基于灰色關聯度的110千伏主網基建模型研究
2021-09-23 08:45:48丁萍剛楊洲王祎
電氣自動化 2021年4期
丁萍剛, 楊洲, 王祎
(國網衢州供電公司,浙江 衢州 324000)
0 引 言
110 千伏主網建設能夠大大提高區域供電可靠性及網架發展適應性,提供更加可靠充足的電力供應,為助力地方區域經濟社會高質量發展提供有力的電力支撐[1]。因此為優化國家電力產業結構,電網企業大力投資建設110 千伏主網基建工程。但建設過程中易受自然因素、經濟因素及建設項目自身等因素的影響,導致基建工程質量與工程項目風險管控不穩定[2]。在確保國家電網高效穩定的前提下,合理地管理110 千伏主網基建模型,增大國家電網建設的收益能力已經成為國家電網公司亟需解決的問題。
目前,國家電網在資金投資預算和主網基建等方面進行了探索,電力部門也對主網基建模型開始了一些新的研究。然而,由于110 千伏主網基建投資測算關系復雜、影響因素多等原因,缺乏考慮因素全面的主網基建模型。隨著國家電網體制改革的逐步深化,電網的經濟效益在投資決策中占據的比例越來越大,主網基建主體的多元化對110 千伏主網基建建模提出了新的挑戰[3]。針對上述背景及存在問題,本文對110 千伏主網基建的相關指標進行分析,將灰色關聯度應用到了主網基建模型設計中,提高主網基建模型的有效性。
1 基于灰色關聯度的110 千伏主網基建模型設計
1.1 選取110 千伏主網基建特征
每一個城市的110 千伏主網基建投資額及運行變化趨勢不同,導致每一個110 千伏主網基建數據指標計算出的灰色關聯度數值也不同。灰色關聯度分析屬于灰色關聯分析方法中的一種,能夠根據所研究項目的發展趨勢提供量化的度量,具有計算量較小的優勢,適合主網基建過程的動態分析[4],可以提取出影響主網基建運行的因素,從而提高主網建設效率。若按各城市110 千伏主網基建運行影響因素的選擇策略進行因素選擇,則各城市主網基建運行影響因素會存在差異,在進行110 千伏主網基建運行影響因素回歸樹訓練時,就無法選擇特征相近的城市數據一起參與訓練。因此需要選取統一的主網基建特征,來保證多個城市的主網基建特征與主網建設效率之間的關聯性。選取5個城市的110 千伏主網基建運行影響因素與主網建設效率數據,計算兩者之間的灰色關聯度,計算結果如表1所示。
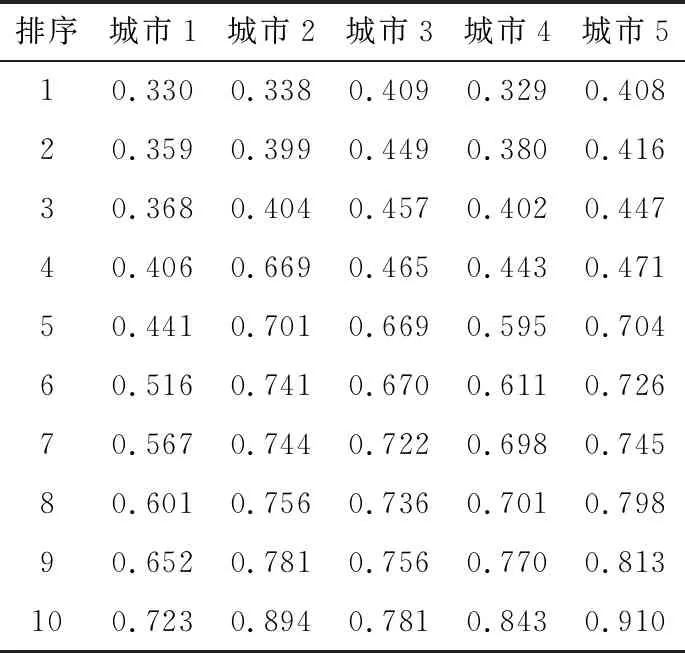
表1 主網基建運行影響因素與主網建設效率的灰色關聯度數據
根據110 千伏主網基建運行影響因素與主網建設效率之間的關聯度數值,制訂主網基建特征選取步驟。
Step 1:將所有關聯度數值排序,選取每個城市前t個110 千伏主網基建數據指標。
Step 2:統計5個城市的110 千伏主網基建特征數據指標i,前t個110 千伏主網基建數據指標出現的次數ni。
Step 3:刪除影響最小的110 千伏主網基建數據指標。
Step 4:如果剩下的110 千伏主網基建數據量小于20,直接進入第五步;否則刪除出現次數最少的c個指標,令t=t-c,重復第一步[5]。
Step 5:綜合主網基建數據類別、出現次數ni,選取6個主網基建數據指標作為110 千伏主網基建特征。
110 千伏主網基建特征選取步驟的流程如圖1所示。

圖1 110 千伏主網基建特征選取步驟流程
為了防止110 千伏主網基建特征出現差別,通過計算110 千伏主網基建運行影響因素與主網建設效率之間的灰色關聯性,制訂了110 千伏主網基建特征選取步驟,完成了主網基建特征的選取[6]。
