
基于確定性策略梯度算法的機(jī)械臂控制模型構(gòu)建及仿真
2021-09-22 12:17:45賈紅濤胡文娟
粘接 2021年9期
關(guān)鍵詞:仿真
賈紅濤 胡文娟
摘 要:為更好的實(shí)現(xiàn)對(duì)工業(yè)制造領(lǐng)域中機(jī)械臂的控制,結(jié)合當(dāng)前的深度學(xué)習(xí)算法,提出一種改進(jìn)獎(jiǎng)勵(lì)函數(shù)的DDPG機(jī)械臂控制方法。在該方法中,通過(guò)引入多獎(jiǎng)勵(lì)參數(shù)等方式,增強(qiáng)機(jī)械臂控制的靈活性,提高目標(biāo)抓取的準(zhǔn)確率。最后通過(guò)參數(shù)設(shè)置和DDPG網(wǎng)絡(luò)模型構(gòu)建,對(duì)改進(jìn)方案進(jìn)行驗(yàn)證。結(jié)果表明,該改進(jìn)方式在目標(biāo)抓取方面更具有穩(wěn)定性。
關(guān)鍵詞:DDPG算法;機(jī)械臂控制;仿真;獎(jiǎng)勵(lì)參數(shù)
中圖分類號(hào):TM359.9 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1001-5922(2021)09-0151-04
Construction and Simulation of Manipulator Control Model Based on Deterministic Strategy Gradient Algorithm
Jia Hongtao, Hu Wenjuan
(Shangluo Vocational and Technical College, Shangluo 726000, China)
Abstract:In order to better control the manipulator in the field of industrial manufacturing, combined with the current deep learning algorithm, a DDPG manipulator control method with improved reward function is proposed. In this method, multi reward parameters are introduced to enhance the flexibility of manipulator control and improve the accuracy of target grasping. Finally, through parameter setting and DDPG network model construction, the improved scheme is verified. The results show that the improved method is more stable in target capturing.
Key words:DDPG algorithm; manipulator control; simulation; reward parameters
