基于服務網格的微服務故障治理
2021-09-14 02:33:56李銘軒
信息通信技術 2021年4期
趙 鑫 李銘軒
1 北京郵電大學 北京 100876
2 中國聯通研究院 北京 100048
引言
在傳統代碼架構中,隨著新功能的增加,代碼庫會越變越大。盡管代碼被分成各個模塊,但隨著時間推移,這些界限將變得模糊。代碼之間功能類似的模塊將越來越多,維護將變得越來越困難[1]。相對于傳統軟件,微服務是一種新型架構方式。它提倡將單一應用程序劃分成一組小的服務,每個服務獨立完成一個很小的功能。服務之間相互協調、互相配合,為用戶提供最終價值。每個服務運行在其獨立的進程中,服務和服務之間采用輕量級的通信機制(通常是基于HTTP的Restful API)相互溝通[2]。但微服務架構下軟件穩定性不夠強,故障率相對較高,且故障原因復雜,微服務的故障治理一直是一個很大的挑戰。
容器是一種虛擬化技術,相比于VM,具有更好的性能,更輕量和更好的擴展性[3]。每個容器上運行一個進程,容器內打包這個進程所需要的所有依賴環境,擁有良好的移植性。容器之間彼此獨立運行,負責單一的功能。容器間也可以相互配合,相互調用,完成更大的功能。容器技術的特點使它與微服務架構完美適配。這里也使用容器技術實現微服務架構。
服務網格是用于處理服務與服務之間通信的專用基礎設施層。其主要思路是為每個微服務實例(往往以容器形式)都設置反向代理組件,即Sidecar。所有進出微服務的流量會被Sidecar劫持,通過該組件進行處理和轉發[4]。服務網格在不侵入業務代碼的情況下可以完成對微服務集群的監控,為微服務故障治理提供了新的解決思路。本文基于服務網格技術,對于微服務軟件進行管理,深入探討微服務的故障特點,提出一套完善的治理方案。
1 微服務的故障問題分析
微服務帶來靈活性的同時,也使得架構變得復雜,原本一個單體軟件被分解成上百個微服務,微服務之間調用關系復雜[5],服務之間協作也容易受到網絡層影響,這對故障的治理提出了很高的要求。微服務故障治理主要體現在以下幾個方面。
1.1 故障定位困難
