利用混合模型CRBM-PSO-XGBoost識別致密砂巖儲層巖性
2021-10-29 00:54:56谷宇峰張道勇鮑志東
石油與天然氣地質 2021年5期
關鍵詞:模型
谷宇峰,張道勇,鮑志東
[1.自然資源部 油氣資源戰略研究中心,北京100034; 2.中國石油大學(北京) 地球科學學院,北京102249]
準確獲取儲層巖性數據對于開展地層對比、沉積展布分析和地質建模等地質基礎工作至關重要,因此巖性識別一直被視為是一項關鍵研究內容[1-6]。經典的巖性識別工具為交會圖。交會圖一般是由2種或3種測井曲線構成的,而選取的曲線需要對各種所需識別的巖性都能有獨特的響應范圍[4-6]。故而,當測井數據點散落在交會圖中,各個巖性對應的測井響應劃分條件便可通過觀察來明確。對于砂質較純或者巖性成分簡單的儲層,該工具能夠有效地解決其巖性識別問題,但隨著油氣勘探范圍的擴大,非常規油氣逐漸成為了油氣研究方向上的核心對象,使得更多關于非常規儲層的巖性識別問題被提出。由于非常規儲層巖性成分復雜,且多數巖性在測井曲線上具有相似的響應特征,導致以交會圖為代表的經典識別工具難以適用,為此眾多地球物理學家發展了以機器學習技術為主的巖性識別方法[7-15]。
機器學習是人工智能的一個重要分支,其主要計算原理是在對學習數據分析的基礎之上,建立自變量與因變量的線性或非線性網絡映射關系,之后根據該關系完成對預測數據的處理。在模式識別領域,目前得到廣泛應用的模型有KNN(K-nearest neighbors),PNN(probabilistic neural network)和SVM(support vector machine)等[7-15]。KNN模型是聚類分析中的代表,主要是依據預測數據點與學習數據點之間距離的遠近進行模式判斷。由于不需要對學習數據進行訓練,所以KNN模型計算效率較高,而且因為預測數據點只會被聚類到距離最近的學習數據點的模式中,所以即使學習樣本中含有少量錯誤樣點,該模型仍能夠進行有效的判斷,體現出其容錯能力。趙彤彤等(2018)使用了一種基于模糊熵的KNN模型進行了巖性識別研究,并取得了較好的識別效果[7]。張梓童等(2019)分析了KNN模型的計算原理,并通過驗證明確了該模型在巖性識別上是一種有效手段[8]。PNN模型是一種基于概率密度分析模式的識別模型,其主要思想是先利用學習樣本建立各個模式的概率密度分布,之后根據預測樣本在分布中的概率值判斷歸屬。由于該模型采用了概率分析,較KNN模型在學習樣本處理上有更高的容錯性,而且概率密度分布的建立無需訓練,所以理論上其預測效率也較高。趙杰和李春華(2009)在巖性識別中嘗試了PNN模型,并取得了不錯的識別效果[10]。陳剛(2018)以隨鉆測井資料為基礎,利用PNN模型對煤層巖性進行了識別,驗證了模型的有效性[11]。SVM模型是監督學習中的代表,其主要計算思想是先通過訓練找到影響模式判斷的最重要的學習樣本(稱為支持向量),之后依據這些樣本完成數據預測。由此可見,該模型的預測效率和預測效果完全取決于支持向量的數量和質量,而不是通過全部樣本學習的,這就大大提升了模型的容錯能力和計算效率。李政宏等(2020)分析了機器學習技術在巖性識別中的重要性,并證明了SVM模型是一種有效識別模型[13]。根據SVM模型的特性,林香亮等(2020)使用PCA(principal component analysis) 模型對其進行改進,并驗證了PCA-SVM混合模型在砂礫巖巖性識別上具有良好的應用效果[14]。