基于特征融合卷積神經網絡的垃圾分類
2021-09-24 05:51:10許玉蕊劉銀華
自動化與儀表 2021年9期
許玉蕊,劉銀華,2,高 鑫
(1.青島大學 自動化學院,青島266071;2.青島大學 未來研究院,青島266071)
隨著我國經濟快速增長,人們日常生活產生越來越多的垃圾所帶來的環境問題日益嚴峻。現階段我國對生活垃圾的處理主要采用焚燒、填埋和堆肥等方式,既占用了寶貴的土地資源,也增加了環境污染和資源浪費。實行垃圾分類,關系廣大人民群眾生活環境,關系節約使用資源,也是社會文明水平的一個重要體現[1]。
近年來,隨著計算機軟硬件的巨大發展,神經網絡的研究與應用得到了飛速的發展,尤其在圖像識別領域,算法精度有了巨大的提升。所以將神經網絡應用到垃圾處理中不僅可以快速而準確地進行垃圾分類處理,還能夠大大減少因垃圾分類處理所需的人工成本。傳統的圖像分類方法普遍使用紋理或顏色等特征,常用的算法有SVM[2]、HOG[3]、ELM[4]等。神經網絡相對于傳統算法減少了人工對數據特征的提取,縮減了到達目標效果所需的時間,提高了魯棒性。為加強特征擬合和加快特征提取能力,基于卷積神經網絡(Convolution Neural Network,CNN)的多種算法被廣泛提出與應用。1998年LeCun 等人提出了LeNet 模型,最初是為了解決手寫數字識別的問題,同時也標志著卷積神經網絡發展的開始。隨后,多種優秀的神經網絡模型接連被提出,例如AlexNet、VGGNet、ResNet、Inecption 等。這些模型已被成功地應用于日常生活及工業生產場景當中,如人臉識別[5]、圖像分類[6]、缺陷檢測[7]等不同的領域。為解決垃圾分類問題,文獻[8]采用了改進的Faster R-CNN 的方法將識別率達到了81.77%;文獻[9]采用卷積神經網絡對塑料垃圾進行分類;文獻[10]通過引入注意力機制來提高網絡的準確率。雖然已有研究人員將卷積神經網絡運用于垃圾分類,但其準確率和識別速度都有待提升,實用性也需考量。
本次研究通過對Inception 模塊和殘差模塊進行特征融合,可以對兩種模塊進行優勢互補。這不僅能通過不同尺寸的卷積核來提取更為豐富有利的信息,也能防止梯度爆炸。同時在Inception 模塊后加一層Batch Normalization 組成Inception-Residual 模塊進一步提高網絡的準確率和分類速度,最終模型的準確率為97.67%,從而達到應用標準。本文首先探索了本次研究所使用的網絡模型,并對其進行分析;其次通過對數據集和網絡參數的選擇對實驗結果進行比較分析,從而驗證本次研究的可靠性。
1 模型設計
1.1 卷積神經網絡
卷積神經網絡(CNN)是模擬人的大腦來分析圖像和數據信息,常用于解決目標檢測和分類問題,其核心“成員”是卷積層和池化層。CNN 能自動提取每類圖片中的特征進行自主學習,模型結構如圖1所示。其主要是通過增加卷積層的通道數或改變卷積核的大小來提高特征提取能力。但伴隨著卷積層的層數和每層輸出通道數的增加會帶來計算量增大、卷積核大小的選擇多樣化和容易出現過擬合等問題。

圖1 CNN 模型結構Fig.1 CNN model structure
1.1.1 Inception 模塊
為保證多種卷積核可以同時對同一層數據進行多種特征提取,Inception 模塊由此誕生。Inception 模塊采用了多分支結構和1×1 卷積核。多分支結構構造了一種較高的稀疏結構,保證了最優的卷積結果和較高的特征復用率,有效地避免了因卷積核大小選取的差異而導致網絡學習效果較差。在彌補了現有方法在特征提取上不足的同時,提高了網絡的分類性能和泛化能力[11]。1×1 卷積可以跨通道組織信息,優化了網絡的表達能力,并且能夠達到升維或降維的作用。
Inception 模塊不僅在寬度上有所改善,還對卷積核結構進行了改進。Inception 模塊采用2 個3×3的卷積核來替代1 個5×5 的卷積核,其結構如圖2(a)所示。除此之外,Inception 模塊還采用了拆分卷積核的方法,即將1 個二維卷積核拆成2 個一維卷積核。如圖2(b)、2(c)所示,將7×7 的卷積核拆分成1×7 和7×1 的2 個卷積核;將3×3 的卷積核分解成1×3 和3×1 的2 個卷積核。這種處理方式具有增加特征多樣性、簡化空間結構、加快運算速度和增加非線性表達能力等優勢。


