基于多傳感器融合的軌道識別方法探究
2021-09-24 03:33:16朵建華楊柏鐘
現代城市軌道交通 2021年9期
關鍵詞:融合
朵建華,楊柏鐘
(寧波市軌道交通集團有限公司運營分公司,浙江寧波 315500)
1 引言
地鐵列車全自動無人駕駛[1]可以在降低人為失誤風險的同時大大提高運營效率,進一步提升出行質量和乘坐體驗,其運行安全主要依賴信號系統的可靠性。信號系統可以實現調度規劃層面的無人駕駛,但只能保證監測行進列車這種合作目標,對于軌道線路上突發性、不可預測的非合作目標侵界與異常則需要車載設備實時進行感知。對軌道識別的研究無論是對于異物入侵檢測,還是對于實現列車的無人駕駛,都具有重要的意義。
2 研究背景
可見光相機對目標的顏色和紋理比較敏感,可以完成目標分類、檢測、分割、識別等任務,已經被廣泛應用于汽車無人駕駛領域的道路車道線檢測,但與道路車道線檢測相比,對軌道交通領域的軌道檢測研究并不多。目前,國內已經有一些基于圖像的算法研究[2-3],主要針對火車軌道、有軌電車軌道等地面軌道,根據像素點計算曲率等特征將軌道與其他場景元素區分。然而,地鐵的應用場景不僅包括高架,也包括水泥混凝土澆筑的地下隧道,環境復雜度較高,軌道的特征更加難以掌控,單一模型已無法滿足軌道識別的實際需求。
隨著近年來卷積神經網絡CNN(Convolutional Neural Networks)[4],特別是針對于語義分割的全卷積網絡(Fully Convolutional Network,FCN)[5]的發展與成熟,其超強的學習能力使其在各個領域嶄露頭角。例如,香港中文大學Xingang Pan等人開發的SCNN(Spatial CNN)[6],該網絡適用于連續形狀結構或者大型的目標,應用在道路上的車道線檢測方面取得了較好的效果。
然而,用單目相機獲取到的圖像只有二維信息,用于檢測三維場景中的物體有缺失維度的缺陷。針對這一問題,目前的研究方向有2個分支:一個分支是使用雙目相機獲取具有深度信息的圖像,對紅綠藍深度(Red Green Blue Depth,RGBD)圖像直接進行語意分割與識別,使用基于RGBD數據的深度神經網絡包括CFN(Cascaded Feature Network)[7]、3DGNN(3D Graph Neural Network)[8]、ACNet(Asymmetric Convotution Network)[9]等;另一個分支是將圖像識別結果與其他測距傳感器,如紅外測距儀、毫米波雷達、激光雷達等獲取的距離數據融合。
3 實現方法
基于車道線檢測算法的研究基礎,單目相機對軌道的識別采用U-Net[10]模型,這是一種由FCN發展而來的網絡結構,它在使用少量數據進行訓練的情況下就能獲得精確的分割結果,最初用于醫學圖像分割。
相比于其他測距傳感器,激光雷達傳感器具有測距精度高、探測范圍大、抗干擾力強等優點[11]。三維激光雷達可以獲取周圍物體在三維空間中的坐標值,提供直觀的位置信息。然而激光雷達傳感器的角分辨率[12]遠不如視覺傳感器,也不能獲取物體表面的顏色信息。
通過結合單目相機和激光雷達的軌道識別方法,旨在通過融合處理2種傳感器獨立檢測的軌道數據,避免單一傳感器的局限性,使得到的軌道坐標更精確,以達到更好的識別效果。
3.1 相機-激光雷達標定
多傳感器融合的基礎條件之一就是每個傳感器檢測到的目標需要統一到同一個坐標系下,如世界坐標系或者車身坐標系,因此需要對多個傳感器進行聯合標定。將激光雷達和相機的安裝位置固定后,進行相機的內參標定以及相機與激光雷達的聯合標定。通過使用棋盤格對相機內參進行標定[13]。在獲取到相機內參后,通過張貼二維碼的方式獲取指定物體在相機坐標系下的坐標信息,通過對指定物體的激光點云進行處理,獲取指定物體在激光坐標系下的坐標信息,從而可以建立同一個物體在激光與相機坐標系下的點對點坐標映射。在獲取多組點對點映射數據后,可通過奇異值分解(Singular Value Decomposition,SVD)[14]的方式求取坐標系之間的轉移矩陣。
3.2 傳感器時間同步
