基于水廠大數據的混凝投藥系統智能模型的構建
2021-09-10 06:05:04李玉寶樊玉芳顧軍農
凈水技術 2021年9期
韓 梅,李玉寶,鄒 放,劉 暢,樊玉芳,顧軍農
(1. 北京市自來水集團有限責任公司,北京市供水水質工程技術研究中心,北京 100012;2. 成都九鼎瑞信科技股份有限公司,四川成都 610000;3. 重慶大學環境與生態學院,重慶 400044)
混凝沉淀工藝一直是凈水廠的核心處理單元,而混凝投藥的精細化控制更是關乎水質效果和能耗的關鍵,是水廠一直追求的目標。近年來,隨著科技發展的驅動,物聯網、大數據、人工智能等多領域的技術和理念已融入水處理領域,混凝投藥系統正在從人工控制向智能控制、精準控制邁進。
傳統的混凝過程具有時延、滯后的特性[1-3],在水源水質、水量等條件發生變化時,難以實現混凝劑投加量的精準控制,導致水質不穩定,影響后續濾池等工藝的濾程、反洗周期等。智能控制技術準確性高、響應快,能夠依據水源水質的變化,及時確定混凝劑的投加量,對建立安全、高效、節能型水廠具有深遠的現實意義。而如何通過精準感知,借力大數據、人工智能等新一代信息技術,真正實現混凝加藥的智能控制還需不斷探索。
目前,XGBoost、LSTM、支持向量機、隨機森林等算法已應用于各個領域的信息挖掘、預測等方面,是相對較成熟的算法[4-7]。XGBoost(extreme gradient boosting)算法是Gradient Boosting算法的高效實現版本,可認為是在GBDT算法基礎上的進一步優化。首先,XGBoost算法在基學習器損失函數中引入了正則項,控制減少訓練過程當中的過擬合;其次,XGBoost算法不僅使用一階導數計算偽殘差,還計算二階導數,可近似快速剪枝的構建新的基學習器;此外,XGBoost算法還做了很多工程上的優化,例如,支持并行計算、提高計算效率、處理稀疏訓練數據等,因而,其在應用實踐中表現出優良的效果和效率,被工業界廣為推崇[8]。LSTM算法即長短時記憶(long short-term memory),最早由Hochreiter等[9]于1997年提出,是一種特定形式的循環神經網絡(recurrent neural network,RNN)。然而,RNN在處理長期依賴(時間序列上距離較遠的節點)時會遇到巨大的困難,計算距離較遠的節點之間的聯系時,涉及雅可比矩陣的多次相乘,會帶來梯度消失(經常發生)或者梯度膨脹(較少發生)的問題。LSTM的巧妙之處在于,通過增加輸入門、遺忘門和輸出門,使自循環的權重發生變化,避免了梯度消失或者梯度膨脹的問題[10]。此外,隨機森林(random forest,RF)算法是以決策樹為基礎的集成學習算法,作為機器學習算法,在處理復雜數據源、數據噪聲及有限訓練樣本方面有較好的表現[6]。支持向量機(support vector machine)是一類按監督學習(supervised learning)方式對數據進行二元分類的廣義線性分類器[11]。
