基于逐步判別分析的顏色讀數與物質質量濃度預測的研究
2021-10-26 12:12:52李興莉蔡紅梅
上海化工 2021年5期
李興莉 蔡紅梅
1 重慶建筑科技職業學院(重慶 401331)2 電子科技大學成都學院(四川成都 611731)
比色法是目前常用的一種檢測物質質量濃度的方法,常用的方法有2種:目視比色法和光電比色法。目視比色法是將試樣溶液滴在特定的試紙表面,等其充分反應以后生成一張顏色穩定的試紙,再將該顏色試紙與標準比色卡進行比較,目視找出色澤最相近的色階,從而確定待測物質的質量濃度檔位。每個人對顏色的敏感差異使得結果有偏差。雖然光電比色法消除了主觀誤差,但也有其缺點(只適用于可見光譜區及只能得到一定波長范圍的復合光),以致比色法后來逐漸被分光光度法所代替。
比色法的主要優點是設備簡單和操作簡便,如果能準確判斷顏色試紙與標準比色卡哪一類色階相同,則能提高比色法的準確性。隨著照相技術和顏色分辨率的提高,照片顏色讀數可靠性不斷提高,為比色法的改進提供了新的思路。本研究通過分析顏色讀數和物質質量濃度的關系建立模型,由顏色讀數通過模型準確判斷待測物質的質量濃度。采用逐步判別法建立二氧化硫溶液(二氧化硫與水制成的溶液)顏色讀數[B(Blue)=藍色顏色值、G(Green)=綠色顏色值、R(Red)=紅色顏色值、H(Hue)=色調、S(Saturation)=飽和度]與質量濃度(mg/L)的關系模型,由判別函數能準確判斷二氧化硫質量濃度。
1 逐步判別分析方法
判別分析建立的判別函數受變量的影響,變量過多會增加計算量,同時一些不重要的變量可能會干擾判別函數的建立,使得判別函數不能準確判別。另外,如果將一些重要的變量刪除,建立的判別函數也不能進行有效判別。逐步判別法可以解決變量選取問題,從而使得判別更加準確。逐步判別法采用有進有出的方法動態選取變量。