一個大型的應用程序被拆分成幾十甚至上百個微服務,分布在多臺服務器上。各個微服務之間相互協作,一層層進行調用,調用拓撲異常復雜。故障可能是某個微服務實例內部發生故障(計算錯誤、返回數據錯誤),可能是多個實例之間交互錯誤(如實例運行順序不對),也有可能是環境因素(如網絡延時,使得請求無法及時響應;配置錯誤,JVM配置和容器配置不一致)。
故障還可以分成功能性故障和非功能性故障,功能性故障會導致運行結果的錯誤,非功能性故障會使服務性能、穩定性下降[6]。相比于功能性故障,非功能性故障更為隱秘,更不容易被發現。總之,在微服務架構下,故障的種類繁多且原因復雜,定位也十分困難,尤其是在幾百臺服務器組成的大型集群中。
1.2 服務集群穩定性低
在單一架構的軟件中,各個功能的協作在設計和開發之初就被設計好,大多數問題能夠在最初開發時被規避。當軟件被拆分成一個個小的服務時,服務之間、服務組件之間層層依賴,一個服務組件出現故障或者因為網絡層發生故障無法通信,會影響到所有與它協作的服務組件,導致這些組件積累大量請求,最終不可用,形成雪崩式的崩潰。
例如,上游發來一次請求,為了完成這個任務,組件中形成了一系列的調用。這些調用將服務組件連接在一起,稱之為調用鏈[7]。假設每次調用服務出故障概率為Fone,整條調用鏈上出現故障的概率Fall,則Fall=1-(1-Fone)n,其中n為調用鏈長度。
如圖1所示,當調用鏈長度增加時,即使單個服務出現故障的概率極小,本次請求調用失敗的概率也會變得很大。
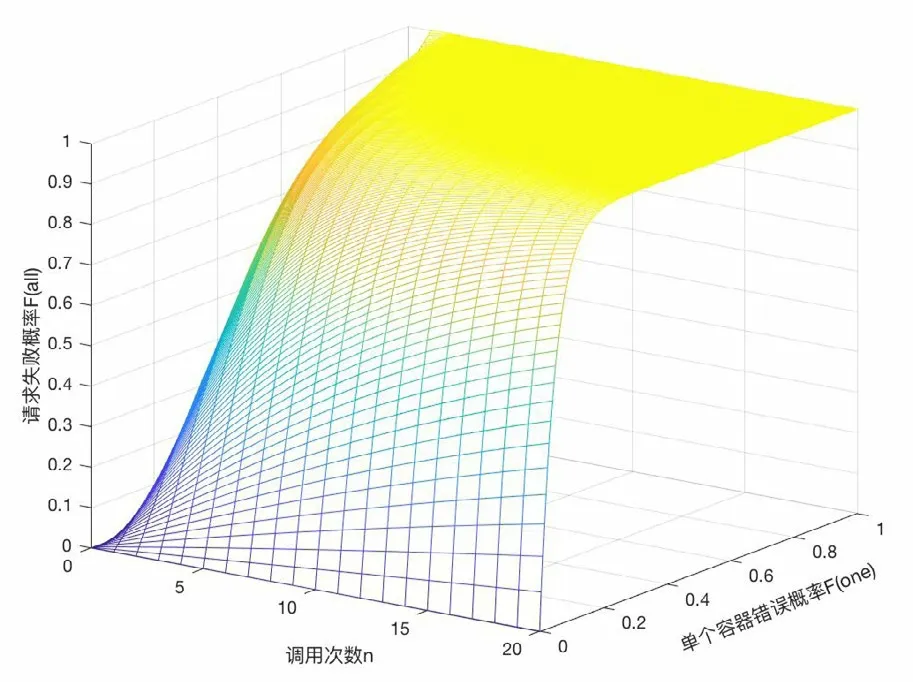
圖1 整體故障概率與調用鏈長度關系
考慮到每個類型的服務有m個備份均衡流量,如果某一個服務組件故障,請求會轉移到備份服務組件,每種類型的服務不可用的概率是:Ftype=Fonem,整條調用鏈Fall=1-(1-Ftype)n=1-(1-Fonem)n,圖2是每種服務分別只有1個、5個、10個備份實例的情況,當每種服務有多個備份時(m變大)能夠有效降低請求失敗的概率。