基于大數據崗位分析推薦系統
2021-09-27 08:15:28程棟檜高琪琪
智能城市 2021年16期
劉 飄 程棟檜 高琪琪 魯 琛
(無錫職業技術學院,江蘇 無錫 214121)
在數據量快速增長的時代,大數據正迅速成為許多組織的社會需求和標準結構。通過人們整理、分析、提取和集成大量數據,能夠發現新的數據,并可以創造出新的價值,讓標準化的認知、判斷、思維方式、服務模式和產品形式形成嶄新的外觀和發展方向。隨著互聯網崗位需求增加,人們需要從大量職位信息中尋找出適合自己的崗位。以往人們需要從許多職位信息中對比、分析這個職業在當前社會的需求和前景。但這樣煩瑣的方式已難以滿足當前人們的需求,使得大數據分析快速發展。通過大數據崗位分析系統幫助高校學生透析職位市場需求變化,預測就業前景,給出現階段符合自己條件的崗位。
1 大數據崗位分析推薦系統環境需求
本系統采用B/S體系架構,設計開發采用Linux開發模式,先在Windows上進行系統和前端的編碼實現,再在Linux上進行測試部署大數據集群環境。
1.1 數據分布式抓爬蟲
使用Python開源爬蟲框架Scrapy并結合redis數據庫,實現從招聘網站分布式爬取職位信息數據,大幅度提高爬蟲的效率。使用Scrapyd提供的Scrapyd JSON API請求管理爬蟲任務,再結合Gerapy可視化管理工具調用Scrapyd提供api,實現對爬蟲任務的打包部署、刪除、停止、監控、日志分析等功能的可視化管理。
1.2 大數據平臺環境
搭建分布式Hadoop集群系統,在此基礎上建立HBase非關系數據庫,對爬取的職位信息進行存儲,以便后續進行數據分析。
1.3 數據分析挖掘Spark
搭建Spark計算引擎,并采用Yarn進行資源分配,進行數據轉移的分布式計算,以升高程序運算的速度,并把職位信息的分析結果存儲到Mongodb非關系數據庫中。
1.4 Web端的應用
用戶訪問網頁并發送http響應請求,由Python開源框架Django進行相應響應,如用戶發送數據可視化請求,使用Django調用Mogodb數據庫調用數據,并將其結果進行響應返回。
2 大數據崗位分析推薦系統實現功能需求
隨著當代互聯網蓬勃發展,大量的工作崗位在網上發布,學生或求職人員需要從大量的數據中分析和了解當前行業的技能要求、薪酬、崗位地區分布、學歷要求、工作經驗、職位發布數量等信息,較為困難。亟須一套能夠幫助學生和求職人員分析崗位信息,將處理好的數據直觀地展示給人們的軟件程序。本系統基于近期行業對人才需求信息進行分析,主要實現了對職位信息分布式爬取、對信息分析處理、對處理完的信息可視化展示、用戶給出需求經行崗位推薦。
3 大數據崗位分析推薦系統特點
當前,大多數國內招聘網站使用基于內容的協同過濾算法來對用戶進行推薦。基于用戶的篩選和基于職業的篩選顯著提高了推薦的質量,但是用戶通常受到特定職位要求的限制或對行業或環境的了解不清,因此無法更好地選擇職位。