雖然上述模型在許多應用案例中都得到了一定程度的認可,但仍難以推廣。由于每個預測樣本都要和所有學習樣本進行計算,所以隨著學習樣本容量的擴大,KNN和PNN模型的計算效率將會嚴重降低;隨著學習樣本維度的增加,樣點間的距離值也會隨之增大,從而加大了KNN模型在模式判斷上的不確定性;建模需要多種經驗參數參與,如PNN模型的概率密度分布窗口長度和SVM模型的懲罰系數等,導致預測模型和預測結果難以確保為最優。
梯度提升是一類優秀的模式識別技術,其主要計算原理是先將目標值與計算值之間的差值作為訓練對象,再通過一系列CART(classification and regression tree)回歸樹訓練將差值減小,最后憑借由這些訓練后的回歸樹組成的強學習器完成預測[16-19]。XGBoost模型是這類技術的代表。由于該模型引入了正則化項,并精細化了學習公式,所以在訓練過程中大概率地避免了過擬合現象的發生,確保了訓練的可靠性;由于融入了并行計算技術,模型的計算效率不會隨著訓練樣本容量的擴大而出現嚴重衰減的現象。因此,該模型因其訓練穩定且計算效率高在巖性識別中也得到了關注[16-19]。Dev 和Eden (2019) 利用了該模型進行了巖性識別,并驗證了模型的有效性[18]。閆星宇等(2019)采用XGBoost模型研究了滲透率預測和儲層評價問題,發現該模型的應用對于測井解釋發展具有重要意義[19]。但需注意,XGBoost模型在建模過程中也有兩點不足:建模需要較多經驗參數參與,使得模型狀態難以確保為最優;當樣本維度變高時,為提高計算效率,模型可通過自身的隨機自變量采樣技術來實現,但這種隨機處理方式也會使得建模后模型狀態難以確保為最優。為使XGBoost模型在建模后達到最佳狀態,本文采用PSO (particle swarm optimization)模型和CRBM (continuous restricted Boltzmann machine)模型對其進行改進。PSO模型能有效解決參數優化問題,而CRBM模型因具有數據提取功能可從源數據中挖掘出更少且對因變量預測更為重要的新自變量,由此解決了樣本隨機降維的問題[20-25]。至此,本文提出利用CRBM-PSO-XGBoost混合模型來解決非常規儲層巖性識別問題。下文將對模型的計算原理和預測效果逐一分析。
1 計算原理
在本文中,由于巖性識別問題是利用由測井資料和巖性觀察數據建立的模型來解決,因此學習數據集中自變量應由測井曲線構成,而應變量由巖性觀察數據構成,可表示為A={Xmn,Ym},其中Xmn為測井數據矩陣,表示有m個樣本,而每個樣本由n條曲線構成,Ym為巖性觀察數據向量,有m個樣本。巖性觀察數據在程序中為字符信息,難以應用,為此采用one-hot coding(獨熱編碼) 技術進行編碼[16-19]。例如,巖性觀察數據為細砂巖,與之對應設定的原始編碼為2,而識別的巖性共有5種,則最終采用的編碼是一個長度為5且第二個元素為1的零向量,可表示為[0,1,0,0,0]。所以,Ym在編碼后可進一步變為YmK,其中K為識別巖性種類,也是每個樣本的長度。此時,因變量的樣本可表示為yi=(yi1,yi2,…,yiK)。XGBoost模型采用CART回歸樹進行迭代訓練,并在訓練后形成一個預測模型。預測模型稱為強分類器,其表達式如下[16]:
