圖書館系統演變及其元數據管理*
2021-10-19 10:25:26許磊
圖書館論壇 2021年10期
許磊
0 引言
自1950年代開始,圖書館開始自研專注于特定業務的獨立系統,用于采購、編目、流通或期刊管理等業務。進入1970年代,圖書館自動化系統(Library Automation System,LAS)更加成熟,并有商業產品推出市場。隨著1960年代出現的MARC(Machine-ReadableCataloging)以及計算機技術的發展,1980年代開始,以MARC為底層元數據標準,集成了各獨立功能模塊的圖書館集成系統(Integrated Library Systems,ILS)逐漸取代LAS成為圖書館自動化轉型的推手[1]。ILS以及隨后的OPAC(Online Public Access Catalog),真正地將圖書館帶入計算機時代。但隨著互聯網出現,圖書館上下游生態環境發生改變,數字資源成為讀者的首選信息源。而ILS基于MARC構建的一套圍繞紙質文獻的采編典流集成系統,不再能夠適應數字化、云計算的互聯網環境。為滿足對電子資源的管理需要,出現了各種獨立的產品和服務,如電子資源管理系統(Electronic Resources Management,ERM),數字資產管理系統(Digital Asset Management,DAM);也出現了與之配套的元數據管理方案,如DC(Dublin Core)、MARCXML、MODS(Metadata Object Description Schema)。但是,各自獨立的系統以及異構的元數據方案阻礙了圖書館的業務流程優化以及資源整合。與此同時,圖書館元數據領域FRBR(Functional Requirements for Bibliographic Records)、RDA(Resource Description and Access)、BIBFRAME(Bibliographic Framework)等基于關聯數據設計的書目本體方案逐漸成為圖書館知識組織與融合的優選方案。因此,圖書館急需一個能夠整合ILS、ERM、OpenURL解析器、DAM等眾多獨立系統功能,也能夠支持各種開放元數據格式和數據交換協議以實現跨媒體的資源描述與組織的下一代圖書館管理系統。2010年OCLC推出的WorldShare Management Services(WMS)標志著圖書館服務平臺(Library Services Platform,LSP)進入圖書館系統市場。LSP是構建在SaaS(Software as a Service)平臺之上,利用云計算、Web技術和發現系統,實現全媒體的資源管理,全流程的業務管理和全網域的資源發現的新一代圖書館系統[2]。
平臺化的前提是信息化,只有開放、多元的信息生態才能促進圖書館的平臺化轉型。信息化不僅僅是解決業務流程的問題,更改變了信息資源的開發、建設與利用的生態鏈。信息化的基礎是自動化,圖書館自動化的發展推動了圖書館的資源與服務的網絡化和數字化[3]。從圖書館自動化到信息化再到平臺化,基礎都是信息資源的開發,也就是利用元數據對資源進行描述、組織與開發利用。無論是LSP的統一資源管理與發現,還是數據的開放與關聯,都對新一代圖書館系統的元數據管理提出了更多的要求。因此,本文從元數據管理角度對圖書館系統的演變進行梳理。并著重分析2類典型的圖書館服務平臺及其元數據管理方案,即商業產品Alma和開源項目FOLIO。
