基于改進Faster-RCNN的IT設(shè)備圖像定位與識別①
2021-10-11 06:47:34丁云峰
計算機系統(tǒng)應(yīng)用 2021年9期
張 曉,丁云峰
1(中國科學(xué)院大學(xué),北京 100049)
2(中國科學(xué)院 沈陽計算技術(shù)研究所 系統(tǒng)與軟件事業(yè)部,沈陽 110168)
國家電網(wǎng)數(shù)據(jù)中心擁有數(shù)量龐大的設(shè)備,提高管理這些設(shè)備的效率和降低相關(guān)管理支出具有重要意義.數(shù)據(jù)中心的IT 設(shè)備(以下簡稱設(shè)備) 可分為服務(wù)器、交換機、路由器等,且這些設(shè)備安裝于機柜中.設(shè)備管理的內(nèi)容有,詳細記錄機柜中設(shè)備的安裝位置和設(shè)備型號.傳統(tǒng)的管理方法是人工抄錄和定期人工巡視復(fù)核,這種方式不但費時費力而且容易出錯,因此找到一種簡單高效的管理方法具有重要的現(xiàn)實意義.
近年來,人們在設(shè)備識別上進行了許多嘗試.傳統(tǒng)的方法主要基于設(shè)備的電學(xué)特性,不同設(shè)備都有自己特定的阻抗、感抗、對地電阻等電學(xué)特性,一方面可以通過電學(xué)指標計算一個特征碼,然后通過實時采集相關(guān)特征計算實時特征碼,通過比對得到設(shè)備的種類;另一方面可以在把采集的電學(xué)特性數(shù)據(jù)當作特征結(jié)合傳統(tǒng)機器學(xué)習的算法進行分類.雖然這兩種算法在一定程度上可以識別出設(shè)備類型,但是需要安裝電學(xué)特征的采集裝置,并且類內(nèi)設(shè)備的型號識別也比較困難.任曉欣等人[1]提出了圖像與支持向量機結(jié)合的算法,但圖像與支持向量機結(jié)合時重要的一步是圖像的預(yù)處理,圖像預(yù)處理的結(jié)果與最終的分類效果息息相關(guān).并且該方案僅支持圖像中單一設(shè)備的識別,對類內(nèi)不同型號的識別效果比較差.王祎瑞[2]提出了基于YOLOv2的TSENet 模型.該模型主要對YOLOv2的輸出層進行調(diào)整,通過fine-turning的方法對模型輸出層進行訓(xùn)練.該模型可以進行多設(shè)備檢測,且算法執(zhí)行速度快,適合視頻流的處理.但是設(shè)備類型識別準確率比較低,達不到進行設(shè)備識別要求的精度.
通過圖像直接識別設(shè)備的類型和位置在邏輯上是比較自然的方案.但是在實際中通過圖像進行設(shè)備識別的主要困難有:類間差別大類內(nèi)差別小,要區(qū)分同一類設(shè)備的不同的型號比較困難;設(shè)備顏色與機柜顏色相近,設(shè)備輪廓識別困難;機柜中設(shè)備安放不規(guī)則,定位實際位置困難[3].當下的研究中,深度神經(jīng)網(wǎng)絡(luò)在設(shè)備管理領(lǐng)域的應(yīng)用比較少,結(jié)合其在其它相近領(lǐng)域的研究成果,文本將深度卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用到設(shè)備上,基于文獻[4]中的提出Faster-RCNN和文獻[5]提出的通道注意塊提出了基于注意力機制的Faster-RCNN 網(wǎng)絡(luò).利用國家電網(wǎng)某數(shù)據(jù)中心的機柜圖像作為數(shù)據(jù)集進行模型的訓(xùn)練和測試.并在內(nèi)部的不同網(wǎng)絡(luò)結(jié)構(gòu)和外部的幾種最有效的算法間進行了比較與分析.