但是在微服務架構中,上層服務需要通過網絡層調用下層服務。網絡層是脆弱的,很容易因為一些不可抗因素發生網絡連接失敗,或者服務沒有及時響應,使得上游一系列服務積壓了大量的請求,占用大量資源,Fone數值激增,導致整個集群雪崩式地崩潰。因此在生產環境下,需要及時發現故障位置,防止整個集群發生崩潰。
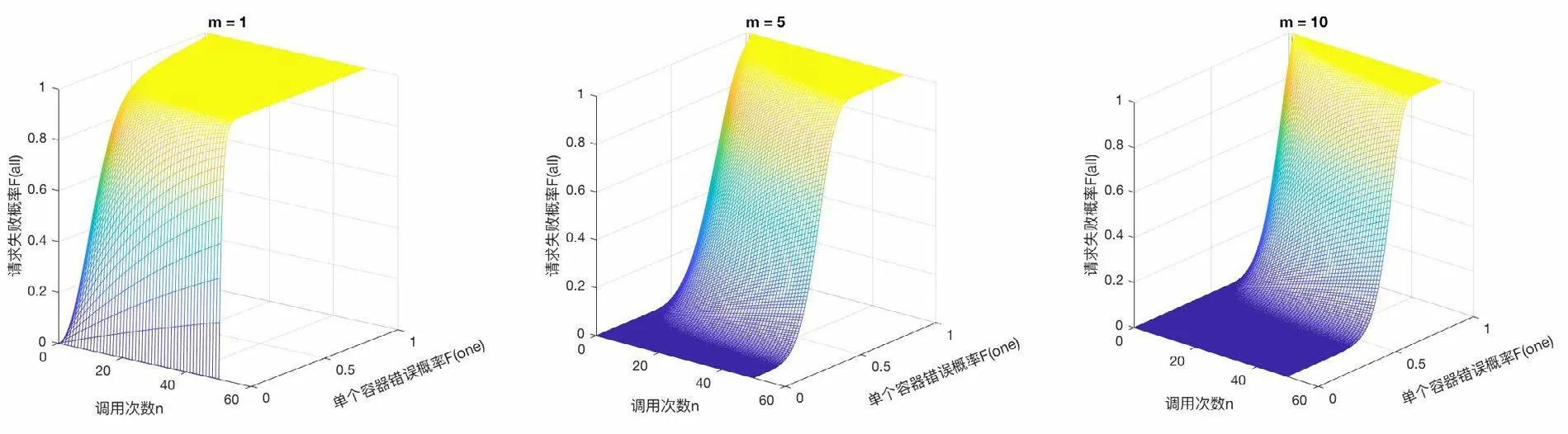
圖2 服務有備份時整體故障概率與調用鏈長度關系
1.3 微服務測試困難
測試對于提前發現錯誤,驗證軟件功能有著極其重要的意義,但是在微服務架構下,軟件被拆分成多個服務,需要為每個服務搭建測試環境,對每個服務功能進行驗證,過程繁瑣,消耗人力巨大。其次,微服務故障多在實例之間交互中產生,而且交互結果容易受到網絡層狀態(延遲、帶寬)影響。微服務本身和實例之間沒有固定的對應關系,服務實例在整個集群中動態地創建和銷毀。故障具有動態性,難以重現,測試環境下很難提前發現故障。
2 服務網格的簡介與選型
2.1 服務網格簡介
容器技術有很強的可移植性,一次打包隨處部署,相比于VM更加輕量級,啟動和銷毀十分容易[8],最重要的是容器之間能相互協作,共同完成更加復雜的任務。這些特點與微服務完美適配,目前工業界普遍以容器的形式部署微服務。如圖3所示,服務網格是在每個容器上增加一個反向代理Sidecar,所有進出容器的流量完全經過Sidecar,被Sidecar監控和控制。Sidecar構成了服務網格的Data Plane。比較新的服務網格在Data Plane的基礎之上增加Control Plane。Control Plane直接與Sidecar通信,將用戶策略轉發至Sidecar,實現對流量的更精準地控制。
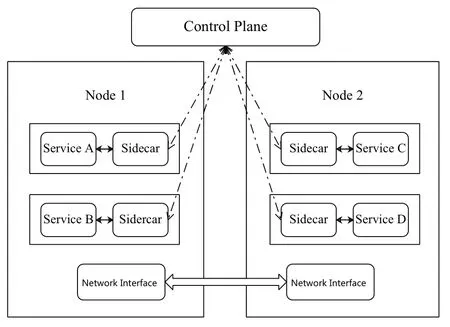
圖3 服務網格示意圖
2.2 服務網格優缺點及選型
服務網格在微服務實例上掛載代理,它與Spring Cloud、Dubbo這類侵入式框架不同,它與業務代碼耦合很小,業務代碼的技術選型、迭代升級都不會受到框架的制約[9]。服務網格有強大的監控功能,能夠提供四個黃金指標的監控(延遲、流量、錯誤、飽和),同時提供完善的日志功能,對于故障定位、原因分析有很大幫助。
