基于時(shí)間特征的可疑資金交易識(shí)別研究
2021-09-09 07:36:28丁曉
現(xiàn)代計(jì)算機(jī) 2021年19期
關(guān)鍵詞:資金
丁曉
(中南財(cái)經(jīng)政法大學(xué)信息與安全工程學(xué)院,武漢 430073)
0 引言
隨著經(jīng)濟(jì)發(fā)展,洗錢犯罪活動(dòng)也呈現(xiàn)擴(kuò)大趨勢,如果不進(jìn)行打擊,將會(huì)對國家和社會(huì)造成嚴(yán)重危害。金融機(jī)構(gòu)、特定非金融機(jī)構(gòu)及相關(guān)監(jiān)管部門都有發(fā)現(xiàn)、打擊這類行為的迫切需求。但是相關(guān)數(shù)據(jù)具有體量大的特征,手工方法已經(jīng)無法甄別,需要用計(jì)算機(jī)技術(shù)進(jìn)行分析。
洗錢活動(dòng)中,部分犯罪分子的資金轉(zhuǎn)移手法有一定規(guī)律性。交易時(shí)間作為資金交易數(shù)據(jù)中的一個(gè)基本特征,能反映該涉案人員的交易習(xí)慣、交易周期等。本文研究以資金交易的時(shí)間特征為研究對象,以聚類分析為輔助手段,進(jìn)行可疑資金交易模式識(shí)別研究,并以“靶心模式”這種行為模式的識(shí)別為例,設(shè)計(jì)了詳細(xì)識(shí)別算法。這個(gè)算法是無監(jiān)督學(xué)習(xí)算法,不需要先驗(yàn)數(shù)據(jù),簡化了算法的應(yīng)用。這個(gè)算法也是辦案人員經(jīng)驗(yàn)、知識(shí)的固化,保證了算法的正確性,而且算法在實(shí)際案件偵查中取得了好的成績。
1 相關(guān)研究
在反洗錢領(lǐng)域,分析算法大體可以分為五大類:
(1)洗錢類型分析,是基于已經(jīng)發(fā)現(xiàn)的案例進(jìn)行檢測。Bhattacharyya等人使用支持向量機(jī)進(jìn)行信用卡欺詐檢測[1];Luo X使用頻繁項(xiàng)模式算法檢測賬戶之間的可疑交易[2];Paula E等使用了深度學(xué)習(xí)方法[3]。
(2)鏈接關(guān)系分析,找出賬戶間的實(shí)質(zhì)關(guān)系。Dreewski等人使用社交網(wǎng)絡(luò)分析法進(jìn)行賬號(hào)間關(guān)系分析,每個(gè)賬戶作為圖的一個(gè)頂點(diǎn),具備介數(shù)中心度、接近中心度、權(quán)威度等屬性,還借助社交網(wǎng)絡(luò)技術(shù),試圖分析各個(gè)賬戶在洗錢犯罪中的角色[4];Colladon AF等人試圖從網(wǎng)絡(luò)中發(fā)現(xiàn)可疑交易[5]。Jin Y等人使用分層模型根據(jù)資金流動(dòng)的方向?qū)~戶進(jìn)行分層,簡化大規(guī)模網(wǎng)絡(luò),還利用熵權(quán)法對各賬戶主體進(jìn)行評(píng)價(jià),分析各主體在洗錢網(wǎng)絡(luò)中的重要性[6]。
