基于程序層次樹的日志打印位置決策方法?
2021-11-09 05:51:38張齊勛吳中海
軟件學報 2021年9期
賈 統,李 影,張齊勛,吳中海,
1(北京大學 信息科學技術學院,北京 10087 1)
2(北京大學 軟件工程國家工程研究中心,北京 10 0871)
3(北京大學 軟件與微電子學院,北京 10260 0)
隨著人工智能技術的發展,Gartner 提出智能運維(AIOps)技術的概念[1],即:通過機器學習等算法分析從多種運維工具和設備收集而來的大規模數據,自動發現并實時響應,以增強IT 運維能力和自動化程度[2].在AIOps技術趨勢下,基于系統日志的大規模分布式系統自動化故障診斷技術發展迅速.這些技術通過分析和挖掘系統日志,構建刻畫系統正常運行時的請求執行路徑的模型,然后自動檢測系統運行時的日志序列與模型之間的偏差,以實現精確異常檢測和故障診斷.然而,這種基于日志的自動化故障診斷技術存在一個重要的瓶頸,即系統日志的質量.對大規模軟件如Apache,Squid,PostgreSQL 等的系統失效報告分析發現[3],77%的系統失效歸結于幾種常見錯誤模式,而這些錯誤模式中有超過一半(57%)并沒有被記錄在系統日志中,導致自動化故障診斷模型無從分析與檢測,從而需要花費大量人工和時間成本來定位、診斷和修復這些錯誤.
現今,軟件系統開發缺乏統一的日志打印標準和規范,其日志打印決策依賴于程序開發人員的個人理解和調試需求.由于軟件開發人員的編程風格、領域知識和需求的不同,程序中日志打印的風格、內容、位置也大相徑庭,由此引發分布式系統日志質量的參差不齊.有調研表明:即使是在國際領先的軟件企業,也很難找到明確的高質量日志打印規范或指導;即使采用專業的日志打印框架如Log4j,Self4j 等,程序開發人員仍需根據相對片面的領域知識進行日志打印決策[4].由于大規模分布式軟件系統代碼量巨大,且結構復雜,人工在系統中添加或修改日志幾乎是不可能的.因此,實現日志的自動化打印決策并提高日志質量的需求越來越迫切.
高質量的日志應具備3 個特征[5].
(1)日志打印的位置合理,即系統運行時產生的日志能夠反映系統運行時狀態的變化;
(2)日志中包含的信息豐富,即日志的文本信息能夠幫助系統管理人員理解系統的運行行為;
(3)日志打印的數量適當.過多的日志會增加系統運行時開銷,同時冗余和無用的日志不利于從日志中搜索和辨識故障信息.
本文關注日志打印位置決策問題,為解決該問題,有研究人員提出通過代碼分析的方法得到若干日志打印位置的規則[6]或日志打印位置[7];也有研究人員提出機器學習的方法,通過學習日志打印位置附近的代碼特征,構建日志打印位置決策模型[4].然而,相關研究工作中存在兩個重要問題:(1)特征提取方法受限于特定編程語言,且日志打印位置決策的區域有限制,例如僅能夠對Exception 模塊的日志打印位置進行決策;(2)現有工作的日志打印位置決策模型無法有效處理不同軟件系統在特征空間上的差異,很難實現跨軟件系統的日志打印位置決策.因此,如何為由不同編程語言實現的不同軟件系統實現自動化與智能化的日志打印位置決策并提高日志質量,仍然是一個亟待解決的難題.
針對該問題,考慮到已多次更新升級的成熟軟件往往具有良好的日志打印策略[8],本文提出一種基于程序層次樹與遷移學習的日志打印位置決策方法,通過有效遷移成熟軟件系統的日志打印知識,來為目標系統決策日志打印位置.具體的,以代碼塊為單位切分軟件系統代碼,構建程序層次樹提取代碼塊子向量,并采用子樹上提和逆序組合的方式提取代碼塊的結構特征和上下文特征,以生成代碼塊特征向量;采用遷移學習的方法構建成熟軟件系統與待決策的目標軟件系統日志打印程序的共同特征空間,使用機器學習模型學習特征空間中的特征向量分布,以實現跨軟件系統的日志打印位置的決策.本文的創新之處在于:(1)提出一種通用的代碼特征向量自動化提取方法,通過構建程序層次樹,屏蔽編程語言與程序模塊實現細節的異構性,以支持不同編程語言編寫的軟件系統;(2)提出一種基于遷移學習的日志打印位置決策模型,利用遷移成分分析算法(transfer component analysis,簡稱TCA)和聯合分配適配算法(JointDistribution adaptation,簡稱JDA)將不同系統特征向量的特征向量映射到新的公共特征空間,進而削減特征差異,以支持跨軟件系統的日志打印位置決策.
在由兩種編程語言實現的 5 個成熟的軟件系統 Apache Ha doop[9],TencentAngel[10],OpenStack[11],SaltCloud[12]和Tensorflow[13]的實驗表明,本文所提出的方法在跨組件、跨相同編程語言的不同軟件系統的日志打印位置決策均具有良好的效果.例如,在以Hadoop 的代碼作為訓練集決策Tencent Angle的日志打印位置實驗中,本方法達到了0.969 的準確率和0.925 的F1.
本文第1 節介紹日志打印位置決策的相關研究工作.第2 節對日志打印決策問題進行明確.第3 節詳細介紹本文提出的日志打印位置決策方法.第4 節給出相關實驗,驗證提出方法的效果.第5 節總結本文的工作,并探討未來的研究工作.
1 相關工作
1.1 基于規則的日志打印位置決策
這類方法通常使用統計分析方法從成熟軟件系統中總結日志打印規則,并使用這些規則構建日志打印位置決策模型.Yuan[6]設計了一個ErrLog 的工具,通過人工分析成熟軟件系統的日志打印語句,總結日志打印的規則,并利用這些規則決策新的日志打印位置.該工具的關鍵問題在于:其僅關注Error 或Warn 級別的日志打印位置,并假設這些日志打印位置均位于異常處理程序中.Fu 等人[8]對微軟的兩個大規模分布式系統日志打印語句進行了分析,總結出其中的若干日志打印策略,然后利用這些策略構建了一個日志打印決策模型.該方法的不足在于:其僅對諸如異常處理,返回值校驗等特殊的代碼結構進行日志打印位置決策.