1.2 聚類處理110 千伏主網基建特征數據
利用均值聚類的最優策略對110 千伏主網基建數據進行聚類處理,最優策略會將主網基建數據看作附加變量,優化操作在附加變量上進行,從而提高主網建設效率。主網基建數據聚類處理流程的具體實現步驟如下。
Step 1:整理110 千伏主網基建數據。
收集110 千伏主網基建數據樣本,用x1表示。設xij為待處理數據,將其加入110 千伏主網基建數據集合[7]。
Step 2:設置待處理數據的初始值。

Step 3:110 千伏主網基建數據隨機分類。
將110 千伏主網基建數據隨機分成c類,隨機得到每一類的初始聚類中心[8]。
Step 4:迭代次數初始化。
Step 5:計算灰色關聯度。
對于110 千伏主網基建數據的每一個110 千伏主網基建數據元素xij,利用式(1)計算得到110 千伏主網基建數據的灰色關聯度公式。
(1)

110 千伏主網基建數據的灰色關聯度需滿足以下條件:
uij>0
(2)
(3)
式中:uij為在第i個指標中j序列中的理想關聯系數。
Step 6:更新110 千伏主網基建數據聚類中心。
根據式(4)來更新110 千伏主網基建數據聚類中心。
(4)
式中:xj為給定聚類數;m為聚類密度。
Step 7:計算待處理110 千伏主網基建數據的關聯度。
對于待處理數據集合中的每一個待處理110 千伏主網基建數據xi′j′,利用式(5)計算待處理110 千伏主網基建數據的關聯度[9]。
(5)
式中:r為迭代次數;ui為在第i個指標的緊鄰均值。
Step 8:判斷迭代計算是否滿足結束條件,如果不滿足,進入Step 9,否則進入Step 10完成數據處理。
Step 9:令r=r+1,返回step 5。
Step 10:得到110 千伏主網基建數據聚類結果。
基于灰色關聯度的110 千伏主網基建數據聚類處理流程如圖2所示。
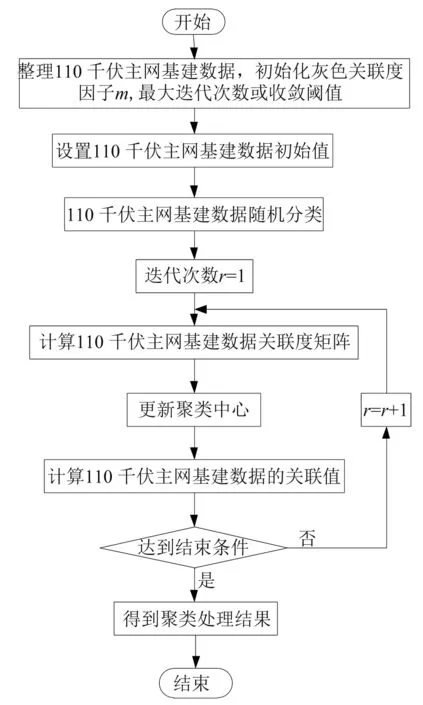
圖2 基于灰色關聯度的110 千伏主網基建數據聚類處理流程
以上根據110 千伏主網基建數據處理流程,將110 千伏主網基建數據整理并設置初始值,依據主網基建數據的隨機分類結果,計算了110 千伏主網基建數據的關聯度矩陣。利用110 千伏主網基建數據關聯度結束條件,完成110 千伏主網基建數據的聚類處理。
1.3 構建110 千伏主網基建模型
依據基建數據聚類結果,采用數學方法構建基于灰色關聯度的110 千伏主網基建模型,從已知主網基建聚類數據中獲取主網負荷和線路負載信息,來提高主網建設效率。基建數據指標體系具有數據量少、變化趨勢不穩定等特點[10],需要從數據中尋找歷史數據的變化規律構建模型,具體步驟如下。
Step 1:預處理110 千伏主網基建數據。
設n年主網基建數據的歷史序列Y0為:
Y0=[y0(1),y0(2),…,y0(n)]
(6)
對110 千伏主網基建數據的歷史序列進行一次累加,得到:
(7)
式中:y1(k)為主網基建數據做一次累加處理后的指標值;y0(i)為主網基建數據歷史值。
Step 2:根據灰色關聯度計算110 千伏主網基建數據的灰色關聯度:
(8)
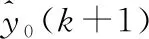
