基于Xception-CEMs神經網絡的植物病害識別*
2021-09-13 01:22:34項小東翟蔚黃言態劉薇
中國農機化學報 2021年8期
項小東,翟蔚,黃言態,劉薇
(浙江科技學院自動化與電氣工程學院,杭州市,310023)
0 引言
智慧農業[1]運用人工智能技術,結合傳統機械和軟件,智能感知和控制農業生產,引領了一場農業技術的革命。將不斷創新的現代化智能算法,應用在現代農業機械上[2-3]能夠更好的實現農業生產,提升生產效率。影響農業生產量的一個重要因素是農作物病蟲害,農作物病害具有種類多,傳播速度快的特點。因此,我們需要尋找一種高效率,低成本和準確性高、實時性強的方法,來快速識別農作物病蟲害。
CNN在圖像識別方面的良好表現,常作為圖像特征提取器應用在深度學習方法中。隨著深度學習技術不斷發展,基于CNN的深度學習方法也開始應用在農作物病蟲害的識別。深度學習技術能夠取代人工提取特征,閆建偉等[4]通過神經網絡對深層次的果實特征進行提取,將提取到的特征與低層次特征進行多次融合,有效的提升了識別精度。蒲秀夫等[5]以符號函數和尺度因子α代替浮點型權值參數,并將權值二值化,提高病蟲害的準確識別度。Luna等[6]在AlexNet上遷移學習,設計出能夠識別番茄疾病的診斷系統。Durmu等[7]訓練深度學習模型SqueezeNet,應用在田間實時識別番茄病蟲害的機器人。Darwish等[8]在VGG16和VGG19兩個預訓練集成模型上,采用正交學習粒子群優化方法尋最優超參數和指數衰減的學習速率方法提高訓練效率,用于植物病害診斷。Zhang等[9]通過對GoogLeNet增加Droupout層、ReLU函數和減少分類器的數量進行優化。改進后的模型在玉米的9種病害中達到了98.9%的識別精度。為了增強在復雜環境下的玉米病害識別能力,Lü等[10]設計了一種基于AlexNet模型的DMS-AlexNet。DMS-AlexNet用擴張卷積和多尺度卷積來增強網絡特征提取能力,在自然環境獲取的玉米圖像上,識別精度達到了98.62%。對于其他農作物疾病,Ramcharan等[11]在InceptionV3上遷移學習,實現了能在移動設備上識別三種木薯疾病的深度學習算法。Lu等[12]設計出了一個能識別10種水稻疾病的深度學習模型,在10次交叉驗證策略下精度遠高于傳統機器學習方法。Lin等[13]將卷積層的卷積核以矩陣形式排列,提出了M-BCNN,用來識別細粒度的水稻疾病圖像。M-BCNN在細粒度圖像上的精度相比AlexNet和VGG得到了顯著提高。Liu等[14]基于AlexNet移除部分全連接層,加入池化層、Inception模塊和NAG算法,提出了一種能識別蘋果四種病蟲害疾病的網絡模型。黃亦其等[15]通過改進的LeNet-5對無人機獲取到的紅樹林圖像進行識別分類,將無人機技術和深度學習應用在傳統農業保護中。孫鵬等[16]將注意力機制應用在大豆蚜蟲的檢測中,與傳統神經網絡相比提高6%的準確率。