(1)
式中:Fk(xi)為作用在樣本xi上的第k類強分類器,i=1,2,…,m;wjk,d為在第d次迭代中第k棵回歸樹(即第k類回歸樹)的第j個葉節點中所有樣本的替代值,無量綱,k=1,2,…,K,d=1,2,…,D,j=1,2,…,J;η為學習速率,無量綱。
以公式(1)為基礎,確定樣本xi被分到第k類巖性的概率由下面的softmax函數計算[16-19]:
(2)
式中:Probk(xi)表示概率值,無量綱。
在所得的概率值中選擇最大值對應的巖性標記為樣本xi的預測巖性。公式(1)中的wjk,d由下式確定[16-19]:
wjk,d=-Gjk,d/(Hjk,d+λ)
(3)
(4)
(5)
式中:xi∈Rjk,d,Rjk,d為在第d迭代中第k棵回歸樹的第j個葉節點對應的區域;fk,d-1(xi)為在第d-1次迭代中作用在樣本xi的第k類學習器,其形式以公式(1)為準;L為損失函數,一般以交叉熵形式為主,在本文中為-yilln[Pl,d-1(xi)],P為公式(2)所示的softmax函數;λ為正則化系數,無量綱。
由于XGBoost模型在應用前要設置好框架,其中有較多經驗參數需要確定,如迭代次數、回歸樹分裂次數、正則化系數和學習速率等,因此建模后模型難以確保在最優狀態。本文采用在多目標最優化問題上計算效率高的PSO模型對其進行優化。在執行PSO模型之前,先要設定種群[20-22]。種群包含許多種子,而每個種子由需要優化的參數構成,所以種群可表示為:
Γ={σi|σi=(σ1i,σ2i,…,σzi),i=1,2,…,q}
(6)
其中,q為種子數量,σi為第i個種子,包含z個參數。之后,PSO模型通過下面的迭代公式計算各參數的最優值[20-22]:
(7)
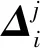
為計算方便,公式(7)中計算結果和目標結果應以原始編碼組成。前人研究結果顯示,在迭代前期采用較大的ω有利于全局搜索,而到后期采用較小的ω有利于局部搜索,為了能夠讓PSO模型高效地進行優化計算,本文采用LDIW(Linear decreasing inertia weight)算法使ω能夠在迭代中自適應地改變[20-22]。
XGBoost模型計算效率一般隨著樣本中自變量個數的增加而降低,因此Chen 和 Guestrin (2016)在創造該模型時為提高其運行速率提出了自變量隨機采樣算法[16]。該算法是在考慮自變量較多時,隨機選擇幾個自變量重組學習樣本,以讓XGBoost模型能夠通過處理容量更小的學習樣本來快速建模。由于自變量是隨機選的,難以保證這些自變量都能影響因變量的變化,為此本文提出采用CRBM模型方法對源數據進行處理,以實現在源數據降維的同時確保得到的新自變量都為關鍵變量。CRBM模型是通過連接可見層和隱含層之間的權重將源數據進行轉換,以此實現自變量由多變少的目的[23-25]。為確保轉換質量,CRBM模型一般要將提取的特征或者稱新自變量反轉化到可見層中,并將重構的數據與源數據進行對比,此時如果兩者之間的誤差在允許的范圍內,則表明轉化是有效的。CRBM模型的框架一般可表示為[23-25]:
(8)
式中:P為概率激活函數,由S函數(即sigmoid函數)確定;V為可見層數據矩陣;W為權值矩陣;H為隱含層數據矩陣;vi為第i個可見層數據向量;hj為第j個隱含層數據向量;σ為設定的噪音方差,無量綱;N為以標準正態分布為準的噪音,無量綱;φh和φl為S函數的上、下漸近線;μ為噪音控制參數,無量綱,當減小時能夠讓S函數從確定狀態變為二值隨機分布狀態;θ為迭代參數集,即在迭代中需要確定的參數集。
