基于自適應MMSE-LSA與NMF的語音增強算法
2021-09-10 03:48:04馬振中
探測與控制學報 2021年4期
董 胡,劉 剛,2,馬振中
(1.長沙師范學院信息科學與工程學院,湖南 長沙 410100; 2.中南大學物理與電子學院,湖南 長沙 410012)
0 引言
語音增強是提高含噪語音信號質量和清晰度的重要步驟,為了更好地理解含噪語音信號,需要一種語音增強技術來去除環境中的噪聲。在以往的文獻中,各種各樣的語音增強技術都被用于降噪。雖然抑制背景噪聲和改善語音質量的語音增強算法的開發已經取得了一定的進展,但在提高語音清晰度和可懂度的算法方面仍需進一步改善。
近年來,相關研究者提出了一些低信噪比[1-2](<6 dB)環境下的語音增強算法。文獻[3]提出基于單麥克風信道的語音增強算法,與傳統的單通道語音增強方法相比,該算法具有較好的語音增強性能,但它不適用于快速變化的非平穩噪聲。文獻[4]和文獻[5]分別提出基于波形網絡、生成對抗網絡的語音增強算法,這兩種算法能較好地將目標語音與混合語音分離,但這兩種算法的計算復雜度較高,對內存資源的要求較高。目前常用的譜減法、維納濾波法、最小均方差估計法在去除背景噪聲方面有一定的效果,但有時會造成語音失真或產生音樂噪聲[6-8]。其中,幅度譜估計算法中的對數譜最小均方誤差估計算法(minimum mean square error of log-spectral amplitude estimator, MMSE-LSA)[9-11]具有較好的語音保真度,因此得到廣泛的關注;然而,傳統MMSE-LSA算法無法依據輸入信號的信噪比對增益因子作自適應調整,在輸入信號的信噪比變化的條件下,該算法性能不穩定。非負矩陣分解(nonnegative matrix factorization, NMF) 算法對語音與噪聲作非負矩陣分解獲得相應字典矩陣,測試階段將混合信號幅度譜分解為字典矩陣與權重矩陣的乘積;最后通過語音字典及權重矩陣乘積重構增強后語音[12-14]。本文針對上述問題,提出了基于自適應MMSE-LSA與NMF的語音增強算法。
1 自適應MMSE-LSA算法
MMSE-LSA算法對語音增強涉及先驗信噪比與后驗信噪比的估算問題[15]。伴隨著對噪聲估計結果的變化,需對信噪比作適時更新,由于在先驗信噪比的估算過程中引入了調節因子α′,通常對其設定一個范圍,再依據多次實驗結果來確定一個經驗值。然而,這種通過實驗來確定經驗值的方法,對于不同信噪比的情況可能會造成語音失真或產生音樂噪聲問題,因此需對α′值作及時更新[8]。自適應MMSE-LSA算法則采用先驗信噪比的最小均方差,依據噪聲變化獲得α′在不同信噪比情況下的自適應最優值。
x(n),d(n)和y(n)分別代表純凈語音、噪聲及含噪語音,有:
y(n)=x(n)+d(n)
(1)
式(1)經FFT變換后可得下式:
|Y(n,k)|2=|X(n,k)|2+|D(n,k)|2