(3)行為模型。Demetis DS使用EM聚類算法,進(jìn)行聚類,根據(jù)客戶的歷史數(shù)據(jù)建立概率密度函數(shù),再據(jù)此判斷新數(shù)據(jù)是否可疑,但是它假設(shè)的用戶交易數(shù)據(jù)滿足高斯分布不一定成立[7]。
(4)風(fēng)險(xiǎn)評(píng)估。Larik和Haider改進(jìn)了歐式自適應(yīng)諧振理論,消除了基于距離聚類和基于密度聚類的弱點(diǎn),計(jì)算出平衡集群,將正常行為模式和稍微偏離正常行為模式的數(shù)據(jù)劃分到同一個(gè)集群,且能通過AICAF索引將兩者區(qū)分開,當(dāng)客戶數(shù)據(jù)差異較大時(shí)效果較好[8];Vikas J等人使用了基于位圖索引的決策樹算法評(píng)估風(fēng)險(xiǎn)因數(shù),特別之處在于構(gòu)造決策樹的方法,效率很高[9]。
(5)異常檢測。異常檢測是識(shí)別、發(fā)現(xiàn)每個(gè)賬戶不同尋常的交易。Raza等將貝葉斯網(wǎng)絡(luò)和聚類技術(shù)結(jié)合,先使用模糊C-means聚類算法對客戶交易數(shù)據(jù)進(jìn)行劃分,接著在每個(gè)聚類上構(gòu)造動(dòng)態(tài)貝葉斯網(wǎng)絡(luò),使用后驗(yàn)概率分布進(jìn)行預(yù)測[10];Andrew Elliott等人將交易數(shù)據(jù)構(gòu)造為有向帶權(quán)圖,綜合使用了網(wǎng)絡(luò)比較分析、社區(qū)劃分、頻譜分析和統(tǒng)計(jì)方法,提取出140多個(gè)特征,接著將這些特征聚合,最后采用隨機(jī)森林進(jìn)行正常、異常的劃分[11]。
和上述工作都不同,本文研究是對辦案人員經(jīng)驗(yàn)、知識(shí)總結(jié)、提煉后,以算法形式實(shí)現(xiàn)對人類知識(shí)的固定。
2 基于時(shí)間特征的可疑資金交易識(shí)別算法
2.1 可疑資金交易行為模式分析
通常來說,洗錢過程可以分為處置階段、培植階段、融合階段[12]。處置階段將非法取得的資金投入洗錢系統(tǒng);培植階段通過多種、多賬戶、多層的金融交易來將非法取得的資金與其來源分離開來;融合階段將“合法化”后的資金集中起來使用。通過這三個(gè)階段來達(dá)到掩蓋資金的非法來源和真實(shí)所有權(quán)的洗錢目的。洗錢案件一般涉及的金額較大,涉案人員為了規(guī)避相關(guān)部門的自動(dòng)審查,往往會(huì)采取拆分的方式對資金進(jìn)行多次轉(zhuǎn)移,但交易數(shù)額均在報(bào)告閾值之內(nèi)。即便如此,這些行為也會(huì)呈現(xiàn)出一定的行為特征。