機(jī)械臂在工業(yè)制造領(lǐng)域發(fā)揮重要作用,早期的機(jī)械臂控制方法采用的是基于任務(wù)的精確數(shù)學(xué)模型,這種控制方法下的機(jī)械臂的自適應(yīng)性不理想,只能滿足特定工作條件和指定任務(wù)目標(biāo)下的應(yīng)用需求,而無(wú)法根據(jù)任務(wù)或緩解的變化而做出調(diào)整,從而實(shí)現(xiàn)更好地控制效果。在最近幾年間,深度強(qiáng)化學(xué)習(xí)(Deep Reforcement Learning,DRL)實(shí)現(xiàn)了快速發(fā)展,并逐步推廣到機(jī)器人控制、人工智能博弈等領(lǐng)域,其中的一個(gè)重要突破就是機(jī)械臂控制開(kāi)始引用DRL技術(shù)。應(yīng)用于機(jī)械臂控制領(lǐng)域的DRL技術(shù)主要是確定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),該算法在發(fā)揮強(qiáng)適應(yīng)性控制效果的同時(shí),也暴露出諸多弊端,比如學(xué)習(xí)效率低、不穩(wěn)定、調(diào)參難、難復(fù)現(xiàn)等。針對(duì)該問(wèn)題,文章提出DDPG算法以提高機(jī)械臂控制中目標(biāo)點(diǎn)到達(dá)以及目標(biāo)抓取任務(wù)中的學(xué)習(xí)效率。
1 深度確定性策略梯度算法
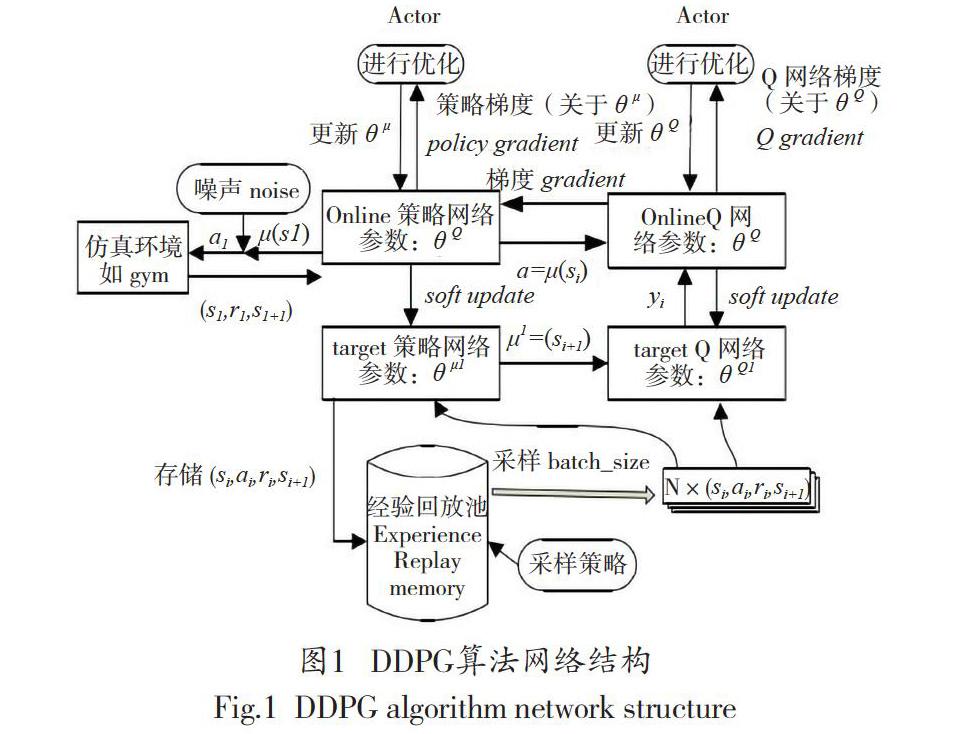
運(yùn)用DQN拓展Q-Learning的方法,Lillicrap等進(jìn)一步改進(jìn)了確定性策略梯度算法,創(chuàng)建了DDPG算法。DDPG算法是強(qiáng)化學(xué)習(xí)領(lǐng)域的重要發(fā)展成果,它的前身是最初的策略梯度算法(Policy Gradient,PG)以及其后的確定性策略梯度算法(Deterministic Policy Gradient,DPG)。DDPG整體結(jié)構(gòu)如圖1所示。
2 實(shí)驗(yàn)機(jī)械臂設(shè)計(jì)
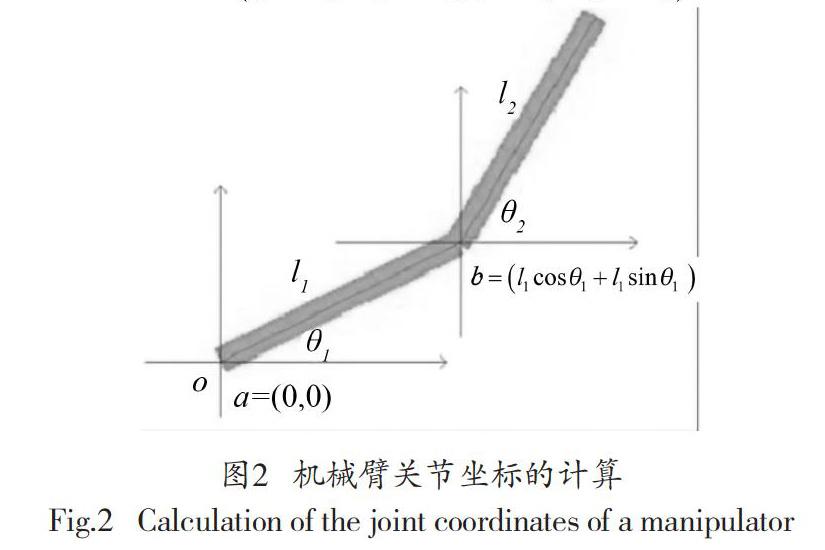
在二維平面上,機(jī)械臂關(guān)節(jié)坐標(biāo)位置和機(jī)械臂關(guān)節(jié)旋轉(zhuǎn)角度的關(guān)系可用圖2表示。
圖2中,o表示坐標(biāo)原點(diǎn)或仿真機(jī)械臂的根節(jié)點(diǎn)。l1的一側(cè)端點(diǎn)坐標(biāo)是a=(0,0),也就是位o點(diǎn)之上,l2末端坐標(biāo)是,l1與l2的焦點(diǎn)b的坐標(biāo)是。同理,可計(jì)算出關(guān)節(jié)點(diǎn)a、b和c的相對(duì)位置,以及目標(biāo)區(qū)域中心點(diǎn)T。
3 基于改進(jìn)DDPG的機(jī)械臂控制設(shè)計(jì)
3.1 輸入狀態(tài)信息設(shè)計(jì)
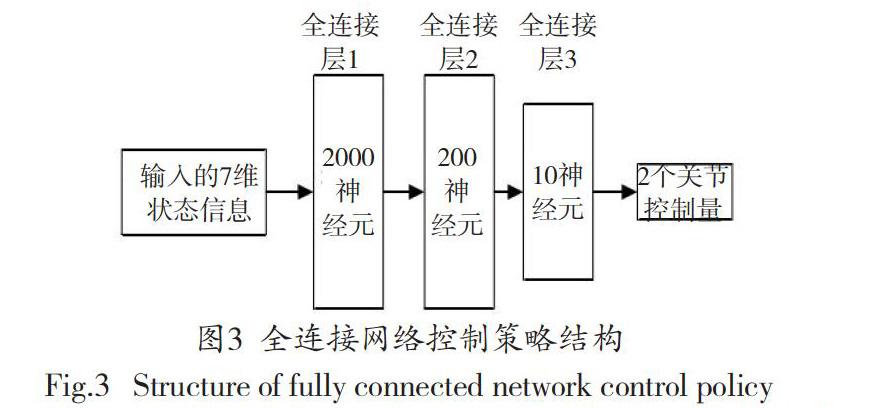