(2)
式(2)中,|Y(n,k)|2,|X(n,k)|2,|D(n,k)|2分別為含噪語音、純凈語音及噪聲短時譜幅度。
Y(n,k)=|Y(n,k)|∠θy
(3)
X(n,k)=|X(n,k)|∠θx
(4)
式(3)、式(4)中,∠θx和∠θy代表相位。
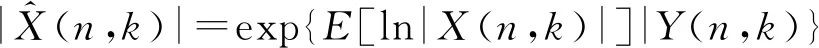
(5)
|X(n,k)|=G(n,k)|Y(n,k)
(6)
(7)
式(7)中,ξ(n,k)為語音信號第n幀的第k個頻率點先驗信噪比,其定義如下:
(8)
(9)
從式(7)可知,計算增益函數須獲得先驗信噪比,進而才能估計出純凈語音,能否準確估計出先驗信噪比對語音增強效果有重要影響。傳統MMSE-LSA算法對先驗信噪比的估計使用直接判決法。

(10)
式(10)中,α依據經驗其取值范圍[0.8,1],ε為一個無限接近于0的正實數,γ(n,k)是后驗信噪比(SNRpost(n,k)),定義如下:
(11)
由文獻[16]可知,先驗信噪比估計的另一種表示式為:
(12)
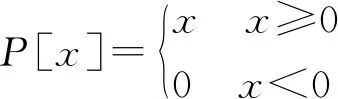
(13)
(14)
由式(12)和式(14)可得下式:

(15)
對M進行求導,并假定?M/?α[n,k]=0,則可求α的最優解:
(16)
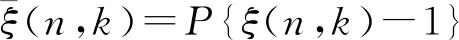
2 NMF語音增強算法
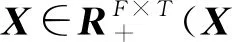
X≈WH
(17)
式(17)中,W為字典矩陣,K為W的維度,H為權重矩陣。W的列向量是描述X頻譜結構的基向量,H中的值為W中基向量對應的激活值。式(17)可通過解決下面最優化問題獲得W和H:
(18)
dKL(·|·)為廣義Kullback-Leiber散度(KL divergence),定義為:
(19)
可通過下述乘法迭代準則得到最小化KL散度:
W=W.*((X./(WH))HT)./(lHT)
(20)
H=H.*(WT(X./(WH)))./(WTl)
(21)
其中,l為值全為1的矩陣,維度與X相同,.*和./表示矩陣逐點相乘和逐點相除。通過將W和H初始化為非負值,然后通過式(20)、式(21)迭代并更新W和H進而獲得最終的W和H。基于NMF的語音增強算法主要由以下四個部分組成:
1) 計算訓練數據中語音和噪聲信號的幅度譜XS和XN、測試信號的幅度譜X;
2) 對XS和XN通過式(17)作非負矩陣分解,得到WS和WN,令W=[WS,WN];
3) 對X作非負矩陣分解,即X≈WH,固定W,由式(21)迭代獲得權重矩陣H;
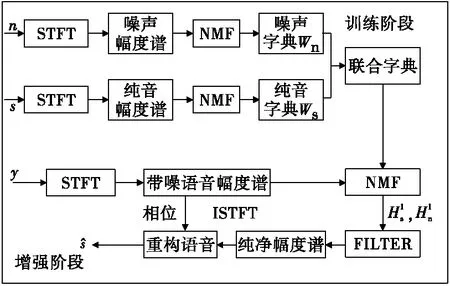
圖1 NMF語音增強框架Fig.1 NMF speech enhancement framework
3 仿真實驗結果