但長期以來服務網格的性能被人詬病,消耗過多的系統資源的同時,對進出流量也造成了比較大的延時。而且伴隨服務網格強大功能的是較高的復雜性,要熟練運用服務網格需要投入一定的學習時間。
目前服務網格產品有很多,文章挑選了比較主流的幾款,分別是Istio、linkerd 2.0、Consul,AWS App Mesh和ASM。綜合比對他們的架構設計、支持的功能、安全性和操作復雜度四個方面的信息,如表1所示。
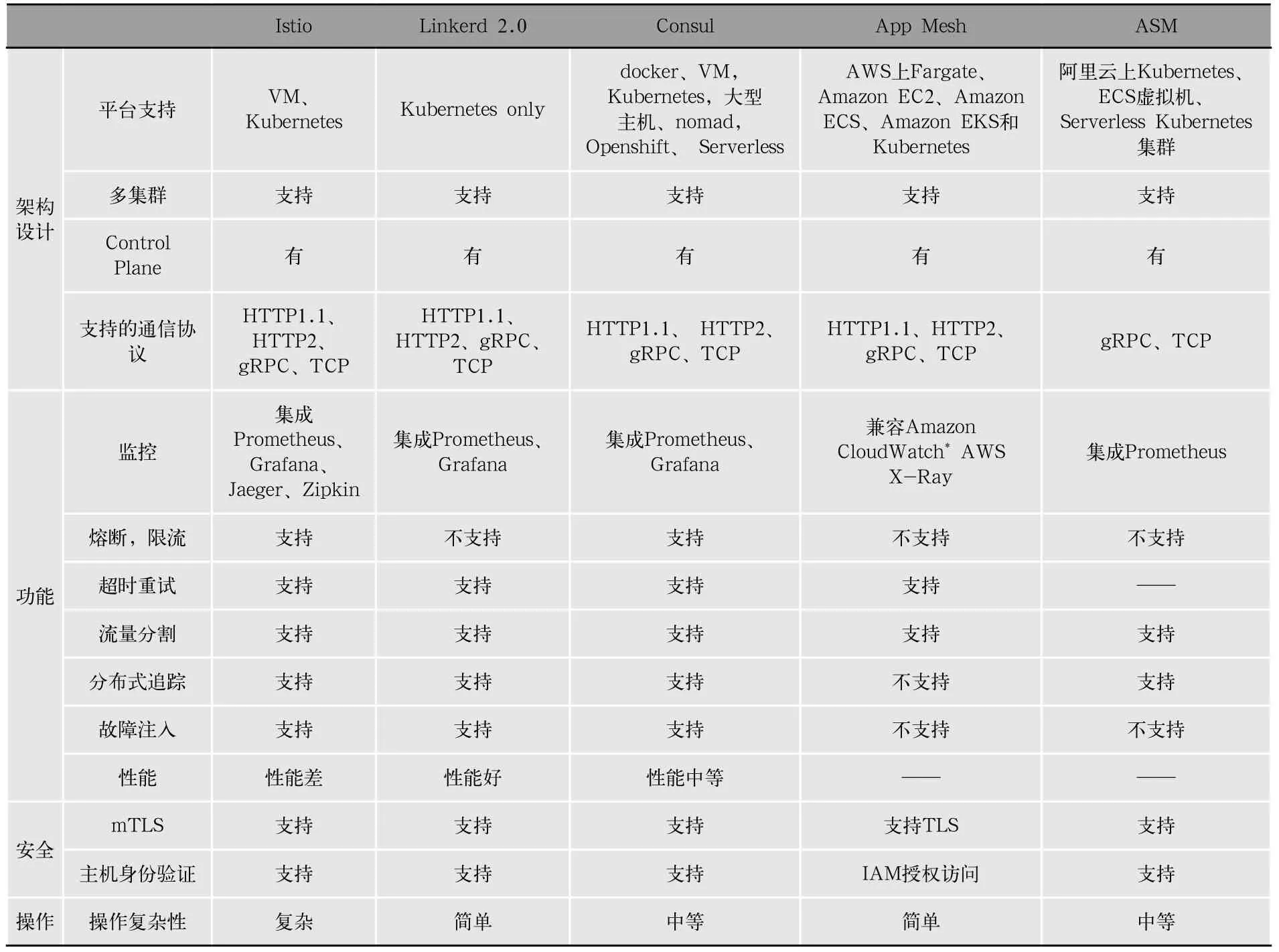
表1 服務網格軟件綜合對比
在各種服務網格產品中,Istio的功能最為強大,最為靈活。它提供流量管理、擴展性、安全和可觀察性四大方面功能,幾乎涵蓋微服務監控所有需求。Istio從1.6版本開始支持虛擬機節點,不再完全依賴Kubernetes平臺,能更好地適應異質架構的大型集群管理。同時Istio是一個開源項目,社區相比于其他的服務網格產品更加活躍,使用Istio作為微服務故障治理解決方案,更有代表意義。
3 故障檢測模型
3.1 故障檢測流程
整個故障預測流程如圖4所示。首先由手動點擊或者使用postman模擬發送http請求,得到正常情況下和故障注入情況下兩種數據,包括可視化監控圖、服務調用日志,各個容器運行指標如表2所示。

表2 容器采集指標
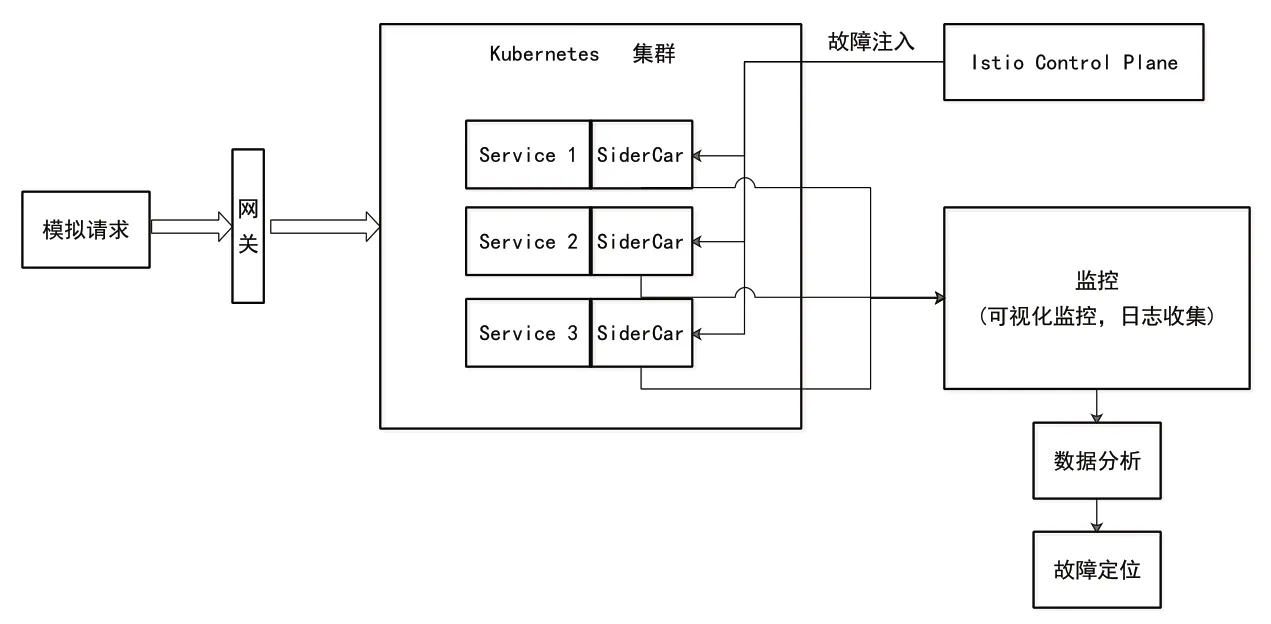
圖4 故障預測流程
最后將可視化監控圖、日志和容器運行時參數、定位故障,輸入故障預測模型,確定故障原因。
3.2 故障注入
使用Istio提供的HTTP abort功能,該功能可以攔截并丟棄所有到達某個容器的流量,使得該容器對其他容器處于不可達狀態。同時故障注入分為服務級別和容器級別故障注入。一種微服務往往有多個容器備份,服務級別故障注入,讓該服務所對應的所有容器全部處于故障狀態,用于服務級別的故障定位驗證;容器級別故障注入,讓該服務的某個容器處于故障狀態,用于容器級別的故障定位驗證。
