大數據平臺下實時電影推薦算法研究
2021-09-13 02:27:43牛路帥彭龑
軟件工程 2021年9期
牛路帥 彭龑

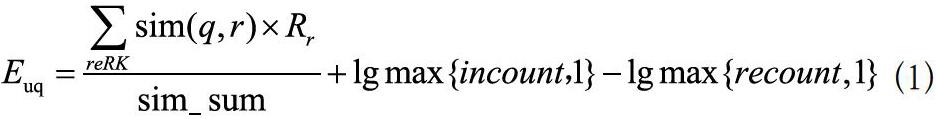
摘? 要:隨著互聯網數據量的不斷擴大,數據的實時推薦需求已經不能被傳統的推薦模型所滿足,協同過濾推薦算法的不足也越來越明顯。為此,通過大數據計算框架Spark平臺構建基于模型的推薦算法來更好地應對海量數據實時推薦的問題。首先,通過預先設定的計算方法進行模型的構建;同時將一種改進的余弦相似度算法應用到模型中,不僅可以縮短推薦實現的時間,而且可以提高推薦性能。實驗結果表明,該算法和傳統協同過濾算法相比,提高了準確率和時效性,驗證了系統可較好地滿足用戶的實時需求。
關鍵詞:Spark;實時;推薦算法;協同過濾
中圖分類號:TP399? ? ?文獻標識碼:A
文章編號:2096-1472(2021)-09-13-04
Abstract: With the continuous expansion of the amount of Internet data, traditional recommendation model can no longer meet the demand for real-time recommendation. The deficiency of collaborative filtering recommendation algorithm is becoming more and more obvious. For this reason, this paper proposes to build a model-based recommendation algorithm based on the Spark platform of big data computing framework, in order to better deal with the problem of real-time recommendation of massive data. First of all, the model is constructed through the preset calculation method, and an improved cosine similarity algorithm is applied to the model, which can not only shorten the time of recommendation implementation, but also improve the performance of recommendation. Experimental results show that compared with the traditional collaborative filtering algorithm, the proposed algorithm improves the accuracy and timeliness, and verifies that the system can better meet the real-time needs of users.
Keywords: Spark; real time; recommendation algorithm; collaborative filtering
1? ?引言(Introduction)
在信息爆炸的今天,信息超載的問題[1]逐漸顯現出來,人們有許多種方式和途徑去獲取信息,但是很難從這些信息中找到自己所感興趣的東西。推薦系統則是解決這個問題的關鍵所在[2-4]。推薦系統能夠通過分析用戶的興趣和行為,智能地向用戶推薦所需信息,其既需要篩選出大量有用的數據,又要實時地滿足用戶的個性化需求[5],所以大數據處理是推薦系統所要具有的能力[6-7]。Spark是一種具有大數據處理能力的內存計算框架[8],運行于Spark平臺的推薦系統可以發揮更高的處理能力。本文旨在利用Spark平臺對基于模型的推薦算法進行優化與并行化實現,和傳統的推薦算法相比,實時性與準確性也都有較大的提高。