本文以大型水廠人工數據和在線數據為基礎,通過LSTM、支持向量機、隨機森林、XGBoost等分別建立了混凝投藥模型,系統比較了各種算法的建模效果,并嘗試采用箱線圖結合移動平滑的技術對異常值進行處理,使得最終混凝投藥模型更精準、適用性更強。
1 試驗裝置和方法
1.1 水廠數據劃分
A、B水廠原水均是南水北調水源,是接收南水的主力水廠,同時,兩個水廠均采用機械加速澄清池作為主要除濁工藝。因此,分別以A、B水廠為研究對象,進行智能投藥模型的構建。
A水廠粗粒度數據建模以d為單位,訓練數據取自2016年7月1日—2018年12月31日,共計914條數據量;測試數據取自2019年1月1日—2019年5月31日,共計151條數據量。細粒度數據建模以5 min為一個粒度,均為在線數據,同樣,將數據集分為訓練集和測試集。訓練集是2015年1月1日—2018年12月31日,共計420 768條;測試集是2019年1月1日—2019年10月15日,共計82 944條。
B水廠數據包括人工數據和在線數據,具體進水量和加藥數據選取2015年1月1日—2020年7月6日,數據粒度為h;在線數據包括進水、機加池、炭池和出廠的水質數據,時間為2015年1月1日—2020年6月30日,數據粒度為5 min;此外,氯投加量、臭氧投加量及混凝劑投加數據的時間是2015年1月1日—2020年6月28日,數據粒度為周。將上述數據合并后,共計578 304條,時間為2015年1月1日—2020年6月30日,數據粒度為5 min。經過處理后得到有效數據共計486 252條,訓練集為2015年1月1日—2018年12月31日,共計363 684條,測試集為2019年1月1日—2019年10月31日,共計85 992條。
1.2 異常數據的處理方法
細粒度數據的數據量較大,且由于在線儀表維護和檢修等會存在一定的異常數據,此外,部分數據大量重復對建模工作不利,需在建模前對數據進行預處理。對A水廠細粒度數據采用了兩種方案的異常數據處理方法。