3.3 故障服務定位
在微服務中,為了完成一個任務,微服務之間往往形成一個很長的調用鏈,這個調用鏈上任意一個服務失敗都會導致本次請求失敗。當故障出現時,表現的是請求結果無回應或者返回錯誤結果。但具體錯誤是出現哪個微服務上,需要消耗大量時間排查。這里提出調用鏈交叉累計法(Invoke Chain Intersection Accumulation Method,ICIAM)。在圖5中,綠色方塊代表正常服務,紅色方塊代表故障服務,灰色方塊代表因上游服務故障而導致下游故障的服務。

圖5 ICIAM示意圖
正常情況下,有三個請求,當某個服務出現故障時(紅色),會影響到兩條調用鏈。對每條出現故障的調用鏈上所有服務實例分數加1。分數最高的服務,往往是故障源頭。
3.4 故障容器定位
每種服務可能存在多個容器備份,需要確定具體故障是否出現在容器[10]。其次,調用鏈交叉部分服務可能不止一個,故障服務不一定會導致后續的服務不可用,使用ICIAM定位的故障源范圍較大,需要進一步縮小。Istio集成Prometheus,可以對每個容器數據進行監控,收集容器CPU、內存方面的數據。容器正常運行和故障時的各項metric特性會有很大差異,可以通過分析這些參數(如表2所示),得到故障容器位置。
4 實例研究
4.1 實驗環境描述
使用4臺8GB、4VCPU、操作系統為ubuntu18.04x64 的虛擬機,搭建kubernetes-1.17.5 集群。在Kubernetes集群基礎上,搭建Istio 1.6.8,對Kubernetes上運行的所有微服務實例進行管理。
4.2 實驗用例應用搭建
使用TrainTicket[11]軟件作為本次實驗測試用例,檢驗故障治理流程能否定位故障。這是由復旦大學實驗室基于微服務架構開發的應用。它是由41個微服務組成,使用了Java、Node.js、Python、Go、Mongo DB和MySQL多種語言和技術。雖然復雜程度不及工業界軟件,但是服務間技術獨立,服務互相配合,使用多種語言開發,幾乎體現了微服務架構下軟件所有特點,使用這款應用進行實驗具有一定的代表性。