多傳感器融合的基礎條件之二就是多個傳感器之間的時間同步,保證同一時刻采集的傳感器數據的時間戳是基本一致的。如果沒做好時間同步,那么處理某個傳感器的數據幀時很可能獲取不到其他傳感器對應時刻的數據幀,就會導致多個傳感器的數據融合失效,不能實現相關功能。對于目前 AI 應用領域的多傳感器、子系統之間的時間同步[15],一般只需要達到毫秒級。目前單目相機支持網絡時間協議(Network Time Protocol,NTP)進行時間同步[16],而激光雷達一般都支持GPS或者精確時間協議(Precision Time Protocol,PTP)[17]進行時間同步,均能滿足傳感器之間時間同步的要求。
3.3 獲取數據
使用激光雷達和相機同時錄制列車前方軌道的視頻和激光點云,并以隔幀抽取的方式將獲取的視頻轉成圖片格式,避免產生大量相似度過高的數據。
3.4 訓練模型
利用標注工具結合手動調整,標注圖片中的軌道區域,如圖1所示。使用卷積神經網絡框架[18](Convolutional Architecture for Fast Feature Embedd-ing,CAFFE),將經過標注的圖片作為訓練集輸入U-Net網絡進行訓練,當損失函數收斂后訓練結束。

圖1 軌道標注
損失函數選用的是Softmax_Loss,這是CAFFE中常用的一種損失函數,計算主要分為2步。
(1)計算Softmax歸一化概率:
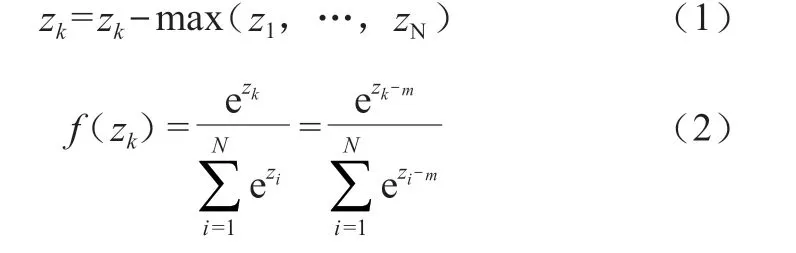
式(1)、式(2)中,i= 1,2,…,N;m= max(z1,…,zN)。
該層共有N個神經元。zk表示第k個神經元的輸入。公式(1)表示將zk的每一個元素減去m,即減去zi的最大值。公式(2)中對zk和zi都做公式(1)中的處理,減去m。這樣處理是為了數值穩定性。
公式(2)中的f(zk)表示第k個神經元的輸出, e 表示自然常數表示了該層所有神經元的輸入之和。
Softmax函數最明顯的特點在于,它把每個神經元的輸入占當前層所有神經元輸入之和的比值,當作該神經元的輸出。這使得輸出更容易被解釋:神經元的輸出值越大,則該神經元對應的類別是真實類別的可能性更高。
(2)根據交叉熵計算損失[19]:
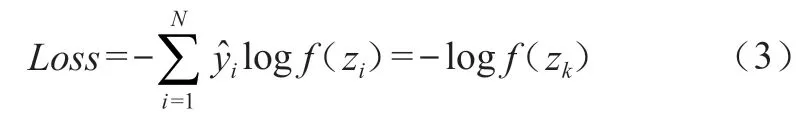
式(3)中,為標簽值,k為標簽為1的神經元所對應的序號,其余神經元所對應的標簽值為0。
訓練約6個Epoch(時期)后,Loss值收斂到較小的值。當Normalize(歸一化)為True時,Loss值會除以樣本數。實際訓練過程中準備了約2萬張軌道圖片的訓練集,Loss值在約6個Epoch后收斂到0.01左右。
3.5 傳感器融合
融合傳感器數據獲得軌道方程的步驟如下。
(1)將訓練后的模型放入U-Net網絡,當有圖像數據輸入時,經過神經網絡識別輸出軌道區域邊緣的像素點,這些像素點表示軌道的圖像識別結果。根據前期標定得到的相機內參和外參,將像素點投影到激光坐標系,實現從相機坐標系到激光坐標系的轉換,表示軌道的點不再是像素而是具有空間坐標的點。由于相機獲取的圖像提供的是二維信息,此時的軌道點僅包含水平面上的空間位置信息,沒有垂直方向上的準確空間位置信息。
(2)獲取與輸入圖像同一時刻的激光點云,由于圖像識別到的軌道點與激光點云中的點并不是一一對應的,為了融合同一時刻的圖像數據和激光數據,設置一個大于軌道寬度的距離閾值,根據圖像識別的軌道點在水平方向上的坐標,找到軌道附近在距離閾值內的激光點集。
(3)考慮到激光雷達的運動畸變,需要對激光點云作運動補償。運動畸變是指一幀激光點云中的點在采集時存在時間差,由于激光雷達隨著載體在運動,不同激光點實際上在不同的坐標系中,記錄的激光點位置與實際位置存在偏差。運動補償過程是首先將原始點云從Lidar坐標系轉到IMU坐標系下,通過IMU數據進行位置漂移估算,再將估算值和Lidar數據進行差值計算,最后再將IMU坐標系下的點云轉換到Start時刻的Lidar坐標系下,從而得到一幀運動補償后的、能更好反映出同一時刻下與軌道圖像一致的真實軌道環境點云數據。
