基于自然語言處理的發電設備知識庫系統研究
2021-10-19 13:16:22沈銘科程相杰方超丁剛陳家穎
現代信息科技 2021年6期
沈銘科 程相杰 方超 丁剛 陳家穎

摘 ?要:文章設計了一種基于自然語言處理的發電設備知識庫系統,包括知識抽取、語料和知識存儲、知識問答排序和知識庫前端問答等模塊,構建過程為:首先進行發電設備領域自然語言處理基礎模型訓練,再針對領域語料進行知識抽取,最后利用排序模型實現知識問答。對比4種知識抽取方案可得:對于Top1和Top3準確率,知識抽取前處理增加MRC模型比后處理增加MRC校驗回路準確率高;對于Top5準確率,后處理中增加MRC校驗回路較前處理中增加MRC模型準確率高。
關鍵詞:自然語言處理;發電設備;知識庫系統;知識抽取;知識問答
中圖分類號:TP391.1 ? ? 文獻標識碼:A 文章編號:2096-4706(2021)06-0013-05
Research on Knowledge Base System of Power Generation Equipment Based on Natural Language Processing
SHEN Mingke,CHENG Xiangjie,FANG Chao,DING Gang,CHEN Jiaying
(Shanghai Power Equipment Research Institute Co.,Ltd.,Shanghai ?200240,China)
Abstract:This paper designs a knowledge base system for power generation equipment based on natural language processing,which includes knowledge extraction,corpus and knowledge storage,knowledge question and answer sorting,and front-end question and answer of knowledge base and other modules. The construction process is:firstly,performs natural language processing basic model training in the field of power generation equipment;then extracts knowledge from the domain corpus;finally,uses the sorting model to achieve knowledge question and answer. Comparing the four knowledge extraction schemes can be obtained that for the accuracy of Top1 and Top3,the accuracy of adding MRC model in the pre-processing of knowledge extraction is higher than that of adding the MRC verification loop in the post-processing. For Top5 accuracy,adding MRC verification loop in post-processing has a higher accuracy rate than adding MRC model in pre-processing.
Keywords:natural language processing;power generation equipment;knowledge base system;knowledge extraction;knowledge question and answer
0 ?引 ?言
在發電機組設備管理過程中,涉及大量自然語言形式承載的不同形式的非結構化文檔,如標準規范、設備說明書、作業手冊、檢修報告、案例總結報告等。這些非結構化文檔是發電企業在日常工作中編寫、業務專家定期分析匯總的經驗性文檔,對指導設備管理工作具有重要意義[1,2]。但往往這些寶貴的文檔分散存儲在企業不同的文檔管理系統和辦公電腦中,導致技術人員在查閱和分析過程中存在困難。雖然發電企業已經開始應用設備文件管理系統和知識庫系統,但大多數的文件系統和知識庫系統存在著一些不容忽視的問題,比如無法針對文本內容進行檢索或者只能采用關鍵詞檢索,缺乏語義層面上的知識問答能力[3,4]。因此隨著數據量逐漸增大,在工作中需要檢索某個設備相關文件具體的章節、段落或條目時,查詢檢索依然非常不方便導致工作效率低下,大量的知識經驗沒有有效發揮其應有的數據價值。