公式(8)表明源數據可通過第一分式轉到隱含層中,而隱含層數據可通過第二分式轉回到可見層,用于檢驗重構數據質量。公式(8)中需要確定的參數有W和μ,因此θ只包含該兩個參數,對應的迭代公式為[23-25]:
(9)
式中:Δwij,k為W第i行第j列元素在第k次迭代中的迭代步長,無量綱;Δμk為在第k次迭代中μ的迭代步長,無量綱,k=1,2,…,K;右上角標0和1分別表示迭代開始前的可見層數據和由隱含層重構得到的可見層數據。

(10)
公式(10)表明由隱含層重構的可見層數據將在處理最后一個mini-batch后得到。在確定步長之后,并在融合mini-batch技術情況下,CRBM模型的迭代公式可表示為[25]:

(11)
式中:ξ為動量系數,無量綱。
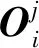
2 實驗驗證
2.1 數據來源及實驗設計
本次實驗以姬塬油田西部長4+5段(延長組4+5段)致密砂巖儲層為驗證對象。姬塬油田處于鄂爾多斯盆地中西部天環坳陷和陜北斜坡兩個一級構造單元之間,其整體構造形態呈一寬緩的北東-南西傾向的單斜(圖2)[26-29]。油田發育多個含油層系,其中長4+5段是主力開發層系之一。長4+5段為淺水三角洲沉積,主要發育三角洲前緣亞相,其儲層的形成受控于沉積展布,多為水下分流河道、水下天然堤和河口壩[26-29]。油田西部目前共有2 000多口探井和評價井,但只有少部分井具有巖心資料,因此為完成長4+5段的精細地層格架建立和沉積展布規律分析等工作,巖性識別成為一項關鍵研究內容。根據多口探井的巖心資料觀察,識別出目的層儲層主要巖性共8種,分別為中砂巖、細砂巖、粉-細砂巖、粉砂巖、泥質粉-細砂巖、泥質粉砂巖、粉砂質泥巖和泥巖。依據經典交會圖的設計原理,本次選用測井數據中顯示孔隙性的AC(聲波時差)、含泥性的GR(自然伽馬)和含油性的AT90(陣列感應電阻率)來劃分巖性。圖3a為AC-GR-AT90三維交會圖,可見8種巖性的測井數據點在圖中融雜在一起,難以進行區分。圖3b—d為3種曲線兩兩組合形成的二維交會圖,同樣,各個巖性的數據點在圖中仍有很大程度上的重合,導致劃分標準難以建立。圖3表明目的層的主要巖性不能由二維或三維交會圖進行識別,其原因是多種巖性具有相似的測井響應特征,使有效的巖性-測井響應識別關系無法形成。為此,本文采用機器學習方法來解決巖性識別問題,并根據在引言中的分析提出一種新的混合模型CRBM-PSO-XGBoost。模型結構及其計算流程已經在計算原理中進行了說明,并用圖1進行了展示,這里不再贅述。
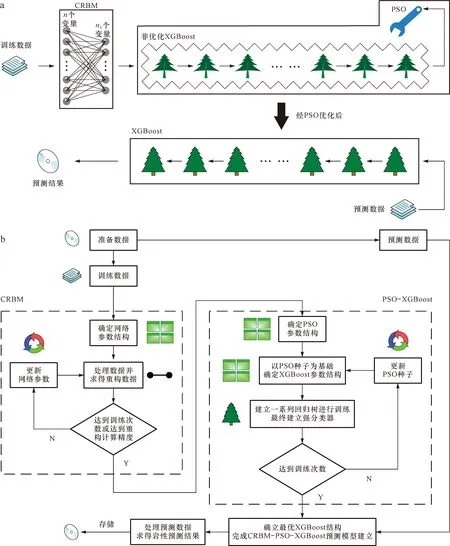
圖1 CRBM-PSO-XGBoost模型結構(a)及其計算流程(b)Fig.1 Structure(a)and computing flow (b) of the CRBM-PSO-XGBoost,a hybrid model proposed
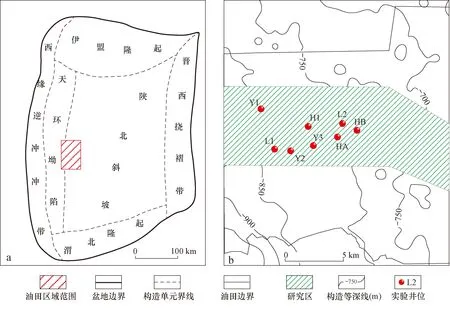
