基于LSTM模型的國民經(jīng)濟GDP增長預測建模研究
2021-09-12 09:02:26朱青周石鵬
經(jīng)濟研究導刊 2021年19期
朱青 周石鵬

摘 要:傳統(tǒng)時間序列方法在預測模型中要求時序數(shù)據(jù)穩(wěn)定,但對復雜的非線性系統(tǒng)擬合能力較差,但GDP增長的預測精度不夠準確。為了提高GDP增長的預測精度,首先利用機器學習算法Random Forest對影響GDP增長的變量進行重要性排序,選取重要變量,之后運用深度學習中的LSTM神經(jīng)網(wǎng)絡(luò)對GDP增長進行預測分析,并將預測結(jié)果與傳統(tǒng)時序型ARIMA及GARCH模型進行比較。實驗結(jié)果表明,基于遞歸神經(jīng)網(wǎng)絡(luò)的LSTM模型能較準確地反映我國GDP增長的變化規(guī)律。因此,LSTM模型在宏觀經(jīng)濟預測中具有較高的應用價值。
關(guān)鍵詞:GDP增長預測;LSTM;特征選擇;隨機森林
中圖分類號:F12 ? ? ? ?文獻標志碼:A ? ? ?文章編號:1673-291X(2021)19-0005-05
引言
近幾年,全球經(jīng)濟和貿(mào)易增長逐漸放緩。國際環(huán)境復雜多變,貿(mào)易壁壘不斷增加,世界經(jīng)濟面臨增長乏力的局面。中國經(jīng)濟正在由高速增長階段轉(zhuǎn)向高質(zhì)量發(fā)展。受全球經(jīng)濟放緩和中美貿(mào)易摩擦不確定的影響,經(jīng)濟運行總體平穩(wěn),GDP增速放緩。GDP增速反映經(jīng)濟發(fā)展趨勢,與人民的生活水平息息相關(guān)。中國國家統(tǒng)計局數(shù)據(jù)顯示,中國經(jīng)濟經(jīng)過多年的高速增長后,2015年GDP增速為6.9%,2016—2018年的增速分別為6.7%,6.8%和6.6%。2019年6.1%的GDP增速是近年來最大的一次經(jīng)濟增速下降。能夠精準預測GDP增速,對宏觀經(jīng)濟目標的可行性和有效性的分析具有重要影響。