1.2 基于機器學習的日志打印位置決策
這類方法使用機器學習算法從成熟軟件系統源碼中學習日志打印語句周圍的代碼片段特征,進而構建日志打印位置決策模型.微軟的Fu 等人[8]利用決策樹模型構建了一個日志打印位置決策模型,基于該工作,Zhu 等人[4]提出了一個日志打印位置決策工具LogAdvisor,該工具通過提取系統源碼的3 種類別特征,構建了一個分類模型以決策一段代碼是否應該添加日志打印語句.上述兩種方法和工具的不足在于,其僅能針對異常處理和返回值校驗的代碼片段進行日志打印位置決策.另外,由于這兩種方法提取的特征依賴于編程語言的語法支持,因此難以拓展到其他語言編寫的軟件系統中.例如,LogAdvisor 提取的特征中包括Throw 和Empty CatchBlock 的數量,但是在腳本語言中,通常少有這種類型的特征.Lal 等人[14]提出了LogOptPlus 的日志打印位置決策方法,該方法通過提取18 個統計類型特征和10 個文本類型特征,利用機器學習算法構建日志打印位置決策模型.該方法的不足在于:其限制日志打印位置決策的區域為“if”和“catch”代碼結構,難以拓展.
同基于規則的日志打印位置決策相比,基于機器學習的日志打印位置決策方法具備如下關鍵優勢.
?首先,日志打印的復雜性導致人工總結日志打印位置難以為繼.日志打印決策需要考慮多方面因素,包括故障診斷、性能記錄、安全程度和對系統帶來的額外負載等,因此難以對不同的軟件系統人工總結普適的日志打印策略;
?基于機器學習的日志打印位置決策假設成熟軟件系統中包含良好的日志打印規律,且這些規律能夠被機器學習算法捕獲[8],從而將該問題轉化為一個智能的有監督學習問題;
?另外,機器學習模型能夠伴隨訓練數據的不同而演化更新,而基于規則的日志打印位置決策方法的更新優化依賴于人工,難以為繼.
因此,本文同樣基于機器學習算法構建日志打印位置決策模型,旨在提出一種普適的特征提取方法和模型構建方法,突破現有工作中的諸多限制,如編程語言限制、代碼結構限制等.另外,本文關注于跨組件、跨軟件系統的日志打印位置決策,而現有工作關注于軟件系統內部的日志打印位置決策.
1.3 特定任務驅動的日志打印位置決策
這類工作通常利用程序分析及信息理論技術等從軟件代碼中搜索符合特定任務需求的日志打印位置.Ding 等人[15]提出了一種日志過濾方法,該方法通過監控系統的性能,搜索對系統性能影響最大的日志打印位置,然后過濾這些日志打印位置.Zhao 等人[7,16]利用程序分析技術,通過計算不同日志打印位置帶來的信息熵增益,找到能夠區分最多程序路徑的日志打印位置作為決策結果.我們之前的工作[17]設計了一種面向故障診斷的日志打印位置決策方法,該方法利用信息增益算法從所有日志打印位置中搜索能夠最大限度表征故障的日志打印位置.這類方法同基于機器學習的日志打印位置決策方法是相輔相成的關系,同時,運用這兩類方法能夠有效提升日志打印位置的質量,達到更加智能化的日志打印位置決策.
2 問題定義
日志打印位置決策的目的是從系統源碼中選擇需要添加日志打印語句的位置(代碼行),但是現有的軟件系統規模極其龐大,代碼量巨大,導致需要添加日志打印語句的位置占所有日志代碼行的比例小于1%,這會導致訓練數據極度不平衡,難以構建機器學習模型.為解決該問題,本文首先定義了代碼塊(CodeBlock)的概念,并使用代碼塊作為日志打印位置決策的基本單位,即,將該問題轉化為對代碼塊中是否添加日志打印語句進行決策.
代碼塊是一段不包含任何層次或嵌套結構的代碼片段.代碼塊的提取可以通過兩種標識符切割,包括分支或循環的起點和分支或循環的終點.以圖1 為例,該圖截取了Hadoop-YARN 項目中RMAppManager.java 文件中的一個函數,通過“{”和“}”對該函數進行切分,共獲取了5 個代碼塊.本質上講,代碼塊是一段順序執行的代碼行的集合,以代碼塊為基本決策單位,能夠有效降低日志打印位置決策問題的復雜性,大大降低訓練數據的不均衡程度.通常而言,一個代碼塊內部的日志打印語句通常表征該代碼塊的功能或執行結果,因此大多數情況下,一個代碼塊中通常只包含一個日志打印語句,且這個日志打印語句的具體位置不重要.經過對hadoop 2.8.1 源代碼的統計分析發現:在包含日志打印語句的所有代碼塊中,有12 812 個代碼塊僅包含一條日志打印語句(占比95.1%),658 個代碼塊包含多于一條日志打印語句(占比4.9%).以圖1 中代碼塊1 的日志打印語句為例,不論該語句位于代碼塊1 中的哪一行,該日志打印語句所表達的信息不受影響.另外,代碼塊作為一個抽象的概念,具備較強的通用性,能夠適配不同的程序開發語言編寫的軟件系統.代碼塊不同于程序基本塊(BasicBlock):基本塊的劃分以程序功能為依據,包括一個單一入口和出口;代碼塊則是以程序結構為劃分依據,其粒度小于基本塊.經過對hadoop 2.8.1 源代碼中所有代碼塊包含的代碼行數進行統計,結果表明,平均每個代碼塊包含4.443 行代碼.因此,對于日志打印位置決策任務而言,以代碼塊為粒度決策日志打印位置,能夠有效地輔助程序開發人員打印日志.
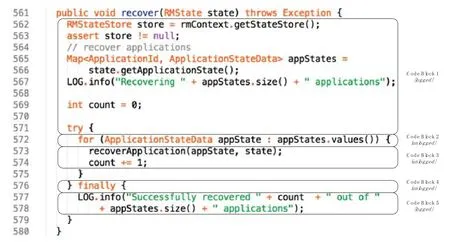
Fig.1 Example of program and code block圖1 程序片段與代碼塊示例
以代碼塊為基礎,這里明確本文的研究目標.