圖2 鄂爾多斯盆地構造區劃(a)及姬塬油田西部工區概況(b)Fig.2 Structural division (a) and outline of western Jiyuan oilfield (b), Ordos Basin
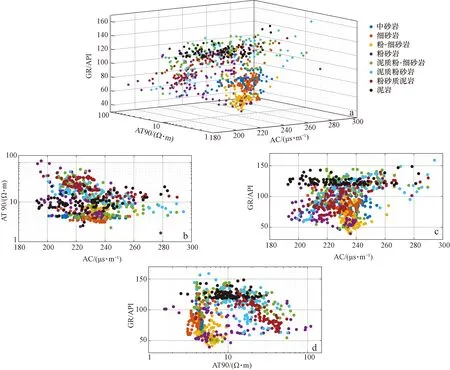
圖3 用于識別目的層8種主要巖性的三維和二維交會圖Fig.3 3D or 2D cross correlations used to identify 8 major types of lithology of target formationsa. AC-GR-AT90三維交會圖;b. AC-AT90二維交會圖;c. AC-GR二維交會圖;d. GR-AT90二維交會圖
為驗證所提出模型的預測能力,本文采用研究區8口取心井的測井及巖心觀察數據進行實驗,井位如圖2c所示。巖心觀察數據是根據每一個測井深度點對應從巖心柱上觀察所得到的巖性數據。Y1,Y2,Y3,L1,L2和H1井設為訓練井,即利用這些井的資料組成學習樣本,而HA和HB井設為驗證井,即利用兩口井的資料組成預測樣本。學習樣本共4 606個,而預測樣本每口井有300個。樣本由測井曲線和巖心信息組成,其中測井曲線有11種,分別是AC(聲波時差)、SP(自然電位)、GR(自然伽馬)、CNL(補償中子)、DEN(補償密度)、PE(光電吸收截面指數)和陣列感應電阻率(AT10,AT20,AT30,AT60,AT90)。巖心信息為巖心觀察數據的原始編碼經one-hot coding技術轉換后得到的信息。本次規定中砂巖、細砂巖、粉-細砂巖、粉砂巖、泥質粉-細砂巖、泥質粉砂巖、粉砂質泥巖和泥巖對應的原始編碼依次為數字1到8。所以,針對某一測井深度點,如果從巖心上觀察到的巖性為細砂巖,則與之對應的原始編碼為2,巖心信息為[0,1,0,0,0,0,0,0]。為簡易說明,巖心信息在表中用原始編碼進行了展示。實驗共有兩個,其中第一個實驗是利用由Y2,Y3,L2,H1資料組成的含有3 060個樣本的學習數據進行預測,第二個是利用全部學習樣本進行預測,其目的是檢驗預測模型的識別準確率是否會在增加訓練樣本量的情況下有所提升。為增強驗證效果,實驗中加入了PNN和SVM模型進行對比。
2.2 實驗過程及結果
在實驗1中,先驗證XGBoost模型是否在嵌入PSO模型和CRBM模型后其預測能力有所改變,之后再對所有預測模型進行對比。對于XGBoost模型,一組根據前人研究成果設定的經驗參數如表1的第3列上部分所示。進行優化前,PSO模型的計算參數也要設定。一組經驗參數展示在了表1中部。需要指出的是,PSO模型較XGBoost模型更容易找到一組理想的設置參數,這是因為PSO模型目的就是將模型參數進行調優以確保預測結果最為可靠,而這點很容易在PSO模型迭代計算中實現,即在不動XGBoost模型預先設置參數的情況下,PSO模型可通過簡單的參數調試甚至不用參數調試即可令XGBoost模型參數達到最優化,所以PSO模型的嵌入雖然增加了預先設置參數的工作量,但在實際操作上減少了調參工作量[20-22]。對于CRBM模型,一組設定的經驗參數如表2所示。