目前,基于自然語言處理的知識庫系統已經在電網、客服、醫療、旅游等領域取得了良好的應用效果[5-9]。為解決發電企業文件系統和傳統知識庫系統的弊端,本文提出了一種基于自然語言處理的發電設備知識庫系統,可以有效提升發電設備文本知識的查詢效率。
1 ?基于自然語言處理的知識庫系統架構設計
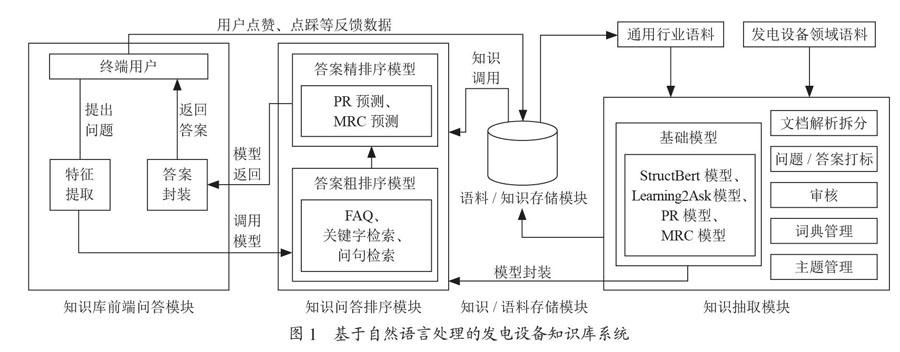
如圖1所示,基于自然語言處理的發電設備知識庫系統主要包含4個模塊:知識抽取模塊、知識/語料存儲模塊、知識問答排序模塊和知識庫前端問答模塊。
各模塊具體內容為:
(1)知識抽取模塊。該模塊包含了文檔解析拆分、問答/答案打標、數據清洗、審核等語料數據預處理功能,以及詞向量預訓練(StructBert)、機器學習提問(Learning2Ask)、篇章排序(PR)、機器閱讀理解(MRC)等用于知識抽取的基礎模型訓練。訓練好的模型經過封裝后還用于知識問答排序模塊進行答案預測。詞典管理、主題管理等功能可以配置行業同義詞和知識主題,用以提高知識抽取的準確率。
(2)知識/語料存儲模塊。該模塊用于存儲語料數據、抽取的知識數據以及終端用戶針對答案進行點贊和點踩的反饋數據。語料數據用來進行知識抽取模塊中模型的訓練,知識數據將為知識問答排序模塊提供答案,用戶反饋數據用來優化模型訓練效果。
(3)知識問答排序模塊。該模塊包括答案粗排序模型和答案精排序模型,用于對知識問答的答案進行排序。粗排序模型中主要有常用問答對(FAQ)、關鍵詞檢索(ES)、問句檢索等算法引擎[10-14];精排序中主要有知識抽取模塊中訓練并封裝后的PR和MRC模型。
(4)知識庫前端問答模塊。該模塊主要包含用戶交互、特征提取、答案封裝等功能。用戶交互功能可以獲取用戶提出的問題,并返回封裝后答案;特征提取主要用于針對問題的分詞、擴詞糾錯、用戶特征識別等特征提取過程;答案封裝主要用于針對知識問題排序模塊返回的多條答案進行組裝展示。
2 ?發電設備知識庫系統構建
2.1 ?知識抽取基礎模型訓練
2.1.1 ?發電設備領域Bert模型訓練
本系統采用的是融合語言結構的Bert預訓練模型(StructBert),通過在訓練任務中增加詞序(Word-level ordering)和句序(Sentence-level ordering)兩項任務,來解決傳統預訓練語言模型BERT在預訓練任務中忽略了語言結構的問題[15,16]。首先,將大規模的通用行業語料文檔進行數據預處理,并訓練生成通用行業的StructBert預訓練模型,再通過數據預處理后的發電設備領域語料將其微調至針對發電設備領域的StructBert模型。
2.1.2 ?Learning2Ask模型訓練
Learning2Ask模型是根據一段自然語言文本而生成問題的模型[17]。本系統采用基于StructBert預訓練模型的自然語言生成模型來實現機器自動生成問題。首先,將訓練生成的發電設備領域的StructBert預訓練模型作為編碼器,并用于問題生成模型的初始化,再搭建一個解碼器來產生問題。
2.1.3 ?PR&MRC模型訓練
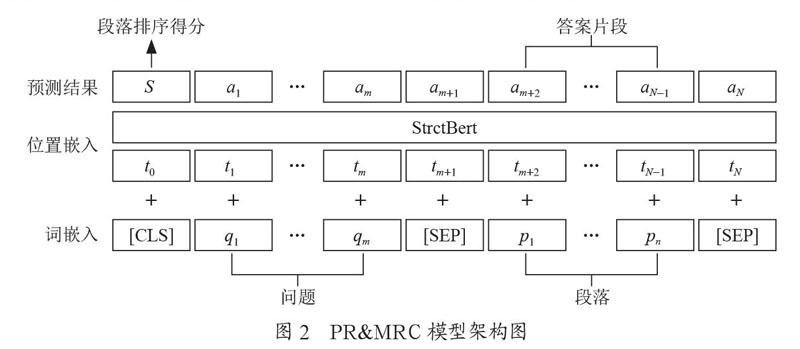
篇章排序模型(PR)用于匹配問題與段落的相關性,為用戶提出問題答案所在的候選段落集進行排序[18]。其具體任務描述為:給定一個三元組(Qi,Pi,Si),根據問題Qi=[q1,q2,…,qm]和相對應的篇章段落Pi=[p1,p2,…,pn],通過自然語言理解,推理給出問題Qi與段落Pi的相關性評分Si,再根據Si進行排序。其中,qi是問題的某個詞語,pi是段落的某個詞語,m為問題的長度,n為段落的長度。
機器閱讀理解模型(MRC)是利用機器來閱讀特定的文本段落并回答給出的問題[19,20]。其具體任務描述為:給定一個三元組(Qi,Pi,Ai),根據問題Qi=[q1,q2,…,qm]和相對應的篇章段落Pi=[p1,p2,…,pn],通過自然語言理解,推理給出問題答案Ai。其中,qi是問題的某個詞語,pi是段落的某個詞語,m為問題的長度,n為段落的長度。
上述兩個模型輸入均為問答文本和段落文本候選集,故本系統采用PR模型與MRC模型綜合考慮的方式,搭建PR&MRC模型,其模型輸出為段落排名分數和答案,模型架構如圖2所示。
2.2 ?發電設備知識抽取
2.2.1 ?前處理過程
知識抽取前處理過程指發電設備語料文本經過粗拆、精拆形成一個個知識點(答案)的過程,如圖3所示。
