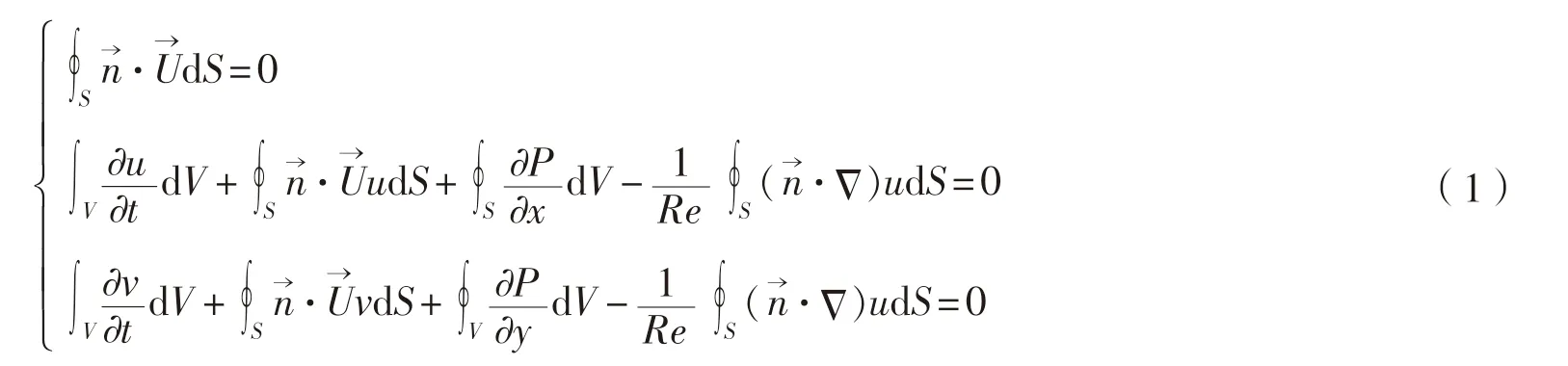
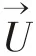
本文采用基于交錯網格的有限體積法離散控制方程。論文在求解控制方程組時,使用了兩種數值算法——SIMPLE算法和人工壓縮算法,兩種算法的求解流程參見圖1。
圖1 SIMPLE和人工壓縮算法計算流程
2 CFD模擬并行計算方案
2.1 國產申威眾核處理器簡介
“神威·太湖之光”超級計算機系統,采用的是國產申威架構SW26010處理器。處理器本身就包括控制核心和計算核心陣列,相當于把CPU和加速處理器集成到一個芯片上,其內部架構見下頁圖2。
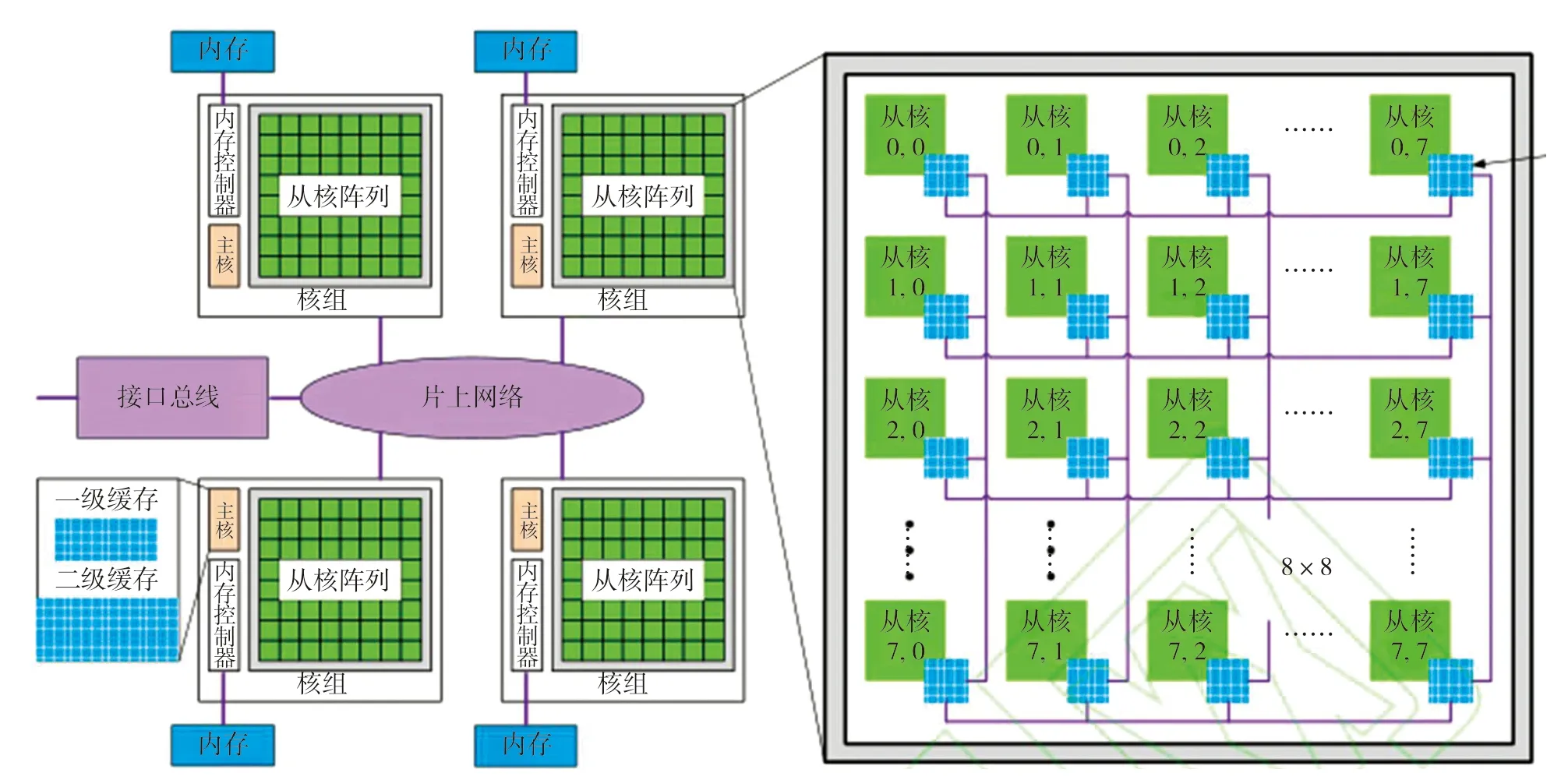
圖2 SW26010處理器架構示意圖
SW26010處理器包含4個核組(CG),各核組之間采用片上網絡(NOC)互聯,每個核組內包含1個主控制核心(主核,MPE)、1個從核(CPE)集群(由64個從核組成)、1個協議處理單元(PPU)和1個內存控制器(MC)。核組內采用共享存儲架構,內存與主/從核之間可通過MC傳輸數據。
