基于改進模糊C回歸聚類的水輪發電機組的模糊辨識
2021-09-28 08:27:02羅紅俊張官祥魏春陽陳緒鵬金學銘李超順
中國農村水利水電 2021年9期
羅紅俊,馬 龍,張官祥,魏春陽,陳緒鵬,金學銘,李超順
(1.中國長江電力股份有限公司白鶴灘電廠,四川涼山615400;2.華中科技大學土木與水利工程學院,武漢430074;3.長江三峽能事達電氣股份有限公司,武漢430000)
水輪發電機組具有時變、強非線性、非最小相位等特性,實現其精確建模一直是學術和工程應用研究的重點和難點,也是實現高品質控制的基礎。
建立被控對象的數學模型的方法大致可分為機理建模和系統辨識兩種方法。前者基于對系統特性和內部機理的清晰認知,后者是一種基于數據驅動的建模方法。由于水輪機內部的運動規律非常復雜,人們目前還無法給出水輪機的精確解析模型。而利用系統辨識方法可以建立能準確表達水輪發電機組的數學模型,克服解析法因機理不清或結構表述困難而難以準確建模的問題。
T-S 模糊模型是復雜系統辨識的有力工具,它結構簡單并且能夠以任意精度逼近非線性系統[1]。前提參數辨識和結論參數辨識是T-S 模糊模型辨識的兩大部分,通常采用模糊聚類算法來進行前提部分辨識[2-7]。聚類算法將輸入空間劃分成若干子空間,每個子空間對應一個局部線性子模型。以模糊C 均值[8]為代表的基于點原型的聚類算法將輸入數據空間劃分成超球形,僅通過樣本與中心之間的幾何距離來定義聚類,并不能很好地保障子模型的線性度。為了克服這一局限,Hathaway 和Bezdek[9]對模糊C 均值進行了改進,得到模糊C 回歸模型聚類算法。由此,發展了一系列基于超平面型聚類的T-S 模糊模型辨識方法[10-14]。
為了提升聚類效果,進一步提高模糊模型辨識精度,筆者對于模糊C 回歸算法進行了改進。首先,筆者應用改進后的模糊C 回歸算法進行前提部分辨識。初始化聚類超平面,通過最小化聚類目標函數求得聚類樣本對于超平面的隸屬度,并將得到的回歸方程與系統實際輸出之間的距離的倒數作為權值賦予各樣本的隸屬度,加權后的隸屬度構成的對角矩陣作為加權最小二乘法的權重矩陣,用以更新聚類超平面。在迭代達到精度要求后,即得到最優聚類結果。然后,采用新提出的超平面型隸屬度函數計算樣本隸屬于模糊規則的隸屬度。最后,利用帶遺忘因子的遞推最小二乘法在線辨識結論參數。將所提出的模糊辨識方法用于辨識某水電廠的水輪機調速系統,實驗結果驗證了所得模型的高精度和強泛化能力。
