融合評分和社會標簽的卷積神經網絡推薦模型研究
2021-09-13 02:27:43鄭東霞
軟件工程 2021年9期


摘? 要:基于線性模型的矩陣分解推薦算法對信息的特征提取單一,當用戶和物品含有大量隱含信息時,無法滿足用戶需求的個性化推薦。針對此問題,提出一種評分和社會標簽融合的卷積神經網絡推薦算法,該算法能夠根據上下文信息,利用非線性模型提取隱含高階信息,處理復雜且稀疏的數據。首先,設計由兩路由多層感知器和卷積神經網絡組成的深層網絡結構,分別實現利用社會標簽信息和用戶評分信息建模用戶興趣和項目信息的潛在特征向量;然后,構建對多層神經網絡學習后的結果進行融合的輸出層,得出預測結果;最后,運用真實數據集進行實驗驗證。結果表明,該算法與當前主流的推薦模型相比,能更好地利用社會標簽信息進行精準推薦。
關鍵詞:評分;社會標簽;卷積神經網絡;推薦模型
中圖分類號:TP391.3? ? ?文獻標識碼:A
文章編號:2096-1472(2021)-09-28-04
Abstract: Matrix factorization recommendation algorithm based on linear model extracts single characteristics of information. It cannot meet user's need for personalized recommendation when users and items contain a large amount of hidden information. Aiming at this problem, this paper proposes a convolutional neural network recommendation algorithm combining rating and social tags. The algorithm can extract hidden high-order information using a nonlinear model based on context information, and process complex and sparse data. First, a deep network structure composed of two-route multi-layer sensors and convolutional neural networks is designed, which realizes the use of social tag information and user rating information to model the potential feature vectors of user interests and item information. Then, a multi-layer neural network after learning is built, and the fusion output layer is used to obtain the prediction result. Finally, the real data set is used for experimental verification. The results show that compared with the current mainstream recommendation models, the proposed algorithm can better utilize social tag information for accurate recommendation.
Keywords: rating; social tag; convolutional neural network; recommendation model
1? ?引言(Introduction)