圖2 Inception 模塊Fig.2 Inception model
1.1.2 殘差模塊
在深層網絡模型中,隨著模型層數的不斷加深,網絡會出現梯度爆炸和權重衰減現象。殘差網絡(ResNet)的提出解決了這一問題。同時解決了因計算量的提高和運行時間的增加,而導致準確率出現飽和甚至下降的現象。該網絡通過采用跳躍連接(Shortcut Connections)的方式擬合前一層的殘差映射,在不增加模型的參數和復雜度的前提下,極大地保證了特征提取的準確性和多樣性[12]。殘差模塊(Residual Module)如圖3所示,在傳統的卷積模型上加入了一個恒等映射層y=x,圖中F(x)表示的是殘差,F(x)+x 是最終的映射輸出。

圖3 殘差模塊Fig.3 Residual module
殘差模塊最后輸出的公式為

式中:F(x,{wi})=W2σ(W1x),Wi為偏置,σ 表示ReLU激活函數。殘差模塊可以有效地防止因梯度爆炸而導致的輸入信息丟失和準確率瞬間下降的問題,同時能夠幫助神經網絡學習不同層之間的差異性信息。
1.2 垃圾分類模型
本次研究采用了基于特征融合卷積神經網絡的垃圾分類方法,保留了傳統InceptionV3 卷積神經網絡的結構。該模型是將原InceptionV3 中的Inception 模塊替換成Inception-Residual 模塊。模型的輸入是經過預處理后的垃圾圖片,輸出的是要估計的垃圾分類。
Inception-Residual 模塊是由Inception 模塊、殘差模塊和Batch Normalization(簡稱BN)層組成,改進后的模塊保留了原有模塊的優點,進一步提高了深度神經網絡的特征提取能力,有利于網絡對原始數據的全面學習和防止過度學習。Inception 模塊和殘差模塊各有其優缺點。Inception 模塊通過增加網絡寬度來提升網絡的準確率和訓練速度,但也會因其對網絡性能的提升作用有限、寬度與深度失衡和變種復雜等問題而導致出現過擬合和參數運算效率低的現象。殘差模塊雖然加深了網絡的深度,但同時也增加了參數量和運算速度,并且特征提取效果略遜于Inception 模塊。因此,將Inception 模塊和殘差模塊相融合可以起到特征互補和優化網絡模型的作用,但相對于單獨的Inception 模塊增加了訓練參數量,并且跳躍連接在復雜的模塊中會容易導致訓練中斷的現象。
Inception-Residual 模塊如圖4所示。該模塊既保留了Inception 的輕量化的特點,減少了網絡整體的訓練參數,提高識別速度,還可以防止因梯度爆炸而導致的準確率下降和因模型復雜而帶來的訓練中斷的問題。同時,在Inception 模塊后面加入一層BN 層可進一步對拼接后的數據進行歸類、優化數據分布,可以防止訓練中斷、提高訓練速度和減少達到最優訓練結果的迭代次數等[13],BN 層表示如下。

圖4 Inception-Residual 模塊Fig.4 Inception-Residual module

式(2)是對每個Batch 求取平均值;式(3)是求每個Batch 的方差;式(4)是對輸入的數據進行標準差歸一化操作,使得數據符合標準正態分布,有助于加快梯度下降;式(5)的作用是恢復出原始某一層所學到的特征分布。
該模型的整體結構如圖5所示。首先對輸入的圖片采用3×3 卷積和最大池化,進行簡單的處理和特征提取。然后將輸出的結果依次傳入Inception-Residual-A、Inception-B、Inception-Residual-C、Inception-D、Inception-Residual-E,通過更多不同尺寸的卷積,獲取更加豐富的特征。最后對輸出結果進行全局平均池化和全連接,從而獲得最終的分類結果。