4.3 實驗過程
使用Postman模擬ts-preserve-service:preserve;ts-travel-plan-service:getByMinStation;ts-travel-service:queryInfo;Ts-preserv-otherservice:preserve;Ts-travel-plan-service:getByCheapest多種操作,這些請求都會調用ts-seatservice,用來獲得交叉調用。每次請求有50ms延時,一共發送1 200次。使用Postman ts-travel-planservice:getByCheapest和ts-preserve-service:preserve兩種請求各300次,測試當服務在實際生產情況下,調用鏈種類不夠豐富的情況下能否定位故障。
使用Istio中集成的Jaeger,每次有請求發生時,將微服務之間調用關系,每個微服務所消耗時間以日志形式記錄。將服務的調用路徑、消耗時間等數據以json格式導出,同時Istio也支持微服務信息可視化,方便故障定位。
收集兩類數據集,一類是所有服務正常情況下的數據集,另外一類是故障注入下的數據集。使用Istio故障注入功能,調用ts-seat-service發生abort故障。請求到此類服務的HTTP請求,全部得到500的HTTP狀態碼。
4.4 驗證結果
4.4.1 ICIAM驗證錯誤服務環節
我們得到的正確數據集合一共是1 200次請求,錯誤數據集也是1 200次請求。每種數據集中包含以下請求,ts-preserve-service:preserve;Ts-travel-planservice:getByMinStation;Ts-travel-service:queryInfo;Ts-preserv-other-service:preserve;Ts-travel-planservice:getByCheapest。