1 圖書館自動化系統及其元數據管理
1.1 圖書館集成系統及其元數據管理
計算機發明之初,圖書館就敏銳地發現計算機的應用對提升圖書館內部效率具有巨大潛力。1950年代美國和英國的圖書館開始嘗試將計算機應用于圖書館的內部業務[4]。到20世紀六七十年代,國內外圖書館開始研發專注于某一個核心業務的獨立系統[5-8]。但直到MARC出現,才真正奠定了圖書館自動化的基礎,推動了圖書館系統從單一功能的自動化系統轉向集成管理系統。MARC作為一種書目元數據格式,不僅提供了創建一致記錄所需的規則,成為支持圖書館龐大基礎結構互通的關鍵標準;而且創造性地在數據內容字段中嵌入目錄,即由頭標區、地址目次區和數據字段區構成的格式結構,解決了早期計算機技術應用于書目數據的諸多限制[9]。MARC的創新性不僅使其成為圖書館自動化系統的基礎,也使得書目數據共享達到了新的水平,推動了聯合目錄的發展與壯大。
圖書館系統在MARC誕生之后,經過初始階段的探索與自主研發后,1980年代逐漸發展為由商業公司主導開發的圖書館集成管理系統,并占據主流直至今日。ILS建立在圖書館標準化的業務流程之上,從采訪、編目、流通到連續出版物管理、聯合目錄等業務都圍繞著標準書目數據格式展開。因此,無論是國內的ILAS、匯文[10],還是國外的Millennium、Aleph500、Horizon[11],都以MARC作為其元數據管理標準格式。自ILS投入使用后,其采編典流等功能模塊基本是穩定的。雖然每個模塊隨著技術升級不斷完善,但仍主要管理紙質資源。進入1990年代,日益增多的電子和數字資源改變了整個圖書館資源和技術生態,幾乎所有圖書館都面臨著同時支持物理和電子資源,并提供適合各種媒介服務的復合任務。由于傳統的ILS側重于紙質資源管理,圖書館不得不開發獨立于ILS的系統以支持電子和數字資源管理,如鏈接解析器、聯邦搜索、電子資源管理系統、數字資產管理系統、機構知識庫。在這種背景下,圖書館需要一個不同于MARC的新的元數據標準。
1.2 數字圖書館系統及其元數據管理
當MARC成為圖書館行業主流的元數據標準時,互聯網和搜索引擎卻在顛覆信息傳播與獲取方式。鑒于MARC已不再適用新型資源的管理,圖書館專家著手利用最新技術對MARC進行改造,MARCXML因此誕生。雖然MARCXML部分解決了MARC格式的缺陷,使其在網絡時代獲得暫時性的新生[12],但它只是一種臨時的補救措施,并不能完全解決MARC對網絡資源的不適性。針對多變的網絡資源,1995年來自圖情檔和計算機領域的專家們在都柏林發布網絡世界的元數據標準DC。DC通過將元數據元素精簡到最低限度,確定最為核心的15個元素,以滿足對各種物理或電子資源的描述。經過DCMI的維護與推廣,DC逐漸成為互聯網描述性元數據的通用標準,也成為文化遺產領域新開發的數字圖書館系統的基礎元數據之一[13-14]。
數字圖書館系統的元數據管理方案復雜。它不僅需要對數字對象進行描述性記錄,還需要對數字對象本身的管理性與結構性信息進行記錄,最后這三種類型的記錄還需要一個整體框架進行封裝,以實現對數字對象完整的元數據管理[15]。因此,即使部分圖書館集成系統支持對DC數據的管理,但依舊無法滿足圖書館的數字資源管理需求。在圖書館自動化系統時代,面向紙質資源的圖書館集成系統元數據管理以MARC格式為主。1990年代后,面對格式多樣的資源,又出現了各種數字圖書館系統。資源管理系統的分裂導致圖書館資源分散,不僅降低了用戶信息檢索的效率,也影響了圖書館內部業務的整合。