基于輕量型卷積神經網絡的菜品圖像識別
2021-10-09 07:31:41姚華瑩彭亞雄
軟件工程 2021年10期
姚華瑩 彭亞雄

摘? 要:使用卷積神經網絡分析研究識別菜品,能夠幫助人們了解食物,根據不同的需求選擇適合的菜品;同時也能被使用在自助餐廳結算系統中,提高結算效率。由于卷積神經網絡有大量的卷積計算,大量參數致使卷積模型體積龐大,不利于將模型嵌入移動設備中,因此設計了一種輕量型卷積神經網絡MobileNetV2-pro分類菜品。通過引入通道混洗、注意力機制提高網絡的檢測能力;利用隨機擦除等圖像預處理技術對菜品圖像進行處理,提高系統的泛化能力。實驗結果表明,該新結構網絡能顯著提高菜品分類準確率。
關鍵詞:卷積神經網絡;輕量化;菜品分類;注意力機制
中圖分類號:TP391.41? ? ?文獻標識碼:A
Dishes Image Recognition based on Lightweight Convolutional Neural Network
YAO Huaying, PENG Yaxiong
(College of Big Data and Information Engineering, Guizhou University, Guiyang 550025, China)
huayingyao97@163.com; 515154900@qq.com
Abstract: Convolutional neural network can be used to analyze and recognize dishes, helping people know about food and choose suitable dishes according to different needs. At the same time, it can also be used in cafeteria settlement system to improve settlement efficiency. A large number of convolution calculations and parameters in the convolutional neural network make the convolution model bulky, which is not conducive to embedding the model in a mobile device. This paper proposes to design a lightweight convolutional neural network MobileNetV2-pro to classify dishes. Channel shuffling and attention mechanism are introduced to improve the detection ability of the network. Image preprocessing techniques such as random erasure are used to process the image of dishes to improve the generalization ability of the system. Experimental results show that the new structure network can significantly improve the accuracy of dish classification.
Keywords: convolutional neural network; lightweight; dishes classification; attention mechanism
1? ?引言(Introduction)