為使PSO-XGBoost混合模型更快速地完成建模,CRBM模型應從源數據中提取更少的特征,因此依據前人研究經驗,隱含層神經元個數可設置為測井曲線個數的一半[23-25]。由于CRBM模型目的只是提取數據特征,所以只要提取的特征滿足迭代條件即認為CRBM模型完成了任務,這使得該模型的調參工作也變得非常簡單。圖4展示了測井源數據和由CRBM模型得到的重構數據的對比情況。可見,各曲線的兩種數據的吻合度非常高,表明CRBM模型對源數據的提取是有效的。在完成CRBM模型處理后,分別利用原始學習樣本和提取特征數據對PSO-XGBoost混合模型進行訓練。圖5顯示了PSO模型作用在XGBoost模型上的優化過程。可以明顯地看出,PSO模型能夠有效地優化XGBoost模型,尤其是在處理提取特征數據的情況下。在完成XGBoost,PSO-XGBoost和CRBM-PSO-XGBoost 3種模型的訓練之后,預測目標便可進行處理,這里先以HA井為例。3種模型的預測準確率分別為51.00%,80.33%和92.67%,顯示出提出模型的預測能力最強。圖6以柱狀圖的形式展示了部分巖性預測結果。圖中取心道的信息為實際取心柱的觀察結果,已經通過深度校正歸位。為便于分析,在取心道上選擇了20個樣點進行對比。通過觀察發現,XGBoost模型結果中有10個錯誤樣點(No.1,3,5,10,12,14,15,17,18,19),PSO-XGBoost混合模型有6個(No.3,6,12,14,16,18),而提出模型僅有2個(No.12和18)。由對比可知,XGBoost模型在使用經驗參數的情況下得到的預測結果不能準確地反映巖性實際分布規律,而經CRBM模型和PSO模型優化后,其預測能力得到明顯提升,得到的預測結果非常可靠,可有效地反映儲層巖性分布情況。
在明確PSO模型和CRBM模型的嵌入對XGBoost模型的預測能力有提升作用之后,提出模型將與PNN和SVM模型進行對比。由于對比模型在建模時也需要用到經驗參數,因此為使所有驗證模型在預測時都能達到最佳狀態,PSO模型和CRBM模型也將對PNN和SVM進行優化。表2記錄了所有驗證模型參數的設置及其優化結果。對于驗證井HA,表3記錄了用3種優化模型得到的預測結果。可見,在相同優化的條件下,XGBoost模型以92.67%的高識別準確率成為預測能力最強的模型。圖7以柱狀圖的形式展示了HA井部分巖性預測結果。通過觀察發現,CRBM-PSO-PNN模型預測結果有6個錯誤樣點(No.2,6,9,14,16,18),CRBM-PSO-SVM模型有4個錯誤樣點(No.2,9,13,19),與提出模型的2個錯誤樣點相比,表中數據格式為(最小值,最大值)。

表1 驗證模型參數設置及優化結果Table 1 Parameters selected for the validation model and corresponding optimized data

表2 CRBM參數設置Table 2 Parameters selected for the CRBM model
反映出PNN和SVM優化模型所給的預測結果不能準確地描述儲層巖性分布狀況。
分析HA井預測結果之后,再利用3種模型對HB井進行預測。建模時,PSO模型和CRBM模型所用的參數設置不變。表3給出了3種優化模型的預測結果。結果顯示,混合模型CRBM-PSO-XGBoost的預測準確率仍為最高,達90.33%,再次表明提出模型的預測能力最強。