令某代碼塊為cbi∈{cbx|0≤x≤p},其中,p代表所有代碼塊的數量.本文旨在構建一個日志打印位置決策模型F(~),預測代碼塊cbi的標簽類型為logged 或unlogged,形式化如下:
labeli=F(cbi).
其中,labeli∈{logged,unlogged}.
3 方法概述
圖2 給出了本文所述方法的整體流程和框架.
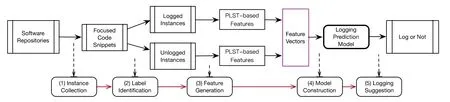
Fig.2 Workflow of our approach圖2 方法流程
本方法包括實例收集、標簽標識、特征向量生成、模型構建和日志打印決策這5 個關鍵步驟.實例收集以代碼塊為單位切分源代碼;標簽標識即從代碼塊中搜索日志打印語句,方法為關鍵詞搜索,如LOG,logging,logger等.通過實例收集和標簽標識,初步得到模型訓練數據實例為
instancei=(cbi,labeli).
如果cbi包含日志打印語句,則labeli取值為logged;反之,取值為unlogged.特征向量生成步驟通過神經語言模型為每個代碼塊生成一個特征向量,稱為子向量,然后組合一段程序中的代碼塊子向量,最終生成完整的特征向量.第3.1 節會詳細介紹特征生成步驟的方法.模型構建步驟首先通過遷移學習算法屏蔽不同組件或不同軟件系統代碼特征空間之間的差異,然后使用機器學習算法構建分類模型.第3.2 節詳細介紹模型構建方法.日志打印決策步驟利用已訓練的分類模型對新的軟件或新的組件中的代碼塊進行日志打印決策.
3.1 基于程序層次樹的特征向量生成
特征向量生成首先利用神經網絡語言模型從每個代碼塊中提取特征向量(下文稱為子向量),以提取代碼片段的文本特征;然后,針對每個代碼塊,組合與其位于相同函數中的其他代碼塊的子向量以生成完整的特征向量,以提取代碼片段的上下文和結構特征.本文提出的特征向量生成方法具有3 個特點.
(1)通用性,適用于不同的編程語言;
(2)全覆蓋性,能夠針對所有的代碼塊生成特征向量,對代碼塊或代碼片段無假設;
(3)自動化.與傳統特征工程不同,該特征生成方法無需任何人工定義或指導.
下面詳細介紹這兩個步驟.
3.1.1 基于神經網絡語言模型生成代碼塊子向量
為了提取代碼文本特征,需要為每個代碼塊生成固定長度的特征向量(即子向量):首先,按照空格和符號切分每個代碼塊,將其轉換成單詞列表;然后使用神經網絡語言模型PV-DM 學習單詞列表,訓練模型對其生成向量表示.PV-DM 模型由輸入層、投影層、隱藏層和輸出層組成:在輸入層,使用1-V 編碼對段落中的段落ID 和前N個詞語進行編碼,其中,N是用戶定義的參數,V是詞匯表的大小;然后,使用共享投影矩陣將輸入層投影到具有維度(N+1)×D的投影層P;輸出層則是經典的SoftMax 分類器.訓練過程中,使用隨機梯度下降法來訓練段向量和字向量,并且通過反向傳播來更新梯度.最后,使用訓練過的D維向量作為每個代碼塊對應的子向量.
3.1.2 基于程序層次樹逆向組合代碼塊子向量
一個代碼塊中是否打印日志,不僅受代碼塊本身內容的影響,還受到其相鄰代碼塊的影響.例如,圖1 中的Codeblock5 中僅包含日志打印語句,而其相鄰的代碼塊則描述了程序邏輯,為該日志打印語句提供了豐富的上下文信息.此外,分支、循環等復雜的程序結構也對日志決策產生重要影響.直觀地說,開發人員更可能在這些復雜的代碼結構中添加日志打印語句,以幫助理解程序邏輯和行為.因此,有必要組合相鄰代碼塊的子向量以捕獲代碼塊的上下文特征和結構特征.
受AST 的啟發,本節提出了一種代碼語法結構的粗粒度表示方法——程序層次樹(program lay ered syntax tree,簡稱PLST)作為組合子向量的基礎.與AST 中每個節點表示變量、關鍵字或運算符等細粒度結構相比,PLST 中的節點表示代碼塊,能夠有效降低復雜性并提高特征提取的效率.令待生成特征向量的代碼塊為目標代碼塊,則在PLST 基礎上如何提取目標代碼塊的附近的代碼特征,即如何組合目標代碼塊附近的代碼塊子向量是一個難題.原因在于:
?第一,影響日志打印位置的程序范圍很難確定.從編程習慣的角度來看,日志打印語句被用來記錄剛剛發生的某個事件或行為,因此對于目標代碼塊而言,最影響日志打印決策的程序片段應該是該代碼塊之前的程序片段;另外,代碼塊的日志打印決策也受到程序功能和代碼邏輯的影響,而函數是程序中最小的功能邏輯單元,因此本方法將函數內目標代碼塊及其之前的代碼塊子向量進行組合,從而完整地表示目標代碼塊;
?第二,鄰近代碼塊的上下文信息極其相似,會極大地混淆日志打印決策模型.兩個鄰近代碼塊周圍的程序文本非常相似,甚至大部分程序文本是相同的,但其數據標簽卻很有可能是完全不同的.這將極大地混淆決策模型,降低決策效果.針對該問題,本節提出一種逆序組合的方法,采用相對位置代替絕對位置,組合目標代碼塊前的代碼塊子向量,從而生成目標代碼塊的特征向量.
每棵PLST 代表一個函數,根表示函數名稱,節點表示代碼塊.每一個代碼塊所處的層由其位于程序中的嵌套層次決定,同一層中的代碼塊嚴格遵循其在代碼中的先后順序排布.每個PLST 通過深度優先遍歷可以恢復成原程序代碼.為獲取PLST,不同編程語言的代碼塊由于語法不同而需要少量適應性處理.例如,Java 中的分層標識為“{”,Python 中則為4 個空格.圖3 展示了程序結構和功能完全相同而編程語言不同的兩段代碼,這兩段代碼可以被轉換成同一棵PLST.