隨著經(jīng)濟學的發(fā)展,出現(xiàn)了大量的經(jīng)濟預測方法,這些模型主要分為兩類:一類是基于時序的外推法,比如移動算數(shù)平均法,指數(shù)滑動平均法;第二類是基于變量因果關(guān)系的因果法,比如回歸分析法、計量經(jīng)濟學方法。但總的來看,經(jīng)濟預測工作進展并不順利,主要體現(xiàn)在預測精度不盡如人意,隨著機器學習和深度學習的發(fā)展,模型對復雜系統(tǒng)的擬合越來越好。
本文主要的嘗試是:提出一種基于隨機森林和LSTM的預測模型,構(gòu)建多層神經(jīng)網(wǎng)絡(luò)更好地擬合宏觀經(jīng)濟中的非線性關(guān)系和時序關(guān)系。
一、相關(guān)研究綜述
目前,國內(nèi)外對宏觀經(jīng)濟預測的研究主要分為以下幾類:首先是基于傳統(tǒng)的時間序列預測模型。李瑞閣、黃佳艷(2018)利用ARIMA乘積模型對國民經(jīng)濟GDP進行預測研究,表明所選模型能較準確地反映我國季度GDP的變化規(guī)律[1];李娜等(2013)利用選定的最優(yōu)ARIMA模型對我國GDP的增長模型進行預測,并闡明了模型的優(yōu)良性和穩(wěn)定性,但由于傳統(tǒng)時間序列方法對復雜的非線性關(guān)系擬合性較差且無法添加與預測指標相關(guān)的變量,預測精度難以提高[2]。之后,學者們轉(zhuǎn)向?qū)Ψ蔷€性系統(tǒng)擬合較好的機器學習算法進行宏觀經(jīng)濟預測。