深度學習技術在農業方面廣泛應用,對于農作物的識別和病蟲害檢測取得了較好的成果。但是對于復雜環境下獲取的農業圖像,還存在精度不高和實時性不強的問題。對于植物病害的細粒度區分,還存在區分不明顯的現象。因此需要提高神經網絡的特征提取能力,來更好的識別植物病害,提高農作物的產量。本文在以上分析的基礎上,對基于Xception識別病蟲害類別進行研究,為智能化農業診斷系統提供依據。
1 材料
1.1 數據集
本文的數據集采用AIChallenger2018農作物病害檢測數據集,以及PlantVillage數據集中的部分農作物數據。其中AIChallenger2018有26 820張,PlantVillage數據集有6 834張。數據集總共有39 234張,其中訓練數據集有33 654張,占總數的86%,測試集數據集有5 580 張,占總數的14%;數據集由10種不同植物的50類圖像組成,分別包括這10種健康植物和27種病害,其中對13種病害進行了兩種程度的分類。考慮到農業生產中的實際需求,對產量較大的農作物進行病害程度分類,更有利于農作物的保護與培育。因此對蘋果黑星病、玉米灰斑病和玉米銹病等13種疾病進行了程度分類,分成健康、一般和嚴重三個程度。如圖1所示為列舉玉米灰斑病的程度圖。

(a)嚴重
1.2 圖像預處理
考慮到數據集在良好的環境下采集,與實際田間作業獲取的圖像存在差異性。為了提高網絡的泛化能力,增強網絡識別圖像的表現,本文對數據集進行了隨機田間化預處理。本文的預處理包括:以圖像中心為軸進行(0,45°)隨機取角度旋轉,來模擬田間抖動獲取圖像帶來的誤差,以[0.9,1.1]為等比例縮放系數進行隨機縮放,來平衡圖像因旋轉操作帶來的特征缺失問題;將圖像進行水平和垂直的隨機翻轉,來模擬田間獲取圖像的真實性;將圖像進行圖像增強和銳化操作,增加圖像的復雜性;圖像進行標準歸一化操作,消除特征之間的差異性,便于網絡學習。最后將圖像分辨率統一為256像素×256像素,圖像類型為RGB。田間化隨機預處理的效果如圖2所示。


(d)垂直翻轉
1.3 病蟲害識別流程
具體流程如圖3所示。
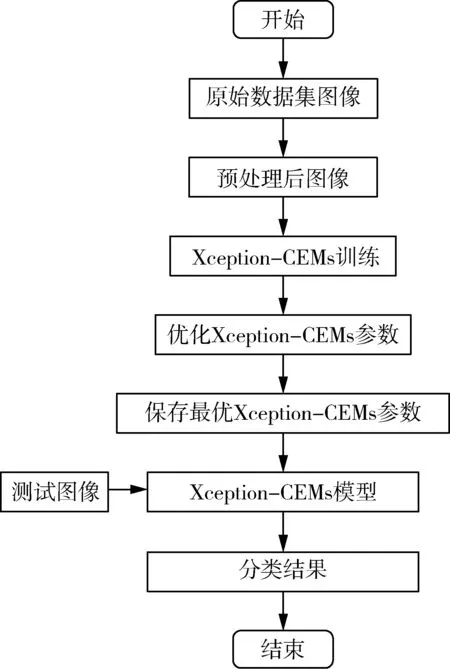
圖3 系統流程圖Fig.3 Flowchart of system
本文提出了一個基于深度學習的植物病蟲害識別系統,應用于田間作物病害程度識別,提高作物的產量。該系統由訓練模型的計算機和實際應用的計算機或移動電子設備組成。一方面,通過33 654張隨機田間化處理的數據信息和類別標注信息訓練模型,不斷迭代優化模型參數,并保存識別精度最高的Xception-CEMs參數模型。另一方面,輸入測試圖像,在最優的模型參數上預測,得到概率最高的分類結果。
2 改進的Xcpetion識別模型
2.1 Xception-CEMs網絡設計
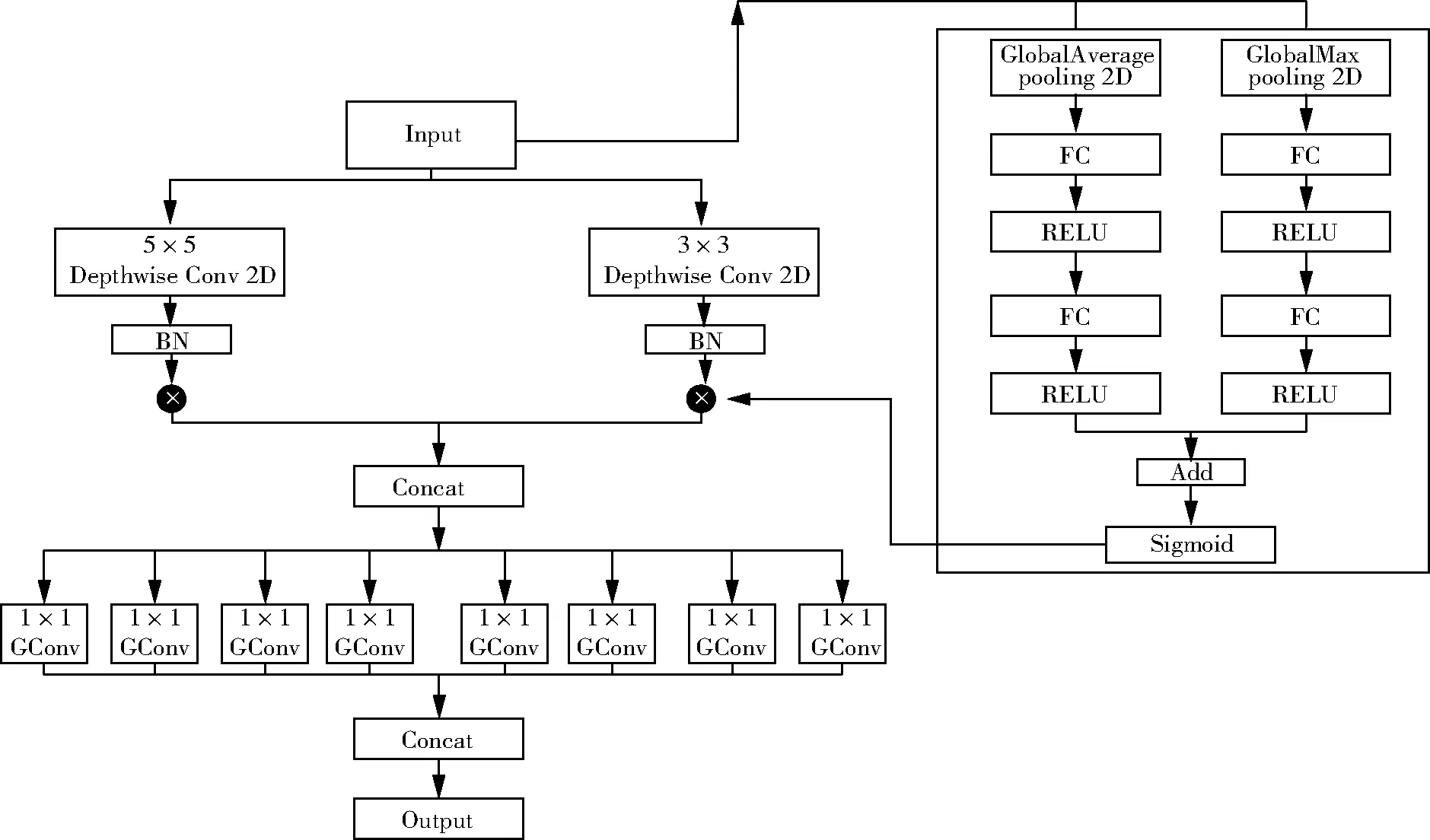