1 T-S模糊模型
T-S模糊模型分為前提部分和結論部分,以第i條模糊規則為例,T-S模糊模型[1]的結構如下:

對于第k個輸入向量,模型的最終輸出以加權解模糊的形式表示:
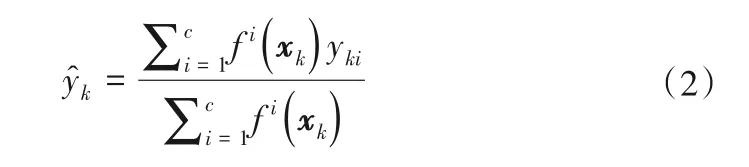
式中:f i(xk)為第k個輸入向量對于第i條模糊規則的總隸屬度。
2 T-S模糊模型辨識方法
2.1 前提部分辨識
模糊C回歸聚類算法[9]中,第i類中的數據樣本符合同一個線性回歸模型:
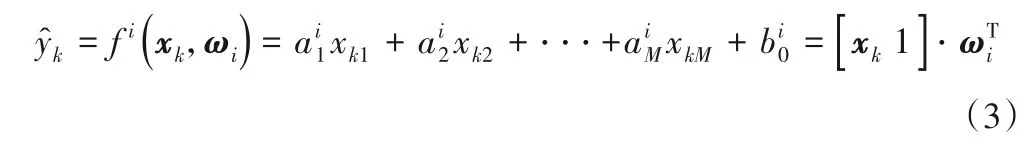
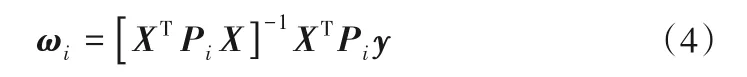
其中X=[xk1]n×(M+1),y=[yk]n×1,以樣本對于聚類超平面的隸屬度構成的對角矩陣作為權重Pi。
2.2 基于改進模糊C回歸聚類的前提參數辨識
模糊C回歸算法的聚類目標函數為:
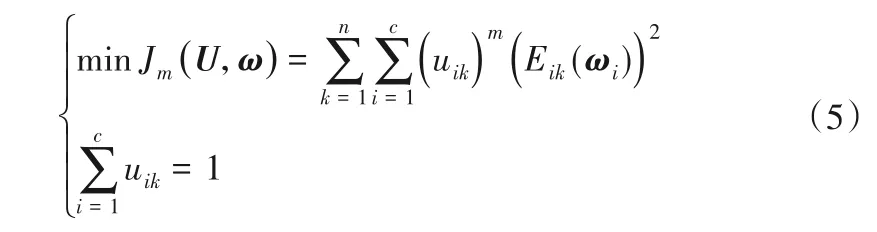
式中:U=[uik]c×n,m為模糊加權指數;Eik為系統輸出與聚類超平面間的距離誤差:
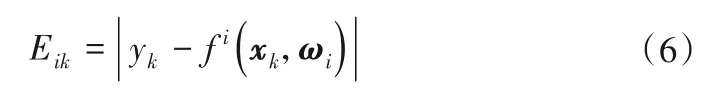
基于改進模糊C回歸聚類的前提參數辨識方法的具體步驟如下:
(1)設置相關參數。構造輸入輸出數據對(xk,yk),給定聚類數c,模糊加權指數m,迭代終止閾值ε以及最大迭代次數Tmax。
(2)計算最優聚類超平面。
①令t= 0,按照式(4)初始化聚類超平面,其中權重矩陣P的初值取為單位矩陣。
②依據式(6)計算誤差值Eik。
③以(5)為目標函數,用拉格朗日乘子法求解聚類樣本(xk,yk)隸屬于超平面的隸屬度:

④對計算超平面所用的矩陣P進行改進。

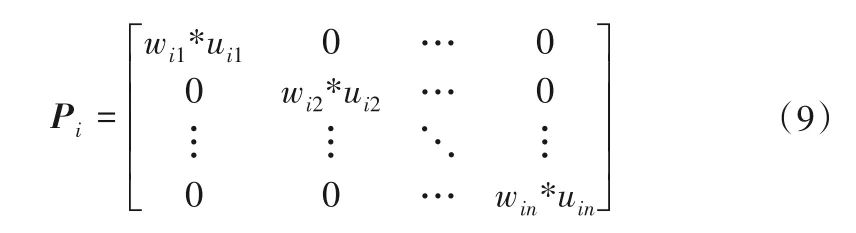
