面向實際應用場景的實時行人檢測算法研究
2021-11-02 11:48:40桑海峰
微處理機 2021年5期
張 萌,桑海峰
(沈陽工業大學信息科學與工程學院,沈陽110870)
1 引言
在深度學習發展成為主流之前,傳統目標檢測算法的實現步驟為:先對檢測目標進行區域選擇,以SIFT[1]和HOG[2]等算法在區域范圍內提取特征,再將提取的特征放入分類器(SVM[3]和Adaboost[4])中進行分類任務。然而這一傳統目標檢測算法存在兩個問題:一是區域選擇沒有針對性,致使時間成本較高;二是魯棒性較低。隨著深度學習時代的到來,目標檢測算法也得到了巨大的改進,以卷積神經網絡為代表的另一種目標檢測算法已經出現。該算法又可以分為類:一類是基于Region Proposal(建議區域)的深度學習目標檢測算法,以R-CNN[5]為代表,除此還包括Fast-RCNN[6]、Faster-RCNN[7]等,都需要先產生建議區域,然后在這一區域上做分類與回歸。另一類則是一個單階段(one-stage)的基于回歸方法的深度學習目標檢測算法(YOLO[8]、SSD[9]等),通過運用一個CNN網絡就可以直接預測不同目標的類別與位置,提高了訓練速度。
行人檢測是目標檢測技術的主要分支,應用廣泛。在具有挑戰性的場景下,例如遮擋、模糊、形態變化等,檢測性能通常會受到影響。為解決這些問題Hariharan等人[10]將分割用作檢測的先驗,周春鑾等人[11]為應對不同的行人遮擋模式設計了模型。但這些方法并不完全適應于現實使用場合。趙祈杰等人[12]提出的M2Det網絡提出了多層次特征金字塔網絡來構建更有效的特征金字塔,用于檢測不同尺度的對象,取得了較好的檢測結果。但是由于M2Det需要使用8個TUM模塊,參數量巨大,訓練占用內存高,為此,此處在M2Det的基礎上加以改進,得到新的行人檢測網絡MCDET。
2 改進的VGG網絡
改進的基于M2Det的行人檢測方法MCDET整體流程如圖1所示。使用改良后的VGG網絡對輸入圖片提取特征,并且在VGG網絡中的conv4_3提取特征層后使用注意力模塊增強細節信息,再與pool5層后得到的特征通過特征融合模塊(FFM)中的FFMv1模塊進行初步融合。將融合后的基礎特征層依次輸入4個瘦化U形模塊(TUM)中進行U型特征提取,先不斷壓縮特征層,再進行上采樣操作融合特征,最終使用TUM模塊獲得6個有效特征層,對其使用FFMv2特征增強融合后再次輸入到下一個TUM中,依此方式一共通過四個TUM模塊,將輸出結果輸入到尺度特征聚合模塊(SFAM)中,最終得到所需的檢測層。
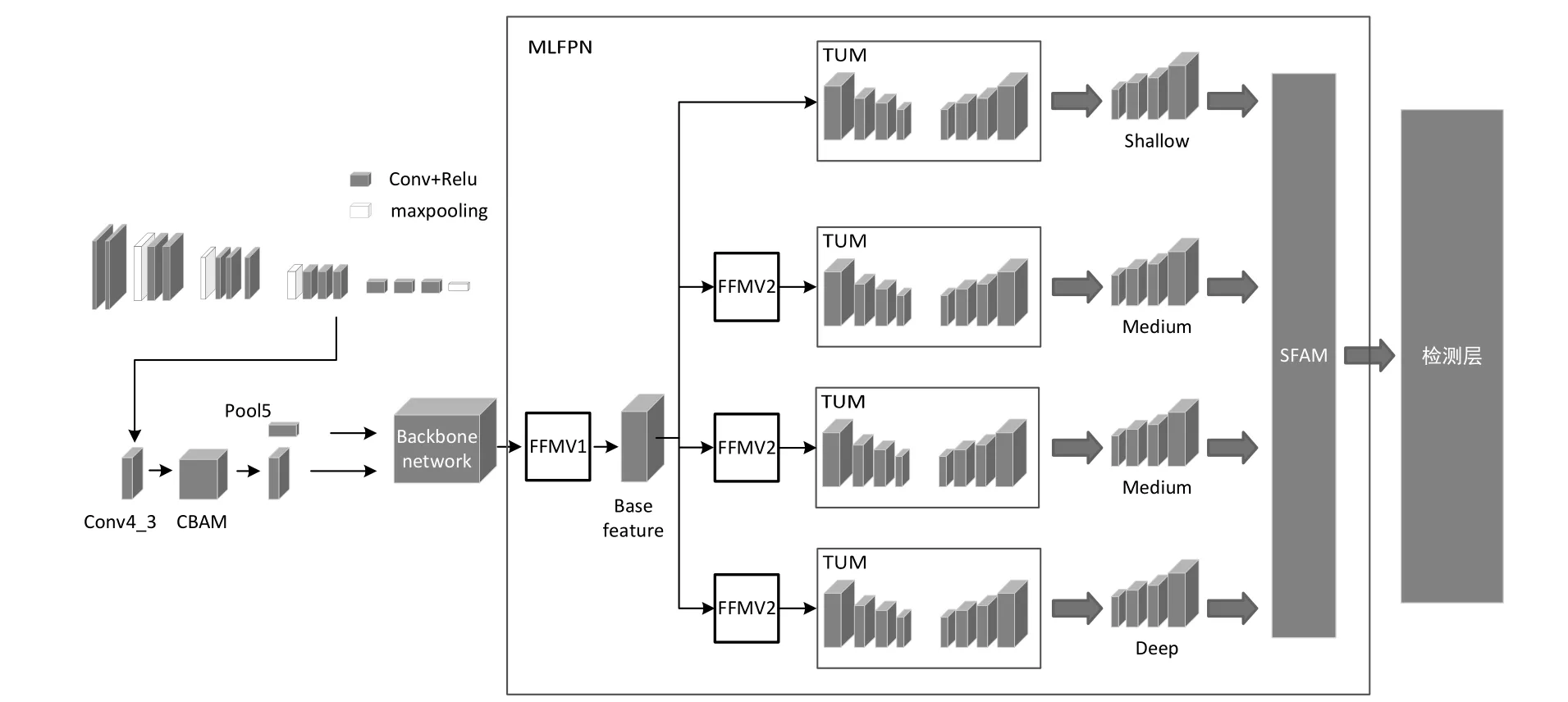
圖1 MCDET網絡結構圖
MCDET提取特征網絡采用的是VGG網絡,使用3個3×3卷積核來替換7×7卷積核,以及使用2個3×3卷積核來替換5×5卷積核。這樣做雖然增加了卷積核的個數,但提升了網絡深度,改善了網絡效果,同時保證感知野不變。VGG自身含有3個全連接層,這3個全連接層參數眾多,會產生大的計算量,占用大量內存。為解決這一問題,此處在VGG網絡的基礎之上做了一定改進:將VGG-16網絡結構中的3個全連接層刪掉以減少參數且對性能基本不產生影響;刪掉conv 4_3后的池化層使conv4_3作為提取的淺層特征信息,pool5作為深層特征信息。改進后的VGG網絡模型如圖2所示。