本文基于Xception提出了一個識別植物病害能力更強、速度更快的Xception-CEMs,網絡結構如圖4所示。

圖4 Xception-CEMs網絡結構圖Fig.4 Network structure of Xception-CEMs
Xception-CEMs圖像經過不同階段的卷積、下采樣等處理后的特征信息如圖5所示。Xception-CEMs由數個CEM堆疊的模塊和一個改進的密集連接模塊組成。不同于Xception的深度可分離卷積,通過帶有通道權重的多尺度深度卷積和1×1組卷積的形式組合,提出了一個通道擴展模塊。該模塊不僅保證了圖像空間和通道的獨立性,獲得更多的病害分布、病害形狀等信息,而且大大減少了模型參數量。圖5階段一中的三張圖體現了通道擴張模塊的有效性,特征圖邊緣信息和病害分布較明顯。由于ResNnet[17-18]中提出對特征的復用,并且Densenet[19]中的密集連接方式更進一步對特征進行跨層復用,因此在深度可分離卷積中采用密集連接,并將改進的密集連接模塊應用于Xception-CEMs中。密集連接模塊的加入,得到病害的高級邊緣特征和病害程度的信息,有利于病害程度識別。圖5階段2中的圖體現了特征復用的有效性,高級邊緣信息和病害分布較明顯。此外,在提出Xception-CEMs的基礎上,還提出了一種先擴張—保持—再擴張—壓縮形式的通道擴張新策略。新的通道擴張策略,減少了MAC時間和降低網絡運算成本。

圖5 Xception-CEMs各階段處理后植物病害結果Fig.5 Results of plant diseases after Xception-CEM streatment
2.2 通道擴張模塊
一個CEM模塊由三部分組成而成,分別為:多尺度深度卷積、通道權重和組數為8的1×1的組卷積組成。鑒于GoogLeNet[20-22]提出了采用多尺度的卷積核進行信息篩選的Inception結構。MobileNet[23-25]和Xception[26]提出了對圖像通道進行卷積操作的深度卷積。結合Inception結構的多尺度卷積核和Xception的深度可分離卷積,我們引進了由卷積核大小為3×3和5×5的兩個分支通過通道相加組合而成的多尺度深度卷積。多尺度深度卷積在空間上更好的適應植物病害的信息分布,在通道上實現了通道信息的獨立性。在通道上單純將通道信息平等相加,容易在空間上造成特征冗余現象,從而影響模型的識別能力,造成病害程度分類和類別分類的錯誤。因此本文考慮通過增加通道權重分配到多尺深度卷積,來提升網絡的性能。考慮到參數問題,本文中5×5卷積核由兩個3×3堆疊代替。在減少了0.02 MB參數的同時,實現了相同的視野。不同于Xception中的點卷積,本文通過用組數為8的1×1的組卷積來控制通道數。這里選用1×1的組卷積,是考慮到利用1×1組卷積的較小參數來平衡多分支卷積帶來的參數,并且過多的通道獨立卷積相加得到的植物病害特征圖缺乏通道聯系性,所以以分組的形式可以增加局部通道的聯系性,提高植物病害識別準確率。
