快速卷積算法的綜述研究 *
2021-10-26 01:17:22劉宗林徐雪剛夏一民
計算機工程與科學(xué) 2021年10期
關(guān)鍵詞:優(yōu)化
李 創(chuàng),劉宗林,劉 勝,李 勇,徐雪剛,夏一民
(1.國防科技大學(xué)計算機學(xué)院,湖南 長沙 410073;2.湖南長城銀河科技有限公司,湖南 長沙 410000)
1 引言
隨著深度學(xué)習(xí)的蓬勃發(fā)展,研究人員對卷積神經(jīng)網(wǎng)絡(luò)CNN(Convolutional Neural Network)的研究工作[1 - 3]將會把重心放在更大規(guī)模和更高準(zhǔn)確率上,在卷積神經(jīng)網(wǎng)絡(luò)中,更大規(guī)模和更高準(zhǔn)確率需要更快速更準(zhǔn)確的運算,所以研究卷積神經(jīng)網(wǎng)絡(luò)的加速方法很重要。與此同時,針對卷積神經(jīng)網(wǎng)絡(luò)的加速優(yōu)化近年來也有了快速的發(fā)展,如低秩分解、定點運算、矢量量化、稀疏表示[4]、剪枝[5]和快速卷積[6 - 10]等,實現(xiàn)了卷積神經(jīng)網(wǎng)絡(luò)整體的加速效果。在一個卷積神經(jīng)網(wǎng)絡(luò)[11]中,卷積是核心,同時運算量最大的部分也是卷積部分,未來計算力的強弱將會決定神經(jīng)網(wǎng)絡(luò)的發(fā)展速度。更大的計算規(guī)模、更豐富的數(shù)據(jù)、更高強度的計算依然是深度學(xué)習(xí)的下一個發(fā)展點,卷積神經(jīng)網(wǎng)絡(luò)能否在眾多應(yīng)用中繼續(xù)體現(xiàn)出巨大優(yōu)勢,這將依賴于更強的計算能力。而卷積神經(jīng)網(wǎng)絡(luò)的計算量絕大多數(shù)集中在卷積操作的乘加操作上,這些巨大的計算量和驚人的功耗極大地限制了卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用的發(fā)展,也限制了研究人員的研究進(jìn)度。卷積加速的研究工作意義非凡,在迫切需求更強計算力的未來,卷積加速的研究工作有待進(jìn)一步加深。目前對于卷積優(yōu)化的方法也有很多,因此本文將對近年來常見的卷積加速方法做一個總結(jié)。
2 概述
2.1 卷積
在CNN中,卷積是圖像處理中最基本又是最重要的操作。卷積是待處理的圖像和卷積核兩者之間發(fā)生的操作,對于待處理圖像中的每一個像素點計算它周圍像素點和卷積核矩陣的對應(yīng)像素點的乘積,然后把乘積結(jié)果累加到一起,作為輸出特征圖的像素點,具體過程如圖1所示,這樣就完成了卷積過程。準(zhǔn)確地說卷積有3種模型,分為Full卷積、Same卷積和Valid卷積,卷積時,卷積核是在卷積圖像上進(jìn)行滑動,F(xiàn)ull卷積指的是從卷積核滑動到和圖像剛相交時就開始進(jìn)行卷積,Same卷積指的是卷積核中心滑動到和圖像剛相交時就開始進(jìn)行卷積,Valid卷積指的是卷積核滑動到如圖1所示位置處開始進(jìn)行卷積。
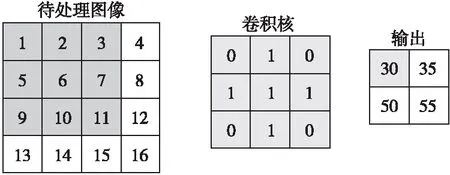
Figure 1 Process of convolution圖1 卷積的過程
引入現(xiàn)實中卷積應(yīng)用的意義,可加深對卷積運算的理解。物理學(xué)中的信號處理過程,信號的輸出不僅僅受t時刻的輸入響應(yīng)影響,還受到t時刻之前的輸入響應(yīng)影響,不過t時刻之前的影響相對于t時刻有一定衰減,所以t時刻的真實輸出應(yīng)該是所有時刻響應(yīng)的疊加,同時由于不同時刻的影響不同,不同時刻的影響應(yīng)該乘以一個系數(shù),這整個過程就是卷積。