Fig.3 Example of PLST of different programming languages圖3 不同編程語言代碼的相同程序層次樹表示
接下來,利用每個代碼塊的子向量及其所屬的PLST,提出一種逆序組合的方法為每個代碼塊生成完整的特征向量.令每個代碼塊的子向量長度為l,逆序組合方法首先遍歷目標代碼塊的左兄弟節點,以目標代碼塊起始,逆序組合其所有左兄弟節點的子向量,設置一個節點上限m:如果逆序組合的節點數量超過節點上限m,則刪除超過部分的子向量;如果不足m,以零向量補齊.組合完畢的向量被稱為層向量,其長度為l×m.然后,以相同的方法處理目標代碼塊的父節點,即逆序組合目標代碼塊的父節點的左兄弟節點,直到節點上限m,得到目標代碼塊父節點的層向量.然后,將該層向量排布在目標節點的層向量之后,設置一個層數上限n.以此類推,組合每層向量直到層數達到上限n.如果從目標代碼塊到PLST 的根節點的總層數小于n,則以零向量補齊至完整特征向量長度達到l×m×n.
基于逆序組合的特征向量生成方法的細節如算法1 所述,輸入是程序層次樹和待生成特征向量的目標代碼塊,輸出是目標代碼塊的特征向量.算法從目標代碼塊在程序層次樹中的層起始,由下至上遍歷,直到根節點或達到層數上限n(第2 行).對于每一層,以臨時目標節點(temp_tb)為起始依次遍歷其左兄弟節點,臨時目標節點被定義為目標節點及其祖先節點,上層的臨時目標節點為下層臨時目標節點的父親節點.依照遍歷順序依次排列臨時目標節點和其左兄弟節點,直到達到節點上限m(第5 行~第10 行).
在逆序組合的過程中,當某節點存在孩子節點時,如果僅組合該節點對應的子向量是不合理的.原因在于:從代碼角度看,其孩子節點也同樣位于目標代碼塊之前,因此會對目標代碼塊的日志打印決策產生影響.為解決該問題,提出了一種子樹上提的方法來捕獲這些孩子節點的特征.如算法2所示:子樹上提利用深度優先遍歷算法,搜索某節點的所有子孫節點(第2 行),然后將這些代碼塊依次遍歷順序排列組合成新的代碼片段(第3 行、第4 行),最后將該代碼片段輸入已訓練的神經語言模型生成新的子向量(第5 行).在逆序組合過程中,使用該新的子向量替代原子向量.
算法1.基于逆序組合的特征向量生成算法.

算法2.子樹上提算法.

圖4 是子向量逆序組合過程的一個例子,其中,N8是目標代碼塊.
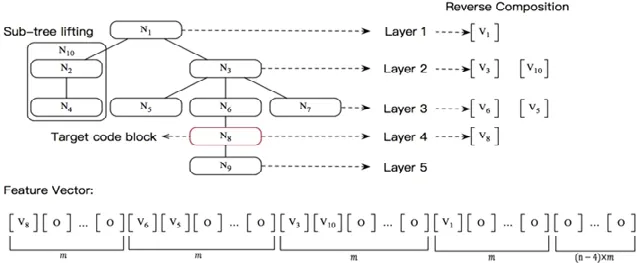
Fig.4 Example of reverse composition圖4 子向量逆序組合示例
本方法首先逆序組合生成第4 層到第1 層的層向量.由于N8是第4 層中唯一的代碼塊,排列N8對應的子向量v8并用零填充的其余部分作為第4 層目標代碼塊的層向量.對于第3 層,依次組合N8的父節點N6對應的子向量v6以及N6的左兄弟節點N5的子向量v5.在第2 層,由于N2有一個子節點N4,因此利用子樹上提方法將其轉換為新節點N10,并依次組成v3和v10.然后,將從第4 層到第1 層的所有向量合成為最終的特征向量.在這個例子中,假設m大于2 并且n大于4,且所有層向量和最終特征向量用零向量填充.
在程序文本中,位置相近的代碼塊的上下文程序相似甚至多數是相同的,然而這些代碼塊在日志打印決策上又往往是相反的.因此,如何從相似的程序文本中為不同的代碼塊提取不同的特征向量,成為通用日志打印位置決策的關鍵問題.逆序組合方法考慮使用相對距離替代絕對距離,即使兩個位置相近的代碼塊的上下文程序是相似的,他們的對齊也是不同的.考慮圖4 中N3和N6是兩個目標代碼塊,由于N6的第一個左兄弟節點是N5,N3的第一個左兄弟節點是N10,因此,N5和N10的子向量對齊.對于目標代碼塊N3,N10在最終特征向量的N3同層排布,然而對于目標塊N6,N10排布在最終完整特征向量中N6的父層向量部分中.
3.2 基于遷移學習的日志打印位置決策模型構建
如圖5所示,日志打印位置決策模型包括一個特征遷移模型和一個分類模型.
?特征遷移模型的輸入是不同軟件或組件的代碼塊特征向量集合;輸出是一個新的特征向量集合,該集合中的特征向量與輸入的特征向量一一對應.特征遷移模型可以利用不同的特征空間的特征向量學習到一個共享特征空間,進而將不同軟件或組件的代碼塊特征向量映射到共享特征空間去;
?分類模型的輸入是共享特征空間的代碼塊特征向量,輸出是對該代碼塊是否添加日志打印語句的決策結果.
