云計算背景下分布式軟件系統故障檢測技術研究
2021-10-29 08:28:40齊莉
電子制作 2021年18期
齊莉
(吉林工程職業學院,吉林四平,136000)
0 前言
根據云計算的特點和當前云計算資源故障檢測的需求,設計了云計算資源故障檢測系統的框架。故障檢測模型的設計是基于深層神經網絡故障檢測模型,利用稀疏自編碼器的并行結構提取原始數據的特征,進而提高故障數據的識別率,保證云計算系統的安全性和可靠性。搭建 hadoop 云計算平臺,設計部署云計算資源故障檢測系統,通過故障模擬,分析測試結果,驗證系統的可行性。故障檢測系統具有實時監測數據分析、自動檢測和故障檢測模型自動更新的優點。它不僅能夠滿足云計算的安全需求,而且能夠保證系統的連續性。
1 概述
■1.1 云計算背景分析
近年來,計算機技術在全球范圍內發展迅速,平臺化計算機技術研究方面也取得了很大的進步。以通信、計算和存儲為核心的各種技術已經在社會生活各個方面廣泛應用,隨著近年來世界計算機技術飛速發展,基于計算機系統平臺得到了跨越式的發展,其復雜性不斷增加,計算機軟硬件系統的運行和維護成本也在迅速上升,給計算機企業的發展帶來了許多阻力和不便。然而,云計算平臺的出現打破了這一限制,改變企業只能“購買整套硬件資源”的局面,使“租用計算機資源”成為可能。云計算作為一種新的計算方式,已經成為專家和企業研究的熱點。一些大公司已經推出了他們自己的云計算解決方案,像谷歌、亞馬遜和微軟這樣的大公司正試圖提供更強大、更可靠、更高效的云服務,并重塑他們的盈利模式。
■1.2 分布式軟件系統故障檢測的可靠性
在對企業調查的時候,從中了解到,一個小時的云計算系統中斷可能會讓一家公司損失15 萬到645 萬美元,并可能造成巨大的聲譽損失。因此,有需要建立一個有高可用性的云端運算系統,以確保云端服務的連續性和用戶服務的可用性,在提高系統可用性的同時不僅要能夠保證關鍵業務數據信息的完整性,而且能夠保持應用程序服務的中斷或無法迅速恢復。為了保證云計算系統的高可用性,必須有高效的故障診斷技術,因此云計算故障檢測技術已成為云計算領域的一個重要研究方向。由于現時并沒有技術可確保云端運算系統運作正常,不會出現故障,因此有需要減少故障次數及恢復所需時間,以確保可靠和持續的云端運算服務,只有有效地偵測到系統故障并正確地恢復,系統的可靠性才能得到保證。目前云環境下故障檢測方法主要從兩個方面進行如下
(1)心跳策略的故障檢測方法:通過對云計算系統節點及節點間的鏈路間通信出現的故障進行檢測。
(2)性能數據的故障檢測方法:通過分析云計算系統運行時產生故障數據(CPU 內存、硬盤、日志等)對云計算進行故障檢測。
綜上所述,國內外目前專門針對與平臺故障檢測與故障恢復能力測評的研究還非常少,雖然在故障檢測領域的相關研究中都會采取經典測評指標來驗證故障檢測方法的準確性、有效性等,但大都不成體系。
2 軟件系統故障檢測技術的系統結構