圖5 Inception-Residual 網絡模型Fig.5 Inception-Residual network model
其中Inception-Residual-A、Inception-Residual-C、Inception-Residual-E 3 個模塊是在Inception-A、Inception-C、Inception-E 的基礎上對其進行如圖4所示的改進,在原有模塊的拼接輸出后添加一層BN 層,然后擬合上一層的殘差映射。Inception-B 和Inception-D 均是由3 個分支組成的Inception 模塊,具有改變輸出通道和圖片大小的作用。Inception-B 與Inception-A 相似,只是減少了單獨的1×1 分支,并且將平均池化層(Avg poolling)改為最大池化(Max poolling)。Inception-D 相比于Inception-C 保留了1×7 和7×1 分支,并在其后增加了1 層3×3 卷積,同時添加了3×3 和最大池化2 個分支。因此,本實驗所提出的方法實現了整個網絡端到端的訓練,并且在增加層數的同時避免了梯度爆炸、提高了訓練速度和減少信息丟失等問題的出現。
2 實驗及結果分析
2.1 數據集
2.1.1 數據采集
本次研究采用的數據集大多數來自華為垃圾分類挑戰杯的數據集,其余數據集是采用網絡爬蟲的方式收集到的,并進行手工標注,總共包含2.5 萬張圖片。數據集包含日常生活中較為常見的4 種垃圾類別:其他垃圾、廚余垃圾、可回收垃圾和有害垃圾。輸入卷積神經網絡中的圖片大小均為299×299×3 的三通道RGB 彩色JPG 圖片。將數據集中所有圖片打亂后按照6∶2∶2 的比例劃分成訓練集、驗證集和測試集。
2.1.2 數據預處理
為確保模型結果的可靠性、提高訓練精度,故在數據處理階段對數據進行了信息歸一化和標準化操作。同時對數據進行了隨機裁剪、水平翻轉、垂直翻轉等不同的數據增強技術,從而降低了對圖像的成像要求。在訓練過程中,處理后的圖片隨機組合后進入網絡模型中,有利于提升模型的魯棒性和泛化能力。
2.2 實驗參數設置及評估指標
2.2.1 參數設置
在模型訓練過程中,學習率(lr)設置為0.001,批尺寸(Batch_Size)設置為16,進行600 次迭代(Epoch)運算。為增強神經網絡各層之間的非線性關系訓練采用ReLU 作為卷積層之后的激活函數。ReLU是一個分段函數,當輸入為負時,輸出為0;否則,輸出等于輸入[14]。使用Softmax 分類器輸出最后的識別結果,并且采用隨機梯度下降(SGD)的方法進行參數學習,其中動量(Momentum)設置為0.9。
2.2.2 實驗評估指標
在進行多目標檢測和分類中,準確率(Accuracy)作為目前最主要的評判指標,即模型預測正確數量占總數量的百分比。本文主要通過對各模型的準確率對比作為本次模型評判標準。除準確率以外,對模型評估的標準還有精確率(Precision)、召回率(Recall)、綜合評價指標(F1-score)。精確率是在被識別為正類樣本中實際為正類的比例;召回率為在所有正類樣本中,被正確識別為正類的比例;綜合評價指標是一種統計量,是精確量與召回率的加權調和平均,其綜合了精確率與召回率的結果,常被用來評價模型好壞[15]。本文應用精確率、召回率和F1 值來分析改進后的Inception-Residual 模型對4類垃圾的識別效果。各評估指標的計算公式如式(6)~式(9)所示。
