基于互信息的多塊k 近鄰故障監測及診斷
2021-09-11 03:13:34鄭靜熊偉麗
智能系統學報 2021年4期
鄭靜,熊偉麗
(1.江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122;2.江南大學 物聯網工程學院,江蘇 無錫 214122)
隨著新型傳感器、數據采集設備和系統的迅速發展,一些先進工業過程積累了豐富的過程數據,使得多元統計過程監控(multivariate statistical process monitoring,MSPM)技術不斷進步[1-3]。其中的主成分分析(principal component analysis,PCA)和k近鄰方法(k-nearest neighbor,kNN)是較為基礎的方法,得到了大量的研究和應用[4-7]。
作為一種降維技術,PCA 通過將數據投影到低維空間以有效地處理高維和線性相關的數據,通過建立主元子空間和殘差子空間的統計量進行過程監控。但是,對于具有非線性和非高斯特性的過程數據,PCA 方法可能無法進行有效的監測。He 等[8]提出基于k近鄰規則的故障監測算法,該算法不局限于線性和高斯數據,使用局部近鄰距離度量樣本相似度,根據故障樣本和正常樣本的相似度不同實現故障監測。但是由于每一個樣本都需要計算與其他樣本的距離,計算量明顯增大。為此,學者們提出了許多改進的kNN 故障監測算法。例如:文獻[9]利用改進K-means 聚類將原始建模數據分成多個類,對每個類分別建立kNN 監測模型,大大縮短故障檢測時間;文獻[10]提出將動態PCA 和kNN 相結合的故障診斷方法,先建立主元模型,再利用kNN 獲取樣本的k個近鄰,明顯提高了故障的報警率;文獻[11]針對kNN模型不能及時更新的問題,提出了一種特征空間自適應k近鄰故障檢測方法,有效提高模型實時監測的能力;文獻[12]考慮到多模態過程數據具有多中心、方差差異大等特點,通過構造標準距離,實現了kNN 方法對多模態數據的有效監測。
由于現代工業過程具有多個操作單元、變量關系復雜等特點,全局建模策略無法更加準確地對過程建模,多塊建模策略成為有效的解決方案。Macgrego 等[13]首次提出了多塊投影方法,為每個子塊以及整個過程建立監測模型。文獻[14]采用Jarque-Bera(J-B)檢測方法并利用變量間的Hellinger 距離獲得高斯和非高斯子塊,然后分別采用不同的方法進行建模,并對每個子塊的統計量進行加權得到總的聯合指標實現在線監控;文獻[15]將整個過程劃分成多個子塊單元,然后在每個子塊單元內分別進行相對變換獨立主元分析處理,實現故障排查和識別;Ge 等[16]提出分布式PCA的全流程過程監控方法,利用過程變量在主元方向上的貢獻度劃分子塊,有效地提高了監控效果。