隨著社會化網絡的迅速發展,網絡上充斥著各個領域的海量數據,信息過載問題日益嚴峻。推薦系統已經成為確保用戶在網絡中快速獲取所需信息的一個重要技術手段,也是當前世界各國學者及工業界研究的一個熱點問題。近些年,一些人工智能、機器學習、數據挖掘等領域的重要學術會議已經將推薦系統列為其中的一個重要研究方向,推薦技術得到前所未有的發展。
推薦系統的發展主要經歷了三個階段:基于內容的推薦、協同過濾推薦及基于深度學習的推薦。傳統的基于內容的推薦主要根據上下文選擇資源描述相似的項目向用戶推薦。協同過濾推薦主要是依據用戶對項目的評分進行預測,矩陣分解技術在協同過濾過程中被廣泛應用。隨著深度學習技術逐漸應用在各個領域中,基于深度學習的推薦算法受到當前學者的廣泛關注。文獻[1]提出了基于用戶評論的深度情感分析和多視圖協同融合的混合推薦算法。該算法使用用戶對物品的評分數據、隱式反饋信息等對用戶進行情感分析,利用對物品的文本描述計算物品相似性,在此基礎上構建基于協同訓練的混合推薦算法。文獻[2]提出一種深度學習模型,該模型從用戶評論和商品評論文本中提取用戶和商品的潛在非線性特征向量,將其與隱向量融合來預測用戶對商品的評分。文獻[3]提出一種基于卷積神經網絡與約束概率矩陣分解的推薦算法。該算法運用卷積神經網絡模型對項目特征矩陣進行初始化,利用約束概率矩陣對用戶特征矩陣進行初始化,最后擬合評分矩陣來預測用戶對項目的評分。文獻[4]建立了改進神經協同過濾模型,利用多層感知機的非線性特征處理提取隱含高階特征的信息,以及利用貝葉斯個性化排序算法提取排序信息,結合電影流行度和電影類型因子進行推薦得分。以上推薦系統模型引入了深度學習,利用文本和評分建立了非線性特征向量,但是在特征提取過程中,并未考慮用戶評論的時效性,因為用戶的興趣會隨著時間推移、年齡增長、環境變化等而發生變化。因此,本文提出一種融合社會標簽和評分的卷積神經網絡模型DSR-CNN(Dynamic Social Tag and Rating-Convolutional Neural Network)。
2? ?相關工作(Related work)
2.1? ?基于社會標簽的推薦方法
很多學者不僅使用評分數據進行推薦,還將隱式數據引入算法中,比如信任關系、社會標簽等,使得推薦效果大幅提升。文獻[5]提出了一種融合社會標簽的近鄰感知的聯合概率矩陣分解推薦算法。該算法通過標簽的相似性來計算用戶間和資源之間的相似性,進行近鄰選擇;然后構建用戶-資源評分矩陣、用戶-標簽標注矩陣、資源-標簽關聯矩陣,運用聯合概率矩陣分解方法計算三個矩陣的隱含特征向量,通過對訓練模型進行參數優化,為用戶進行推薦。文獻[6]提出了一種融合社會標簽和信任關系的社會網絡推薦方法。該方法利用概率因式分解技術實現了社會信任關系、項目標記信息和用戶項目評分矩陣的集成;從不同維度出發,實現了用戶和項目潛在特性空間的互聯;再通過概率矩陣因式分解技術實現降維,從而實現了有效的社會化推薦。文獻[7]提出一個融合社交行為和標簽行為的推薦算法。該算法用引力模型計算社交網絡中用戶節點之間的吸引力來度量用戶社交行為的相似性;再通過標簽信息構建用戶喜好物體模型,并使用引力公式計算喜好物體之間的引力來度量標簽行為的相似性;最后,引入變量融合兩方面信息,獲取近鄰用戶,產生推薦。
以上融合社會標簽的算法相對于傳統推薦算法,在推薦質量上有了顯著提高。但當用戶和物品含有大量隱含信息時,仍無法滿足用戶需求的個性化推薦,因此本文提出融合評分和標簽的卷積神經網絡推薦模型,以緩解冷啟動及數據稀疏問題。
2.2? ?融合卷積神經網絡的推薦方法
卷積神經網絡(CNN)是一類包含卷積計算且具有深度結構的前饋神經網絡,是深度學習的代表算法之一[8-9],其基本結構為四層:輸入層、卷積層、池化層、輸出層。輸入層用于獲取輸入信息;卷積層用于對輸入信息的特征提取;池化層用于減少參數和特征數量,提取關鍵特征,防止過擬合;輸出層用于將處理后的文本潛在特征向量輸出。CNN在計算機視覺領域的應用較為廣泛,近些年,學者們陸續將CNN運用到了推薦模型中的文本處理上,通過CNN提取隱式信息的特征,能夠對文本進行更深入的學習,提高推薦精度[10-11]。
