一種循環迭代的智能語料標注系統
2021-11-08 02:37:22劉勇陸小慧
廣東通信技術 2021年10期
[劉勇 陸小慧]
1 研究背景
在人工智能飛速發展的今天,特別是在認知智能的智能問答系統研發過程中,語料的標注和校對工作一直需要消耗大量的人力和時間。眾所周知,人工智能領域的算法模型需要通過訓練大量的語料得到,這些訓練語料被事先進行標注,往往通常都是人工標注,標注過程需要耗費大量人力和時間。
因為標注的過程實際上是對語料中語言單位的特征進行解釋的過程,不同的人可能會有不同的解釋結果,所以語料標注帶有很大的主觀性。不同標注者的知識結構和語法理論也各不相同,如果只以少數人的標注結果作為訓練語料,訓練出的算法就可能有較大的誤差。
本文研究旨在積累歷史語料標注結果對算法模型訓練的效果,降低語料標注工作的人力和時間成本投入,降低標注過程中的失誤率,提高語料標注的準確率和效率。
2 系統定義與關鍵技術
語料標注,是對原始浯料進行加工,把各種表示語言特征的標簽標注在相應的語言成分上,以便于計算機的識別和讀取。包括:實體標注、詞性標注、句法標注、分類標注、情感標注、篇章關系標注等。
本文研究并通過實施例詳細說明了一種語料標注方法和系統,即根據預設的算法模型對待標注語料集中的語料進行標注,基于標注結果生成對應的訓練集,通過訓練集更新算法模型,用于下一次語料標注。通過本文實施例的實施,以每一次標注后的結果來更新算法模型,從而大大減少了人工標注的工作量,同時提升了標注的一致性和準確性。本系統分為如下3 個模塊。
①語料標注模塊,用于根據預設的算法模型對待標注語料集中的語料進行標注;
② 訓練生成模塊,用于基于標注的結果,生成對應的訓練集;
③算法訓練模塊,用于通過所述訓練集更新所述算法模型,用于下一次的語料標注,如圖1 所示。
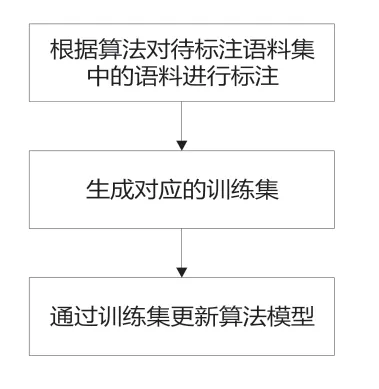
圖1 語料標注方法流程圖
首次語料標注工作需要采用原始的人工標注方式,將標注結果作為訓練語料用于初始算法模型的訓練。從第二輪迭代開始,只需將前一次標注的語料訓練得到的算法模型,應用于為標注語料設計的標注系統中。該語料標注系統可自動將現有語料同領域的不同細分小類的語料進行標注,且準確率較高,并篩選出少量當前算法未覆蓋到的無法實現自動標注的語料,在下一輪迭代中進行人工標注。假設第三輪跌代出現不同領域的語料時,則需要人工參與新領域語料的標注,并將語料標注結果應用于算法模型的訓練中。從第四輪迭代開始,只需將第三輪跌代輸出的算法模型,再次應用于當前語料標注系統,使智能標注系統得到擴展,算法覆蓋面更大,準確率更高,標注系統更加智能,可自動化實現新一種領域的語料標注工作。
如此循環迭代,語料標注系統可隨算法訓練和人工標注新領域語料的持續作用日益完善,變得更加智能,從而大大提高語料標注的工作效率,降低相似語料的人工標注成本。