圖6顯示了CEM的兩種組成形式,考慮到植物病害的淺特征主要體現在病害局部與邊緣的信息,因此選用圖6(a)中的CEM模塊,在提取更多病害特征的同時也不會造成特征冗余現象。考慮到植物病害的深特征主要體現在語義的抽象特征,因此選用圖6(b)中的CEM模塊,有利于模型的預測輸出。
(a)通道擴張兩倍時CEM模塊
2.3 通道擴張的新策略
本文中,通過堆疊CEM模塊,提出了一種新穎的通道擴張策略。不同于Xception的擴張-保持策略,這種策略是讓通道先擴張—保持—再擴張—壓縮的形式進行通道數變化。通道先擴張,保證在空間上和通道上先獲取更多的病害特征信息。參考ShuffleNetV2[27],過多的組卷積會增加MAC時間。通道保持減少了MAC時間,來降低網絡運算成本,從而提高植物病害識別速度。通道再一次擴張,為了在相對較深的特征上提取更多的抽象特征,有利于模型的預測。最后通道壓縮,防止通道數增加過快而帶來參數過大問題。本文提出的通道擴張新策略相比原來的Xception,不僅模型參數量變小了,同時提升了網絡的識別性能,提高了病害識別的精度,降低了網絡復雜度,更快的識別病害。
2.4 深度可分離密接連接
本文通過對特征信息進行特征復用的方法,代替了Xception中重復堆疊深度可分離卷積和殘差結構的方法。提出了基于深度可分離卷積的密集連接模塊。該模塊在保持通道數不變的情況下,總共有4個卷積層,前三層采用的是深度可分離卷積,最后一層采用了1×1的卷積。深層網絡中提取得到的是高級的病害特征,采用特征復用的方式,使得模型更具有判別力用于病害分類。
3 試驗結果和分析
3.1 試驗環境
為了驗證網絡性能,將Xception-CEMs網絡應用在39 234張數據集上進行試驗,所有試驗都采用了相同的參數配置。模型訓練的處理器是Intel(R)Core(TM)i7-9700CPU@3.0GHZ,內存是32 G,圖形卡是NVIDIAGTX2080Ti,視頻內存是11 G,并且操作系統為win10。軟件系統使用pycharm2019.2,tensorflow-gpu2.0.0,keras-gpu2.2.4,OpenCV3.3.1。試驗采用Keras框架,迭代次數為50次,批量大小設置為20,選用了Adam作為優化器,學習率的初始值設為0.001,當模型的精度在2個epoch下降時,會以0.1為減小因子調整學習率。
3.2 多尺度深度卷積在網絡位置的選擇
為了在空間上獲得更多的特征信息和增加特征通道的獨立性,在方法中分析了多尺度深度卷積的加入對于網絡的精度提升的有效性。實驗中,采用卷積核大小為3和5組合的多尺度深度可分離卷積來代替原模型中卷積核大小為3的深度可分離卷積的可行性卷積,對于精度的差異如表1所示。
為了驗證多尺度深度可分離卷積的可行性,本文采取了控制變量,當將多尺度深度可分離卷積部署在不同階段時,剩余的卷積采用同原模型相同的卷積進行試驗進行對比。