在信息論領域里,互信息(mutual information,MI)是一種相對成熟的統計分析技術,可以通過信息熵度量兩個隨機變量之間的依賴性,并且這種度量不局限于數據線性關系的假設條件[17-19],已經在數據分析與建模領域得到了比較多的應用。文獻[20]利用變量間的互信息定義數據的相關性矩陣,為過程數據建立更為精確的描述模型。文獻[21]利用互信息矩陣之和替代傳統主成分分析中的協方差矩陣,計算其特征向量與特征值,得到較主成分分析更好的降維效果。文獻[22]利用高維k 近鄰互信息方法,有效解決建模過程中的特征選擇問題。
綜上所述,為了更加充分地對復雜過程變量之間的關系進行描述,并提取過程的局部特征,利用多塊建模策略,提出一種基于互信息的k 近鄰故障監測算法。該算法在計算訓練集樣本間的互信息基礎上,根據互信息值的大小將變量分成多個子塊,對每個子塊建立相應的kNN 模型,并利用核密度估計方法求出控制限,最后利用貝葉斯推斷將各子塊的監測結果融合,使得整體的監測效果更為直觀。本文進一步采用基于馬氏距離的故障診斷方法,通過計算樣本中各變量與其均值的馬氏距離,找出引發故障的源變量并對其隔離。利用田納西?斯曼(Tennessee Eastmann,TE)和實際高爐煉鐵過程數據,對所提方法進行了仿真,并與幾種傳統監測方法進行了對比,驗證了本文方法的性能。
1 相關算法介紹
1.1 kNN 算法
k近鄰算法是數據挖掘和數據分類中最常用的方法之一,傳統kNN 算法通過尋找k個近鄰樣本,采用投票的方法確定待測樣本的類別。基于kNN 的故障監測,其基本思想是通過計算近鄰距離度量樣本間的相似度,若樣本點與訓練集中前k個近鄰樣本距離的平方和大于正常樣本的相應距離平方和,則該樣本點被定義為故障點。監測過程包括模型建立和故障檢測兩步,具體描述如下:
1)建立模型
首先在訓練集中,尋找每個樣本xi的前k個近鄰樣本,記做其中,表示樣本xi的第j個近鄰樣本。然后,計算每個樣本xi與其k個近鄰樣本的歐式距離平方和作為統計量,如式(1)所示,其中,表示樣本xi與它的第j個近鄰樣本的歐氏距離平方。接著,根據置信度α確定訓練模型的控制限
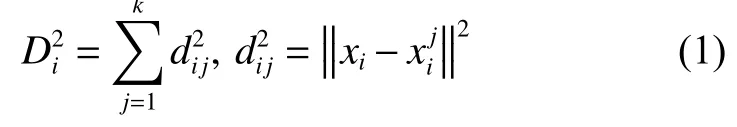
首先,在訓練集中尋找待測樣本x的前k個近鄰。然后,計算x與其k個近鄰樣本的歐式距離平方和,記做最后,比較的大小,若則判定為故障點,反之為正常點。
1.2 互信息
