中醫文本實體關系的聯合抽取
2021-11-07 03:11:29盧苗苗牛亞琴王亞文王培
電腦知識與技術 2021年25期
盧苗苗 牛亞琴 王亞文 王培


摘要:中醫典籍凝聚了古人的智慧結晶及臨床經驗。近年來,中醫領域的實體識別和關系抽取任務受到了廣泛關注,并且一些聯合抽取方法得到了應用。為了進一步提高實體關系聯合抽取的效果,采用一種分層二進制標注框架對中醫領域的實體關系進行聯合抽取,充分結合了預訓練語言模型的優勢,解決了三元組重疊問題。實驗證明,該框架能有效地解決三元組重疊問題,在不同重疊模式下的中醫語料數據集上F1值均超過了75%。
關鍵詞:中醫文本;聯合抽取;實體識別;關系抽取;三元組重疊
中圖分類號:TP3? ? ? ?文獻標識碼:A
文章編號:1009-3044(2021)25-0179-02
1引言
一直以來,醫學實體關系抽取的相關研究大多都是面向英文醫學文獻的,且多為西醫知識的獲取。隨著自然語言處理(NLP)的廣泛應用,面向中文醫學文獻的研究需求不斷增加。在NLP任務中,命名實體識別和關系抽取任務是構建知識庫的必不可少的步驟,同時也是最重要的部分,并且基于這兩個任務的聯合抽取方法越來越受到關注。當前針對中醫領域的相關實體識別以及實體之間的關系抽取的研究仍然非常稀少。為了能夠獲取大量的中醫語料,并進行深入挖掘,在未標注的語料中先進行預訓練,然后與下游任務模型進行結合。
實體關系聯合抽取可以自動化地從輸入文本中抽取出包含某種關系類型的實體對,構成實體關系三元組。因此,科研人員提出了使用聯合模型,利用兩個任務之間的潛在信息來解決這個難題,但是傳統的聯合模型一般又嚴重依賴于復雜的特征工程。Miwa[1]等人沒有直接對整個句子建模,沒有考慮同一句子中其他實體對的關系。2017年,Katiyar[2]直接對整個句子建模,但是無法處理多關系的問題。Wang[3]等人通過設計一個有向圖機制將聯合抽取任務轉換為一個有向圖問題,使用基于轉移的解析框架來解決,但是只解決了一個實體和多個實體之間存在關系的重疊問題,并沒有解決同一實體對存在多個關系的重疊問題。2018年,Zeng[4]等人是第一個在關系三重提取中考慮重疊三重問題的人,并嘗試通過具有復制機制的序列到序列(Seq2Seq)模型來提取三元組。
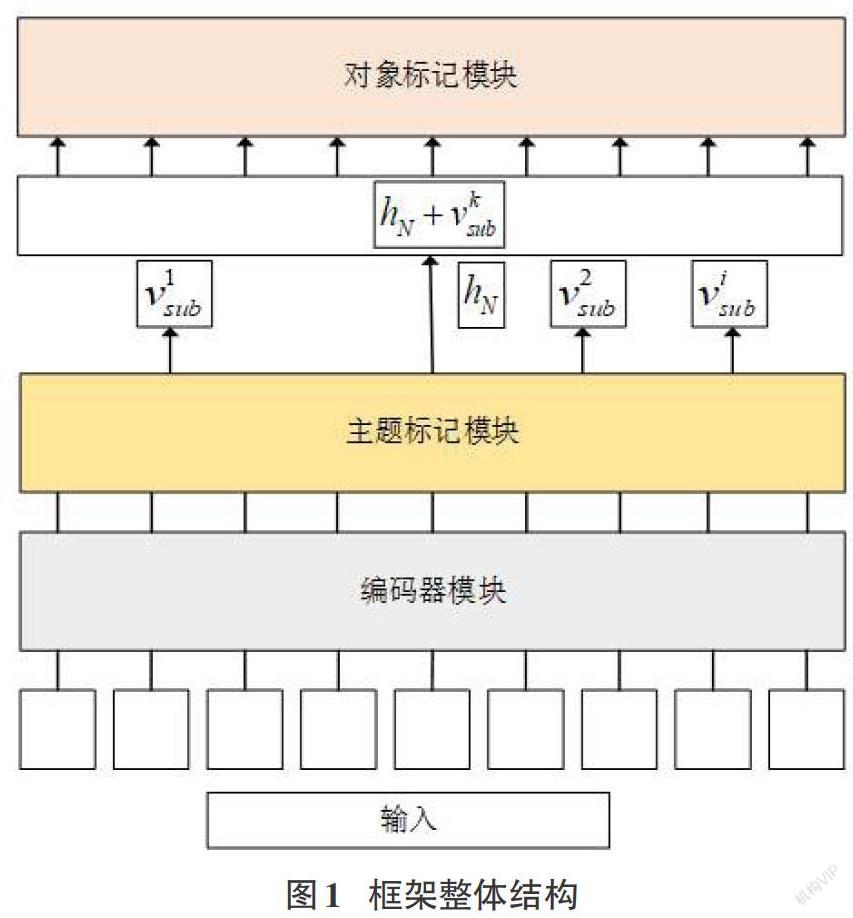
本文所采用的框架思想來源于Wei[5]等人提出了一個分層二進制標注框架,該框架由基于BERT模型的編碼器模塊和分層解碼器模塊組成。其中,分層解碼器模塊又由主題標記模塊和對象標記模塊組成,圖1展示了框架的整體結構,下文稱為聯合框架。
2聯合框架
在這種聯合框架下,首先,確定中醫文本句子中所有可能的主題實體,比如“前胡清肺熱,化痰熱,推陳致新之藥也”,然后針對“前胡”這個主題實體,應用關系特定標記器來同時識別所有可能的關系和相應的對象。