與其他異構眾核架構一樣,SW26010處理器的計算能力主要體現在從核上;但相比于GPU和MIC,從核上的存儲空間和帶寬較小,往往使數據傳輸成為程序運行的瓶頸。
2.2 主要并行工具與函數
Athread與OpenACC*均可用來進行從核并行,與OpenACC*相比,Athread的操作性更高,可以通過調用相關實現數據傳輸和從核運算的自主可控,加速部分不再只限于循環計算,能夠更加方便對并行方案進行設計。
完整的從核加速過程通常包含以下函數,如表1所示。
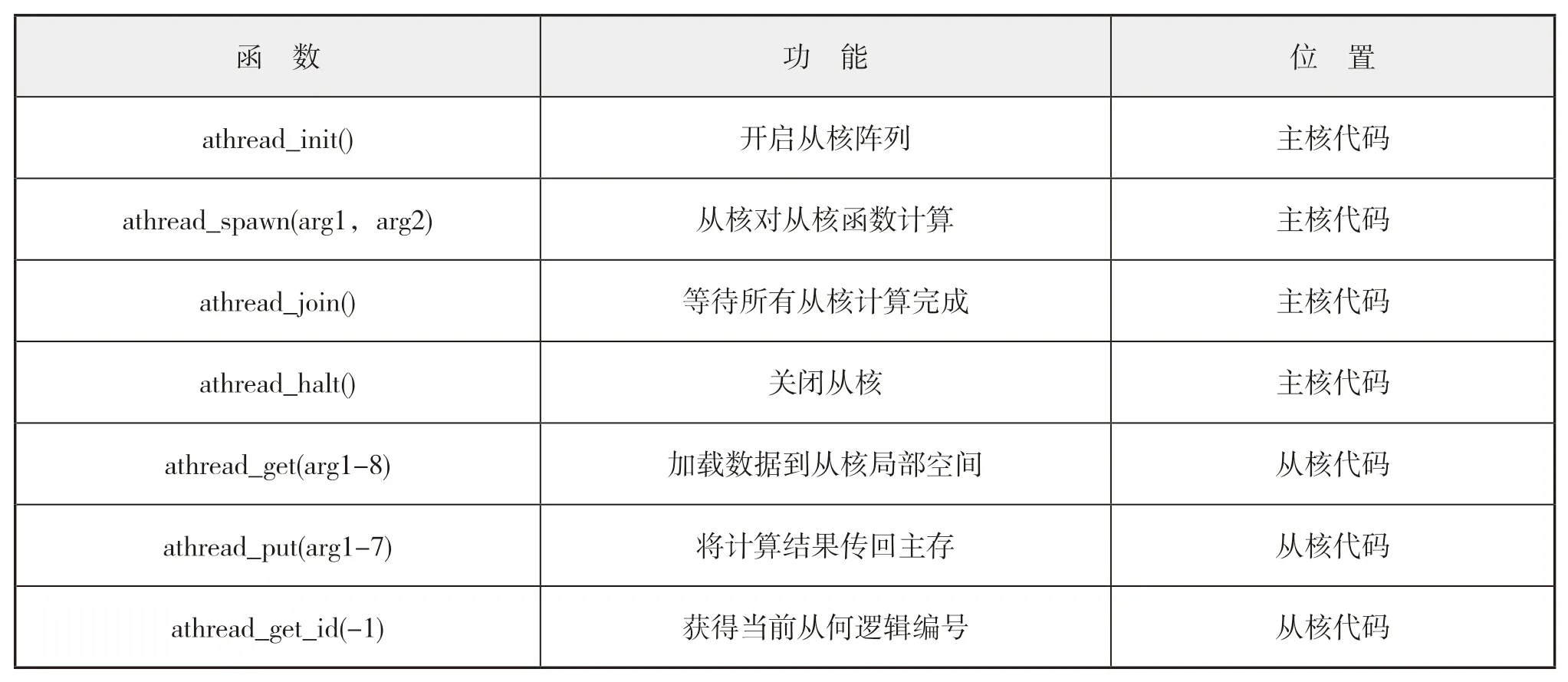
表1 Athread常用行數
2.3 眾核并行計算方案設計
2.3.1 數據存儲模式
由于本文采用交錯網格,速度u
、v
和壓力p
3個主要變量存儲在3套網格上,數據量和計算索引均不統一,將會使尋址過程變得更加復雜。為此,本文中采用一種特殊的數據存儲模式(如圖3所示):將速度u
、v
相對壓力p
多出的數據單獨存儲,此時,u
、v
、p
共同存儲在主控制體上,且擁有相同的索引,從而簡化尋址過程、提高尋址效率。
圖3 交錯網格下變量分布和存儲方式
2.3.2 數據分配
本文采用循環并行,由于從核局部空間大小有限(64 KB),因此合理分配數據才能充分利用從核局部空間和計算資源。數據分配方案設計為:設定單個從核單次計算的數據量NS,則64個從核一次能夠計算64×NS