以誤差值的倒數wik作為權值賦給相應的隸屬度uik,由加權后的隸屬度構成Pi進行接下來的迭代計算。
⑤利用式(4)更新聚類超平面。
⑥t=t+1,重復執行步驟②至⑥,直到或者t> Tmax。達到終止條件后,輸出超平面參數向量ωi。
(3)利用新提出的超平面型隸屬度函數計算各樣本的隸屬度。
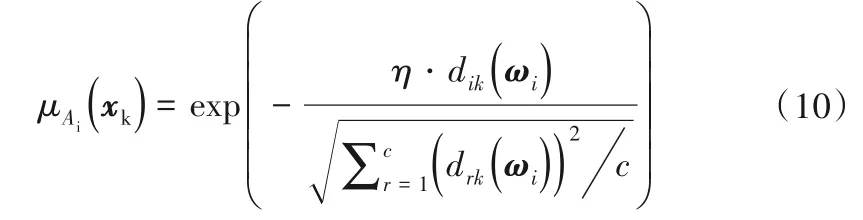
式中:η為調節系數;dik(ωi)表示第k個樣本到第i個聚類超平面的距離,由下式定義:
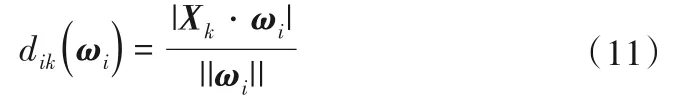
由于誤差值Eik表示實際輸出與聚類超平面之間的距離,它的值越小,樣本(xk,yk)的權重越大,因此提出了誤差值的倒數wik這一指標用于改進加權矩陣Pi。改進后的加權矩陣可以加快迭代計算的收斂速度,使得聚類超平面朝著更優的方向更快地更新。新提出的超平面型隸屬度函數避免了將超平面轉化為超球形聚類參數,不僅保留了超平面聚類在T-S 模糊模型辨識中的優勢,而且減少了額外的計算量。
2.3 結論參數辨識
將n個輸入輸出數據對(xk,yk)(k= 1,2…n)整理成矩陣形式:

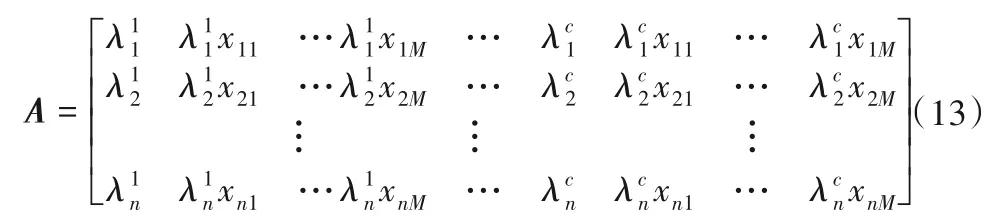

本文采用帶遺忘因子的遞推最小二乘法按照以下步驟來辨識式(12)中的結論參數。
①將系數矩陣A和系統輸出y對應地劃分為若干塊,每一塊包含若干個向量或僅包含一個向量。
②令k= 0,k代表待處理數據塊的編號。按照式(15)初始化結論參數,并用式(16)初始化迭代參數P(0)。
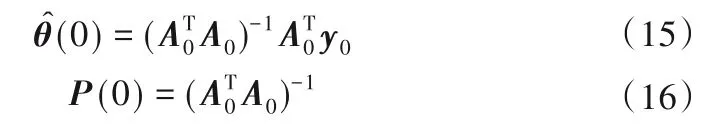
③k=k+ 1,計算相應的參數值:
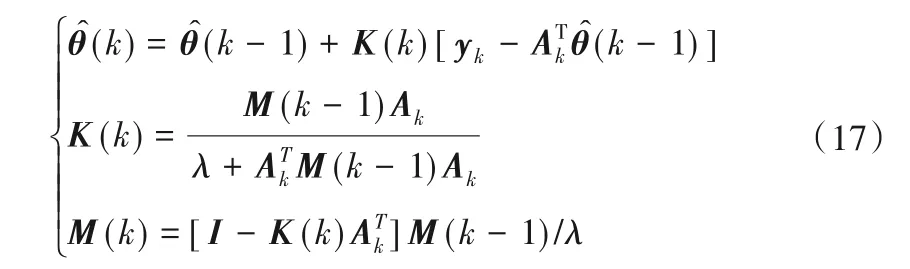
結論參數得到后,可計算出與輸入數據塊相應的輸出估計值向量:

④重復步驟③直到所有的數據塊處理完畢,那么就得到了最終的結論參數以及完整的預測輸出序列。
帶遺忘因子的遞推最小二乘法賦予新的觀測值更高的權重,并逐漸遺忘舊的樣本,它的應用使得辨識得到的模型可以隨著系統的變化實時地調整結論參數,這些是普通最小二乘法無法實現的。
