圖計算加速器中稀疏向量比較單元的設計與實現
2021-10-18 01:51:26鄧軍勇趙一迪劉新闖
計算機應用與軟件 2021年10期
田 璞 蔣 林 鄧軍勇 趙一迪 劉新闖 樊 萌
1(西安郵電大學電子工程學院 陜西 西安 710121) 2(西安科技大學集成電路設計實驗室 陜西 西安 710054)
0 引 言
大數據時代,每天產生的數據量呈指數增長,預計到2020年,全球的數據量有望達到44 ZB[1-2]。這些數據很大一部分以圖的形式存儲在各個領域中,而圖是一種眾所周知的數據格式,例如在線零售、社交網絡、機器學習和生物信息學中的數據以圖的形式存儲[3-4]。現實世界中實體規模的擴張導致相應圖數據的規模有數十億個頂點和上萬億條邊,龐大的頂點和邊構成的結構信息,以及頂點與邊附帶的各類屬性信息使得遍歷、查找、分析等圖計算過程中無法預知相鄰頂點,造成存儲訪問的隨機性強、局部性差,圖計算實時性強的高“訪存/計算比”不僅要求帶寬高,而且帶寬浪費嚴重[5-6]。真實世界圖數據的平均度數通常只有幾到幾百,與上千萬甚至上億個頂點的規模相比顯得極為稀疏,且度數呈冪律分布。該分布的圖數據往往組織成鄰接稀疏矩陣的形式存儲,由于零元素多、規模大,壓縮以后存儲可以節約大量的空間[7],常見的圖數據壓縮格式有壓縮稀疏列(Compressed Sparse Column,CSC)、壓縮稀疏行(Compressed Sparse Row,CSR)、坐標列表(Coordinate List,COO),但這些壓縮方式難以精確尋址,且現有的圖計算加速器需要將壓縮后的圖數據重新解壓縮才能執行后續處理。
隨著圖計算、稀疏線性代數和機器學習的興起,圖計算應用變得越來越重要和普遍[8]。對于常用的圖計算應用,專用的硬件加速器是實現高性能低功耗的一種途徑[9-12]。根據圖計算系統中數據處理對象的局部性差、“訪存/計算比”高的實際特性,本文已經設計了一個優化的圖數據組織形式獨立壓縮稀疏列(Compressed Sparse Column Independently,CSCI)和圖計算加速器[13],深入挖掘圖數據潛在并行性。