實驗用的純凈語音來自于IEEE語音數據庫,噪聲選用Noisex-92噪聲數據庫。通過人工加噪方式,將純凈語音信號與噪聲信號按一定信噪比進行混合(SNR=-5~10 dB),進而獲得一定量的含噪語音信號,分別使用譜減算法、維納濾波算法及本文提出的自適應MMSE-LSA與NMF算法進行語音增強,并將純凈語音信號作為評價增強效果的標準信號。選擇語音質量感知評價(perceptual evaluation of speech quality, PESQ)[17]和對數譜距離(log-spectral distance, LSD)[18]作為語音增強效果的客觀評價指標。
為了說明本文所提自適應MMSE-LSA與NMF語音增強算法的有效性,圖2—圖5分別給出white噪聲、factory噪聲、m109噪聲及volvo噪聲環境下SNR=-5 dB的含噪語音信號經譜減算法、維納濾波算法及本文算法進行語音增強結果。從圖2—圖5可知,在-5 dB的white噪聲、factory噪聲、m109噪聲及volvo噪聲環境下,譜減算法的去噪效果相對于維納濾波及本文提出的算法較差,對于語音中的清音部分幾乎被噪聲所掩蓋;在低信噪比的factory噪聲、m109噪聲及volvo噪聲環境下,譜減算法不僅無法有效提取語音中的清音部分,而且會產生語音失真及音樂噪聲現象。在-5 dB的white噪聲、factory噪聲、m109噪聲及volvo噪聲環境下,維納濾波算法相對譜減算法雖能較好地去除背景噪聲,但維納濾波算法無法提取出含噪語音中的清音部分,甚至將部分清音信號濾除掉,且會產生音樂噪聲現象。本文算法與譜減算法、維納濾波算法相比,不僅能準確有效地提取含噪語音中的清音部分,而且降低了音樂噪聲,在可懂度和清晰度方面均具有較明顯的優勢。
實驗對比分析了譜減算法、維納濾波算法和本文提出的自適應MMSE-LSA與NMF語音增強算法在不同噪聲環境下的語音增強效果,實驗所得結果見表1與表2。表1給出了不同噪聲環境下三種增強算法進行增強語音后的PESQ值,表2給出了對應的LSD值。

圖2 含white噪聲SNR=-5 dB譜減、維納及本文算法增強結果Fig.2 Spectral subtraction, Wiener and enhancement results of our algorithm with SNR =-5 dB white noise

圖3 含factory噪聲SNR=-5 dB譜減、維納及本文算法增強結果Fig.3 Spectral subtraction, Wiener and enhancement results of our algorithm with SNR =-5 dB factory noise

圖4 含m109噪聲SNR=-5 dB譜減、維納及本文算法增強結果Fig.4 Spectral subtraction, Wiener and enhancement results of our algorithm with SNR =-5 dB m109 noise