在概率論和信息論領域,互信息是一種非常實用的信息度量方法。它可以度量兩個隨機變量相互依賴的程度,表示出兩個變量共享的信息,反映兩個變量的相關性[21],這種度量同樣適用于非線性相關的變量。對于密切相關的變量,它們擁有較大的互信息。令隨機變量X和Y的聯合概率分布及邊緣概率分布分別為p(x,y)、p(x) 和p(y),其中x∈X,y∈Y,X的熵定義如式(2)所示。
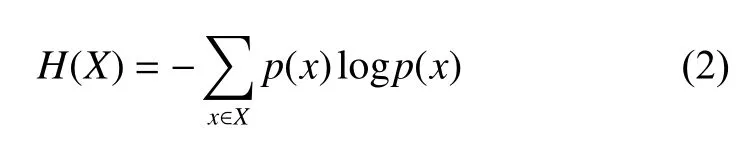
聯合熵為
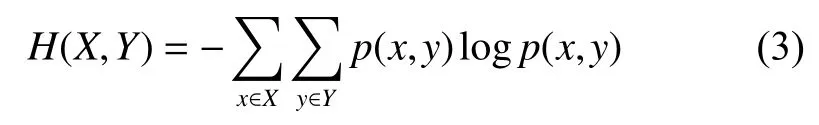
則變量X和Y之間的互信息可以定義為
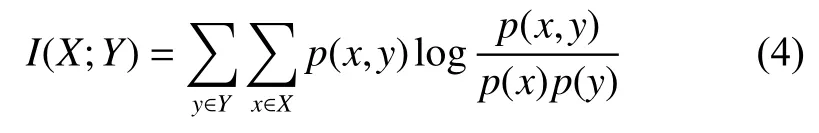
若X和Y相互獨立,則X不對Y提供任何信息,此時互信息值最小,結果為0。反之,兩個變量間的相關性越高,互信息值越大。
2 基于互信息的多塊建模kNN 故障監測及診斷
2.1 基于互信息的分塊策略
在實際的工業過程中,變量之間大多是線性、非線性共存,高斯、非高斯混合分布,傳統的PCA 與kNN 方法往往從全局的角度出發,系統的本質特征無法得到充分的展示。因此,首先對變量進行MI 計算,將互信息大的多個變量放在一起組成子塊,使得子塊內的變量擁有更多相同的信息,最大化地反映變量的一個或者多個局部特征,同時也大大降低了監控過程的復雜度,從而有效地提高系統的監控效果。
對于訓練集X∈Rn×m,xi∈X,xj∈X,計算變量xi與變量xj之間的互信息Iij,即
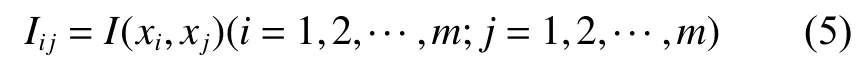
若Iij≥Ii,l,則把變量xj與變量xi放到相同的子塊中。Ii,l一般根據經驗獲得,本文結合互信息針狀圖為了更好地劃分變量,Ii,l取 1.3IiM,其中IiM是Iij的中值。本文所采用的多塊建模方法如圖1所示。
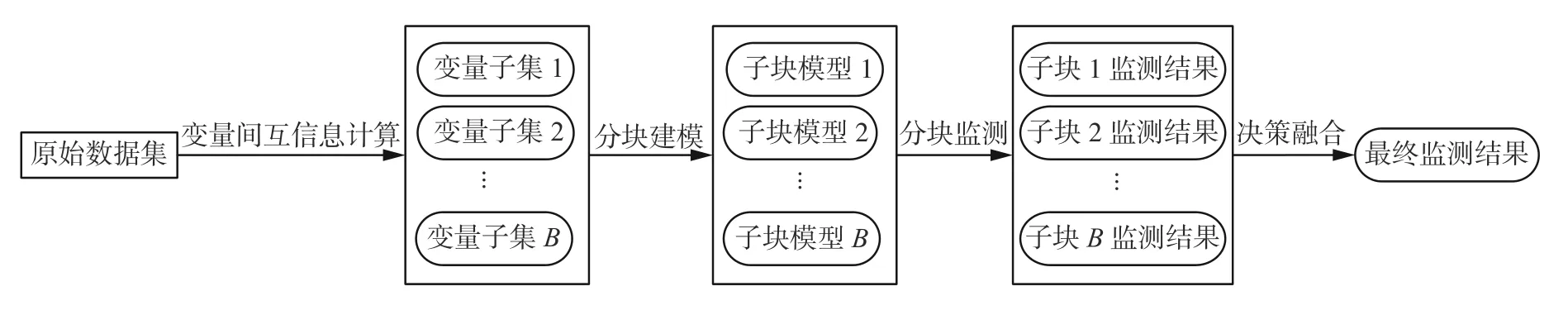
圖1 本文所采用的多塊建模方法Fig.1 Multi-block modeling method in this paper
2.2 故障監測及診斷
針對劃分好的子塊,建立kNN 監測模型。尋找各子塊中樣本的k近鄰樣本集,記做其中xib表示第b個子塊中的變量表示樣本xib的第k個近鄰樣本。
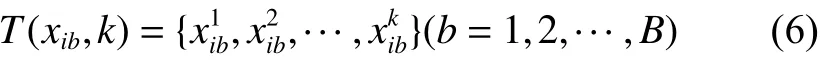
然后計算每個子塊中樣本與其k近鄰樣本的歐式距離平方和作為子塊統計量,即其中表示第b個子塊的統計量。
通過核密度估計法(kernel density estimation,KDE)估計每個統計量的概率密度,再繪制累加概率密度圖,根據置信度確定每個塊中統計量的控制限。由于子塊數目較多且產生多個監測結果,無法得到一個直觀的最終決策,因此,采用貝葉斯融合策略[23],將正常事件和故障事件與貝葉斯推斷相結合,從概率的角度將所有子塊的統計量組合成一個新的統計量來得到最終的監測結果。