文獻[12]提出融合動態協同過濾和深度學習的推薦算法,將時間因素融入協同過濾算法中,利用深度學習模型來學習用戶和電影特征信息,形成高維潛在空間的用戶特征和電影特征的隱向量,進而融合到動態協同過濾算法中進行推薦。文獻[13]為緩解推薦系統中數據稀疏性問題,提出一種改進CNN的局部相似性預測推薦模型LSPCNN。該模型對初始用戶-項目評分矩陣進行迭代調整,使用戶興趣偏好局部特征化,再融合CNN對缺失評分進行預測,從而實施個性化推薦。本文在以上工作基礎上進行改進,建立兩路神經網絡模型:一路網絡對以用戶ID檢索的評分矩陣和用戶標注的標簽信息進行訓練;另一路網絡對以項目ID檢索的評分矩陣和項目被標注的標簽信息進行深度學習,利用融合層對用戶特征偏好和項目特征信息進行融合輸出,進而提高推薦準確性。
3? DSR-CNN模型描述(DSR-CNN model description)
本文提出融合評分和標簽的卷積神經網絡模型DSR-CNN,其模型結構如圖1所示。本模型由四路并行的神經網絡組成。首先,其中兩路神經網絡從用戶角度和項目角度分別運用多層感知器對評分矩陣的行向量信息和列向量信息進行提取,進而獲得用戶評分潛在特征向量和項目評分潛在特征向量;另外兩路神經網絡使用卷積神經網絡分別對用戶標注的標簽信息、項目標簽信息進行深度學習,從而獲得用戶標注標簽潛在特征向量和項目標簽潛在特征向量。其次,將用戶評分和用戶標注標簽潛在特征向量融合得到用戶特征的矩陣;將項目評分和項目標簽潛在特征向量融合得到項目特征矩陣。第三,將上一步驟的結果輸入融合層,再進行預測評分輸出。本文僅講解如何運用多層感知器及CNN提取用戶特征,由于項目特征提取過程與用戶特征提取過程類似,因此不再贅述。
3.1? ?用戶動態特征提取模塊
3.1.1? ?用戶評分潛在特征向量提取
用戶評分潛在特征向量提取包括評分矩陣輸入層、特征向量層、多層MLP層、輸出層。假設有 個用戶、 個項目,分別表示為,。用戶-項目評分矩陣記為,表示用戶對項目的評分,當用戶對項目無評分時,=0;矩陣中行數據代表用戶對每個項目的評分,列數據代表項目獲得的用戶評分。代表用戶潛在特征矩陣,代表項目潛在特征矩陣,向量表示用戶的維特征向量,表示項目的維特征向量。獲得了用戶評分特征向量后,將其作為輸入數據輸入多層感知器(MLP)中,經過MLP深度學習獲得用戶潛在特征向量,各層MLP學習后的輸出結果表示如式(1)所示。
其中,是用戶經過MLP學習的評分特征向量,是第個評分矩陣,為第個偏置,為MLP中的隱藏層數,是非線性激活函數。
3.1.2? ?用戶標注標簽潛在特征向量提取
通常,用戶在網絡上對喜歡的資源標注標簽,標簽的信息能夠反映出用戶的喜好。因此本文利用CNN提取用戶標注標簽信息,進而建立用戶特征矩陣。用戶標注標簽潛在特征向量提取包括標簽矩陣輸入層、嵌入層、用戶標注標簽特征向量層、池化層、輸出層,其框架圖如圖2所示。
用戶標注標簽潛在特征向量提取模塊首先利用詞嵌入技術將標簽的稀疏矩陣向量映射為稠密矩陣向量,然后使用卷積神經網絡(CNN)來提取標簽信息的語義特征。假設有 個標簽,用戶標注標簽矩陣記為,表示用戶標注的標簽。用戶對項目標注標簽記為,其中是標簽中第 個文本的詞嵌入向量,嵌入層將標簽表中的每個詞映射到維的向量中,。如果同一個標簽出現多次,則相同標簽共享嵌入內容,因此利用文本嵌入方法將每個標簽轉換成詞嵌入矩陣,其中表示文本長度。
CNN中的卷積層用來從標簽文本中提取語義特征向量。假設有個卷積濾波器,分別表示為,每個濾波器的輸入參數均由矩陣構成,其中表示濾波器窗口的大小,表示向量維度。第個濾波器在嵌入矩陣上的卷積計算結果如式(2)所示。
其中,代表非線性激活函數,代表卷積運算,是的偏差參數。第個濾波器產生的標簽特征向量,然后使用H卷積濾波器獲取多種特征,公式如式(3)所示。
池化層的作用主要是提取通過卷積層得到的特征向量中的最大值,本文利用最大池化方法獲取最重要的信息,操作如式(4)所示。
之后進入全連接層,即將用戶評分特征向量和用戶標簽特征向量采用加權處理得到用戶的潛在特征向量表示,其操作定義如式(5)所示。
3.2? ?融合模塊和預測輸出模塊