隨著人們生活質量的提高,菜品種類變多,利用卷積神經網絡能高效地實現菜品的分類。首次應用了卷積神經網絡(Convolution Neural Networks, CNN)的AlexNet[1]在ImageNet圖像分類競賽中取得了優異的成績,由此卷積神經網絡得到研究人員的廣泛關注,并衍生出新的網絡結構(如GoogLeNet[2]、VGG[3]、ResNet[4]等)。雖然這些網絡在圖像分類上的精度不斷提高,但是新的問題是卷積網絡結構大多使用卷積層與全連接層的組合,用來提取圖片特征,全連接層訓練的網絡模型內存占用高,大量卷積層導致計算量巨大。近幾年,一些學者提出了輕量神經網絡(Lightweight Neural Network),如MobileNet[5]采用深度可分離卷積減少卷積運算量;ShuffleNet[6]提出通道混洗,打亂原有的通道順序并重新分組,有效地提高了特征的提取。類似的輕量神經網絡模型還有SqueezeNet[7]、Xception[8]等。輕量神經網絡模型是專門針對嵌入式視覺應用終端設計的輕量且高效的神經網絡模型[9],這類模型具有計算資源需求少,模型簡單的優點,能夠有效提高計算機視覺的性能。
本文提出一種新輕量化神經網絡模型,體積更小,運算量更少,易于應用在各類移動端用于識別菜品。該網絡基于MobileNetV2[5]基礎模型,結合ShuffleNet[6]提出的通道混洗思想,引入通道注意力機制加強特征學習能力,在訓練網絡時利用隨機擦除技術對圖片部分像素進行擦除,多方面對基礎模型進行改進,提高了模型在菜品分類上的準確率。
2? ?相關工作(Related work)
2.1? ?深度可分離逆殘差卷積塊
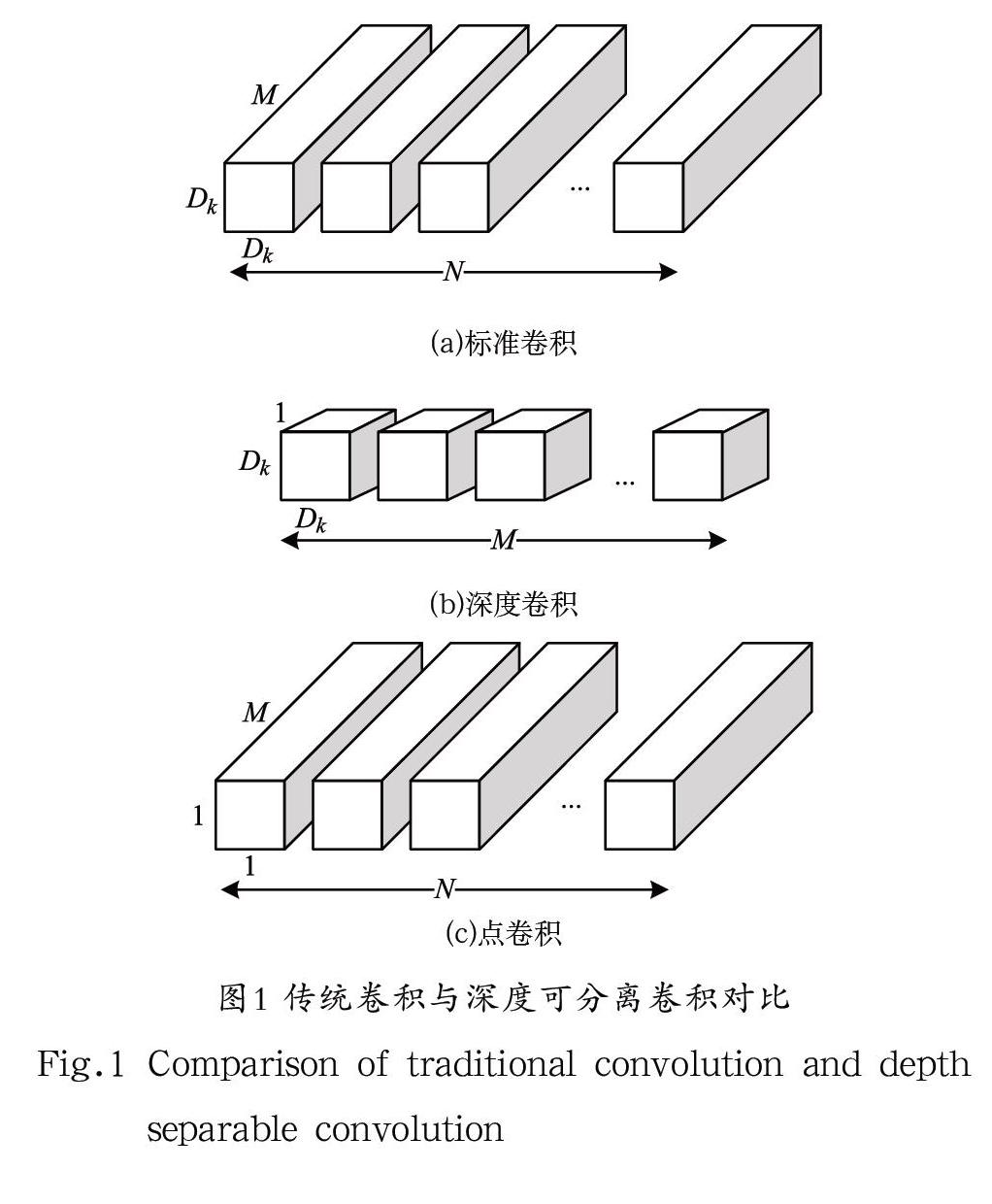
本文為盡可能減少卷積過程中的運算量,采用了深度可分離卷積(Depthwise Sparable Convolution)替代傳統卷積,用一個深度卷積和一個點卷積替換標準卷積,有效減少了卷積運算量。首先進行深度卷積,即對每個輸入的通道各自用單個卷積核進行對應的卷積運算,每個通道各自得到的卷積結果則為深度卷積的最終結果;然后是一個1×1卷積,即點卷積,負責將深度卷積過程輸出的卷積結果線性組合,構建新的特征[10]。如果不考慮偏置參數,深度分離后的卷積參數運算量為:
(1)
標準卷積計算量為:
(2)
其中,為卷積核尺寸,為輸入圖像尺寸,和分別是輸入通道數量和輸出通道數量。圖1中對比了深度可分離卷積和傳統卷積過程。
傳統卷積的計算量是深度可分離卷積的() 倍,當卷積核大小為3×3時,計算量相比傳統卷積減少了九倍多。
在新的模型中,采用殘差模塊提高特征提取能力,淺層網絡與深層網絡所包含的特征量不同,通過“特征映射”和跳躍式的連接形式,可以融合不同分辨率的特征。
圖2使用了一種“逆殘差結構”,對輸入特征通道先擴充后縮減,用1×1卷積核代替3×3卷積核,減少計算量。由于1×1卷積核得到的信息少于3×3卷積核,模型準確度受到了一定程度的影響,因此,使用逆殘差結構用來保證得到的特征量足夠至不影響模型精度[11]。表1為逆殘差結構的卷積實現架構。
2.2? ?通道混洗卷積
依據卷積過程中數據僅在固定通道之間流動這一特點,在本文的新網絡結構中引入通道混洗[6](Channel Shuffle),它是基于通道分組卷積實現的通道混合卷積。通道混洗基于分組卷積技術,將輸入通道分為g組,每組分別與對應的1 個卷積核卷積,這樣做使計算量降低為普通卷積的1/g,對每組通道進行打亂重組,原本封閉固定的通道經過打亂重組后特征得到交流,解決了由于分組固定導致特征融合效果差的問題。圖3(a)為普通分組卷積,分組固定,特征無法交流;圖3(b)表示對每個組內通道再次分組;圖3(c)為通道混洗,將圖3(b)中的每一小組通道組合起來。
2.3? ?通道注意力機制