在貝葉斯推斷(bayesian inference,BI)中,測試樣本xtest在第b個子塊中的D2統計量的故障條件概率可以表示為
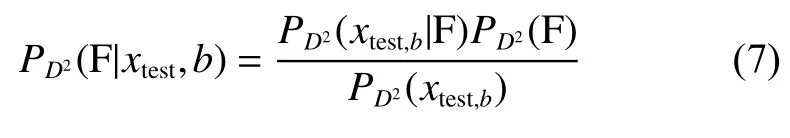
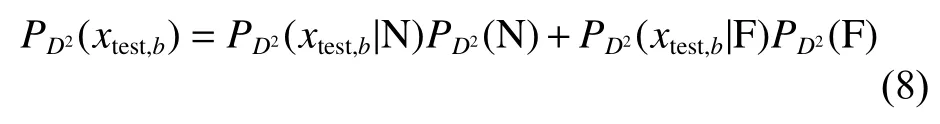
式中:xtest,b表示第b個子塊中的測試樣本。條件概率可定義如式(9)所示。
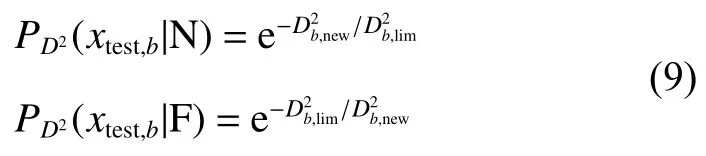
其中,“N”和“F”分別代表“normal”和“fault”,即正常樣本和故障樣本。為正常樣本的先驗概率,由置信度 α 決定,則為為新樣本在第b個子塊中的統計量是第b個子塊中由核密度估計方法估計得出的統計量的控制限。最終,融合的BIC 統計量即為待測樣本發生故障的概率,如式(10)所示。

BIC 統計量的控制限由1?α確定(本文α 取0.01),當BIC 的值大于1?α 時,判斷發生故障;否則,過程正常。
當檢測到故障后,需要找出引發故障的源變量并對其進行分離。計算數據樣本中各變量與其均值的馬氏距離[17],即加權計算數據樣本中各變量相較于其均值的偏移量,偏移量越大,說明該變量對于故障貢獻越大。該方法可以有效辨識引發故障的源變量,即發生故障的根本原因。
2.3 基于MI-MBkNN 故障監測算法流程
基于互信息的多塊kNN 故障監測算法流程如圖2 所示,具體步驟描述如下。

圖2 基于MI-MBkNN 的故障監測流程Fig.2 Fault monitoring flowchart based on MI-MBkNN
1) 獲取正常訓練數據,并對其進行標準化處理;
2) 計算兩兩變量間互信息,根據2.1 節所述方法對變量進行分塊,得到各個子塊;
3) 對每個子塊分別建立kNN 模型,利用核密度估計方法確定各自的故障控制限;
4) 對于新來的測試樣本,同樣對其進行標準化處理和分塊處理;
5) 對每個子塊進行kNN 故障監測,獲得每個子塊的監測結果;
6) 通過貝葉斯推斷方法,利用式(10)將各個子塊的統計量組合成為一個新的BIC 統計量,并根據置信度確定控制限,當BIC 超過控制限時則判斷發生了故障,否則正常;
7) 監測到故障后計算數據樣本中各變量與其均值的馬氏距離,確定故障變量及故障塊,分離出對故障影響最大的變量。
3 仿真實驗
3.1 TE 過程仿真