絕大多數圖計算應用都可以映射為稀疏矩陣向量乘法運算[14]。根據大多數流行的圖計算應用的運算功能,比如廣度優先搜索算法(Breadth First Search,BFS)之類的圖算法將比較最大/最小運算作為核心運算。相比之下,其他圖計算應用(比如Page Rank)則利用算術運算(比如求和)來迭代累加相鄰的值,直到最終收斂,所以可以將圖計算應用分為兩類:算術運算和最小/最大比較[15],各種圖計算應用程序的核心運算總結如表1所示[16]。經CSCI數據存儲格式存儲的圖數據在進行以上兩種圖應用時,不論核心運算是算術運算還是比較運算,都需要比較確定兩個矩陣列向量中的元素在同一列。由于圖數據規模大、稀疏性強,如何高效地實現兩個稀疏列向量的比較運算就是一個值得考慮的問題,針對這一問題,本文提出兩個稀疏矩陣向量的比較方法。
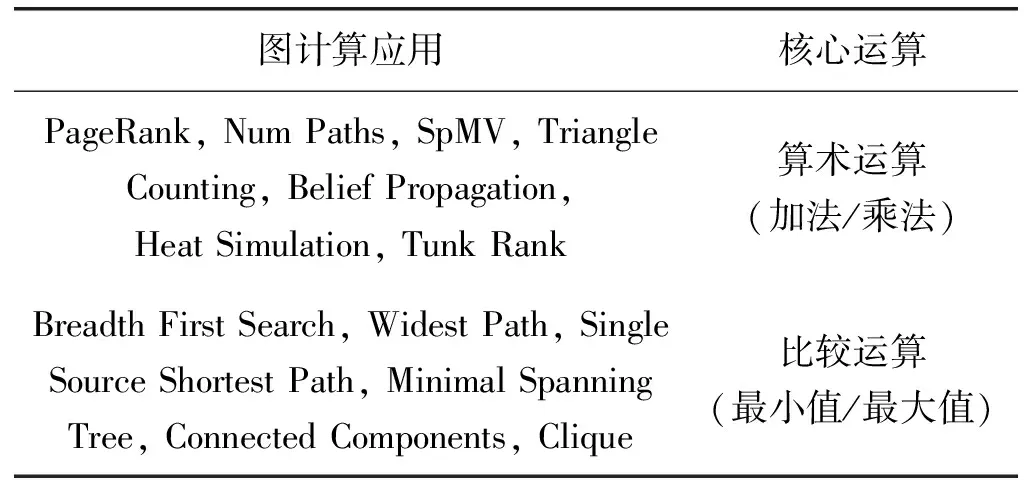
表1 圖計算應用的核心運算總結
1 CSCI圖數據格式的稀疏向量比較
1.1 圖計算加速器和圖數據壓縮方法
圖計算加速器的電路結構如圖1所示,包括預處理電路、存儲器、控制器、數據訪問單元、調度器、混合粒度處理單元和結果產生單元。預處理電路根據CSCI數據壓縮方法[13]對鄰接稀疏矩陣數據進行轉換處理。控制電路用于接收預處理電路中存儲完畢之后發送的轉換就緒指示信號,根據主機發送的圖計算應用類型控制所述數據訪問單元、混合粒度處理單元、結果產生單元的操作。數據訪問單元從所述存儲器中讀取CSCI的圖數據和列標識,并根據所述根頂點索引、源頂點索引或結果產生單元傳送的活躍頂點索引計算指定頂點在存儲器中的物理地址以進行數據訪問,以及將讀取的數據傳輸到調度器;調度器用于將CISI中列標識指示的非零元素個數暫存,并根據所述混合粒度處理單元內處理元的狀態信號,將暫存的數據分配到混合粒度處理單元內的處理元進行處理。混合粒度處理單元根據控制電路內的應用類型和結果產生單元的活躍頂點數據對調度器內暫存的數據進行并行處理,并將處理后的中間數據傳輸至結果產生單元。結果產生單元根據控制電路內的圖計算應用類型對中間數據進行處理,以及將處理過程的活躍頂點索引發送數據訪問單元,將處理后的最終結果存儲。
