基于生成對抗網(wǎng)絡(luò)的唇形重建改進方法
2021-10-29 03:54:02毛志煒朱錚宇
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用 2021年8期
關(guān)鍵詞:模型
◆毛志煒 朱錚宇
基于生成對抗網(wǎng)絡(luò)的唇形重建改進方法
◆毛志煒 朱錚宇通訊作者
(廣東技術(shù)師范大學(xué)電子與信息學(xué)院 廣東 510665)
在視覺語音識別(Visual Speech Recognition,VSR)研究領(lǐng)域,已有的研究表明,基于正面的視圖語音識別率是非常高的。而用于視覺研究的額葉面語料庫很少。一方面,研究者從非正面視圖(尤其是大角度)嘗試提高視覺語音的識別效率;另一方面,研究者試圖找到解決在現(xiàn)實場景下難以獲取正面視圖而從非正面視圖進行重構(gòu)正面視圖的方法。本文就是基于第二種方案,基于生成對抗網(wǎng)絡(luò)(GAN)強大的圖像生成能力,對多角度視覺庫中唇部進行正面視圖重建。本文模型采用了U-Net網(wǎng)絡(luò)結(jié)構(gòu),添加身份一致性損失Lid,在重構(gòu)正面唇形的同時,保留了身份特征。
視覺語音識別(VSR);GAN;U-Net;圖像重建;身份損失
1 研究背景
語音識別作為人工智能領(lǐng)域重要的一類,近些年發(fā)展非常迅猛。而視覺唇讀語音識別也是其中的研究熱門。我國語音技術(shù)發(fā)展相對于發(fā)達國家來說還不夠完善,尤其是視覺語音識別方便的研究相對甚少。缺少合適的語音視聽研究語料庫是存在的突出問題。
近些年,隨著硬件水平的提高,也帶動了深度學(xué)習(xí)領(lǐng)域飛速發(fā)展。深度學(xué)習(xí)成了繼人工智能、大數(shù)據(jù)又一熱門的詞匯。在深度學(xué)習(xí)領(lǐng)域,2014年基于自編碼器改進的對抗生成網(wǎng)絡(luò)的誕生,改變了傳統(tǒng)的機器學(xué)習(xí)方式,尤其在和卷積神經(jīng)網(wǎng)絡(luò)融合之后。現(xiàn)如今,對抗生成網(wǎng)絡(luò)成為圖像處理領(lǐng)域繞不開的一個模型。肖芳等[1-3]都是以往對人臉正面化的研究,由于人臉有多個面目特征,其由眼睛,鼻子,嘴巴,輪廓等組成,在復(fù)原人臉過程中就容易忽視掉局部器官的微小特征,為此本文提出基于生成對抗網(wǎng)絡(luò)新的方案實現(xiàn)唇形重建過程,以解決視覺語音中缺少正面語料庫的問題。
2 數(shù)據(jù)獲取與預(yù)處理
2.1 數(shù)據(jù)庫介紹
本文中使用的芬蘭奧盧大學(xué)機器視覺中心制作的多視覺視聽數(shù)據(jù)庫Ouluvs2,此數(shù)據(jù)庫有53位測試者,其中男女人數(shù)分別為40位和13位。數(shù)據(jù)庫從5個角度0°,30°,45°,60°,90°,6臺攝像機同時錄制,被測者從數(shù)字、短語、長句子三個方面進行說話,隨機的數(shù)字,日常用語和長句子。特別的數(shù)據(jù)庫針對嘴部區(qū)域制作唇部數(shù)據(jù)集。
2.2 圖像預(yù)處理
由于本文針對視覺唇讀演技語料庫缺少的問題,所以只對唇部的動態(tài)特點進行研究,為了減少gpu和內(nèi)存的消耗,提高運算效率,本發(fā)明對數(shù)據(jù)進行灰度化處理,同時按視頻的幀率進行剪裁,最后都歸一化,統(tǒng)一數(shù)據(jù)類型和數(shù)據(jù)形狀大小。
假設(shè)樣本(xxx,x),x為樣本中像素點的值,x表示中最小像素點值,x表示中最大像素點值,歸一化[-1,1]之間的值:

歸一化后的值,送到深度學(xué)習(xí)網(wǎng)絡(luò)當中,可以使求最優(yōu)解過程變得更加平緩,更容易正確的收斂。同時統(tǒng)一數(shù)據(jù)量綱以后,還可以消除一些奇異數(shù)據(jù)的不良影響。
3 唇形重建原理
3.1 對抗生成網(wǎng)絡(luò)
生成對抗網(wǎng)絡(luò),簡稱GAN(Generative Adiversarial Networks),由IJ Goodfellow[6]在2014年引入深度學(xué)習(xí)領(lǐng)域。隨后,基于GAN思想的創(chuàng)新百花齊放,誕生了許多優(yōu)異的GAN相關(guān)算法模型。
GAN的基本架構(gòu)由生成器和判別器組成,生成器G接受隨機向量生成假的樣本數(shù)據(jù)(),()和真實樣本同時輸入到判別器網(wǎng)絡(luò)進行判別。對于真實的數(shù)據(jù)判別器判斷為1,對于假數(shù)據(jù)判斷為0。判別器網(wǎng)絡(luò)訓(xùn)練的目標就是使得判別真假數(shù)據(jù)越來越精確,生成器網(wǎng)絡(luò)訓(xùn)練的目標就是使得生成的數(shù)據(jù)越來越接近1,騙過判別器網(wǎng)絡(luò)。最后無論是真或假樣本,都會被判別器判別輸出概率為0.5,此時生成器網(wǎng)絡(luò)模型達到最優(yōu)。
3.2 本文改進算法
3.2.1模型架構(gòu)
循環(huán)生成對抗網(wǎng)絡(luò)(CycleGAN)使用一個生成器和判別器網(wǎng)絡(luò)共享權(quán)值得到兩個生成器和兩個判別器,通過循環(huán)一致性損失,實現(xiàn)對圖像不同域的映射。如圖1,是本文改進單向CycleGAN實現(xiàn)過程。把X域轉(zhuǎn)向Y域的框架圖,X域中的樣本I送到生成器GXY中,得到I′,GXY把I′復(fù)原為I,使得I和I越接近越好,同時為了保證身份一致,生成器GXY對I進行驗證。判別器GY判別I和I′。

圖1 本文改進的模型框架
生成器的網(wǎng)絡(luò)架構(gòu)使用U-Net網(wǎng)絡(luò)模型。連接具有相同特征的圖層,可以很好地保留原域與映射域間共同的特征,減少相同權(quán)值的特征在網(wǎng)絡(luò)中傳播疊加,防止造成網(wǎng)絡(luò)訓(xùn)練成本增加。模型的卷積深度為13層,每層卷積核大小為4*4,步長為2。使用實例標準化(InstanceNormalization)加速模型收斂,保持每個圖像實例之間的獨立性。在反卷積層里面加入Dropout層,以防止過擬合。
判別器架構(gòu)使用馬爾科夫判別器,由全卷積層組成,輸出為30x30的矩陣。最后以矩陣均值作為真假判斷輸出,矩陣的每一個輸出都代表原圖中的感受野。這樣可使得生成器生成的圖像保持高分辨率、高細節(jié)。
3.2.2損失函數(shù)設(shè)計
假設(shè)有待重構(gòu)樣本集={1,2,3,…,a},額葉面唇部域樣本集={1,2,3,…,b},為了使域樣本特征重建為域,:→。實驗使用三部分損失對網(wǎng)絡(luò)進行優(yōu)化:
對抗損失:
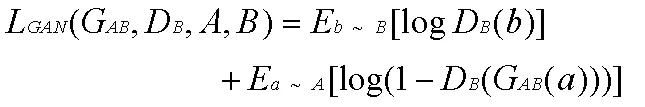
重構(gòu)總損失:
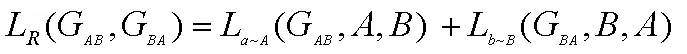
身份保持總損失:

由(1)到(3)組合,總的損失表示為:
其中,分別為生成器和判別器,為不同的樣本數(shù)據(jù)集。分別表示中的樣本數(shù)據(jù),和為超參數(shù)用于對網(wǎng)絡(luò)的影響。