TE 仿真平臺是基于實際工業過程的仿真平臺,它由反應器、冷凝器、壓縮機、分離器和汽提塔5 個主要操作單元組成[24-25]。該過程包含的變量數目多,且變量與變量之間的關系復雜。主要分為12 個操作變量,41 個測量變量,21 個預設定的故障。本文選取22 個過程測量變量和11 個操作變量(不包括攪動速度)用于監測方法建模和監測性能測試,具體變量描述見文獻[16]。對于每種故障,訓練集用于訓練建立模型,測試集用來檢驗模型監測性能。訓練集和測試集均采用960個樣本,測試集中故障從第161 個樣本點引入。
為了建立多塊模型,對選取的過程變量和操作變量進行互信息的計算并進行分塊,分塊結果如表1 所示。圖3 分別展示了變量18、變量19、變量31 與其他32 個變量間的互信息,圖中的虛線表示為1.3 倍互信息中值,互信息超過虛線的變量即為與該變量具有較大互信息的變量。因此將變量18、變量19 和變量31 放到相同的子塊中。圖4 分別展示了變量10、變量17、變量28、變量33 與其他32 個變量間的互信息,因此將它們組成一個子塊。
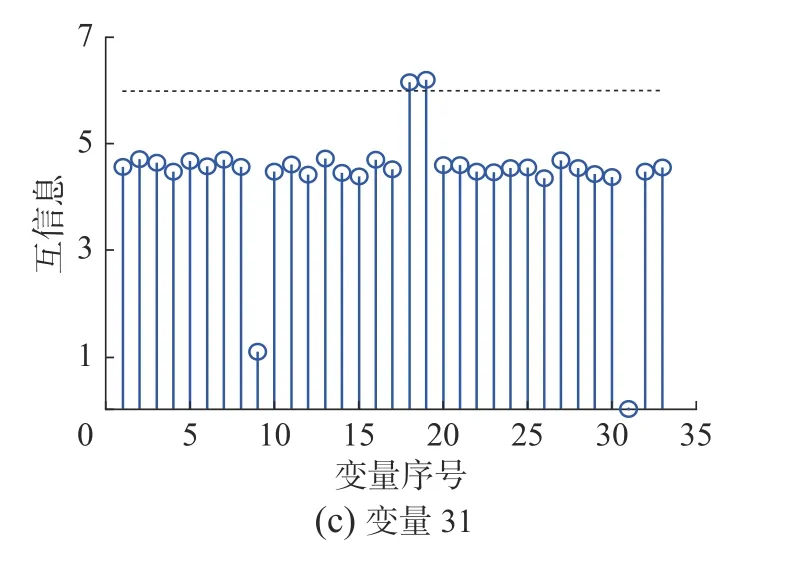
圖3 子塊4 中各變量間的互信息Fig.3 Mutual information between variables in block 4
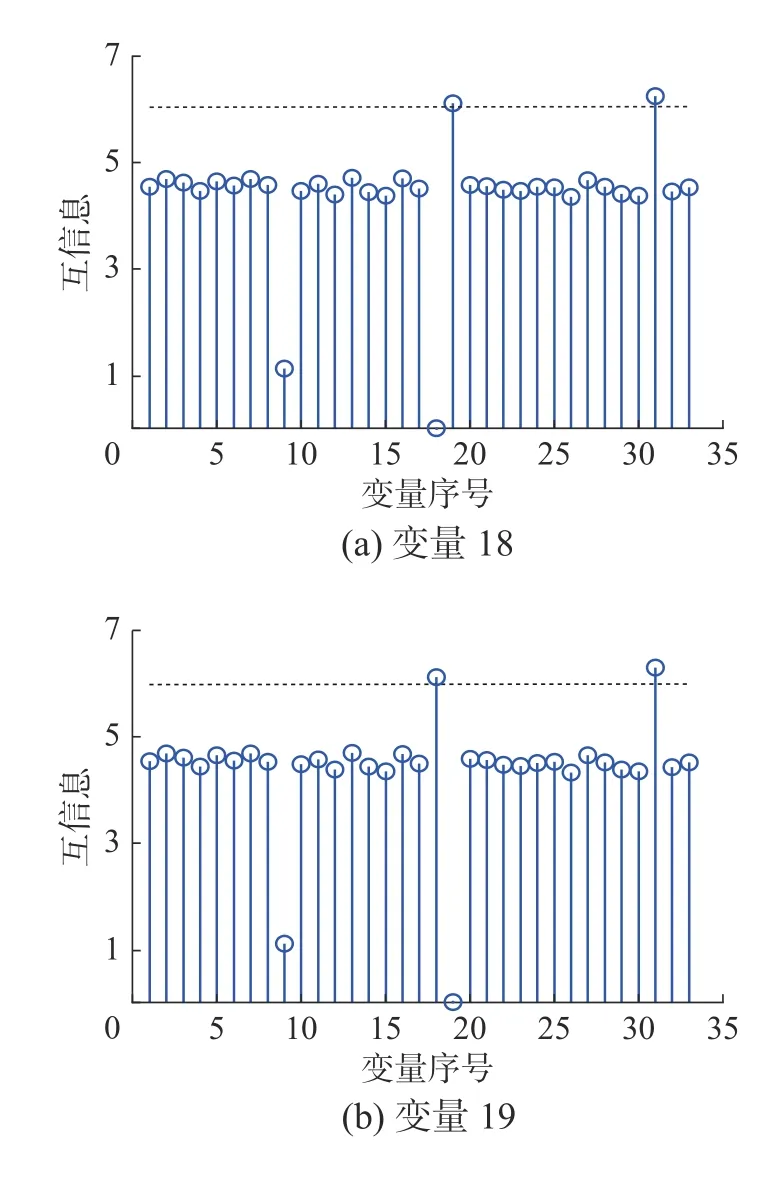
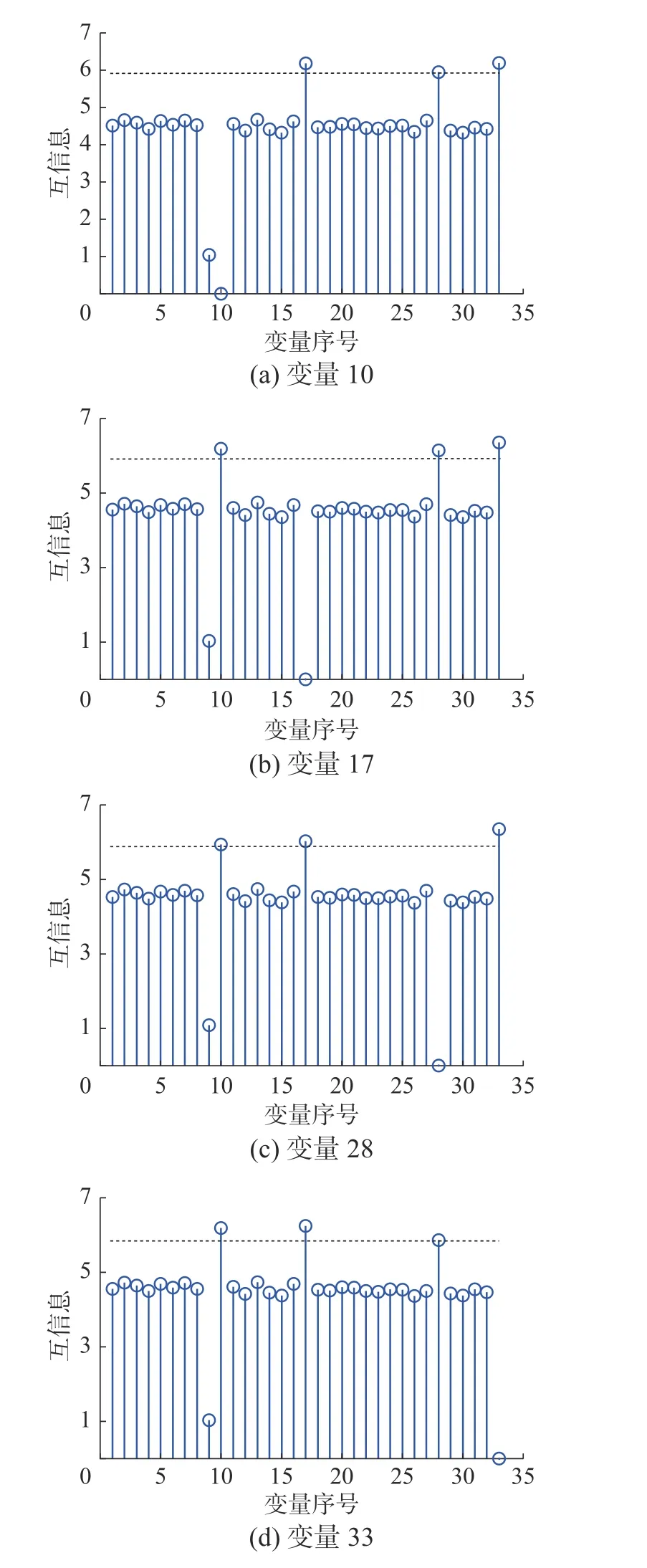
圖4 子塊5 中各變量間的互信息Fig.4 Mutual information between variables in block 5

表1 TE 過程子塊的劃分Table 1 Blocks division in the TE process
表2 給出了7 個子塊對21 種故障的報警率、平均報警率和平均誤報率。從報警率來看,對于大多數故障類型,子塊7 的監測結果要優于其他6 個子塊。子塊5 的平均報警率很低,但是對于某些故障(如故障5),子塊5 的報警率達96%,對整個的監測起到了關鍵的作用。對于不同的故障,由于某些子塊擁有較高的報警率和較低的誤報率,使得最終融合的BIC 統計量表現了良好的監測性能。從對21 種故障的監測結果來看,對于大部分故障,融合后的監測性能有了明顯的提高。
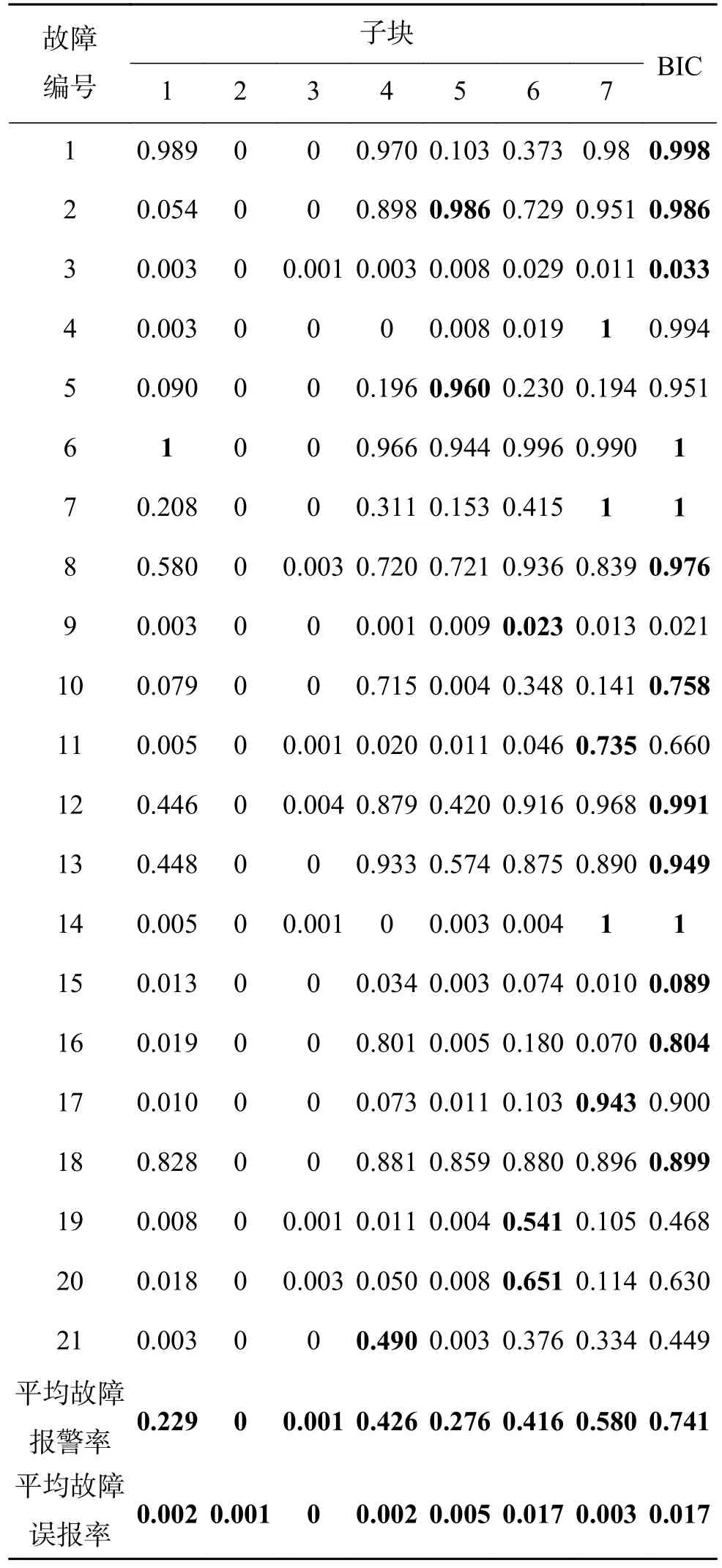
表2 TE 過程各故障報警率Table 2 Alarm rates of TE process
表3 給出了TE 過程21 種故障在不同監測方法下的報警率和誤報率,主要方法包括傳統PCA、SVDD、kNN 和本文提出的MI-MBkNN。從仿真結果可以看出,對于絕大多數故障類型,MIMBkNN 能取得優越于其他3 種方法的監測結果,尤其是對故障5、故障10、故障 16、故障 19 的監測。圖5 以故障5 為例展示了詳細的監測過程與結果。