2? Spark分布式計算框架(Spark distributed computing framework)
2.1? ?Spark運行架構原理
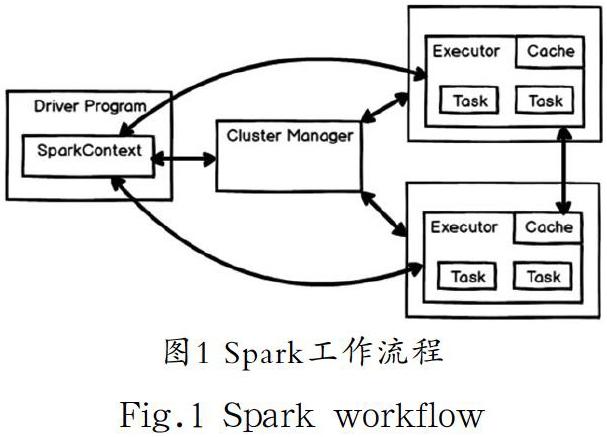
Apache Spark是一種基于內存的快速、通用、可擴展的大數據計算引擎[9]。當執行一個用戶編寫的Spark應用程序時(SparkContext),Driver程序會創建SparkContext向集群申請資源,并在此階段中生成DAGScheduler和TaskScheduler兩個模塊,資源管理器啟動Executor進程。DAGScheduler將任務解析成Stage,之后把一個個TaskSet提供給底層調度器 TaskScheduler處理[10]。
Executor向應用程序申請Task,TaskScheduler將Task發放給Executor運行并提供應用程序代碼。具體流程如圖1所示。
2.2? ?Spark平臺部署
本文搭建的Spark集群[11]采用3 臺普通的PC,其中包括1 個Master節點和2 個Slave節點。3 個節點均采用CentOS 6 Linux系統,節點之間采用局域網連接,具體情況如表1所示。
Java JDK安裝包采用jdk-8u144-linux-x64.tar.gz,Scala安裝包采用scala-sdk-2.11.8.tar.gz,Hadoop安裝包采用hadoop-2.7.2.tar.gz。安裝過程中配置安全外殼協議(SSH)以便實現遠程無密碼登錄與管理。完成Hadoop集群的配置安裝后進行Spark的安裝,Spark安裝包采用Spark-2.1.1-bin-hadoop2.7.tgz,軟件開發環境采用IntelliJIDEA 2019.2.4。
3? 推薦系統與協同過濾推薦算法(Recommendation system and collaborative filtering recommendation algorithm)
推薦系統需要大量的數據作為支撐,和搜索引擎[12]一樣,它需要挖掘和解析用戶歷史的行為數據,盡可能地知曉用戶的個性化需求,進而主動為用戶提供所需信息,給用戶的興趣建模[13-14]。
協同過濾推薦算法[15-17]是根據用戶行為數據設計的較早的著名推薦算法。協同過濾推薦算法可以分為基于用戶的協同過濾算法[18]和基于物品的協同過濾算法[19]兩類。基于用戶的協同過濾算法的主要思路是首先確立目標用戶并找出與他相似興趣的用戶,在不考慮他們皆感興趣部分的前提下,將相似用戶感興趣的內容推薦給目標用戶,適用于用戶較少的場合,比如新聞推薦。基于物品的協同過濾算法主要是通過分析用戶的歷史行為記錄找出與之相似的物品,將這一類物品推薦給用戶,適用于物品數遠小于用戶數的場合,比如圖書、電子商務。
4? ?基于模型的實時推薦算法(Model-based real-time recommendation algorithm)
實時推薦結果反映了用戶最近一段時間的偏好[20-21],用協同過濾推薦算法已經不足以滿足實時的需求,本文提出了基于模型的實時推薦算法,其主要思路是根據預先設定的模型來完成推薦。算法設計如下:
當電影q被用戶u評分時,將對u的推薦結果進行實時更新。此時,推薦結果會產生改變,把和電影q極為近似的K 個電影挑選出來,將它們標記為備選電影。每個備選電影被推薦的先后順序取決于“推薦優先級”的權重,它們會通過用戶u最近時間內的評分,分別計算出各自的推薦優先級,根據計算出來的結果同上一次的推薦結果進行歸并和更換,得出最終的實時推薦結果。詳細過程如下:
按照時間先后順序,得到用戶u最近的K 個評分,表示為RK;對于電影q,將S記為與其最為近似的K 個電影的集合;之后計算每個電影的推薦優先級,公式如式(1)所示。
電影q和電影r之間的相似度用來表示,為了計算簡便,將最小相似度的閾值設置為0.7。兩個電影之間相似度如果低于0.7,則表示它們沒有關聯,不予考慮;代表的是在RK中,不但與電影q相似,而且自身評分大于等于3的電影數量;RK中評分低于3,與電影q相似的電影數量則用來表示;是在RK中符合最小閾值條件的電影數量;其中在計算過程中用到了一種改進的余弦相似度公式,計算公式如式(2)所示。