通過計算110 千伏主網基建運行影響因素與主網建設效率之間的關聯性,制訂了主網基建特征選取步驟,完成了基建特征的選取;設置主網基建數據初始值,依據基建數據的隨機分類結果,利用基建數據灰色關聯度結束條件,完成主網基建數據的聚類處理;實現基于灰色關聯度的110 千伏主網基建模型設計。
2 仿真試驗與分析
2.1 試驗環境
為檢驗此次構建模型的有效性,以基建工程質量控制標準(WHS)合格率及基建的建設風險值為試驗指標,與基于BIM構建的模型、基于運營數據的模型作對比。以浙江省某110 千伏工程項目基建數據為試驗樣本。采用電力系統的分析軟件ETAP進行仿真建模。
2.2 主網基建質量合格率對比
為驗證此次構建模型的有效性,在仿真平臺運用三種模型建設110 千伏主網基建工程,檢驗不同模型的主網基建質量。以WHS合格率作為評價標準。WHS合格率的指標考核內容為工程實體質量水平和施工、監理、建設和設計等單位的現場質量管理水平,是評價電網基建工程質量的指標之一[11]。WHS合格率以一周為報送周期,其計算公式如式(9)所示。
(9)
式中:μ為本項工程WHS質量控制點執行抽檢合格點數;φ為抽檢總點數。WHS合格率Q≥80%時,項目質量為合格。
基于上述試驗環境,對比不同模型的基建工程合格率,具體WHS合格率試驗結果如圖3所示。

圖3 不同模型的基建工程合格率
由圖3對比結果可知,對比其他兩種模型的WHS合格率,所設計模型的WHS合格率高于90%,說明基建工程質量較佳。因為該模型選取了主網基建特征,并對特征數據進行了聚類處理,提高了基建工程的WHS合格率。
2.3 基建工程項目風險對比
為驗證此次設計模型的建設效率,對比三種方法的基建工程項目風險。由于工程項目風險包含的內容較多,選擇與110 千伏主網基建關系較為緊密的三個方面(技術風險、運行風險和環節控制風險)作為主要考察指標[12],得到整體建設風險計算公式。
D=P+F+S
(10)
式中:P為技術風險;F為運行風險;S為環節控制風險。不同的風險通過風險可能發生的概率、頻率以及嚴重程度的量化數值乘積計算,不同風險的量化值范圍均為1~10。基于上述試驗環境及建設風險計算公式,對比三種模型的基建工程項目風險,具體結果如圖4所示。
從圖4可以看出,對比模型的基建工程項目風險值均高于12,而所設計模型的風險值則低于5,遠小于其他兩種模型的建設風險。所設計的模型計算了影響主網基建運行因素與主網建設效率之間的灰色關聯度,排除了關聯度較低的因素,降低了建設風險。
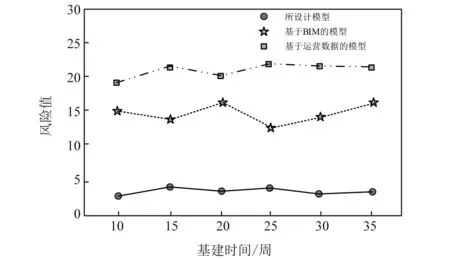
圖4 不同模型的基建工程項目風險
3 結束語
針對主網基建過程影響因素較多的問題,提出了基于灰色關聯度的110 千伏主網基建模型研究。對影響主網基礎設施運行的因素和主網建設效率進行灰色關聯計算,剔除關聯程度低的影響因素,選取主網基建特征數據并對其進行聚類處理。結合主網歷史序列數據構建主網基建函數模型,通過主網基建模型的構建,實現了基于灰色關聯度的110 千伏設計。仿真試驗表明,此次設計模型的基建工程WHS合格率高于90%,且基建風險較低。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代畜牧科技(2021年9期)2021-10-13 06:38:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生質量管理(2015年2期)2015-12-01 05:43:57
現代企業(2015年8期)2015-02-28 18:55:23