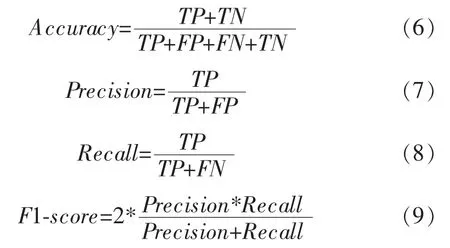
TP(True Positive,真正例)是指將正類正確預測為正類的個數。TN(True Negative,真反例)是指將負類正確預測為負類的個數。FP(False Positive,假正例)是指將負類錯誤預測為正類的個數。FN(False Negative,假反例)是指將正類錯誤預測為負類的個數。
2.3 實驗結果與分析
針對本次研究所提出的Inception-Residual 模型,通過進行對比實驗來驗證其性能。本文記錄了相同數據集、相同訓練環境下使用3 種不同模型所訓練的準確率,如表1所示分別羅列了InceptionV3、ResNet101 和Inception-Residual 3 種不同圖像識別模型應用于本次研究的準確率、測試集所消耗的時間和總的訓練參數。其中本次研究所提出的方法最終訓練準確率為97.67%,驗證準確率為93.98%,測試準確率為94.19%,訓練準確率分別高于其它圖像識別算法2.08%、3.31%;測試集所消耗的時間也略低于其它網絡;總訓練參數也比Resnet101 減少了152.2 M。綜合評價,改進后的Inception-Residual 網絡通過犧牲較少的訓練參數從而提高準確率這是值得的。
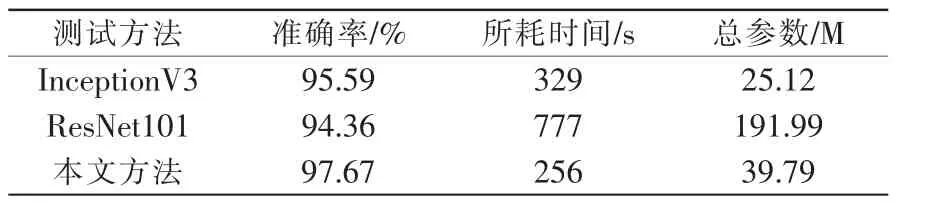
表1 各種圖像識別算法的性能比較Tab.1 Performance comparison of various image recognition algorithms
本次研究所采用的Inception-Residual 模型對4種類別垃圾識別的精確率、召回率和F1 值如表2所示。除有害垃圾的召回率外,其余數值均在90%以上,相較于其它模型均有所提升。由實驗結果可知,該模型對4 類垃圾有較好地識別效果,并且該模型可以對垃圾圖片進行快速穩定的識別,這也證明了本此研究所設計的垃圾分類模型完全符合預期目標。
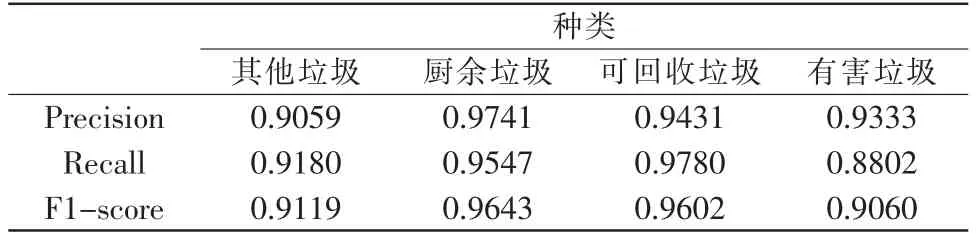
表2 Inception-Residual 模型對不同垃圾種類的評估結果Tab.2 Inception-Residual model assessment of different types of garbage
由于本次實驗所采用的數據集圖片背景雜亂、數據分布不均,導致卷積神經網絡對垃圾圖片的分類帶來了極大的挑戰。圖6顯示了該模型在測試集上所得出來的混淆矩陣,從圖中可以看出,被誤分類的數據較多,下一階段將重點解決這一問題。

圖6 測試模型混淆矩陣Fig.6 Test the model confusion matrix
3 結語
本次研究主要針對人工分揀垃圾工作環境差、效率低和垃圾處理不當而造成的環境污染等問題,通過對現有的Inception 模塊和殘差模塊進行融合和改進,構建了一種更加快速和準確的Inception-Residual 模型,并對其進行分析和實驗驗證,最終準確率可達到97.67%,滿足實際應用的需求,充分證明了該模型對垃圾圖片有較高的準確率。下一步將在本次研究的基礎上進一步改善模型,提高模型的整體性能;擴大數據集并對四大類垃圾進行細分,從而實現更加精準地識別各種垃圾,提高識別精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