圖1卷積過程需要36次乘法和32次加法操作,隨著輸入圖像尺寸的增大以及通道數(shù)的增加,卷積運算所需的乘加次數(shù)也在倍增。可以看出,卷積操作會占用卷積層乃至整個網(wǎng)絡(luò)執(zhí)行時間的絕大部分,目前針對卷積操作的優(yōu)化實現(xiàn)也有了初步的進(jìn)展,但是隨著計算機體系結(jié)構(gòu)的發(fā)展,優(yōu)化工作需要繼續(xù)展開,根據(jù)不同的體系結(jié)構(gòu)實現(xiàn)不同的優(yōu)化方法。
圖像直接卷積運算的本質(zhì)是若干個子矩陣塊與卷積核的卷積。卷積圖像可劃分成若干和卷積核大小一致的小塊,塊和卷積核的運算如算法1所示,而圖像直接卷積是最傳統(tǒng)的計算方法,其實現(xiàn)見算法2。算法2中M是本層輸出的特征圖尺寸,K是卷積核尺寸,C_in是輸入圖像的通道數(shù),Kernel_num是輸出特征圖的通道數(shù),kernel為卷積核的尺寸,在卷積神經(jīng)網(wǎng)絡(luò)中,單層的時間復(fù)雜度為O(M2*K2*C_in*Kernel_num)。Matlab中的conv函數(shù)實現(xiàn)以及cuda-convnet2函數(shù)的實現(xiàn)采用的就是直接卷積方法,這種直接卷積方法效率不是特別高,所以研究人員對該卷積加速運算進(jìn)行了進(jìn)一步的研究。
算法1Block_Conv
Input:Block,Kernel。/*Block,Kernel分別是2D多通道圖像的1個小塊和卷積核*/
Output:y。//y是塊卷積的輸出
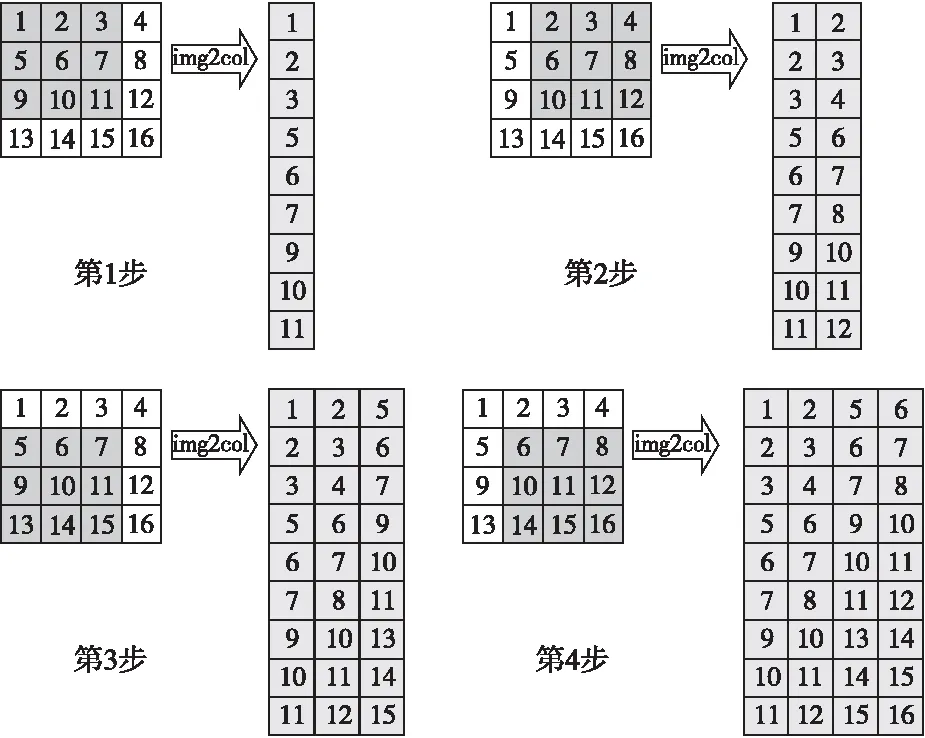
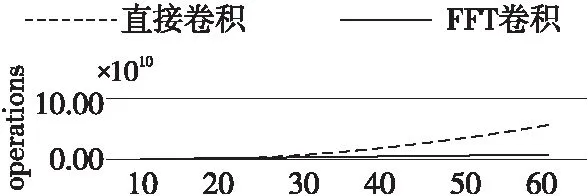
Fork=0;k Fori=0;i y=Block[k][i] *Kernel[k][i]; Returny 算法2Image_Conv Input:Img,Kernel。/*Img,Kernel分別是2D多通道圖像和卷積核*/ Output:Y。//Y是輸出圖像 Form=0;m Forn=0;n Forc=0;c Forr=0;r Y[r][m][n]+=Block_Conv(Img[c][m][n],kernel) ReturnY 卷積操作是卷積神經(jīng)網(wǎng)絡(luò)中耗費時間最長的部分,因為計算涉及到多次乘加運算。在任何一個卷積神經(jīng)網(wǎng)絡(luò)中,每一卷積層對圖像信息進(jìn)行卷積處理時,其計算量可表示為輸出特征圖的大小和參數(shù)量的大小的乘積,例如:當(dāng)卷積核的尺寸為5*5*3,卷積核的個數(shù)為2時,卷積核的參數(shù)量為 5*5*3*2,偏差的參數(shù)量為2,輸入圖像尺寸為28*28*3,無填充,且步長大小為1,則按照式(1)計算得到卷積后的輸出特征圖尺寸為24,輸出特征圖的數(shù)量為2。 Out_map=In_img+2*pad- kernel/Strides+1 (1) 其中,Out_map是輸出特征圖的尺寸,In_img是待處理圖像的尺寸,pad是填充尺寸,kernel是卷積核的尺寸,Strides是步長。 這一層卷積操作所需要的計算量為(5*5*3*2+2)*(24*24)=87552。所以,卷積操作占了執(zhí)行時間的絕大部分。目前針對卷積操作的優(yōu)化實現(xiàn)也有了初步的進(jìn)展,但是隨著計算機體系結(jié)構(gòu)的發(fā)展,優(yōu)化工作需要繼續(xù)展開,根據(jù)不同的體系結(jié)構(gòu)設(shè)計不同的優(yōu)化方法。 CNN主要由卷積層、池化層和全連接層構(gòu)成,其中卷積層用來提取圖像特征,池化層用來降維減少運算量,全連接層用來輸出分類。CNN的大部分計算量集中在卷積層上,而隨著深度學(xué)習(xí)的發(fā)展,研究人員正采用更多卷積層的復(fù)雜模型來提高預(yù)測精度,這些模型的巨大計算量和驚人功耗限制了CNN在嵌入式設(shè)備的廣泛應(yīng)用。因此,加速卷積算法正成為近期研究的一個熱點。 CNN在計算機視覺領(lǐng)域有著非常廣泛的應(yīng)用,常用來進(jìn)行圖像的識別與分類、圖像分割、目標(biāo)檢測與定位、圖像生成等。