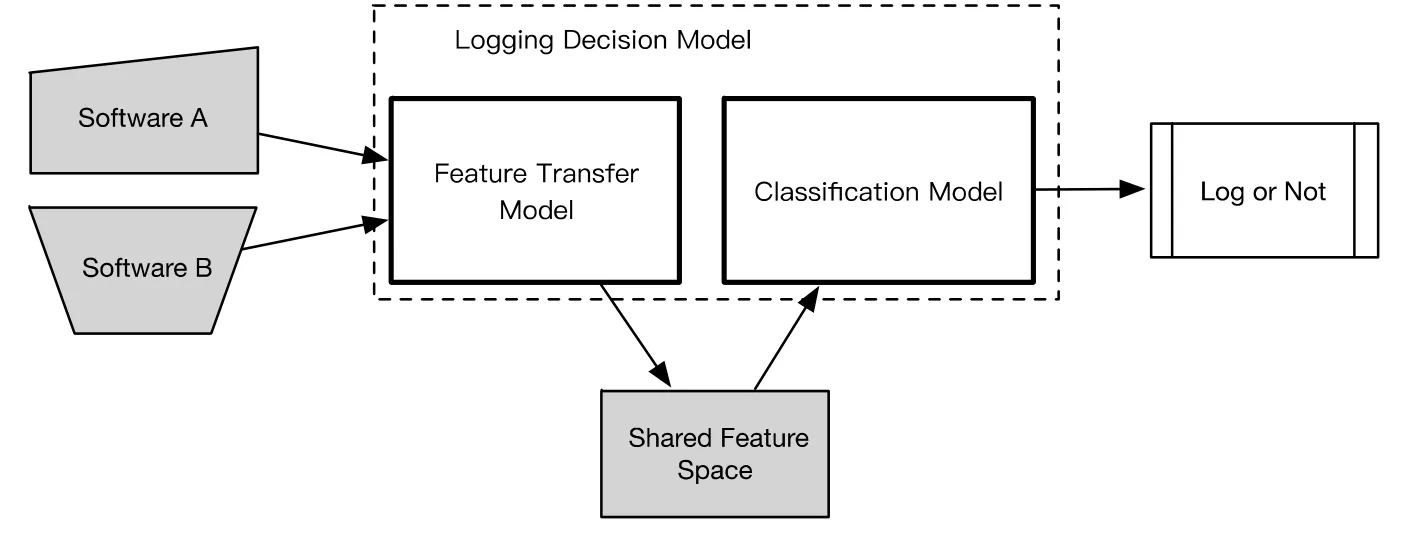
Fig.5 L ogging point decision model圖5 日志打印位置決策模型
下面分別介紹這兩個子模型.
特征遷移模型采用兩種經典的特征遷移算法——遷移成分分析算法(transfer co mponent a nalysis,簡稱TCA)[18]和聯合分配適配算法(JointDistribution adaptation,簡稱JDA)[19]將源系統特征向量和目標系統特征向量映射到新的特征空間.TCA 算法假設源系統特征向量集合和目標系統特征向量集合分別為XS和XT.TCA 利用邊緣概率分布來估計源系統特征向量和目標系統特征向量之間的差異.令一組數據集合X的邊緣概率分布為P(X),顯然,P(XS)≠P(XT).TCA 的目標是獲取一個轉換函數φ,使得P(φ(XS))≈P(φ(XT)).這樣,φ(XS)和φ(XT)是獨立且同分布的.為計算該轉換函數,TCA 首先使用最大均值差異(maximum m ean di screpancy,簡稱MMD)來衡量P(XS)和P(XT)之間的距離,計算公式如下:
無極之道里沒有一個壞人,也沒有一個好人,在這個虛構的寓言里,他們都是最為真實的人。兒時的傾城為了活命欺騙了一個純真的孩子,她背叛了她的諾言。恨意在無歡心里增長,從此他缺乏安全感并且工于心計,并以此來保護自己。在大將軍光明面前,他打心里認為自己永遠是個二流貨色,他的自卑帶給他無窮的恐懼。傾城選擇了滿神給出的命運,滿神又改變了大將軍光明的命運,大將軍光明與之抗爭也注定失敗。無極之道的悲劇在于自然人性與命運抗爭的注定失敗。
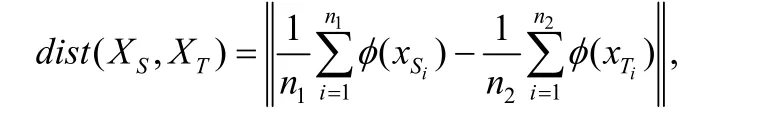
其中,n1和n2表示訓練向量和測試向量的數量.然后,TCA 引入一個計算內核獲取滿足dist(XS,XT)取最小值的最優值.訓練完畢后,XS和XT分別由φ(XS)和φ(XT)取代.
同TCA 不同,JDA 不但使用邊緣概率分布來估計源系統特征向量和目標系統特征向量之間的差異,同時還考慮兩者之間的條件概率分布差異.條件概率分布可以被形式化為P(YS|XS)和P(YT|XT).JDA 的目標是獲取一個轉換矩陣AT,使得P(YS|AT(XS))≈P(YT|AT(XT)).為計算該轉換矩陣,JDA 同樣使用MMD 來衡量XS和XT的距離.但是,由于目標系統特征向量集合沒有標簽數據,因此YT是未知的.為生成YT,JDA 使用源系統特征向量集合訓練一個簡單的分類器(XS,YS),然后對XT進行標注,進而得到仿造的標簽,并以替代YT.訓練完成后,XS被ATφ(XS)取代,XT被ATφ(XT)取代.
分類模型采用3 種經典的機器學習算法,包括支持向量機(support vector machine,簡稱SVM)、k-最近鄰(knearest neighbor,簡稱kNN)和Logistic 回歸(logistic regression,簡稱LR).SVM 的基本思路是,在共享特征空間中學習能夠決策日志打印的最大邊距超平面.kNN 算法的分類決策依據代碼塊在共享特征空間中最近鄰的幾個代碼塊所屬的類別,如果與一個代碼塊相似的若干其他代碼塊中均包含日志打印語句,則該代碼塊也應包含日志打印語句.LR 的因變量即是否應添加日志打印語句,自變量是使用經過特征遷移后的代碼塊共享特征向量,經過回歸分析,可以得到特征向量中的每一個維度對因變量的影響權重,進而判定目標系統代碼塊共享特征向量的因變量值.
4 實驗設計與結果驗證
4.1 實驗設計
為了評估所提出的方法,實驗使用Apache Hadoop[9],Angel[10],OpenStack[11],SaltCloud[12]和Tensorflow[13]等5個流行的大型開源軟件系統源代碼進行了兩組實驗.Hadoop 是當今最流行的大數據分析平臺之一,Angel 是騰訊開源的分布式機器學習平臺,OpenStack 和SaltCloud 是兩個開源云計算平臺,Tensorflow 是Google 開源的深度學習平臺.其中,Hadoop 和Angel 由Java 語言編寫,OpenStack,SaltCloud 和Tensorflow 由Python 語言編寫.