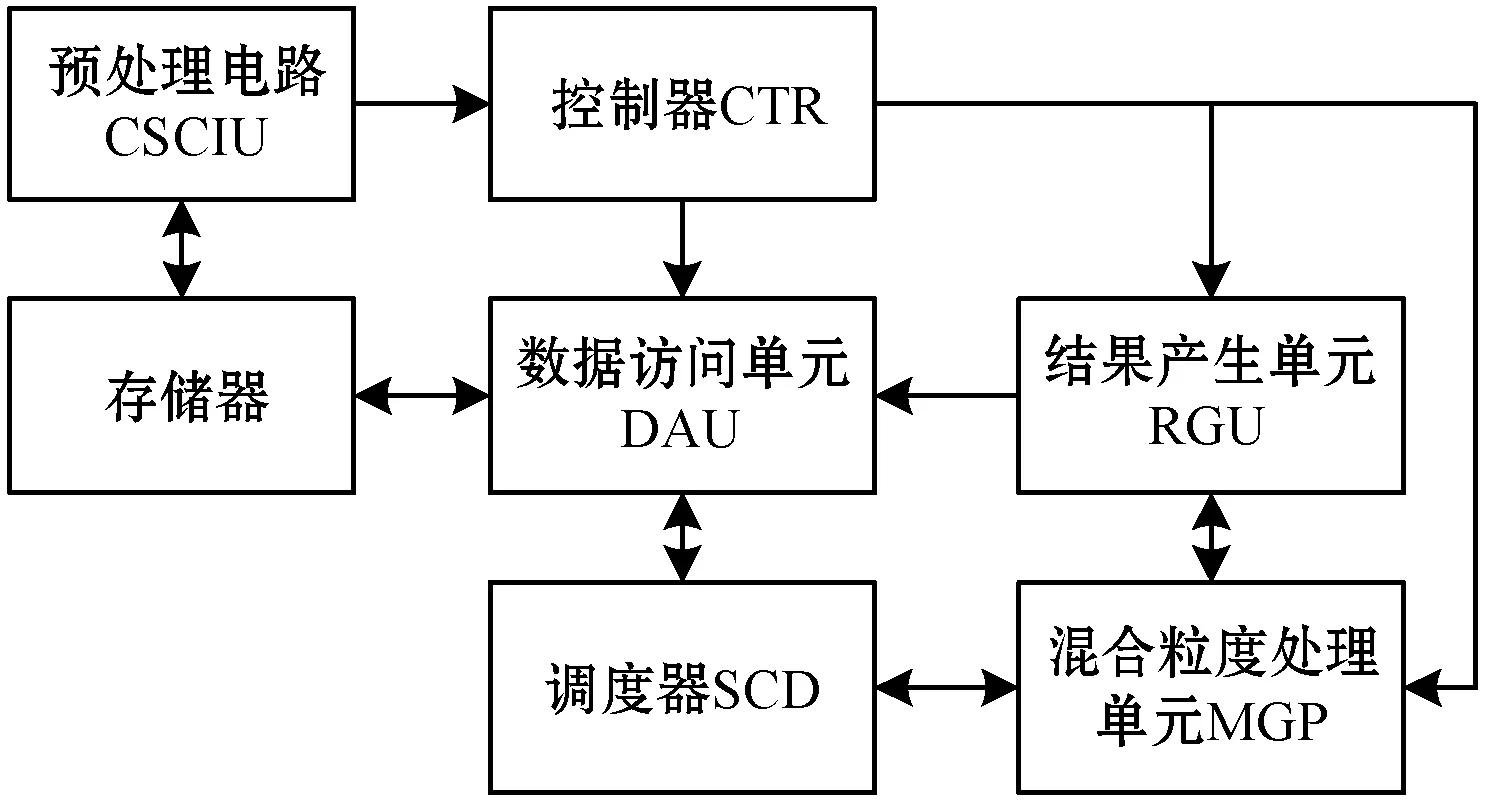
圖1 圖計算加速器的結構
圖計算加速器的預處理電路將待處理的以鄰接矩陣表示的圖數據轉換成獨立的稀疏列壓縮CSCI格式的圖數據,每列獨立壓縮后的圖數據包括列標識數據對和非零元素數據對,每個數據對都包括索引(index)和數值(value),索引的最高兩位指示索引其余位和數值的含義。
表2是CSCI格式中數據對的具體含義,當index最高兩位為“01”時,index其余位表示列索引,value表示鄰接稀疏矩陣中該列的非零元素數目;當index最高兩位為“10”時,index其余位表示列索引,且該列為鄰接稀疏矩陣的最后一列,value表示鄰接矩陣中該列的非零元素數目;當index最高位為“00”時,index其余位表示行索引,value表示稀疏鄰接矩陣中對應的非零元素值。
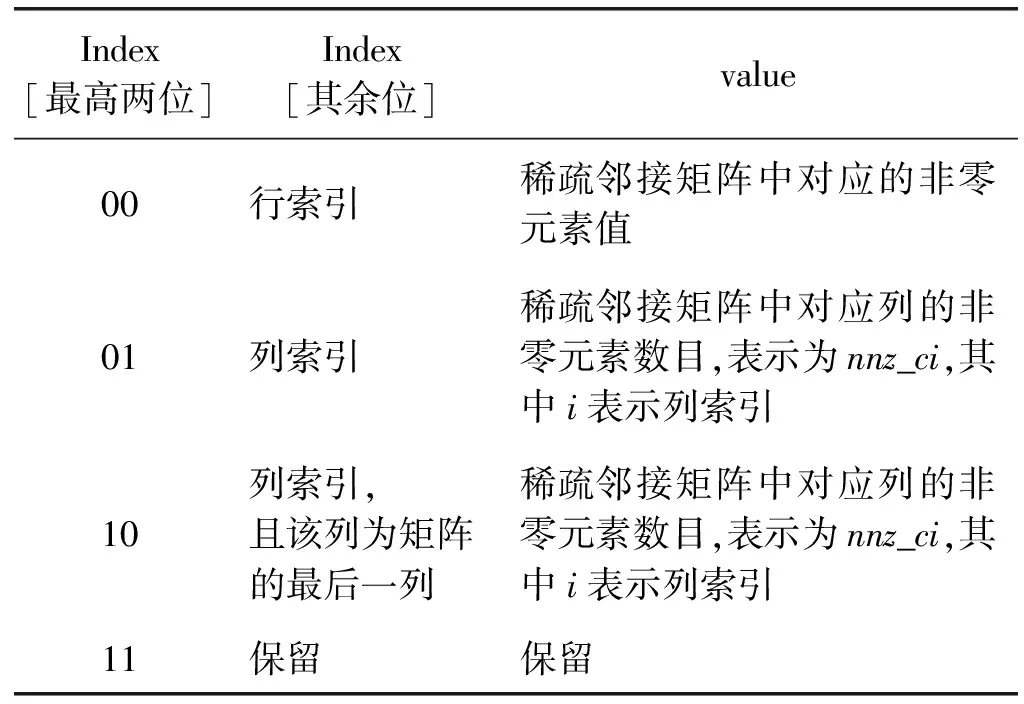
表2 CSCI格式中數據對含義
1.2 比較設計
經過CSCI[13]格式壓縮過的圖數據,對于多種圖計算應用,都會涉及到兩個稀疏矩陣列向量的比較運算操作,為高效地實現兩個CSCI格式表示對的稀疏向量的比較,本文設計一種基于圖計算加速器的稀疏矩陣列向量比較電路。
(1) 整體結構。稀疏矩陣列向量比較電路如圖2所示,假設兩個稀疏向量一個是目標向量,一個是比較向量,該設計包括64個比較運算電路,比較向量的所有非零元素輸入至第一個比較運算電路,目標向量的所有非零元素分別輸入至64個比較運算電路。第一個比較運算電路的輸入是所有比較向量元素和目標向量的第一個非零元素,經過比較運算后可以直接輸出的元素不再輸出至第二個比較運算電路與目標向量的第二個非零元素進行比較運算,需要與目標向量的第二個非零元素做比較運算的元素只是比較向量非零元素的一部分,以此類推,越后面的比較運算電路的比較運算操作越少,計算量越少。