洗錢活動(dòng)中資金交易行為模式有很多,本文以一種“靶心模式”為例展開研究。賬戶所有人若在短時(shí)間內(nèi)有一筆大額資金轉(zhuǎn)入,隨后又以多筆小額資金的形式進(jìn)行轉(zhuǎn)出,這種“一進(jìn)多出”的交易行為模式,本文將其稱作“靶心模式”。除此之外,資金轉(zhuǎn)入、轉(zhuǎn)出的時(shí)間間隔不長,具有快進(jìn)快出的特點(diǎn);作為中轉(zhuǎn)賬戶,操作人有收取手續(xù)費(fèi)的行為,轉(zhuǎn)出總金額和轉(zhuǎn)入總金額的比例在一定范圍之內(nèi);這種轉(zhuǎn)賬工具賬戶具有突發(fā)性,每次資金轉(zhuǎn)移行為的前后時(shí)間段,往往沒有其他資金進(jìn)出行為。在資金融合階段,存在類似的但是方向相反的行為模式。
本文以“靶心模式”為例進(jìn)行探究,提出了一種基于時(shí)間特征的可疑資金交易識(shí)別算法,目的是識(shí)別出呈現(xiàn)“靶心模式”的可疑資金交易。
2.2 基本概念
定義1,交易資金序列。對于序列集X={(d,m,t)│d∈D,m∈R,t∈T},D={′轉(zhuǎn)入′,轉(zhuǎn)出′},R為實(shí)數(shù)集合,T為離散的交易時(shí)間集合,則稱序列集X為某賬戶的交易資金序列。令c=|X|,設(shè)p∈X,q∈X,若p≠q,則p(t)≠q(t)。
定義2,轉(zhuǎn)入交易資金序列。交易資金序列I,I?X,I={(d,m,t)│d=′ 轉(zhuǎn)入′,m∈R,t∈T},則稱交易資金序列為某賬戶的轉(zhuǎn)入交易資金序列。令m=|I|。
定義3,轉(zhuǎn)出交易資金序列。交易資金序列O,O?X,O={(d,m,t)│d=′ 轉(zhuǎn)出′,m∈R,t∈T},則稱交易資金序列為某賬戶的轉(zhuǎn)出交易資金序列。令n=|O|。
2.3 算法框架
“靶心模式”的突發(fā)性行為特點(diǎn),導(dǎo)致了可以采用時(shí)間聚類的方法對交易資金序列進(jìn)行自動(dòng)劃分,然后再結(jié)合其他交易特征進(jìn)行可疑交易的提取和識(shí)別。
如果突發(fā)性不明顯,可能會(huì)使得多次資金轉(zhuǎn)移數(shù)據(jù)混合在一起,導(dǎo)致行為特征不明顯,進(jìn)而降低算法的準(zhǔn)確性。
考慮到在“靶心模式”下,每次資金轉(zhuǎn)移行為的轉(zhuǎn)入和轉(zhuǎn)出存在時(shí)間上的先后關(guān)系,故不對整個(gè)交易資金序列進(jìn)行時(shí)間聚類,而是分別對轉(zhuǎn)入交易資金序列和轉(zhuǎn)出交易資金序列進(jìn)行聚類,這樣有利于降低突發(fā)性不明顯帶來的問題;然后根據(jù)時(shí)間特征,把每個(gè)轉(zhuǎn)出聚類簇和轉(zhuǎn)入聚類簇進(jìn)行對應(yīng),匯集成一次資金轉(zhuǎn)移行為的交易簇;再針對交易簇?cái)?shù)據(jù)進(jìn)行“靶心模式”行為特征匹配,判斷該次資金轉(zhuǎn)移行為是否為可疑交易。
“靶心模式”的可疑交易資金的識(shí)別算法框架如圖1所示。
(1)對數(shù)據(jù)進(jìn)行預(yù)處理,轉(zhuǎn)換為交易資金序列;
(2)將交易資金序列按照資金流動(dòng)方向劃分為轉(zhuǎn)入交易資金序列和轉(zhuǎn)出交易資金序列;