雖然在信息服務方面,通過聯邦檢索[16],OAIPMH(Open Archives Initiative Protocol for Metadata Harvesting)、SRU(Search/Retrieve via URL)等元數據收割協議[17],或建設統一元數據倉儲[18]等技術手段實現資源的統一檢索,但在圖書館內部業務整合潮流之下,圖書館自動化系統的升級慢了很多。圖書館不得不在原有的ILS基礎上開發各種補丁式工具,或者另起爐灶開發獨立的管理系統,以滿足日益多樣的資源類型、用戶需求和業務流程[19]。這種打補丁堆疊的系統開發方式使ILS喪失了“集成性”,并導致數據的孤島化,進而降低了圖書館的服務效能[20]。圖書館需要更新系統以滿足不斷變化的需求。從2008年開始,系統生產商著手研發取代ILS的下一代圖書館系統。直到2010年,OCLC發布下一代圖書館系統WorldShare Management Services,才昭示紙電合一的圖書館服務平臺正式進入圖書館自動化市場。
2 圖書館服務平臺及其元數據管理
2.1 現狀與需求
在數據驅動業務轉型以及研究范式變化[21]的當下,開放共享數據日漸成為重要的生產資料,圖書館的主要矛盾已變為用戶對圖書館新型服務的需求與圖書館服務能力不足的矛盾,特別是深度的數據服務、知識服務、智慧服務等[22]。可以說第三代圖書館正在經歷從信息環境到數據環境、知識環境的轉變,經歷資源與信息服務向知識服務平臺的轉變[23]。
如阿克夫DIKW金字塔(Ackoff's pyramid)所描述的,知識是在信息之間建立有意義的聯系,而信息則是有組織的數據。從底層的數據到信息到知識乃至到理解與智慧,每個層次的上升關鍵在于在低層次的各部分之間建立聯系,產生新的模式,從而組成新的聚合體,并成為下一個層次的組成部分,而元數據正是其粘合劑[24]。一方面,傳統圖書館元數據無論是MARC還是DC都是以記錄為最小單位,無法應對資源數據化和服務知識化的挑戰;另一方面,圖書館服務平臺的統一資源管理與發現的基本特征決定了中央知識庫在整個平臺中的核心地位[25]。中央知識庫集成了其他各個模塊的異構資源,提高了平臺效率、互操作性和自動化水平。針對多源異構元數據的互操作,服務平臺需要在元數據之上建立某種機制,作為“元”元數據的知識本體就是一種解決方案[26]。長遠看,無論是圖書館數據規范[27],還是資源發現服務[28],以一體化本體模型為基礎的元數據模式是相對高效的解決方案[29]。業務與系統功能整合、資源關聯與融合、服務智慧化與知識化這一圖書館新常態對新一代圖書館服務平臺的元數據管理提出了新的需求,即完整的生命周期管理、資源類型兼容、標準規范兼容、互聯網環境下的書目與規范控制、知識組織與知識融合[30]。
2.2 特點
(1)全媒體資源管理已經成為智慧圖書館的基本功能。圖書館服務平臺需要兼容各種標準,實現元數據間的互操作。位于架構核心的中央知識庫的數據模型將作為現有元數據的共同子集,實現對各種標準的兼容。一方面支持圖書館靈活描述紙質資源、電子資源、數字資源,不受限于文獻類型與格式;另一方面也支持用戶對跨媒體資源的內容發現、識別、選擇、獲取與導航。
(2)新一代圖書館服務平臺不僅需要支持各類型圖書館本地特色性功能,也要滿足未來新型服務形式的開發需求。因此,針對各種個性化和未知性的需求,服務平臺的元數據是可擴展的。一方面新部署的應用程序或模塊的元數據可以在原標準上進行應用內擴展,也可以啟用新標準;另一方面中央知識庫的元數據可以通過映射轉換實現對新標準的兼容,或可以對現有模型進行擴展實現兼容。