3 水輪發電機組模型辨識
以混流式機組為例,水輪發電機組主要包含有壓引水系統、水輪機和發電機三部分。水輪機采用全特性數學模型,引水系統采用時滯方程模型,發電機采用一階慣性環節[15]。水輪發電機組結構如圖1所示。
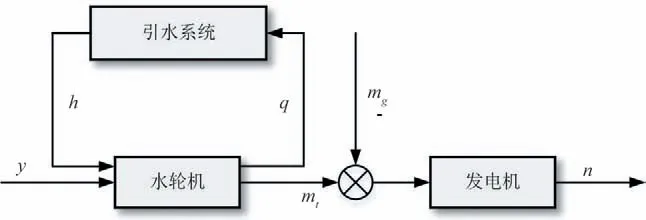
圖1 水輪發電機組結構圖Fig.1 Structure diagram of hydro-turbine generating unit
目前還無法建立精確的水輪機模型,因此實現水輪發電機組的高精度建模仿真比較困難。考慮到利用系統輸入輸出數據集進行系統辨識可以得到精確模型,我們采用基于改進模糊C 回歸聚類的T-S 模糊模型辨識方法對水輪發電機組進行建模。
圖2所示模型辨識圖說明了水輪發電機組模型辨識的過程。將水輪發電機組視為一個整體,以其輸入輸出構建數據對樣本,通過改進模糊C回歸算法得到聚類超平面參數,然后利用新提出的超平面型隸屬度函數計算各樣本的隸屬度,最后采用帶遺忘因子的遞推最小二乘法辨識結論參數。利用辨識所得模型參數,可計算模型輸出,即轉速估計值序列。
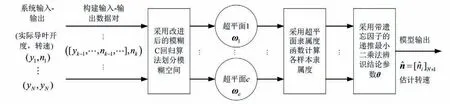
圖2 水輪發電機組模型辨識圖Fig.2 The identification diagram of hydro-turbine generating unit model
4 仿真實例
本節首先采用3 個常用的非線性對象作為實例,以驗證所提辨識方法與其他方法相比具有更佳的性能。然后,將所提方法用于某水電站水輪發電機組的模糊辨識。
為了衡量辨識性能,我們采用均方差MSE作為性能指標:
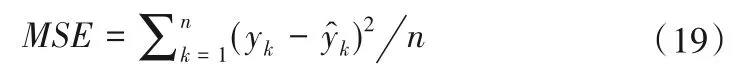
式中:yk和分別為第k個系統輸出和模型輸出。
4.1 一維Sinc函數建模
一維Sinc 函數是先前文獻[16]提出的用于測試建模精度的示例,定義如下:
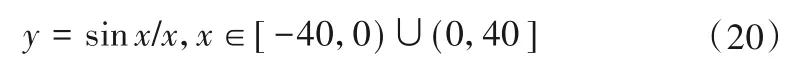