個數據,當數據量很大時,可以將數據分批多次加載到從核上進行計算。此時,可以根據當前的加載次數k
、當前次加載的數據量N
以及從核ID號,確定當前從核(線程)所計算數據的起始位置,并從主存獲取數據。同時,為了考察通信的影響,論文對單獨一個循環進行測試,測試對象為人工壓縮算法中內部單元壓強的計算過程,結果見圖4。從圖4可見,當NS
增大時,加速比逐漸上升并趨于定值(左圖)。其原因為:隨著NS
值的增加,通信占比逐漸降低并趨于定值(右圖),從而使計算過程的加速效果愈發突顯。
圖4 不同NS值下加速比、通信占比和計算占比變化曲線
2.3.3 數據結構
根據數據分配方案,NS代表從核計算的數據量,而從核局部空間的大小使單個從核存儲的數據量有限;同時,由于CFD計算過程復雜,將數據以結構體形式合理存儲,可使數據的傳輸和使用更為方便。但是,將多個變量集中在一個數據結構中,必然會造成在當前計算中部分變量未使用的情況,這樣既增加通信負擔,又占據存儲空間。因此,合理的數據結構非常重要。
由于CFD程序中有多個計算熱點需要并行化,因此對數據結構進行針對性的設計比較困難,本文將重點放在盡量減少無用數據的存儲和傳輸上。在CFD程序中,將系數變量組成單個結構體,將u