考慮到在二維機(jī)械臂仿真環(huán)境中的狀態(tài)信息并不充分,因此選用三層全連接網(wǎng)絡(luò)進(jìn)行數(shù)據(jù)特征提取即可滿足應(yīng)用需求。具體控制策略如圖3所示。
通過(guò)上述的策略,可獲取2段機(jī)械臂l1、l2的關(guān)節(jié)角度信息、。
設(shè)定機(jī)械臂l1、l2的長(zhǎng)度均為100,通過(guò)上式(1)獲取與環(huán)境相關(guān)的狀態(tài)信息,這些狀態(tài)信息也是算法的狀態(tài)輸入。
式(2)中,d1-x,d2-x分別是機(jī)械臂關(guān)節(jié)b、c的橫坐標(biāo)距離;d1-y,d2-y表示目標(biāo)中心點(diǎn)T的縱坐標(biāo)距離;d3-x,d3-y分別是目標(biāo)中心點(diǎn)T與仿真環(huán)境中心點(diǎn)的橫坐標(biāo)距離、縱坐標(biāo)距離;goal表示布爾值,當(dāng)機(jī)械臂末端在目標(biāo)中心點(diǎn)T范圍內(nèi)部,布爾值等于1,否則等于0。通過(guò)式(2)可獲取算法輸入的7維狀態(tài)信息。
3.2 輸出控制動(dòng)作設(shè)計(jì)
完成以上網(wǎng)絡(luò)控制策略后,機(jī)械臂的2個(gè)關(guān)節(jié)動(dòng)作控制量可表示為式(3)。
其中,a表示動(dòng)作輸出控制量w1、w2,它是由轉(zhuǎn)動(dòng)角度變量共同構(gòu)成的,其單位是弧度。其中,w1表示機(jī)械臂l1根關(guān)節(jié)在該次動(dòng)作中所需轉(zhuǎn)動(dòng)的角度,w2表示機(jī)械臂l2與機(jī)械臂l1連接關(guān)節(jié)在該次動(dòng)作值所需轉(zhuǎn)動(dòng)的角度。轉(zhuǎn)動(dòng)角度變量w1、w2的取值區(qū)間是[-1,1],設(shè)定這一角度區(qū)間是為了避免出現(xiàn)機(jī)械臂轉(zhuǎn)動(dòng)突變的情況,也是防范控制異常的常規(guī)辦法。
在完成關(guān)節(jié)旋轉(zhuǎn)動(dòng)作以后a=[w1、w2],機(jī)械臂的關(guān)節(jié)角度從變化成,即輸入7維狀態(tài)信息,輸出2維的關(guān)節(jié)轉(zhuǎn)動(dòng)控制量。
3.3 原始獎(jiǎng)勵(lì)函數(shù)改進(jìn)
設(shè)r為二維仿真機(jī)械臂獎(jiǎng)勵(lì)函數(shù),獎(jiǎng)勵(lì)r包括r1與r2兩部分組成。
式(4)中,r1表示目標(biāo)區(qū)域中心點(diǎn)與機(jī)械臂末端的距離獎(jiǎng)勵(lì)函數(shù),;r2表示稀疏獎(jiǎng)勵(lì)函數(shù),即機(jī)械臂末端在目標(biāo)區(qū)域內(nèi)環(huán)境反饋值為1的單步獎(jiǎng)勵(lì);r=r1+r2表示DDPG算法的原始獎(jiǎng)勵(lì)函數(shù)。