表2反映了將多尺度深度卷積放置在Xception網絡不同階段時,網絡的準確率都有提升。其中階段1為輸入流,階段2為中間流,階段3為輸出流。根據上表的結果可以分析出,多尺度深度卷積模塊的加入,總體上對網絡都有精度的提高效果。其中,在輸入流和輸出流同時部署效果最佳。由于在低層級和高層級對卷積層的優化,可以加強特征提取,更好的保存特征。但是過多的多尺度深度卷積,會造成特征信息冗余現象。因此將多尺度深度卷積應用在輸入流和輸出流,使分類的結果更加趨于真實結果。

表2 多尺度深度可分離卷積部署在網絡不同階段準確率變化表Tab.2 Accuracy of multi-scale depthwise separable convolution deployed at different stages of the network
除了對網絡的精度評價,計算量和參數量也是網絡的一個評價標準,該模塊部署在網絡的不同部分的計算量和參數量如表3所示。
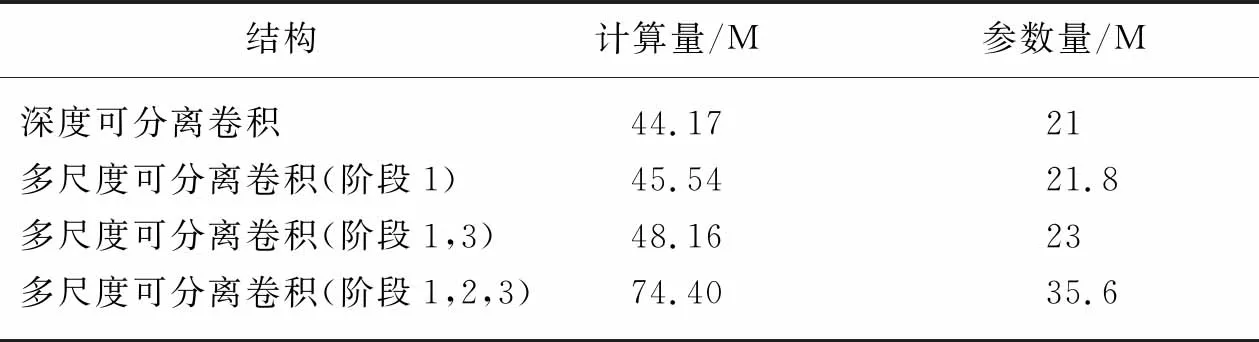
表3 多尺度深度可分離模塊在網絡不同部分應用的計算量和參數量表Tab.3 MFLOPs and parameters of multi-scale depthwise separable convolution applied in different parts of the network
表3反映了將多尺度深度卷積加在不同位置時,用計算量和參數量分別來衡量模型的復雜度和輕量化度。這里用M作為單位。可以從上表的結果得到,該模塊應用在網絡的輸入流、中間流和輸出流中,模型的復雜度過高和參數量過大。只在輸入流或在輸入流和輸出流中應用該模塊,計算量和參數量與原模型差距不大。
從評價網絡的角度出發,綜合考慮多尺度深度卷積的加入對模型的精度、復雜度和參數的影響。在精度、模型復雜度和參數量這三者獲取一個平衡點,得出將模塊應用在輸入流和輸出流兩個部分的結論。多尺度深度卷積可以在特征圖的低級特征中獲取更多的圖像實體特征,在特征圖的高級特征中獲得更多的信息概括實體圖像的屬性,結果更加接近真實。
3.3 CEM中的組卷積選擇
通過多尺度深度卷積代替原網絡中的單一深度可分離卷積后,得到最優的部署策略是將該模塊應用在輸入流和輸出流部分。接著考慮到過多通道獨立卷積,使通道之間缺乏聯系性,從而影響網絡的性能。本文加入了分組卷積的策略來代替原網絡的點卷積,對組卷積的組數,分別嘗試對一組、兩組、四組和八組的應用。以下圖7是多尺度深度卷積和分組策略應用的精度和損失值變化圖。圖中的標注表示的是不同組數的組卷積與多尺度可分離卷積組合和原模型。從精度角度,組卷積和多尺度深度卷積組合后,網絡整體的精度都提高了。當epoch為50的情況下,其中組數為2和8這兩個組別,相比原網絡精度提升較明顯,分別提升了8.4%和8.2%。從擬合速度來看,組數2和8在epoch為10左右,曲線就開始趨于平緩,表示網絡擬合速度較快。從損失值的角度,當epoch為50情況下,組數2和8的損失值較原網絡也有明顯的下降。其中組數為2下降了0.233,組數為8下降了0.215。