(3)隨著語義網和關聯數據技術的日漸成熟,元數據的語義化改造已成為趨勢。伴隨著這股浪潮,知識服務、智慧服務正在成為圖書館新的發展方向。傳統元數據通過標簽或字段名定義元素的語義信息,不同元數據標準即使字段名相同其含義也會不同。在開放數據情境下,無法精確定義的元素不能有效支持對知識的推斷。與傳統元數據相比,知識本體利用RDF進行形式化編碼,通過URI提供所標識元素的上下文語境。它不僅利用URI的全網唯一性,實現圖書館在互聯網時代規范控制的宏愿,也使得資源描述的粒度由記錄級細化到陳述級,描述對象深入到知識和實體,激活圖書館的知識服務。新一代圖書館服務平臺元數據方案中本體與RDF的應用,將打破圖書館行業的“孤芳自賞”,信息組織、規范控制的思想可以貢獻到整個網絡之中。同時,圖書館也可以整合機構內外的各種資源,在語義層面實現元數據互操作,賦予其機器可理解的能力,促進圖書館數據的開放與融合,助推圖書館服務轉型。
3 Alma平臺元數據管理
Alma是商業上最成功的圖書館服務平臺,無論是在用戶滿意度還是留存率上都處于第一梯度[31]。作為支持多類型資源管理和元數據協作的云服務平臺,Alma設計了不同于傳統圖書館集成系統的集中式元數據管理服務(Metadata Management Service,MMS)。一方面,Alma元數據根據需要存儲在三個不同的數據區:機構區(Institution Zone)、共享區(Community Zone)和網絡區(Network Zone)[32]。機構區保存有圖書館本地的Alma配置和元數據。共享區是Alma對所有租戶開放的共享記錄部分,包含中央知識庫、規范數據庫和聯合書目庫。網絡區則保存機構聯盟的共享記錄。這種混合模式允許機構管理其獨特的本地館藏,同時支持一個共享的聯盟目錄,以及一個全球社區目錄。另一方面,每個數據區又分層為MMS記錄和館藏記錄(Inventory records)。MMS記錄包括各種配置信息,如導入、查重、數據合并,以及MARC、DC等多種格式的描述性記錄。館藏記錄包括紙質資源的館藏復本記錄、電子資源檔案和數字資源表達與文檔,并進一步分為3層:知識實體層(intellectual entity,IE)、中間層(Middle level)和單件層(Item)[33],如圖1所示。知識實體層是一個不可見的透明實體,僅作為指向MMS記錄的指針。通過IE,館藏記錄與書目描述記錄實現關聯。中間層對不同資源類型有不同的層次分組,這個層級記錄包括紙質資源的館藏信息、電子資源的服務信息、數字資源的表達信息。最底層的單件記錄是關于紙質復本、電子文件、數字文檔的有關信息。

圖1 Alma元數據記錄分層結構
Alma通過上述的分區、分層的元數據管理模式實現對包括本地、聯盟和全球社區的多源資源的共享與協作。也實現對多種元數據格式、內容標準和通信協議的兼容,雖然這一定程度上增加了資源管理與業務操作的復雜性,但可以滿足圖書館對紙質、電子和數字資源的統一管理與聚合揭示的需求[34]。另外,Alma利用嵌入式URI實現對關聯數據的支持,并通過RESTful API對外提供數據服務[35]。
