基于特征選擇及機器學習的犯罪預測方法綜述
2021-10-21 05:11:08張天祎冉義兵
科學技術與工程 2021年28期
魏 東, 張天祎*, 冉義兵
(1.北京建筑大學電氣與信息工程學院, 北京 100044; 2.北京市科學技術委員會建筑大數據智能處理方法研究北京市重點實驗室, 北京 100044)
隨著經濟改革的日趨深入,各類犯罪數量居高不下,犯罪手段與規模也在迅速發展。各類案事件犯罪(如網絡犯罪、吸毒販毒、搶劫盜竊、沖突糾紛、電信詐騙等)整體呈現出“高發低破”的態勢[1]。例如,近幾年犯罪量呈小幅下降趨勢的毒品犯罪案引發的社會問題仍不可小覷。據中華人民共和國最高人民法院發布的2020年司法數據顯示,2020年中國共破獲毒品犯罪案件量高達6萬余起,繳獲毒品量超過55 t,捕獲犯罪嫌疑人9萬余名,相較于2019年分別下降了22.9%、14.8%和18.6%,但毒品犯罪勢態仍較為泛濫。與此同時,犯罪類型結構隨著時代革新也在逐漸發生變化。目前以互聯網、電信等為媒介的非接觸性犯罪正逐漸增多,傳統犯罪加速向網絡空間蔓延。據統計,2020年中國檢察機關起訴涉嫌網絡犯罪14.2萬人,同比上升47.9%[2]。網絡犯罪案件作案手段多樣,犯罪形式隱蔽,特別是利用網絡實施的詐騙和賭博犯罪持續高發,據司法數據顯示,30%以上的網絡犯罪案件涉及詐騙罪及非法買賣、盜竊、販毒等多類案件,使犯罪防控工作面臨著新的挑戰[3]。
“日常活動理論”是古典犯罪學中的一種理論[4],該理論將引致犯罪的要素歸為三項:具有犯罪動機的人、適合的目標及犯罪監管力的缺乏,當同時滿足這三要素時,將造成犯罪發生在特定區域的概率增加。為解決犯罪和恐怖活動防控問題,中外多個研究機構正在開展犯罪行為預測方面的研究,從而構建犯罪預測模型。犯罪預測模型是在建立犯罪歷史數據間關聯性的基礎上,充分汲取罪犯及受害人提供的信息[5],實時采集和分析視頻監控[6]、通信、網絡等各類數據,通過數據處理和機器學習等算法將犯罪從發生到發展的全過程進行還原復現,從而達到全面反應犯罪趨勢的效果。因此,犯罪預測模型具有巨大的應用價值和研究價值。
為此,主要回顧了目前中外犯罪案事件建模和預測領域的研究成果,在全面綜述案事件預測系統領域的最新研究成果的基礎上,歸納整理了預測各類案件所選取的特征屬性,分類分析了不同特征適用的建模方法,并對比了其預測性能的優劣勢,通過系統論述現有研究成果中對犯罪信息的利用及處理方法方面存在的理論與技術挑戰,對未來研究方向進行了展望。
1 犯罪預測方法綜述