在故障檢測系統中,為能夠對云計算環境下所有節點進行監控,保證對每個節點準確覆蓋,必須對每個節點監控模式進行設計,在大規模的監控體系結構中最常用有兩種模式:基于層次式的監控模式和基于扁平的監控模式
(1)在層次式的監控模式中會分成不同的節點,不同的組來進行傳輸系統也會呈現出你個結構圖,在每一個結構組的節頭點都會對組內其他節點進行檢測,也可以通過組內的頭結點進行上傳消息,實現了對全局的一個掌控,這樣清晰的系統節點排序組織,并大大降低對信息傳遞的難度以及復雜性。層次式構圖如圖1 所示。
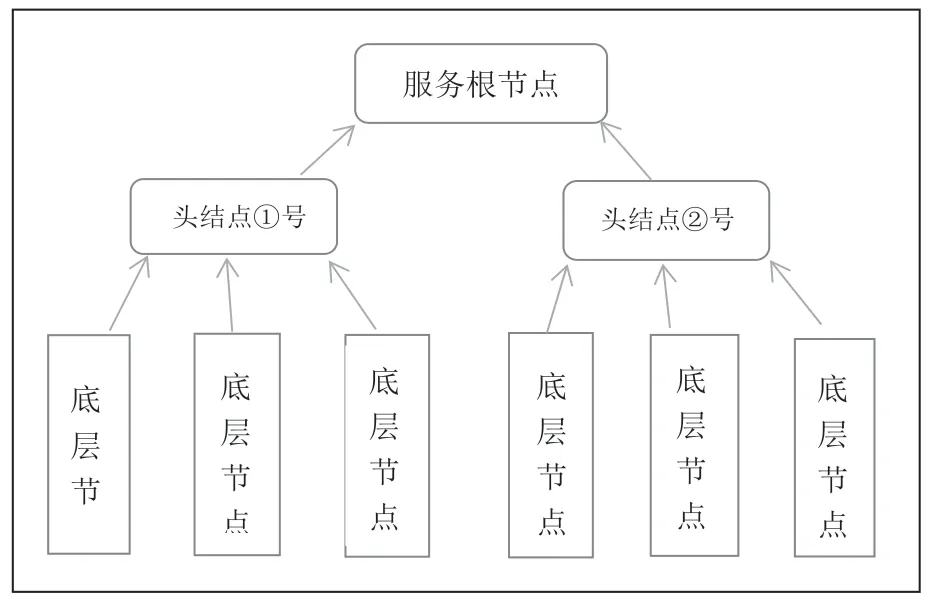
圖1 層次式監控模式
(2)扁平結構的模式節點沒有存在明顯的層次區分,二是呈現扁平化結構,該結構最最常見的就是隨即散播檢測了,消息并不是任意節點之間的傳播,每一輪消息傳遞過程,每個節點會根據概率選擇某些節點進行信息交換,在經過多輪交換后系統中會確保信息到達所有節點,根據概率交換避免信息的重復冗余。基于扁平模式的結構圖如圖2 所示。
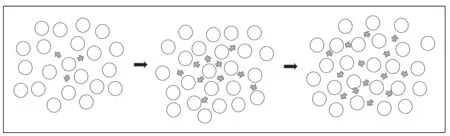
圖2 扁平結構的模式
3 分布式軟件系統故障檢測技術問題分析
(1)云計算系統遠比普通計算機系統復雜,即使能夠保證非常高的可靠性,也會出現一些故障或者錯誤。這些故障或者錯誤一般可以歸結為資源競爭、配置錯誤、軟件缺陷、硬件失效等,而且這些情況的出現往往具有不確定性,并且類似失誤難以再次重現等,但是這些故障的數量所占比卻例高達80%要保障云計算系統正常運行,只靠在系統開發測試階段往往不夠,并且一般問題是在特定環境下發生,同時后臺管理員難以人工跟蹤定位問題,因此故障檢測技術被廣泛應用。檢測技術通過對系統各個組件的故障檢測,自動及時有效檢測系統運行狀態,當檢測系統發現系統中有出現的程序漏洞或者服務失效時,及時報告給中心管理系統或者后臺服務者,為故障后提供故障策略,并對故障進行定位操作,及時處理失效服務,提高系統的穩定性和可信度。所以,故障檢測系統必須能夠保證對云計算系統內的組件等進行實時跟蹤,獲取實時狀態數據,檢測組件健康狀態。為保障了云計算系統的安全可靠性。
(2)云計算下的故障檢測系統主要是服務于云計算資源,故障檢測的目的是幫助管理員及時有效的發現云計算服務的各種故障或者潛在隱患錯誤等,避免人工排查實現高自動化檢測方式。從系統功能角度看,檢測系統主要是向用戶及時檢測云計算服務運行時的實時狀態,幫助用戶及時發現運行時的故障服務,能夠及時避免或者降低損失。
4 分布式軟件系統故障檢測的測評與實現