多層感知器學習得到用戶評分矩陣,卷積神經網絡學習得到用戶標注標簽矩陣,兩者融合得到用戶深度特征向量,融合公式如式(6)所示。
同理,分別經過感知器學習和卷積神經網絡計算得到項目被評分矩陣和項目被標注標簽矩陣,兩者融合得到項目深度特征向量,融合公式如式(7)所示。
利用公式(8)對用戶深度特征向量和項目深度特征向量進行融合得到預測值。
公式(8)中,為激活函數,該函數用于更好地學習用戶和項目之間的非線性關系;為權重矩陣,用于學習各種向量之間的聯系程度。
3.3? ?模型損失函數
對項目進行預測評分的任務實質上是回歸問題,本文利用平方損失函數訓練模型來優化參數,采用正則化項以避免過度擬合,損失函數如式(9)所示。
其中,表示待訓練實例的集合,表示用戶對項目的真實評價,表示正則化項的常數參數,表示模型中的所有未知參數集合。
4? ?實驗分析(Experiment analysis)
4.1? ?數據集
MovieLens數據集是研究機構GroupLens從http://movielens.org網站在不同的時間段收集并提供的評級數據集。該數據集描述了電影推薦服務的5星評分和自由標注標簽活動。MovieLens 20 MB數據集中包含27,278 個電影中的20,000,263 個評分和465,564 個標簽應用,以上數據由138,493 位用戶參與生成。
用戶對電影評分數據的稀疏度為:
用戶對電影標注標簽數據的稀疏度為:
實驗選取數據集中比例分別為8∶1∶1和7∶1∶2的數據作為訓練數據、驗證數據和測試數據,驗證不同稀疏度的情況下推薦模型的準確性。
4.2? ?評價指標
RMSE(Root Mean Squared Error)被稱為均方根誤差,也叫標準誤差。文中實驗采用RMSE作為評價指標來衡量預測推薦評分的誤差。其公式表示如式(10)所示。
式(10)中,表示測試數據集中的記錄個數,表示本文模型計算的預測評分,表示數據集中的用戶實際評分。
4.3? ?對比算法
本文與以下四種算法進行實驗結果對比分析。
(1)RA1[14],提出了一種基于張量Tucker分解和列表級排序學習的個性化標簽推薦算法,采用優化MAP的方式進行訓練,實現根據用戶喜好進行推薦。本文中將此推薦算法記為RA1。
(2)DeepCoNN[15],提出基于一種神經網絡的模型,一種是從某個用戶的評論中學習到該用戶的喜好;另一種是從所有用戶對某個商品的評論中學習到該商品的特征和特點。用戶和項目學習的潛在特征用于在兩個網絡頂部引入的層中預測相應的等級。
(3)TTMF[16],該模型為融合標簽和時間信息的矩陣分解推薦模型,通過評級數據和標簽信息構建用戶、項目、標簽三者之間的矩陣模型,進而使用梯度下降方法進行推薦計算。
(4)RA2[17],提出了一種用于前N 個項目推薦的新穎方法,該方法使用三種不同類型的信息:用戶項目評分數據、用戶之間的社交網絡以及與項目相關聯的標簽。通過上面三種信息進行優先級計算,實現推薦。
4.4? ?結果分析
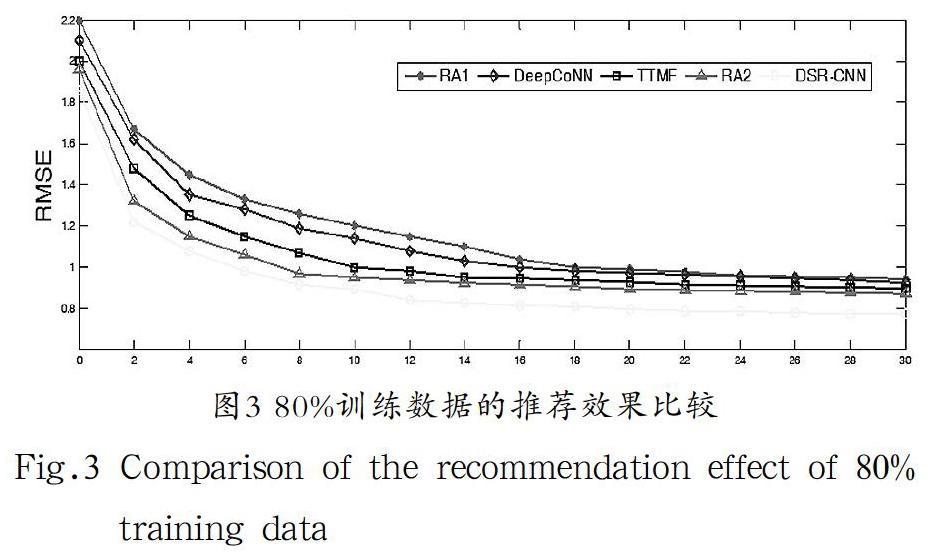
圖3顯示了80%數據作為訓練數據、10%數據作為驗證數據、10%數據作為測試數據情況下,本文算法與RA1、DeepCoNN、TTMF、RA2四種算法計算結果的RMSE比較圖。從圖3中可以看出,本文提出的算法DSR-CNN性能要優于其他模型,特別在數據稀疏的情況下,DSR-CNN算法也能夠較好地進行推薦。綜上所述,融合評分和標簽的卷積神經網絡推薦模型,當用戶數據稀疏的情況下,能夠根據用戶和項目信息學習潛在的影響因素,從而進行更有效的推薦。
5? ?結論(Conclusion)
本文提出了一種融合用戶評分和用戶標注標簽信息的卷積神經網絡推薦模型。模型通過建立由兩路由多層感知器和卷積神經網絡組成的深層網絡結構,分別實現利用社會標簽信息建模用戶動態興趣和項目信息的潛在特征向量;模型能夠充分根據上下文語境信息提取隱含高階信息,進而解決稀疏數據的推薦問題。文中采用MovieLens 20 MB數據集對模型的推薦效果與其他四種算法進行了實驗比較,實驗結果表明該模型能夠有效地根據用戶的偏好進行個性化推薦。
參考文獻(References)