1 神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計
1.1 改進模型分析
當前在圖像多物體識別領(lǐng)域已經(jīng)取得了許多成果,相關(guān)研究可以分為RCNN 體系和YOLO 體系.RCNN體系中主要有RCNN,Fast-RCNN,Mask-RCNN,SSD以及Faster-RCNN.從字面意思上就可以得到Faster-RCNN是從Fast-RCNN 改進來的,而Mask-RCNN 則是在Faster-RCNN 基礎(chǔ)上添加FCN 層進行像素級別上的卷積,該算法在語義分割上取得了非常好的成績,SSD算法[6]提出一種新的錨框生成機制,不再需要RPN 結(jié)構(gòu)來提取生成錨框,簡化了網(wǎng)絡(luò)的模型.YOLO 體系最先有谷歌團隊提出來后續(xù)經(jīng)過改進產(chǎn)生了YOLOv1,YOLOv2 等算法模型.本文選用Faster-RCNN 作為基礎(chǔ)模型是因為雖然Faster-RCNN不如YOLOv2的運算速度快,但是模型的精確度高[7].而Mask-RCNN在訓(xùn)練時需要進行像素級標注構(gòu)建訓(xùn)練樣本困難,并且該結(jié)構(gòu)分塊明確在模型改進上相對容易.
綜合以上考慮使用Faster-RCNN 作為網(wǎng)絡(luò)的基礎(chǔ)模型,該模型首先經(jīng)過預(yù)訓(xùn)練的VGG-16 網(wǎng)絡(luò)提取特征圖,然后分兩個分支一個是用來初步生成錨框的RPN結(jié)構(gòu),另一個與RPN的結(jié)果通過ROIPooling 作用生成新的特征圖然后進行物體分類和錨框的重新調(diào)整.雖然該結(jié)構(gòu)在很多圖像分類任務(wù)上取得了比較優(yōu)秀的成績,但是在IT 設(shè)備識別中,設(shè)備的型號一般標注在左上角或者右上角的一個小區(qū)域中,我們希望在進行分類時除了關(guān)注設(shè)備的輪廓外,還要更多的關(guān)注于設(shè)備類型標簽區(qū)域.除此之外,設(shè)備在機柜中的位置相比自然圖片比較規(guī)則,可以根據(jù)實際情況減少錨框的初始生成數(shù)量,可以在一定程度上減少RPN 模塊的訓(xùn)練時間.且該模型中ROIPooling 中的線性插值法進行融合時比較暴力,與原圖的映射關(guān)系也不明確,機柜中的設(shè)備之間排布比較緊密所以我們采用了更好的雙線性插值來做模型融合.