研究認(rèn)為,傳統(tǒng)的單一獎(jiǎng)勵(lì)函數(shù)設(shè)置無(wú)法對(duì)機(jī)械臂動(dòng)作的優(yōu)劣程度做出準(zhǔn)確評(píng)定,也無(wú)法通過(guò)訓(xùn)練建立理想的算法模型。優(yōu)化后的獎(jiǎng)勵(lì)函數(shù)能夠避免機(jī)械臂的無(wú)效探索,還能夠促進(jìn)強(qiáng)化學(xué)習(xí)算法走向收斂,對(duì)此,可以組合應(yīng)用分布獎(jiǎng)勵(lì)、稀疏獎(jiǎng)勵(lì)、形式化獎(jiǎng)勵(lì)等不同的獎(jiǎng)勵(lì)方法。舉例來(lái)說(shuō),選定上式(4)作為機(jī)械臂的獎(jiǎng)勵(lì)函數(shù),在算法控制下,機(jī)械臂會(huì)進(jìn)行轉(zhuǎn)圈甩動(dòng),其末端會(huì)在某一瞬間抵達(dá)目標(biāo)塊位置,然后繼續(xù)轉(zhuǎn)圈甩動(dòng)偏離目標(biāo)點(diǎn),說(shuō)明該算法只能實(shí)現(xiàn)機(jī)械臂轉(zhuǎn)動(dòng)至目標(biāo)點(diǎn),卻不能使機(jī)械臂停留在目標(biāo)點(diǎn)。根據(jù)式(4)的弊端,文章提出了多種獎(jiǎng)勵(lì)策略相結(jié)合的獎(jiǎng)勵(lì)函數(shù),即增加r3以改進(jìn)該獎(jiǎng)勵(lì)策略。
式(5)中,d、d`分別表示機(jī)械臂末端與目標(biāo)點(diǎn)在這一時(shí)刻及下一時(shí)刻的距離。在上式(6)中,獎(jiǎng)勵(lì)函數(shù)包含了r1、r2、r3三部分。其中,r1表示機(jī)械臂末端與目標(biāo)點(diǎn)之間關(guān)于距離的懲罰性獎(jiǎng)勵(lì)函數(shù),二者的間距越大,r1值越大,表示懲罰越嚴(yán)重,反則反之。
3.4 整體機(jī)械臂抓取控制策略設(shè)計(jì)
結(jié)合以上輸入、輸出,以及對(duì)獎(jiǎng)勵(lì)函數(shù)的改進(jìn),將DDPG的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)為如圖4所示。
DDPG包含策略網(wǎng)絡(luò)和價(jià)值網(wǎng)絡(luò),它們的學(xué)習(xí)率均是10-3,獎(jiǎng)勵(lì)折扣率y=0.9,回放記憶單元存放數(shù)據(jù)量為30000,單次提取的數(shù)據(jù)batch_size=32。根據(jù)上述設(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu)看出,首先從save、R、S以及S_中調(diào)取出經(jīng)驗(yàn)回放池內(nèi)的數(shù)據(jù),應(yīng)用Actor網(wǎng)絡(luò)和Critic網(wǎng)絡(luò)進(jìn)行對(duì)其訓(xùn)練。然后,應(yīng)用依據(jù)策略梯度和TD殘差更新策略網(wǎng)路和價(jià)值評(píng)價(jià)網(wǎng)絡(luò)的權(quán)重,實(shí)現(xiàn)參數(shù)優(yōu)化。
4 實(shí)驗(yàn)驗(yàn)證
4.1 參數(shù)設(shè)置