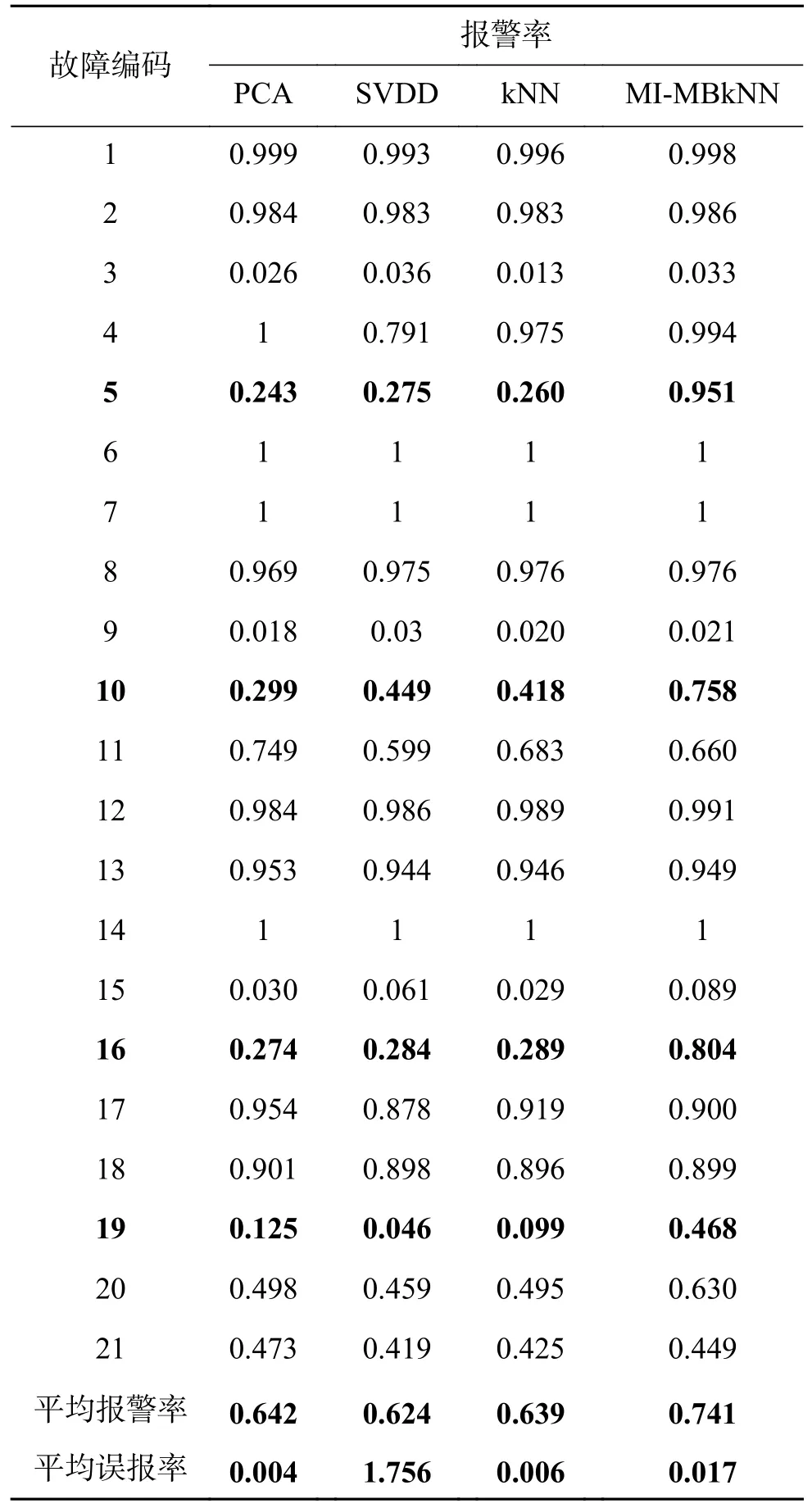
表3 幾種現有的監測方法性能比較Table 3 Comparison of some state of monitoring methods
TE 過程中的故障5 涉及冷凝器冷卻水入口溫度的變化,當故障發生時,從冷凝器到氣/液分離器的出口流量增加,使溫度升高。使用傳統PCA、kNN、SVDD 方法和本文提出的MI-MBkNN 的監測結果如圖5 所示。從圖5(a)~(d)可以發現,在故障開始時就可以檢測出故障,但是在大約350 個樣本的時候,統計量出現低于控制限的情況,導致故障的漏報。由于該故障是局部故障,因此很難在全局模型中檢測到,為了更好地找出故障的原因,圖6 給出了數據樣本在第161個樣本點(故障最開始處)的各變量與其均值中心的馬氏距離。

圖5 故障5 監測結果Fig.5 Monitoring result of fault 5
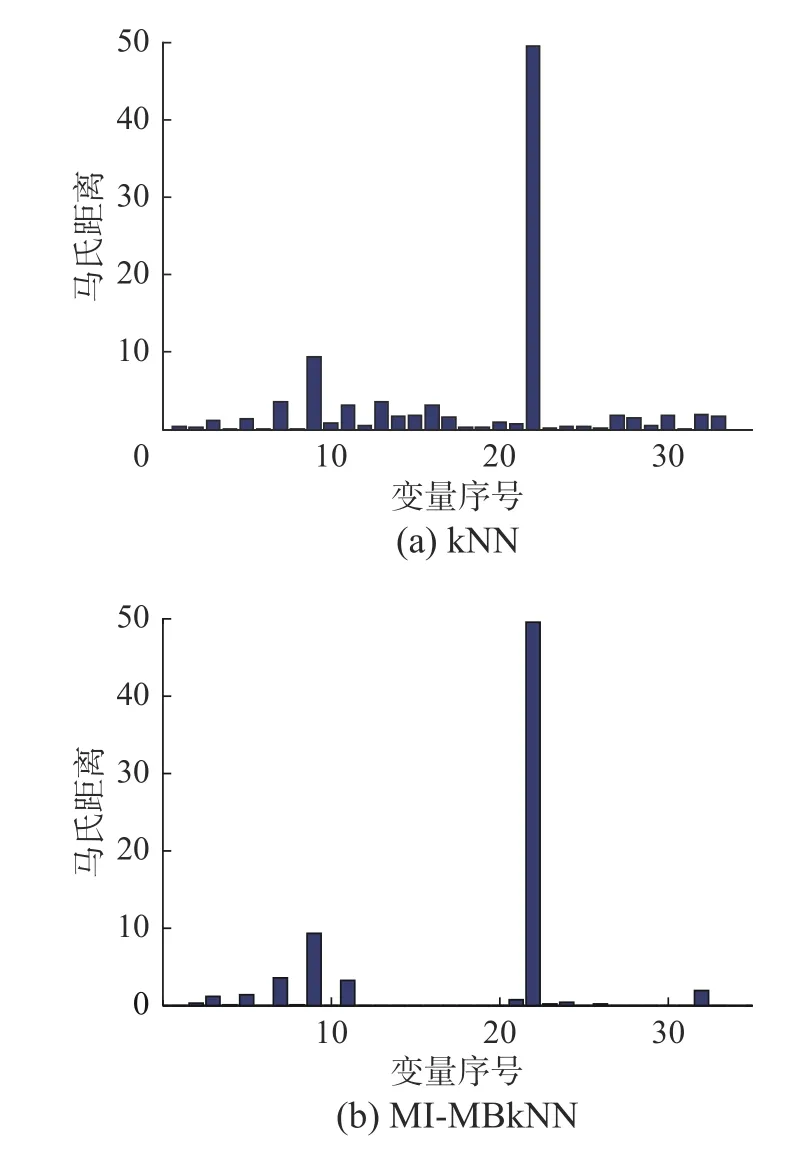
圖6 第161 樣本點故障5 的變量識別結果Fig.6 Variables identification results of fault 5 on the 161th point
可以看出這兩個模型都能正確識別變量在過程中的變化,如分離器冷卻水出口溫度的變化(變量22),反應器溫度(變量9),產品分離器溫度(變量11)和反應器冷卻水流量(變量32)。但是在350 個樣本點后,從圖7(第400 個樣本點)可以看出,kNN 無法識別出冷凝器冷卻水流量的變化(變量33),但是MI-MBkNN 模型可以成功識別,因此MI-MBkNN 對故障5 表現出了優越的監測效果。
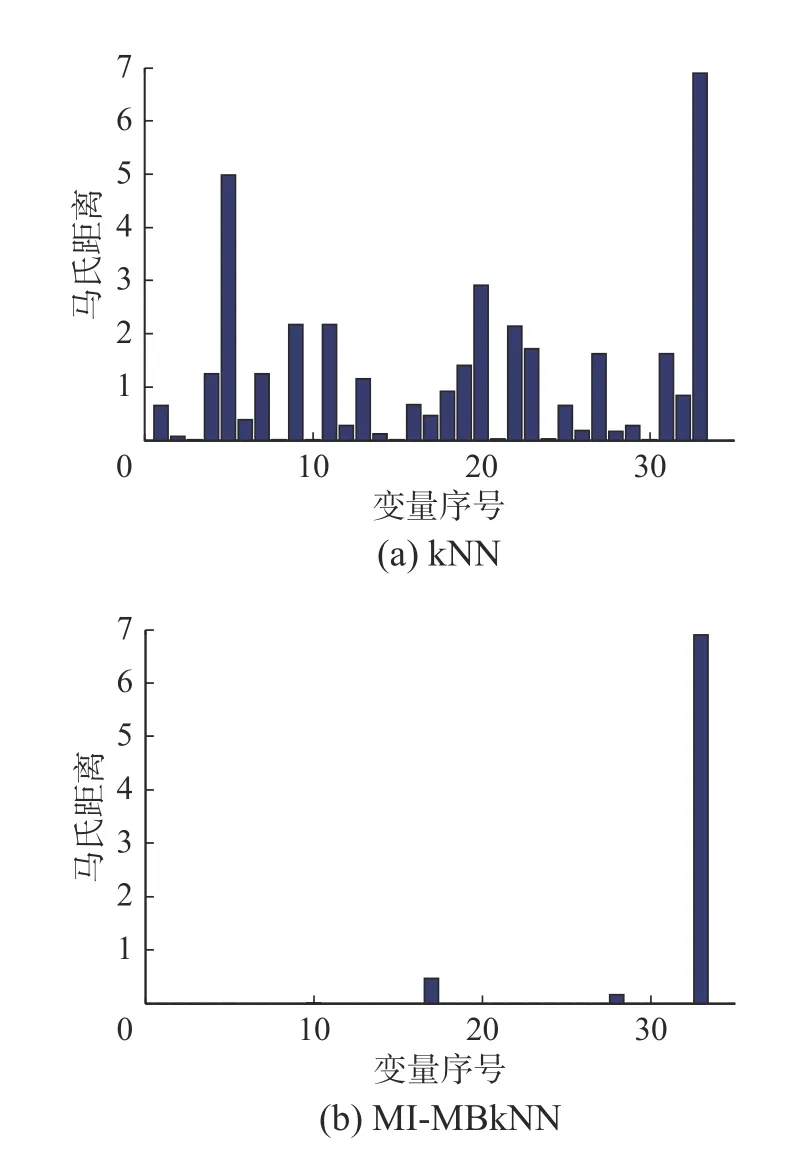
圖7 第400 樣本點故障5 的變量識別結果Fig.7 Variables identification results of fault 5 on the 400th point
故障10 是流2(C 進料) 中溫度的隨機變化,從圖8 中可以看出350~650 樣本,傳統的監測方法很難監測到故障,但是MI-MBkNN 卻能很好地檢測出來。
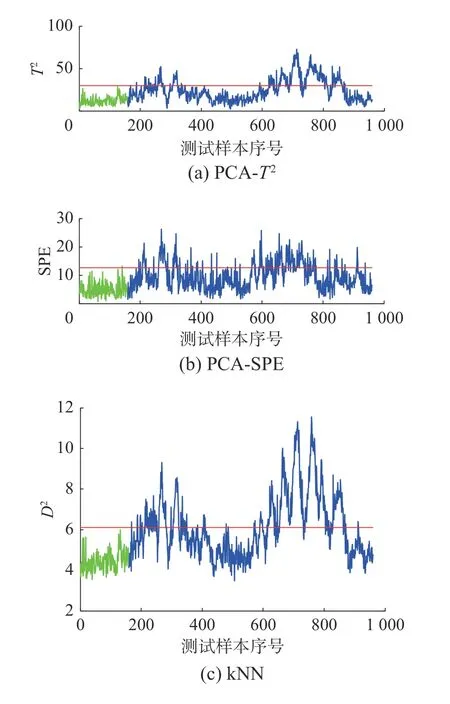

圖8 故障10 監測結果Fig.8 Monitoring result of fault 10