本文提出了基于注意力機制Faster-RCNN 網(wǎng)絡(luò),模型結(jié)構(gòu)如圖1所示,圖中加粗的框為改動的地方.圖中加粗的框主要有3 處,分別對應(yīng)標號①~③.接下來詳細闡述改進后的網(wǎng)絡(luò)結(jié)構(gòu).
1.2 注意力機制
圖1中標號①的部分,主要為神經(jīng)網(wǎng)絡(luò)加入注意力機制,即為特征圖增加注意力特征.
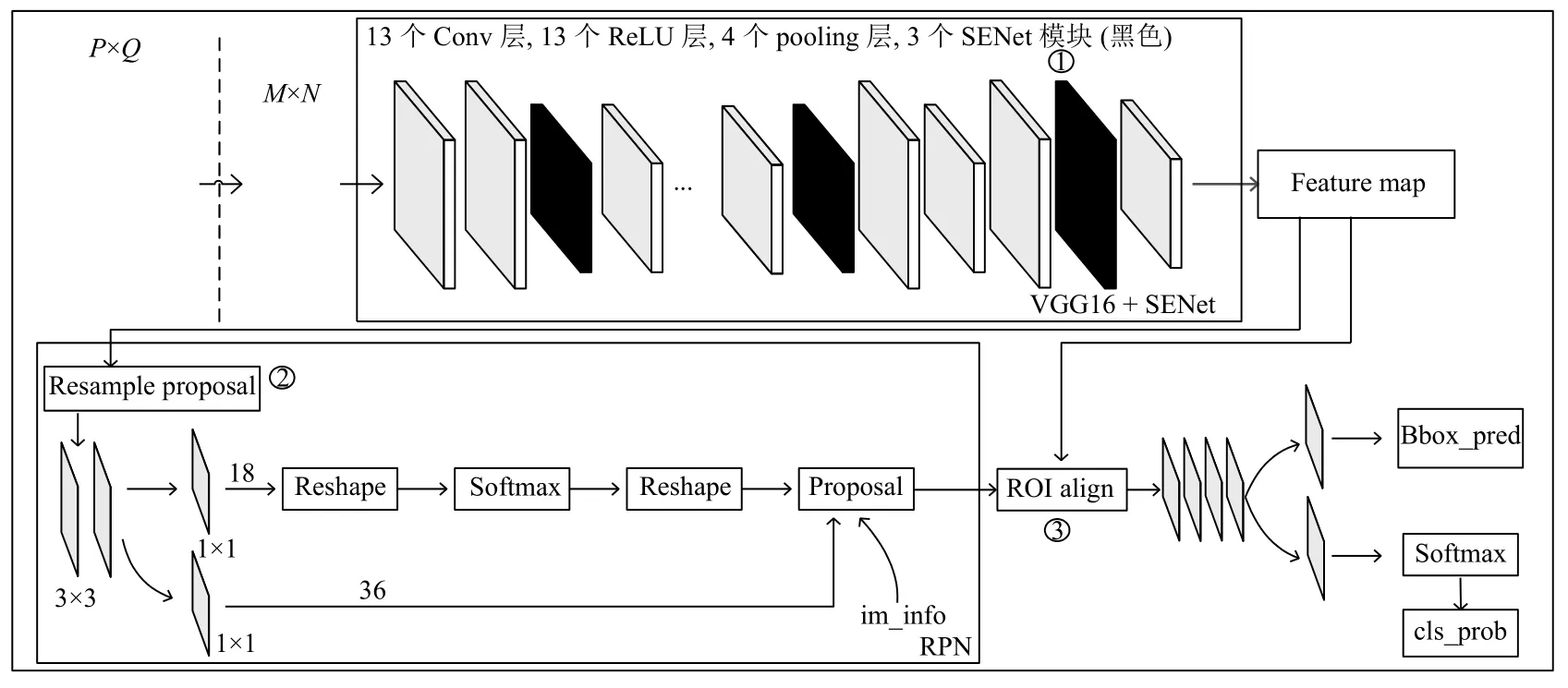
圖1 改進的Faster-RCNN 結(jié)構(gòu)
注意力機制現(xiàn)在已經(jīng)被廣泛應(yīng)用在圖像領(lǐng)域中.其在圖像的領(lǐng)域的應(yīng)用主要分為3 個方面.一種是Mnih 等人提出的基于空間域[8]的注意力模型,通過一個空間轉(zhuǎn)換器將圖片中的空間域信息做對應(yīng)的空間變換,然后將圖片的關(guān)鍵信息提取出來.但是這種方式是對所有的通道信息做統(tǒng)一變換,但是在卷積之后每一通道表達的特征信息就被弱化了.于是文獻[9]提出了基于通道域的注意力模型,通過擠壓、激勵和注意3 個模塊生成每個通道的注意力分布.第3 種方案就是綜合空間域和時間域的混合域了,由Wang 等人提出[10].作者受殘差網(wǎng)絡(luò)的設(shè)計思想的啟發(fā)提出了該注意力機制,創(chuàng)新點就在于不僅把轉(zhuǎn)換之前的特征向量作為下層的輸入,也把轉(zhuǎn)換之前的特征向量作為下一層的輸入,可以獲得更好的注意力特征.前文提到識別的難點之一是IT 設(shè)備與機柜的顏色相近,也就是前景色和背景色相近.并且設(shè)備標簽一般占整個圖的比例較小,通過注意力機制可以提高標簽的識別效果.因此我們通過對通道設(shè)置不同的權(quán)重來進一步提高通道的表達能力.本文使用了基于通道的注意力機制.
具體的設(shè)計細節(jié)如圖2所示.通過實驗,綜合運行時間和精度分別在VGG-16的Pool2、Pool4和Pool5之后添加注意力提取模塊.