2.1 編碼器模塊
采用預訓練的BERT模型對輸入的中醫文本上下文進行編碼。從句子中提取特征信息,并將提取的[hN]、[vksub]等信息放入后續的標記模塊中。BERT是基于多層雙向Transformer的語言表示模型,其中[x]表示輸入向量。具體操作如公式(1)(2)所示:
其中[S]是輸入句子中子詞索引的一元向量的矩陣,[Ws]是詞嵌入矩陣,[Wp]是位置嵌入矩陣,其中[p]代表輸入序列中的位置索引,[hα ]是隱藏狀態向量,即輸入句子在第[α]層的上下文表示,[N]是Transformer塊的數量,[Trans(·)]—Transformer塊。
2.2 解碼器模塊
分層解碼器由主題標記模塊和特定于關系的標記模塊組成。主題標記模塊通過直接解碼[N]層BERT編碼器產生的編碼向量[hN]來識別輸入句子中的所有可能主體。更準確地說,它通過選擇兩個相同的二進制分類器分別為每個標簽分配0或者1的標簽來指示主實體的開始和結束位置,從而分別檢測實體的開始和結束位置。主題標記器對每個標簽的詳細操作如公式(3)(4)所示:
其中[pistart_s]和[piend_s]分別表示將輸入序列中的第[i]個標簽識別為對象的開始和結束位置的概率。如果概率超過某個閾值,則將為相應的標簽分配為1,否則分配為0。[xi]是輸入序列中第[i]個標簽的編碼表示,即[xi=hN[i]],其中[W]表示可訓練的權重,[b]是偏差,而[σ]是sigmoid激活函數。
3實驗
3.1實驗數據
本文以中醫古籍文本為實驗對象,研究中醫文本實體關系的聯合抽取。首先通過中醫相關的醫學專業網站對中醫文本爬取了總計約700本中醫古籍。并用正則的表達式對字符串進行清洗,除去漢字以外的字符、換行符以及空格等。例如,將“淡白而瘦小,- -氣血兩虛”這句話,經過正則方式處理完之后就變成了“淡白而瘦小,氣血兩虛”。接著以句子為單位對文檔按照句號,問號進行拆分,得到大約180萬個句子。由于中醫文本具有中國古代的語言風格,通常也會出現一些虛詞,停用詞,且對句子含義的理解毫無意義,我們通過剔除停用詞表中出現的詞,進行特征提取,這本質上也屬于特征選擇工作的一部分。最后,對句子使用jieba分詞工具加載詞典的方法來為中醫文本分詞,得到對應的詞序列。
經過以上處理,得到一批訓練、測試數據,將數據按照關系三元組是否存在共享同一實體的情況,即存在重疊關系,按照不同重疊模式將句子劃分為兩類:一對一實體無關系重疊,多實體多關系重疊共享,并對這些中醫實體關系三元組進行詳細實驗。
3.2實驗結果
為進了證明聯合框架具有良好的解決三元組重疊問題的能力,本文分別在不同重疊情況的中醫語料數據集上統計聯合框架的查準率、召回率和F1值。表1為聯合框架在中醫語料數據集上不同重疊模式下的F1值。
實驗結果表明,在不同重疊程度的中醫數據集上F1值都高于75%,說明該聯合框架具有優越的解決三元組重疊問題的能力。