方案一是根據經驗對水質指標進行約束,限定范圍,如直接去除進水渾濁度大于20 NTU的數據、機加池出水渾濁度大于5 NTU的數據、預臭氧大于0.7 mg/L的數據和pH值大于8.6或小于4.66的數據,對于進水電導率大于400 μS/cm或小于100 μS/cm的數據使用電導率的均值替代,對于進水氨氮大于0.24 mg/L的數據使用均值替代,同時,去除部分時間段高度重復的數據;方案二是采用基于滑動均值的異常數據識別技術,本研究窗口大小為200,即某一時刻的滑動均值等于從該時刻開始往前的200條數據的加權平均值,數據的權重呈指數分布,離該時刻越近的數據權重越大。
B水廠異常數據采用箱線圖和基于滑動均值的異常數據識別技術相結合的方法處理。如圖1所示,箱線圖是對數據分布的一種常用表示方法,先將數據從小到大排序,然后找到最小值、1/4位數、中位數、3/4位數、最大值,進而計算最小觀察值和最大觀察值,如式(1)~式(2)。如果最小值≤最小觀察值,則下邊緣=最小觀察值;反之,最小值>最小觀察值,則下邊緣=最小值。如果最大值≥最大觀察值,則上邊緣=最大觀察值;反之,最大值<最大觀察值,則上邊緣=最大值。數據如果落在下邊緣和上邊緣之間為正常數據,不在這個范圍的數據為異常數據。
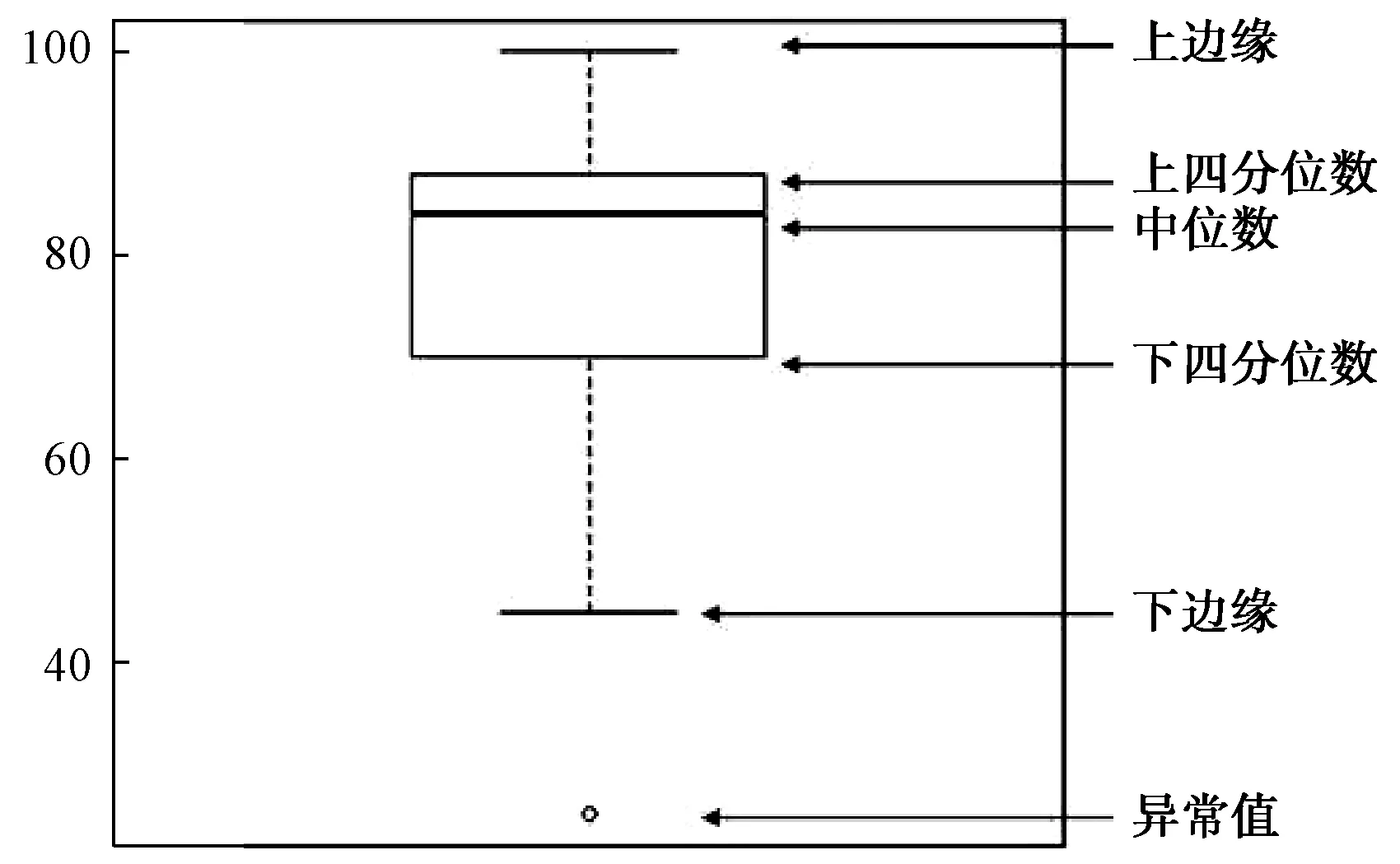
圖1 箱線圖說明Fig.1 Description of Boxplots
最小觀察值=1/4位數-1.5×(3/4位數-1/4位數)
(1)
最大觀察值=3/4位數+1.5×(3/4位數-1/4位數)
(2)
使用箱線圖分別對進水流量和進水渾濁度數據進行異常數據的篩分,如圖2所示,將數據按照每月分組,分析各自的數據范圍,對不在正常范圍的數據標記為異常數據直接刪除。如圖3所示,對聚合氯化鋁(PAC)和三氯化鐵(FeCl3)采用箱線圖篩分,如果PAC大于50,直接剔除該條數據,否則采用滑動均值替換異常值,FeCl3的異常數據采用滑動均值替換異常值的方法進行處理。對水溫、pH和機加池出水渾濁度數據也采用類似的方法進行處理。此外,對部分時間缺失字段較多的樣本直接刪除,對少量缺失數據使用均值、插值填充。
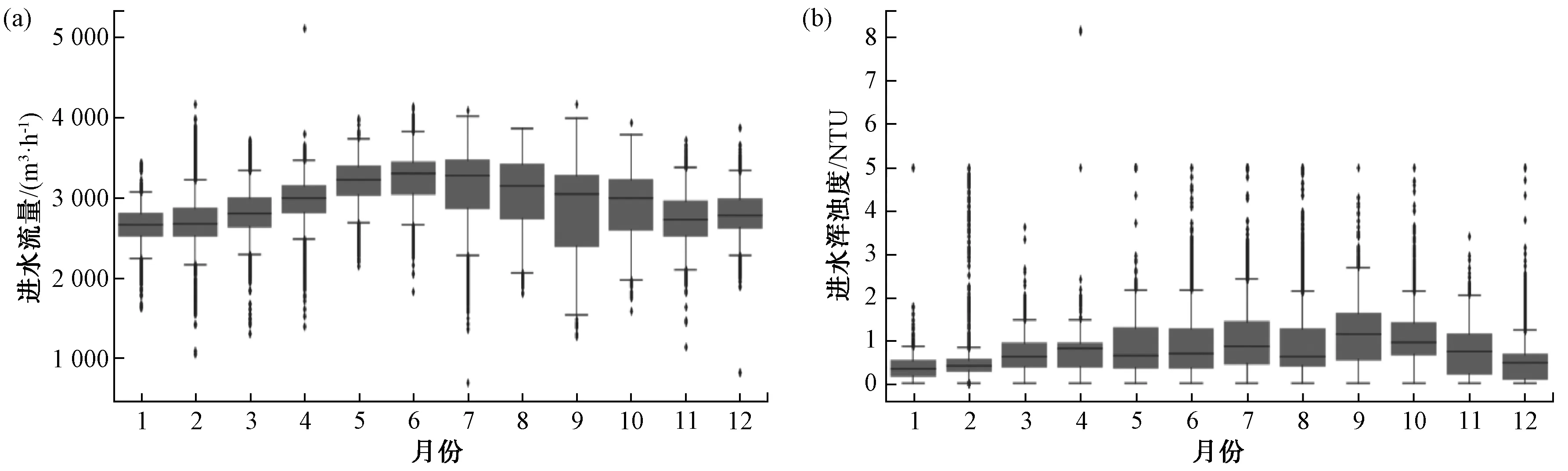
圖2 異常數據篩分 (a)進水流量;(b)進水渾濁度Fig.2 Screening of Abnormal Data (a) Inflow Rate; (b) Inflow Turbidity
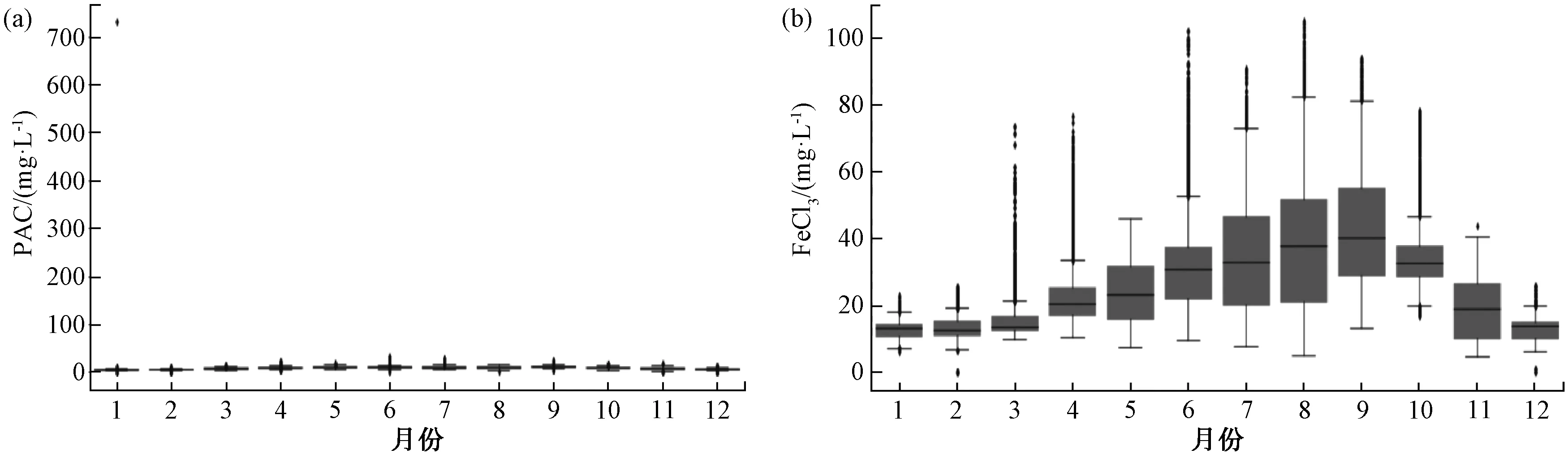
圖3 異常數據篩分 (a) PAC; (b) FeCl3Fig.3 Screening of Abnormal Data (a) PAC; (b) FeCl3
1.3 中試試驗裝置