犯罪預測可根據警方的不同需求分為宏觀預測和微觀預測兩類。宏觀預測主要為公安機關制定各類政策以及統籌規劃服務,而微觀預測則通過案事件預測的手段,為特定時間和特定地點內的警力資源分配調控,以及為決策人員提供數據支持服務[7]。案事件預測方法主要分為兩大類:一類是傳統分析方法,指的是將犯罪數據按照嫌疑人特征、時間特征、犯罪地點特征等進行數量統計比較,并結合犯罪學理論相關方法進行分析和預測。傳統分析方法多采用關聯規則挖掘算法實現,通過支持度和置信度進行規則的篩選[8];另一類是經驗模型法,指的是基于機器學習的方法,訓練模型模仿人類決策策略進行預測,通過分析時間、位置、車輛、地址、物理特征和財產等因素,基于決策樹[9]、神經網絡[10]、支持向量機[11-12],以及針對犯罪預測研究的自適應調整[13]等算法進行建模,并實現線下犯罪預測;此外,對于線上犯罪,犯罪關聯[14]、聚類[15]和用于研究網絡平臺犯罪文本信息的非結構化數據情緒分析[16]等算法能夠進行網絡犯罪行為預測,并揭示利用互聯網傳播非法信息或惡意代碼的網絡罪犯身份。
1.1 傳統分析法
傳統分析法在判斷犯罪案情時,通常需要借助數據統計、統計比較、關聯規則分析等方法。傳統分析法在犯罪決策時所涉及的犯罪學和統計學方法如圖1所示。
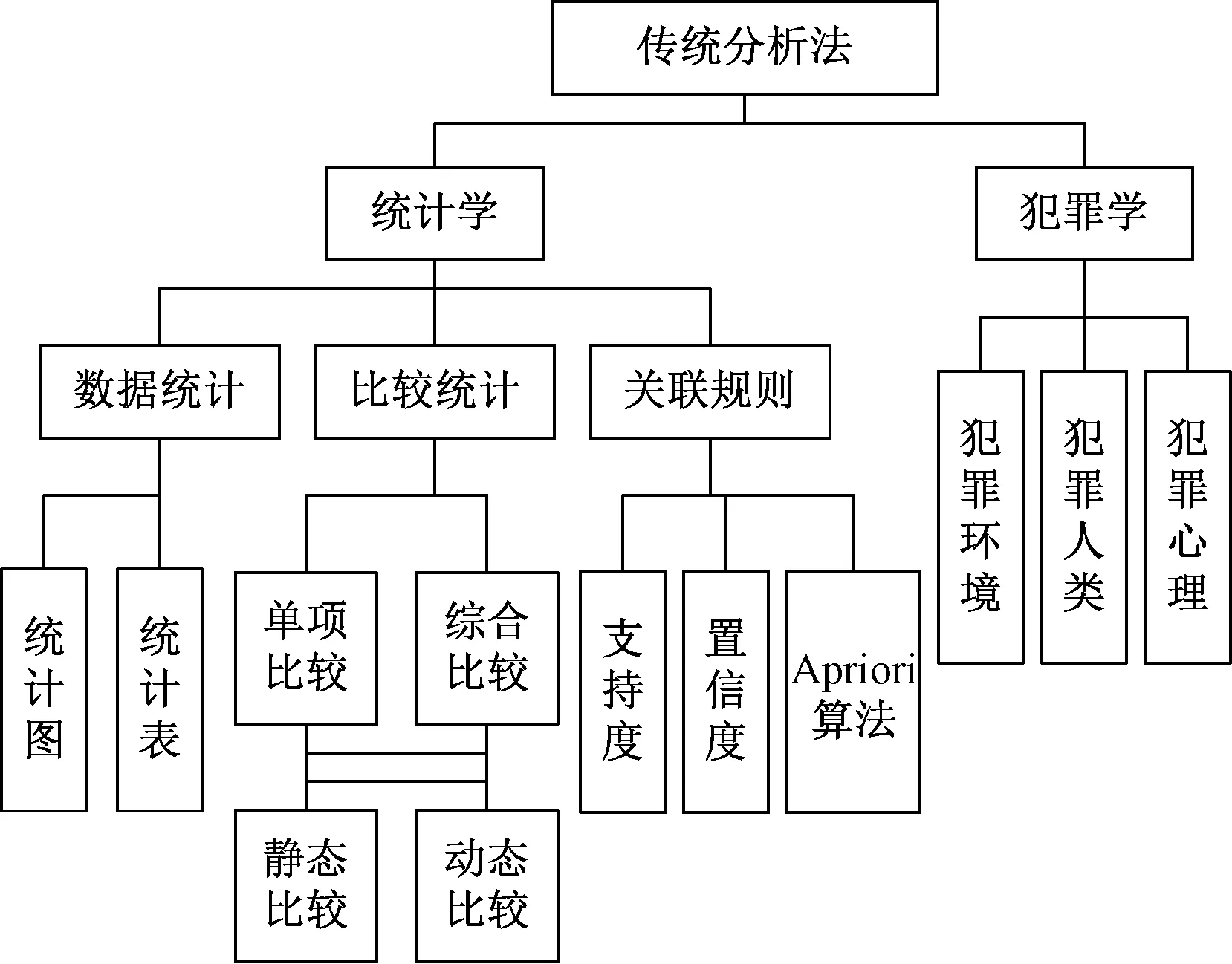
圖1 傳統分析法犯罪決策所涉及內容Fig.1 The contents involved in crime decision by traditional analysis method
但在實踐過程中發現,犯罪案件的形成往往受到各方面因素的共同作用,而傳統分析方法無法做到實時統籌分析各類影響因素對犯罪的影響及其相互間的作用,從而影響預測效果。如海量實時更新的數據無法做到即時采集及歸納整合、預測對象不可控、無法準確預測犯罪等[17]。因此,在大數據時代傳統分析法不適合廣泛使用,需要借助經驗分析法進行改進更新[18]。
1.2 經驗分析法
經驗分析法,是以偵查人員的經驗知識為基礎,以機器學習算法為手段,建立犯罪預測系統[19],其核心是在建立犯罪數據間關聯性的基礎上進行數據信息的預測[20]。經驗分析法能夠評估復雜的異質數據,通過逐步將一線執法人員的經驗和犯罪學理論轉化為機器可處理的特征,能夠更有效地利用專家經驗,從而提高預測準確性[21]。
如圖2所示,經驗分析法的研究方向主要分為兩類,即經驗模型和時空模型,前者側重于對犯罪特征及相關屬性進行研究,后者則重點分析連鎖犯罪案發地點及整個時間軸之間的聯系。
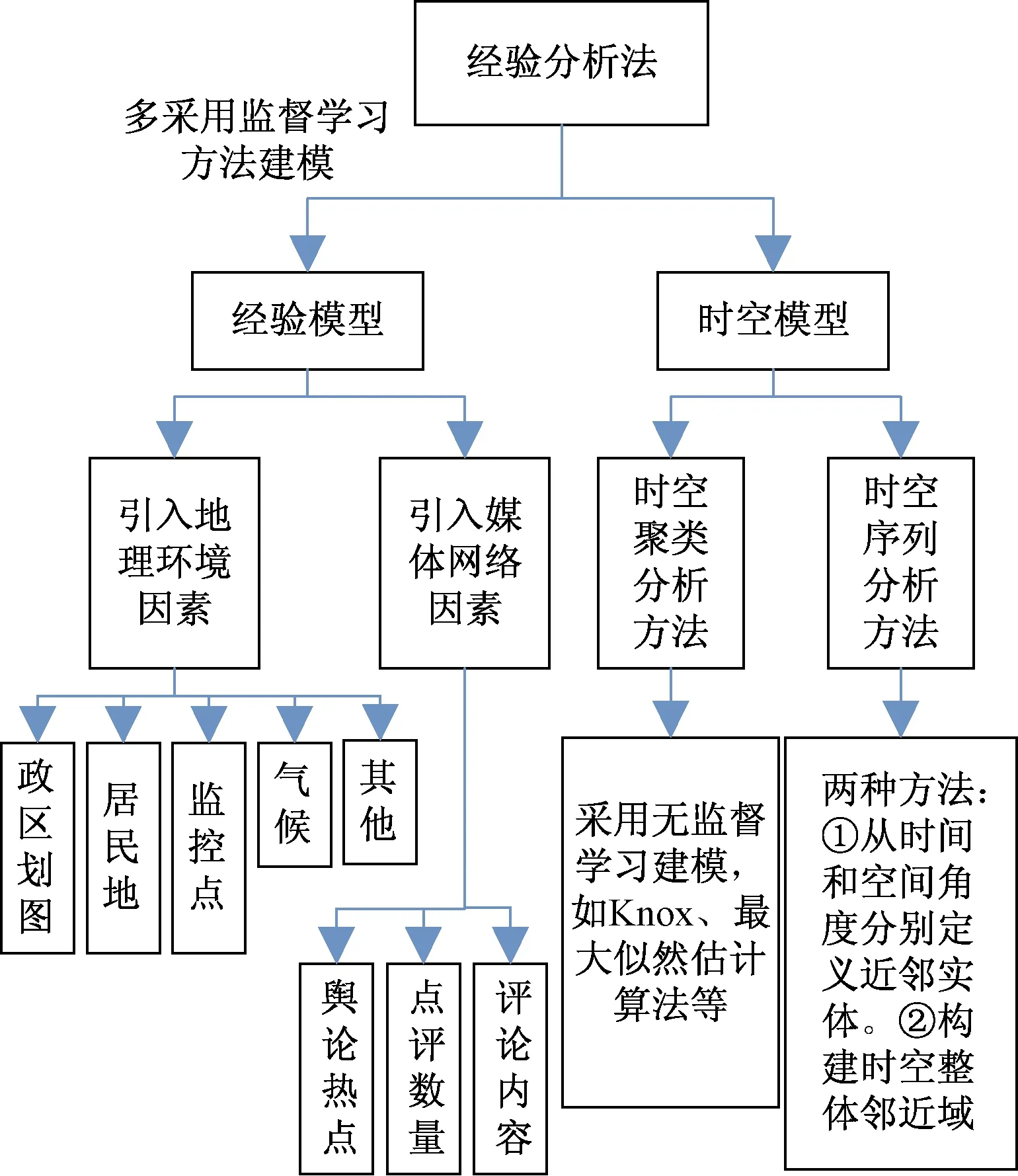
圖2 經驗分析法分類Fig.2 Empirical analysis classification
2 模型特征選擇
犯罪預測系統可對所收集到的數據進行研判,如表1[22-29]所示,并預測出犯罪熱點地區,從而能夠指導公安機關分配更多的警力資源來應對該地區潛在犯罪高發的風險。
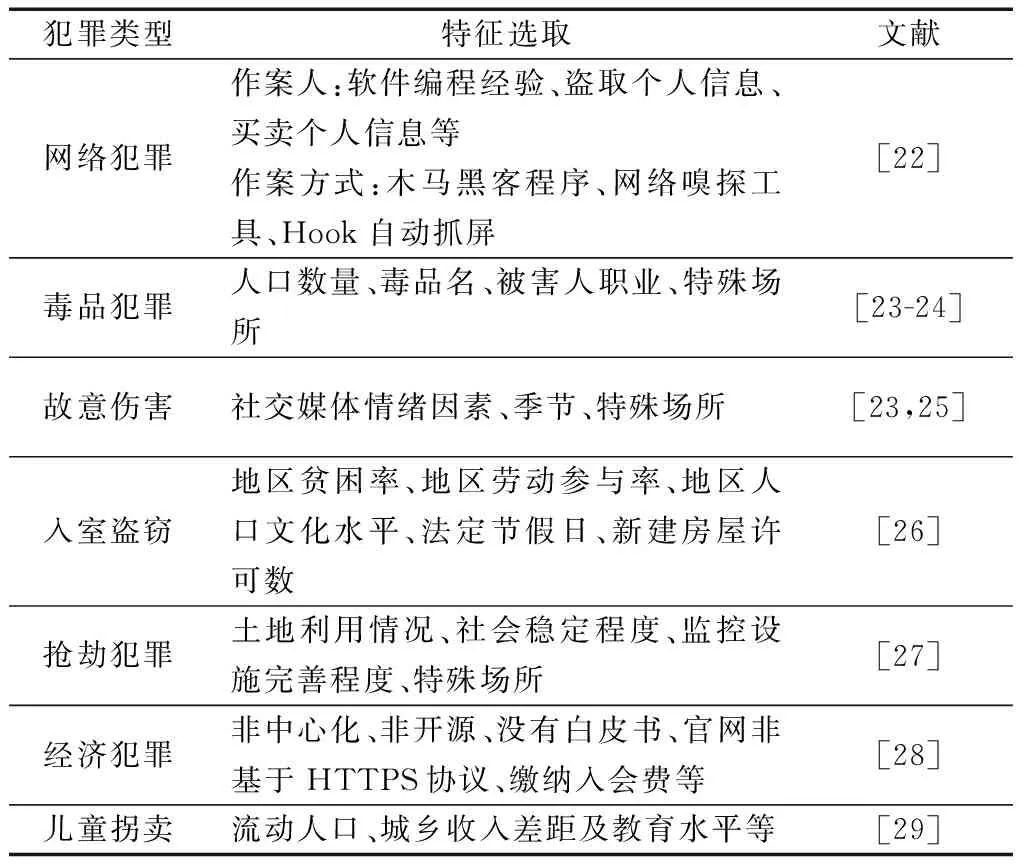
表1 常用犯罪特征選取[22-29]Table1 Selection of common criminal characteristics[22-29]