為了更好地找出引發故障的源變量,圖9(a)和(b)分別給出了使用kNN 和MI-MBkNN 方法時數據樣本在第400 樣本點處的各變量與其均值中心的馬氏距離,可以發現MI-MBkNN 在尋找故障源變量方面提供更重要的指導,即汽提塔溫度(變量18),汽提塔蒸汽流量(變量19),汽提塔蒸汽閥的變量(變量31)是引起故障10 的原因,因此子塊4 的監測效果明顯優于其他子塊。通過貝葉斯融合后,使得整體的監測效果得到了很高的提升。因此本文提出的方法對故障10 的監測效果優于其他幾種傳統的監測方法。圖10 對比了PCA、kNN、本文方法的子塊4 和MI-MBkNN 的對故障16 的監測結果,傳統kNN 方法在統計量上只能從450~500 樣本和790~840 樣本之間做到相對持續的報警,而本文監測方法從故障引入點處開始就能做到大范圍的持續報警。
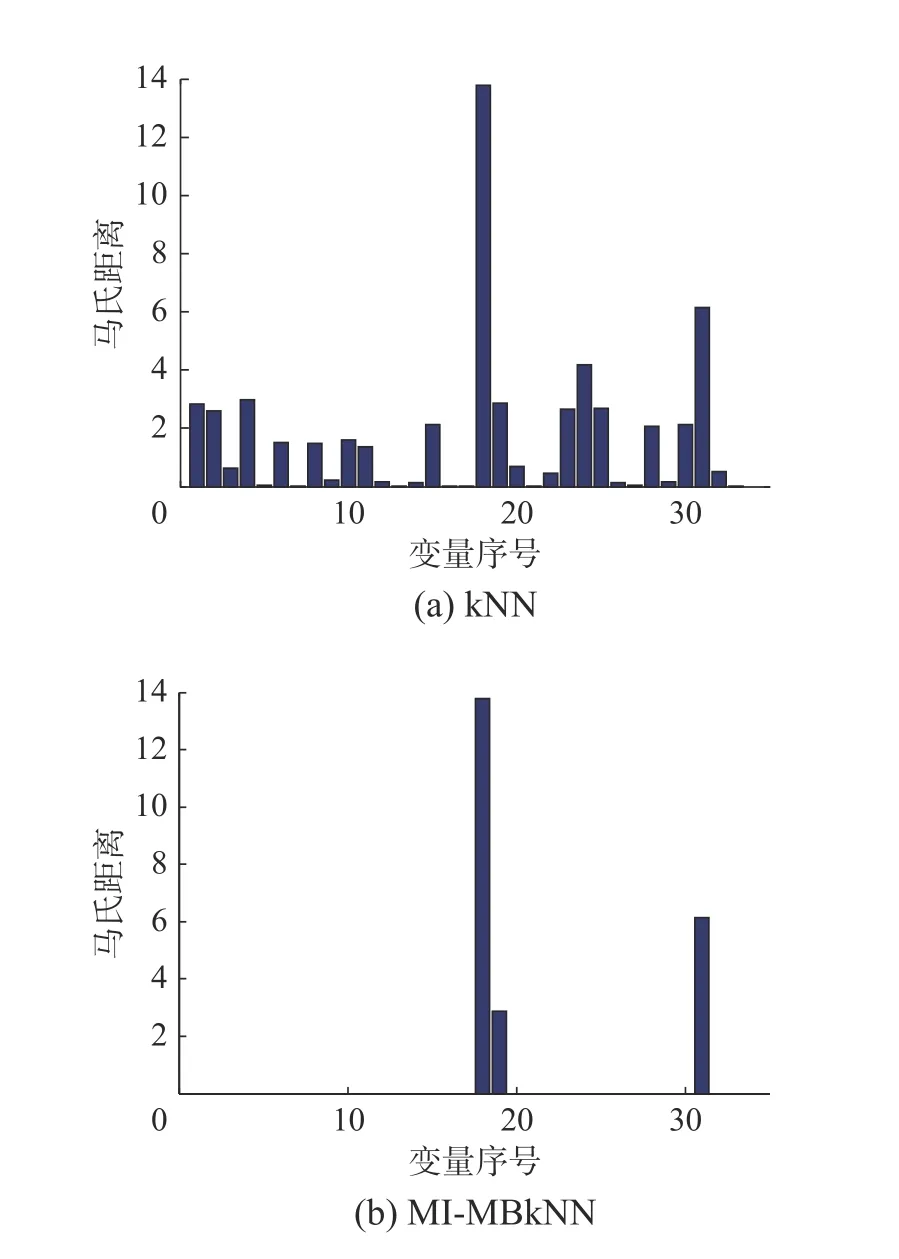
圖9 變量識別結果Fig.9 Variables identification results
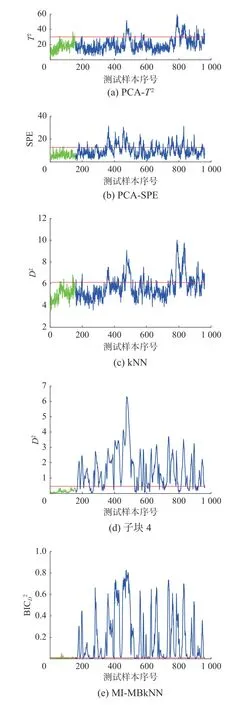
圖10 故障16 監測結果Fig.10 Monitoring result of fault 16
圖11 給出了對故障16 的診斷結果,可以看出,相比于kNN,本文方法對故障提供更清晰的識別結果,即引起該故障的源變量是變量x18、x19和x31。因此子塊4 對故障10 的敏感程度遠遠大于其他子塊,其表現了良好的監測性能。通過貝葉斯推斷融合后提升了整體的監測效果,再次驗證了本文所提方法的有效性。

圖11 變量識別結果Fig.11 Variables identification results
3.2 高爐煉鐵實際過程應用
為了達到高爐煉鐵過程節能降耗的目的,必須保證鐵水的生產質量和產量。當氣體流動不穩定時會影響碳的燃燒,最終導致爐腹架空,產生懸掛故障。若沒有及時檢測出懸掛故障,將會導致熱應力和內部的氣體壓力過大,使得頂部結構受到嚴重的破損。本節考慮了實際情況中懸掛故障的存在,采集正常工況下的8 個過程變量的2 000個樣本作為訓練樣本,同時采集了懸掛故障下的1 900 個樣本作為測試樣本。在懸掛故障下,爐內的溫度和壓力增加,爐頂的一氧化碳和二氧化碳濃度上升,氫氣的濃度下降。為了更好地表現變量的特性,表4 給出了8 個過程變量的描述,圖12給出了8 個變量的變化曲線圖,其中前2 000 個樣本為正常樣本,后1 900 個樣本為故障樣本。

表4 懸掛故障監測中選擇的過程變量Table 4 Process variables selected for monitoring of the hanging fault
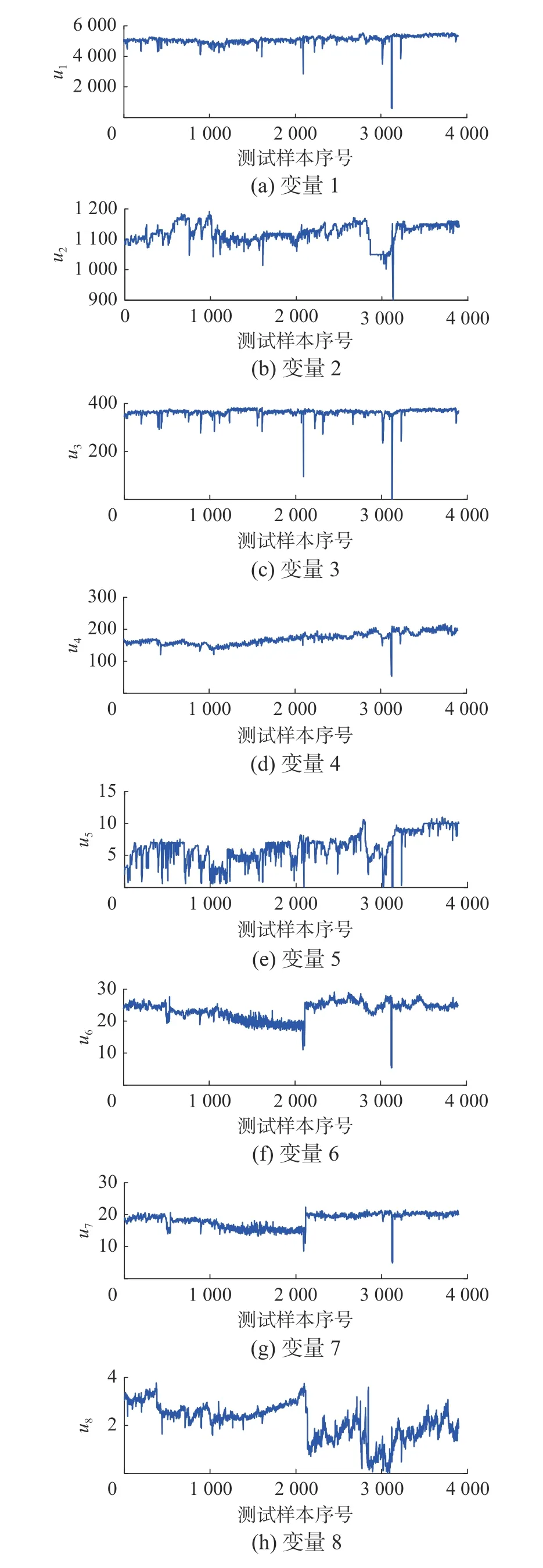