無故障情況下每種請求一次請求所引起的總共調用次數,以及調用了ts-seat-service的次數如表3、表4所示。

表3 無故障時各類服務調用次數
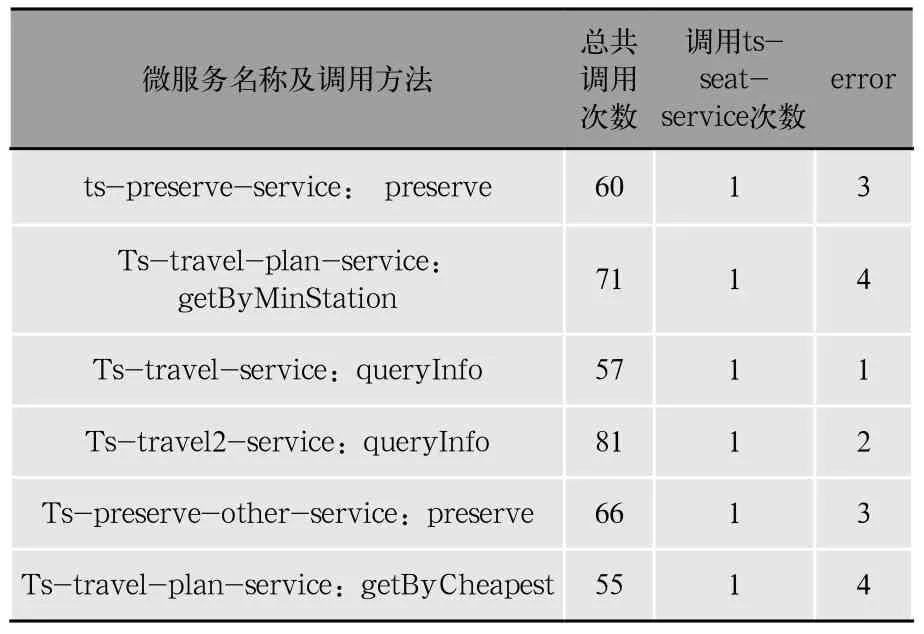
表4 ts-seat-service故障時服務調用次數
總的調用次數少了,因為當請求到達ts-seatservice故障位置時,得到錯誤響應,后續服務全部終止。ts-seat-service被調用的次數為1,因為到這里請求發生錯誤,調用終止。
如圖6所示,同時發起5種請求,使用ICCA算法得分最高的前5名服務如表5所示。
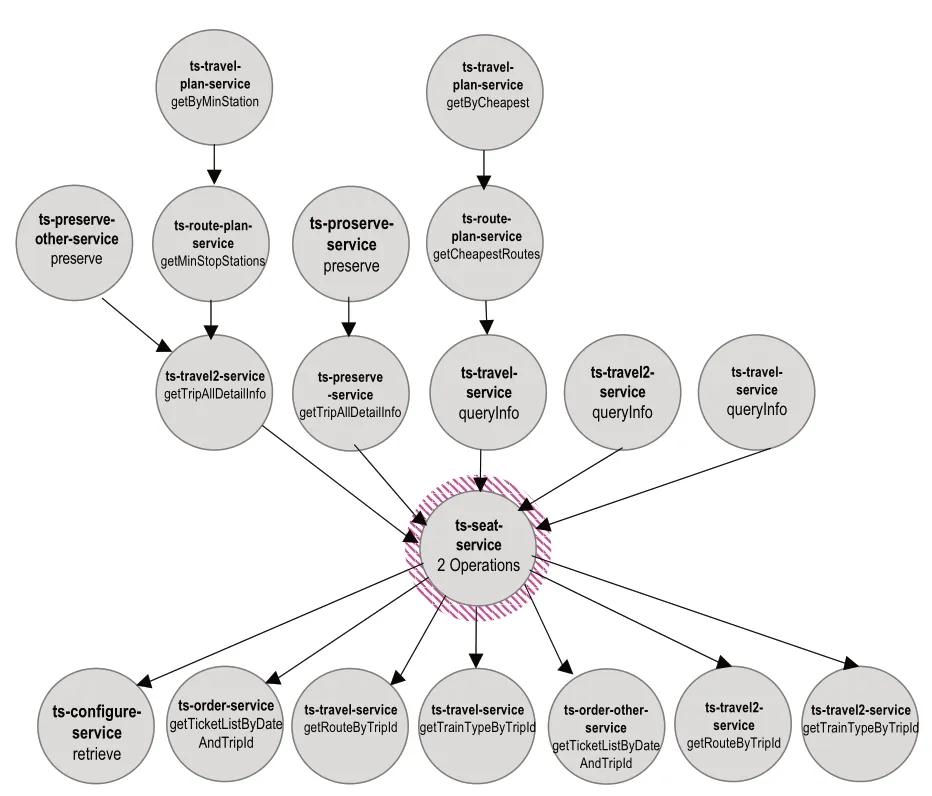
圖6 5種請求故障調用鏈示意圖
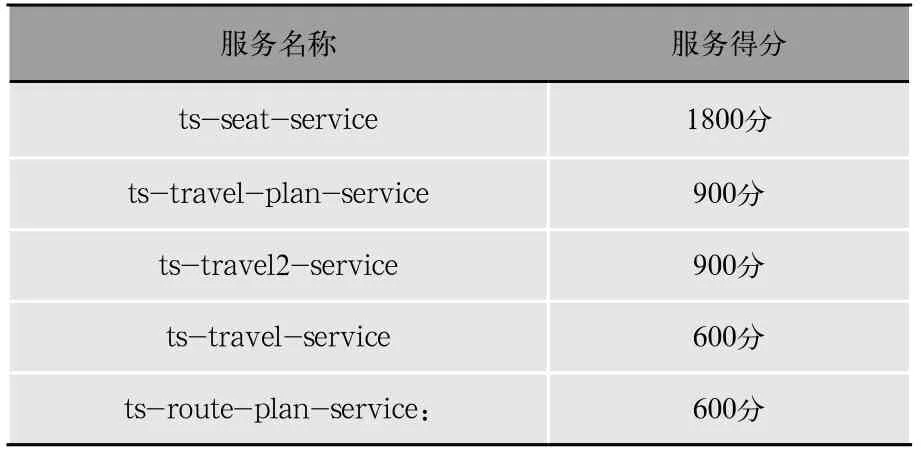
表5 5種請求時ICCA算法得分最高前5名服務
由于ts-seat-service是故障源頭,所有故障鏈的終點都會匯聚到這個服務,增加ts-seat-service得分,最終故障源頭的得分最高。當我們減少請求種類如圖7所示,只發起ts-travel-plan-service:getByCheapest和tspreserve-service:preserve兩種請求,使用ICIAM得分最高的前5名服務如表6所示。
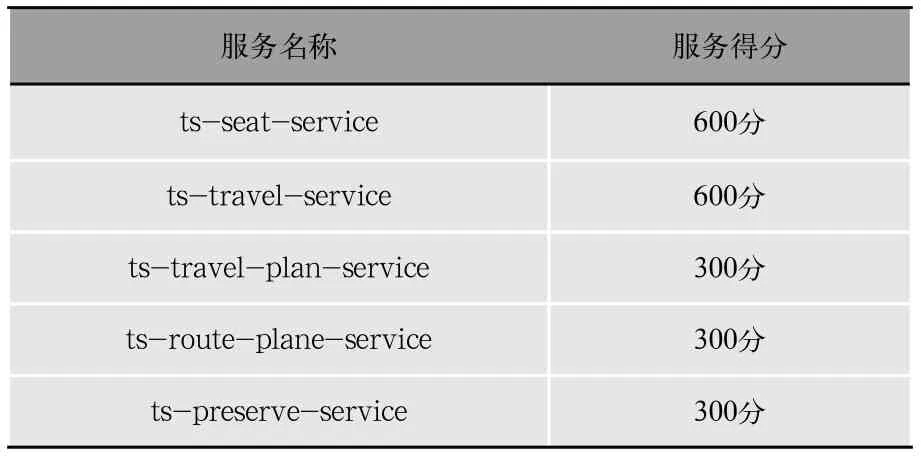
表6 2種請求時ICCA算法得分最高前5名服務
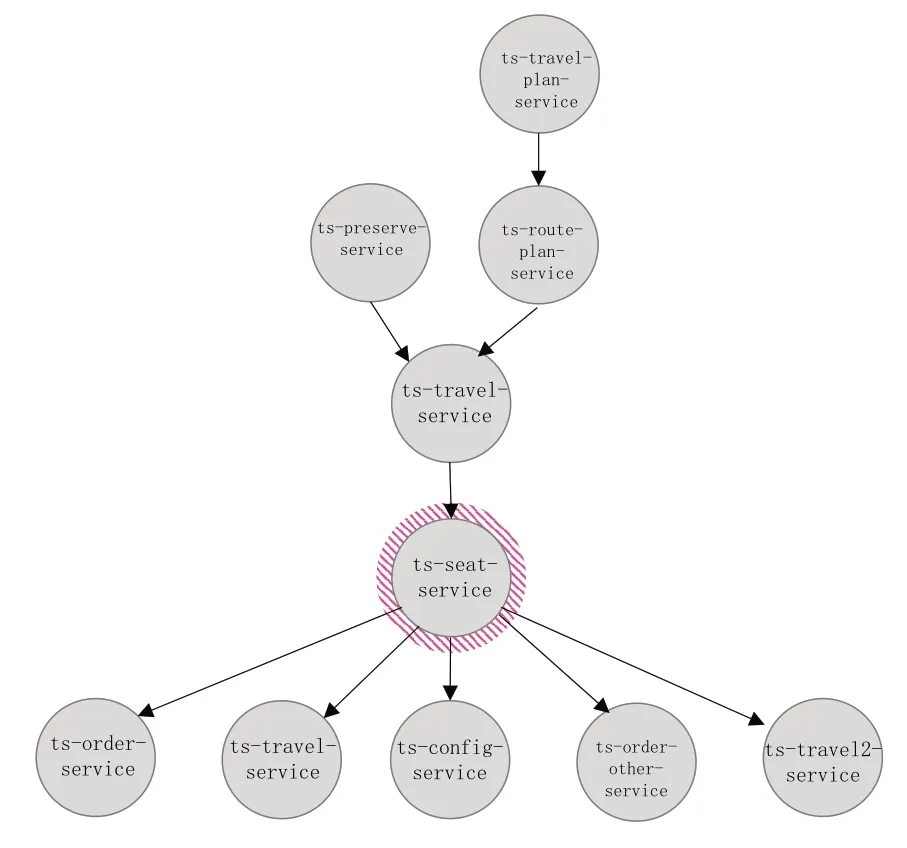
圖7 2種請求故障調用鏈示意圖
可以看到,當故障服務上游服務一一對應時,可能出現故障服務得分和唯一上游服務相同的情況,但是這種情況比較少見,很少出現一種服務只是被一種服務調用。其次,即使出現這種情況,故障服務的得分也是故障調用鏈上最高之一,也能大概確定故障服務位置。
綜合比較,使用ICIAM,服務被越多種服務調用,發生故障時,越容易被定位出來。總體來說,ICIAM可以通過服務網格提供的調用路徑,定位到故障服務位置。