在實驗2中,所有4 606個學習樣本將用于建模,其目的是檢驗在訓練更多學習樣本的情況下,各驗證模型的預測能力是否有所加強。建模時,PSO模型和CRBM模型所用的參數設置與實驗1的一致。表3記錄了用3種優化模型得到的兩口驗證井的預測結果。通過對比發現:①在訓練更多學習樣本后,各驗證模型的預測準確率都有所提升,表明增大訓練樣本容量是提高模型預測能力的一種有效途徑;②提出模型的識別準確率最高,都超過了90%,不僅顯示出提出模型所得的預測結果可靠性高,還再次證明了該模型的預測性能最佳。
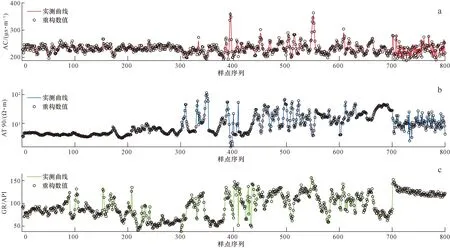
圖4 CRBM重構數據檢測Fig.4 Testing of reconstructing data for the CRBM modela. AC實測曲線與其重構數據比較;b. AT 90實測曲線與其重構數據比較;c. GR實測曲線與其重構數據比較
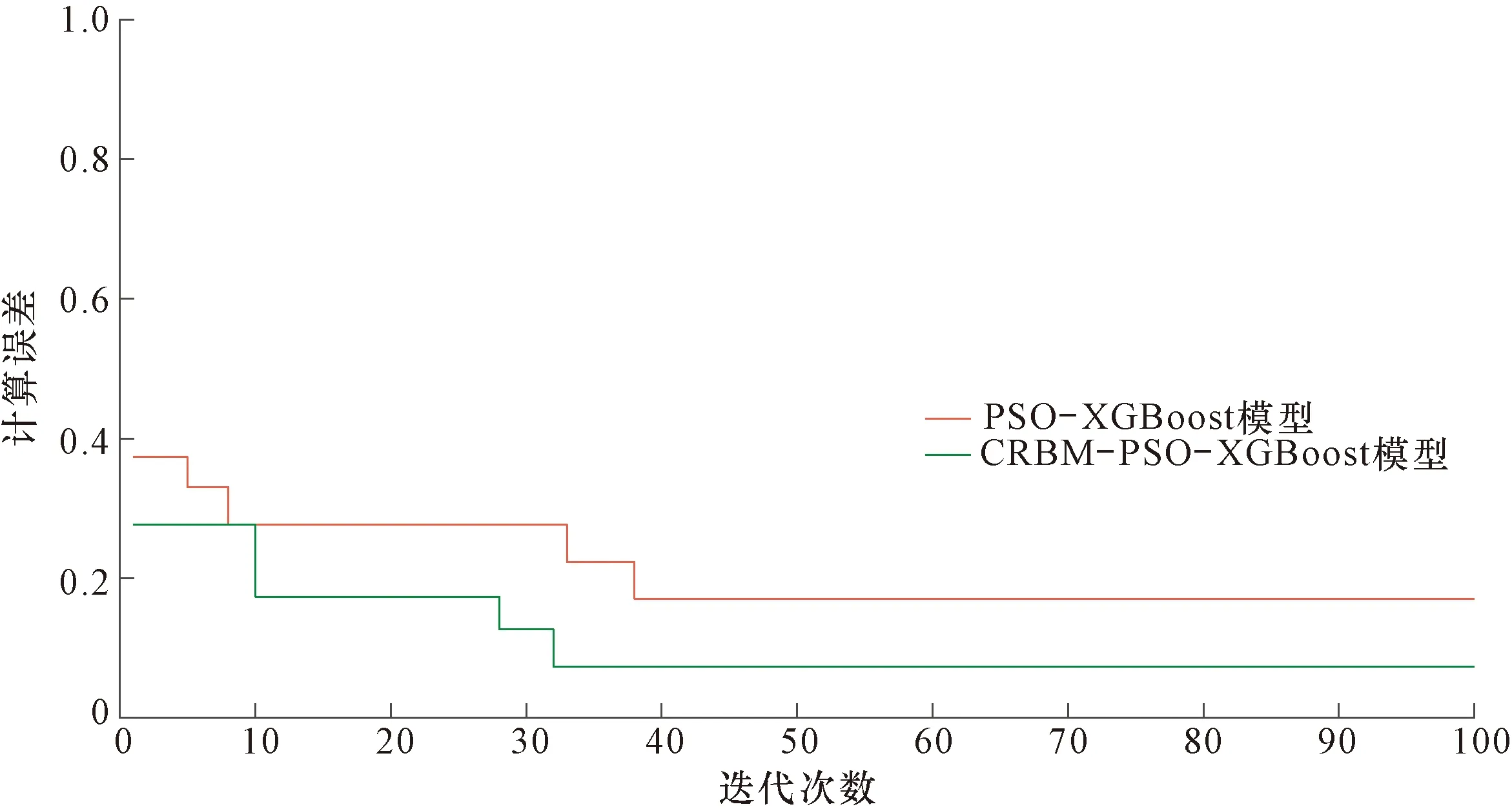
圖5 PSO-XGBoost和基于CRBM的PSO-XGBoost訓練優化過程Fig.5 Training optimization of PSO-XGBoost and CRBM-based PSO-XGBoost
表3中的計算時間數據顯示CRBM-PSO-PNN耗時最長,而CRBM-PSO-SVM的最短。對于PNN模型,由于每個預測樣本在預測時都要與全部訓練樣本進行計算,因此耗時最長,而且這種耗時會隨著訓練樣本容量的擴大而急劇增加(對比實驗1和實驗2的數據),表明在處理大數據時該模型效率低。SVM模型預測時,采用的是支持向量而不是全部學習樣本,所以耗時短。但與XGBoost模型相比,SVM模型在兩個實驗中的計算時間也都僅快10 s左右,這在巖性識別問題中優先考慮預測準確率的情況下,并沒有顯示出該模型的預測效率高,反而體現了XGBoost模型的預測效率高。因此,綜合來看,提出模型的預測效率最高,即使是在增大訓練樣本容量的條件下。

圖6 實驗1中HA井巖性預測信息柱狀圖Fig.6 Columns showing the predicted lithology in Well HA derived from the Experiment 1

圖7 實驗2中HA井巖性預測信息柱狀圖Fig.7 Columns showing the predicted lithology in Well HA derived from Experiment 2

表3 驗證井預測準確率和計算時間信息統計Table 3 Data summary of prediction accuracy and computing time of validation wells
3 結論
1) PSO在建模過程中能夠優化XGBoost多種經驗參數,為強化模型預測能力奠定了基礎。
2) CRBM模型可從源數據中提取更少但更利于分析因變量的新特征或稱新自變量,為提高PSO-XGBoost混合模型計算效率提供了途徑。
3) CRBM-PSO-PNN,CRBM-PSO-SVM和CRBM-PSO-XGBoost的預測能力可在訓練更多學習樣本的情況下得到提升,表明擴大訓練樣本容量是提升各驗證模型預測能力的一種有效手段。
4) CRBM-PSO-XGBoost相比于CRBM-PSO-PNN和CRBM-PSO-SVM能給出更為可靠的預測結果,且耗時也較短,表明該模型預測效率高,在解決致密砂巖儲層巖性識別問題上更具推廣性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