設(shè)訓(xùn)練集總數(shù)為2000,每集最大步數(shù)為300,目標(biāo)區(qū)域的大小為40×40。若目標(biāo)域連續(xù)停留50步,即可判定控制機(jī)械臂已經(jīng)抵達(dá)目標(biāo)點(diǎn)并處于穩(wěn)定狀態(tài),隨即終止該輪訓(xùn)練。
4.2 實(shí)驗(yàn)結(jié)果
4.2.1 不同獎(jiǎng)勵(lì)函數(shù)下的獎(jiǎng)勵(lì)變化趨勢(shì)
reward_trend表示平均獎(jiǎng)勵(lì)隨訓(xùn)練集數(shù)的變化趨勢(shì)。同時(shí)為對(duì)比該算法的優(yōu)勢(shì),將上述改進(jìn)的獎(jiǎng)勵(lì)函數(shù)與傳統(tǒng)的A3C獎(jiǎng)勵(lì)函數(shù)進(jìn)行對(duì)比。根據(jù)實(shí)驗(yàn),得到圖5的結(jié)果。
根據(jù)圖5所示,A3C算法有效利用了cpu的多核性能,可同時(shí)對(duì)多個(gè)智能體進(jìn)行訓(xùn)練,因此提高了計(jì)算的效率。此外,該算法還可以信息共享的方式更新結(jié)構(gòu)參數(shù),進(jìn)而提高訓(xùn)練速度。通過(guò)對(duì)比上述兩種獎(jiǎng)勵(lì)函數(shù)下的收斂速度發(fā)現(xiàn),本研究提出的改進(jìn)DDPG算法波動(dòng)性的平均獎(jiǎng)勵(lì)上升速度更快,波動(dòng)性最小,說(shuō)明該算法擁有更好的收斂性,只需有效的集數(shù)就可以實(shí)現(xiàn)收斂上升。
4.2.2 訓(xùn)練效果對(duì)比
通過(guò)對(duì)比A3C算法與改進(jìn)的DDPG算法在最后100集中的訓(xùn)練效果,得到圖6的對(duì)比結(jié)果。
由圖6分析,A3C算法平均每集所用步數(shù)是171.30,改進(jìn)DDPG算法的平均步數(shù)是111.45。依據(jù)上圖6(a),每10集進(jìn)行一輪統(tǒng)計(jì),發(fā)現(xiàn)改進(jìn)DDPG算法的整體步數(shù)普遍少于A3C算法,而且相對(duì)步數(shù)的波動(dòng)性更小。依據(jù)上6(b),在100集內(nèi)最終達(dá)成探索任務(wù)的,A3C算法只有77%,而改進(jìn)DDPG算法增加至87%。綜上可知,改進(jìn)DDPG算法在準(zhǔn)確性、穩(wěn)定性上都優(yōu)于A3C算法,整體表現(xiàn)更優(yōu)。
5 結(jié)語(yǔ)
通過(guò)改進(jìn)的DDPG算法與傳統(tǒng)的主流算法相比,在機(jī)械臂的連續(xù)控制效果方面,無(wú)論是在準(zhǔn)確性,還是在穩(wěn)定性方面,都具有明顯的優(yōu)勢(shì)。說(shuō)明文章改進(jìn)的獎(jiǎng)勵(lì)函數(shù)方式對(duì)提高機(jī)械臂的穩(wěn)定性具有非常積極的作用和價(jià)值。
參考文獻(xiàn)
[1]李廣源,史海波,孫杳如. 基于層級(jí)深度強(qiáng)化學(xué)習(xí)的間歇控制算法[J].現(xiàn)代計(jì)算機(jī)(專業(yè)版),2018(35):3-7.