詞向量的引入,使得CNN可以在機器翻譯、文本分類、語音識別等自然語言處理領(lǐng)域得以應(yīng)用。生活中常見的自動駕駛技術(shù)、美顏、人臉識別打卡等都是基于CNN設(shè)計的,F(xiàn)acebook提出的CNN機器翻譯,在當(dāng)時比谷歌的翻譯快9倍。 通過查看當(dāng)前主流的深度學(xué)習(xí)框架,就能知道目前主流的卷積層優(yōu)化算法,在Caffe中卷積層采用的是img2col+GEMM(GEneral Matrix Multiplication)算法,PaddlePaddle中卷積層使用的是Winograd算法,而Facebook曾經(jīng)的NNPACK(acceleration PACKage for Neural Network computations)中的卷積實現(xiàn)和LightNet中的CNN實現(xiàn)采用的都是基于快速傅里葉變換FFT(Fast Fourier Transform)的算法。這3種算法是目前最為流行的針對卷積層進(jìn)行加速的加速算法。 img2col是用來優(yōu)化卷積運算的一個重要算法,Caffe框架的卷積實現(xiàn)就是采用的這種方法。傳統(tǒng)卷積運算時,根據(jù)不同的卷積核大小需要不斷地從卷積圖像矩陣中取出和卷積核同樣大小的卷積塊,使用for循環(huán)來實現(xiàn)卷積,遇到卷積圖像尺寸過大時,需要多次訪存,非常耗時。img2col算法的核心思想是把圖像感受野部分轉(zhuǎn)換為一行或一列來存儲,減少內(nèi)存訪問次數(shù),從而達(dá)到優(yōu)化卷積運算的目的。從另一方面來講,當(dāng)img2col把卷積圖像信息做完轉(zhuǎn)換后,可以把感受野部分轉(zhuǎn)換后的若干行或若干列拼成矩陣,對于卷積圖像而言,拼成的矩陣的行數(shù)或者列數(shù)就是卷積核在卷積圖像上滑動的次數(shù)。img2col算法的轉(zhuǎn)換過程如圖2所示。卷積圖像被轉(zhuǎn)換為新矩陣后卷積運算就變成了矩陣相乘運算,輔以現(xiàn)有的矩陣乘優(yōu)化庫可以明顯地加快卷積速度。 Figure 2 Principle of img2col圖2 img2col的原理 GEMM在深度學(xué)習(xí)中發(fā)揮著十分重大的作用,卷積神經(jīng)網(wǎng)絡(luò)中的全連接層和卷積層的運算都可以用矩陣乘來實現(xiàn),而一個卷積神經(jīng)網(wǎng)絡(luò)中90%的運算量都集中在全連接層和卷積層,優(yōu)化GEMM可以實現(xiàn)對卷積神經(jīng)網(wǎng)絡(luò)的加速。GEMM卷積算法如算法3所示,其中A和B是用img2col算法轉(zhuǎn)換后的卷積圖像和卷積核矩陣,A是一個R*C的矩陣,B是一個C*K的矩陣,R為輸出矩陣的寬和高的乘積,C為卷積核寬和高的乘積,K為卷積核的數(shù)量。 算法3GEMM_Conv Input:A,B。 Output:C。 Form=0;m Forn=0;n Fork=0;k C[m][n]+=A[m][k] *B[k][n]; ReturnC img2col+GEMM實現(xiàn)卷積操作是目前計算卷積的常用方法之一。可以利用GEMM的優(yōu)化來實現(xiàn)對卷積的優(yōu)化,目前現(xiàn)有的矩陣優(yōu)化技術(shù)已經(jīng)可以將常見的矩陣乘運算改進(jìn)約7倍。按照傳統(tǒng)卷積的方式,參與運算的數(shù)據(jù)在內(nèi)存中的存放是不連續(xù)的,因此需要多次訪存。為了解決該問題,研究人員提出了img2col,可以節(jié)省訪存的時間,從而達(dá)到加速的目的。img2col把卷積操作轉(zhuǎn)換為矩陣乘后,使用優(yōu)化后的GEMM可以實現(xiàn)進(jìn)一步的加速。