從[-40,0) ∪(0,40]中均勻采樣121 個輸入數據點,并產生對應的輸出數據,用這121 個輸入輸出數據對進行建模。對數據集進行劃分,用于初始化的數據塊大小為52,約占訓練集數據總數的40%,其余的數據塊大小設置為1。取模糊指數為m= 2,模糊規則數為c= 4,取遺忘因子為λ= 0.95;根據試錯法,確定調節系數為η= 4.8。將結果與基于模糊C 均值算法的辨識方法以及基于模糊C回歸聚類轉化為超球形隸屬度的辨識方法進行比較。圖3展示了應用本文所提方法得到的模型辨識結果,與其他方法的精度對比在表1 中給出。表中,傳統方法1指基于模糊C 均值算法的辨識方法,傳統方法2 指基于模糊C回歸聚類和高斯超球形隸屬度的辨識方法。表1結果表明本文辨識方法比其他兩種方法具有更高的建模精度。
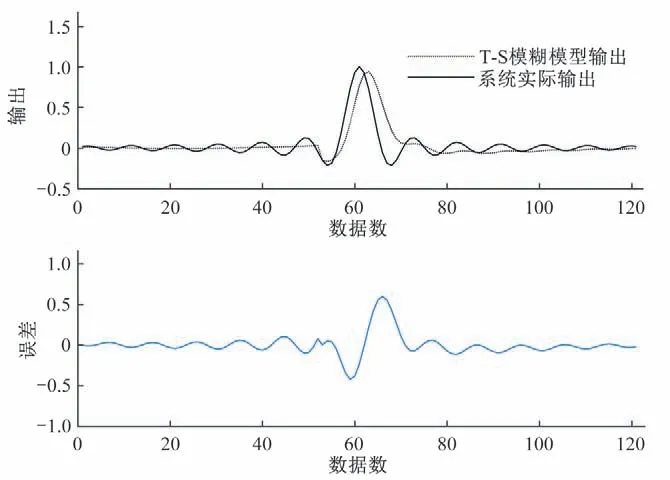
圖3 本文方法對于一維正弦函數的辨識結果Fig.3 The identification result of our approach for the one-dimensional Sinc function

表1 3種方法對于一維正弦函數辨識精度比較Tab.1 Comparison of the identification accuracy of three methods for the one-dimensional Sinc function
4.2 非線性差分方程建模
選用如下二階非線性差分方程進行模糊建模,這個例子摘自Sugeno等人的研究[17]。
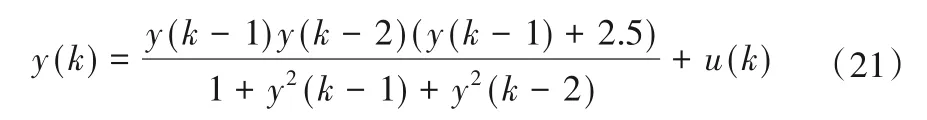
首先,輸入500 個[-2,2]上均勻隨機分布的輸入信號u(k),產生500 個訓練樣本用以建立T-S 模糊模型。用于初始化的數據塊大小為200,其余的數據塊大小設置為1,取m= 2,c= 4,λ= 0.95,η= 4.6。其次,輸入一個正弦信號u(k) =sin(2k/25)產生500個測試樣本用來測試辨識所得模型的性能,測試數據塊的大小取為1。圖4 顯示了采用本文所提方法對該非線性方程進行建模和測試的結果,與其他方法的對比在表2列出。表2 說明本文所提方法不僅具有更高的辨識精度,還具有更強的泛化能力。同時,以這一示例為例,給出最終模型對應的相關參數。