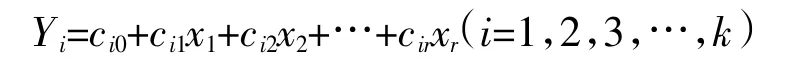
需要判斷一個樣品的質量濃度時,只需要將變量x1,x2,…,xr的數據代入判別函數,計算出每個判別函數值Y1,Y2,Y3,…,Yk,樣品質量濃度是最大函數值對應的數值。
2 逐步判別分析建立二氧化硫顏色讀數與質量濃度關系模型
將31 組訓練數據,包含5 個變量(B,G,R,H,S)的二氧化硫顏色讀數,以及分類變量二氧化硫質量濃度(0,20,30,50,80,100 和150 mg/L)導入SPSS軟件中,按照步驟分析(Analyze)→分類(Classify)→判別(Discriminate)選擇逐步進入方式,可以得到分類結果。
2.1 逐步進入步驟分析
將F進設為5,F出設為3.5,得到變量逐步引入的各項數據、指標(見表1),以及引入變量是否顯著,是否剔除的各項數據、指標(見表2)。
從表1 數據可以知道每次是否有變量被選入。第一次最大F值為5 323.871,對應變量G,且對應Wilks 的Lambda 值最小為0.001,所以變量G 首先被引入模型;第二次判斷變量H 的F值為56.120,是還未被引入變量中最大的,且Wilks 的Lambda 值小于0.001,所以變量H 第二個被引入模型;第三次判斷后被選入的是變量B;第四次判斷后被選入的變量是R;第五次判斷變量S 的F值小于F進=5,因此變量S 不被引入模型。