其中,表示電影的兩兩相似度,u代表用戶。由于存在熱門電影,很多用戶都很喜歡,這樣計算的相似度就會很大,因此會造成任何電影都會和熱門電影有很大的相似度。還有一種情況是,用戶看很多電影并不都是出于自身的興趣,雖然活躍,但是有可能是職業需要,而且這些電影覆蓋了很多領域,所以這個用戶對于他所看過的電影的兩兩相似度的貢獻應該遠遠小于一個只看了幾部自己喜歡的電影但是不活躍的用戶。公式針對熱門電影和活躍用戶進行了一定的懲罰。
在每個備選電影q中,從用戶u的最近K 個評分之中,發現和電影q相似度大于等于0.7的電影,將發現的每個電影r與備選電影q之間的相似度乘上r自身的評分,然后進行加權求和,得出用戶u對電影q評分的預測值。在用戶u評分的K 個電影中,將與電影q相似并且評分值大于等于3的電影數量標記為,而評分值小于3的電影數量標記為。用作電影q的“強化因子”,其作用是表示在用戶u評分過的K 個電影當中,評分值大于等于3且與電影q相似的個數,那么需要根據相似的個數相應地去增加電影q的推薦優先級,如果其中相似的高評分電影越多,那么電影q被推薦的可能性越大;反之其被推薦的可能性比較小。用作電影q的“弱化因子”,作用是表示在用戶u評分過的K 個電影當中,評分值小于3且與電影q相似的個數,則需要根據近似的個數相應地去減少電影q的推薦優先級,如果其中相似的低評分電影有很多,那么不推薦電影q的可能性較大。
最終通過公式(1)計算出用戶u的每個備選電影q的推薦優先級,并且形成一個電影
在Spark上實現算法時,首先計算電影相似度矩陣,會為用戶、電影分別生成最終的特征矩陣。用戶特征矩陣為矩陣,每個用戶由 個特征描述;物品特征矩陣為矩陣,每個物品由 個特征描述,將它們保存在MongDB中。再計算每一個用戶最近對電影的K 次評分,存儲在Redis中。接下來讀取數據庫的數據,計算備選電影的推薦優先級,更新對userId的實時推薦結果。流程圖如圖2所示。
5? ?實驗結果分析(Analysis of experimental results)
5.1? ?實驗數據集
本文使用公開MovieLens數據集,在Spark平臺和單機系統分別對比實時推薦算法在相似度修改前和修改后(實時推薦算法-l),以及基于物品的協同過濾算法在相似度修改前(ItemCF)和修改后(ItemCF-l)的推薦效果。此處選擇的數據大小為10 MB,共10,000 部電影、72,000 名用戶及1,000萬條評分數據。評分取值為1—5,得分越高,用戶對電影的評價越高。
5.2? ?評測標準
實時推薦算法的評價標準一般包括推薦時間效率、推薦質量和推薦多樣性,它們分別反映了推薦算法的實時響應、推薦性能和推薦過程中用戶的個性化請求。其中,推薦時間效率通過執行算法的時間來衡量,推薦的質量可以通過準確率和召回率來衡量[22-23]。
準確率:推薦正確的電影數量占推薦電影總數的比例,公式如式(3)所示。
召回率:在推薦結果中滿足用戶要求的電影數量占所有滿足要求的電影數量之比,公式如式(4)所示。
其中,是基于用戶在訓練集上的行為向用戶做出的推薦列表,是測試集上的用戶行為列表。
5.3? ?實驗結果與分析
論文選擇Recall和算法執行時間作為推薦算法的評測標準。實驗隨機取數據集中的80%作為訓練集,20%作為測試集。分別計算四種算法的Recall值和執行時間,經過八次計算,結果如圖3和圖4所示。
由此可以看出,本文提出的算法效果要比傳統的協同過濾算法在性能上有較大的提升。Spark平臺推薦算法并行化實現,實時推薦算法的部分運行結果如圖5所示。根據顯示的結果,推薦算法成功地將用戶的隱式行為與實際行為結合起來,可以根據用戶的當前反應進行實時推薦,推薦結果更符合用戶的當前意圖。
6? ?結論(Conclusion)
本文提出了實時推薦算法并且設置了一種改進的余弦相似度公式,以減少活躍用戶對相似度的干擾。與傳統推薦算法相比,真實數據集的實驗檢驗了該算法在電影實時推薦中的準確性與時效性。但是,模型在評價指標的提升上沒有達到預期,這可能是模型的調參問題,或推薦模型的選擇問題,或特征工程不夠完善的問題,有待于進一步研究。
參考文獻(References)
[1] 陳瑋瑜.互聯網時代信息超載問題研究[J].傳播力研究,2019,3(08):243.