對于同領域相同子類的語料,如果將多人多次標注的結果持續積累起來,從一定程度上能降低人工標注主觀性引起的誤差。
該系統不受限于算法或數據的類型,無論是文本、音視頻還是圖片圖像的數據,以及對應于這些數據的各種算法,都可以按照這種循環迭代的方式構建一個標注系統,來實現智能化的數據標注。具體來說,該系統實現分4 個部分:①對算法模型未覆蓋語料進行人工標注;② 用標注的語料進行算法模型訓練;③將算法模型應用于智能標注系統中;④ 智能標注系統對同領域新語料實現自動化標注。
下面對該系統的實現流程加以說明,如圖2 所示。
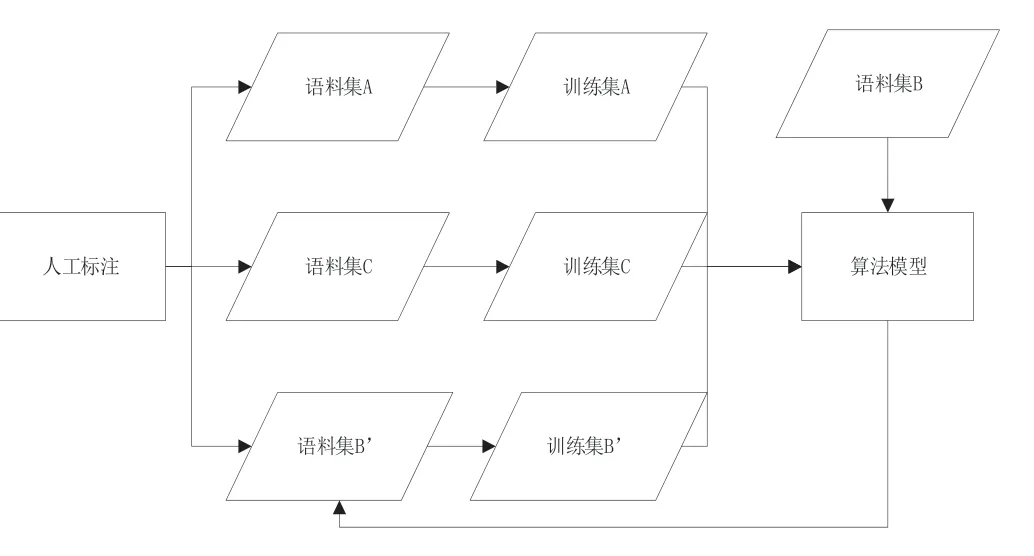
圖2 語料標注示意圖
其中,語料集A 作為初始語料集,以人工標注的形式進行標注并生成訓練集A,基于訓練集A 訓練出了算法模型,此處即為初始算法模型。語料集B 作為與語料A領域相同的語料集,也就是與算法模型領域一致的語料,可直接通過集成了該算法模型的自動化標注系統進行標注;該自動化標注系統除了集成了算法模型之外,還具備一些標注所需的其他組成部分,比如工作流、權限控制等相關功能。盡管如此,語料集B 中還有領域之下的類別不同的語料集B’,不能直接通過算法模型進行標注,而采用人工的方式進行標注。語料集C 是與語料集A 領域不同的語料集,也就是與算法模型領域不一致的語料集,直接通過人工標注的方式進行標注。
不管是對語料集B的標注,還是對語料集B’的標注,還是對語料集C的標注,最終均生成對應的訓練集,通過訓練集來更新算法模型,作為下一次的語料標注所參考的算法模型。
此外,還可以包括,根據在各次算法模型對待標注集中的語料進行標注時,語料集B 在待標注語料集中的占比,和/或各次標注的準確率,評估算法模型對待標注語料的標注能力是否達標。在每一次的語料標注中,根據待標注語料的領域與算法模型的領域的相同與否,會對應產生相應的語料集B 和語料集C,根據可以直接標注的語料集B 在待標注語料集中的占比可以確定算法模型的標注能力;另外,每一次對于待標注語料集的標注之后,再經過校驗就可以得知標注的準確率,根據準確率也可以確定算法模型的標注能力。在得知算法模型的標注能力之后,如果算法模型的標注能力較弱,或者是標注能力不達標,則可能需要繼續借助語料集進行訓練,逐步完善算法模型標注能力。
基于標注的結果生成對應的訓練集。生成訓練集是為生成算法模型,以及更新算法模型提供了可能,由于初始算法模型已經根據對初始語料的人工標注生成了,因此后續的訓練集都是作為更新算法模型而用。
通過訓練集更新算法模型,用于下一次的語料標注。下一次的語料標注一般都是參考上一次的語料標注更新后的算法模型來進行,而迭代的次數越多,覆蓋的領域越廣,因此需要人工參與的次數也越少,標注的準確率也越高。為了保證語料標注的可靠性,通過訓練集更新算法模型可以包括:對訓練集進行校驗;在校驗完成后,通過校驗后的訓練集對算法模型進行更新。基于標注的結果對訓練集進行校驗可以包括:以抽查的方式從訓練集中隨機抽取部分進行校驗;或以全量的方式,直接校驗訓練集中的所有內容。