、v
、p
以主控制單元的形式組成結構體,并在此基礎上設計了如圖5所示的數組結構體和結構體數組兩種形式,用于對比兩者并行加速效果。
圖5 兩種數據結構
3 典型流動眾核并行計算結果與分析
3.1 并行計算結果
本文以二維方腔驅動流CFD模擬為算例,研究眾核并行的加速效果。
方腔驅動流,是指方腔中的不可壓縮流體隨頂蓋勻速運動過程中的流動及流場結構變化等現象,具有幾何外形簡單、流動結構特征顯著、邊界條件容易實施等特點,常被用作不可壓縮流動模擬結果驗證和數值算法測試的典型算例。數值模擬中,邊界條件都可采用速度邊界:其中上邊界(頂蓋)有水平方向速度,其他邊界滿足無滑移條件。
使用SIMPLE和人工壓縮算法,分別采用數組結構體和結構體數組兩種數據結構,開展不同網格單元數(100×100 ~1 000×1 000)情況下、Re
= 1 000工況方腔驅動流的CFD模擬。圖6給出了方腔水平中線與垂直中線上的無量綱速度分布數值計算結果,下頁表2則給出主渦和次渦相對位置的數值模擬結果;圖表中同時給出文獻[10]中Ghia的計算結果。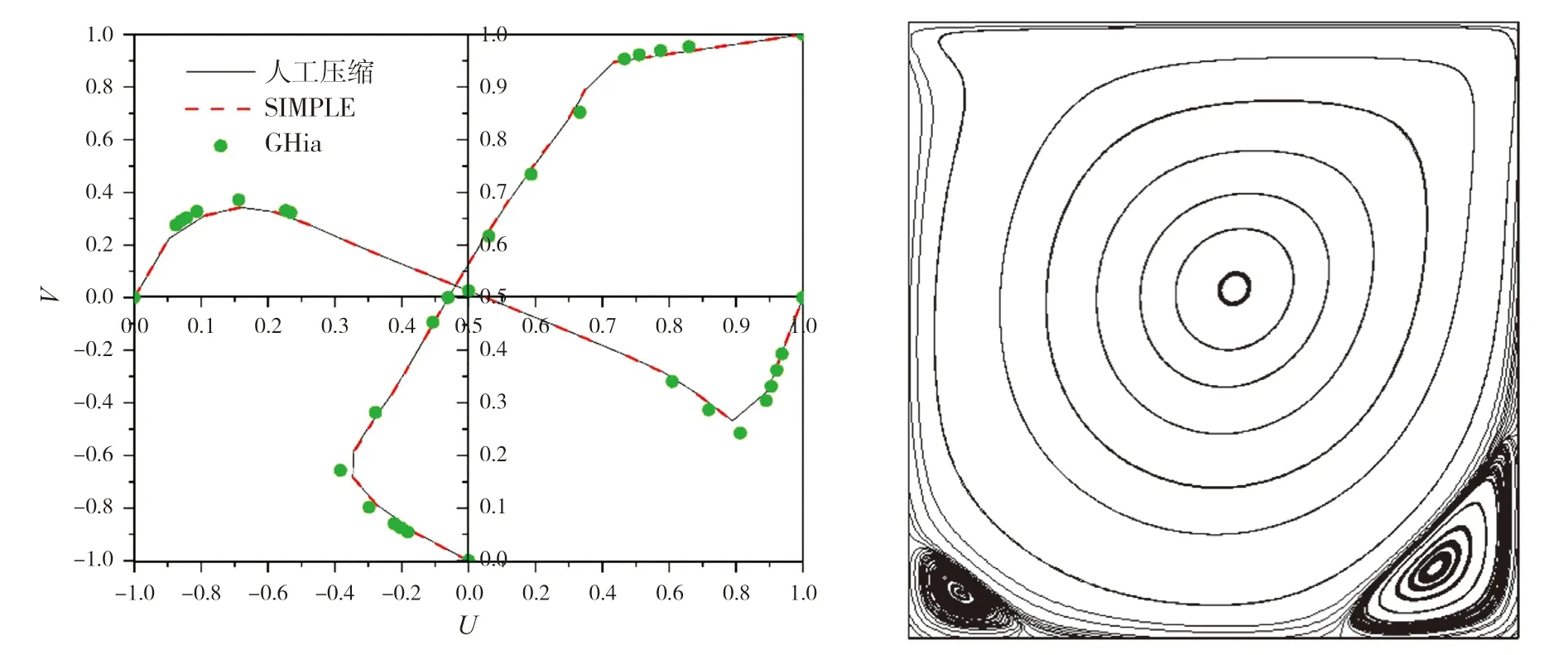