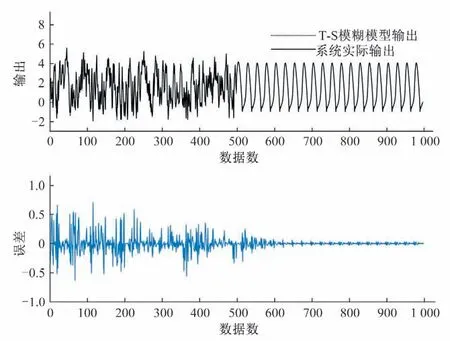
圖4 本文方法對于非線性差分方程的辨識結果Fig.4 The identification result of our approach for the nonlinear difference function
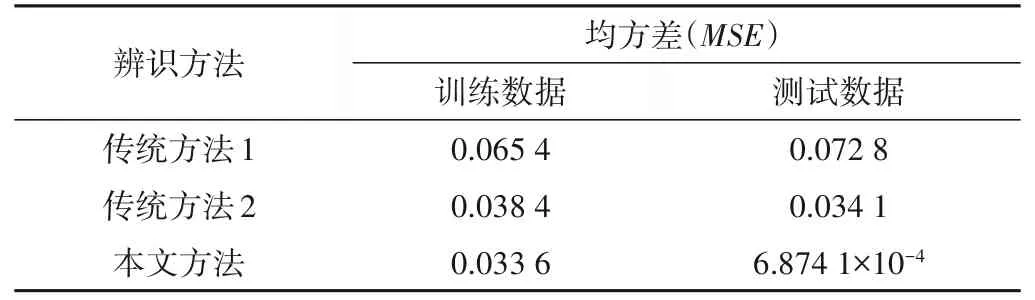
表2 3種方法對于非線性差分方程辨識精度比較Tab.2 Comparison of the identification accuracy of three methods for the nonlinear difference function
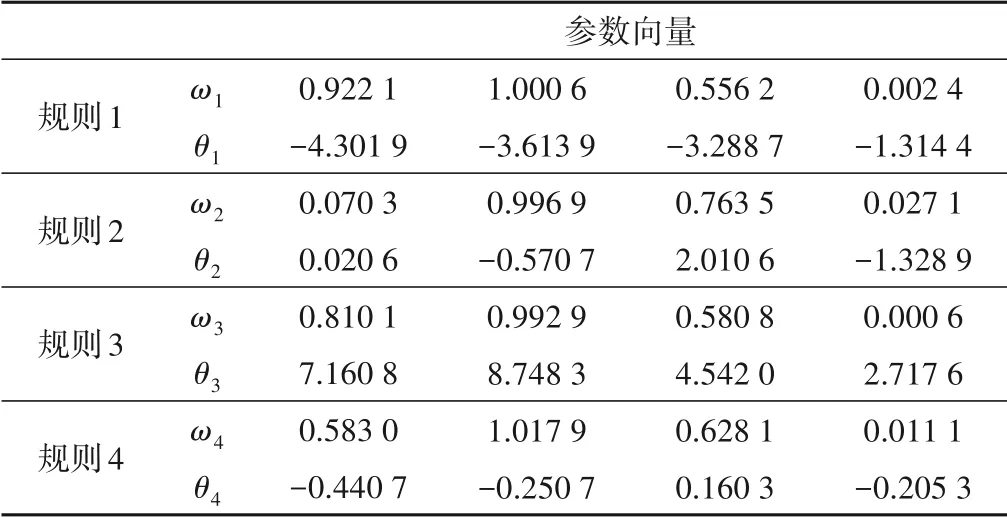
表3 對于非線性差分方程所建模型的參數列表Tab.3 List of parameters of the model built for the nonlinear difference function
4.3 Mackey-Glass混沌系統建模
Mackey-Glass 混沌微分時延方程是用于比較不同模型學習及泛化能力的有力工具,Mackey-Glass 混沌時間序列由式(22)生成:
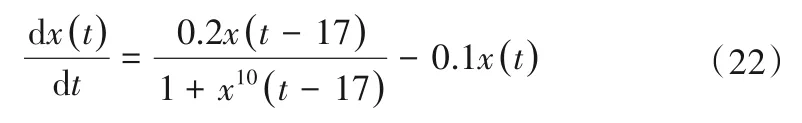
為實現更高的預測精度,使用x(t-18),x(t-12),x(t-6)和x(t)這4 個過去的值,來預測值x(t+6)的序列。在本文中,從Mackey-Glass 混沌時間序列中選取1 000 個輸入-輸出數據對[x(1 001),…,x(2 000)]作為數據集,其中前500 個數據對[即x(1 001),…,x(1 500)]用作訓練集;剩余的500 個數據對[即x(1 501),…,x(2 000)]用作測試集。取m= 2,c= 10,λ= 0.95,η= 5.3。建模階段用于初始化的數據塊大小為191,其余的數據塊大小設置為1。
圖5展示了采用本文辨識方法對Mackey-Glass混沌時間序列進行建模和測試的結果,與其他方法的對比記錄在表4 中。從表4可以看出,辨識所得的模型精度高,泛化能力強。