注意力機制類似人眼,將重點關注特征明顯的區域,運用在卷積過程中,能將不重要的背景因素剔除,本文使用了通道注意力機制,更多地關注菜品的特征部分。通道注意力機制[12]關注通道間的聯系,有一個SE塊由壓縮(Squeeze)和激發(Excitation)兩個部分構成。經過SE塊后的特征被賦予不同的權重,表示出特征之間不同的重要程度,引入了注意力機制的網絡能提高學習特征的能力,進一步提高識別的準確率[13]。
圖4為本文使用了注意力機制和未使用注意力機制的MobileNet的菜品特征圖,可以明顯看出,本文的網絡處理的圖片白色亮點區域更多,說明提取到圖片特征點更多。通過對網絡部分卷積特征層的可視化,不同的卷積層的注意力響應程度不一,可以看到在conv_4后的高層卷積,都對菜品中雞蛋的部位響應更加強烈,而對碗這種與菜品關系弱的部分響應較弱。
2.4? ?菜品識別網絡模型
本文新模型的架構針對輸入的特征圖會首先進行一次通道注意力機制處理,此操作能夠對輸入的通道進行加權處理,得到不同通道中特征的重要程度。
如圖5(a)所示,新的殘差結構在步距S=1時,在模塊最后增加了一個Channel Shuffle層,加強通道間的特征交流;如圖5(b)所示,由于在步距S=2階段沒有殘差結構,遂不經進行混洗操作。最后將得到的菜品特征信息通過全連接層進行分類。
表2顯示了MobileNetV2-pro模型每層的輸出形狀和參數量。多次疊加使用深度可分離逆殘差卷積塊減少卷積計算量;在淺層卷積塊中使用注意力機制快速確定菜品位置和特征點,有效降低了自然環境中背景對菜品定位的影響;深層卷積層利用通道混洗技術提高數據之間的匯通融合能力,在深層的特征圖中最大限度地學習菜品特征。
3? 實驗結果與分析(Experimental results and analysis)
3.1? ?實驗評估
為了驗證本文提出的新型網絡在菜品分類上的有效性,使用數據集進行驗證。FOOD-101是包含101 種菜品的圖像數據集,包含101,000 張圖像,每類菜品包含250 張驗證集和750 張訓練集,圖片最大邊長為512 像素。圖6為數據集中的部分菜品圖像。
3.2? ?實驗環境
使用NVIDIA Geforce RTX 1060、pytorch 1.5,在Windows 10環境下訓練網絡。Batchsize為64,共設置200 個epoch,初始學習率為0.001,在epoch分別達到50、80時調整學習率為上一階段的一半。
3.3? ?參數分析
對訓練圖像做預處理,將輸入網絡的圖片隨機翻轉和裁剪為224×224大小,使用不同的擦除概率討論最優值,用于訓練網絡。
本文利用隨機擦除對圖像做預處理,對圖片中的部分像素進行擦除,模擬自然環境中的遮擋情況,在此過程中將生成擦除面積不同的圖片,能夠增加數據集訓練數據。通過預處理后,網絡具有更高的魯棒性。隨機擦除的實現步驟如下:
(1)設置擦除的概率,則不被擦除的概率為,假設圖片大小為:
(3)
(2)設置擦除矩形區域的參數,可以得到擦除的面積為:
(4)
和是設置的最小擦除面積和最大擦除面積,隨機擦除矩形長寬比為,此值隨機產生。隨機擦除的矩形高和寬為:
(5)
(3)在圖像中隨機選擇一個點,被擦除的區域為,對選擇的區域隨機賦值,其中點A需滿足:
(6)
隨機擦除效果如圖7所示,分別是未進行擦除的原圖及最大擦除概率為0.2、0.4的效果圖。隨機在原圖像中生成同原尺寸比例為0.2或0.4的矩形塊,模擬遮擋情況和提高模型的泛化能力。
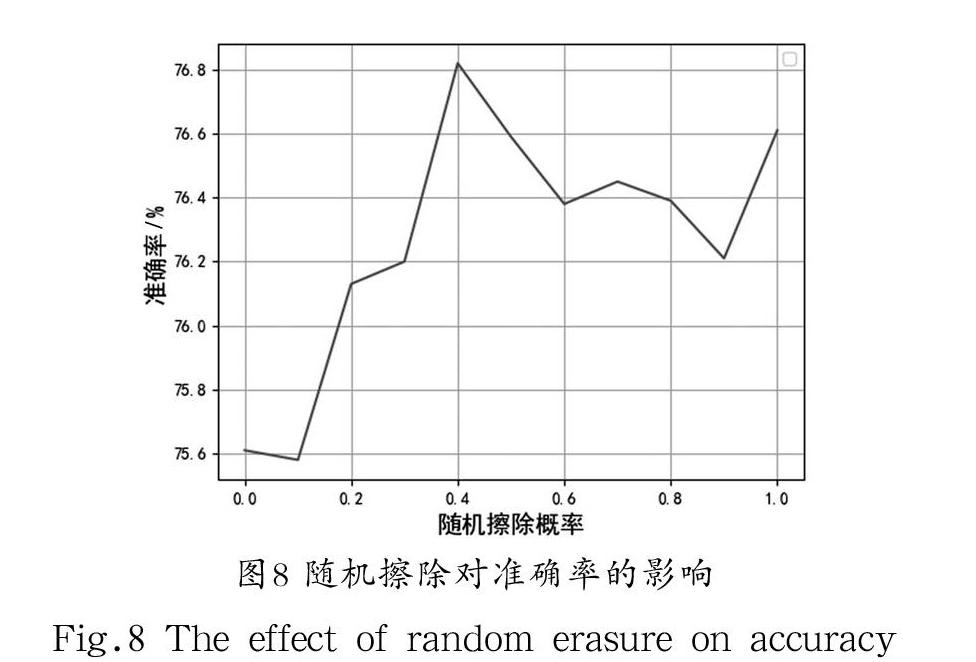
對菜品進行隨機擦除,模擬自然環境下被遮擋的情況,被遮擋部分在學習過程中卷積計算值為零,減少了卷積運算量。從圖8可以明顯看出,在數據集FOOD-101上,隨著隨機擦除比例的改變,模型分類準確率逐步上升,我們把隨機擦除概率設置為0.4時,模型在食物數據集上的分類準確率最高。
本文通過分類準確率和檢測速度衡量模型性能,通過對基礎網絡增加通道混洗、注意力機制和隨機擦除的數據增強,可以看出網絡對菜品的分類準確率都有不同程度的提升。從表3中能看出,本文提出的模型相比基礎網絡,在模型體積上減少18.2%,參數和浮點計算都有相應的減少,在檢測時間大致相同的情況下,準確率提高0.84%。本文的模型(Ours)準確率均高于其他網絡,通過在數據集FOOD-101上訓練和測試,對比其他網絡的實驗結果,可以得出本文提出的網絡模型具有更好的效果。