圖5 含volvo噪聲SNR=-5 dB譜減、維納及本文算法增強結果Fig.5 Spectral subtraction, Wiener and enhancement results of our algorithm with SNR =-5 dB volvo noise
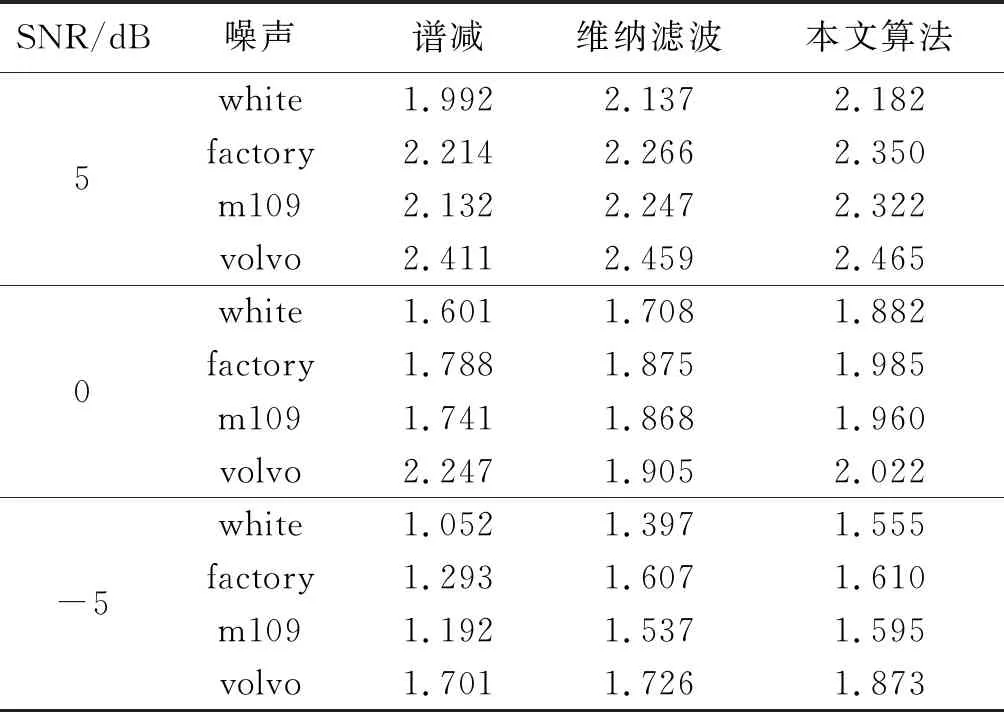
表1 不同噪聲環境下的PESQ
由表1可知,在white、factory、m109和volvo背景噪聲環境下,當SNR分別為5、0和-5 dB時,本文提出算法的PESQ值要比譜減算法及維納濾波算法高。
在SNR=-5 dB的white噪聲及m109噪聲環境下,本文所提算法的PESQ值最高比譜減算法分別高出0.503及0.403;在SNR=0 dB的white噪聲及SNR=-5 dB的volvo噪聲環境下,本文所提算法的PESQ值最高比維納濾波算法分別高出0.174及0.147。
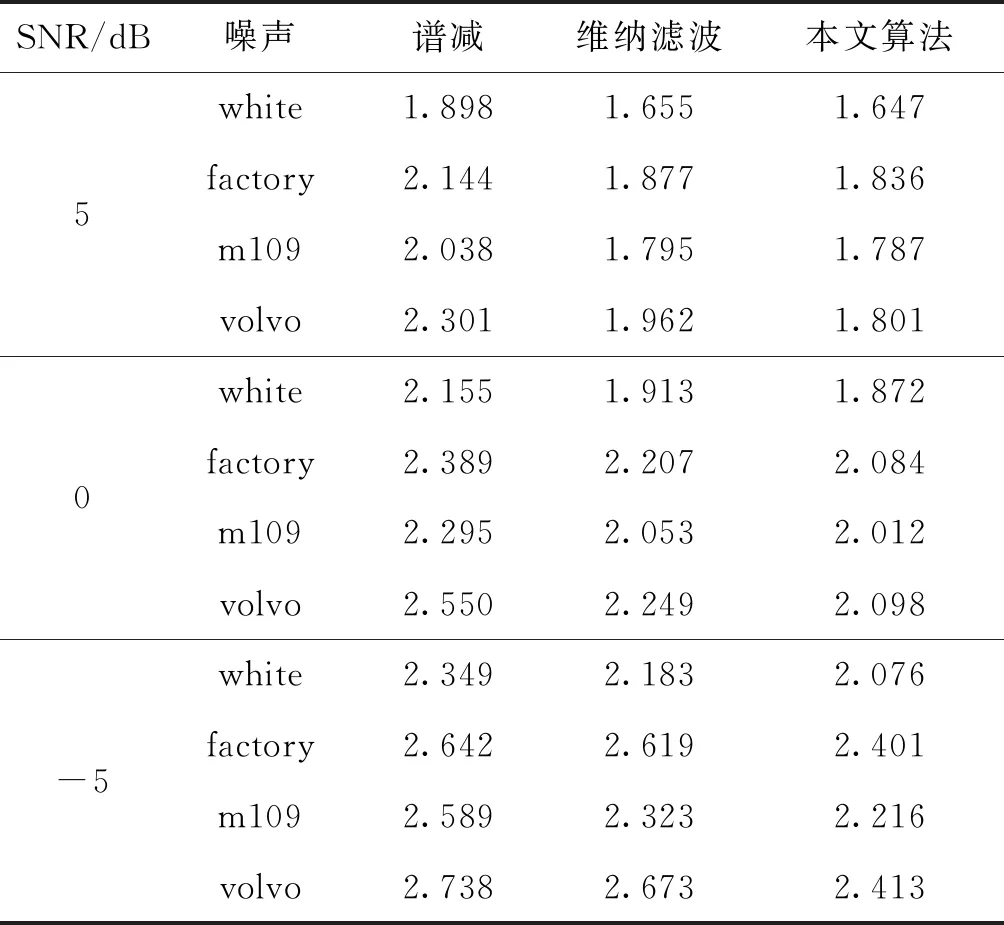
表2 不同噪聲環境下的LSD
表2為在white、factory、m109及volvo噪聲背景下,三種不同語音增強算法的LSD值。由表2可知,本文算法的LSD值均要小于譜減算法及維納濾波算法,這主要是因為譜減算法及維納濾波算法語音增強后存在“音樂噪聲”,導致它們的LSD值相對較高。在給出的四種不同信噪比的噪聲環境下,本文的語音增強算法的語音失真度都較小。在處于-5 dB的white噪聲下,本文算法的LSD值相對于另外兩種語音增強算法平均下降9.15%;在factory噪聲下,LSD值平均下降 9.56%;在m109噪聲下LSD值平均下降10.83%;volvo噪聲下,LSD值平均下降12.12%。由此可見,低信噪的噪聲環境下,本文提出的語音增強算法相對于譜減算法及維納濾波算法,其LSD性能表現為最優。
4 結論
本文提出了基于自適應MMSE-LSA與NMF的語音增強算法。該算法結合了自適應對數譜幅度最小均方誤差和非負矩陣分解兩種語音增強算法的優點,利用MMSE估計器對含噪語音信號進行增強,提高輸入信號的信噪比,然后利用NMF算法對增強后產生的語音失真和殘留噪聲進行補償,既能有效地降低背景噪聲又減少了語音失真。仿真實驗結果表明,綜合PESQ及LSD兩種語音增強標準,本文提出的自適應MMSE-LSA與NMF語音增強算法要優于譜減算法及維納濾波算法。此外,在不同的低信噪比環境下,語音增強算法具有良好的增強效果,表明本文提出的算法具有較強的適應能力。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年3期)2019-02-01 06:12:26
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