(2) 比較運算電路。每個比較運算電路包括了操作電路、直接輸出模塊和中間輸出模塊,具體的電路設計如圖2右上部分所示。比較向量的非零元素數目是64,正如操作電路(Operate Circuit,OC)中包含了8個比較單元(Compare Unit,CU),比較運算的結果需要傳輸至下一個比較運算電路的非零元素通過中間輸出電路輸出,可以直接輸出的非零元素通過直接輸出電路輸出。中間輸出電路輸出的元素是運算元素,需要在下一個比較運算單元與下一個目標向量的非零元素進行比較運算。直接輸出電路輸出的元素是輸出元素,為保證最后一級比較運算電路輸出最終的比較運算結果,輸出元素在每一級的比較運算電路都是透傳。
操作電路OC包括了8個比較單元,分別為CU0-CU7,比較向量的非零元素順序分組后,每個CU都有8個比較向量的非零元素,每個CU的具體比較過程如圖3所示,實現一個目標向量非零元素和比較向量中的8個非零元素進行比較的過程。其中:target表示目標向量元素;com表示目標向量的元素;“00”表示目標向量元素的索引等于比較向量元素索引;“01”表示小于;“10”表示大于。
目標向量元素首先與比較向量的首個元素索引進行比較,小于或相等就可以結束比較,直接輸出相應結果,比較向量的其他元素可以輸出至下一級進行比較。若大于,接著與比較向量的最后一個元素索引進行比較。若相等輸出相應結果,本級的比較結束,小于該元素索引的比較向量元素都可以送至直接輸出模塊;若大于比較向量的最后一個元素索引,則要與下一組比較向量繼續進行比較;若小于比較向量的最后一個元素索引,繼續按照二分法進行比較,得到本級比較的結果。最后將可以直接輸出的向量元素送至直接輸出模塊,將需要輸出下一級比較的比較向量元素送至中間輸出模塊。
圖4是目標向量元素和比較向量元素的行索引三種比較情況,每個CU中目標向量的第一個非零元素與比較向量分組后的第一組8個非零元素進行行索引比較。