將混凝投藥模型應用于中試全工藝流程試驗系統中(圖4)。全流程工藝系統設計產水量為1 m3/h,包括原水箱、進水泵、預臭氧接觸池、混凝反應池、斜管沉淀池、砂濾池、臭氧接觸池、碳濾池、清水箱等。該試驗系統配置全方位的在線水質分析設備,包括UV254、濁度儀、pH、余氯測定儀及臭氧濃度儀。在線儀表將數據傳輸給中控端PLC,PLC通過遠程模塊將水質參數和工藝運行參數遠傳到數據采集終端。采集的數據用于機器學習,最終一方面在混凝投藥管控平臺上展示,另一方面反饋輸出加藥指令。

圖4 中試工藝系統Fig.4 Pilot Test Process System
2 結果和討論
2.1 基于A水廠數據對不同算法的建模效果評估
2.1.1 水廠數據探索
要建立加藥量的模型,首先對水廠水質數據、工藝運行數據與加藥量的相關性做了探索。由于粗粒度數據類型較多,包括水廠日檢水質數據,如溫度、色度、渾濁度、溶解氧、電導率、氨氮、pH和余氯等;還包括工藝運行參數,如水量、預臭氧投加量、預氯化投加量、PAC投加量、FeCl3投加量等;此外,還包括機械加速澄清池的運行維護參數,如攪拌機轉速、排泥時長、沉降比。鑒于后續濾池是直接反饋機械加速澄清池運行效果的工藝,因而,濾池出水閥開度、反洗周期也需納入考慮范圍。由于粗粒度數據水質參數和工藝參數種類較多,為全面分析各種數據之間關系的權重,做了相關性矩陣。如圖5所示,以矩陣的形式展示各指標之間的相關性,絕對值越大,相關性越高,發現PAC、FeCl3投加量和進水溫度、渾濁度、預加氯、時均水量、排泥時長、濾池出水閥開度、月份和季節等相關性較大。因此,在建模過程中,應對相關水質指標和運行參數重點關注,作為特征值輸入。
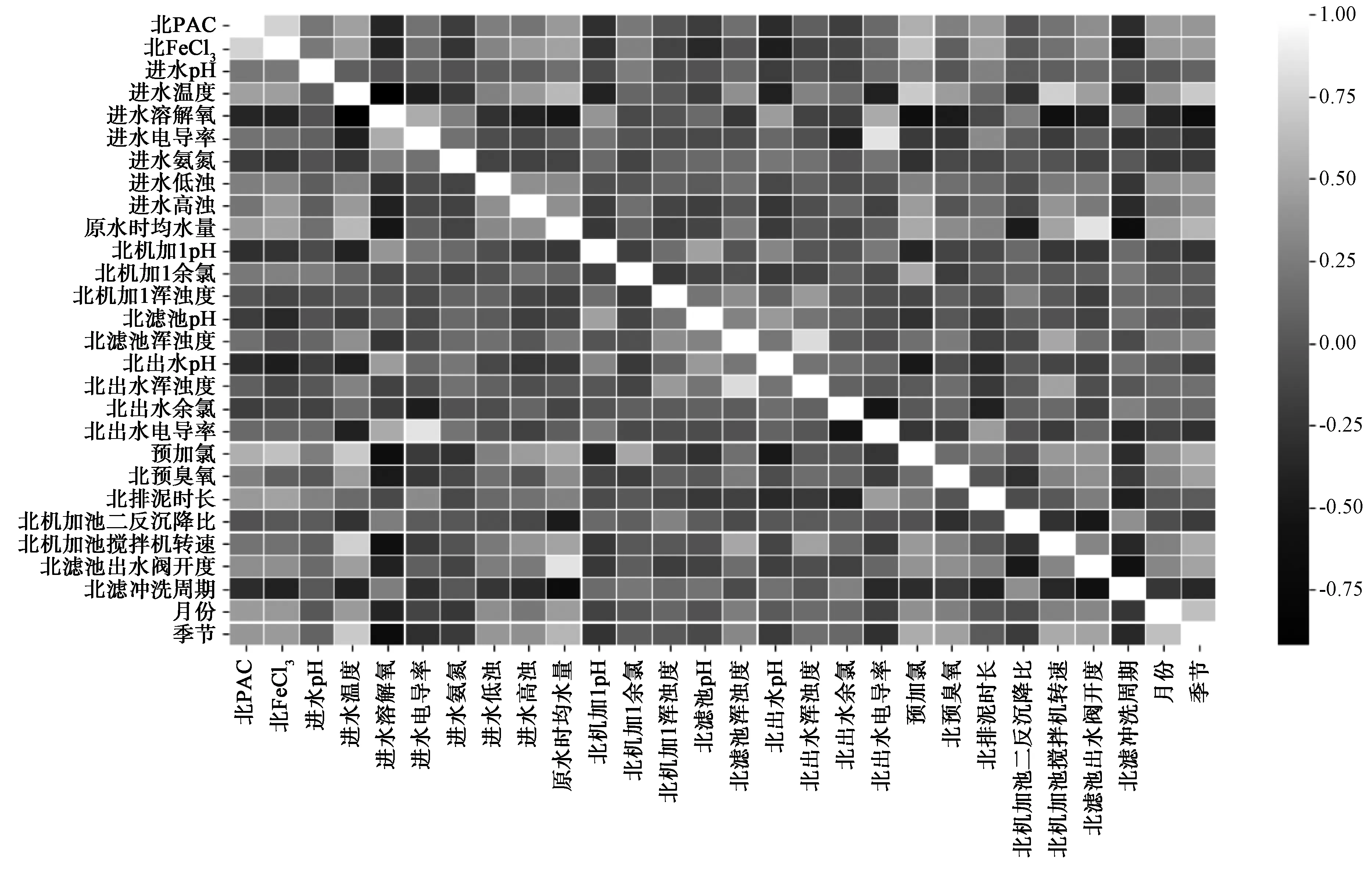
圖5 各指標參數間的相關性矩陣Fig.5 Correlation Matrix of Each Index Parameters
2.1.2 建模效果評估
水廠機械加速澄清池采用PAC和FeCl3雙藥投加的模式,因而,對PAC和FeCl3的投加量分別進行了模型構建。基于A水廠日檢的粗粒度數據對PAC的建模,分別嘗試采用了隨機森林、支持向量機、LSTM、XGBoost算法,各種算法輸入的特征具體為[‘原水渾濁度’, ‘炭池渾濁度差值’, ‘原水色度’, ‘原水pH’, ‘預加氯投加率’, ‘溫度區間’, ‘季節’, ‘預臭氧投加率’, ‘機加池渾濁度’, ‘炭池出水渾濁度’]。基于水廠日檢的粗粒度數據對FeCl3建模,分別嘗試采用了隨機森林、線性回歸、LSTM、XGBoost算法,各種算法輸入的特征具體為[‘原水渾濁度’, ‘機加池渾濁度差值’, ‘炭池渾濁度差值’, ‘原水色度’, ‘原水pH’, ‘預加氯投加率’, ‘原水溫度’, ‘季節’, ‘預臭氧投加率’, ‘機加池渾濁度’, ‘炭池出水渾濁度’]。