圖12 高爐過程各變量曲線圖Fig.12 Curves of Blast furnace process variable
利用上述所提分塊方法將8 個變量分成兩個子塊,子塊1 為u1、u3,子塊2 為u2、u4、u5、u6、u7、u8,圖13 給出了子塊1 中各變量間的互信息。表5 給出了不同監測方法的監測結果,圖14 展示了子塊1 和子塊2 的監測結果。可以看出子塊2 在2 200 樣本點后可以達到持續報警,其監測效果明顯好于子塊1,結合圖15 給出的故障診斷結果,可以看出變量4 和變量8 是引起故障的主要原因,由于本文所提方法對變量進行了合理分塊,把結構相似且對故障最為敏感的變量放在同一個子塊中,使得整體的監測性能得到了提升,再次驗證本文所提方法的有效性和優越性。
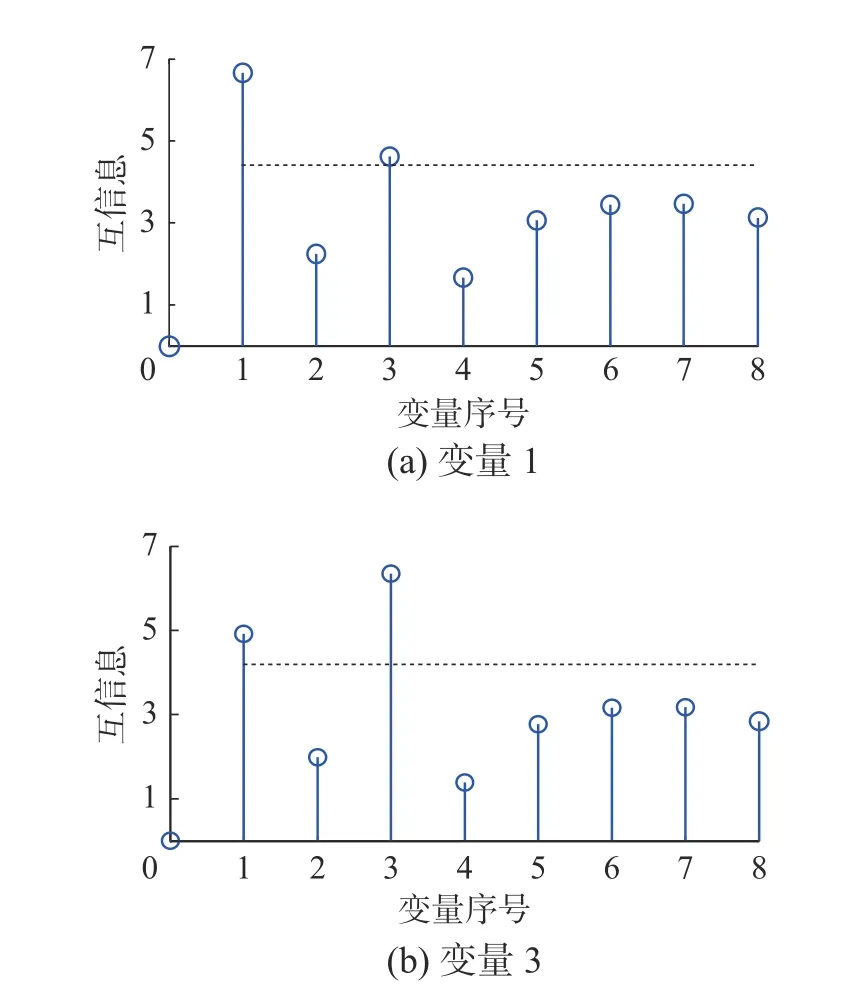
圖13 高爐過程子塊1 變量間的互信息Fig.13 Mutual information between variables in blast furnace process block 1

表5 不同方法的監測性能比較Table 5 Comparison of monitoring performance of two methods in blast furnace process
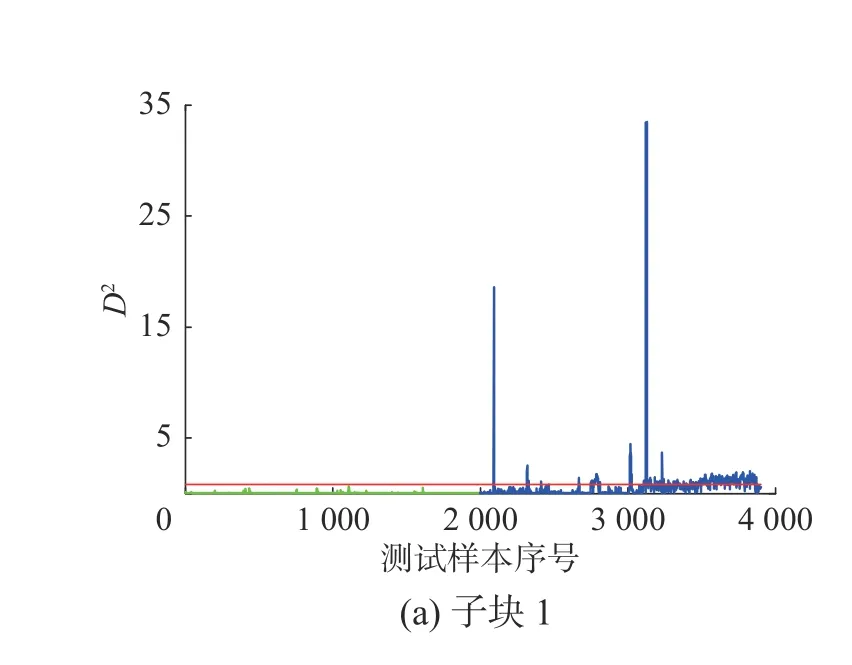
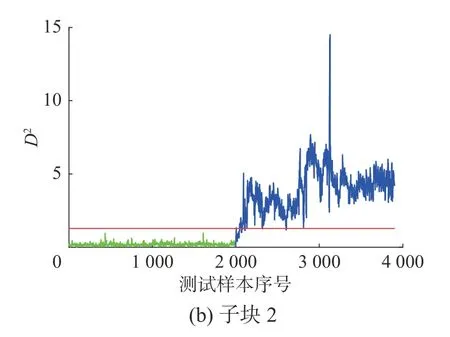
圖14 高爐過程子塊1 和子塊2 的監測性能比較Fig.14 Comparison of monitoring performance of block1 and block2 in blast furnace process
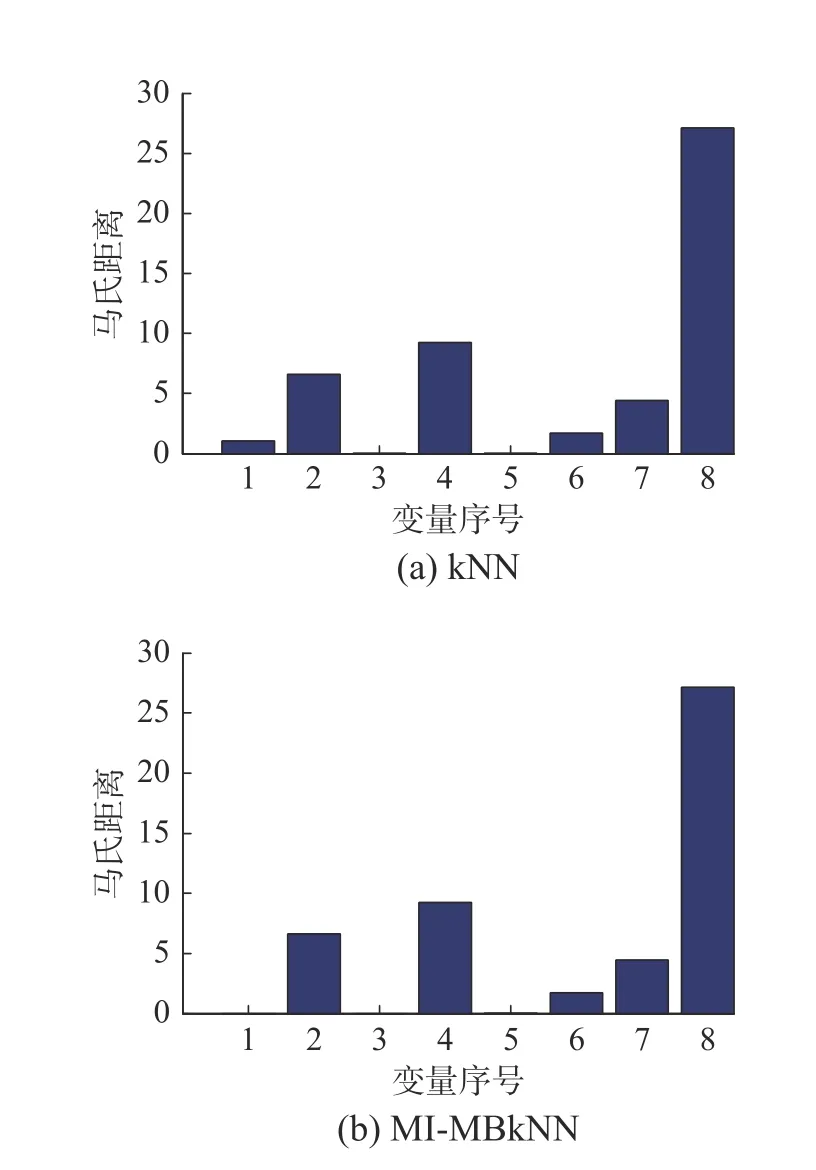
圖15 高爐過程變量識別結果Fig.15 Variables identification results of the blast furnace process
4 結束語
本文提出了一種基于互信息的多塊k近鄰故障監測方法,使用互信息對過程變量進行劃分,并在每個子塊中建立基于kNN 的故障監測模型,所提方法反映了過程的更多局部特征,所以更易于故障的監測和診斷。將所提方法應用于TE 過程和實際高爐煉鐵過程中,均取得了比較好的監測效果。本文所提方法是一種完全基于數據驅動的監測方法,可以考慮將其與先驗知識或專家經驗相結合,并且可以考慮變量間關系的更多細節,提出其他分塊方法,是本文進一步研究的工作之一。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