這兩組實驗包括多場景評估實驗和各階段評估實驗:多場景評估旨在驗證本文所提出的跨組件、跨軟件系統的日志打印決策方法在不同應用場景下的有效性;各階段評估旨在分別評估特征向量生成和日志打印位置決策模型的效果.第4.2 節和第4.3 節詳細介紹這兩組實驗的實驗結果.本節接下來介紹實驗過程中的數據處理、基線設置、參數設置、評價指標等.
4.1.1 實驗參數設置與數據處理
實驗參數的選擇,可能會影響實驗結果.在特征生成步驟,存在3 個關鍵參數需要預設,包括子向量長度l、子節點數量上限m和層數量上限n.實驗中,這3 個參數的預設值分別為50,10 和10,使得最終特征向量的長度為5 000(l×m×n).為提升訓練速度,實驗中使用了PCA 算法對特征向量降維,在保證95%以上數據方差的基礎上,將特征向量降至200 維.實驗過程中使用了若干種不同的參數取值,實驗結果對參數不敏感.由于論文長度限制,在本節并未將所有實驗結果一一列舉.
4.1.2 評價指標
評價指標采用使用經典的機器學習算法評價指標準確率(accuracy)和F1 值.
?Accuracy指日志打印決策正確的代碼塊占所有代碼塊的比例,它反映了日志打印決策模型的整體性能,計算如下:
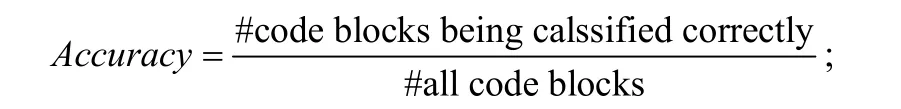
?F1 指標精確率(precision)和召回率(recall)的調和平均值,代表模型對正樣本的分類效果.高精確率意味著多數被分類為需要打印日志的代碼塊都是正確的,高召回率則意味著多數打印日志的代碼塊被正確地分類.F1 反映了模型能夠精確且全面地識別包含日志打印語句的代碼塊的性能,其計算公式如下:
F1=(2×Precision×Recall)/(Precision+Recall).
4.1.3 相關工作對比
日志打印位置決策任務的相關研究工作主要有LogAdvisor 和LogOptPlus,然而這些工作存在若干限制.表1 列舉了本文的方法同這些工作的對比.相關工作均針對特殊類型的代碼塊和特定的日志級別,同時對編程語言有一定的限制,僅支持C#,Java 等高級編程語言,無法支持C 語言以及一些腳本語言.本文所述方法是一種針對所有代碼塊的通用日志打印位置決策方法,在根本目的上與現有工作有較大區別.如果僅對比特定代碼塊的日志打印決策效果對本文的方法不公平,如果對比所有代碼塊的日志打印決策效果則對相關工作不公平,因此實驗中沒有同相關工作進行決策效果對比.實驗選取了LogAdvisor 中所對比的方法——隨機添加日志打印語句(random error logging)作為基線,并隨機測試5 次取平均以減少實驗結果的偏差.

Table 1 Comparison on related works表1 相關工作對比
4.2 多場景下評估日志打印位置決策
在這個實驗中,我們首先定義了3 個場景,包括版本升級、組件開發和系統開發.根據編程語言的不同,5 個軟件系統被分為兩組:Python 組和Java 組,分別在兩組實驗系統上測試3 種場景下日志打印位置決策模型的效率.如表2所示:在版本升級場景中,選擇軟件系統的舊版本代碼作為訓練集,新版本的代碼選作測試集,驗證和評估所提出的方法在跨版本日志打印位置決策中的效率;在組件開發場景中,選擇一個組件的代碼作為訓練集,同一系統的另一個組件的代碼作為測試集,驗證和評估所提出的方法在跨組件日志打印位置決策中的效率;在系統開發場景中,選擇一個系統的代碼進行訓練,另一個系統的代碼進行測試,驗證和評估所提出的方法在跨系統日志打印決策中的效率.
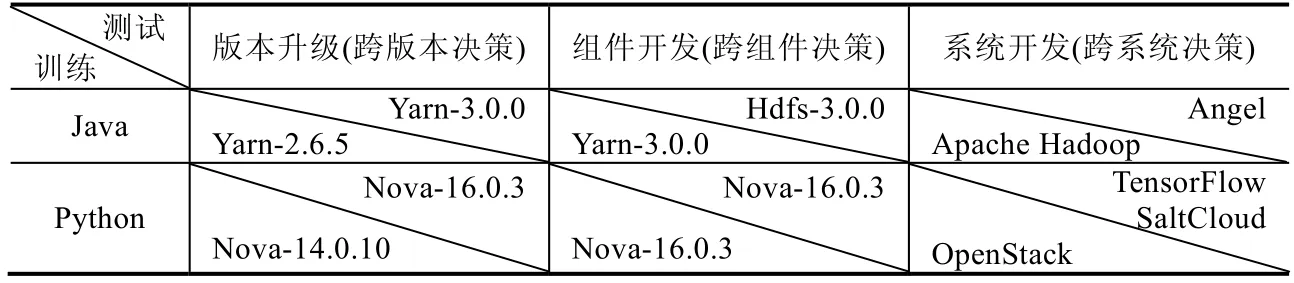
Table 2 Design of multiple scenario experiment表2 多場景評估實驗設計
實驗結果如圖6所示.
?在版本升級場景下評估跨版本的日志打印位置決策模型(如圖6(a)所示),Python 組實現了0.692 的準確率和0.525 的F1 指標;同時,Java 組達到了0.965 的準確率和0.890 的F1;
?在組件開發場景下評估跨組件的日志打印位置決策模型(如圖6(b)所示),Python 組實驗得到了0.659的準確率和0.690 的F1,Java 組實驗中達到了0.960 的準確率和0.866 的F1;
?在系統開發場景下評估跨系統的日志打印位置決策模型(如圖 6(c)所示),Python 組的實驗以TensorFlow 為測試集時達到0.663 的準確率和0.529 的F1,使用SaltCloud 作為測試集時準確率達到0.773,F1 達到0.565;在Java 組實驗中達到0.969 的準確率和0.925 的F1.同基線(RandomErrorLogging)相比,Python 組提升了近20%的準確率,Java 組則提升了40%以上的準確率.
