面向分類的自動化機器學習模型構建
2021-10-28 07:51:00孫長麟汪紅強
軟件導刊 2021年10期
孫長麟,汪紅強
(中國空間技術研究院503 研究所,北京 100095)
0 引言
隨著人工智能技術的發展,機器學習開始廣泛應用于大量場景的預測、分類任務。然而,沃爾伯特的免費午餐定理意味著沒有任何模型能很好地應用于所有數據集[1]。面對日益增加的應用場景及龐大的數據量,構建科學、高效的自動化機器學習模型顯得尤為重要,已成為機器學習領域亟待解決的問題之一[2]。因此,本文構建一種基于分層級聯結構與改進遺傳算法的自動化機器學習模型,可自動、高效地生成機器學習管道。將其應用于預測、分類任務,并在公共數據集上進行評估,結果表明該模型具有較高的準確性。
針對分類任務,傳統方案為使用超參數修正方法設計、構建分類模型。為增強構建的分類模型的普適性與魯棒性,降低人工成本,將自動化機器學習概念引入分類任務中。國內外很多學者對此進行了研究,并取得了一定成果。如Pavlyshenko[3]提出傳統的級聯模型,可獲得較高的分類精度,但靈活性較差,不適用于廣泛的數據集;Feurer等[4]引入強大的自動化機器學習系統——Auto-sklearn,該工具包可產生具有110 個超參數的結構化假設空間,并實現自動地高精度分類,但其輸出攜帶的信息較少,且規模也較大,計算時間較長,若想作進一步訓練只能重寫代碼;Gijsbers 等[5]提出H2O 開源平臺,該平臺可自動訓練模型并輸出模型的排名列表,彌補了Auto-sklearn 的不足,但其應用于OpenML 數據集的分類效果遜色于前者;Olson 等[6]提出TPOT 架構,使用TPOT 進行一系列監督分類任務的基準測試,可獲得更高準確率,但其時間成本也較高。
以上方法雖能實現較好的分類效果,但規模較大,本文通過級聯與改進的遺傳算法構建自動化機器學習模型,使模型更加輕量化,同時也能獲得較為理想的分類效果。
1 模型構建
本文構建的模型具有兩種屬性:①級聯。在每個堆疊層都保留原始數據集,可合成特征,后層可學習前層的錯誤,這種靈活的結構可應對廣大數據集的挑戰;②遺傳算法。使用改進的遺傳算法自動尋找效果最佳的管道[7]。
1.1 級聯
在自動化機器學習模型構建過程中,提出一種新的組合結構方式——級聯,該結構是受到集成學習啟發而提出的[8]。集成學習的思路為訓練若干個體學習器,通過一定的結合策略最終生成一個強學習器,即將這些個體學習器作為初級學習器,并加入多層次級學習器,將上層數據輸出作為下層數據的輸入,每層依次進行訓練得到最終訓練結果[9]。級聯與該方式略有不同,其結構由層與節點構成,每個節點代表個體學習器,第一層用于接收原始數據集,后一層為前一層學習器的輸出。區別于集成學習的stacking,經過單層預測后,原始數據集合不會被舍棄,而是會連同上層預測結果作為下一層的輸入。其原因是,數據集中的項目數可能較小,如果后層舍棄原始數據,每層預測結果可能只包含很少關于問題的信息,從而導致局部最優等問題[10]。而且將預測結果添加到原始數據集這一做法非常靈活,如果這些特征對預測的準確性非常重要,可給予這些特征更大權值,以達到最佳效果。
1.2 遺傳算法
遺傳算法是模擬達爾文生物進化論中自然選擇與遺傳學機理的生物進化過程計算模型,是一種基于種群的元啟發優化算法[11-12]。將其應用于人工智能場景,效率高于超參數的“暴力搜索”,是一種較為新穎的構想。遺傳算法涉及初始化群體(管道)、適應度評估、交叉與變異、自然選擇、逐代演化等,從低適應到高適應,可以說是一個絕妙的進化過程[13]。遺傳算法具有很好的收斂性與魯棒性,但同時遺傳也具有一定局限性:算法對初始種群的選擇具有一定依賴性,搜索速度一般,得到精確的解需要花費較多訓練時間。因此,提出一種改進方案:在初始化群體之前生成數量較多的個體,按照適應度進行0 代選擇,并按照一定比例選擇其中高、中、低適應度的個體作為初代種群。該方式可保證初代種群的完整性與典型性,且在不影響準確性的情況下,能夠節約資源、提高效率。