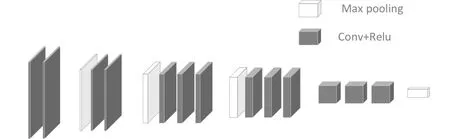
圖2 改進的VGG網絡結構圖
M2Det本身具有8個TUM模塊。TUM模塊使用簡化的U形結構,這一點上與FPN和RetinaNet兩種都不同。編碼器采用的是3×3卷積層,步長為2。解碼器解碼后得到多個特征層,制成特征集。當前級別的多尺度特征由當前TUM的解碼器中的所有輸出組成;多層次多尺度特征由堆疊的TUM的所有輸出組成;淺層特征、中等特征、深層特征分別由TUM的前、中、后分別提供。每個TUM經計算共有6210432個參數,如若使用8個TUM模塊參數量過于龐大,導致訓練時間長,內存占用量大,因此需要使用4個TUM模塊,將參數量減少至原有的一半,以減少訓練時長。
將原有的8個TUM模塊改為4個,在一定程度上減少了淺層信息的獲取,此時就需要在淺層特征層添加注意力機制來增強對淺層信息的獲取,即添加卷積塊注意力機制模塊(CBAM),其網絡結構如圖3所示。CBAM兼顧了空間注意力和通道注意力,與只關注一方面的注意力機制相比,取得了更佳的結果,尤其有助于對小目標捕獲能力的提升。
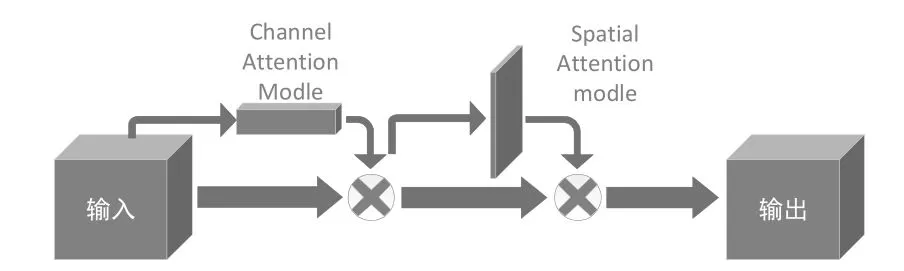
圖3 CBAM模塊結構圖
CBAM的通道注意力機制結構如圖4所示,其流程為:特征圖輸入后,通過基于width和height的全局最大池化和全局平均池化后再通過多層感知器(MLP)操作,最終加和;再使用Sigmoid對加和結果激活,生成最終的通道注意力特征圖。將所生成的特征圖與輸入特征圖做elementwise乘法操作,得到下一部分空間注意力模塊所需的輸入特征。
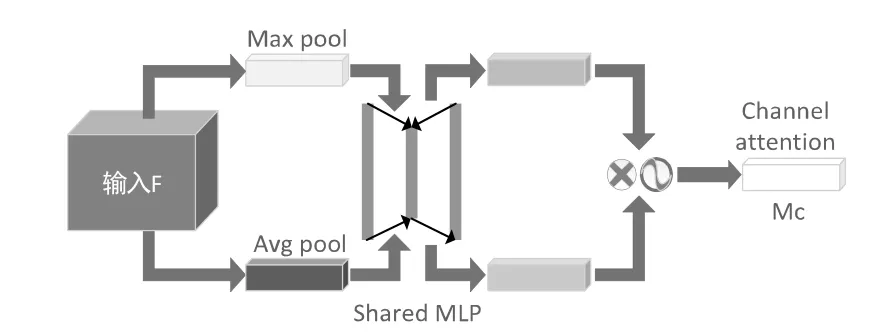
圖4 通道注意力機制結構圖
CBAM的空間注意力機制結構如圖5所示。結構流程為:輸入通道注意力產生的特征圖后,首先在基于通道的全局最大池化和全局平均池化的結果上做基于通道的concat操作。然后通過卷積操作將特征降維為1個通道。再使用sigmoid操作生成空間注意力的特征圖。最后將得到的特征和輸入的特征做乘法操作,最終生成特征即為使用CBAM模塊后得到的特征。
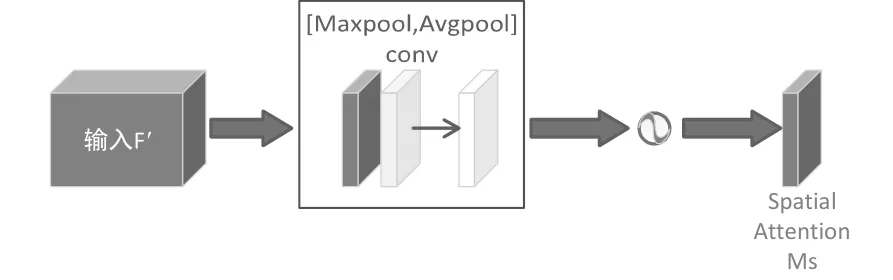
圖5 空間注意力機制結構圖
3 實驗結果與分析
實驗的軟件環境均在Ubuntu16.04系統下進行配置,使用的深度學習框架為Keras2.1.5;電腦顯卡為GeForce RTX 2080 Ti,顯存大小為11GB。主要采用Caltech作為數據集來完成對于改進算法的訓練和評估。
實驗采用目標檢測領域公認的平均精度(AP)來衡量模型的性能。將Caltech中122187張圖片劃分為訓練集和測試集,其中73312張圖片用于訓練,48875張圖片用于測試。不同算法在caltech數據集下的檢測結果如表1所示。可以看到改進的MCDET算法相較于yolo v3算法,以及相較于只有四TUM模塊的M2Det算法,在平均精度上均有不同程度的提高。