從圖2可以看出,卷積圖像的信息被多次復(fù)用提取到轉(zhuǎn)換后的矩陣中,增加了額外的內(nèi)存開銷,以Lenet網(wǎng)絡(luò)模型的第1層卷積為例,輸入圖像大小為32*32,6個5*5的卷積核,輸出6個28*28的輸出特征圖信息,用img2col把輸入信息轉(zhuǎn)換為維度為(28*28)*(5*5)的矩陣,相較于原始的32*32的圖像輸入信息所占用的內(nèi)存,轉(zhuǎn)換后的矩陣信息所占用的內(nèi)存高達(dá)18倍以上。 img2col+GEMM能將復(fù)雜的卷積過程轉(zhuǎn)化為矩陣相乘的簡單運算,不僅適用于二維卷積,還可推廣到三維甚至更高的維度,具有很好的通用性。 Winograd算法早在1980年就被提出用來減少有限長單位沖激響應(yīng)FIR(Finite Impulse Response)濾波器的計算量,同F(xiàn)FT一樣都需要把數(shù)據(jù)變換到其他空間進(jìn)行處理后再變換回原空間,不同于FFT的是Winograd變換不涉及復(fù)數(shù)。在2016的CVPR會議上,Andrew等[7]提出的快速算法就使用了Winograd進(jìn)行卷積加速。目前騰訊的NCNN(Neural Network Inference Computing Framework)、Facebook的NNPACK和NIVDIA的cuDNN(NVIDIA CUDA Deep Neural Network)中計算卷積的算法都是采用的Winograd算法。 Andrew等[7]對Winograd算法做卷積運算做了很大篇幅的介紹,其中一維Winograd算法需要進(jìn)行3次線性變換,具體轉(zhuǎn)換過程如式(2)所示,二維Winograd算法需要6次線性變換,具體實現(xiàn)過程如式(3)所示: Y=A′[(Gg)⊙(B′d)] (2) Y=A′[(GgG′)⊙(B′dB)]A (3) 其中,☉表示點乘,A′表示矩陣A的轉(zhuǎn)置,用來對結(jié)果做線性變換,B′表示矩陣B的轉(zhuǎn)置,用來對輸入信息進(jìn)行線性變換,G是用來對卷積核做線性變換處理的變換矩陣,g是卷積核數(shù)據(jù),d是輸入數(shù)據(jù)。 一維Winograd算法中的A,B′,G如下所示: 大部分卷積神經(jīng)網(wǎng)絡(luò)加速器都采用的卷積加速算法就是Winograd算法,它是Strassen算法的變形。Strassen算法是一種通過減少矩陣相乘中的乘法次數(shù)來實現(xiàn)矩陣相乘的矩陣相乘優(yōu)化算法,關(guān)于Strassen算法不作過多介紹,可參考文獻(xiàn)[12],它把矩陣乘法的算法復(fù)雜度由O(n3)降低到了O(n2.81)。Winograd的相關(guān)算法也是從減少矩陣相乘算法中的乘法次數(shù)來實現(xiàn)卷積計算的加速效果,2011年研究人員已經(jīng)利用Winograd算法把矩陣相乘算法的復(fù)雜度降低到了O(n2.3727)。Winograd算法已經(jīng)在深度學(xué)習(xí)的大部分應(yīng)用中顯示出較大的優(yōu)勢,成為當(dāng)前最常用的卷積加速算法之一。 Andrew等[7]對Winograd算法的卷積運算進(jìn)行了很大篇幅的介紹,目前主流的加速器對于卷積操作的加速大部分都采用的是Winograd快速卷積算法。Winograd快速卷積算法利用了卷積圖像像素點之間的結(jié)構(gòu)相似性,運用恰當(dāng)?shù)臄?shù)學(xué)技巧將乘法運算轉(zhuǎn)換為加法運算,因此能降低算法復(fù)雜度,實現(xiàn)卷積加速。 對于一維Winograd卷積,當(dāng)輸出長度為m,卷積核長度為r,所需要的乘法數(shù)量是m+r-1,相較于不使用Winograd算法時的m*r次乘法,Winograd算法帶來了性能上的提升。輸入信號為d=[d0d1d2d3],卷積核g=[g0g1g2]時,其卷積如式(4)所示: (4) 其中: m0=(d0-d2)g0, m2=(d1-d3)g2, 在Winograd算法中,所需的乘法次數(shù)為2+3-1=4次,直接運算需要6次乘法,而且卷積核部分的數(shù)據(jù)加法在訓(xùn)練時只需計算1次,在推理過程中可以省略,整體的運算量下降,從而實現(xiàn)了加速。