圖2 基于通道域的注意力特征結(jié)構(gòu)
圖2中虛線框的部分就是一個注意力提取模塊,我們希望通過注意力提取模塊學(xué)習每個通道的權(quán)重,從而產(chǎn)生通道的注意力.注意力機制模塊分為3 個部分:擠壓、激勵和注意.具體來說,首先將經(jīng)過卷積和池化生成的特征圖輸入如式(1)所示的擠壓函數(shù):
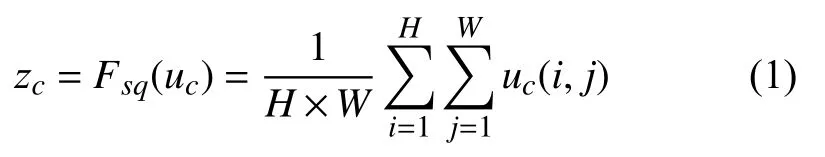
其中,uc(i,j) 表示輸入注意模塊的特征圖u的第c個通道的(i,j)位置的像素值.很明顯擠壓函數(shù)的作用是把每個通道內(nèi)所有的特征值相加再取平均,也就是計算了一個全局平均值.然后將計算得到的zc輸 入激勵函數(shù)Fex(z,W):
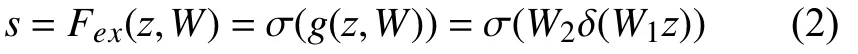
其中,δ表示ReLU函數(shù),σ表示Sigmoid函數(shù),其中參數(shù)r為維度縮放比率,為了在不同的網(wǎng)絡(luò)中限制訓(xùn)練的復(fù)雜度.通過激勵函數(shù)可以充分使用擠壓函數(shù)生成的信息,盡可能捕捉通道間的依賴信息[11,12].通過學(xué)習這兩個權(quán)重得到s,并將其輸入尺度函數(shù)Fscale中:
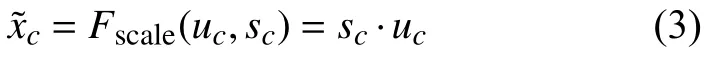
其中,uc∈?H×W,表示通道c的注意力權(quán)重.
綜上分析,通道注意力模塊的詳細設(shè)計如圖3所示.

圖3 通道域注意力機制詳細結(jié)構(gòu)設(shè)計
1.3 初始錨框調(diào)整
Faster-RCNN的RPN 中每個特征點生成3不組不同大小的初始錨框[13,14],每組有長寬比例不同的3 個錨框.但本文中IT 設(shè)備的形狀比較規(guī)則,所以本文對每個特征點生成2 組錨框,每組3 個錨框比例分別是,16:1、4:1和1:4.6 個錨框雖然不能將整張圖片完全覆蓋但是可以覆蓋掉所有的放置在機柜上的IT 設(shè)備.本文的錨框生成偽代碼為:

算法1.錨框生成算法//vgg-16 xbase1 Δ=16 let Δ=1,ybase1 Δ=1,xbase2 Δ=16,ybase2 for scale in scales:w=xbase2-xbase1+1 h=ybase2-ybase1+1 xcenter=xbase1+0.5*(w-1)ycenter=ybase1+0.5*(h-1)for ratio in ratios:ws_mid=sqrt(size/ratio)hs_mid=ws_mid*ratio ws=ws_mid*scale hs=hs_mid*scale return ws,hs,xcenter,ycenter
錨框的生成圖示如圖4所示.