[1] 張宜浩,朱小飛,徐傳運,等.基于用戶評論的深度情感分析和多視圖協同融合的混合推薦方法[J].計算機學報,2019,042(006):1316-1333.
[2] 馮興杰,曾云澤.基于評分矩陣與評論文本的深度推薦模型[J].計算機學報,2020,043(005):884-900.
[3] 馬海江.基于卷積神經網絡與約束概率矩陣分解的推薦算法[J].計算機科學,2020(S1):540-545.
[4] 王駿,虞歌.基于改進神經協同過濾模型的電影推薦系統[J].計算機工程與設計,2020,041(7):2069-2075.
[5] 曹玉琳,李文立,鄭東霞.融合社會標簽的聯合概率矩陣分解推薦算法[J].信息與控制,2017(4):400-407.
[6] 胡云,張舒,李慧,等.融合社會標簽與信任關系的社會網絡推薦方法[J].數據采集與處理,2018,033(004):704-711.
[7] 李慧,馬小平,胡云,等.融合社會網絡與信任度的個性化推薦方法研究[J].計算機應用研究,2014(03):808-810.
[8] HEATON J. Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning[J]. Genet Program Evolvable Mach, 2018(19):305-307.
[9] GU J X, WANG Z H. Recent advances in convolutional neural networks[J]. Pattern Recognition, 2018, 77(01): 329-353.
[10] LIU H, WANG Y, PENG Q, et al. Hybrid neural recommendation with joint deep representation learning of ratings and reviews[J]. Neurocomputing, 2020, 374(1):77-85.
[11] HUANG Z H, SHAN G X, CHENG J J, et al. TRec: An efficient recommendation system for hunting passengers with deep neural networks[J]. Neural Computing and Applications, 2019, 31(1):209-222.
[12] 鄧存彬,虞慧群,范貴生.融合動態協同過濾和深度學習的推薦算法[J].計算機科學,2019,046(008):28-34.
[13] 吳國棟,宋福根,涂立靜,等.基于改進CNN的局部相似性預測推薦模型[J].計算機工程與科學,2019,041(006):1071-1077.
[14] 楊洋,邸一得,劉俊暉,等.基于張量分解的排序學習在個性化標簽推薦中的研究[J].計算機科學,2020,47(S2):525-529.
[15] HAN J, ZHENG L, XU Y, et al. Adaptive deep modeling of users and items using side information for recommendation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019(99):1-12.
[16] 趙文濤,任行學.融合標簽信息和時間效應的矩陣分解推薦算法[J].信息與控制,2020,49(4):472-477.
[17] BANERJEE S, BANJARE P, PAL B, et al. A multistep priority-based ranking for top-N recommendation using social and tag information[J]. J Ambient Intell Human Comput, 2021(12):2509-2525.
作者簡介:
鄭東霞(1978-),女,碩士,副教授.研究領域:機器學習,推薦系統.
