基于Hadoop技術的并行計算模式定向數據挖掘方法
2021-09-22 06:13:50葉苗張國華
電子技術與軟件工程 2021年15期
關鍵詞:數據挖掘
葉苗 張國華
(南京師范大學泰州學院 江蘇省泰州市 225300)
信息技術迅猛發展,互聯網數據呈指數倍增長態勢,傳統計算機體系架構已難以有效處理當前的大規模數據。因此,云計算技術應運而生,為海量數據挖掘領域提供良好契機[1]。隨著網絡技術日新月異的發展,許多傳統的數據挖掘策略已不再適用于不斷更新換代的數據類型與應用環境,其已對挖掘精度與實時性提出了更高的要求。因此,研究一種更理想的海量數據挖掘方法具有重要的現實意義。
為滿足當前數據挖掘技術的應用需求,本文利用Hadoop技術與并行計算模式,設計出一種定向數據挖掘方法。其中,Hadoop平臺具有管理存儲在多臺計算機上數據分塊的能力,憑借優秀的運算能力、存儲能力、調度能力,在數據挖掘[2]方向被廣泛應用;設計校驗修正公式與控制允許誤差范圍的容忍度閾值,提升校驗公式兩邊數值相等概率,確保挖掘結果的可靠性,校驗節點存儲容量與性能值的一致性;通過MapReduce計算模式下樸素貝葉斯分類算法,提升定向數據挖掘精度與效率。
1 Hadoop技術下并行計算模式定向數據挖掘
1.1 基于云計算平臺實現HDFS分布式文件系統存儲
1.1.1 HDFS分布式文件系統
將分布式文件系統引入云計算平臺中,管理存儲在多臺計算機上的數據分塊,該系統以Hadoop分布式為基礎,主要組成部分是一個主數據節點與多個從數據節點。前者將元數據服務給予分布式文件系統內部,掌控全部文件;后者則用于備份、存儲若干個切分存儲文件得來的數據塊。系統客戶端決定著新建文件過程中的數據塊大小與備份數量。利用標準的TCP/IP[3]協議完成HDFS(Hadoop Distributed File System)分布式文件系統內部各節點間通信。該系統體系框架如圖1所示。

圖1:HDFS結構示意圖
1.1.2 數據存儲
大規模數據存儲主要通過分布式文件系統中的數據節點實現。為此,評估Hadoop集群內節點性能,根據得到的節點性能值,選取存儲數據塊的合適節點,按比例在各節點存儲一定數量的數據塊[4]。具體過程描述如下:
(1)節點性能評估:假設i表示任意服務器節點,處理器性能值、內存性能值以及磁盤I/O性能值分別是Ci、Mi與Di,則該節點對應性能值Pi表達式如下所示:

式中,各指標對服務器性能不同權值影響的參數是α、β、γ,且滿足下列等式:

為確保挖掘結果的可靠性,校驗修正各節點性能值的測量結果。假設有N個節點,其中,節點i完成的任務個數為Si,Hadoop集群里各任務數據具有相同規格,所以,節點i在固定時段中處理的數據量也可以用Si表示,則推導出下列校驗公式:

若Hadoop集群中的任意兩節點均滿足該校驗公式,說明基于當前Hadoop應用場景,測得的節點性能值具有有效性。設定一個控制允許誤差范圍的容忍度閾值p,令校驗公式兩邊數值等率更高,則改寫校驗公式為下列表達式,將其作為實際應用中測量結果校驗標準:
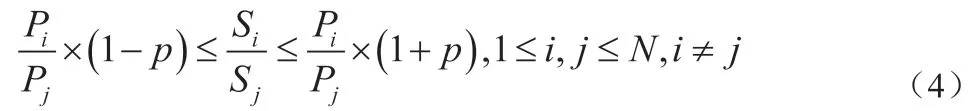
其中,節點i任務數量Si與主數據節點總任務數SA關系如下所示:

(2)存儲節點選取:根據各節點數據處理能力,在分布式文件系統中完成大規模數據文件存儲,利用節點存儲容量校驗策略,選取有效存儲節點,校驗節點存儲容量與性能值的一致性。
假設U1,U2,...,UN是各節點存儲集群的數據量規格,P1,P2,...,PN是相應節點性能值,UA表示集群存儲數據量規格,則任意節點i存儲集群的數據量規格Ui應使下列不等式成立:

式(6)的作用是校驗數據量存儲規格與節點i性能值的匹配程度。其中,節點i存儲集群的數據量規格Ui與集群存儲數據量規格UA關系如下所示:

1.2 基于HDFS平臺構建HBASE分布式數據庫
以分布式文件系統作為運行基礎,構建HBASE分布式數據庫,為大量數據提供任意、實時的讀寫訪問服務,提升數據可靠性與系統魯棒性。該數據庫通過學習使文件系統中大表數據庫的所有功能得以實現,完成大規模數據的存儲與處理。
1.3 基于Hadoop技術設計MapReduce并行計算模式
1.3.1 并行分布式計算
由Map映射功能與Reduce歸約功能組成的MapReduce并行分布式計算模式,是一種具有處理大量數據能力的并行分布式編程模式。用戶利用界定的Map函數,處理key/value(即鍵/值對)與取得的中間結果,經Reduce函數結合所有擁有相同key值[5]中間結果的value值。Map函數的作用是分塊處理輸入數據,將數據塊劃分至不同節點加以并行運行;Reduce函數功能是歸約中間生成key值的value值,并依據某分塊函數,分類中間生成的key值。
1.3.2 MapReduce計算模式下樸素貝葉斯分類
Map函數的分布計算中難以實時交互各Mapper節點信息。為獲取計算模式運行結果,需憑借最終產生的中間結果,且確保各節點有相同且獨立的任務。基于此,利用設計的樸素貝葉斯分類算法,求取待分類定向數據與不同類別的分類概率[6],劃分定向數據至最大分類概率的類別內,完成定向數據挖掘。
若定向數據類別C1,C2,...,Cm的數量為m,各數據對應屬性個數為n,則采用下列n+1維屬性向量X的表達式來表示各定向數據:

針對待分類的定向數據X',判定其與類別Ci的從屬結果,且滿足下列不等式:

為使定向數據X'屬于類別類別Ci的概率超過其余類別,應最大化處理P(Ci|X'),引用下列樸素貝葉斯公式實現:
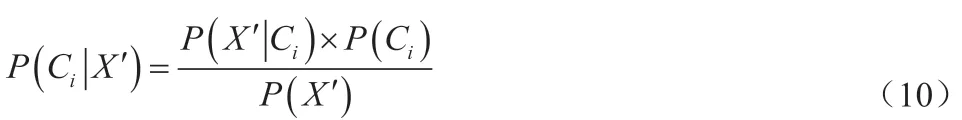
式中,用=P(X')表示常數,P(Ci)與P(X'|Ci)的計算公式分別為:

式中,D內Ci類別的訓練元組數為|Ci,D|。
若求解目標是P(x'k|Ci),判定其屬性Ak種類:當屬性Ak為離散時,P(x'k|Ci)是屬性取x'k下Ci類別中元組數量與所有定向數據內Ci類別中元組數量的比值;當屬性Ak為連續時,服從高斯分布,其均值與標準差分別是μ與σ,則P(x'k|Ci)用下列界定表達式指代:

根據解得的最大概率類別,完成該定向數據X'分類、挖掘。
在MapReduce并行分布式計算模式執行該算法的過程中,Main函數主要負責讀取數據集、轉換Reduce的整合結果以及計算節點上的分類器讀取,Map函數的功能是統計離散屬性取值、求解連續屬性均值與標準差以及劃分各待分類定向數據,而Reduce函數則用于根據要求統計、輸出分類與挖掘結果。各函數具體實現描述如下:
(1)Map函數:假設分布式文件系統的定向數據id號與內容分別是key與value,已知數據集中各定向數據及對應屬性;若屬性是離散型,則將定向數據類別的屬性取值個數累積起來,若屬性是連續型,則求取屬性取值的總和與平方和;當前分片經過遍歷、統計,輸出所得結果。
(2)Reduce函數:讀取Mapper節點全部臨時信息;整合離散型統計結果,獲取概率;針對L個定向數據的連續屬性,若∑X'表示屬性取值總和,∑X'2表示平方和,采用下列兩公式求取屬性均值μ與標準差σ;統計完全部項目后,輸出MapReduce程序的最終結果。

(3)Main函數:讀取輸出的最終結果;當鍵值對標記為離散屬性時,按照屬性號、取值、標簽號、概率的形式進行變換與輸出;當鍵值對標記為連續屬性時,按照屬性號、取值、均值、標準差的形式進行變換與輸出。
2 實際案例應用
選取某市中心城區擴展建設用地,在本文設計的基于Hadoop技術的并行計算模式定向數據挖掘方法的支持下,探索城市建設用地的空間格局與演變特征。該城市建設項目中涉及到的數據分別有建成區域面積與總土地面積、建設用地種類、方位數據以及時間數據。建設用地擴展趨勢如圖2所示。

圖2:建設用地擴展趨勢示意圖
根據本文方法挖掘得到的連續七年城區建成區域面積變化數據與建設用地不同方向擴展強度堆積數據可知:該市中心城區的建設用地面積呈線性擴展趨勢;前兩年建設擴展方向以西部為主,后三年主要擴展南部方向建設,2013、2014連續兩年在東部方向進行了較高強度擴展,擴展形式以圈層漸進式展開,后期擴展強度有所減緩。
3 結語
數據挖掘技術目標是從海量低價值數據里發掘可用的高價值數據,為拓寬該項技術的應用領域。本文以Hadoop技術為基礎,提出一種并行計算模式的定向數據挖掘方法[7]。針對爆炸式增長的龐大數據,需結合更新、更理想的分類算法,進一步優化挖掘效果。為此,在未來的研究階段,探索Hadoop平臺啟用時間的縮減策略,加快平臺小數據處理速度;應嘗試探究相關運行參數,合理配置Hadoop云計算平臺,進一步提升數據挖掘效率,也為城市管理者制定城市建設方案提供依據和參考。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