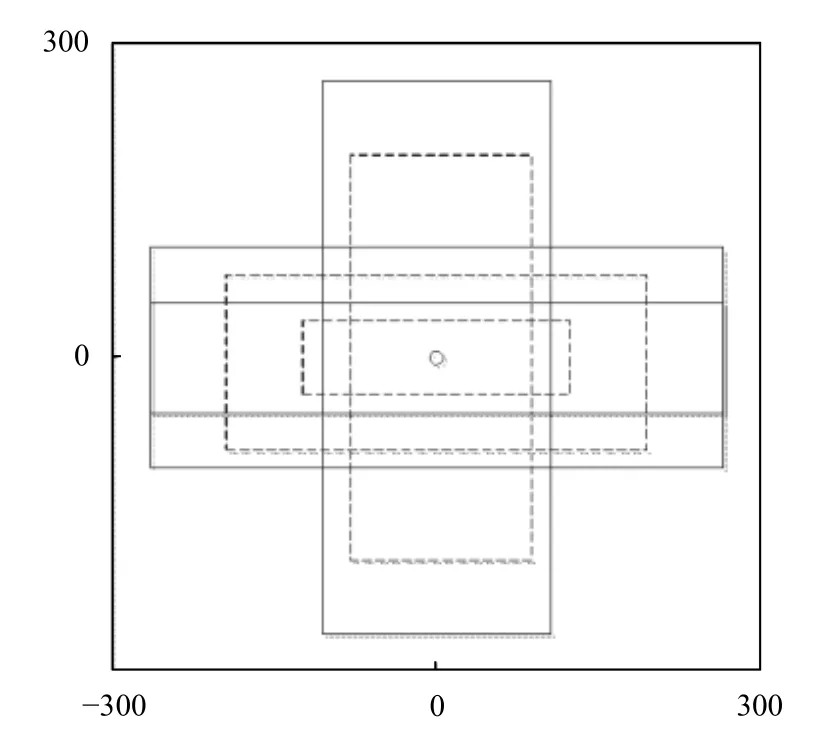
圖4 錨框生成示例
1.4 ROIAlign
Faster-RCNN 中使用ROIPooling 來融合RPN 輸出和特征圖[15-19],使用最近鄰插值直接對特征圖進行pooling,在恢復(fù)尺寸階段對于縮放后坐標不能剛好為整數(shù)的情況,采用了粗暴的舍去小數(shù),相當于選取離目標點最近的點,損失一定的空間精度.
而ROIAlign 將最近鄰插值換為雙線性插值,使得即使縮放后坐標不能剛好為整數(shù),也能通過插值得到浮點數(shù)處的值處理得到pooling 后的值,保證了空間精度.
2 模型訓(xùn)練
2.1 VGG-16+SENet 訓(xùn)練
本文加入了SENet 模塊,我們重新訓(xùn)練了VGG-16的特征提取網(wǎng)絡(luò).結(jié)合文獻[9]中提出的SENet 訓(xùn)練的方法,我們在ImageNet2012 數(shù)據(jù)集上進行了4 輪測試,目的是找到在VGG-16 添加SENet的合理方案.VGG16 網(wǎng)絡(luò)雖然結(jié)構(gòu)簡單但在圖像分類任務(wù)中取得了很好的成績,因此現(xiàn)在的許多深度網(wǎng)絡(luò)將VGG16 作為復(fù)雜圖像任務(wù)中的特征提取的預(yù)訓(xùn)練模型.該網(wǎng)絡(luò)的主要特點是通過13 層卷積的分布進行特征的有效提取,以每一個池化層的結(jié)束為一個特征提取模塊.將SENet 模塊放置在池化層之后是因為每經(jīng)過池化后一次高層次特征提取才算完成,這樣就在保留了原有特征提取的優(yōu)良特性基礎(chǔ)上發(fā)揮SENet 模塊對關(guān)鍵特征增強的優(yōu)勢.VGG16 中共有5 層池化,使用3 個SENet模塊進行注意力生成.具體放置方案如表1所示.
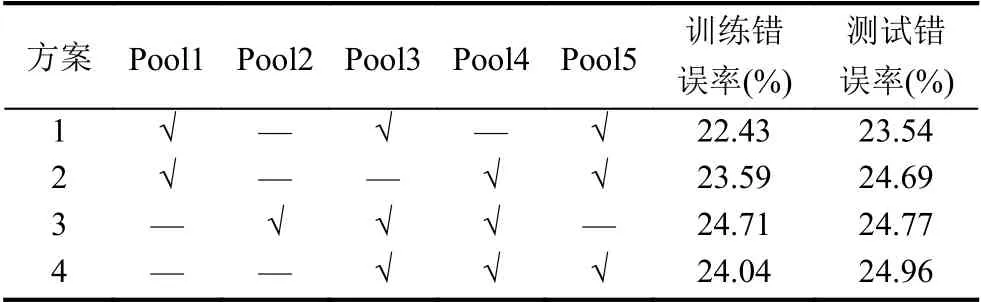
表1 SENet 模塊放置方案對比
使用Image2012 數(shù)據(jù)集的部分數(shù)據(jù)對該模型進行預(yù)訓(xùn)練和注意力放置方案的評估.從數(shù)據(jù)集中隨機抽取100 萬張有標記的數(shù)據(jù),其中30 萬張作為測試數(shù)據(jù),另外70 萬作為訓(xùn)練數(shù)據(jù).共進行15 個epoch,每個batch為500 張圖片.訓(xùn)練的過程采用fine turning的思想,通過凍結(jié)某些層可以加快訓(xùn)練速度,比如方案4 中分別在Pool3、Pool4和Pool5 中加入了注意力模塊,在訓(xùn)練時凍結(jié)Pool4 之前的所有層,只更新Pool4 之后的層的權(quán)重.