若比較向量的第一組中的非零元素的最小行索引(compare0_index)都大于目標向量第一個非零元素的行索引(target0_index),則目標向量的第一個非零元素可以直接輸出至直接輸出電路,分組比較單元CU0-CU7不再運行,將不再進行比較的比較向量的非零元素輸出至操作電路連接的中間輸出模塊,之后作為第二個比較運算電路的輸入比較向量,繼續與目標向量的第二個非零元素比較,如圖4中①所示。
若比較向量的第一組中的非零元素中存在與目標向量的第一個非零元素行索引相同,則將兩個非零元素的數值進行相應的運算,該結果傳輸至直接輸出電路,比較向量中其他索引小于目標向量的第一個非零元素的索引的非零元素傳輸到直接輸出電路,剩余大于目標向量的第一個非零元素的索引的非零元素傳輸到中間輸出電路。剩余分組比較單元CU1-CU7不再運行,將不再進行比較的比較向量的非零元素輸出至操作電路連接的中間輸出模塊,之后作為第二個比較運算電路的輸入比較向量,繼續與目標向量的第二個非零元素比較,如圖4中②所示。
若比較向量的第一組中的非零元素的行索引均小于目標向量第一個非零元素的行索引,將比較向量非零元素的第一組輸出至直接輸出模塊,目標向量第一個非零元素的行索引繼續與比較向量的第二組CU2的8個非零元素的索引比較,比較方法以此類推,如圖4中③所示。
(3) 共享存儲。共享存儲是用來存儲每一個比較運算電路中可以直接輸出的向量元素,如圖5所示,共享存儲包括一個初始地址寄存器和一個數據存儲。當一個比較運算電路運算結束后,根據初始存儲地址將數據依次存儲在數據存儲RAM中,當把本級比較運算電路直接輸出的向量元素存儲完畢會產生一個停止存儲的地址,該地址作為下一個比較運算電路的直接輸出向量元素在共享存儲中的初始地址。共享存儲的輸出是兩個稀疏向量比較運算的結果,當兩個稀疏向量的所有比較運算結束后,共享存儲的輸出將作為整個稀疏向量的比較運算結果輸出,此時,兩個稀疏向量的比較運算結束。
2 實驗結果及分析
本文所設計的圖計算中稀疏向量的比較運算電路,基于Verilog HDL語言在ModelSim SE-64 10.1c上完成設計和功能驗證,并且采用Xilinx公司的ISE14.7開發環境進行綜合,使用Xilinx公司ZYNQ系列的zc706 FPGA開發板對硬件電路進行測試。圖數據選自斯坦福大學SNAP(Stanford Network Analysis Project)的數據集Flickr[17]。