首先,將語料文本利用文檔序號層級、標點符號識別等規則進行粗拆處理形成段落,段落字數要求控制在500字以內,然后將段落再精拆處理形成答案。根據精拆處理方法不同,前處理過程可以分為2種方式:
方式1(規則拆解):在粗拆形成段落后,再利用規則拆解的方法進行精拆處理得到答案;
方式2(規則拆解+MRC抽取):在粗拆形成段落后,同時利用規則拆解的方法和抽取式MRC方法進行精拆處理得到答案。抽取式MRC是指機器通過閱讀問題和文章后,從原文中抽取一段連續文本作為答案[21,22]。
2.2.2 ?后處理過程
知識抽取后處理過程指文本精拆處理后產生的答案經過Learning2Ask模型自動生成問題、PR模型篇章排序過濾后形成FAQ并存儲至語料/知識存儲模塊,如圖3所示。根據機器自動提問流程不同,后處理過程也可以分為2種方案:
方案1(串行):精拆后生成的答案和對應的段落<段落,答案>,輸入至Learning2Ask模型中自動生成問題,再將<問題,段落>輸入至PR模型中進行過濾,置信度高的<問題,答案,段落>將以三元組形式作為知識存儲起來,置信度低的<問題,答案,段落>將提取出來作為數據集,對PR模型進行增強訓練。
方案2(串行+MRC校驗回路):與方案1不同的是,將<段落,答案1>輸入至Learning2Ask模型生成問題后,再將問題輸入至MRC模型進行預測生成答案2,并對答案1、答案2進行一致性檢查,只有通過一致性檢查的<問題,答案,段落>才能進入PR模型過濾過程,未通過一致性檢查的<問題,答案,段落>提取出來作為數據集,對MRC模型進行增強訓練。
2.3 ?發電設備知識問答
用戶在知識庫前端問答模塊輸入問題后,知識庫系統針對問題進行分詞、擴詞等過程提取問題特征,并輸入到知識問答排序模塊中進行答案粗排序。利用ES關鍵詞檢索引擎從知識庫中選取候選FAQ集,通過用戶問題文本與候選FAQ集中的問題文本進行相似度匹配,如果相似度大于設定的閾值,則輸出相應FAQ中的答案文本封裝后返回用戶;如果相似度小于設定的閾值,則將用戶問題文本、候選FAQ集中的段落文本輸入到PR&MRC模型中進行預測,并將預測答案封裝后返回用戶,如圖4所示。用戶評估答案后進行點贊或點踩,系統收集用戶反饋信息后對PR&MRC模型進行增強訓練。知識庫系統問答效果示例如圖5所示。
3 ?不同知識抽取方案的知識問答效果對比
將某電廠80份發電設備相關技術文件利用設備知識庫系統進行知識拆解,并利用人工標注的方式從80份文件中提取3 000個問答對進行知識庫問答效果驗證,不同知識抽取方案的知識問答準確率如表1所示。
由圖6可以看出,4種不同知識抽取方案的知識問答Top1準確率到Top5準確率都有明顯的提升,方案1的Top5準確率達到76.7%,說明基于自然語言處理的發電設備知識庫系統具有較好的問答效果;由表1可得,針對知識問題Top1準確率和Top3準確率,前處理過程中增加MRC生成模型可以提升4.4%~5.8%,后處理過程中增加MRC校驗回路可以提升2.3%~3.7%,說明在前處理過程中增加MRC生成模型相對于后處理過程增加MRC校驗回路提升問答準確率效果更加明顯;但從圖6可以看出,方案3在Top1和Top3的準確率雖然高于方案2,但方案2的Top5準確率提升較大,并且超過方案3的Top5準確率,說明后處理過程中增加MRC校驗回路在對答案排名要求較低的場景應用效果較前處理過程中增加MRC生成模型的效果更好;知識問答準確率最高的是方案4,可見同時在前處理過程中增加MRC生成模型和在后處理過程中增加MRC校驗回路,將顯著提升設備知識庫的問答準確率。
圖6 不同知識抽取過程的知識問答效果對比圖
4 ?結 ?論
為提升文本知識的查詢效率,文章提出一種基于自然語言處理的發電設備知識庫系統,包括知識抽取、語料/知識存儲、知識問答排序和知識庫前端問答等4個模塊。利用發電設備領域語料訓練得出的StructBert、Learning2Ask、PR&MRC模型能有效實現發電設備知識抽取,完成設備知識庫構建。
4種不同知識抽取方案中,知識問答的Top5準確率最低達到78.1%,說明知識庫系統具有較好的問答效果;針對知識問題Top1準確率和Top3準確率,在前處理過程中增加MRC生成模型相對于后處理過程增加MRC校驗回路提升問答準確率效果更加明顯;而后處理過程中增加MRC校驗回路在對答案排名要求較低的場景應用效果較前處理過程中增加MRC生成模型的效果更好;同時在前處理過程中增加MRC生成模型和在后處理過程中增加MRC校驗回路,將顯著提升設備知識庫的問答準確率。
參考文獻:
[1] 李廣偉,王永.火力發電機組日常性能檢測的流程及結論規范化研究 [J].鍋爐制造,2020(3):21-23.