圖6 方腔水平和垂直中線上速度分布(左)及方腔內部流線分布(右),Re=1 000
本文在并行計算過程中,并未改變迭代方法等計算過程,因此,不同的數據結構和算法應有基本一致的計算結果。根據圖6以及表2可以看出:無論是速度分布或主渦與次渦的渦心坐標,均與參考文獻的結果十分接近,這也說明并行計算結果的正確性。
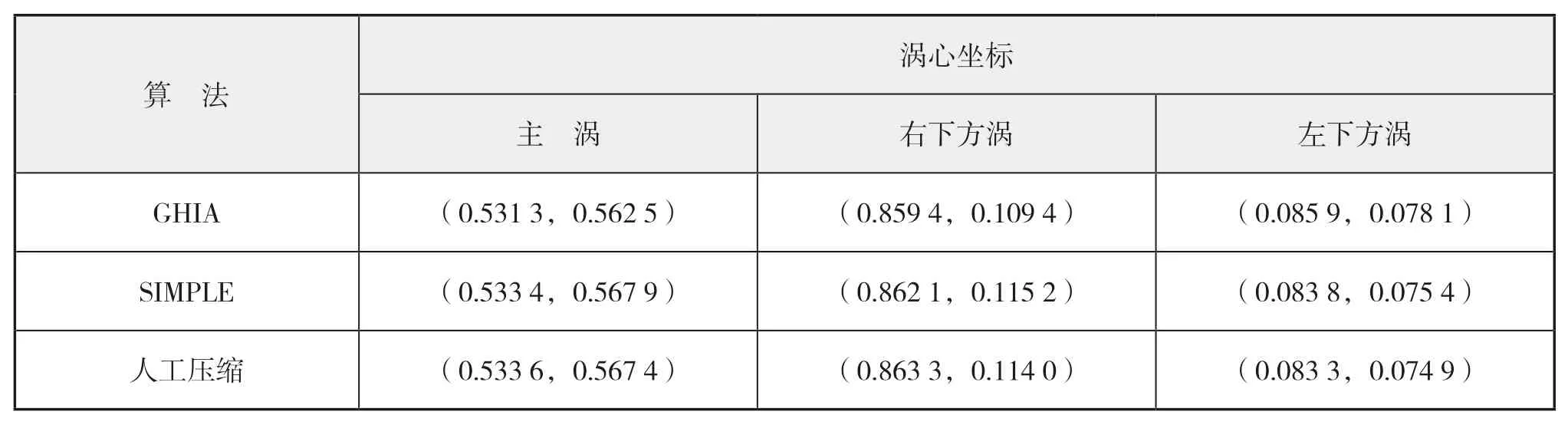
表2 渦心位置計算結果
圖7給出不同網格單元數情況下,眾核并行的加速情況。從圖中可以看出:
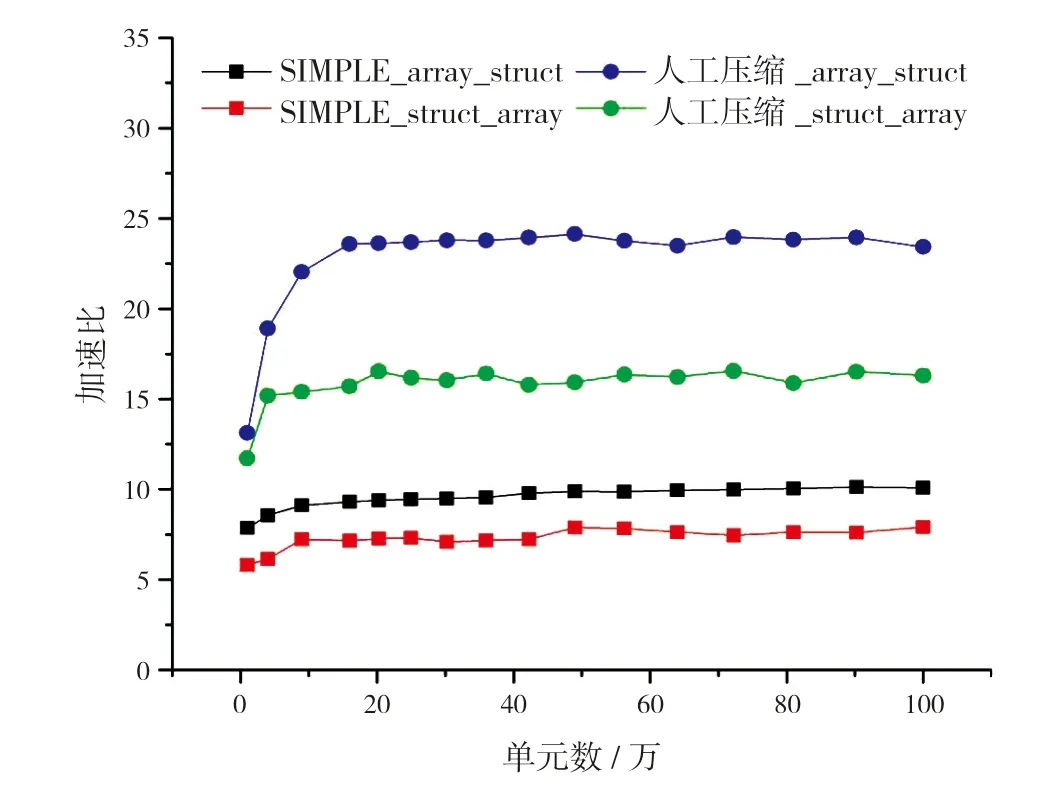
圖7 眾核并行加速曲線
(1)隨著網格單元數增加,加速比逐漸上升并趨于平穩;
(2)從兩種算法的對比來看,人工壓縮算法的加速效果(最高約24倍)優于SIMPLE算法(最高約9倍);
(3)從兩種數據結構的對比來看,采用數組結構體并行加速效果優于采用結構體數組。
3.2 對SIMPLE算法計算流程的優化
根據上一節的研究可以發現,在采用相同數據結構的情況下,SIMPLE算法的并行加速效果明顯不如人工壓縮算法。其原因是SIMPLE算法的計算流程更為復雜(見圖1),從而導致計算熱點分布較為分散。表3給出了SIMPLE算法和人工壓縮算法的計算熱點分析結果。