(a)不同組數與原網絡精度對比圖
有了精度和損失值的指標,網絡的參數量和模型計算量依然是本文的重要評價指標。表4反應了多尺度深度卷積與組卷積結合的參數量和計算量。從參數量考慮,當組數為2、4和8,都有參數量的降低的趨勢。當組數為8時,模型有最小的參數量為19.5 M。在計算量方面,分組為2、4和8的時候,都有接近的模型復雜度,與原模型對比,復雜度都減小。其中組數為8的模型復雜度最小。因此能證明,分組的策略有利于輕量化模型。
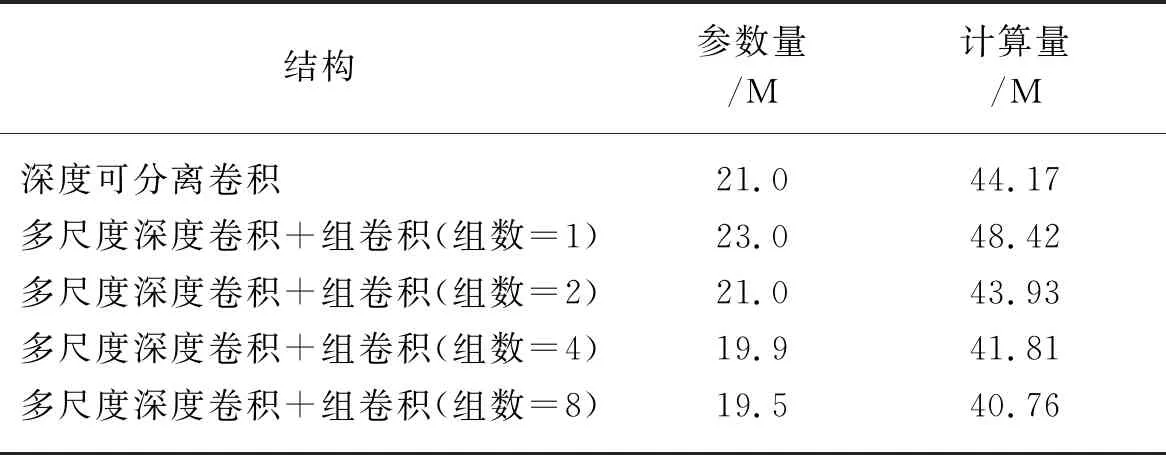
表4 多尺度深度卷積和組卷積的參數量和計算量表Tab.4 Parameters and FLOPs of multi-scale depthwise convolution and group convolution
在分組策略的融合下,不僅要考慮模型的計算量和參數量,還需要考慮模型的精度和損失值。綜合上述指標考慮,CEM模塊中選擇了組數為8的組卷積。
3.4 CEM中通道權重的選擇
在多尺度深度卷積和組卷積組合的基礎上,根據特征通道的重要程度,還需要在通道上加上權重來增強重要的通道信息,減弱次重要或者無關信息。表5反映了兩種不同的得到通道權重方法,分別應用在多尺度深度卷積與組數為2和8的1×1組卷積上。
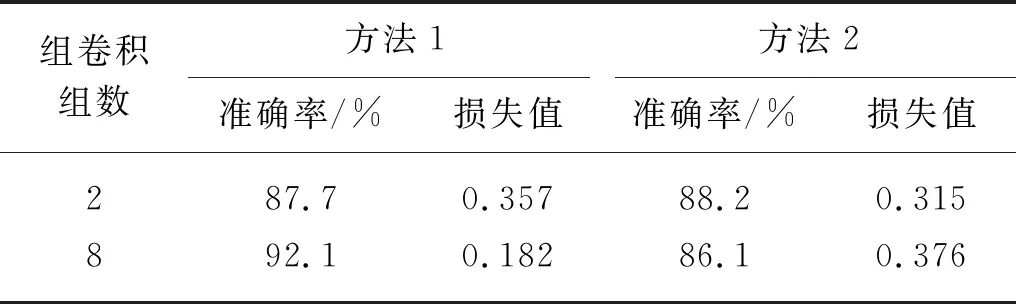
表5 采取兩種不同通道權重的結果表Tab.5 Results of two different channel weight
第一種方法是通過并行全局平局池化→全連接→全連接和全局最大池化→全連接→全連接這兩個分支然后相加得到的通道權重策略。考慮到全連接層的參數量較大和全局最大池化只是通過選擇最大值來衡量通道的信息,會使次重要信息丟失。第二種方法是通過全局平均池化→點卷積→點卷積得到通道權重。實驗證明,在多尺度深度卷積與組數為8的1×1組卷積組合上,搭配第一種方法得到的通道權重,是網絡的最佳結構方案。
通過上述的三個試驗,最終得到了本文提出的CEM模塊。試驗證明,把CEM模塊應用在網絡的輸入流和輸出流效果最佳,通過對特征圖低級特征和高級特征的處理,得到在精度、模型復雜度和參數量上更優的網絡。
3.5 Xception-CEMs模型驗證
本文通過準確率、精確率、召回率和F1值對模型進行評價。其中精確率表示真實樣本實例占模型預測正樣本的比例,其計算公式如式(1)。
(1)
召回率表示真實樣本占所有樣本的比例,其計算公式如式(2)。
(2)
式中:TP——真陽;
TN——假陽;
FP——真陰;
FN——假陰。
F1值表示精確率與召回率的平衡值,其式如式(3)所示。
(3)