[2] 李學超,張文德,曾金晶,等.推薦系統領域研究現狀分析[J].情報探索,2019,26(01):112-119.
[3] 劉君良,李曉光.個性化推薦系統技術進展[J].計算機科學,2020,47(07):47-55.
[4] 周萬珍,曹迪,許云峰,等.推薦系統研究綜述[J].河北科技大學學報,2020,41(01):76-87.
[5] 嚴磊,汪小可.基于Spark流式計算的實時電影推薦研究[J].軟件導刊,2019,18(05):44-48.
[6] CHEN M, MAO S W, LIU Y H. Big data: A survey[J]. Mobile Networks and Applications, 2014, 19(2):171-209.
[7] 蔡江輝,楊雨晴.大數據分析及處理綜述[J].太原科技大學學報,2020,41(06):417-424.
[8] 孫麗.常見大數據處理框架比較研究[J].電腦知識與技術,2020,16(12):3-5.
[9] 宋泊東,張立臣,江其洲.基于Spark的分布式大數據分析算法研究[J].計算機應用與軟件,2019,36(01):39-44.
[10] 須成杰,肖喜榮,張敬誼.基于Spark的大數據分析平臺的設計和應用[J].中國衛生信息管理雜志,2019,16(05):633-637.
[11] 唐未香,吳學楊,劉科峰.Spark分布式集群的搭建[J].福建電腦,2020,36(02):102-104.
[12] GUEVARA S. Improve your search engine experience[J]. Information Today, 2020, 37(7):20.
[13] 周雪梅.用戶興趣建模支持下的行為推薦算法特性分析[J].現代信息科技,2019,3(09):11-13.
[14] 楊李婷,陳翰雄.用戶興趣建模綜述[J].軟件導刊,2015,14(10):20-23.
[15] 翁小蘭,王志堅.協同過濾推薦算法研究進展[J].計算機工程與應用,2018,54(01):25-31.
[16] ZHANG F, GONG T, LEE V E, et al. Fast algorithms to evaluate collaborative filtering recommender systems[J]. Knowledge-Based Systems, 2016, 96(15):96-103.
[17] TAO J H, GAN J H, WEN B. Collaborative filtering recommendation algorithm based on Spark[J]. International Journal of Performability Engineering, 2019, 15(3):930-938.
[18] 蔣宗禮,于莉.基于用戶特征的協同過濾推薦算法[J].計算機系統應用,2019,28(08):190-196.
[19] 焦富森,李樹青.基于物品質量和用戶評分修正的協同過濾推薦算法[J].數據分析與知識發現,2019,3(08):62-67.
[20] 李亞欣,蔡永香,張根.結合實時推薦與離線推薦的推薦系統[J].計算機系統應用,2019,28(10):45-52.
[21] 劉宇,周虎.基于Spark Streaming實時推薦系統的研究與設計[J].計算機與數字工程,2020,48(05):1172-1175.
[22] 朱郁筱,呂琳媛.推薦系統評價指標綜述[J].電子科技大學學報,2012,41(02):163-175.
[23] DUBE K, KAVU T D, RAETH P E, et al. A characterisation and framework for user-centric factors in evaluation methods for recommender systems[J]. International Journal of ICT Research in Africa and the Middle East, 2017, 6(1):1-16.
作者簡介:
牛路帥(1997-),男,碩士生.研究領域:大數據,推薦系統.
彭? ?龑(1967-),男,博士,教授.研究領域:計算機應用.