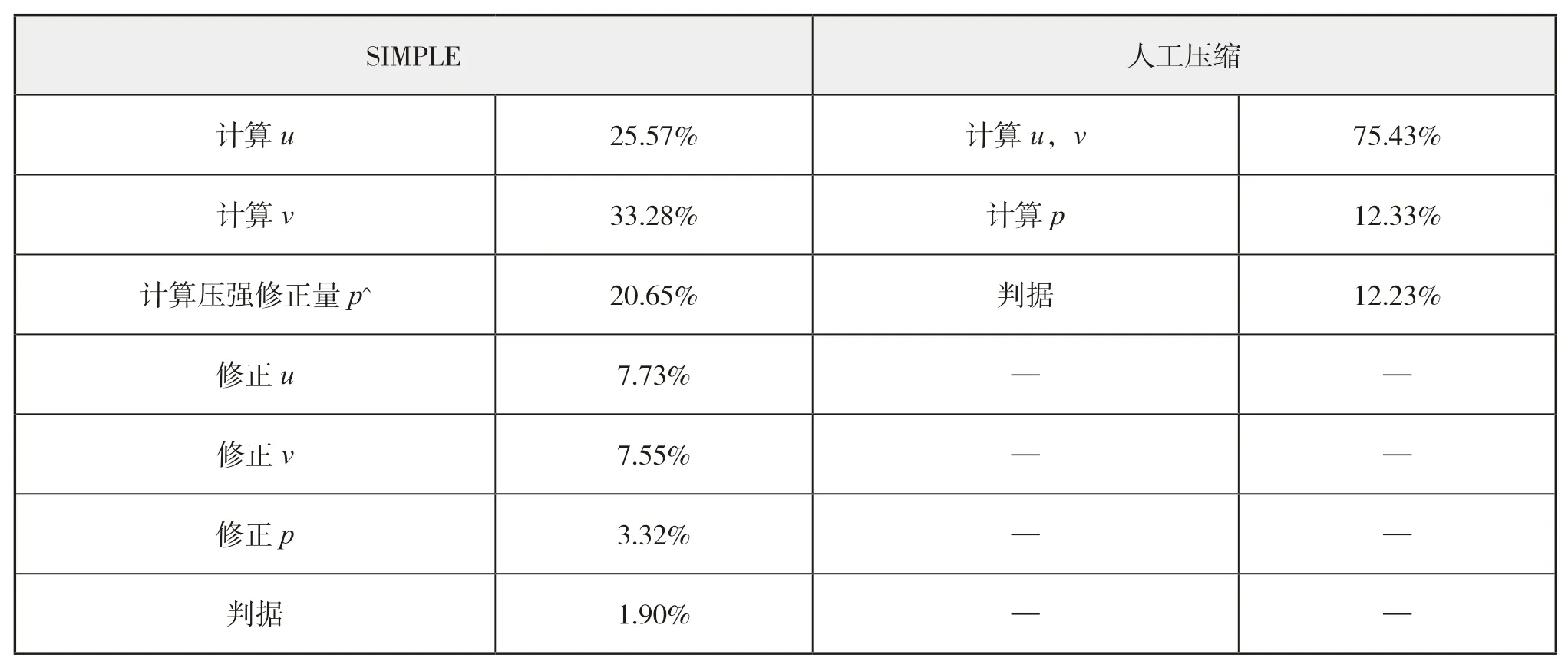
表3 SIMPLE算法和人工壓縮算法計算熱點分析
結合2.3節(圖4)通信占比與計算占比之間的關系,SIMPLE算法分散的熱點會導致在眾多的簡單循環計算中,因數據量有限,當計算中需多個變量時,必然造成通信的增加,導致通信相對計算有較大的占比,使局部加速效果偏低,進而導致整個CFD計算程序的并行加速效果不理想。
為此,本文對SIMPLE算法的計算流程進行優化,將SIMPLE算法中非相關的數據計算過程進行集中處理,即在一個大循環中通過判斷語句進行不同的計算。這樣,在從核計算中,提高了數據的復用性,減少常用變量的重復傳輸。流程優化前后的計算熱點對比見表4。
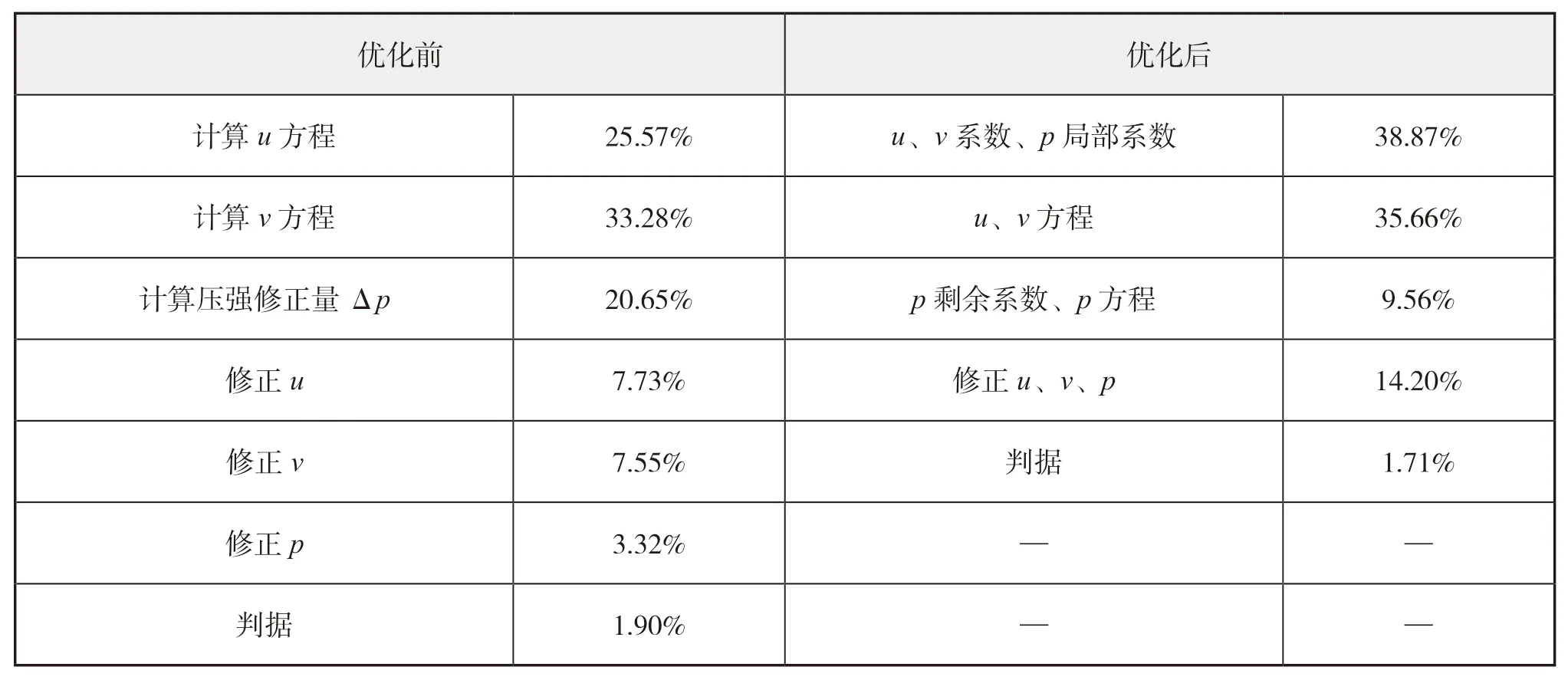
表4 SIMPLE算法計算流程優化前后計算熱點分布
由表4可見,優化后的SIMPLE算法流程,減少了計算步驟,使計算熱點分布更加集中,其中u
、v
系數、p
局部系數(由u
,v
,p
計算的部分)計算與u
、v