4.4.2 定位故障容器位置
一個服務往往有多個備份容器分攤流量,需要定位到具體哪個實例出現問題,采集容器CPU、內存等方面指標,從這些指標可以得到具體故障位置。
如表7、表8所示,使用Istio進行故障注入,sidecar將所有請求攔截,返回http狀態碼500,此刻容器的CPU負載明顯低于正常情況,內存也有少量降低,但是影響很小,分析原因是容器在啟動時Request Memory設置在250MB,容器處于空閑狀態或處于較低負載水平時,內存保持在250MB左右,當容器處理大量求量之時,會額外申請內存。通過容器各項指標參數,可以發現故障容器異常,從而判別故障。
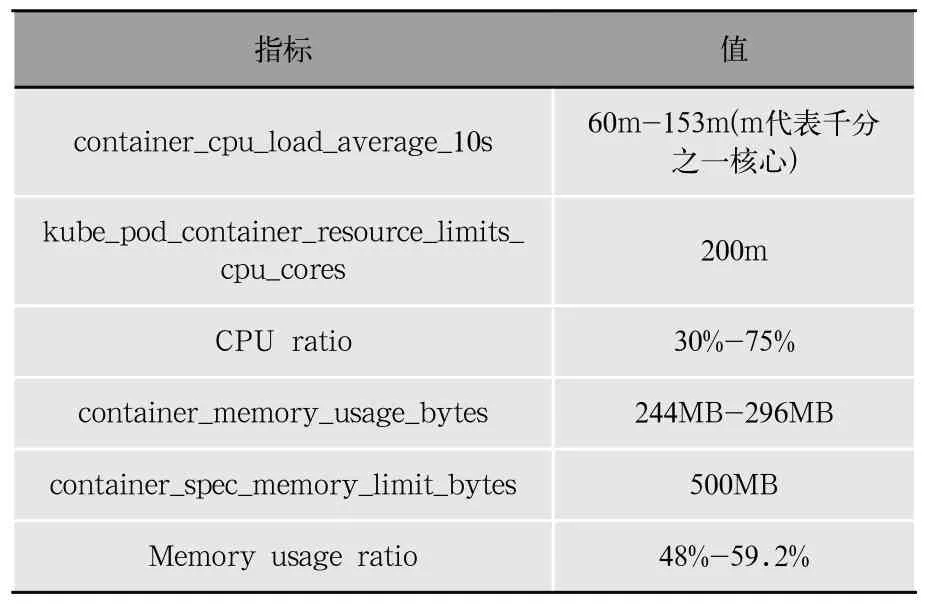
表7 無故障情況下容器CPU、內存情況
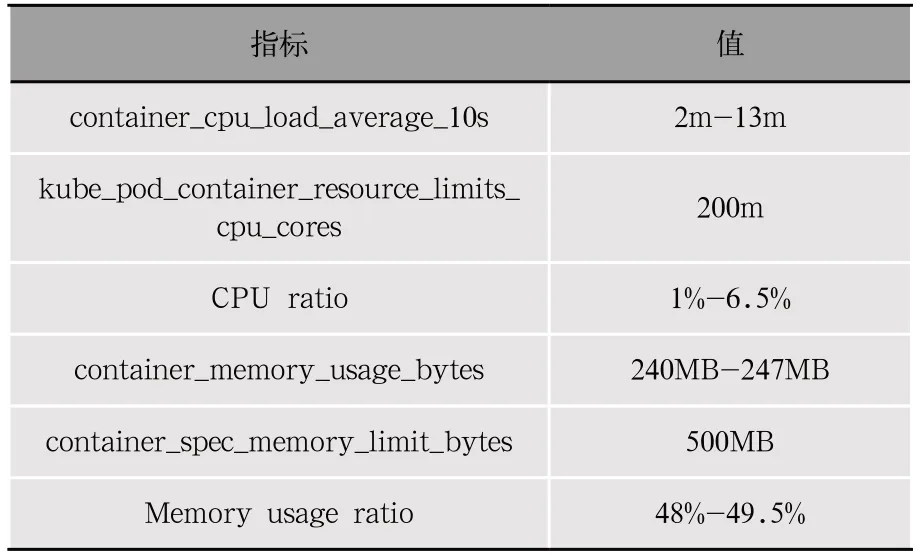
表8 故障注入情況下容器CPU,內存情況
5 結果與未來工作
使用服務網格實現了對微服務全方位的監控,包括服務調用路徑、在每個節點延時、容器運行各項指標。完善的監控體系對于故障定位有著很大意義。
使用ICIAM方法能有效確定故障服務種類,而且在服務請求種類越多的情況下效果越明顯。因為服務請求種類越多,故障服務越有幾率被多種請求調用,得分更高。如果服務請求種類少,而且故障服務上游僅有少量服務甚至一條調用路徑,定位的故障范圍可能會擴大,但基本能夠確定故障位置。通過容器各項運行指標,定位具體故障容器。
然而,微服務故障治理不應該僅僅定位故障位置,還應該找到故障原因。這篇文章研究故障注入類型比較單一,只是使用istio對ts-seat-service在網絡連接上進行故障注入,真實生產環境下故障種類十分復雜,有內存負載過大、CPU負載過大、網絡環境故障、程序本身錯誤、配置錯誤等多種原因,需要進一步細分。這也是未來需要研究的方向。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