模型訓(xùn)練過程中的主要困難是經(jīng)過修改后的VGG16 添加了注意力模塊,打破了原來神經(jīng)網(wǎng)絡(luò)反向傳播算法的遞歸求解特性.所以在反向傳播到注意力模塊時要單獨來求解該模塊的參數(shù)更新方法,綜合式(1)~式(3)得到注意力模塊的反向傳播的權(quán)重公式為:
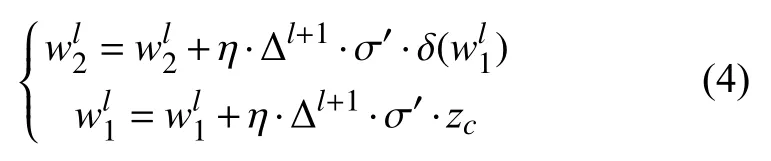
其中,Δl+1表示通過上一層,即卷積層傳遞過來的誤差.σ′表示式(2)中的Sigmoid 函數(shù)的導(dǎo)數(shù),δ表示式(2)中的ReLU 函數(shù),η表示學(xué)習率,訓(xùn)練時學(xué)習率設(shè)為1 0-4.通過式(4)來更新權(quán)重w1,w2,并且更新時先更新w1再 更新w2.
分析表1在測試和訓(xùn)練階段的錯誤率發(fā)現(xiàn),第一種方案的效果是比較好的.因此本文采用第1 種方案,然后將訓(xùn)練好的網(wǎng)絡(luò)最后兩層移除,由此得到了特征圖生成模塊的網(wǎng)絡(luò)模型.
2.2 其它模塊的訓(xùn)練
本文的圖片數(shù)據(jù)來自于國家電網(wǎng)某大數(shù)據(jù)中心,數(shù)據(jù)中心中一共有33 中不同型號的設(shè)備.所以根據(jù)實際情況,將圖1中的RPN 模塊的分類層和最終的分類層修改為33 類輸出.網(wǎng)絡(luò)中除了與分類層相連的全連接層其它層都處在凍結(jié)狀態(tài)不進行參數(shù)的更新.模型的輸入首先將圖片輸入特征提取網(wǎng)絡(luò),經(jīng)過特征提取后將結(jié)果輸入RPN 網(wǎng)絡(luò)中進行訓(xùn)練.
3 實驗分析
本文選用來國家電網(wǎng)某數(shù)據(jù)中心的圖片數(shù)據(jù),一共2 萬張.其中1.7 萬張作為訓(xùn)練集,0.3 萬張作為測試集,數(shù)據(jù)集使用LabelImg 工具自行標注,標注后的數(shù)據(jù)集如圖5所示.

圖5 標注后部分數(shù)據(jù)集樣例
3.1 模型比較
模型訓(xùn)練時一共進行1000 次迭代,一次放入圖片150 張.首先經(jīng)過預(yù)訓(xùn)練特征提取模塊得到特征提取圖.將提取到的特征輸入RPN 模塊和ROIAlign 模塊進行后續(xù)的訓(xùn)練工作.為了更好的檢驗修改后的網(wǎng)絡(luò)模型的性能,首先進行了相同數(shù)據(jù)規(guī)模和輸入圖片的兩次訓(xùn)練.分別是原始的Faster-RCNN 網(wǎng)絡(luò)和經(jīng)過修改后帶有注意力機制的改進Faster-RCNN 網(wǎng)絡(luò),并得到如圖5的訓(xùn)練結(jié)果圖.為了更清楚的展示模型性能使用了平方損失作為考察項,平方損失是個簡單高效的損失函數(shù)橫軸表示進行迭代的輪次.公式如下:
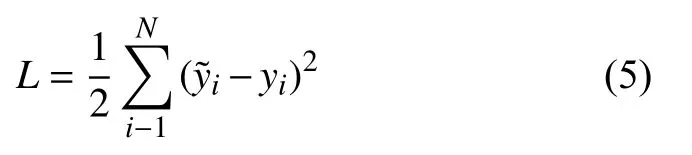
觀察圖片發(fā)現(xiàn),改進的Faster-RCNN 網(wǎng)絡(luò)模型雖然在前200 次迭代時波動較大,但是在200 輪之后該模型的收斂速度要比原模型快30%,并且最終收斂的損失要比原模型低10%.