2.1 仿真設計結果
在對本文所設計的稀疏向量比較運算電路進行驗證時,首先將數據集中的非零元素轉換為CSCI格式,然后將這些壓縮過的數據作為整個設計的輸入。根據每個向量中非零元素的數目不同,分別對整個設計進行驗證。圖6是仿真的部分波形圖,圖6(a)是第一級比較運算電路的波形圖,第一級比較運算的實現周期是23,圖6(b)是第36級比較運算電路的波形圖,該級比較運算的實現周期是16。可以看出比較運算電路的實現周期數減少了。

(a) 第1級比較運算電路
(b) 第36級比較運算電路圖6 比較運算電路仿真結果
如圖7所示,根據稀疏向量中非零元素數目的不同,每一級比較運算電路實現的周期數也不同,前幾級的比較運算電路實現的周期數比較多,但是越往后,比較運算電路所做的計算量越少,實現的周期數也越少。圖7中的比較向量/目標向量中的非零元素數目分別是:64/64、55/50、40/42、32/40、23/20,雖然非零元素的數目不同,但所呈現的趨勢一樣。橫坐標表示比較運算電路的第一級至最后一級,每八個比較運算電路為一組,第一級的比較運算電路實現的周期數目在19~26個,第二級電路的實現也在20~24個周期,第三級至第四級的比較運算電路所實現的周期個數比前兩級明顯減少,且周期數基本保持在11~15個,后面三級的比較運算電路實現的周期數也明顯的減少,甚至有的運算電路由于非零元素數目的個數太少,導致最后三級的比較運算電路不執行,直接輸出最終的比較結果。
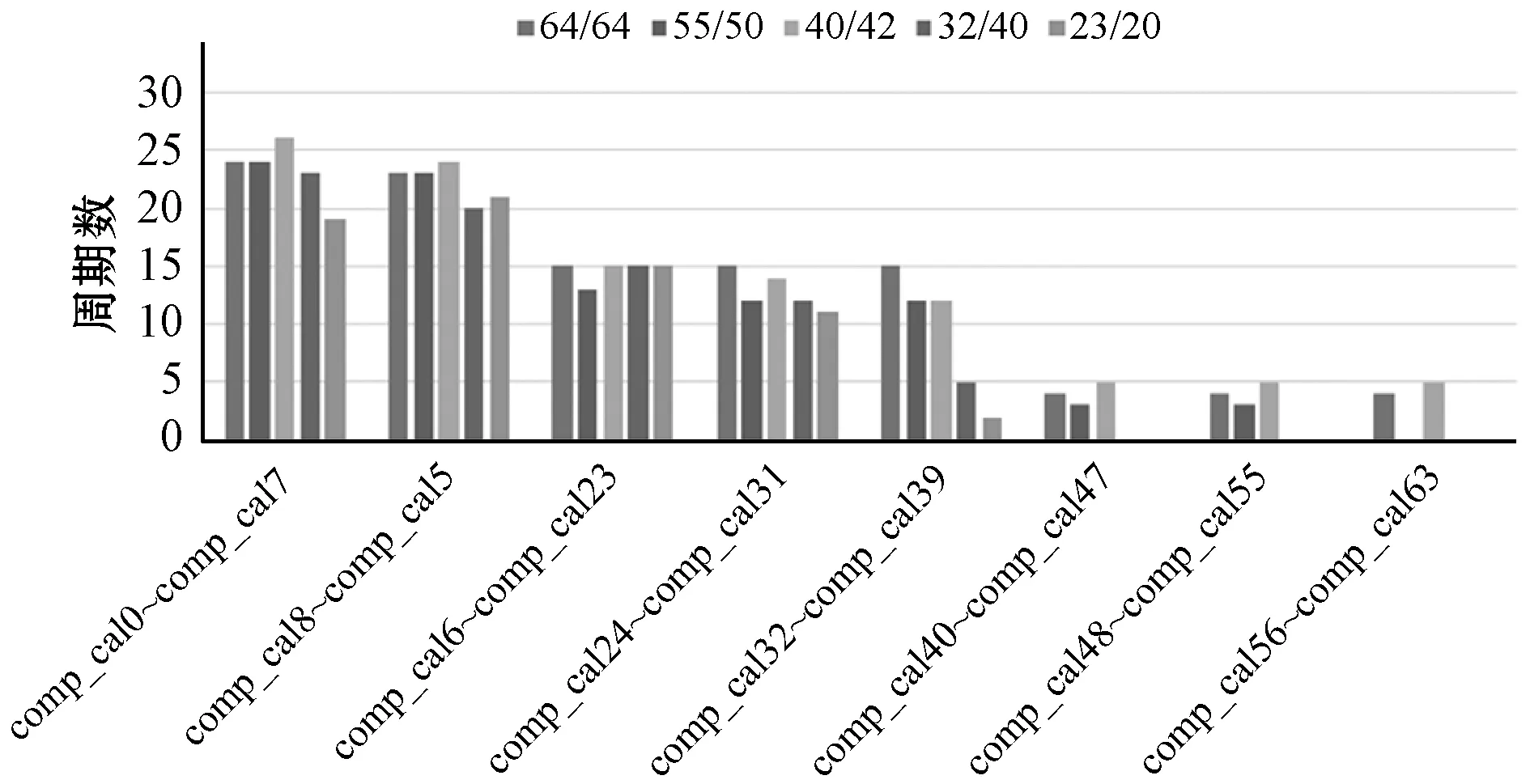
圖7 不同非零元素數目每個比較運算電路實現的周期數
2.2 綜合結果
由于圖計算加速器的主要瓶頸就是在兩個稀疏向量的比較運算上,所以本文所設計的兩個稀疏向量比較單元的性能在一定程度上可以代表整個圖計算加速器的性能。表3是與文獻[9]的資源利用的對比結果,可以看出,本文所設計的硬件電路LUTs資源使用減少了80 k,FFs資源使用減少了281 k。