(3)分別對轉(zhuǎn)入交易資金序列和轉(zhuǎn)出交易資金序列進(jìn)行時(shí)間聚類,在適當(dāng)排除噪聲、調(diào)整聚類方法的參數(shù)后,保證兩次聚類得到的簇?cái)?shù)目一致;
(4)對每一個(gè)轉(zhuǎn)入交易資金序列的聚類簇Ca,在轉(zhuǎn)出交易資金序列的聚類簇中尋找一個(gè)聚類簇Cb,使得Cb簇中心的交易時(shí)間大于Ca簇中心的交易時(shí)間,且差值在預(yù)設(shè)區(qū)間內(nèi);將Ca、Cb合并為交易簇Ct;
(5)計(jì)算每個(gè)交易簇中轉(zhuǎn)出總金額和轉(zhuǎn)入總金額的比值,如果不在預(yù)設(shè)區(qū)間,則為不平衡賬戶,不符合“靶心模式”行為特征;
(6)計(jì)算每個(gè)交易簇中轉(zhuǎn)出總筆數(shù)與轉(zhuǎn)入總筆數(shù)的比值;如果不在預(yù)設(shè)區(qū)間,則視為不符合“靶心模式”行為特征;
(7)通過(5)和(6)檢測的交易簇?cái)?shù)據(jù),就是具備“靶心模式”行為特征的可疑交易數(shù)據(jù)。
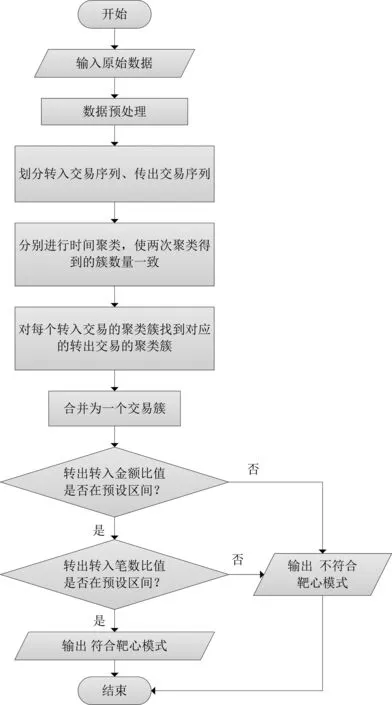
圖1 算法流程圖
2.4 聚類算法的選取
聚類方法可以按照算法思想分為四類:基于劃分、基于密度、基于層次、基于網(wǎng)格。常見的聚類算法有:K均值算法(K-means),基于密度的聚類算法(DBSCAN)、凝聚層次聚類,它們分別對應(yīng)于基于劃分、基于密度、基于層級(jí)的聚類算法。
不同的聚類算法在不同的數(shù)據(jù)集上的表現(xiàn)存在差異,依據(jù)數(shù)據(jù)集的特點(diǎn)選擇合適的聚類算法是十分必要的。K-means作為聚類算法中使用最為廣泛的算法,其優(yōu)點(diǎn)是理解簡單、容易實(shí)現(xiàn)、時(shí)間復(fù)雜度低,缺點(diǎn)是對噪聲和離群值敏感、不適用于結(jié)果是非凸形分布的數(shù)據(jù)、需要給定聚類簇?cái)?shù)。DBSCAN的優(yōu)點(diǎn)是無須預(yù)先給定聚類的簇?cái)?shù)、可以識(shí)別任意形狀的數(shù)據(jù)、可以識(shí)別噪聲,缺點(diǎn)是不適用于密度不均勻的數(shù)據(jù)。層級(jí)聚類的優(yōu)點(diǎn)是無須預(yù)先給定聚類的簇?cái)?shù),可以發(fā)現(xiàn)類的層次關(guān)系,缺點(diǎn)是計(jì)算復(fù)雜度高,容易聚成鏈狀。
在本文研究的“靶心模式”行為特征的交易資金序列,不存在層次關(guān)系;轉(zhuǎn)入交易資金序列的特點(diǎn)是交易筆數(shù)少,單筆交易金額大,交易時(shí)間分散;轉(zhuǎn)出交易資金序列的特點(diǎn)是交易筆數(shù)多,單筆交易金額相對轉(zhuǎn)入一般不大,交易時(shí)間密集且不一定均勻。考慮到轉(zhuǎn)入交易資金序列中的交易筆數(shù)少,即樣本點(diǎn)不多,噪聲對聚類的影響較大,故使用DBSCAN對轉(zhuǎn)入交易資金序列進(jìn)行時(shí)間聚類。由于轉(zhuǎn)出交易資金序列中交易筆數(shù)多,即樣本點(diǎn)多,噪聲對整體聚類影響不明顯,且存在交易時(shí)間分布密度不均勻的情況,故使用K-means對轉(zhuǎn)出交易資金序列進(jìn)行時(shí)間聚類。