從表2 可知,每次變量被選入之后,判斷是否將其剔除時,計算出的F值都大于F出=3.5,所以這4個變量都不被剔除。最終得到的判別函數中包含R,G,B,H4 個變量,對應判別函數中的x1,x2,x3,x4。
2.2 判別函數
由上述步驟分析得到Fisher 的線性判別式函數見表3。
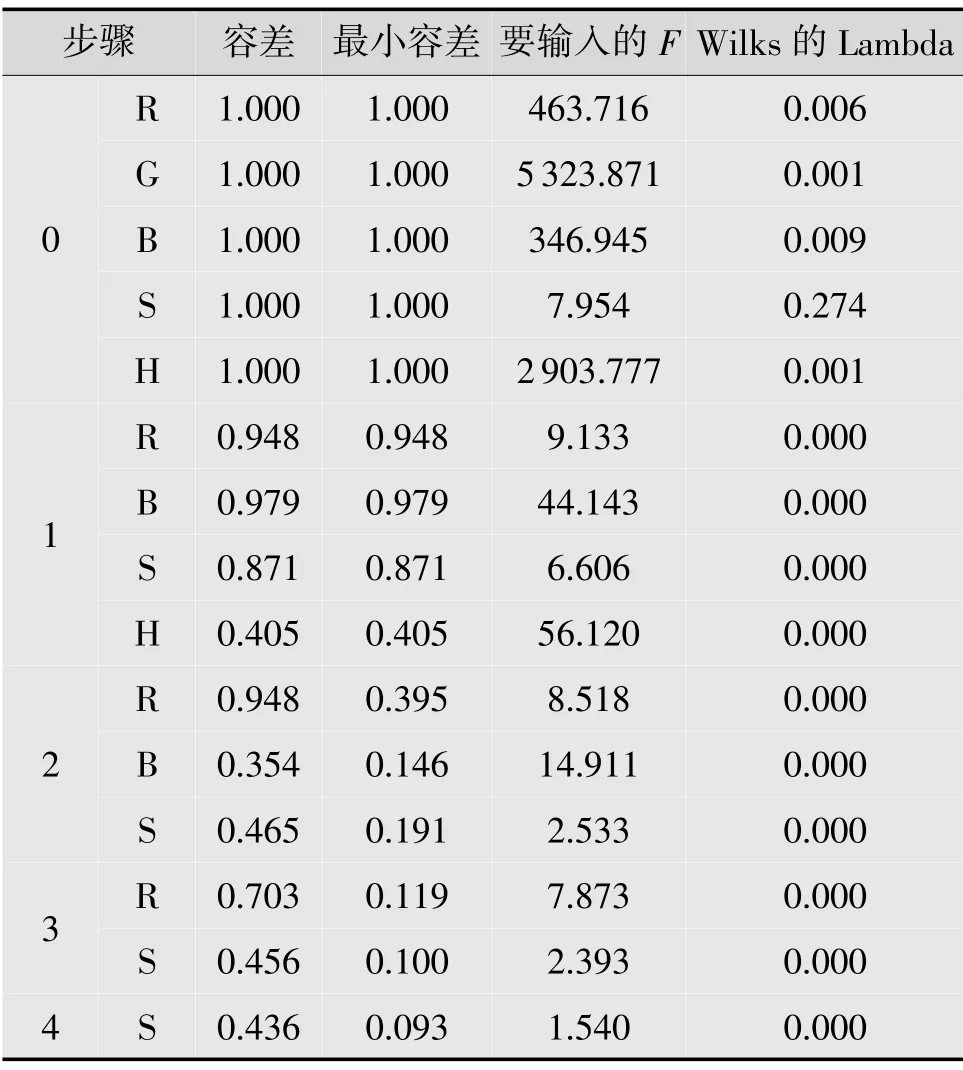
表1 不在分析中的變量
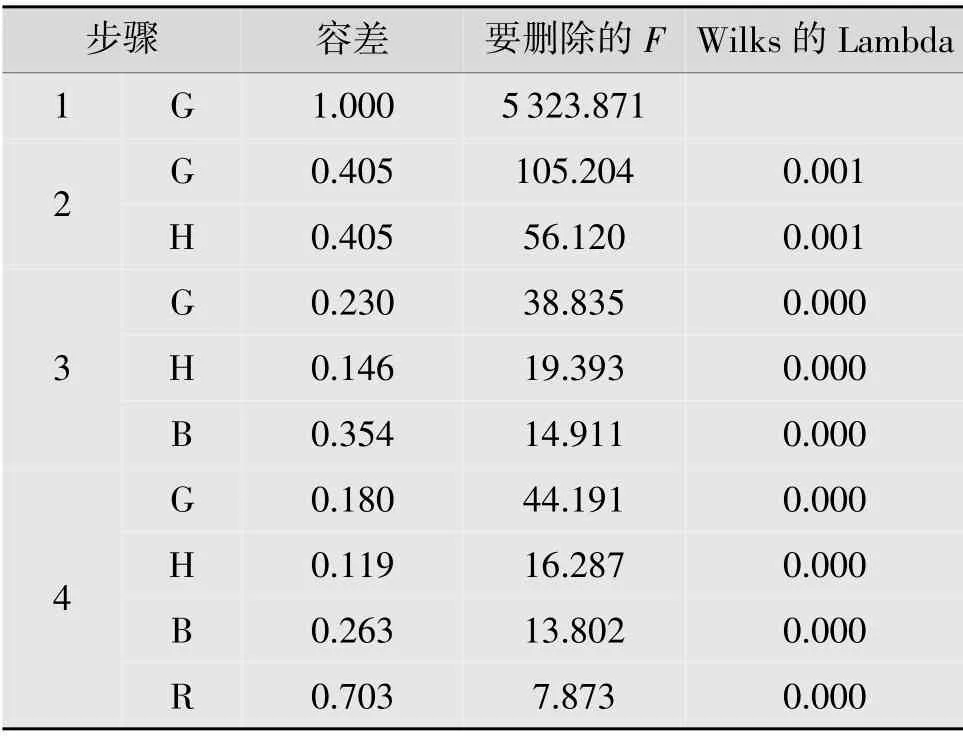
表2 分析中的變量
從分類函數系數可以得到判別函數:
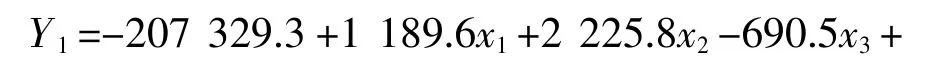
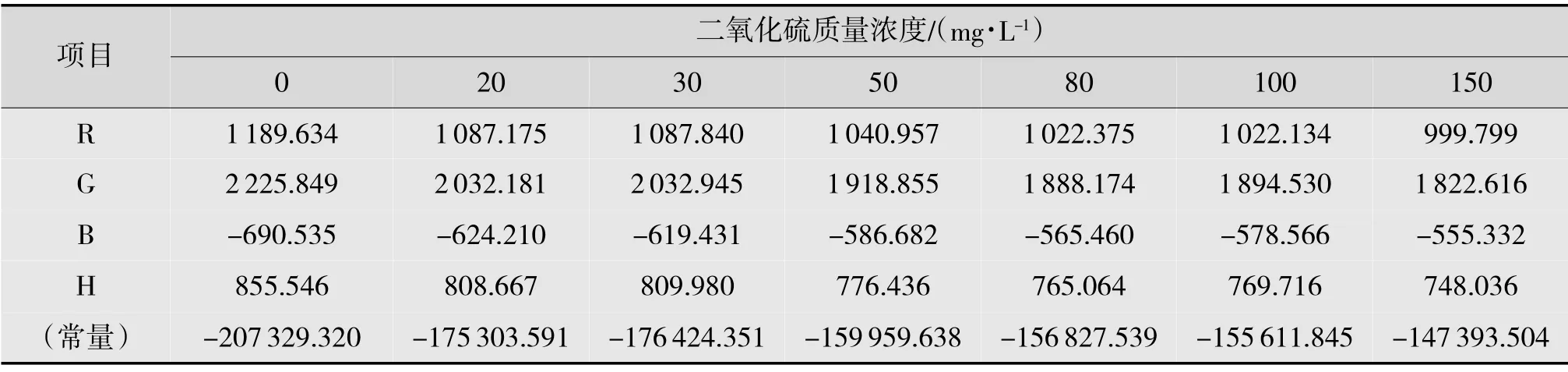
表3 分類函數系數

3 模型檢驗
對一個待測數據進行分類,只需要將數據中的R,G,B,H 分別代入7 個判別函數計算函數值,例如將測試組中的第一條記錄代入判別函數,計算得F1=207 666,F2=205 126,F3=202 068.3,F4=202 058,F5=200 965.9,F6=201 091.1,F7=198 610,這些值中F1最大,所以屬于第1 類,即質量濃度為0,與原始分類相同。利用該模型建立的判別函數對測試組的25組數據進行計算,得到的預測結果與原始數據完全吻合。
為了更好地說明該模型對二氧化硫質量濃度測定的準確性,作進一步分析。從前面二氧化硫的質量濃度判別分析模型知道:變量S 沒有被引入判別函數,即如果減少變量S 再進行判別分析,得到的判別函數及結果不會發生變化。去掉變量S 用SPSS 軟件進行分析,發現得到的結果與未去掉變量S 的分析結果一致。