方程求解兩部分總和占比超過74%。圖8給出了SIMPLE算法計算流程優化前后的眾核并行加速曲線。從圖中可見,優化算法流程使加速效果略有提升,說明計算熱點分布的集中程度會影響眾核加速效果,且熱點越集中加速效果越好。
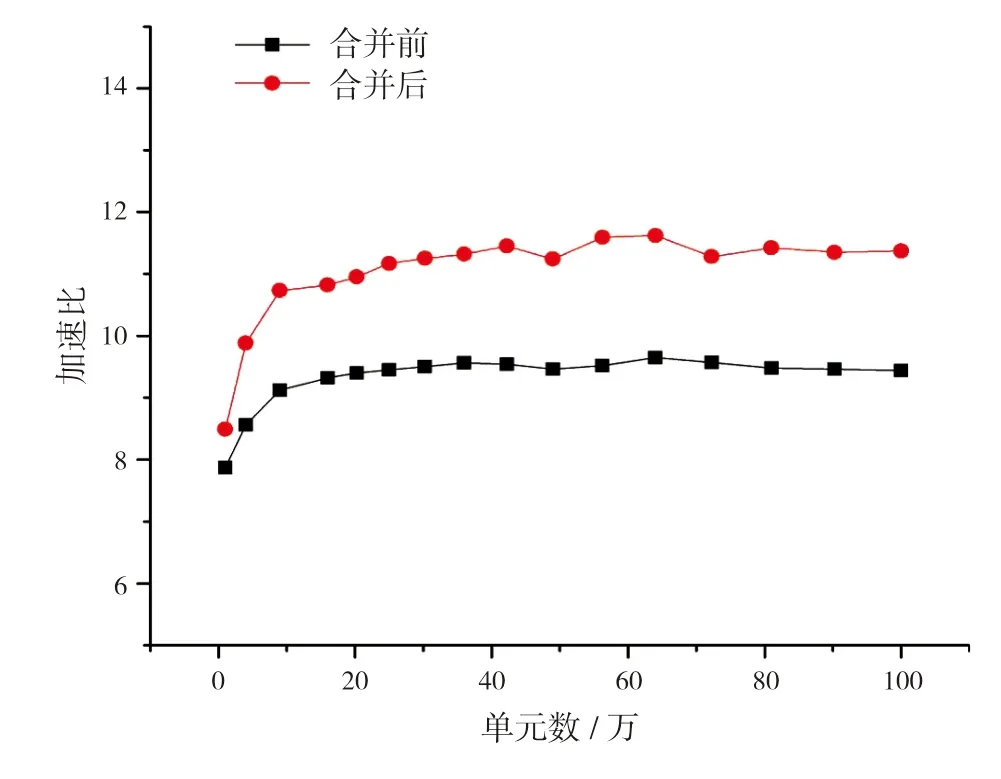
圖8 SIMPLE算法計算流程優化前后并行加速比
同時,對比圖7和圖8可見,即使經過計算流程優化,SIMPLE算法的眾核并行加速效果也遠未達到人工壓縮算法的并行加速效果,經分析主要原因如下:
(1)SIMPLE算法涉及方程的迭代求解,迭代過程自身就包含數據更新、計算新值和判斷收斂三部分,而數據更新和判斷收斂在單個迭代步內占比較小,但是由于內迭代和外迭代的重復進行,也會影響最終的加速效果。
(2)算法本身計算過程中讀取數據對于高速緩存的利用等。
4 結 語
本文面向異構眾核處理器,開展不可壓縮流動的CFD并行計算探索研究。針對國產申威26010處理器的特點,對SIMPLE算法和人工壓縮算法設計了眾核并行計算方案,并通過二維方腔驅動流算例測試和驗證了眾核加速效果:人工壓縮算法最高加速約24倍,SIMPLE算法最高加速約11倍。論文的研究工作,初步展現了眾核處理器在不可壓縮流動CFD計算中的應用潛力。
論文的研究工作目前還是探索性的:一方面,僅探討了單個核組使用從核陣列的加速效果,并且諸如寄存器通信、雙緩沖等優化方法暫未使用,因此加速效果還有一定的提升空間;另一方面,論文中開發、使用的CFD程序較為簡單,而面向工程應用的大型CFD軟件在數據結構、計算流程等方面復雜得多,在神威平臺上進行眾核加速,則需要在各方面進行更多的探索和研究。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
好日子(2021年8期)2021-11-04 09:02:46
小學生學習指導(爆笑校園)(2020年6期)2020-07-03 10:01:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
攝影之友(影像視覺)(2018年12期)2019-01-28 09:01:02
中華詩詞(2018年11期)2018-03-26 06:41:34
小學生學習指導(低年級)(2017年11期)2017-10-23 01:32:36
Coco薇(2016年8期)2016-10-09 02:11:50
中國醫藥科學(2015年19期)2015-02-27 12:33:11