1.3 分類算法
機器學習管道包括數據預處理、特征工程與模型選擇[14]。模型選擇通常涉及構建模型節點(即單個分類器)的優化,例如支持向量機(SVM)或集成方法,如AdaBoost、Bagging 等。以下介紹構建模型節點的分類算法及超參數優化。
支持向量機是一種二分類模型,其基本模型是定義在特征空間上間隔最大的線性分類器。因間隔最大,令其有別于感知機。SVM 還包括核技巧,使其成為實質上的非線性分類器。SVM 的學習策略是間隔最大化,也等價于正則化合頁損失函數的最小化問題。其學習算法是求解凸二次規劃的最優化算法,基本思路是求解能夠正確劃分訓練數據集且幾何間隔最大的分離超平面。SVM 分類使用核函數可向高維空間進行映射,并將樣本與決策面的間隔最大化。該過程可概括為3 個步驟:①利用核函數方法將樣本空間轉換為能線性可分的空間;②利用最大化間隔方法獲取分隔最大的分割線,得到支持向量;③利用分割線與支持向量對樣本進行分類預測。
使用SVM 分類器時,需設置核、gamma、決策函數等超參數,可使用默認參數或改進的遺傳算法進行自動化的超參數搜索。在構建的模型中,使用強分類器能有效提高分類準確率與效率。例如,集成方法之一的AdaBoost 是一種迭代算法,其核心思想是針對同一個訓練集訓練不同分類器(弱分類器),之后把這些弱分類器集合起來,構成一個更強的最終分類器(強分類器)。具體流程為:先對每個樣本賦予相同的初始權重,每一輪學習器訓練過后都會根據其表現對每個樣本權重進行調整,提升分類錯誤樣本的權重,使先前分類錯誤的樣本在后續得到更多關注。按此過程重復訓練出若干個學習器,最后進行加權組合,構建出強分類器。該過程亦可概括為以下3 個步驟:
(1)初始化訓練數據的權值分布D1。假設有N 個訓練樣本數據,則每一個訓練樣本開始都被賦予相同權值:w1=1/N。
(2)訓練弱分類器hi。具體訓練過程為:如果某個訓練樣本點被弱分類器hi 準確地進行了分類,在構造下一個訓練集過程中,其對應權值要減小;相反,如果某個訓練樣本點被錯誤地分類,其對應權值則應增大。權值更新后的樣本集被用于訓練下一個分類器,整個訓練過程如此迭代地進行下去。
(3)將訓練得到的各個弱分類器組合成一個強分類器。各個弱分類器訓練結束后,提高分類誤差率低的弱分類器權重,使其在最終分類函數中起著較大的決定作用,同時降低分類誤差率高的弱分類器權重,使其在最終分類函數中起著較小的決定作用。換言之,誤差率低的弱分類器在最終分類器中所占權重較大,從而得到較高的預測精度。
另一種集成方法Bagging 又稱為裝袋算法,其采用一種有放回的抽樣方法生成訓練數據。通過多輪有放回的初始訓練集隨機采樣,并行化生成多個訓練集,對應可訓練出多個基學習器(基學習器間不存在強依賴關系),再將這些基學習器結合起來構建出強學習器[15]。其本質是引入樣本擾動,通過增加樣本隨機性達到降低方差的效果。
以上介紹了分類算法,構建的模型將結合各自分類算法的特點優化超參數,以提高模型的普適性與魯棒性。
2 實驗與分析
2.1 級聯結構設計
為驗證自動化機器學習模型的有效性,本文構建一個結構模型。級聯結構如圖1 所示。
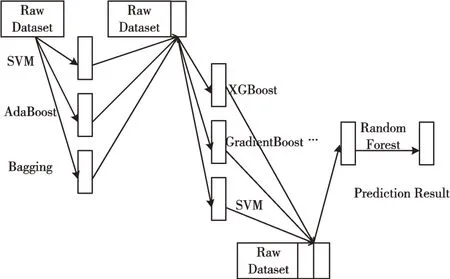
Fig.1 Cascade structure圖1 級聯結構
原始數據集經過每層每個節點的學習器/分類器,例如,經過首層每個節點時,都會經過k 折交叉驗證以及無重復抽樣、訓練,得到預測結果true/false,并將其添加到原始數據集中,在層中連接合成特征,作為下層的數據輸入[16-17]。因此,后層可學習前層的分類錯誤并對其進行糾正,且這種結構可直接從原始數據集中級聯信息。最后的數據集將包含個特征,其中,K為整體層數,Ni為第i層節點個數,經過K層的學習得到預測結果。設計的學習模型結構較為靈活,每層的節點個數、層數是可變的。節點列表如表1 所示。