再將逐步進入法中最后進入模型的變量R,以及貢獻一般的變量B 去掉后分析(即去掉S,R,B),發現雖然組質心、判別函數都不同,但是不影響模型的判別結果。以上3種不同維度判別分析得到的預測分類結果的準確率都是100%。減掉對模型貢獻較大的變量G,H,B 之后進行判別分析,發現測試結果發生了變化,有部分誤判。表4 顯示了部分數據,其中Dis_1 是5 個變量R,G,B,S,H 作為自變量的預測結果;Dis_2 是去掉未被引入的變量S 后進行判別分析的預測結果;Dis_3 是去掉未進入模型的變量S 以及后進入模型的變量R、變量B 后進行判別分析的預測結果;Dis_4 是減掉對模型貢獻較大的變量G,H,B 之后進行判別分析的預測結果。
從表4 可看出減掉對模型貢獻較大的變量G,H,B 之后,判別分析得到的第8 條和第22 條記錄結果與原結果不同。第8 條記錄將質量濃度為20 mg/L 判斷成了30 mg/L,而第22 條記錄將質量濃度為150 mg/L 判斷成了100 mg/L,結果判斷有偏大也有偏小的情況。因此,隨意減少變量對判斷結果會有影響。表4 也說明逐步判別分析法在該模型中對變量的篩選非常準確,模型效果非常好。
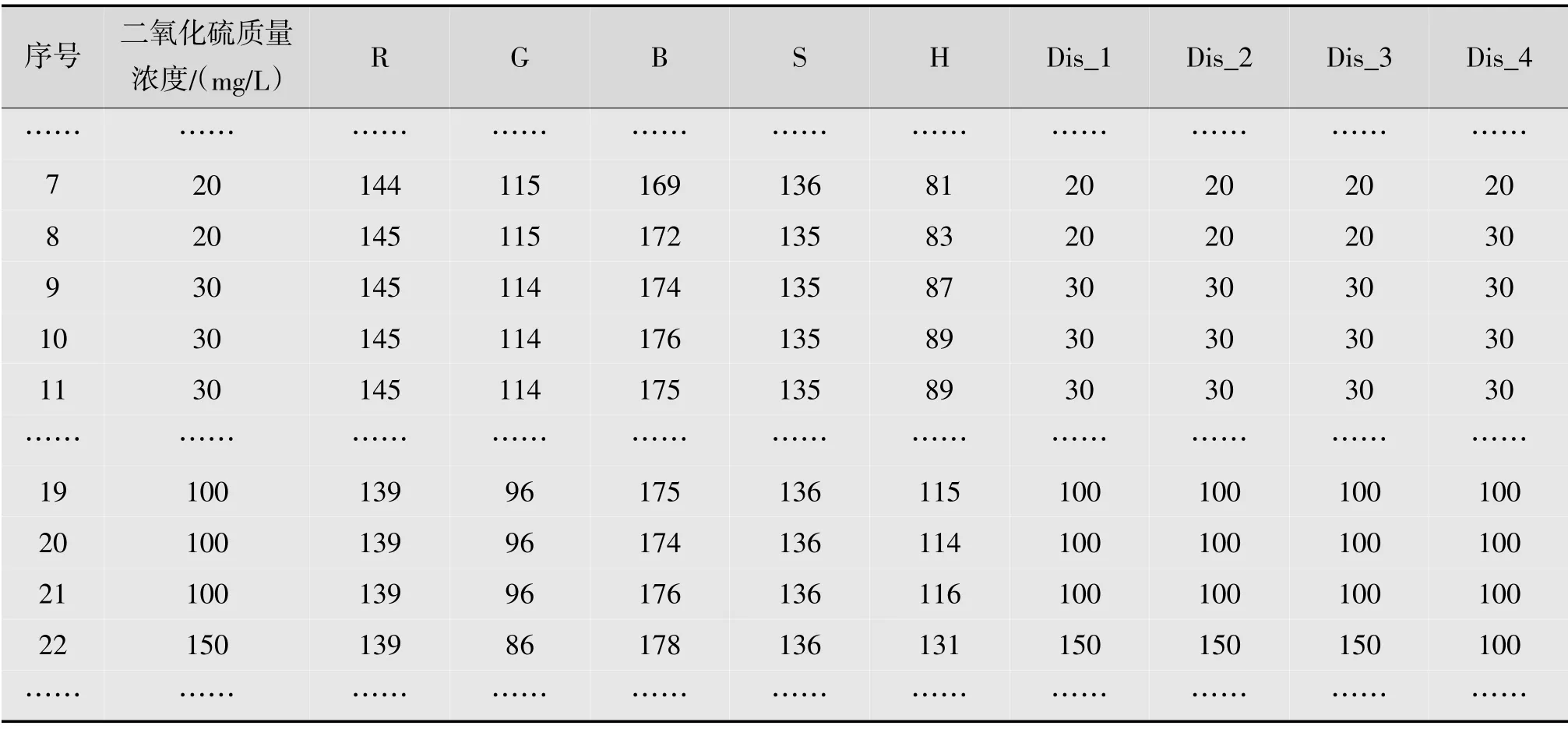
表4 幾種不同變量的預判結果圖
4 結論
用逐步判別分析法建立的二氧化硫顏色讀數和其質量濃度的關系模型,能有效判斷溶液的質量濃度,且精確度較高。該方法在化學物質檢測中具有一定的參考價值,可以推廣用于其他溶液(如溴酸鉀溶液)質量濃度的測定,通過建立各自的判別函數,可提高比色法檢測的準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