新一代圖書館系統是圖書館平臺化轉型的基礎。平臺化的一個重要特征是開放的標準的信息生態,任何人都可以在生態平臺上開發新的應用與服務[36]。平臺化強調的是協作,是與利益相關方建立的社區,合作創新促進更多價值的產生。按此理解,以Alma、WMS、Sierra為代表的商業LSP,更側重于圖書館在云環境中對各類型資源管理的能力。雖然它們在朝著平臺化方向發展,即使開放了API供數據交互,但本身仍然是一個缺乏其他行業參與者的“封閉”系統。
吳建中[37]、劉煒[38]在關于第三代圖書館及其圖書館系統的論述中都強調不同于傳統圖書館的空間服務、知識服務。以商業公司主導無論是集成性、開放性還是技術先進性的問題[39],并不能完全適應第三代圖書館多樣性和差異化的發展趨勢。正如朱強所言,當前圖書館對其管理系統的發展無話語權,系統與數據開發商對數據庫和系統的壟斷極大地限制了我國圖書館的發展。因此,第三代圖書館需要更大的自主權,利用松散耦合的應用組合方式滿足本地的特色發展;需要一個模式自選、業務自組、數據自管的開放服務平臺應對從資源到空間、從業務到服務的各種挑戰[40]。更強大的新一代圖書館服務平臺不僅要滿足統一的資源與業務管理,也要具有足夠的靈活性、擴展性和個性化,以支持圖書館大量已知或未知的業務,滿足個性化發展需求。而這種社區驅動的平臺化在開源的FOLIO項目中可窺見一二。FOLIO不僅致力于開發一個創新的開源圖書館服務平臺,更是一個由圖書館、開發商、供應商及其他利益機構共同組成的協作社區。
4 FOLIO平臺及其元數據管理
4.1 FOLIO平臺的元數據方案
一方面,作為一個面向圖書館的微服務平臺,FOLIO的元數據方案遵循微服務架構數據管理的域敏感,即每一個服務可以有自己的數據模型與數據存儲。根據業務需求,FOLIO將整個服務平臺劃分成不同的“域”,如典藏域、流通域、采訪域、數字資源管理域以及核心的Codex域等。每一個FOLIO域是由多個應用程序(Apps)組成,完成特定任務的功能模塊。域的數據模型與元素秉承最小化原則,只保留滿足本模塊功能的核心元素。另一方面,FOLIO根據資源管理域所需的描述詳略程度和它們所服務的目的,將元數據記錄從下到上分成3層:正式記錄層(Formal Records)、業務記錄層(Working Records)、統 一 記 錄 層(Unifying Records)[41]。FOLIO針對具體的管理功能,根據文獻類型,在不同域的App中執行。在預先了解了資源屬性與相應的管理程序時,可以直接訪問這些應用程序獲取和管理資源,即業務記錄層。但在一般情況下,是以Codex域中的應用程序作為入口,即頂層的統一記錄層。根據需要,從Codex可以導航到系統的任何地方,以便在適當的應用環境中管理資源。如圖2所示,FOLIO通過Codex記錄與各種資源管理應用程序中的業務記錄相鏈接,再與底層的正式記錄相連,形成一條從Codex到最細粒度元數據的鏈接路徑。
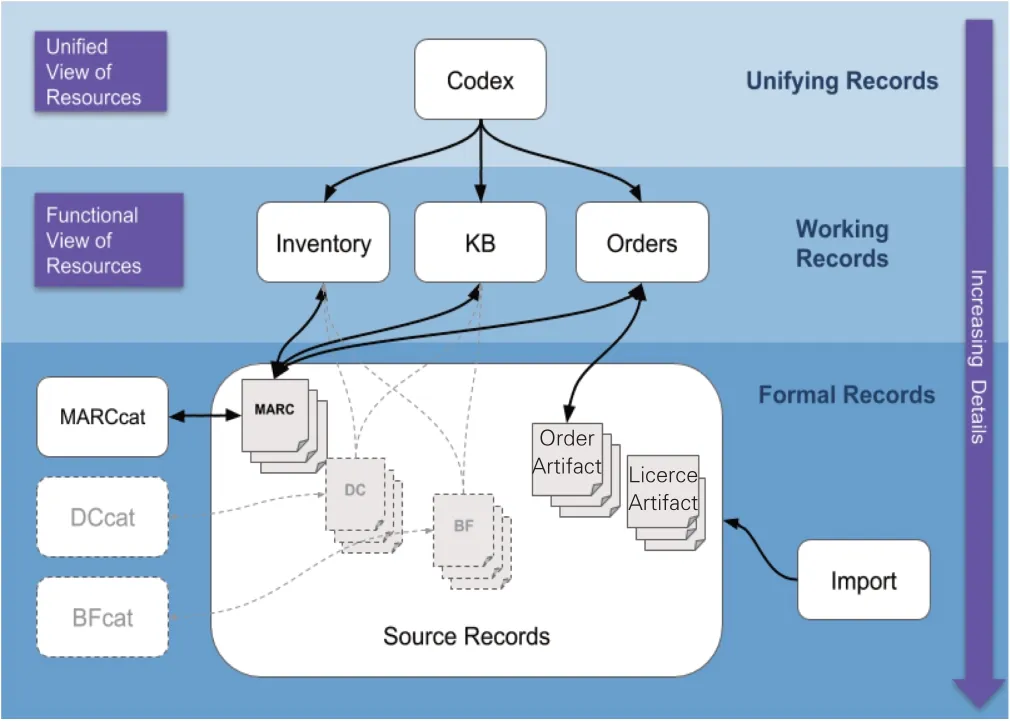
圖2 FOLIO系統的數據分層[41]

圖3 Codex數據模型[42]
4.1.1 Codex的元數據方案
Codex是一個規范的虛擬層,使用一個通用模型域與元素來整合不同類型資源,而不考慮格式、編碼或存儲位置。
(1)Codex定位于FOLIO平臺的數據注冊與鏈接中心,避免各業務域之間的糾纏。在FOLIO分層結構中,位于頂層的Codex可以充當不同模塊之間的協調者。每個模塊只需與中介模塊集成,即可實現對其他模塊的數據需求,而不用與其發生依賴關系。同時,Codex中介域的角色決定了它在整個FOLIO系統中的資源中心地位,其他資源管理模塊都會將其數據記錄通過映射轉換后在Codex域中生成對應的記錄,自然也成為所有資源查詢的起點。從Codex開始,用戶可以深入到更低的、更豐富的業務、正式記錄層。