該網絡在33 654張數據集上訓練,達到91.9%的準確率,在5 580張上測試,可以達到89.9%的準確率,Xception-CEMs的參數量是14.05 M,計算量是29.33 M。在10種不同植物的50類圖像組成的分別包括10種健康植物和27種病害,其中對13種病害進行了程度分類的數據集上,達到了88.7%的精確度,82.45%的召回率和85.33%的F1值。關于Xception-CEMs各個指標的具體數值如表6所示。

表6 Xception-CEMs性能表Tab.6 Performance of the Xception-CEMs
在相同實驗設備的條件下,與其他經典神經網絡模型對比,能夠更好的體現本研究中優化策略的優越性。表7是本研究中優化的網絡與其他的典型網絡的訓練后的模型在精度和損失值上的對比。
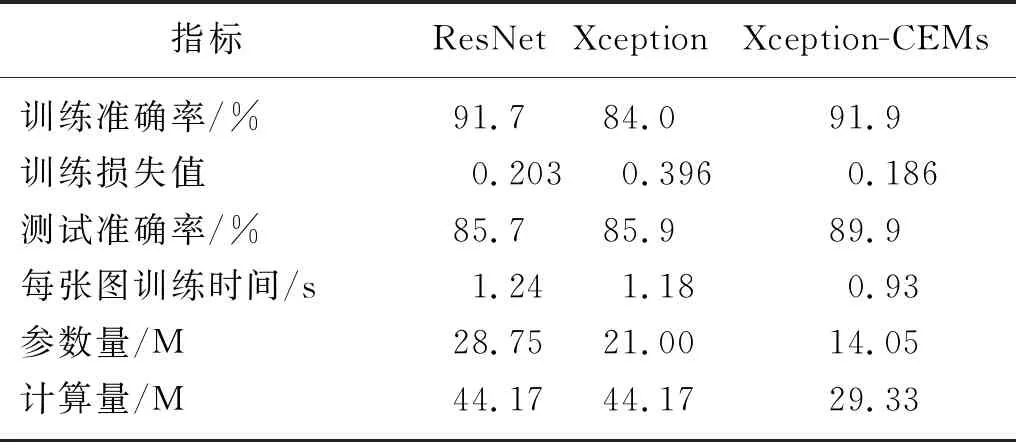
表7 優化模型與典型模型結果的對比表Tab.7 Comparison of results between optimized model and typical models
由表8可以看出,經過本研究優化后的Xception-CEMs模型,在植物病蟲害識別領域上有更好的優勢。在經過同等配置的訓練后,相比Resnet、Xception這些經典網絡,Xception-CEMs有更高的訓練和測試精度和更低的損失值。Xception-CEMs在參數量和模型復雜度方面也有著顯著的優勢,在保證模型精度的條件下,參數量明顯下降,模型復雜度明顯下降。該結果證實了,將Xception-CEMs模型應用在病蟲害圖像識別上的可行性。
3.6 Xception-CEMs定性分析
將Xception-CEMs應用在10種不同植物的50類圖像組成的分別包括10種健康植物和27種病害,其中對13種病害進行了程度分類的數據集上,分析了每一類的精度結果,結果如圖7表示。模型在優化之后,在50個類別中,有45個類別都有更高的精度。其中有5個類別的精度有所降低,分析原因可能為一些植物病害的一般、嚴重程度,圖像特征區別很小。對于這些數據的標定都有困難,因此很難被區分開來。

圖7 Xception-CEMs與Xception每一類的精度Fig.7 Accuracy of Xception-CEMs and Xceptionon each disease
本文還運用了混淆矩陣,來可視化類別的預測結果和實際結果。我們對典型的蘋果、玉米、葡萄和番茄這四個農作物大類做了混淆矩陣的分析。關于這四類農作物的混淆矩陣如圖8~圖11所示。

圖8 蘋果的混淆矩陣Fig.8 Confusion matrix of apple

圖9 玉米的混淆矩陣Fig.9 Confusion matrix of corn

圖10 葡萄的混淆矩陣Fig.10 Confusion matrix of grape

圖11 番茄的混淆矩陣Fig.11 Confusion matrix of tomato