云計算平臺故障檢測與恢復能力的測評體系組成,包括負載、指標、測試流程與評估模型四個部分。測評體系的組成部分,直接體現了云測評工具需要具備的功能需求。從負載的解析與選取中分析,云測評工具需要控制云計算平臺中虛擬機的運行與終止,以及虛擬機中運行的應用程序的運行與終止;選取的指標決定了云測評工具中必須具備能夠獲取指定指標信息的能力,同時將指標進行存儲,用于最后的評估計算;測試流程的設計,指導了云測評工具如何控制整個測試過程的執行操作;最后,評估模型的建立,說明云測評工具需要具備對指標的計算與分析能力,同時將測評結果提供給云測試用戶。此外,為了讓云測試用戶能夠直觀觀察測試結果,以 Web 界面的方式提供可視化展示的功能。以及,根據不同的用戶需求,在云計算平臺中,提供不同的故障注入方式。
云計算平臺故障檢測與恢復能力的測評工具的模塊劃分與工具功能劃分一一對應,主要分為 Web 模塊、測試流程控制模塊、指標采集與存儲模塊、測試報表生成模塊與故障注入模塊。以下對不同模塊進行簡要介紹:
(1)Web 模塊主要提供工具功能的可視化顯示,便于云測試用戶的遠程訪問和控制。通過網頁提供測試過程、配置信息和測試報告的可視化;
(2)故障注入模塊,負責支持多種針對云計算平臺的多種故障注入方式,主要分為計算、存儲和網絡相關的資源故障與云計算平臺提供的計算、存儲等相關的服務故障。不同的故障,注入的方式也不同;
(3)測試報表產生模塊,基于評估模型的指導,對獲取的性能指標數據進行分析計算得出評估指標。生成的測試報表信息,包含測試日期、測試人員、云計算平臺環境配置、測試結果等多種信息,并存儲數據庫中;
(4)測試流程控制模塊,提供對云計算平臺故障檢測與恢復測試流程的控制,涉及對虛擬機的控制、虛擬機中負載發生工具執行情況的控制、負載接收集群的配置、測試環境清理等多種環節的控制,保證測試流程的正常運行,并最終為云測試用戶提供可視化的報表展示;
(5)指標采集與存儲模塊,該模塊主要分為兩個部分,分別為指標的采集與指標的存儲。指標的采集依賴于云計算平臺中運行的負載工具,而指標的存儲采用 Mongo DB 數據庫,有利于存儲多種格式的指標信息。
5 結語
隨著云計算部署模式越來也成熟,“云”的應用領域也來越廣泛,人們對云計算可用性要求越來越高。云計算故障發生的時間越長對企業和客戶的損失就越大,因此快速高效的故障檢測方法成為許多學者和專家的追求。計算機的出現徹底改變了整個互聯網商業模式,通過有效的資源共享和提高社會企業的效率,改變了傳統 it 基礎設施的高硬件成本和低資源利用率。因此,隨著政府和研究機構的廣泛推薦,越來越多的企業將其原有的業務系統遷移和部署到云計算平臺。云端運算服務供應商若要提升客戶體驗,達到客戶需求的目標,必須首先保證云端運算系統運作服務的可靠性,以確保客戶業務的正常運作。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
汽車維修與保養(2019年7期)2020-01-06 03:30:42
家庭影院技術(2017年9期)2017-09-26 03:41:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