隨著預測系統在公安日常工作中的快速普及,犯罪預測建模已然是近幾年的研究熱點。指揮官利用時間、地形、氣候及周圍環境因素對犯罪發生的可能性進行預測,并將警務預測分析與實踐進行有機結合至關重要。Anneleen等[30]證明了兩周一次與每月一次的晝夜預測差異對最終的預測性能有決定性的影響。因此,模型需要根據應用背景的具體情況來調整特定的方法。
3 經驗模型研究分析
對于經驗模型而言,在利用基本犯罪特征(如作案人特征、人口屬性及社會條件等)的前提下,將其按照引入新特征的不同分為融合基本地理特征模型[31]和媒體網絡信息模型[32]兩大類。研究人員多采用有監督學習方法建立此類模型,有監督學習在訓練集中識別事物并尋找規律后,為測試樣本中的數據加標簽并使用所得規律進行識別[33]。經驗模型即利用現有的經驗知識來識別犯罪事件,無需利用模型尋找數據集中的規律性,因此使用有監督學習便可達到預測目的[34]。
3.1 融合地理特征的預測模型
犯罪場所論與邊界帶理論認為,作案人思維中由住所位置、工作(或學校)地點和商業購物消費圈構成的三角區域的犯罪地圖,是其選擇作案場所的重要依據[35]。基于地理特征的方法專注于作案地點周圍環境以及氣候等環境因素,對案件發生的概率進行預測[36]。現有基于地理特征分析預測犯罪的模型,主要以警用地理信息系統(police geographic information system,PGIS)、犯罪地理目標模型(criminal geographic targeting,CGT)及其衍生模型為代表。
PGIS將空間關系納入犯罪預測時,現有成果往往利用PGIS,在建模時適用空間自相關方法進行犯罪數據的聚類和回歸分析,最終得出犯罪案件或犯罪主體及客體的分布聚集性熱點地帶[37]。然而,城市犯罪數據的非高斯分布和多重共線性特征,導致傳統PGIS處理后的犯罪信息覆蓋率及數據精度較低,為解決該問題Wang等[38]利用最小絕對收縮和選擇算子(least absolute shrinkage and selection operator,LASSO)模型量化特征參數對犯罪的影響。此外,為了服務于不同的警種任務,研究人員仍需在PGIS系統基礎上進行多功能開發。如連環犯罪事件,作案人會在重復性犯罪行為中顯露其思維定勢,產生犯罪行為的類似性[39],而傳統PGIS系統缺乏考慮其關聯性。
CGT是一種基于地理信息系統的時空分析方法,根據犯罪地點或其相關地點在時空分布上存在的規律,分析推斷出最有可能發生下次犯罪的位置。方嘉良等[14]利用此模型預測連環案件嫌疑人落腳點,并在此基礎上采用分段距離遞減函數模擬罪犯行為路徑,在此基礎上采用灰色關聯分析方法[40]對犯罪系統發展事態進行定量描述。李新光[10]以CGT為基礎,結合模糊反向傳播(back pro-pagation,BP)神經網絡和元啟發式算法,將作案環境分為3個模糊集,將搜索區域面積增加到優化前的3倍的同時命中率提高了至少6%以上。