2.5 算法設(shè)計(jì)
在識(shí)別具備“靶心模式”行為特征的可疑資金交易時(shí),設(shè)X為某涉案賬戶A的交易資金序列,設(shè)集合中元素?cái)?shù)量為c,故有X={x1,x2,…,xc-1,xc}。
(1)按照資金流動(dòng)方向,交易資金序列X劃分為轉(zhuǎn)入交易資金序列I和轉(zhuǎn)出交易資金序列O,它們各自的交易筆數(shù)分別為m和n。則有轉(zhuǎn)入集合I={i1,i2,…,im-1,im},轉(zhuǎn)出集合O={o1,o2,…,on-1,on},c=m+n。
(2)抽取轉(zhuǎn)入交易資金序列I和轉(zhuǎn)出交易資金序列O的時(shí)間集合,轉(zhuǎn)入時(shí)間集合表示為TI={t1,t2,…,tm},轉(zhuǎn)出時(shí)間集合可以表示為TO={t1,t2,…,tn}。
(3)使用K-means算法對轉(zhuǎn)出時(shí)間集合TO進(jìn)行聚類,k從2開始,多輪聚類,取使輪廓系數(shù)最大的k值為最終簇?cái)?shù)量。
(4)使用DBSCAN算法對轉(zhuǎn)入時(shí)間集合TI進(jìn)行聚類,調(diào)整DBSCAN算法中的的參數(shù),包括鄰域距離eps和鄰域最小樣本個(gè)數(shù)MinPts,排除噪聲點(diǎn)后保證聚類得到的簇?cái)?shù)量與上一步驟中的k值相同。如果無法得到k個(gè)簇,算法終止。
(5)將轉(zhuǎn)入時(shí)間集合的聚類結(jié)果按照聚類中心升序排序后,定義每個(gè)轉(zhuǎn)入時(shí)間簇為TI1,TI2,…,TIk,TI=TI1∪…∪TIk;同樣,將每個(gè)轉(zhuǎn)出時(shí)間簇定義為TO1,TO2,…,TOk,TO=TO1∪…∪TOk。
(6)對轉(zhuǎn)入時(shí)間簇TIi,找到晚于且最接近于其聚類中心的轉(zhuǎn)出時(shí)間簇TOj,且兩個(gè)聚類中心的時(shí)間差小于閾值γ;TIi∪TOj構(gòu)成一個(gè)交易時(shí)間簇。在交易資金序列X中按照交易時(shí)間查找對應(yīng)元素,形成對映的交易簇。
(7)給定閾值δ,計(jì)算每個(gè)交易簇中轉(zhuǎn)入總金額MI、轉(zhuǎn)出總金額MO,若MO/MI>δ,則認(rèn)為該交易簇的交易行為不符合扣手續(xù)費(fèi)的特征,不符合“靶心模式”。
(8)給定閾值σ,計(jì)算每個(gè)交易簇中轉(zhuǎn)入總筆數(shù)FI、轉(zhuǎn)出總筆數(shù)FO,若FO/FI>σ時(shí),則認(rèn)為該交易簇的交易行為模式符合“靶心模式”,該交易簇中全部交易為“靶心模式”下的可疑資金交易。