Wang&Shang(2014)、Wang等(2016)將改進SVM模型應用于證券與股票指數(shù)預測中,證明了改進支持向量機模型預測的有效性[3~4]。然而在經(jīng)濟領(lǐng)域數(shù)據(jù)之間普遍存在時序關(guān)系,機器學習算法不能較好地反映樣本間的時序關(guān)系。隨著機器學習領(lǐng)域中深度學習的研究和發(fā)展,其中的遞歸神經(jīng)網(wǎng)絡(luò)(RNN)適用于處理序列數(shù)據(jù)。但是由于RNN存在長期依賴問題,Hochreiter和Schmidhuber(1997)提出RNN的改進模型LSTM神經(jīng)網(wǎng)絡(luò)[5],并被Alex Graves等(2013)進行改良和推廣,使LSTM得到更廣泛的應用[6]。Fu等(2017)針對交通流的隨機性和非線性特征,使用LSTM和門控循環(huán)單位(GRU)神經(jīng)網(wǎng)絡(luò)方法來預測短期交通流量,實驗證明基于遞歸神經(jīng)網(wǎng)絡(luò)的LSTM和GRU模型表現(xiàn)優(yōu)于ARIMA模型[7]。
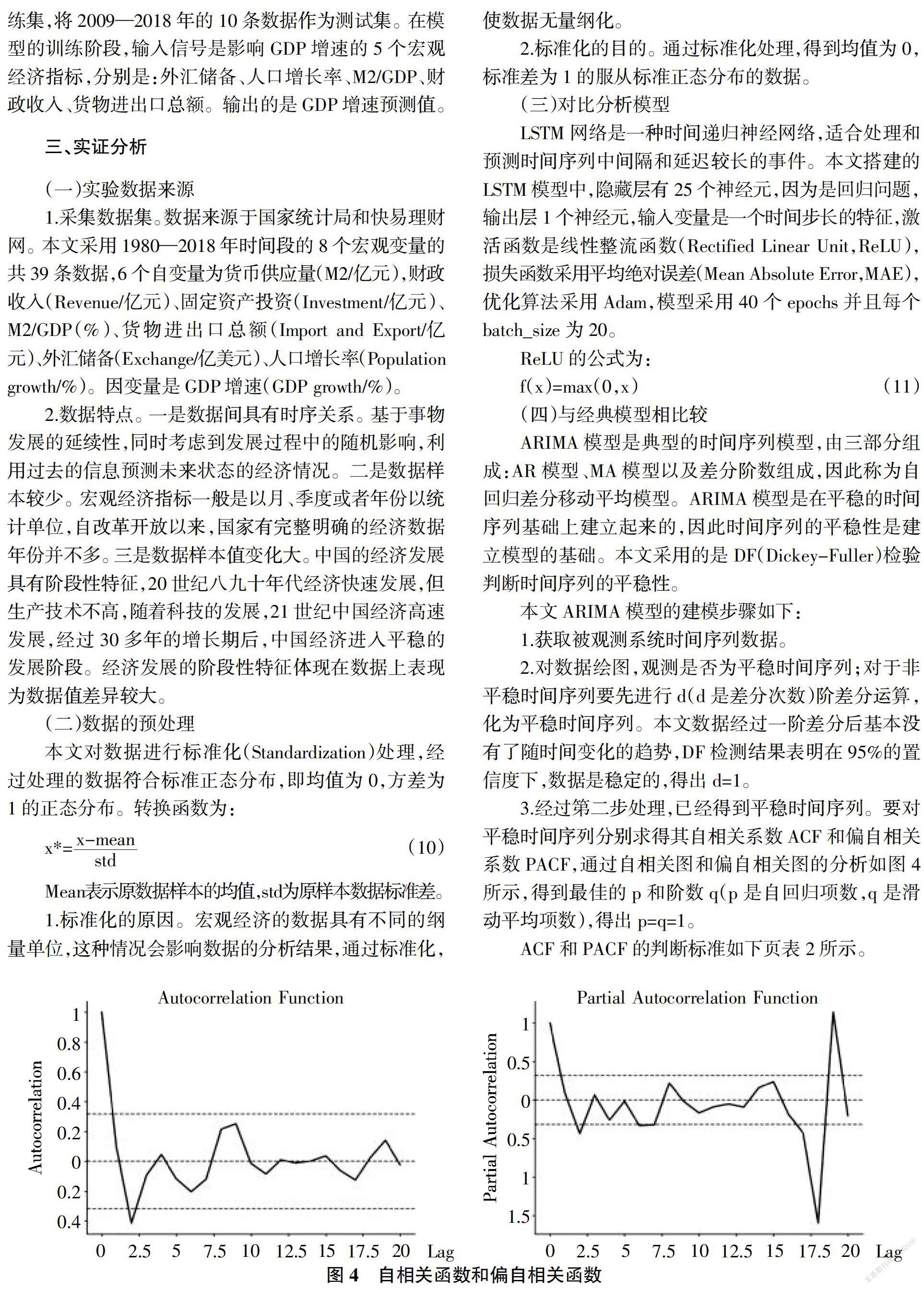
根據(jù)以上分析,本文主要是利用LSTM模型對中國宏觀經(jīng)濟變量GDP增速進行預測分析。考慮影響經(jīng)濟的眾多可能因素,在此分析過程中利用機器學習Random Forest算法提取影響經(jīng)濟發(fā)展的重要特征指標,通過LSTM算法對這些指標數(shù)據(jù)進行學習訓練,對宏觀經(jīng)濟進行預測分析。最后與時間序列預測模型(AR,MA,ARIMA)結(jié)果進行對比,可以看出LSTM算法在預測時序問題中具有精確高效性。
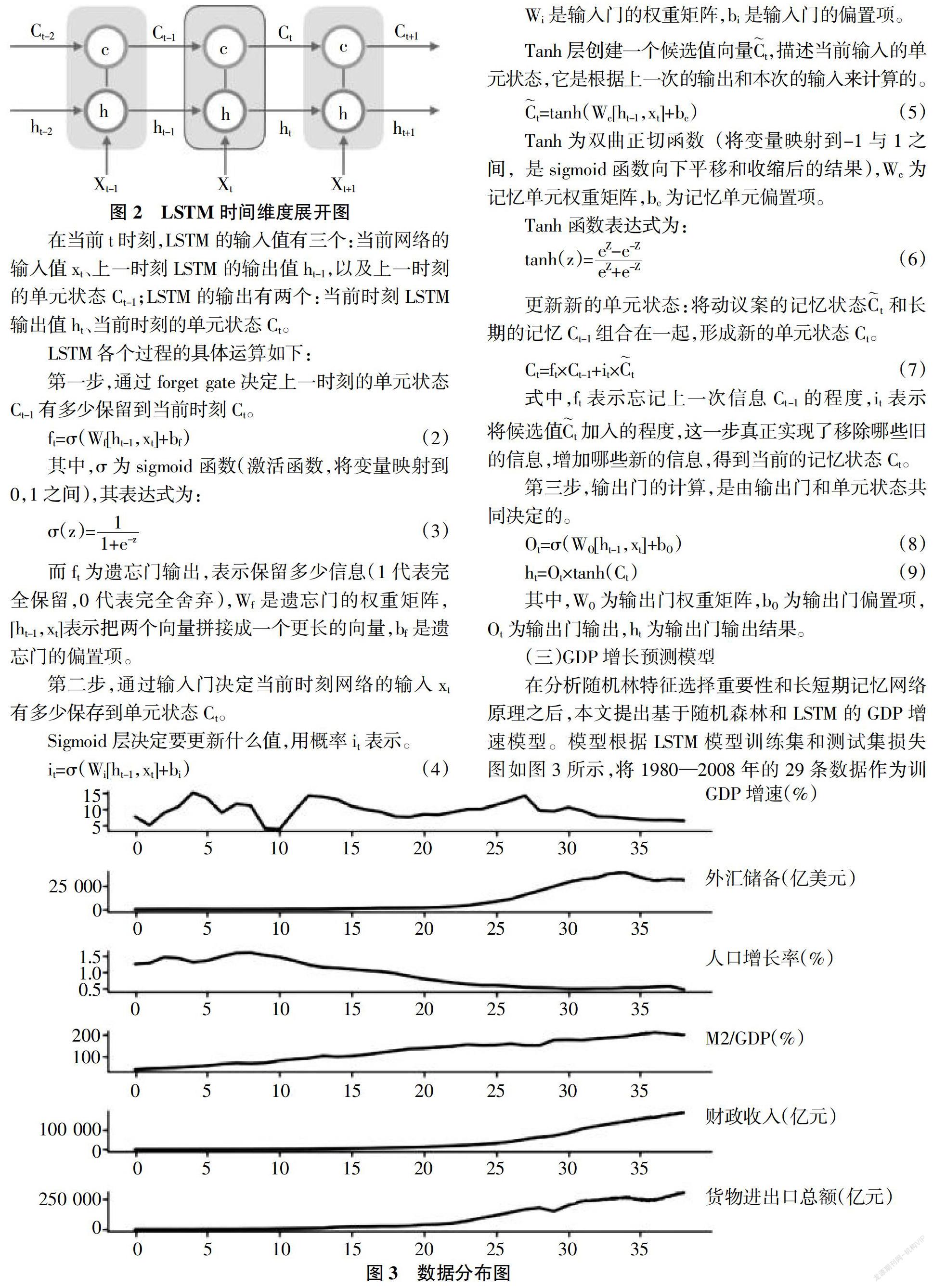
二、隨機森林和LSTM預測模型