而天氣因素作為基本地理因素常被研究人員所忽略。研究發現暴力犯罪的發生概率與氣溫呈正線性關系,從而證明了天氣因素,尤其是溫度特征,是導致罪犯產生犯罪行為的重要影響因素之一[41]。從歷史犯罪數據分布來看,某些時間節點會導致犯罪數量趨勢出現或大或小的波動。Sherry等[42]采用自助抽樣法調用線性回歸,并利用Box-Cox變換對異方差進行校正,分析日常犯罪數據發生率,研究結果證實,引入天氣屬性可以提高模型短期預測能力,并指出各類犯罪率均依賴于一年之中的特殊時間點,如節假日和工作日。
3.2 融合社交網絡信息的控制模型
隨著社交網絡用戶數量的快速增長,數據平臺中積累了廣泛的信息資源,這些數據隱藏的信息可能會促使犯罪的生成,或暴露犯罪意圖及動機[43-44]。對于犯罪預測而言,研究人員能夠通過不同的社交平臺獲取特定公共群體的數據來提高模型的預測能力。用于犯罪預測的社交媒體數據主要從Twitter平臺數據集中獲取,公開的人群數據可以指導預測犯罪率的變化趨勢。利用Twitter推文預測犯罪事件的流程如圖3[16]所示。
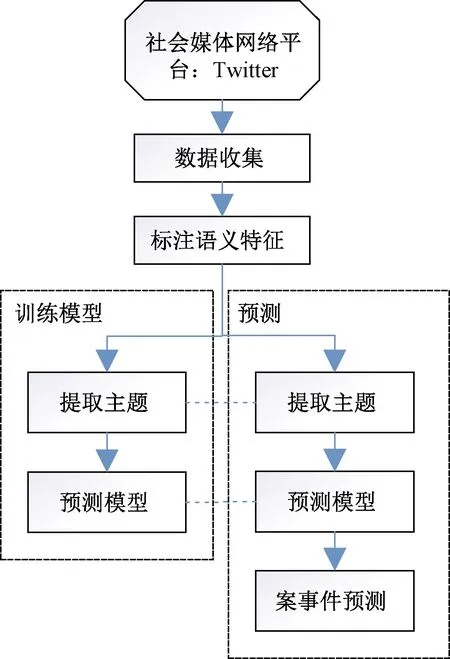
圖3 利用Twitter預測犯罪事件的流程[16]Fig.3 The process of using Twitter to predict criminal events[16]
Twitter數據中的文本內容可以顯露出發言人積極與消極程度,從而探索犯罪趨勢。因此,Johan等[45]基于Twitter上每日訂閱的文本內容,采用OpinionFinder測量積極和消極情緒的程度,然后利用格蘭杰因果關系分析情緒狀態對犯罪行為的影響,并采用自組織模糊神經網絡方法建立模型,使得犯罪系統預測準確率高達86.7%,證實了情緒可以深刻地影響一個人的行為和決策。同樣,Chen等[46]利用文本分析方法研究犯罪預測,選擇結合歷史犯罪記錄進行核密度估計(kernel density estimation, KDE),并通過邏輯回歸模型得出較熱天氣環境下,消極的評論文字容易引發暴躁情緒,導致暴力犯罪發生較為頻繁。Wang等[16]考慮到圍繞網絡社交媒體環境中的興趣點,使用語義角色標注(semantic role labeling, SRL)的自然語言處理技術(natural language processing, NLP),對Twitter中的推文內容進行自動分析理解,結合隱狄利克雷分配模型(latent dirichlet allocation, LDA)識別、提取事件中的突出主題,并在該主題上建立線性回歸模型,研究人員通過搜索與正面意見和負面意見高度相關的話題,能夠檢測出與情緒極性相關的犯罪活動。網絡信息數據中描述了犯罪事件的細節,Das等[47]開發了一種增量式監督學習技術,動態地進行在線分類和統計分析,幫助執法機構在實際工作中針對不同案件類型制定犯罪預防戰略。