在交易資金序列的定義中,已經(jīng)約束了某賬戶的每筆交易具有時(shí)間唯一性,保證了在步驟(6)中,能夠正確地從交易資金序列X中按照時(shí)間找到對應(yīng)元素。
3 實(shí)驗(yàn)設(shè)計(jì)及結(jié)果
3.1 數(shù)據(jù)準(zhǔn)備
根據(jù)某可疑賬戶的數(shù)據(jù),設(shè)計(jì)了具有相同行為特點(diǎn)的模擬數(shù)據(jù)。模擬數(shù)據(jù)的時(shí)間跨度從2017年4月到2017年12月,包含2358條交易數(shù)據(jù),有129條轉(zhuǎn)入交易數(shù)據(jù),2229條轉(zhuǎn)出交易數(shù)據(jù),轉(zhuǎn)入資金總計(jì)約4470萬元,轉(zhuǎn)出資金總計(jì)約3870萬元。每個(gè)數(shù)據(jù)項(xiàng)包含交易時(shí)間、金額、交易方向和交易對手ID四項(xiàng)內(nèi)容,其中交易時(shí)間為時(shí)間戳格式。
接著清洗數(shù)據(jù)。刪除小額交易數(shù)據(jù),這往往是正常的消費(fèi)數(shù)據(jù);刪除交易對手是自己的數(shù)據(jù),這是自己對倒行為,不是本文要分析的內(nèi)容,排除后可以減少干擾。每個(gè)數(shù)據(jù)項(xiàng)保留交易時(shí)間、金額和交易方向三項(xiàng)內(nèi)容,按照交易方向,將數(shù)據(jù)劃分為轉(zhuǎn)出交易資金序列和轉(zhuǎn)入交易資金序列。最終得到2316條數(shù)據(jù)。
將清洗后的交易數(shù)據(jù)進(jìn)行按月時(shí)間-頻次可視化后,發(fā)現(xiàn)交易頻次比較高的集中在2017年5月和2017年7月兩個(gè)月份,2017年5月有數(shù)據(jù)260條,轉(zhuǎn)入4條,轉(zhuǎn)入金額238萬元,轉(zhuǎn)出256條,轉(zhuǎn)出金額295萬元,2017年7月有數(shù)據(jù)258條,轉(zhuǎn)入8條,轉(zhuǎn)入金額489萬元,轉(zhuǎn)出250條,轉(zhuǎn)出金額458萬元;其余月份頻次低,轉(zhuǎn)入、轉(zhuǎn)出間隔較遠(yuǎn),明顯不符合“靶心模式”的行為特征,所以選取2017年5月與2017年7月兩個(gè)月的交易數(shù)據(jù)進(jìn)行分析。
3.2 實(shí)驗(yàn)過程及分析
使用Python3,調(diào)用sklearn.cluster中的K-means方法對轉(zhuǎn)出交易資金序列的時(shí)間進(jìn)行聚類,不斷調(diào)整參數(shù),繪制輪廓系數(shù)隨k值變化的曲線,選取效果最佳的k值;調(diào)用sklearn.cluster中的DBSCAN方法對轉(zhuǎn)入交易資金序列的時(shí)間進(jìn)行聚類,依據(jù)確定的k值,對DBSCAN進(jìn)行調(diào)參。統(tǒng)計(jì)聚類結(jié)果中每個(gè)交易簇的各項(xiàng)指標(biāo),觀察指標(biāo)是否符合閾值規(guī)定的區(qū)間。按照簇中心時(shí)間相近、方向?qū)?yīng)原則,合并得到多個(gè)交易簇。對每一個(gè)交易簇進(jìn)行“靶心模式”識(shí)別。