建模的精確性評估標準以平均絕對百分比誤差(MAPE)和平均絕對誤差(MAE)為指標,如式(3)~式(4),建模的目標是MAPE、MAE越小越好。結果如表1所示,對不同模型的評估值MAPE進行比較,發現采用XGBoost算法對PAC和FeCl3加藥量建立的預測模型均最優,其MAPE最小。因此,為進一步優化模型的準確度,需采用細粒度數據做進一步訓練模型。

表1 采用多種模型算法預測的評估值比較Tab.1 Comparison of Evaluation Predicted by Various Model Algorithms
(3)
(4)
其中:MAPE——平均絕對百分比誤差;
MAE——平均絕對誤差;
n——樣本數量;
yk——第k個樣本的實際值;

為進一步提高模型的預測精度,對A水廠采用以5 min為單位的細粒度數據進行建模。通過粗粒度建模,發現XGBoost算法建模效果最好,此外,LSTM在數據量比較大的情況其算法也具有一定的優勢。因此,基于A水廠細粒度數據對XGBoost算法和LSTM做了進一步的比較,同時,也比較了方案一和方案二兩種異常數據處理方法在建模效果上的差異(表2)。在細粒度數據支撐下,XGBoost較LSTM模型仍具有較大的優勢,評估效果較好。細粒度較粗粒度數據對建立模型的效果更好,如對PAC的MAPE評估值由粗粒度的15.99降到細粒度的8.87;采用基于滑動均值的異常數據識別技術(方案二)與常規異常數據處理方法(方案一)相比,MAPE進一步下降,對PAC的MAPE評估值由方案一的12.38降到8.87,說明模型預測的效果更好。
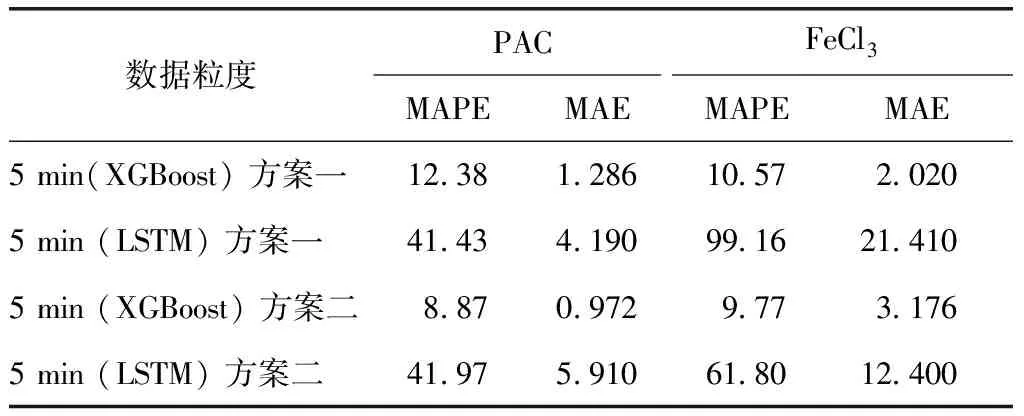
表2 不同粒度模型效果對比Tab.2 Comparison of Different Granularity Models
2.2 基于B水廠數據構建智能混凝投藥精準模型
2.2.1 PAC加藥模型的構建
為進一步提升模型的預測效果,將B水廠人工記錄和在線數據相結合,并采用箱線圖和移動平滑技術相結合的方法對數據進行預處理,提取到小時粒度的水量數據和加藥數據,最終以得到的近50萬條有效數據進行建模。對B水廠混凝劑投加量的建模分別采用XGBoost、LSTM和隨機森林算法進行了比較。