Winograd快速卷積算法可以被推廣到二維,基于分塊矩陣的思想,先把輸入圖像矩陣展開成大矩陣形式,劃分成一維的形式,進(jìn)行進(jìn)一步的處理。將一維卷積擴(kuò)展到二維卷積,二維的F(2*2,3*3)需要16次乘法,而原來的算法需要進(jìn)行36次乘法,乘法次數(shù)減少了36/16倍,加速效果更明顯,二維的Winograd卷積加速算法可見文獻(xiàn)[7]中的算法1。 采用Winograd算法做卷積,相較于直接卷積的6層循環(huán),里面2層循環(huán)可以設(shè)計Winograd計算模塊來替代,Liang等[13]介紹了Winograd算法在FPGA上的實現(xiàn),在他們的研究成果中調(diào)用設(shè)計好的Winograd計算模塊,就可以直接計算出卷積參數(shù),減少了50%以上的乘法操作,F(xiàn)(2*2,3*3)的Winograd卷積算法具體實現(xiàn)步驟如下所示: 第1步:滑動提取一個tile(即提取每幅圖像上的一小塊數(shù)據(jù))直至遍歷完輸入圖像信息,tile大小選擇4*4; 第2步:對提取的tile做線性變換; 第3步:對卷積核做線性變換; 第4步:對變換后的卷積核和tile做點乘; 第5步:對第4步的輸出結(jié)果做線性變換,循環(huán)執(zhí)行。 二維的Winograd卷積算法的復(fù)雜度為O(M2*C_in*C_out),其中C_out表示輸出通道數(shù)。在實際中使用Winograd算法做卷積時,減少乘法次數(shù)是以增加加法次數(shù)為代價,同時額外的轉(zhuǎn)換計算也會增加算法的整體運行時間,所以多方面的代價需要我們在選擇Winograd算法實現(xiàn)卷積加速時進(jìn)行綜合考慮。 從2.1節(jié)算法1的介紹中可以看出,卷積的本質(zhì)是塊與卷積核之間的計算,所以可以通過對算法1進(jìn)行加速來加快整個圖像卷積的計算速度。快速傅里葉變換FFT是離散傅里葉變換的快速算法,能加快多項式乘法的運算速度。1965年,Cooley等[14]提出了FFT算法,節(jié)約了計算機的計算處理時間,普通多項式乘法的時間復(fù)雜度為O(n2),而FFT能讓多項式乘法在O(nlbn)的時間內(nèi)完成運算,所以,在算法1的計算中,可以利用FFT來實現(xiàn)加速。 卷積定理指出函數(shù)卷積的傅里葉變換是函數(shù)傅里葉變換的乘積,這個定理是傅里葉變換滿足的一個重要性質(zhì),關(guān)于卷積定理的證明可參考文獻(xiàn)[15],卷積定理為FFT能在深度學(xué)習(xí)領(lǐng)域進(jìn)行卷積加速運算提供了可能性。Mathieu等[16]曾在2014年ICLR會議上提出了用FFT加速卷積網(wǎng)絡(luò)訓(xùn)練的方法,并且在當(dāng)時的卷積運算方面有著1個數(shù)量級以上的改進(jìn)。關(guān)于FFT做卷積運算的研究已經(jīng)開展了很多年,相關(guān)研究[17]取得了一定的進(jìn)展,也已經(jīng)獲得了很大的性能提升,基于Matlab的輕量級深度學(xué)習(xí)框架LightNet[18]、Facebook的NNPACK框架和CUDA的cuDNN等,都支持基于FFT實現(xiàn)卷積。目前的研究工作中,經(jīng)常使用一維和二維序列的FFT變換操作。無論是一維還是二維FFT實現(xiàn)快速卷積,其主要步驟相同,只是在進(jìn)行FFT變換時有所不同,執(zhí)行1次二維FFT變換相當(dāng)于2次一維FFT變換。利用FFT實現(xiàn)一維快速卷積的算法如算法4所示,其中,“.*”符號表示對應(yīng)位置元素相乘。 算法4FFT_Conv Input:卷積圖像序列X和卷積核序列Y,長度分別為S和N。 Output:Res。 