為了更好的分析模型性能,本文選用在圖片物體檢測領(lǐng)域最常用的3 個算法SSD,Mask-RCNN,YOLOv2,這3 個算法在前文進行1.1 節(jié)進行了概括介紹,這里不再闡述.因為這些算法的輸出與本文不相符所以使用前文的1.7 萬張圖片對它們進行輸出結(jié)構(gòu)修改后的訓(xùn)練.并選取了4 張在訓(xùn)練集和測試集都沒有的圖片的對這些模型進行測試,保存預(yù)測輸出的損失值如表2所示和輸出的預(yù)測結(jié)果圖,如圖6所示.結(jié)合表2和圖6所示,無論在視覺上還是具體的數(shù)值指標上,本算法均取得了優(yōu)于其他算法的結(jié)果.
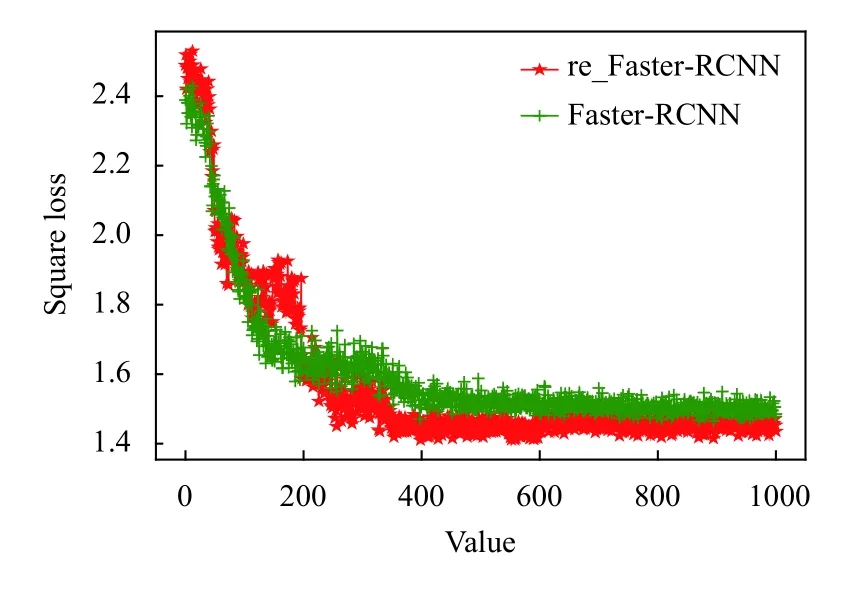
圖6 原始模型與改進模型的訓(xùn)練平方損失
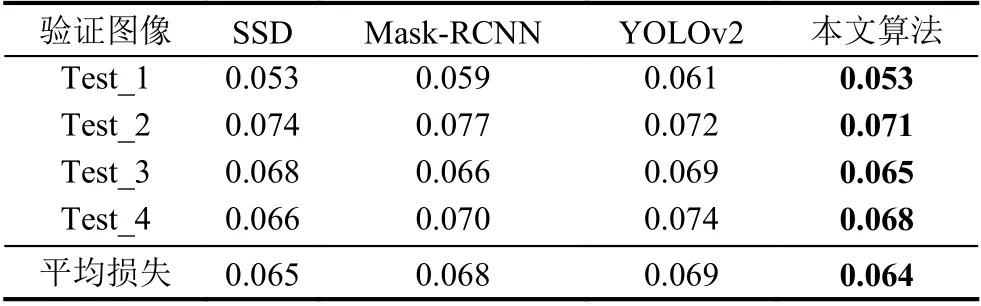
表2 不同算法損失比較
3.2 RPN 網(wǎng)絡(luò)作用比較
在修改的模型中減少了錨框的生成數(shù)量,在改進的Faster-RCNN的訓(xùn)練過程中進行修改和未修改情況的對比,對比結(jié)果如圖7所示.