(4)由于設置的距離閾值大于實際軌道寬度,選取的激光點有冗余,不僅包含軌道,同時也包含其他無關區域,需要對激光點做進一步篩選處理。使用DoN算法對點云作過濾:以某一激光點作為中心,在某一半徑r距離內的相鄰激光點擬合平面,并計算得到該激光點的表面法向量的模;當r選取不同大小時,表面法向量的模不同;與平面相比,軌道邊緣的表面曲率變化較大,在不同半徑r下對應表面法向量的模差異性也較大。假設在較小的半徑rS下計算得到的表面法向量的模為mS,在較大的半徑rL下計算得到的表面法向量的模為mL,Δm= |mL-mS|,去除Δm小于閾值對應的激光點,保留邊緣特征明顯的點。根據點與點之間的歐式距離去除DoN過濾產生的離散點:計算剩下的每一個點到最近N個點的平均歐式距離,將距離值過大的點作為離散點去除。
(5)由于經過上一步驟的過濾會去除一部分表示軌道的激光點,剩下的激光點可能由于點數過少無法直接用于曲線擬合,需要運用生長算法選出更多表示軌道的激光點。
(6)將上一步驟得到的點云作為種子點,選取種子點最前端前后長度為d的一段點云作為生長起始段,由于在水平方向上軌道曲率的變化率較小,可認為在小距離范圍內(例如1 m≤d≤3 m)軌道形狀是近似直線。根據生長起始段重點激光點在水平面上的坐標(x,y)擬合直線方程y=kx,其中k表示斜率,y軸正方向是水平向前,x軸正方向是水平向左。
(7)根據軌道的寬度和高度設置閾值xM和zM,從步驟(3)所得的激光點集P中選出到種子點集的橫向距離不大于xM且垂直距離不大于zM的點,并將這些點合并到種子點中,重新選取種子點最前端前后長度為d的點云擬合直線得到斜率,如果前后2次的斜率變化Δk在設定的范圍內,則更新起始點并繼續向前生長,否則生長結束。向后生長的算法與向前生長的算法類似,得到表示軌道的激光點云。在水平面和垂直平面上分別對軌道點云作曲線擬合從而得到軌道方程。
4 實驗結果
列車車頭安裝300線激光雷達和8 mm單目攝像機,在40~60 km/h條件下同步采集視頻和激光點云數據。經過數據標注、訓練和數據融合后,實際運行結果如圖2、圖3所示,結果表明,本算法可以識別出軌道的直道和彎道,并且在大約50 m內具有較好的識別效果,融合算法在一定程度上彌補了圖像深度學習結果的邊緣粗糙問題,并可以根據擬合結果獲取軌道坡度信息,但是由于激光點云隨著距離增大而稀疏的特性,對50 m以外的軌道識別只能根據擬合方程預測,會存在一定的誤差。

圖2 軌道圖像推理結果

圖3 軌道激光點云
圖4a中紅色的點表示根據融合算法識別的軌道點云,軌道邊緣已經比較平滑;圖4b是融合結果的側視圖,網格邊長1 m,圖4b中綠色表示軌道擬合曲線,從右端到左端呈緩慢上升趨勢,融合算法使軌道坐標具有了三維坐標空間中垂直水平面方向上的信息。

圖4 軌道識別融合結果
5 結論及建議
(1)相較于利用軌道的邊緣特征和直線特征進行識別的傳統圖像處理算法和采用單一傳感器的識別算法,基于深度學習U-Net網絡模型的軌道識別算法,通過自動學習優化參數和權重,提取圖片特征,對不同環境具有較強的魯棒性,融合了基于深度學習網絡模型和激光點云處理的軌道識別算法更能發揮不同傳感器的優勢,對不同環境具有較強靈活性和普適性。
(2)實驗也表明,圖片標注的精度以及傳感器標定精度會影響到識別和融合的效果,因此提高訓練圖片的數量和質量,優化對傳感器標定的方法,將是基于多傳感器融合的軌道識別算法的改進方向。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
數學年刊A輯(中文版)(2022年4期)2022-02-16 08:17:34
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
無線電通信技術(2021年4期)2021-07-13 08:58:28
無線電通信技術(2021年3期)2021-06-08 03:33:48
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
福利中國(2015年4期)2015-01-03 08:03:38