L:L滿足L≥S+N-1,且L是2的冪次方; Form=S;m X[m]=0; EndFor∥補零 Forn=N;n Y[n]=0; EndFor∥補零 Res=ifft(fft(X).*fft(Y)); ReturnRes 當(dāng)FFT變換的點數(shù)為n時,F(xiàn)FT做卷積的復(fù)雜度為3次n點FFT計算與n次乘法,即為3*O(nlogn)+O(n),所以本算法的復(fù)雜度為O(nlogn)。利用FFT實現(xiàn)一維卷積[19 - 21]時,當(dāng)FFT的變換點數(shù)L越大時,加速效果越明顯,L越小加速效果就越差。在一些嵌入式平臺上,有相應(yīng)的硬件支持,F(xiàn)FT快速卷積的效率更高,文獻(xiàn)[22 - 24]探索了在微處理器平臺上實現(xiàn)FFT卷積的性能,研究表明內(nèi)置的FFT指令能進(jìn)一步對卷積運算進(jìn)行加速。FFT卷積實現(xiàn)了一定程度上的卷積加速,但是其依然存在一些缺陷,在卷積神經(jīng)網(wǎng)絡(luò)中有一定的限制,因為在卷積神經(jīng)網(wǎng)絡(luò)中,卷積核的尺寸很小,比如VGG(Visual Geometry Group)里面大小為3*3和5*5的卷積核非常多,在這種情況下,卷積圖像大小和卷積核尺寸大小相差很大,再使用FFT實現(xiàn)卷積,需要在用FFT進(jìn)行變換時補零,開銷加大,使用FFT實現(xiàn)卷積就有點得不償失。 利用時域卷積等于頻域乘積的性質(zhì),用FFT進(jìn)行快速卷積運算,這里以二維FFT做卷積為例,F(xiàn)FT 1次變換和IFFT(Inverse Fast Fourier Transform)1次變換需要的計算量都為O(2M2*logM),FFT實現(xiàn)卷積需要對卷積圖像、卷積核和輸出進(jìn)行轉(zhuǎn)換,所需要轉(zhuǎn)換的數(shù)量分別為(單批次)C_in,C_out和C_out*C_in,FFT變換所需要的總計算量為2M*M*logM*(C_out+C_in+C_in*C_out),變換之后的張量之間(復(fù)數(shù))的乘積所需要的計算量最少為4*C_in*C_out*M*M,所以FFT實現(xiàn)卷積需要的總計算量為O(2M2*logM*(C_out+C_in+C_in*C_out)+4*C_in*C_out*M*M)。 FFT變換是一種線性變換,不會影響多通道變換后的結(jié)果,能節(jié)省出很大一部分開銷。FFT變換會增大內(nèi)存帶寬需求,占用大量內(nèi)存,與此同時,對于卷積步長大于1的卷積操作,由于數(shù)據(jù)比較稀疏,這種情況下利用FFT做卷積的效率也很低。 為了解決FFT卷積在卷積核過小而輸入圖像數(shù)據(jù)過大時不適用的問題,Lin等[25]提出了一種tFFT(tile Fast Fourier Transform)算法,實現(xiàn)了CNNs傅里葉域的基于tile的卷積,對于卷積核比較小的情況,可以進(jìn)行批量FFT運算,通過隱藏數(shù)據(jù)讀取時間,復(fù)用旋轉(zhuǎn)因子,提高FFT的計算效率。在對卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練時,會有成千上萬次卷積運算,為了利用FFT進(jìn)行加速訓(xùn)練和推理該tFFT算法是針對FFT做卷積加速時不適用較小的卷積核這一問題提出的一種新算法,引入了tile分解的方法對經(jīng)典的FFT進(jìn)行擴(kuò)展,使其能適用小卷積核的情況,達(dá)到加速卷積運算的目的。tFFT的實現(xiàn)過程大致如下:首先將大尺寸輸入在邏輯上劃分為與濾波器核大小相近的塊,然后在傅里葉域中對這些邏輯上劃分的塊和濾波器進(jìn)行轉(zhuǎn)換。其次,遞歸地將之前的分塊輸入分解為蝴蝶運算,這些蝴蝶運算操作在GPU的并行流上進(jìn)行計算。在批大小為128以內(nèi),相較于經(jīng)典FFT卷積算法,tFFT在ResNet-34模型上的平均算法復(fù)雜度降低到原來的1/3左右,在VGGNet-19模型上的平均算法復(fù)雜度降低到原來的1/4左右,在AlexNet模型上的平均算法復(fù)雜度降低到原來的1/4左右。 