4 實驗結(jié)果分析
4.1 訓(xùn)練環(huán)境設(shè)置
實驗使用3.3節(jié)中網(wǎng)絡(luò)框架,為每一個視圖創(chuàng)建一個模型,生成額葉面(正面)圖像。作為網(wǎng)絡(luò)的輸入,使用40位測試者的數(shù)字和短語視頻進行幀畫面截取,對12位測試者的幀畫面進行測試。本試驗使用英特爾酷睿i7-7700(3.60GHz)16G和NVIDIA GeForce 1070 8G的計算機進行運行,迭代200個周期,使用每個域各為1.2萬幀圖像,兩個生成器和兩個判別器都使用β=0.5,學(xué)習(xí)率為10-4對模型進行優(yōu)化,超參數(shù)設(shè)置=10,=10-2。
4.2 驗結(jié)果分析
如圖2所示,第一列依次為30°,45°,60°和90°真實唇部圖像,第二列為對應(yīng)的正面真實唇部圖像,第三列為我們每個模型對應(yīng)生成的唇部圖像,很好的生成正面視圖的開閉嘴特征,特別是高頻細節(jié)能夠很好保留。當角度增大時,接受特征減少,還原正面圖像的難度會增大。
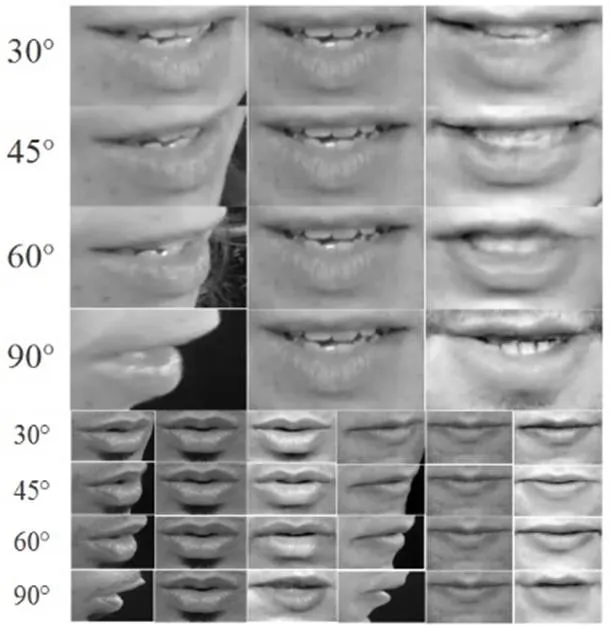
圖2 唇部圖像
原圖像生成圖像之間的結(jié)構(gòu)相似性(SSIM)和信噪比(PNSR)與view2view對比發(fā)現(xiàn),本文使用的方案結(jié)果有明顯提升(表1)。

表1 對比表
5 總結(jié)與討論
本文基于對抗生成網(wǎng)絡(luò)的改進方案,使用U-net網(wǎng)結(jié)構(gòu),加入身份一致?lián)p失很好地重建了正面唇形,本文的初始目標是解決視覺語音語料庫不足的問題,同時本實驗方案也可以用于人臉轉(zhuǎn)正,為人臉轉(zhuǎn)正也提供一個參考方案。本試驗不足之處,由于本身視覺語料庫的缺少,可供實驗的數(shù)據(jù)較少,本試驗基于實驗環(huán)境下數(shù)據(jù)庫有很好的效果,但面對更復(fù)雜的條件,比如含光照,噪聲等野外低分辨率數(shù)據(jù)還有待探究。
[1]肖芳.基于深度學(xué)習(xí)的多姿態(tài)人臉識別算法研究[D].四川:電子科技大學(xué),2019.
[2]馬佳欣. 基于深度學(xué)習(xí)的人臉正面圖像合成方法的研究與實現(xiàn)[D].北京郵電大學(xué),2019.
[3]錢一琛. 基于生成對抗的人臉正面化生成[D].北京郵電大學(xué),2019.
[4]Koumparoulis, Alexandros, and Gerasimos Potamianos. "Deep view2view mapping for view-invariant lipreading." 2018 IEEE Spoken Language Technology Workshop(SLT). IEEE, 2018.
[5]Rui Huang,Shu Zhang, Tianyu Li and Ran He, “Beyond Face Rotation:Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis”, arXiv:1704.04086,2017.
[6]Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks[J]. arXiv preprint arXiv:1406.2661,2014.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