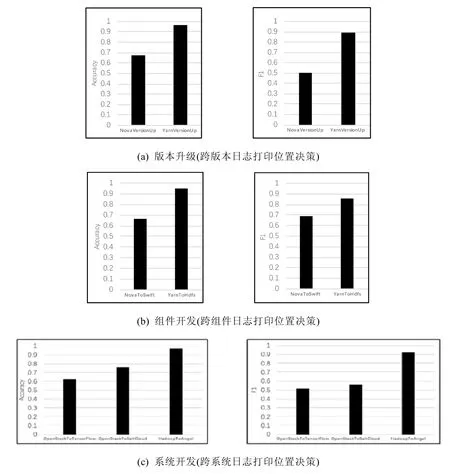
Fig.6 Results of multiple scenario experiment圖6 多場景評估實驗結果
上述實驗結果表明:本方法在3 種典型場景和5 種流行的軟件系統上都取得了良好的表現,在Java 組中達到0.95 的準確率和0.85 的F1,在Python 組中達到超過0.65 的準確率和0.5 的F1.更進一步的,本方法在新系統開發場景下的跨系統日志打印位置決策表現最佳,準確率比另外兩類場景高出約0.1.其原因在于:在新系統開發場景中將整個系統的源代碼作為訓練集,而在另外兩種場景下僅選取一個組件的源代碼用于訓練,訓練集的大小可能影響分類模型的性能.值得注意的是:本方法在Java 組中取得了更好的效果,遠超Python 組.如圖7所示,3 個場景中Java 組的準確性均比python 組高20%左右.究其原因:
?Python 的編程風格更加靈活,且支持多種易用功能強大的語法,特征向量生成方法將代碼視為純文本,并側重于提取文本特征.因此,類似功能的不同實現所生成的特征有較大差異,導致決策模型的效果欠佳;
?而Java 語言則存在更好的異常和錯誤處理機制,日志打印語句往往在這些異常和錯誤處理代碼中出現.這使得特征向量生成更容易捕獲包含日志打印語句的代碼塊和未包含日志打印語句的代碼塊之間的差異,決策模型表現更良好.
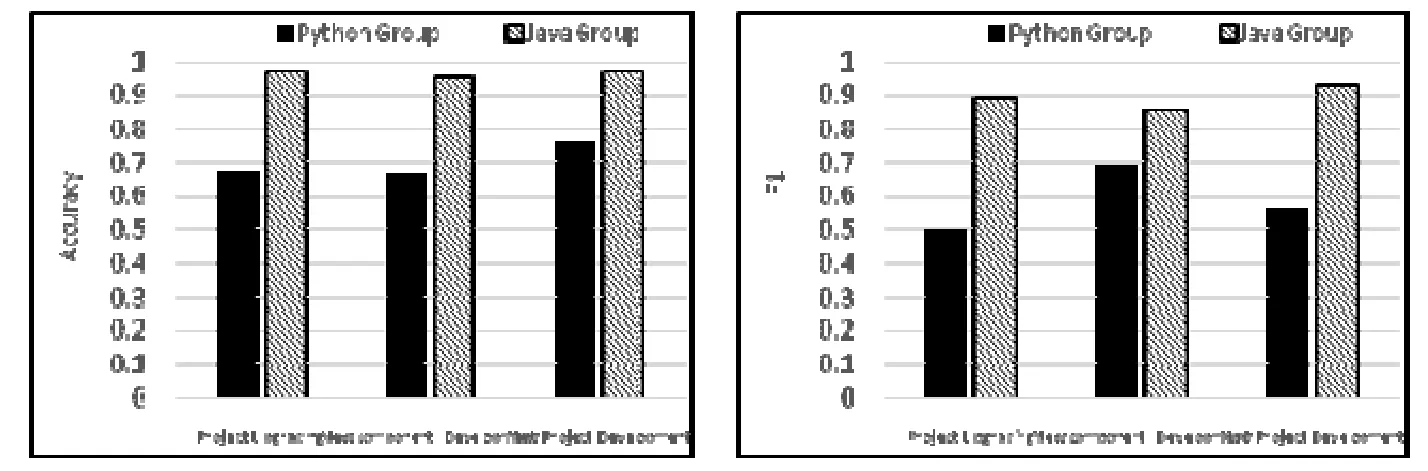
Fig.7 Comparison of results of Python group and Java group圖7 Python 組和Java 組實驗結果對比
4.3 多階段評估日志打印位置決策
本實驗旨在評估特征向量生成步驟與日志打印決策模型的效果.在特征向量生成評估中,僅利用基礎分類模型,包括Logistic 回歸(logistic regr ession,簡稱LR)、k-最近鄰(k-nearest n eighbor,簡稱kNN)和支持向量機(support vect or m achine,簡稱SVM)的分類效果來評估所生成的特征向量的質量.在日志打印決策評估中,則對比分析了加入遷移學習模型后和僅使用基礎分類模型的效果.
圖8 為特征向量生成步驟的實驗結果.
?在版本升級(跨版本決策)場景中,Java 組的平均準確率為0.959,平均F1 為0.865;在Python 組中,平均準確度為0.664,平均F1 為0.469;
?在新組件開發(跨組件決策)場景中,Java 組的平均準確率為0.943,平均F1 為0.838;同時,Python 組的平均準確率為0.649,平均F1 為0.644;
?在新的系統開發(跨系統決策)場景中,Java 組的平均準確率為0.960,平均F1 為0.899;而Python 組的平均準確率為0.667,平均F1 為0.527.
結果表明,特征向量生成方法可以有效地從源代碼中提取特征向量.即使使用基本的簡單分類模型,Java 組中的實驗結果也達到0.9 以上的精確度和0.8 以上的F1.