模型輸入特征為[‘進水pH’, ‘進水溫度’, ‘進水流量’, ‘出水溫度’, ‘出水渾濁度’, ‘進水渾濁度’, ‘出水pH’, ‘最近1 d PAC投加量的均值’, ‘最近3 h PAC投加量的均值’, ‘月份’, ‘日期’],模型預測值為PAC投加量,其中,采用滑窗統計的方法獲得‘最近1 d PAC投加量的均值’和‘最近3 h PAC投加量的均值’。采用XGBoost建模預測結果如圖6所示,評估結果MAPE為3.42;采用LSTM建模預測結果如圖7所示,評估結果MAPE為8.50;采用隨機森林建模預測結果如圖8所示,評估結果MAPE為4.20。通過將隨機森林建模效果與XGBoost、LSTM做縱向比較,發現XGBoost預測效果最好,隨機森林次之,LSTM最差。
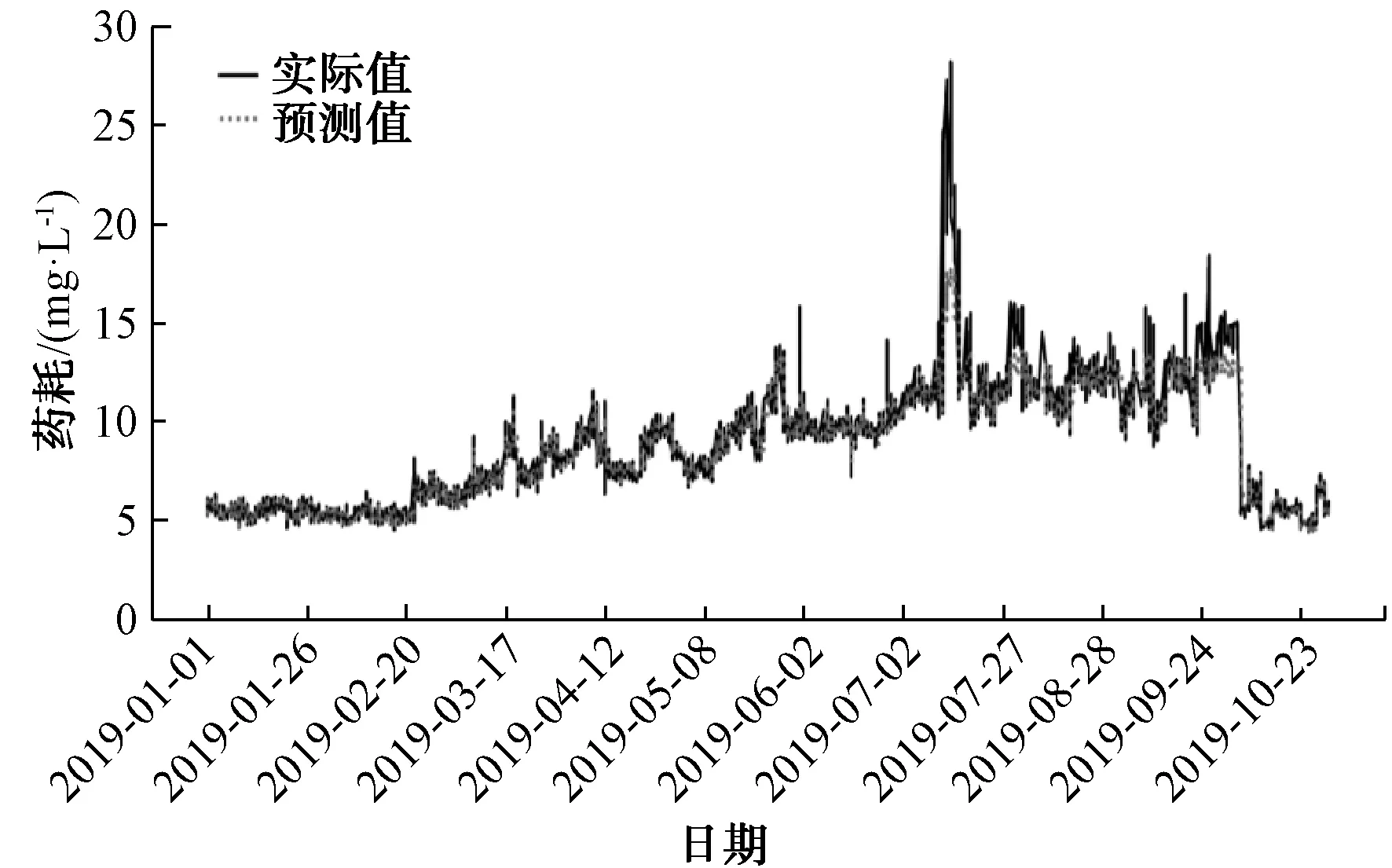
圖6 采用XGBoost對PAC的預測效果Fig.6 Application of XGBoost in PAC Prediction
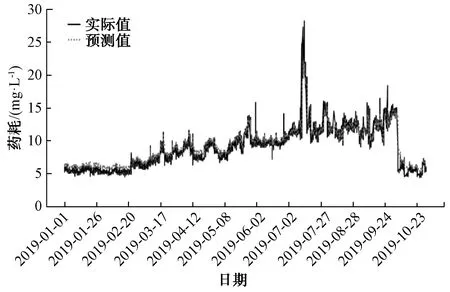
圖7 采用LSTM對PAC的預測效果Fig.7 Application of LSTM in PAC Prediction
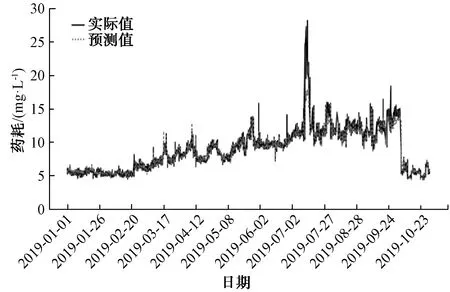
圖8 采用隨機森林對PAC的預測效果Fig.8 Application of Random Forest in PAC Prediction
2.2.2 FeCl3加藥模型的構建
對B水廠FeCl3投加量的建模同樣采用XGBoost、LSTM和隨機森林算法進行了比較。模型輸入特征[‘進水pH’, ‘進水溫度’, ‘進水流量’, ‘出水溫度’, ‘出水渾濁度’, ‘進水渾濁度’, ‘出水pH’, ‘最近1 d FeCl3投加量的均值’, ‘最近3 h FeCl3投加量的均值’, ‘月份’, ‘日期’],預測值為FeCl3投加量。采用XGBoost建模效果如圖9所示,評估結果MAPE為3.72;采用LSTM建模預測效果如圖10所示,評估結果MAPE為4.70;采用隨機森林建模預測效果如圖11所示,評估結果MAPE為5.09。通過將隨機森林建模效果與XGBoost、LSTM比較,發現對鐵鹽的預測與鋁鹽有差異,但均顯示XGBoost預測效果最好,不同的是LSTM次之,隨機森林效果最差。
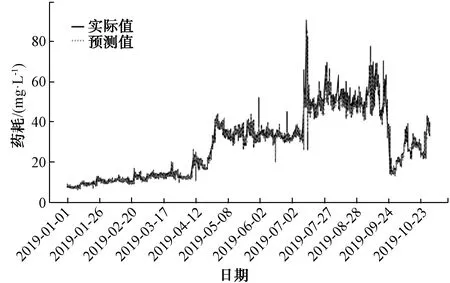
圖9 采用XGBoost對FeCl3的預測效果Fig.9 Application of XGBoost in Ferric Chloride Prediction