4 時空模型研究分析
4.1 時空模型概述
犯罪模式理論認為,犯罪者通常選擇他們自己最熟悉的地域,作為自己犯罪活動空間的一部分,而不是冒險進入未知的領域,并且,往往犯罪發生的時間和空間存在緊密聯系[48],這就是犯罪所具有的近似重復特性。為了獲得有效的犯罪預測模型,并對每一種數據特征進行分析,研究人員引入深度學習方法利用多個計算模型對這些種類繁多的數據進行處理,對于彼此之間存在關系的數據,生成更高層次的知識表示模型[49]。以犯罪學為基礎的時空特征如表2[50]所示。

表2 以犯罪學為基礎的時空特征[50]Table 2 A spatio-temporal feature based on criminology[50]
此外,在犯罪學研究中明確提到[51],犯罪不應該被認作隨機事件,其發生會受到一些周期性因素的影響,從而使犯罪具有周期性。犯罪時空模型在學習分析離散案件點的各類因子間隔長度的基礎上,深入探究案件點間內部時空自相關性,進而優化基礎模型缺乏分析犯罪近似重復屬性的不足。時空模型專注于對連環犯罪的整個案件鏈進行研究分析,以精準抓取鏈首案件,實現下一個犯罪案發生的時間地點預測,從而可幫助公安機關對應分配警力資源,達到高效防控的目的。
總體來說,從時空角度將犯罪預測模型進行分類,可分為四類:①單從時間或空間角度進行分析預測;②分別從時間和空間進行預測,并組合結果;③將事件和空間作為獨立變量共同作為輸入參數建立模型;④利用時空序列方法挖掘數據建立模型。第一種分類往往結合其他屬性進行建模(見第3節),②、③類通常采用聚類方法建立模型,而相較于前3種,④類則利用時空序列模型更好地顧及了時空自相關性和時空異質性(見4.2節)。
4.2 時空聚類分析方法
4.2.1 時空聚類分析方法原理
時空聚類分析對于揭示犯罪的變化規律、發展趨勢及本質特征具有至關重要的意義[52],其旨是一個無監督分類的過程,其根據相似性準則將時空犯罪案事件劃分成一系列較為均勻的時空簇,如圖4[53]所示,同一簇內犯罪案事件的相似度要盡可能大于不同簇間的相似度,從而分析時空緯度中案件與案件間的相互作用,能夠準確識別犯罪時空近似重復模式[54],并確定出控制和預防犯罪發生的最佳點,能夠為公安機關警力部署工作提供有力依據。在研究自相關性顯著的連環犯罪案件類型時,該類模型性能表現突出。
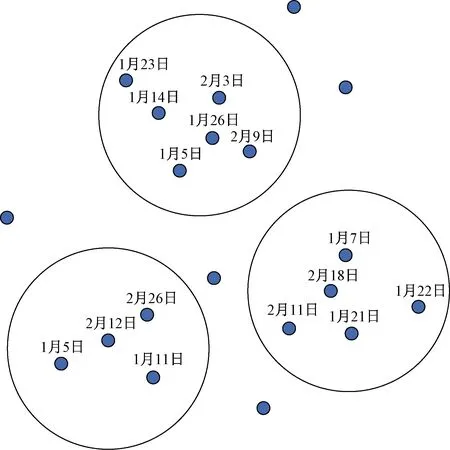
圖4 2016年犯罪時空簇示例[53]Fig.4 Examples of crime clusters in 2016[53]
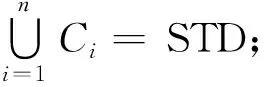
4.2.2 時空聚類分析方法的應用