(2)作為一個域,Codex就有自己的概念模型來描述資源。在BIBFRAME 2分層模型和DC元素定義基礎上,Codex定義了一個輕量級的作品—實例—單件/館藏的3層數據模型。它是單個資源管理域所使用的更復雜、更專業的數據模型的共同交集。該模型足夠完整,可以滿足Codex域的資源描述任務。但又足夠的小,避免與其他域元數據過多的重復。另外,為滿足對電子資源的管理,Codex核心模型中還定義了資源包(Container)、覆蓋范圍(Coverage)和館藏地信息(Location),如圖3所示。
4.1.2 FOLIO的實體對象管理
以2008年瑞典國家圖書館的關聯書目數據發布為標志,圖書館書目、規范數據的實體化轉向成為行業共識[43]。FOLIO的元數據方案融合BIBFRAME模型特征和DC的最小化原則,為滿足未來面向實體對象的下一代元數據管理構建了良好的基礎。Codex愿景也表明對整個FOLIO服務平臺的實體標識與關聯的設想。而在具體的實施層面,FOLIO則設計了專用的實體管理App(Entities Management App)[44]。
實體管理App是FOLIO平臺跨域進行實體規范控制的核心,它不僅可以對本地規范數據和取值詞表進行統一的創建、發布和永久URI維護,也可以對外部開放數據源進行實時調用檢索甚至于本地化緩存。FOLIO暫將實體分成代理(Agents)、體 裁(Genres)、地 理(Geographic)、主題(Subjects)、作品(Works)和其他6類實體。代理、地理、主題實體以及其他取值詞表,是傳統圖書館規范控制工作的延續,外部來源可以包括VIAF、LC名稱規范庫(LCNAF),蓋蒂藝術家聯合名錄(Getty Union List of Artist Names)、地理名稱(GeoNames)、LC主題詞表(LCSH)、分面應用主題詞表(FAST)、MARC和RDA中取值詞表等。體裁在用戶信息檢索中的重要性已經得到證實[45],因此FOLIO將其作為一個獨立實體進行標識管理,外部數據來源可以有善本手稿專業委員會詞表(RBMS Genre Terms),蓋蒂藝術與建筑詞表(Getty Art & Architecture Thesaurus)等。而作品實體作為書目領域最為核心的基礎實體,FOLIO更是在已有的書目本體方案基礎上,兼容了最新的研究進展,即作品—超級作品模型,其作品實體包含LC BIBFRAME Works、LC hub、OCLC Works、Share-VDE Works、Share-VDE Opus。其中的LC hub,Share-VDE Opus即是在實踐中對作品—實例—單件/館藏模型的擴展,在作品層之上定義超級作品,聚合相關作品,形成作品家族。
實體管理App的元數據方案遵循FOLIO平臺的域敏感以及分層結構。實體管理App中的元數據屬于業務記錄層,主要是提供對受控字符串的訪問,而不是對實體的完整描述性。更詳細的正式記錄存儲在實體源記錄庫(Entities Source Record Storage)中,或直接鏈接到外部數據源。因此,其數據模型也是一個抽象層,不關心原始實體描述數據的格式或存儲位置。FOLIO Apps通過實體管理App提供的檢索查找服務或API獲取本地或外部的首選標簽應用于描述數據中。