3 具體實施方式
下面具體描述一下細化的流程,如圖3 所示。
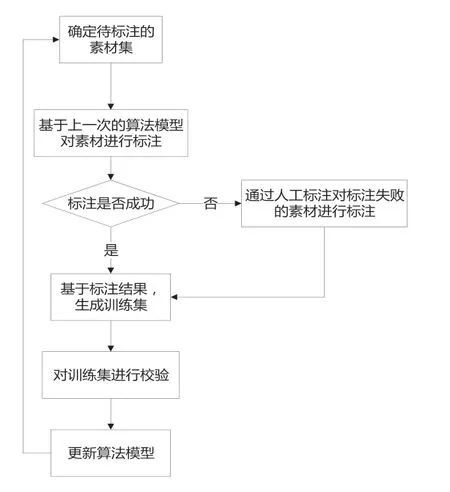
圖3 標注方法細化流程圖
我們先確定待標注的語料集:語料可以包括智能問答系統中的語料,文本識別中的文本,以及音視頻、圖片等多媒體語料。
基于上一次語料標注后的算法模型,對待標注的語料集中的語料進行標注;語料中往往包含了很多很豐富的內容,但是計算機可能不能直接的識別和讀取,因此需要對這些語料進行標注,標注也就是對語料庫中的語料進行加工,把語料中的各種特征以計算機可識別的方式進行標注。
算法模型根據迭代階段的不同,大致可分為初始算法模型和過渡算法模型兩類;初始算法模型,也就是在本次語料標注中第一個算法模型,這個算法模型大致決定了以后所有相關的語料標注的算法邏輯。過渡算法模型指的是在初始算法模型之外的算法模型,與初始算法模型不同,過渡算法模型通常是持續變化的。
判斷標注是否成功,也就是從語料中篩選出語料集B 和語料集C的過程;而確定待標注語料集中的語料集B和語料集C的方式,可以是通過關鍵詞篩選等等方式進行,或者是由人工參與進行判斷,或者是直接假設都是相同領域的直接進行標注。對于無法直接標注的部分則分離出來作為不同領域的語料集C 進行人工標注。
基于標注結果,生成訓練集。生成訓練集就為生成算法模型,以及更新算法模型提供了可能。由于初始算法模型已經根據對初始語料的人工標注生成了,因此后續的訓練集都是作為更新算法模型而用。
為了保證語料標注的可靠性,可對訓練集進行校驗,具體的校驗方式可以包括:以抽查的方式從訓練集中隨機抽取部分進行校驗;或者以全量的方式,直接校驗訓練集中的所有內容。
通過校驗后的訓練集更新算法模型,返回供下次標注新的語料集;并通過人工標注對標注失敗的語料進行標注。
下面對技術方案的實施做進一步的詳細描述,如圖4所示。
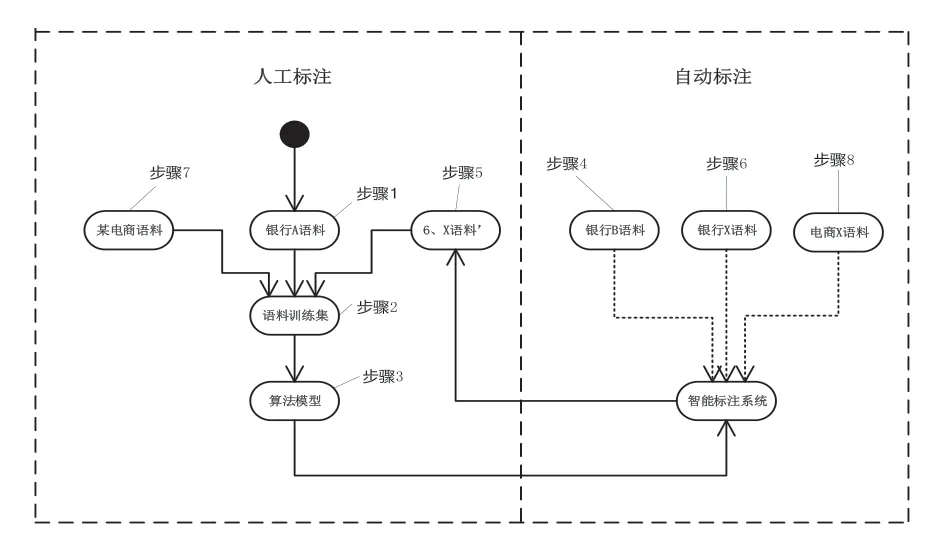
圖4 銀行業務語料標準流程示意圖
本實施例中的語料標注方法以銀行的業務語料為基礎,通過訓練相應的算法模型和循環迭代,來實現自動標注。智能語料標注系統不斷將用新語料訓練得到的算法模型進行集成,標注系統以循環迭代的方式得到擴展和優化。
以智能語料標注系統以建行業務語料為基礎,將訓練出的算法模型集成,經過迭代后可以自動對中行語料進行標注為例,循環迭代的智能語料標注系統實現步驟如圖4 所示。
步驟1,確定第一批銀行A的業務語料;
步驟2,形成銀行A的語料訓練集;
步驟3,基于銀行A的語料訓練集訓練生成算法模型,嵌入智能標注系統中;