[2] 劉青,車鵬程.某電廠2#爐高再異種鋼焊口裂紋原因分析報告 [J].鍋爐制造,2019(4):47-49+52.
[3] 任紀兵.基于.NET的興隆電廠檔案管理系統設計與實現 [D].成都:電子科技大學,2016.
[4] 劉欣,李怡.文檔管理在發電廠信息化管理中的應用 [J].信息技術與信息化,2016(10):36-38.
[5] 李佳,楊婷婷,劉偉.數字多媒體旅游咨詢信息智能問答系統設計 [J].現代電子技術,2017,40(12):66-68+71.
[6] 湯偉,楊鋮.智能檢索技術在電網調度本體知識庫中的應用 [J].自動化與儀器儀表,2019(2):193-196.
[7] 佟佳弘,武志剛,管霖,等.電力調度文本的自然語言理解與解析技術及應用 [J].電網技術,2020,44(11):4148-4156.
[8] 陸婕,李少波.基于知識庫的智能客服機器人問答系統設計 [J].計算機科學與應用,2019,9(11):7.
[9] 管棋,蔡榮杰,楊小燕,等.智能問答系統在乳腺疾病影像領域的研究與應用 [J].實用放射學雜志,2019,35(7):1159-1163.
[10] 張琳,胡杰.FAQ問答系統句子相似度計算 [J].鄭州大學學報(理學版),2010,42(1):57-61.
[11] 梁敬東,崔丙劍,姜海燕,等.基于word2vec和LSTM的句子相似度計算及其在水稻FAQ問答系統中的應用 [J].南京農業大學學報,2018,41(5):946-953.
[12] 周映,韓曉霞.ElasticSearch在電子商務系統中的應用實例 [J].信息技術與標準化,2015(5):72-74.
[13] 張建中,黃艷飛,熊擁軍.基于ElasticSearch的數字圖書館檢索系統 [J].計算機與現代化,2015(6):69-73.
[14] 王宇,王芳.基于HNC句類的社區問答系統問句檢索模型構建 [J].計算機應用研究,2020,37(6):1769-1773.
[15] DEVLIN J,CHANG M W,LEE K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding [C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,Volume 1(Long and Short Papers).Minneapolis:Association for Computational Linguistics,2019:4171-4186.
[16] WANG W,BI B,YAN M,et al. StructBERT:Incorporating Language Structures into Pre-training for Deep Language Understanding [J/OL].arXiv:1908.04577v3 [cs.CL].(2019-08-13).https://arxiv.org/abs/1908.04577v3.
[17] DU X Y,SHAO J R,CARDIE C. Learning to Ask:Neural Question Generation for Reading Comprehension [C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).Vancover:Association for Computational Linguistics,2017:1342-1352.
[18] 龐博,劉遠超.融合pointwise及深度學習方法的篇章排序 [J].山東大學學報(理學版),2018,53(3):30-35.
[19] 顧迎捷,桂小林,李德福,等.基于神經網絡的機器閱讀理解綜述 [J].軟件學報,2020,31(7):2095-2126.
[20] 張超然,裘杭萍,孫毅,等.基于預訓練模型的機器閱讀理解研究綜述 [J].計算機工程與應用,2020,56(11):17-25.
[21] 曾俊.抽取式中文機器閱讀理解研究 [D].武漢:華中師范大學,2020.
[22] WANG Z,LIU J C,XIAO X Y,et al. Joint Training of Candidate Extraction and Answer Selection for Reading Comprehension [C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers).Melbourne:Association for Computational Linguistics,2018:1715-1724.
作者簡介:沈銘科(1991.11—),男,漢族,浙江麗水人,中級工程師,碩士,研究方向:智慧電站技術研究。