主對角線上的顏色越深,代表模型在該類別上的識別精度越高。其中X表示為預測的類別,Y軸表示為真實的類別。對角線上的數據代表正確的分類,從圖中可以看出,預測分類的最大值都在對角線,驗證了本文算法的可行性,具有較好的植物病蟲害識別能力。
3.7 測試結果分析
通過保存訓練好的最佳模型,對上傳的預測圖片可以顯示不同類別和不同程度的預測結果。本文對5 580 張數據進行了預測,其中部分病害的測試結果表8所示。
比如蘋果黑腐病這類病害圖像,圖像總數為122張,其中88張是預測正確的數量,即表示為真陽。34張表示預測錯誤的圖像,即表示為假陰。根據式(2)中對召回率的定義,即預測正確的數量占總數的比例,得到蘋果黑腐病的召回率,來衡量測試結果的好壞,從而評價模型的性能。表8中其他數據均根據以上定量描述計算得到。根據測試結果,蘋果和玉米的召回率都比較高,表明基于Xception-CEMs神經網絡的方法可以高效的完成植物病蟲識別工作。
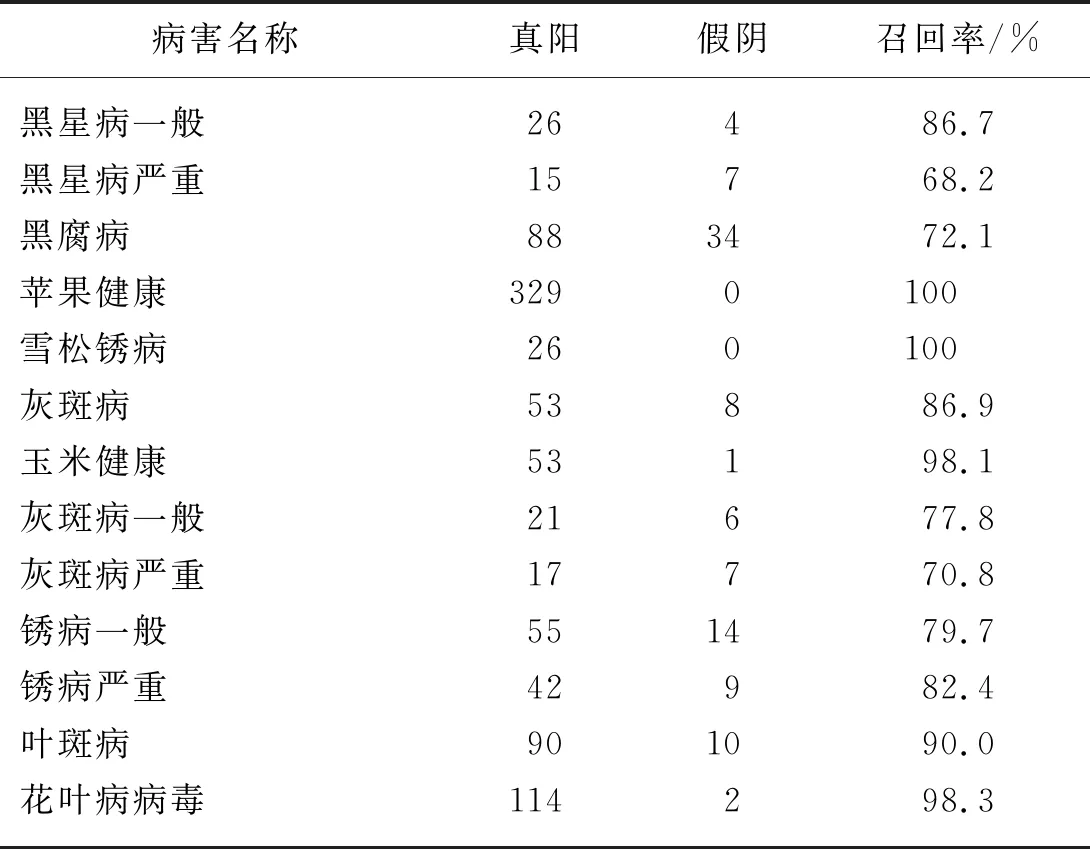
表8 各類別的測試精度結果表Tab.8 Tes tprecision results in different categories
4 結論
1)為了增強神經網絡的特征提取能力可以及時分辨植物疾病,應用于實際農業生產需求。本文建立了一個由AIChallenger2018和PlantVillage組成的包含33 654張圖像的數據集。其中,AIChallenger2018有26 820張圖像,占數據集的80%;PlantVillage有6 834 張圖像,占數據集的20%。
2)本文提出了一個新穎的植物病蟲害識別方法,該方法基于深度學習和Xception-CEMs網絡框架。在Xception-CEMs中,本文了引入了CEM模塊、基于深度可分離卷積的密集連接模塊和一種新穎的擴張-保持-再擴張-壓縮的通道擴張策略。Xception-CEMs對10種植物作為研究對象,數據集包括這10種健康植物和27種病害,并對其中的13種病害類別進行程度分類,在所組成的50個類別中,達到了91.9%的準確率,88.7%的準確率,82.45%的召回率以及85.33%的F1得分。Xception-CEMs在植物病害識別上具有更大的優勢,相比Xception,準確率提高了7.7%。Xception-CEMs在模型輕量化方面也得到了優化,計算量為29.33 M,參數量為14.05 M,相比Xception分別降低了33.6%和33.1%。
3)本文提出的基于深度學習的植物病蟲害識別系統,成為植物病害診斷系統的候選。農業人員可以依據該方法的識別結果,對有疾病的植物及時采取措施,提高作物的產量。未來,本文提出的算法還可以應用于移動端用來實時識別作物病害,提高檢測系統的便攜性。提出的Xception-CEMs可以作為特征提取器應用在病害檢測等領域,為農業領域做出貢獻。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