對在數據預處理階段構建時空交互多維框架,是犯罪時空聚類分析的常用方法[55],將空間密度聚類在時空域上進行擴展,其采用密度作為犯罪案件間相似性的度量標準,將時空簇定義為一系列被低密度噪聲分割的高密度連通區域。隨著城市中兩個區域地理距離的增加,區域間在一定時間段內的犯罪差異有增大的趨勢,采用時空鄰近域估計時空犯罪案事件的密度。同時,框架中可以根據需求選擇不同的時間顆粒,如小時、日、周、月等。時空聚類框架工作流程如圖5[56]所示。
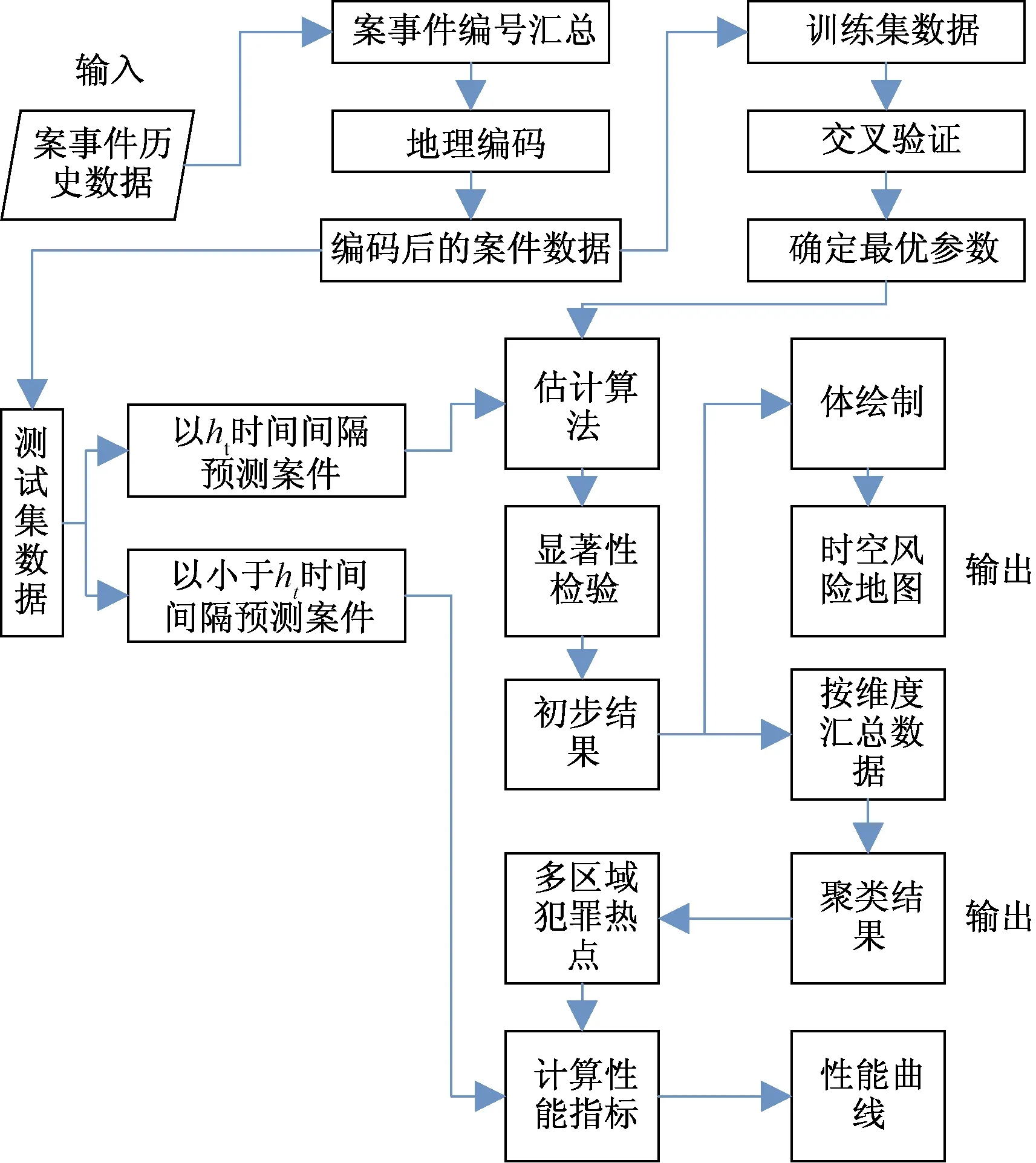
ht為基于不同時間顆粒單位下設定的時間間隔長度圖5 時空聚類框架的工作流程[56]Fig.5 The workflow of the spatio-temporal clustering framework[56]
針對不同警務應用,研究人員將預處理所得時空數據輸入到對應算法模型中。為研究犯罪地圖中各個位置上的熱點屬性,Pukhtoon等[39]按犯罪持續時間長短細分為長期熱點和動態熱點,結合長短期的核密度估計,發現了長期熱點是熱點地圖的主要組成部分。針對研究盜竊案時空熱點分布規律和形成問題,李欣竹等[8]將模擬退火的遺傳算法引入到犯罪時空框架中,并通過交叉變異的方法篩選出案發時空分布密集性較高的區域,最后采用時空熱點矩陣法對分布成因進行了關聯規則的結果分析。Chandra等[57]利用動態時間規整(dynamic time warping, DTW)和Minkowski參數模型的方法,在不同犯罪地點的不同犯罪序列中尋找相似的犯罪趨勢,并將這些信息用于預測未來犯罪趨勢。在此基礎上,Li等[58]證明了DTW用于度量連環案件特征相似性的優勢,并結合信息熵方法精確識別相似的犯罪行動及犯罪對象特征,從而獲取全面的作案過程相似性特征。
4.3 時空序列分析方法
4.3.1 時空序列分析方法原理
西方環境犯罪學中“二八定律(80/20 Rule)”指出,將近80%的犯罪通常發生在很小的一塊地區或時間段內,且僅與20%的作案者或案件相關[59],這說明犯罪熱點分布及形成存在規律性和關聯性,該研究基于犯罪熱點形成特點及時空序列規律,得到完整的犯罪鏈預測模型。公安機關根據時空序列規律,在犯罪將要發生的區域,加強巡邏工作,重點部署警力資源,達到精準防控犯罪的目的。
當定量的時間序列在空間上存在相互影響時[60-61],表明這些時間序列具有時空依賴性,便可稱為時空序列[30],時空序列混合預測建模過程如圖6所示。
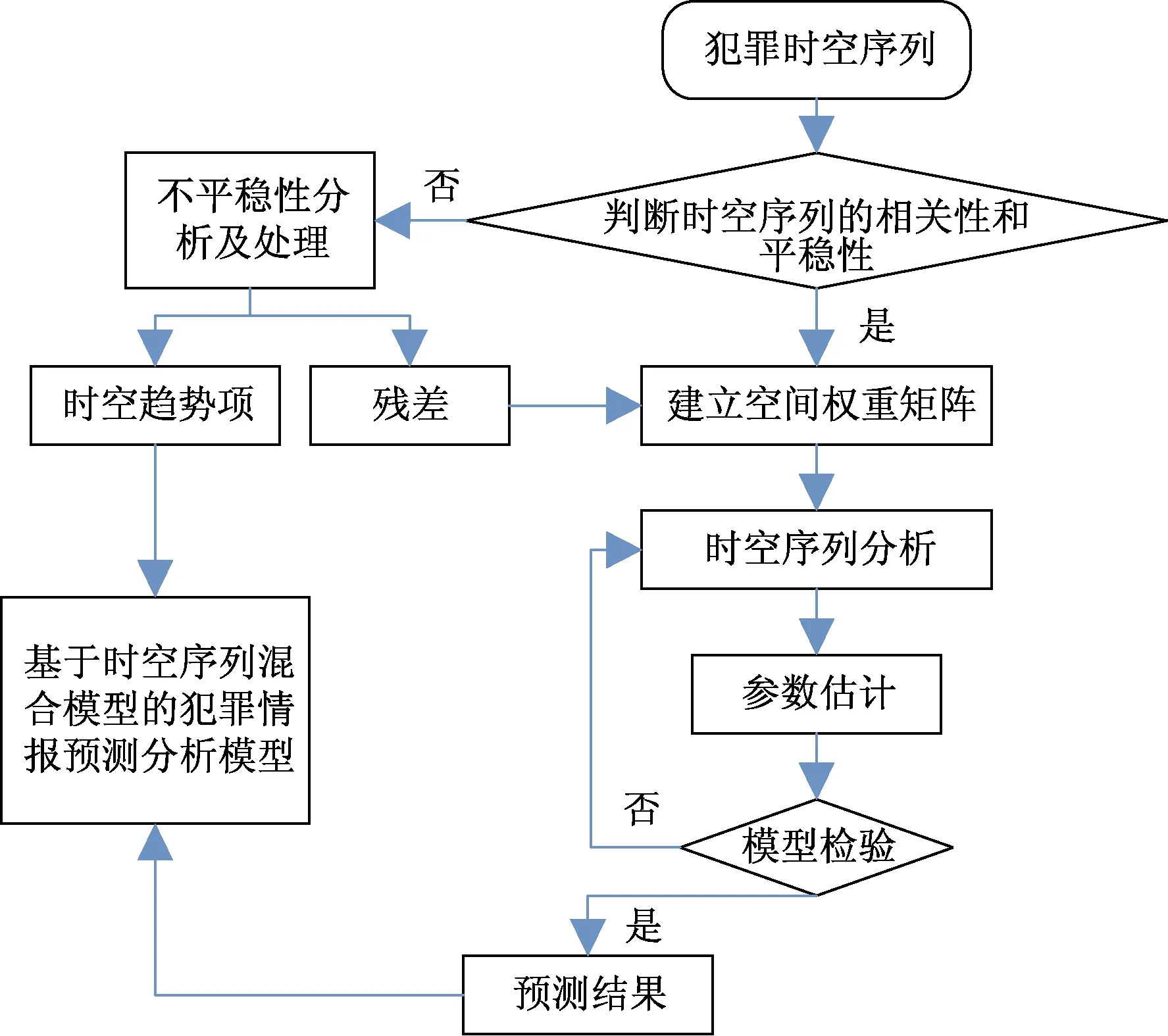
圖6 時空序列混合模型的建模流程圖Fig.6 Modeling flow chart of spatio-temporal sequence hybrid model