Table 1 Node list表1 節點列表
考慮到結構的復雜性以及預測效率與準確性,設定每層學習器為3~5 個,層數為2~5 層。
2.2 遺傳算法搜索超參數
構建結構模型后,需在廣闊的變量空間中尋找合適的解決方案。這些變量包括各節點選用的基本學習器、框架設置等。此處不是將其視為優化問題,而是將其建模成超參數進行自動化搜索。選擇改進的遺傳算法完成超參數的自動化搜索,構建面向分類的自動化機器學習模型。算法流程如圖2 所示。
隨機初始化0 代種群,n 取4,N 取64,共256 個模型,選擇預測準確率作為適應度函數,分別從高、中、低適應度的個體中選擇32、18、14 共64 個個體組成初代種群[18]。考慮到傳統遺傳算法性能受初代種群影響較大,該方式既可保證初代種群科學、典型,又可減少種群數量,減少資源浪費,提高效率。在一半模型中運行一步突變得到N/2 個模型,突變同樣隨機產生,另N/2 個模型用于交叉,即兩兩隨機分組,交換后一半結構形成新模型。之后訓練2N 個模型,并通過交叉驗證進行評估,選擇準確度最高的N 個模型作為下一代種子模型。設置進化代數為100,使用multiprocessing 進行多進程訓練、評估,以提高效率[19-20]。
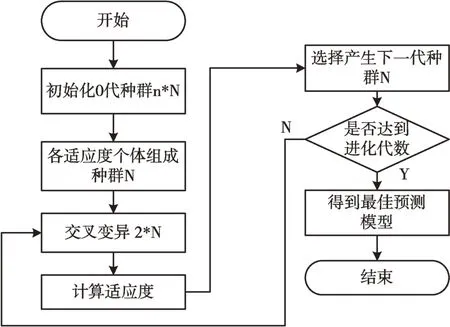
Fig.2 Improved genetic algorithm search flow圖2 改進的遺傳算法搜索流程
2.3 實驗結果
為了驗證構建模型的性能,本文選擇OpenML 公共數據集進行實驗。分別使用幾個典型的基本學習器ada-Boost、Bagging、DecisionTree 以及H2O 開源平臺、TPOP 框架(各學習器與框架都采用默認設置)進行12 輪驗證,比較預測準確性與效率[21]。此處列舉使用的部分公共數據集,如表2 所示。
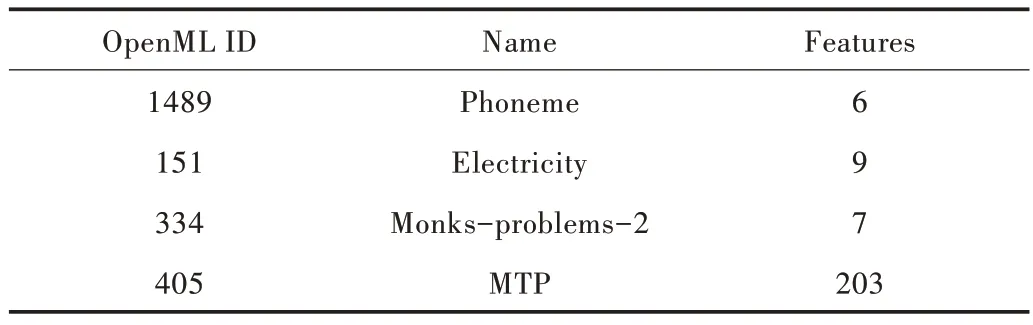
Table 2 Partial public dataset表2 部分公共數據集
經過12 輪驗證、測試與評估,得到各基本學習器、開源結構、框架與構建的自動化機器學習模型——New model在分類任務中的準確率,如表3 所示。

Table 3 Accuracy rate of each learner,framework and model表3 各學習器、框架與模型準確率
本文構建模型的準確率相比H2O 與TPOT 有所提高,在多次實驗中,發現就較小的數據集而言,本文構建的模型更具有優勢。不同模型、框架的平均執行時間比較如圖3 所示。
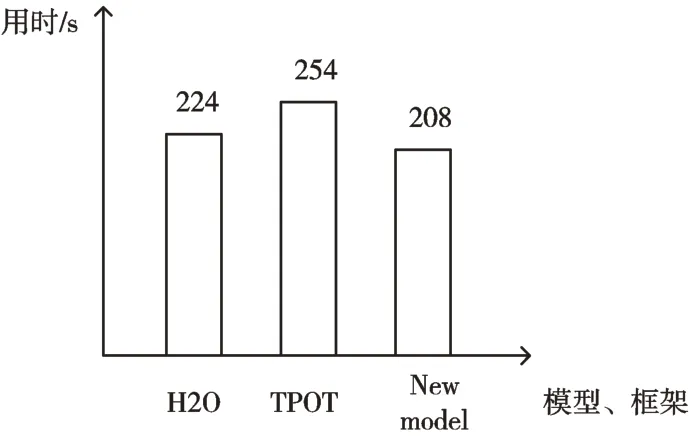
Fig.3 Comparison of the average execution time of different models and frameworks圖3 不同模型、框架平均執行時間比較
本文構建的模型執行時間相比H2O 減少了16s,相比TPOT 減少了46s,效率有所提高。
3 結語
本文構建一種用于分類的自動化機器學習模型,其結合了創新的級聯思想與改進的遺傳算法,在公共數據集上憑借其輕量級、準確性以及執行速度快等方面優勢顯示出其競爭力,但在大型、高維數據集與多任務問題上效果一般。未來研究方向是將更高級的學習器合并到構建的模型中,并使用更好的搜索算法使模型更加高效。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