4.2 與Alma元數據方案的比較
憑借后發優勢,FOLIO在微服務域以及元數據模型設計上,原生支持基于語義的規范控制與知識融通。一方面,基于微服務架構的FOLIO平臺是一個基于標準協議的框架,框架內是一個個按照單一職能原則獨立開發和部署的應用程序。不同的應用程序根據不同的業務需求會設計不同的數據模型與元數據元素。而頂層的Codex域則解決了異構資源的統一管理問題,同時中介各服務間的元數據鏈接,維持整個平臺的低耦合。另一方面,基于BIBFRAME設計的最小化元數據模型,以及實體管理App,都將保障FOLIO平臺實現圍繞實體進行身份的管理與服務。
Alma平臺雖然在異構資源整合和基于MARC的業務流程上提供了強大的功能,但也因此在基于身份的實體管理方面依舊處于BIBFLOW所言的第一階段[46],即通過在MARC中 嵌 入URI,導 出BIBFRAME、RDA/RDF、JSON-LD記錄[47]在界面中顯示,或提供SPARQL、API端 點。Alma通 過FRBR化 在Primo發現層[48]對讀者提供有限的信息增值服務,但其內部元數據管理依舊圍繞記錄展開。雖然Alma在最新的開發路線圖中描述了圍繞關聯數據構建的一套元數據管理流程[49],但受限于現有技術架構與元數據方案,全面的實體轉向效果仍待觀察。二者元數據方案對比見表1。
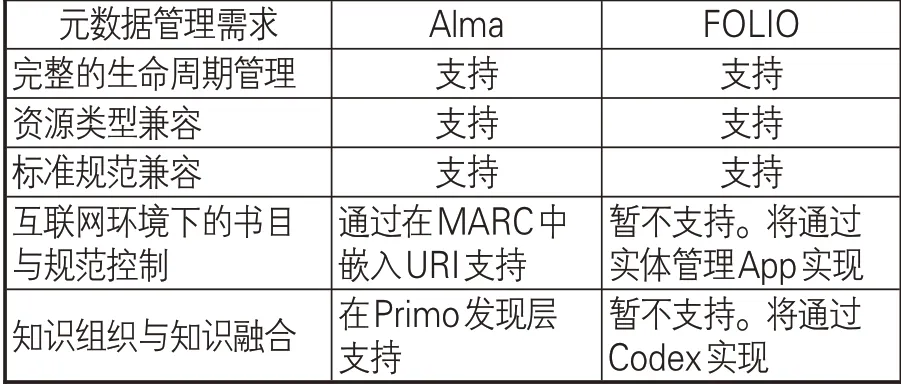
表1 Alma與FOLIO元數據方案比較
5 結語
成也MARC,敗也MARC。進入互聯網時代,誕生于1960年代的MARC已經成為圖書館融入網絡環境的一大掣肘。雖然在元數據方案方面,圖書館一直在積極變革,如1995年DC、1998年FRBR、2000年MARCXML、2002年MODS、2010年RDA、2011年BIBFRAME 1.0、2012年SchemaBibEx。圖書館元數據管理方案一直在努力實現更細粒度的深層描述與資源展示,但受限于圖書館管理系統與MARC的深度綁定,面向對象的實體編目以及跨領域的知識融合收效甚微。
新一代的圖書館服務平臺以全新的技術架構整合各自獨立的圖書館系統,通過一組標準化的內部數據結構,或通過一種本地存儲不同類型記錄的機制,打破MARC格式的封閉性,同時支持各種元數據標準,為圖書館提供一個開放的元數據管理環境[50],實現紙電合一的業務流程管理以及資源描述和發現服務。但在數據為王的時代,第三代圖書館需要對系統設計和數字資產擁有更大的自主權。以FOLIO為代表的新一代圖書館服務平臺可以滿足圖書館對管理系統的深度參與按需定制。FOLIO基于BIBFRAME和DC為基礎設計的Codex抽象數據層作為其元數據管理核心。同時,根據微服務的數據管理原則,對元數據記錄劃分為“統一記錄—業務記錄—正式記錄”的三層結構。這樣一來,不僅可以跳出MARC“圍城”,不再考慮元數據格式以及存儲位置,為深度知識組合與融合提供基礎;更進一步,FOLIO設計了單獨的實體管理App,順應了互聯網環境下圖書館書目與規范控制的語義化趨勢,為圖書館資源與服務的“出圈”提供了可能。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
商周刊(2017年9期)2017-08-22 02:57:56
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