對2017年5月的轉(zhuǎn)出交易資金序列,根據(jù)交易時(shí)間,k的取值從1到50變化,依次進(jìn)行K-means聚類;根據(jù)每次聚類得到的輪廓系數(shù),畫出變化曲線,如圖2所示。當(dāng)k=3時(shí)輪廓系數(shù)最大,為0.995,所以最終確定簇?cái)?shù)量k為3。
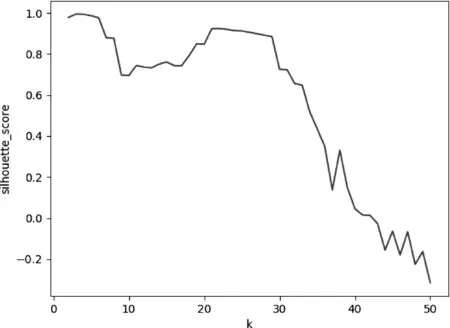
圖2 輪廓系數(shù)隨k值變化曲線
對轉(zhuǎn)入交易資金序列,根據(jù)交易時(shí)間使用DBSCAN進(jìn)行聚類。計(jì)算[元素個(gè)數(shù)/k]=1,所以令參數(shù)MinPts=1;對交易時(shí)間排序后計(jì)算差分,得到差分序列,以各差分值為鄰域距離參數(shù)eps,逐次聚類,取聚類數(shù)量為3時(shí)的結(jié)果為最終結(jié)果。
根據(jù)聚類結(jié)果,將轉(zhuǎn)入交易資金序列劃分為3個(gè)子序列,每個(gè)子序列根據(jù)交易時(shí)間分別畫出箱線圖,如圖3(a)所示,橫坐標(biāo)代表各聚類中心點(diǎn)的時(shí)間順序,縱坐標(biāo)為交易時(shí)間。同樣根據(jù)聚類結(jié)果,將轉(zhuǎn)出交易資金序列劃分為3個(gè)子序列,每個(gè)子序列根據(jù)交易時(shí)間分別畫出箱線圖,如圖3(b)所示,橫坐標(biāo)代表各聚類中心點(diǎn)的時(shí)間順序,縱坐標(biāo)為交易時(shí)間。
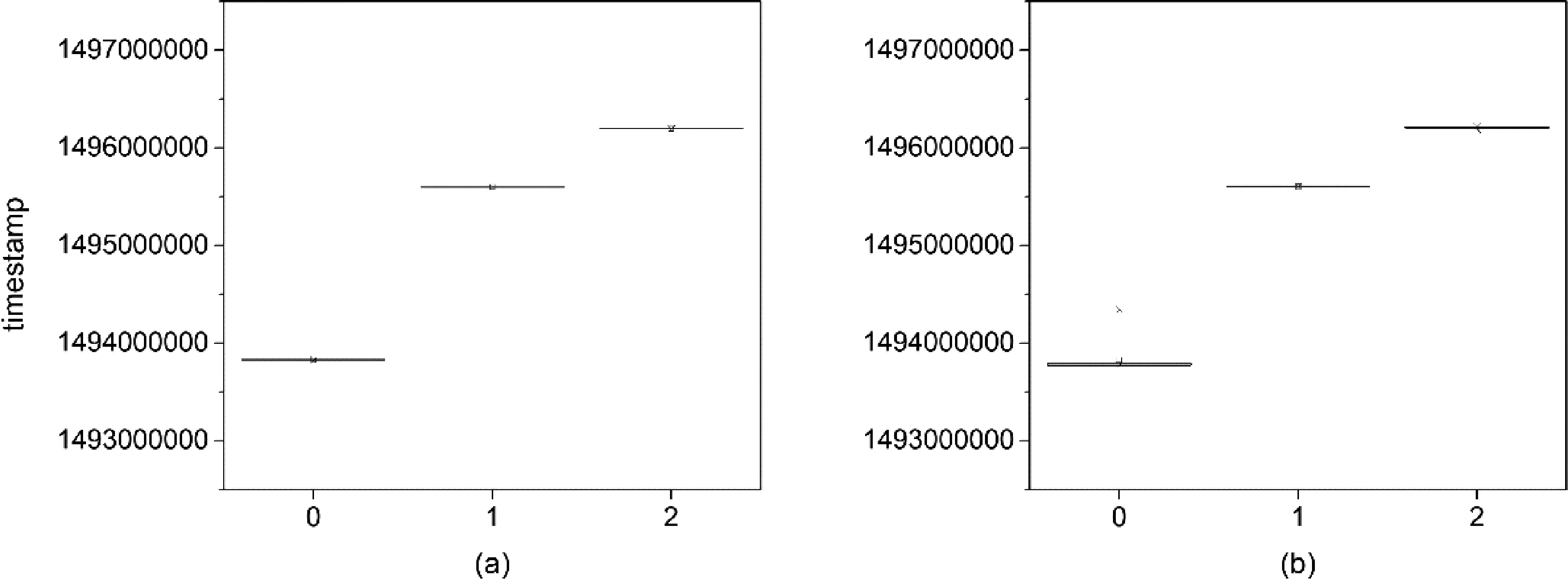
圖3 2017年5月交易數(shù)據(jù)分簇箱線圖
箱線圖可以反映出每個(gè)簇中交易時(shí)間的分布情況,具體體現(xiàn)在極大值、極小值、中位數(shù)和兩個(gè)四分位數(shù)上。當(dāng)以上幾個(gè)值相當(dāng)接近或完全重合時(shí),箱型圖的形狀趨近于一條直線。可以看出,2017年5月發(fā)生的交易在基于時(shí)間特征進(jìn)行聚類后,每個(gè)簇的交易時(shí)間十分緊密,每個(gè)箱型圖的形狀趨近于一條直線,且與其他的簇分布位置相隔一段距離,這也反映出聚類的輪廓系數(shù)很高。還可以看出,對轉(zhuǎn)入時(shí)間集合和轉(zhuǎn)出時(shí)間集合聚類后得到的簇分布位置非常一致。
同樣的方法,在對2017年7月交易資金序列進(jìn)行計(jì)算后,轉(zhuǎn)出資金序列數(shù)據(jù)聚類數(shù)為2,轉(zhuǎn)入資金序列在聚類時(shí)候存在噪聲,所以多了一個(gè)噪聲簇。刪除噪聲簇后所畫箱線圖如圖4所示。