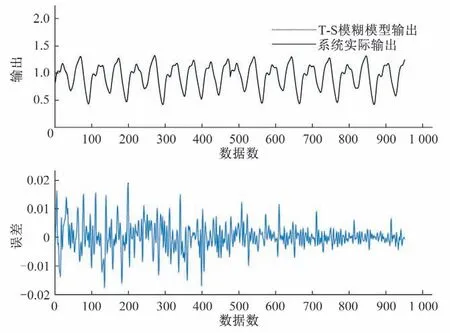
圖5 本文方法對于Mackey-Glass混沌時間序列的辨識結果Fig.5 The identification result of our approach for the Mackey-Glass chaotic time series
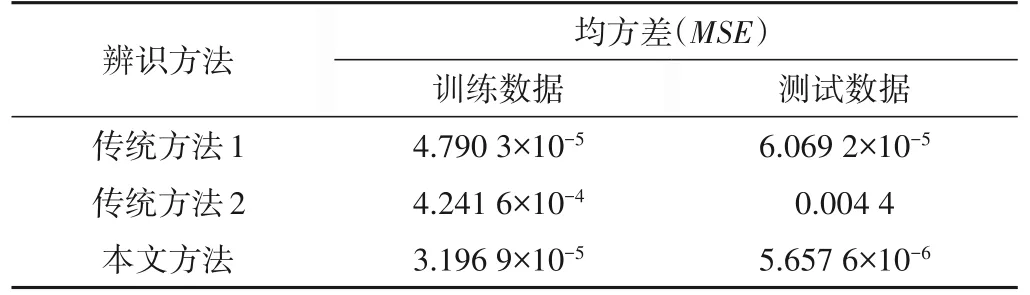
表4 3種方法對于Mackey-Glass序列辨識精度比較Tab.4 The parameter vectors of the model built for the nonlinear difference equation
為了證明本文所提的改進聚類算法比模糊C回歸聚類算法具有更快的收斂速度,將3 個示例下兩種聚類算法的運行時間記錄在表5。
從表5 可以看出,改進后的超平面聚類算法具有更高的聚類效率,可以更快得到最優聚類超平面。再結合辨識結果可知,精度和速率都得到了提升。
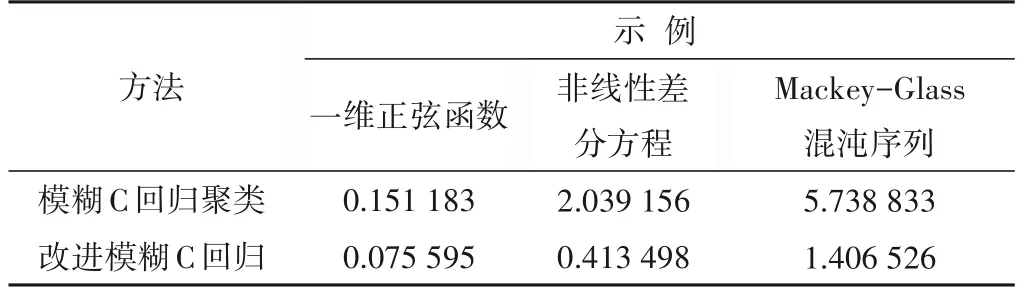
表5 3個示例下兩種聚類算法耗時Tab.5 The time-consuming of two clustering algorithms under three examples
4.4 水輪發電機組模糊模型辨識
依據某水電站水輪發電機組的輸入輸出采樣數據,可以建立水輪發電機組的T-S模糊模型。本文考慮水輪發電機組的輸入輸出序列分別為導葉開度u(t)和轉速y(t),基于系統的輸入輸出采樣值構造模型的輸入輸出數據對[xk,yk],其中xk=[u(k- 1),u(k- 2),y(k- 1),y(k- 2),y(k- 3)]是由歷史開度和轉速組成的維數為M= 5的模型輸入向量,yk為第k個時刻的轉速y(k)。選取同一種水頭下的雙機開機、同時甩負荷、同時減3%負荷、同時減8%負荷4 種情況下1 號機組的數據作為訓練集進行建模,在另一種水頭下分別測試辨識所得模型在各種工作狀態下的精度。取m= 2,c= 2,λ= 0.95,η= 5.6。訓練階段,輸入的是輸入輸出數據對的隨機序列,用于初始化的數據塊大小為訓練集數據總數的40%,其他數據塊大小為10。訓練所得的模型精度可達7.475 7×10-14,辨識結果如圖6所示。