[2]多南訊,呂強(qiáng),林輝燦,等.邁進(jìn)高維連續(xù)空間:深度強(qiáng)化學(xué)習(xí)在機(jī)器人領(lǐng)域中的應(yīng)用[J].機(jī)器人,2019,41(02):276-288.
[3]劉乃軍,魯濤,蔡瑩皓,等.機(jī)器人操作技能學(xué)習(xí)方法綜述[J].自動(dòng)化學(xué)報(bào),2019,45(03):458-470.
[4]柯豐愷,周唯倜,趙大興.優(yōu)化深度確定性策略梯度算法[J].計(jì)算機(jī)工程與應(yīng)用,2019,55(07):151-156+233.
[5]解永春,王勇,陳奧,李林峰.基于學(xué)習(xí)的空間機(jī)器人在軌服務(wù)操作技術(shù)[J].空間控制技術(shù)與應(yīng)用,2019,45(04):25-37.
[6]卜令正.基于深度強(qiáng)化學(xué)習(xí)的機(jī)械臂控制研究[D].徐州:中國(guó)礦業(yè)大學(xué),2019.
[7]王斐,齊歡,周星群,等.基于多源信息融合的協(xié)作機(jī)器人演示編程及優(yōu)化方法[J].機(jī)器人,2018,40(04):551-559.
[8]周慶鋒,王思淳,李德鑫,等.基于DDPG的風(fēng)電場(chǎng)動(dòng)態(tài)參數(shù)智能校核知識(shí)學(xué)習(xí)模型[J/OL].中國(guó)電力:1-8[2020-09-18].
[9]張耀中,許佳林,姚康佳,等.基于DDPG算法的無(wú)人機(jī)集群追擊任務(wù)研究[J/OL].航空學(xué)報(bào):1-13[2020-09-18].
[10]張斌,何明,陳希亮,等.改進(jìn)DDPG算法在自動(dòng)駕駛中的應(yīng)用[J].計(jì)算機(jī)工程與應(yīng)用,2019,55(10):264-270.
猜你喜歡
中國(guó)教育技術(shù)裝備(2016年20期)2016-12-12 10:09:15
中小企業(yè)管理與科技·下旬刊(2016年10期)2016-11-18 20:57:34
科技資訊(2016年18期)2016-11-15 20:09:22
科技資訊(2016年18期)2016-11-15 07:55:28
價(jià)值工程(2016年29期)2016-11-14 02:01:16
電子技術(shù)與軟件工程(2016年18期)2016-11-14 00:46:54
數(shù)字技術(shù)與應(yīng)用(2016年9期)2016-11-09 23:25:33
數(shù)字技術(shù)與應(yīng)用(2016年9期)2016-11-09 22:09:07
科技視界(2016年18期)2016-11-03 21:44:44
科技視界(2016年18期)2016-11-03 20:31:49