表3 本文與文獻[9]的資源使用對比
圖的大小是圖計算的一個關鍵性能參數,表4是各圖計算加速器所用的數據集和數據集中的頂點V及邊E的大小。文獻[9]的數據集為SpMV,文獻[11]和文獻[12]均來自社交網絡和合成圖Kronecker,由表4可以看出,本文所采用的數據集Flickr比文獻[9]的數據集規模大,最大的頂點數目和最大的邊數目分別是GraphSOC[9]的58倍和7.9倍,但均小于文獻[11]和文獻[12]圖的規模。GraphOps[11]和GraFBoost[12]采用的圖的大小均大于Flickr,特別是GraFBoost[12]的數據集大小遠遠大于Flickr。
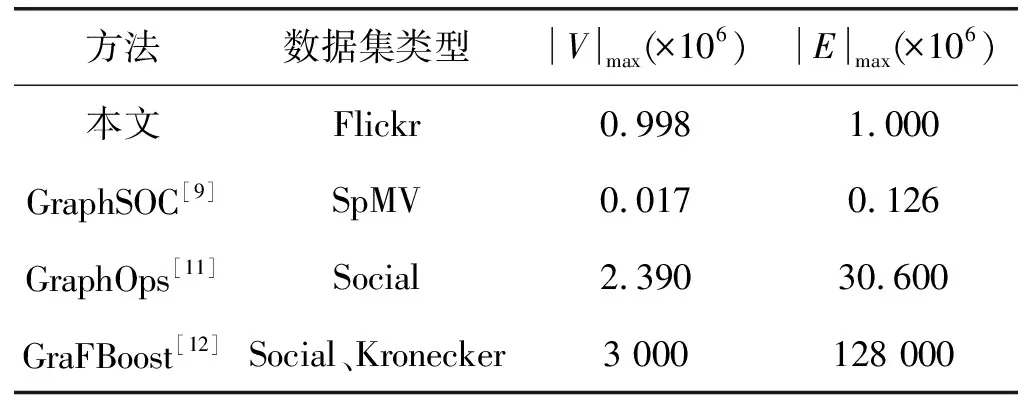
表4 數據集和數據集中的頂點及邊的大小
與圖計算加速器GraphSOC[9]、GraphOps[11]和GraFBoost[12]的數據集、圖數據壓縮格式和頻率進行了比較,結果如表5所示。GraphOps[11]采用的圖數據壓縮格式是自定義的,GraFBoost[12]采用的圖數據壓縮格式是CSR,本文采用的圖數據壓縮格式是CSCI[13]。本文硬件電路綜合的頻率均高于以上三個圖計算加速器,分別提高了5.6%、76%和111%。
在數據集大小相差不多的情況下,本文所設計的硬件電路比GraphSOC的資源使用低,且具有更高的綜合頻率。雖然綜合頻率高于GraphOps[11]和GraFBoost[12],但是本文用于驗證的數據集均小于這兩個加速器,并且本文設計的硬件電路是圖計算加速器的一部分。
3 結 語
為了高效地實現圖計算加速器中的稀疏矩陣列向量的比較運算,本文設計一種稀疏矩陣列向量的比較運算電路。本文提出的電路由64個比較運算電路和一個共享存儲模塊組成,經實驗分析,與其他的圖計算加速器相比,具有更高的工作頻率和更少的資源利用率。通過在Xilinx公司的ZC706開發板上進行驗證,表明可實現稀疏向量比較的功能。