(1)使用大數據技術進行分析,采用大數據分析算法,對工作行業分布、城市分布、工資分布、學歷信息、各個地區的用戶等數據進行分析,讓用戶對行業和企業工資有清晰了解。系統可以幫助求職者選擇自己的職業,以便求職者可以更好地了解自己的環境。
(2)利用Spark算法庫對職位信息內容進行特征抽取分詞,并轉換為哈希成特征向量。使用關鍵詞提取的方法對職位所需的具體技能進行提取,通過Spark機器學習將相同職位所需要掌握的技能,使用貝葉斯算法進行分類建立模型,再使用建立的模型為求職者進行智能推薦。
4 大數據崗位分析推薦系統模塊功能介紹與設計
4.1 運行的基礎平臺
大數據基礎平臺采用三臺服務器搭建,一臺作為主節點,另外兩臺服務器為從節點。大數據集群主要搭建和使用Hadoop大數據平臺、Zookeeper分布式協調服務、Spark計算引擎、Hbase數據庫和Mongodb數據庫等。
4.2 數據爬取
使用三臺服務器對python開源框架Scrapy結合redis數據庫的分布式爬蟲,在主節點上對需要招聘信息的url地址經行爬蟲,并將其存入redis數據庫中。另外兩臺從節點從redis數據庫中調用url進行對招聘網站上職位信息的爬取,并將爬取的職位信息數據存在Hbase數據庫中,再結合使用Scrapyd和Gerapy可視化管理爬蟲集群。
Scrapy是一套純Python語言開發的、用于爬取網頁內容或各種圖片并提取結構化數據的開源網絡爬蟲框架,可以應用于數據挖掘、信息處理或存儲數據等一系列操作中,是目前Python中使用最受歡迎和最廣泛的爬蟲框架。
Redis是遵循鍵值存儲原理的非關系數據庫,內存中鍵/值存儲主要作為一個應用程序的高速緩存或快速響應數據庫。Redis將數據存儲在內存中,不存儲在磁盤或固態驅動器(SSD)上,Redis提供了速度、可靠性和性能。
Scrapyd是一個應用程序,可以在服務器上部署爬蟲并計劃爬網作業,并提供對爬蟲項目的API管理。
Gerapy用于Scrapyd集群可視化管理,對Scrapy日志分析、自動打包和部署、啟動和停止服務、在線修改代碼、監控和警報以及Web應用程序。
4.3 數據存儲
系統數據的存儲分為分布式HBase存儲和Mongodb存儲。
HBase是一個基于在HDFS上開發的分布式數據庫,不同于常見的關系數據庫,其非常合適鍵/值對數據存儲的數據庫,主要用以存儲龐大的結構化數據。邏輯上,HBase存儲用于表、行和列的數據。與Hadoop類似,HBase可以針對企業進行水平擴展,通過增加廉價商業服務器的發展,提高學生計算和存儲管理能力。
HBase是面向列的NoSQL數據庫,雖然類似于包含行和列的關系數據庫,但不是關系數據庫。關系數據庫面向行,HBase面向列。
在此系統中需要處理和分析大量半結構化或非結構化數據,在線分析處理大量數據,并進行挖掘與分析,采用HBase這種非關系數據庫存儲大量數據比關系數據庫更具有優勢。
MongoDB是一種分布式非關系數據庫,MongoDB數據結構如鍵值對構成,類似一個JSON文檔。Mongodb可以儲存更多的復雜的數據結構,查詢語言系統強大,語法結構相似于高級語言的查詢方式,如java語言面向對象的方式查詢。此外,還可以實現類似關系數據庫的查詢功能單表,提供對數據索引的最大支持。