Budden等[26]提出了一種快速張量卷積算法。同Winograd算法類似,快速張量卷積也是通過減少乘法次數(shù)來減少計算量的卷積算法,該算法引入中國剩余定理的思想,不需要生成Winograd卷積算法的轉(zhuǎn)換矩陣,并且可在高維上實現(xiàn)卷積運算。同時,Budden等[26]也引入了在多核上實現(xiàn)深度加速的方案,利用多核處理器高度并行的能力,對卷積運算進(jìn)行深度加速,在性能上獲得了可觀的效果。 基于常見的GEMM卷積算法和Winograd卷積算法,Kala等[27]提出的一種變體算法研究了在Winograd算法基礎(chǔ)上結(jié)合GEMM的實現(xiàn)方案。 而基于常見的FFT卷積算法和Winograd卷積算法,文獻(xiàn)[28]提出了Winograd和FFT融合方案,便于數(shù)據(jù)處理。 Winograd算法是目前最實用的快速卷積算法,在各大深度學(xué)習(xí)框架可以看到大量的研究工作者不約而同地都在使用Winograd算法,針對Winograd快速卷積算法的研究,延伸出了多種變體算法,除了上述幾種外,文獻(xiàn)[29]提出了一種改進(jìn)算法,能夠?qū)ΩL序列的卷積網(wǎng)絡(luò)進(jìn)行加速;文獻(xiàn)[30]提出了一種基于積分的卷積核縮放方法,可以使最終的結(jié)果沒有太大的精度損失,文獻(xiàn)[30-37]等都是融合了Winograd快速算法的思想。 基于額外內(nèi)存占用問題,文獻(xiàn)[38-40]等提出了優(yōu)化內(nèi)存與速度的卷積計算方法,盡可能減少內(nèi)存消耗。 前文提到的多種快速卷積算法多數(shù)都是從運算技巧上入手,通過減少運算次數(shù)實現(xiàn)加速優(yōu)化,從減少參數(shù)運算量的方面,也可以加速卷積運算。對參與卷積運算的卷積核進(jìn)行分解,可以顯著降低參數(shù)量,以7*7的卷積核為例,可以用3個3*3的卷積核替代實現(xiàn)相同的效果,前者需要的參數(shù)量為49,后者需要的參數(shù)量只有27,降低了40%以上的參數(shù)量,能實現(xiàn)卷積的快速運算,此外模型壓縮、量化等都是從降低參數(shù)量的方面實現(xiàn)對卷積的優(yōu)化。 CNN最終要部署在計算設(shè)備上來完成圖像識別、語音識別和自然語言處理等任務(wù),涉及到具體的實現(xiàn),就要根據(jù)計算設(shè)備的特性來實施部署的方案。每一幅特征圖的卷積運算可以被分解為若干幅小特征圖和卷積核的浮點乘加計算,這些運算過程是相對獨立的,不存在先后順序和相互影響,可以利用并行處理來實現(xiàn)加速。根據(jù)目前CNN使用狀況,使用者常把CNN部署在CPU或者GPU上運行進(jìn)行訓(xùn)練和推理,將CNN部署在移動終端上完成推理任務(wù)在近年來也得到了很多關(guān)注: (1)基于GPU的CNN加速。GPU是專為執(zhí)行復(fù)雜的數(shù)學(xué)和幾何運算而設(shè)計的,具有大量的計算核心,適合大規(guī)模的并行運算,當(dāng)前GPU在CNN中占有重要的地位。Andrew等[7]在實現(xiàn)Winograd算法時,使用VGG網(wǎng)絡(luò)模型,實驗測試相比cuDNN,Winograd算法在不同批次不同浮點數(shù)位數(shù)時都有一定的性能提速,且最高提速達(dá)到了7.42x。Mathieu等[14]從算法復(fù)雜度方面詳細(xì)論述了FFT卷積算法的優(yōu)勢,而使用CUDA能方便地利用計算平臺提供的cuFFT來實現(xiàn)卷積計算。如圖3展示了FFT卷積和直接卷積所需要的運算操作次數(shù),其中,n是參與FFT的點數(shù),縱軸是所需操作數(shù),量級是1010。CUDA是NVIDIA推出的運算平臺,它能提供豐富的函數(shù)接口,利用CUDA可以方便快速地實現(xiàn)卷積。