4? ?結論(Conclusion)
為了幫助人們在自然環境下更方便地分辨菜品,對菜品圖像使用隨機擦除方法,提高網絡的特征提取能力。新的模型引入了通道混洗及注意力機制,縮減了網絡的卷積層,將其命名為MobileNetV2-pro,新的網絡體積更小。實驗表明,本文網絡能更快地提取特征,在菜品分類中表現更好。下一步工作將圍繞網絡處理更多種類菜品,以增強特征提取能力,提高準確率為主,對網絡做進一步改進。
參考文獻(References)
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6):84-90.
[2] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE Computer Society, 2015:1-9.
[3] KAREN S, ANDREW Z. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014, 6(1):1-14.
[4] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE Computer Society, 2016:770-778.
[5] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE Computer Society, 2018:4510-4520.
[6] ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE Computer Society, 2018:6848-6856.
[7] IANDOLA F, HAN S, MOSKEWICZ M, et al. SqueezeNet: Alexnet-level accuracy with 50x fewer parameters and<0.5 mbmodel size[C]// ICLR Organizing Committee. ICLR' 17 Conference Proceedings. Toulon: International Conference on Learning Representations, 2017:207-212.
[8] CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Computer Society, 2017:1251-1258.
[9] 梁峰,董名,田志超,等.面向輕量化神經網絡的模型壓縮與結構搜索[J].西安交通大學學報,2020,54(11):106-112.
[10] 王韋祥,周欣,何小海,等.基于改進MobileNet網絡的人臉表情識別[J].計算機應用與軟件,2020,37(04):137-144.
[11] 程越,劉志剛.基于輕量型卷積神經網絡的交通標志識別方法[J].計算機系統應用,2020,29(02):198-204.
[12] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// CVPR Organizing Committee. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE Computer Society, 2018:7232-7241.
[13] 張翔,史志才,陳良.引入注意力機制和中心損失的表情識別算法[J].傳感器與微系統,2020,39(11):148-151.
作者簡介:
姚華瑩(1997-),女,碩士生.研究領域:深度學習.本文通訊作者.
彭亞雄(1963-),男,本科,副教授.研究領域:通信系統.