(一)隨機森林評估特征的重要性
隨機森林特征重要性評估能夠輔助我們對特征進行篩選,從而使模型的魯棒性更好。
特征重要性選擇的目的:尋找與響應變量高度相關(guān)的重要變量,便于變量選擇,使少數(shù)變量足以很好地預測響應變量[8]。
隨機森林進行特征重要性評估的思想為:通過袋外(out-of-bag,OOB)數(shù)據(jù)誤差增長百分率指標衡量特征重要性。
假設(shè)隨機森林有N棵樹,第K棵樹的誤差增長百分率如式(1):
其中,errOOBK1代表袋外數(shù)據(jù)誤差,errOOBK2是對袋外數(shù)據(jù)對應變量加入噪聲干擾或者改變樣本在特征變量x處的值,再次計算得到的袋外數(shù)據(jù)誤差。對于N棵決策樹,如果加入隨機干擾后,errOOBK2的值大幅上升,即誤差增長百分率大幅上升,說明特征的重要程度比較高[9]。
隨機森林根據(jù)特征重要性進行特征選擇的步驟如下:
第一步,估計和排序。一是對隨機森林的特征變量按照變量重要性(Variable Importance,VI)降序排序。二是確定刪除比例,從當前的特征變量中刪除相應比例不重要的指標,從而得到一個新的特征集。三是用新的特征集建立新的隨機森林,并計算特征集中每個特征的VI并排序。四是重復以上步驟,直到剩下m個特征。
第二步,根據(jù)第一步得到的每個特征集和建立的隨機森林,計算對應的袋外誤差率(OOBerr),將袋外誤差率最低的特征集作為最后選定的特征集。本文收集的原始數(shù)據(jù)集中共包含8個變量,1個因變量和7個自變量。根據(jù)隨機森林特征重要性排序,7個自變量的特征重要性排序如表1所示。從表1可以看出,第6、第7兩個變量即貨幣供應量和固定資產(chǎn)投資,特征重要性比較低,故本文選取前5個變量作為模型的自變量,即人口增長率,M2/GDP,外匯儲備,貨物進出口總額,財政收入[10]。