針對特定領(lǐng)域的應(yīng)用,CUDA為開發(fā)人員提供了多種多樣的庫,包括針對深度學(xué)習(xí)領(lǐng)域的庫[36],其中cuDNN[41]是NVIDIA開發(fā)的用于深度學(xué)習(xí)網(wǎng)絡(luò)的GPU加速庫,利用cuDNN可以方便地實現(xiàn)各種卷積算法,研究人員可以對卷積算法進(jìn)行快速的驗證對比,使研究人員更多地專注于神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的層次,而不用過多地思考性能問題。 Figure 3 FFT convolution versus direct convolution performance on GPU圖3 GPU上FFT卷積和直接卷積的對比 (2)基于CPU的卷積加速。現(xiàn)在CPU多數(shù)都具有多個CPU核心,而目前很多程序都沒有進(jìn)行過多核優(yōu)化,因此對程序進(jìn)行并行設(shè)計,盡量使用多線程處理,可以充分利用CPU的硬件資源,提高算法的執(zhí)行效率。David 等[42]基于CPU硬件擴(kuò)展了Winograd類的卷積算法,使其能在高維上進(jìn)行有效卷積計算,并通過向量化處理加速卷積計算,利用多核并行充分發(fā)揮CPU的硬件性能,相比以前的先進(jìn)水平,有著5~25倍的吞吐量提升。Jia 等[43]從數(shù)據(jù)布局、數(shù)據(jù)轉(zhuǎn)換和批量矩陣乘法等方面出發(fā),在CPU硬件上實現(xiàn)了Winograd類卷積算法,相比其他種類卷積,有著3倍的性能提升。 (3)基于移動終端的CNN加速。用戶需要將CNN部署在手機、無人機和汽車等移動終端上,完成圖像分類、識別,目標(biāo)檢測與定位,人臉識別等任務(wù),考慮到便攜性和成本,存在存儲資源和計算資源有限的問題,導(dǎo)致在移動設(shè)備上無法部署規(guī)模較大的網(wǎng)絡(luò),輕量級模型和模型壓縮是解決存儲限制和降低功耗的有效方法之一。 卷積神經(jīng)網(wǎng)絡(luò)需要大量的數(shù)據(jù)來保證較高的準(zhǔn)確率,所以計算速度在近年來一直是研究人員所關(guān)注的重點,無論是自動駕駛,還是醫(yī)學(xué)分析亦或其他的應(yīng)用領(lǐng)域,都需要快速地響應(yīng)處理,這都依賴于更快的計算速度。對卷積運算進(jìn)行加速,無疑是一種對網(wǎng)絡(luò)模型進(jìn)行高度加速的有效途徑。前文論述的幾種快速卷積算法,各有利弊,很多時候研究人員使用的是這些算法的綜合變體算法,未來卷積加速工作的重心將會放在更小卷積核與更大的卷積圖像信息的卷積加速上,F(xiàn)FT的一些變體算法,以及Winograd的卷積核尺寸多變算法等將成為卷積加速研究的主流。2.2 卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用
3 快速卷積算法
3.1 img2col+GEMM
3.2 Winograd卷積算法
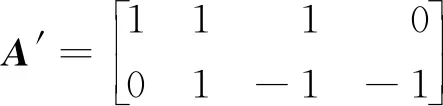

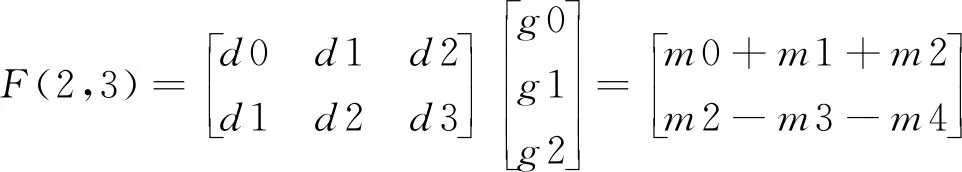
3.3 FFT卷積算法
3.4 其他快速卷積算法
4 具體實現(xiàn)
5 結(jié)束語
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14能源工程(2022年1期)2022-03-29 01:06:28建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59消費導(dǎo)刊(2018年8期)2018-05-25 13:20:08家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41電子制作(2017年20期)2017-04-26 06:57:45