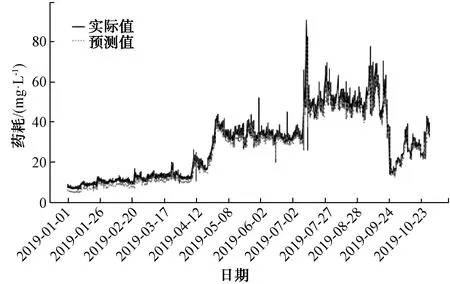
圖10 采用LSTM對FeCl3的預測效果Fig.10 Application of LSTM in Ferric Chloride Prediction
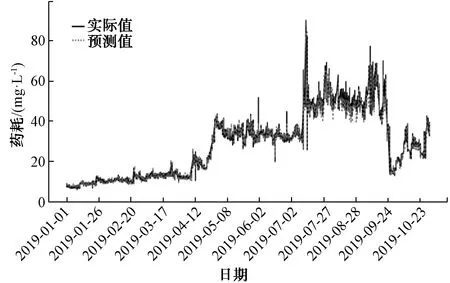
圖11 采用隨機森林對FeCl3的預測效果Fig.11 Application of Random Forest in Ferric Chloride Predicion
同時,B水廠較A水廠混凝劑投加量變化更頻繁,且提取到了小時粒度的水量、加藥數據,模型預測的準確性更高。在異常數據處理方面,使用了箱線圖的異常數據識別方法,構建了基于滑動窗口的加藥歷史數據統計特征,模型效果大幅提升。如對A水廠采用XGBoost對PAC投加量建模,最優情況下的MAPE評估值為8.87;而對B水廠采用XGBoost對PAC投加量建模,最優情況下的MAPE評估值僅為3.42,明顯低于8.87,可見對模型的效果提升明顯。
2.2.3 雙藥投加的模型構建方法
由2.2可知,采用XGBoost、LSTM和隨機森林3種算法對混凝劑投加量分別建模,效果最優的是XGBoost算法,因此,雙藥投加的建模方法仍采用XGBoost。對雙藥投加的建模方法嘗試采用PAC的預測效果作為FeCl3的輸入,即首先預測PAC,預測結果作為特征輸入FeCl3預測模型。FeCl3模型輸入的特征值為 [‘進水PH’, ‘進水溫度’, ‘進水流量’, ‘出水溫度’, ‘出水渾濁度’, ‘進水渾濁度’, ‘出水pH’, ‘每d FeCl3投加量的均值’, ‘每3 h FeCl3投加量的均值’,‘PAC預測’, ‘月份’, ‘日期’],預測值為FeCl3投加量。采用XGBoost建模預測結果如圖12所示,評估結果MAPE為3.70。采用FeCl3的預測效果作為PAC的輸入,即首先預測FeCl3,預測結果作為特征輸入PAC預測模型。PAC模型輸入的特征值為[‘進水PH’,‘進水溫度’,‘進水流量’,‘出水溫度’,‘出水渾濁度’,‘進水渾濁度’,‘出水pH’, ‘每d PAC投加量的均值’, ‘每3 h PAC投加量的均值’,‘FeCl3預測’,‘月份’,‘日期’],預測值為PAC投加量。采用XGBoost建模預測結果如圖13所示,評估結果MAPE為3.39。
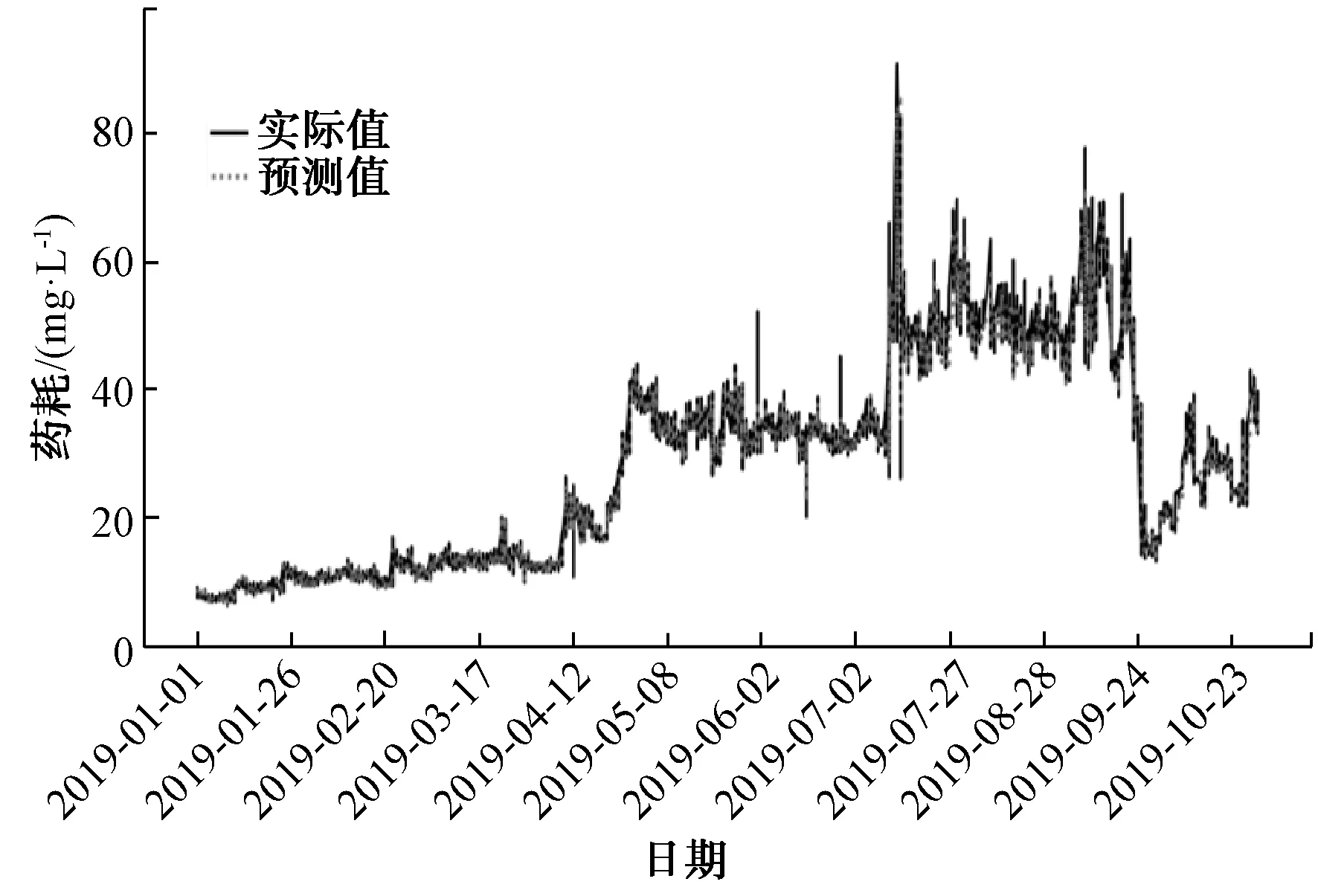
圖12 采用XGBoost對FeCl3的預測效果Fig.12 Appliction of XGBoost in Ferric Chloride Prediction