通常犯罪歷史數據中都有犯罪時間點及地點的記錄,所以可以用時空序列的方法進行分析,避免單獨分析時間特征和空間特征后再進行結果的組合而帶來的在時空域中結果不適用的可能性[62]。犯罪案事件除了自相關性外,還具有時空異質性和時空尺度依賴特性。其中,時空異質性表示犯罪時空變量的統計特征隨時間和空間的演變而變化的;而時空尺度特性表示犯罪時空數據在不同的時空粒度上所遵循的規律及表征不盡相同,利用上述特性探尋犯罪規律。在時空序列方法建模過程中,時空數據在大尺度上表現出犯罪區域性的總變化,受系統性的大范圍因素影響;而在小尺度上,受局部變異的隨機因素影響,可以捕捉到犯罪細節信息;同時兼顧犯罪時空數據在這兩種尺度上的變化特征,全面地綜合時空維度中數據局部和整體兩個層次的特征漸變規律[63]。
犯罪時空序列在兩類空間尺度下可表示為
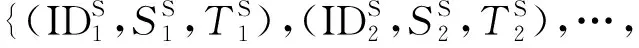
(1)
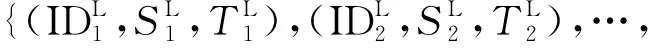
(2)
4.3.2 時空序列分析方法的應用
現有的犯罪時空序列預測建模方法大多是在傳統時間建模的基礎上,結合犯罪數據的時空典型的時空序列分析方法有時空自相關移動平均模型、長短期記憶網絡(long short-term memory, LSTM)及其衍生方法。
時間循環神經網絡LSTM模型常用于城市網格化管理預測案件數量,對此陳欒杰等[22]分別采用Box-Jenkins、Auto-ARIMA和LSTM 3種模型進行實驗對比,發現LSTM模型預測精度較為平穩,可調節參數多利于優化。LSTM模型能夠較好地預測日盜竊犯罪數量的變化趨勢,但其對數量波動較大時段的預測效果不佳[64]。因此,黃娜等[65]提出了一種基于改進LSTM的犯罪態勢預測模型,在預測過程中利用實際數據自動修正網絡,與依賴先前時間步長的預測值進行滾動預測方法相比,預測結果的均方根誤差平均值降低了57.33。
時空自相關移動平均模型是一個線性模型,劉美霖等[66]針對其只能對平穩的時空序列進行建模的不足,從算法結構入手,結合神經網絡預測犯罪變化趨勢,該混合模型處理了傳統STARMA模型數據的不平穩性[67],添加了非線性功能,從而提高了模型擬合的精準性,并且預測時間單位可根據實際需求及時進行調整[68-69]。從優化線性函數角度入手,王尚北等[70]基于樣本數據驅動的空間權重矩陣建立方法,將建立空間權重矩陣轉換為求解位置系數方程,以非線性函數代替線性組合,從而彌補了時空自相關移動平均模型的不足之處。劉宵婧等[71]將地理加權回歸(geographically weighted regression, GWR)和時空自相關移動平均模型結合,綜合考慮訪問時空分異特征對地區檢測點相應時間的影響,并描述其時空趨勢。
5 展望
現階段,研究人員致力于通過機器學習算法建立預測模型,如表3所示,分析大量與案件有關的數據,預測下一次犯罪或犯罪活動將在何處發生,這些研究主要集中在兩個方面:利用歷史數據判斷案件的因果關系并結合決策人員經驗建模(即經驗模型),以及基于時間空間的發展變化規律建模(即時空模型)。警務預測模型在實際應用時,可以根據不同的側重方向從多個視角對犯罪行為進行多維度的預測,使犯罪預測系統達到靈活應用的目的,從而有針對性地指導警務工作。