圖7中橫坐標表示模塊的收斂所用的時間,縱坐標表示該模塊的平方損失,該模塊的損失代表錨框的位置損失,紅色的帶五角星的曲線表示修改后的模塊,另一條則代表未修改的原來的模塊.觀察圖像發(fā)現(xiàn)修改后模塊的收斂時間相比原模塊縮短30%,特別發(fā)現(xiàn)通過這個操作,使得模型的損失降低了大約1%,這意味著可以以更高的精度輸出IT 設(shè)備的位置.分析之后發(fā)現(xiàn),修改之后的錨框在比例和尺寸上更加符合IT 設(shè)備的輪廓比例和大小.并且少但是更精確的錨框數(shù)量,減少了RPN 模塊中回歸模型的運算量和錯誤率.
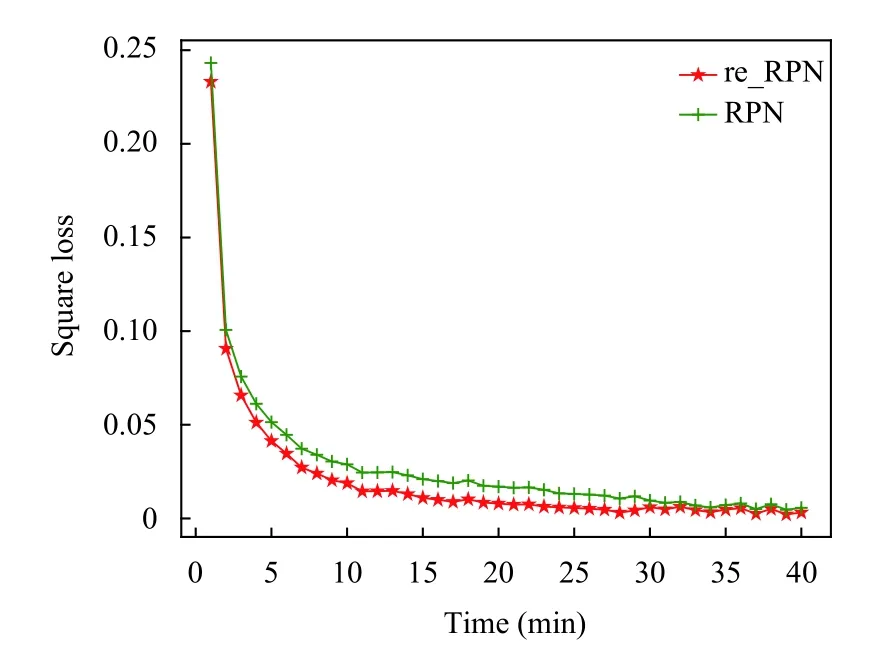
圖7 原始RPN 與改進RPN 模塊的時間對比
4 結(jié)論與展望
本文結(jié)合實際應(yīng)用場景,綜合考量了當前存在的比較優(yōu)秀的算法.并針對這些算法的特點進行實際測試.最終選定了在圖像物體檢測領(lǐng)域取得了優(yōu)秀成果的Faster-RCNN 作為最終基礎(chǔ)算法模型,并根據(jù)實際情況對結(jié)構(gòu)進行調(diào)整.首先加入了基于通道的注意力機制,得到了不同通道權(quán)重分布特征圖.通過調(diào)整錨框提升了時間效率和初步預(yù)測的精度.特別是RoiAglin機制的加入,可以準確的將RPN 輸出的錨框的坐標與特征圖對應(yīng),為后面的精確分類提供了高質(zhì)量的特征.
但是本文的網(wǎng)絡(luò)結(jié)構(gòu)比較復(fù)雜,雖然精確度高但是模型的耗時也高.還需要在模型的結(jié)構(gòu)等方面不斷的探索調(diào)整,尋找一個復(fù)雜度和耗時比較均衡的模型.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國特種設(shè)備安全(2022年6期)2022-09-20 02:52:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:26:08
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
工業(yè)設(shè)計(2016年12期)2016-04-16 02:52:00