步驟4,第二批銀行B的業務語料需要進行標注時,判斷銀行A 和銀行B的業務語料同屬于銀行領域的語料,屬于同一領域的不同子類,大部分業務用語、詞匯相似,于是將銀行B的業務語料輸入智能標注系統中進行自動化標注。根據需要自動標注的語料規模,可考慮部署分布式智能標注系統。
步驟5,對于銀行B的業務語料中,無法通過智能標注系統中的算法模型自動標注的部分,形成X 語料’,人工對X 語料’進行標注,此時大大降低了人工標注的工作量和耗時。人工標注的結果形成第二批訓練集,再次執行步驟2、步驟3,從而實現了算法模型的更新,智能標注系統得到第二次優化和擴充。
步驟6,當第三批銀行X的業務語料需要標注時,重復步驟4 中的操作,從而實現了算法模型的更新,智能標注系統得到再一次優化和擴充。
步驟7,當第四批某電商的客服語料需要進行標注時,判斷電商的客服語料和已人工標注過的銀行語料不是同一領域的語料,用語、詞匯差異很大,于是人工對某電商客服語料進行標注。形成第四批訓練集,再次執行步驟2、步驟3,從而實現了算法模型的更新,智能標注系統得到第四次優化和擴充。
步驟8,當第五批電商X的客服語料需要標注時,重復步驟4 中的操作,從而實現了算法模型的更新,智能標注系統得到第五次優化和擴充。
如果需要對同領域同子類型的語料進行標注,使用智能標注系統對這些語料進行自動化標注,如果智能標注系統已經過多輪迭代和優化擴充,這批語料理論上可以完全實現自動化標注且準確率達標。
分析智能標注系統對同領域不同子類、同領域相同子類新語料的自動化標注比例和準確率,可以判斷是否需要收集更多更豐富的語料來繼續訓練算法模型。
4 總結
本文研究并提供了一種人工智能認知智能領域的語料標注方法和系統,首先確定已生成的算法模型,根據算法模型對待標注語料集中的語料進行標注;基于標注結果生成對應的訓練集,通過訓練集更新算法模型,用于下一次語料標注。通過本文舉例實施例的實施,以每一次標注后的結果來更新算法模型,從而大大減少了人工標注的工作量,同時也提升了標注的一致性和準確性。
每當一批新語料需要進行標注時,人工判斷這批新語料是否屬于現有領域及子類,如果屬于現有領域的新子類,則用標注系統自動標注,并篩選出系統無法覆蓋到的未實現自動標注的語句進行人工標注;如果屬于新領域的語料則直接進行人工標注。
根據實現自動標注的語料所占新語料的百分比,結合標注系統對現有領域新子類語料歷次能實現自動化標注比例經驗值及標注準確率,及人工對這批新語料類別的判斷,可分析出當前該標注系統在某領域某子類的自動化標注能力是否達標,是否需要更多的該領域語料來訓練算法。
如果需要自動標注的語料規模較大,該智能標注系統可考慮分布式部署。
該系統不受限于算法或數據的類型,無論是文本、音視頻還是圖片圖像的數據,以及對應于這些數據的各種算法,都可以按照這種循環迭代的方式構建一個標注系統,來實現智能化的數據標注。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