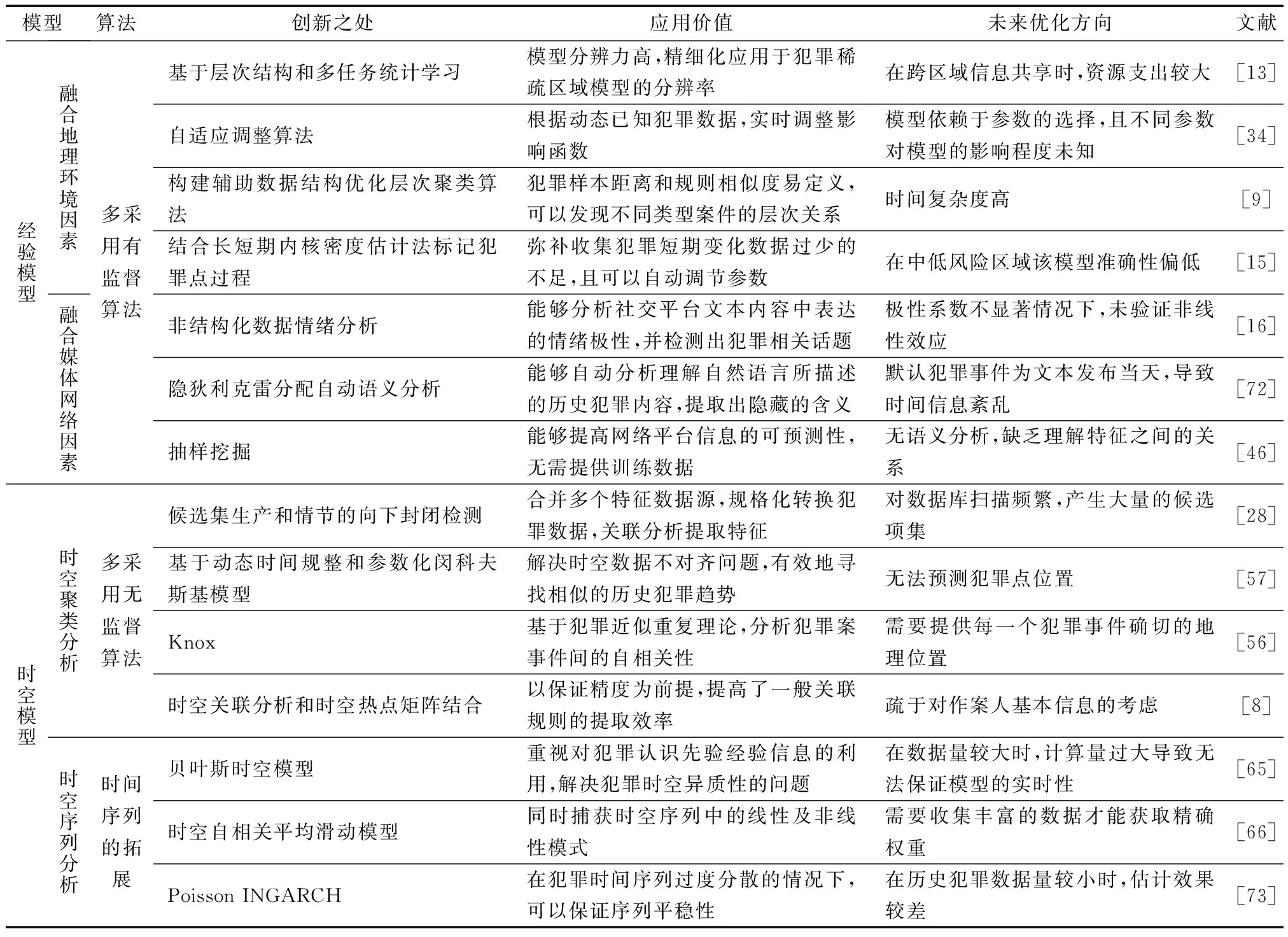
表3 建模方法對比及未來優化方向Table 3 Modeling method comparison and future optimization direction
在大數據背景下,數據的范圍不僅在橫向上聚攏,也在縱向上逐漸深化,執法機構利用數據分析和建模技術來預防及應對犯罪比以往任何時候都重要。由于網絡電信犯罪擁有隱蔽性和智能性的優勢變得日益猖獗,對該類犯罪行為進行預測將是未來的重要研究方向。同時,目前國際形勢復雜,有組織的暴力和恐怖主義有抬頭的趨勢,研究人員應利用移動設備和定位技術收集現代城市數據,精準預測犯罪軌跡,為犯罪分析研究提供新視角。
6 結論
當前的中外研究還存在一些共性問題,主要體現在以下幾點。
(1)對于低人口密度地區的犯罪預測模型,研究人員普遍采用超集成算法進行建模,決策規則依賴于數據驅動,而缺乏理論解釋性,因此不適用于測試個體特征對預測性能的影響。在未來研究無監督學習的領域中,可以進一步探索高度不平衡分類的其他方法,如奇異值探測和離群點檢測,此類方法不受離群值的影響,在觀測中檢測異常是研究的重點。
(2)對于研究樣本數量級較小的犯罪類型,由于數據限制無法以年為單位進行時空分析,隨著時間的推移,犯罪趨勢變化小。例如仇恨犯罪,在未來的研究中可以額外考慮添加種族、經濟和社會變量來擴充樣本容量,使用離散全球網格系統(discrete global grid system, DGGS)將仇恨犯罪的點級數據引入數據框架中相關聯后采用空間回歸分析方法[74]。
(3)研究人員對網絡平臺數據的利用普遍拘泥于標記詞性和情緒主題建模方面,而缺少對網絡平臺數據文本內容的分析,在未來研究中,研究人員可以嘗試深度挖掘文本的語義進而提高預測模型的性能,例如,可通過分析推文的述詞論元結構來提取案件信息和案件參與者。未來可以將成熟的新聞分析程序應用于Twitter文本,研究Twitter內部的各種網絡結構(如follower-followee和@-mentions)[43]等。同時,該方法也可以應用于其他微博類網絡平臺,如新浪、騰訊、網易等。
(4)在犯罪相關性分析中,為保證分析的全面性,研究人員可能會選擇較多特征作為模型輸入,這會導致分析過程的難度和復雜性增加。由于犯罪概率與其影響因子間具有一定的相關系數,因此在未來的研究中,可以嘗試利用主成分分析法[75]在保證盡可能多的保留原始變量所反映的信息的前提下,用較少的新變量代替原變量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
光學精密工程(2016年6期)2016-11-07 09:07:19