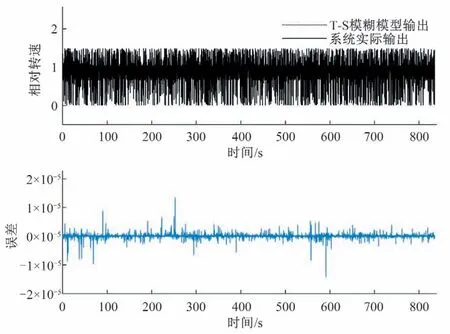
圖6 本文方法對于該水輪發電機組的辨識結果Fig.6 The identification result of our approach for the hydro-turbine generating unit
在測試階段,用辨識得到的模型對于另一水頭下甩負荷,雙機開機,減3%負荷以及減8%負荷4 種情況依次進行測試,數據塊的大小依次取為10,25,35,50。以雙機開機為例給出測試結果,如圖7所示。
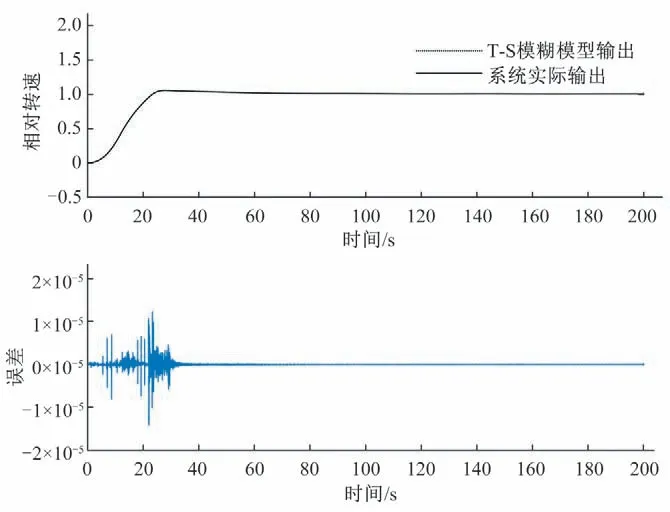
圖7 辨識所得模型對于雙機開機的測試結果Fig.7 Testing results of the identified model for dual machine startup
具體的訓練和測試性能指標列在表6中。結果表明本文提出的方法比傳統方法具有更高的建模精度,并且辨識得到的模型對于不同的測試集均具有很好的辨識結果,總體優于傳統方法。由此可見,本文的T-S 模糊模型辨識方法在進行水輪發電機組辨識時具有很高的精度和相當強的泛化能力。
5 結論
本文提出了一種基于改進模糊C回歸聚類算法的T-S模糊模型辨識方法用于水輪發電機組的精確建模,依據實際的輸入輸出數據建立與待辨識機組匹配的T-S模糊模型。用改進的模糊C回歸聚類算法劃分模糊空間,提升了聚類效果;采用新提出的超平面型隸屬度函數得到前提參數,避免了轉換為超球形聚類參數帶來的優勢削減和額外的計算量;再用帶遺忘因子的遞推最小二乘法辨識結論參數,進一步提高了辨識精度。三個數學示例和一個水輪發電機組實例的模型辨識結果及與其他方法的對比結果表明,本文所提的模糊辨識方法具有較高的建模精度和較強的泛化能力。□
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