表1 不同算法在Caltech數據集下的平均精度
為實現面向實際情況的行人檢測系統,在實驗中也比較了算法的檢測速度,以檢測所需的時間來衡量,實驗結果如表2所示。由表中看到,雖然注意力機制的添加稍微延長了檢測時間,但相對于8個TUM的M2Det,檢測速度還是有些許提升的。

表2 不同算法的檢測時間
為更加直觀地體現MCDET模型的檢測效果,將改進算法與Yolov3開源代碼算法的實際表現進行對比,如圖6所示。其中,圖6(a)、圖6(b)為簡單場景下的檢測效果,圖6(c)、圖6(d)為復雜場景下的檢測效果;而圖6(a)、圖6(c)采用的是Yolov3源碼檢測,圖6(b)、圖6(d)則為MCDET改進算法的檢測效果。可以看出簡單場景下兩者檢測效果基本相同,但在復雜場景下MCDET對行人的檢測效果更佳。

圖6 算法檢測實際效果對比
圖7 顯示了MCDET算法針對遮擋的檢測效果。圖8為MCDET算法針對遠處小目標行人的檢測結果。可以看出在這兩種有代表性的實際應用場景下,該算法均有較為理想的良好表現。

圖7 對被遮擋行人的檢測效果

圖8 對遠處小目標行人的檢測效果
4 結束語
提出一種融合CBAM模塊的改進M2Det目標檢測模型的行人檢測方法MCDET,使得對于檢測較小目標的有效特征層能夠很好地融合,獲得一個較強的語義信息,并可以進行實時檢測。該模型在Caltech數據集中在保持精度的前提下實現了對于行人的實時檢測,具有實際意義。因為TUM模塊的減小,導致改進算法在精度上相較于Yolov3系列之后的算法還有所遜色,因此在后續研究中,對于像Caltech這樣的大規模數據集還應進行進一步的模型實現與分析,同時還應注重移動設備端的研究,如Tiny-Yolo之類的淺表替代模型,以在硬件有限的情況下提高準確性。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年8期)2016-10-09 02:11:50