圖13 采用XGBoost對PAC的預測效果Fig.13 Appliction of XGBoost in PAC Prediction
對于雙藥投加,通過將一種藥劑的投加量作為另一種藥劑預測的特征值輸入,與前述各自單獨預測藥劑投加量相比,模型的預測效果略有提升。
2.3 智能混凝投藥模型的應用
為驗證模型的預測效果,將采用XGBoost算法建立的混凝投藥模型應用于中試系統,對模型的預測加藥量與實際加藥量進行了效果比對。如表3所示,通過5組數據比較了不同投藥量下出水渾濁度、UV254的變化情況,每組數據中包括當天模型預測加藥下出水水質與人工加藥下出水水質,水質數據均為當前投藥量下運行穩定后1 h在線數據(在線數據采集間隔以min計)的平均值。與人工投藥相比,采用模型預測投藥時,沉淀池與砂濾池出水渾濁度均有不同程度的降低,但對UV254的去除未見差異。將人工投加和模型預測加藥量進行藥耗對比,以兩種投藥量下分別運行24 h計,模型預測加藥的情況下PAC、FeCl3分別需要3.24、1.09 kg;而人工加藥的情況下PAC、FeCl3分別需要3.38、2.13 kg,說明采用模型預測加藥能有效節省藥劑消耗。
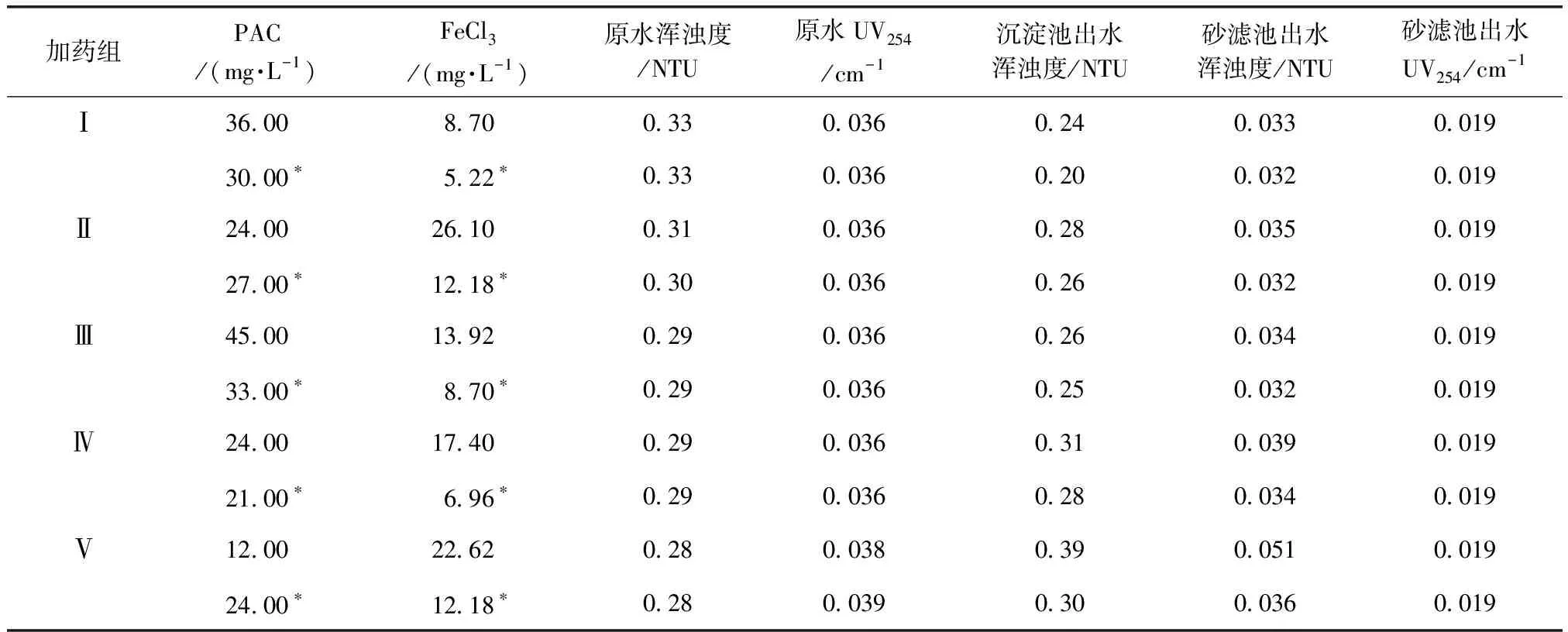
表3 兩種加藥方式下的水質對比Tab.3 Comparison of Water Quality between Two Dosing Methods
3 結論與建議
1)與隨機森林、LSTM、支持向量機等算法相比,基于南水北調水源的水質特征,采用XGBoost算法構建混凝投藥模型效果最優,其構建的PAC模型MAPE評估值為3.39,FeCl3模型MAPE評估值為3.89。將混凝投藥模型應用于中試工藝系統,提升出水水質的同時降低了藥耗。
2)數據采集是構建水廠智能投藥模型的基礎,原水時均水量、渾濁度、溫度、歷史加藥數據的精細統計對混凝劑投加量的準確預測有重要影響。
3)使用箱線圖結合移動平滑的技術進行異常值的處理,小時粒度的水量、加藥數據結合在線水質數據對混凝投藥模型的構建有大幅的提升。將一種藥劑的投加量作為另一種藥劑預測的特征值輸入的方法,對雙藥投加模型的預測效果提升有限。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年8期)2016-10-09 02:11:50
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫藥科學(2015年19期)2015-02-27 12:33:11