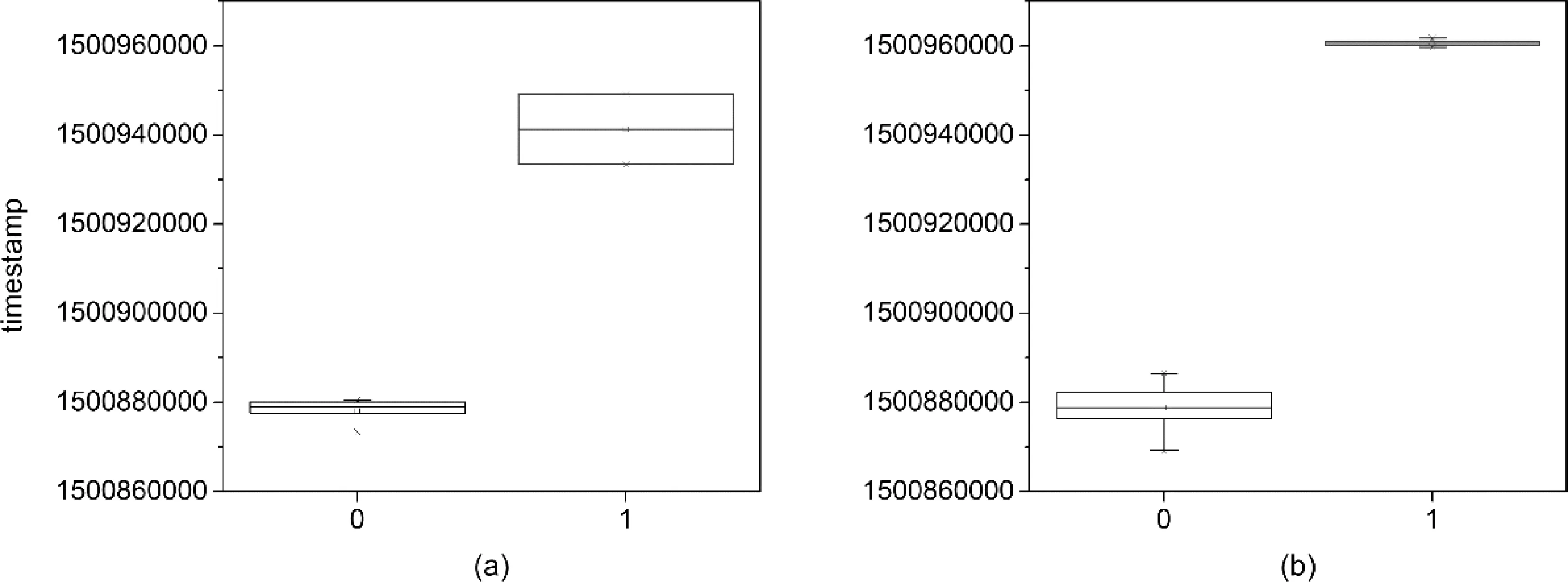
圖4 2017年7月交易交易數(shù)據(jù)分簇箱線圖
根據(jù)辦案干警經(jīng)驗(yàn),取δ=1.05,σ=100,即“靶心模式”模式要求轉(zhuǎn)出總金額與轉(zhuǎn)入總金額相差在百分之五以內(nèi),每筆轉(zhuǎn)入要對應(yīng)100筆以上的轉(zhuǎn)出。兩個(gè)月的交易數(shù)據(jù),分別按聚類簇計(jì)算,結(jié)果如表1和表2所示。

表1 5月數(shù)據(jù)實(shí)驗(yàn)結(jié)果

表2 7月數(shù)據(jù)實(shí)驗(yàn)結(jié)果
表1中,0號(hào)交易簇,兩個(gè)比值都不在閾值之內(nèi),2號(hào)交易簇,雖然轉(zhuǎn)出總金額與轉(zhuǎn)入總金額基本平衡,但轉(zhuǎn)出交易筆數(shù)不符合“靶心模式”的特點(diǎn),只有1號(hào)交易簇滿足設(shè)定的閾值,可以判定為“靶心模式”的可疑資金交易。
表2中,0號(hào)交易簇雖然轉(zhuǎn)入轉(zhuǎn)出總金額基本平衡,但是轉(zhuǎn)入轉(zhuǎn)出筆數(shù)不滿足“靶心模式”的特點(diǎn)。1號(hào)交易簇滿足設(shè)定的閾值,可以判定為“靶心模式”的可疑資金交易。
4 結(jié)語
本文算法實(shí)現(xiàn)了對可疑交易資金的識(shí)別,但是這些交易行為是否就一定是違法行為,單純從交易資金數(shù)據(jù)上是無法給出準(zhǔn)確結(jié)論的。本文研究定位于先找出可疑的資金數(shù)據(jù),進(jìn)而提供偵查方向。本文算法已經(jīng)在經(jīng)濟(jì)犯罪案件偵查中得到應(yīng)用,算法能夠在海量資金數(shù)據(jù)中找到可疑的賬戶和人員,為案件偵查提供了方向,辦案部門據(jù)此展開進(jìn)一步偵查,已經(jīng)偵破了多起案件。
猜你喜歡
股市動(dòng)態(tài)分析(2020年21期)2020-11-06 07:24:07
股市動(dòng)態(tài)分析(2020年20期)2020-10-26 02:22:07
股市動(dòng)態(tài)分析(2020年19期)2020-09-26 09:35:37
股市動(dòng)態(tài)分析(2020年18期)2020-09-12 14:30:15
股市動(dòng)態(tài)分析(2020年17期)2020-09-02 07:16:26
股市動(dòng)態(tài)分析(2020年16期)2020-08-17 07:24:32
股市動(dòng)態(tài)分析(2020年15期)2020-08-12 09:09:31
股市動(dòng)態(tài)分析(2020年14期)2020-08-12 09:09:12
股市動(dòng)態(tài)分析(2020年13期)2020-08-12 05:25:53
股市動(dòng)態(tài)分析(2020年12期)2020-08-12 05:25:33