MongoDB的非結構數據都存儲在類似于JSON的文檔中,使數據的持久性和合并更容易。應用程序的代碼對象已被推送到文檔模型中,可以簡單使用數據,架構的管理、數據的訪問和各種復雜豐富的功能不會受到任何影響,且沒有停機時間,可以動態更改架構,具有較好的操作靈活性。
系統需要對數據進行分析和可視化處理,對數據管道、數據搜索、圖形處理以及數據的可靠性、靈活性和安全性需求較大,采用Mongodb數據庫更具有效性和實用性。
4.4 數據分析
使用Python編程語言調用Spark API,實現對HBase數據庫中的大量非結構化職位信息數據進行快速分析和處理,可以進行行業的學歷統計、行業職業崗位統計、行業需求技能統計、行業薪酬統計、職位發布日期統計以及行業工作經驗統計以及行業工作地點統計的數據處理工作,并將分析結果存儲到Mongodb數據庫中。
Spark是一種快速發展的新開源技術,可在計算機節點群集上工作。速度是Apache Spark的標志之一,在這種環境下工作的開發人員可以獲得基于RDD(彈性分布式數據集)框架的應用程序編程接口。RDD可以將節點分離到群集上的較小分區中,以便獨立處理數據。
4.5 信息展示
使用web網頁方式展示信息,使用python開源框架Django。為了給用戶可視化直觀展示采用了Apache的ECharts開源可視化圖表庫,提供更直觀、交互豐富、可高度進行個性化定制的數據信息可視化圖表。
4.6 系統采用的推薦算法
利用Spark MLlib機器學習的樸素貝葉斯算法對職位信息進行建模,學生或求職者需要推薦合適職位時,可以通過提交表單對web法出請求,程序對其做出響應,并調用推薦算法程序進行分析,再將結果返回給用戶。
Spark機器學習庫(MLlib)建立在Spark上,并在分類、回歸、決策樹,聚類等領域提供了大量算法。Spark在內存中運行,性能較好,可以與其他模塊結合使用,以執行特征轉換、提取和選擇。
Spark MLlib支持迭代計算,優化性能和結果質量,提供了許多ML算法的分布式實現。算法具有低級基元和實用程序,可用于優化、特征提取和線性代數。
系統整體架構如圖1所示。
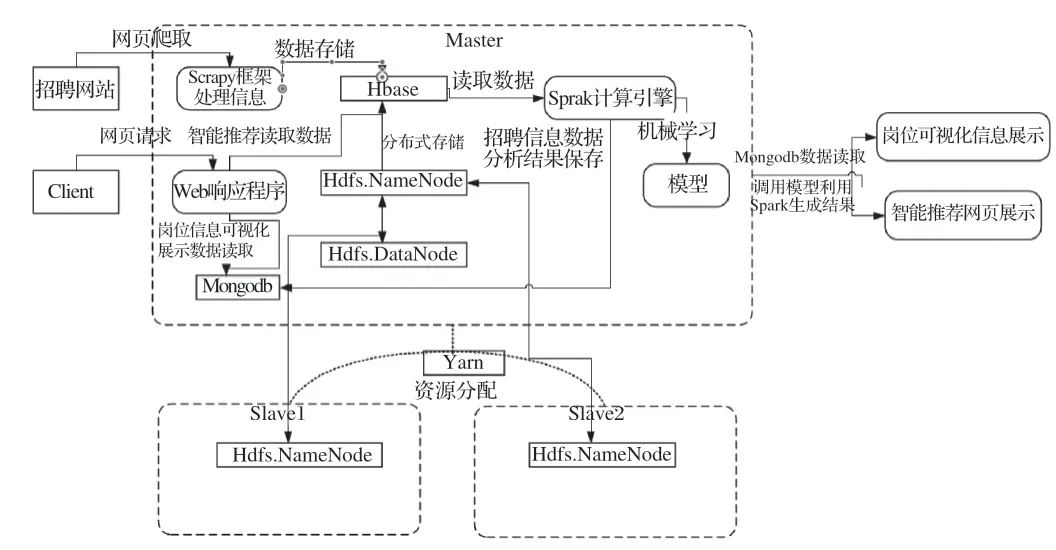
圖1 系統整體架構
5 結語
本文介紹了大數據崗位分析系統功能的實現與系統的運用。通過對系統設計和系統的實現做了比較詳細的介紹,并介紹了系統所依賴的各種環境并對其分析和比較其他工具的優勢,如Spark計算框和數據庫的選擇。通過大數據崗位分析系統幫助高校學生透析職位市場需求變化,預測就業前景,并給出現階段符合自己條件的崗位。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
電子制作(2018年18期)2018-11-14 01:48:24
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