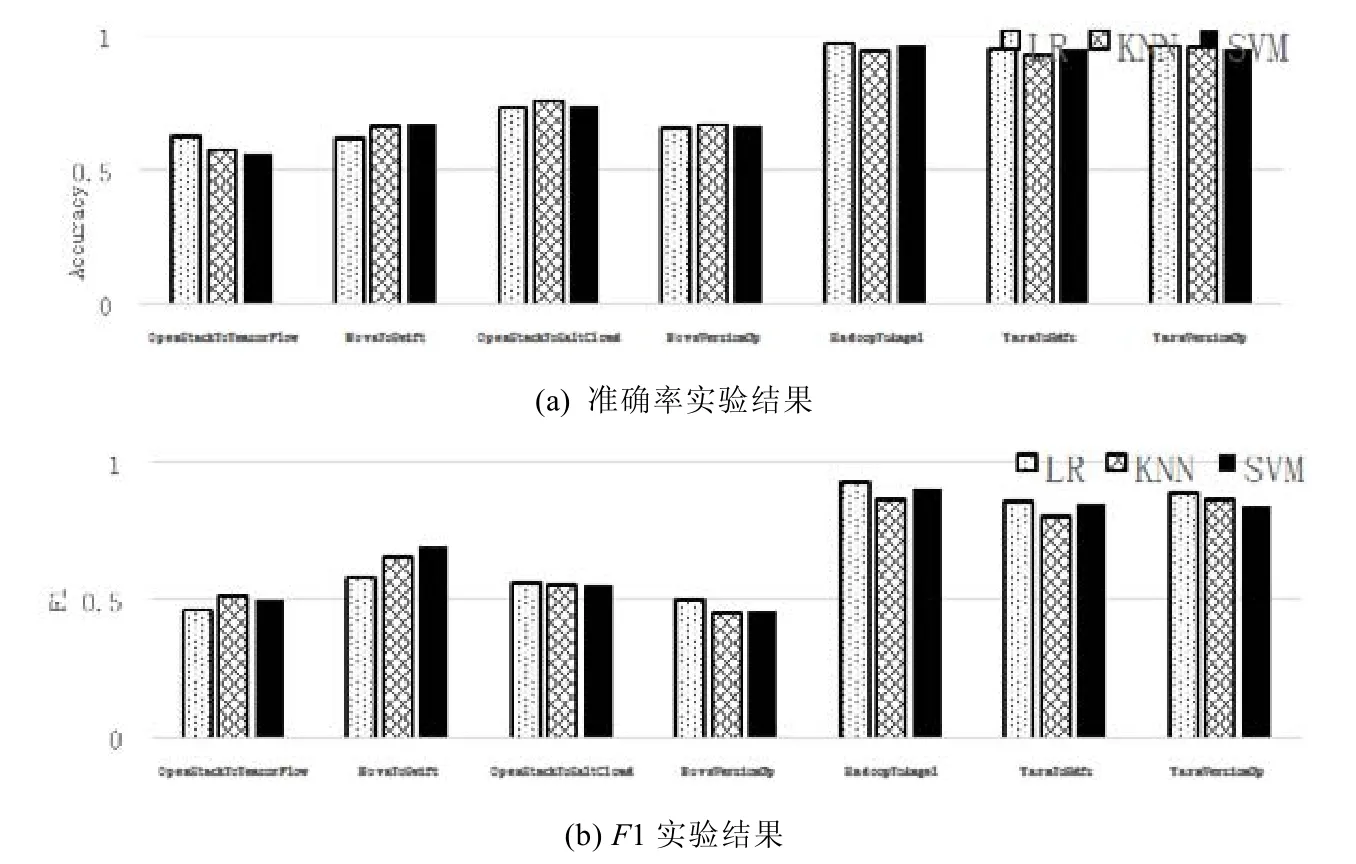
Fig.8 Experiment result of feature vector generation圖8 特征向量生成步驟效果驗證實驗結果
圖9 展示了日志打印決策步驟的實驗結果.
?Python 組:在版本升級(跨版本決策)場景中,TCA 和SVM 模型組合達到最佳準確率0.692,而JDA 和KNN 模型的組合得到最佳F1 為0.525;在新組件開發(跨組件決策)場景中,TCA 和SVM 模型的組合達到最佳準確率為0.690,TCA 和LR 模型的組合達到最佳F1 為0.695;在新的系統開發(跨系統決策)場景中,JDA 和KNN 模型的組合達到的最佳準確率為0.663,最佳F1 為0.529;
?Java 組:TCA 和LR 模型的組合在版本升級(跨版本決策)場景中達到最佳準確率為0.962,最佳F1 為0.878;在新組件開發(跨組件決策)方案中,JDA 和KNN 的最佳準確率為0.960,最佳F1 為0.866;在新的系統開發(跨系統決策)場景中,TCA 和SVM 的組合達到0.965 的最佳準確率和0.912 的最佳F1.
與簡單分類模型相比,Python 組實驗中遷移學習有效地提高了2%~9%的準確率和1%~12%的F1.在版本升級(跨版本決策)場景中,TCA 和SVM 模型的組合比SVM 的最優精度提高了3%,而JDA 和KNN 模型組合的F1 比KNN 模型提高了7.3%;在新組件開發(跨組件決策)場景中,TCA 和SVM 模型的組合比SVM 基線的最高精度提升了2.3%,TCA 和LR 模型的F1 比LR 基線提升11.1%;在新軟件系統開發(跨系統決策)場景中,JDA 和KNN 模型的組合達到最佳精度和F1,與KNN 基線相比,它提高了8.6%的準確率和1.2%的F1.
在Java 組中,遷移學習的平均準確率和F1 降低1%左右.在版本升級場景和新軟件系統開發(跨版本和跨系統決策)場景中,TCA 和LR 模型的組合平均下降約0.8%的準確率和1.9%的F1;在新組件開發(跨組件決策)場景中,JDA 的準確率提高了3.3%,F1 提高了1.1%.Java 組中采用遷移學習后準確率和F1 值下降可能是由于源域和目標域的特征向量之間的分布差異較小,沒有明顯適合遷移的部分,導致出現負遷移的情況.所謂負遷移即遷移學習在轉化和評估過程中的遷移損失大于遷移增益.在Java 組的實驗中,基本模型的結果良好,意味著源域和目標域之間沒有明顯的分布差異,因此在遷移學習轉化過程中帶來的損失占據主導.盡管在Java 組的部分實驗中存在性能下降,但遷移學習模型在Java 組中總體表現仍然出色,能夠說明日志打印決策模型的有效性.
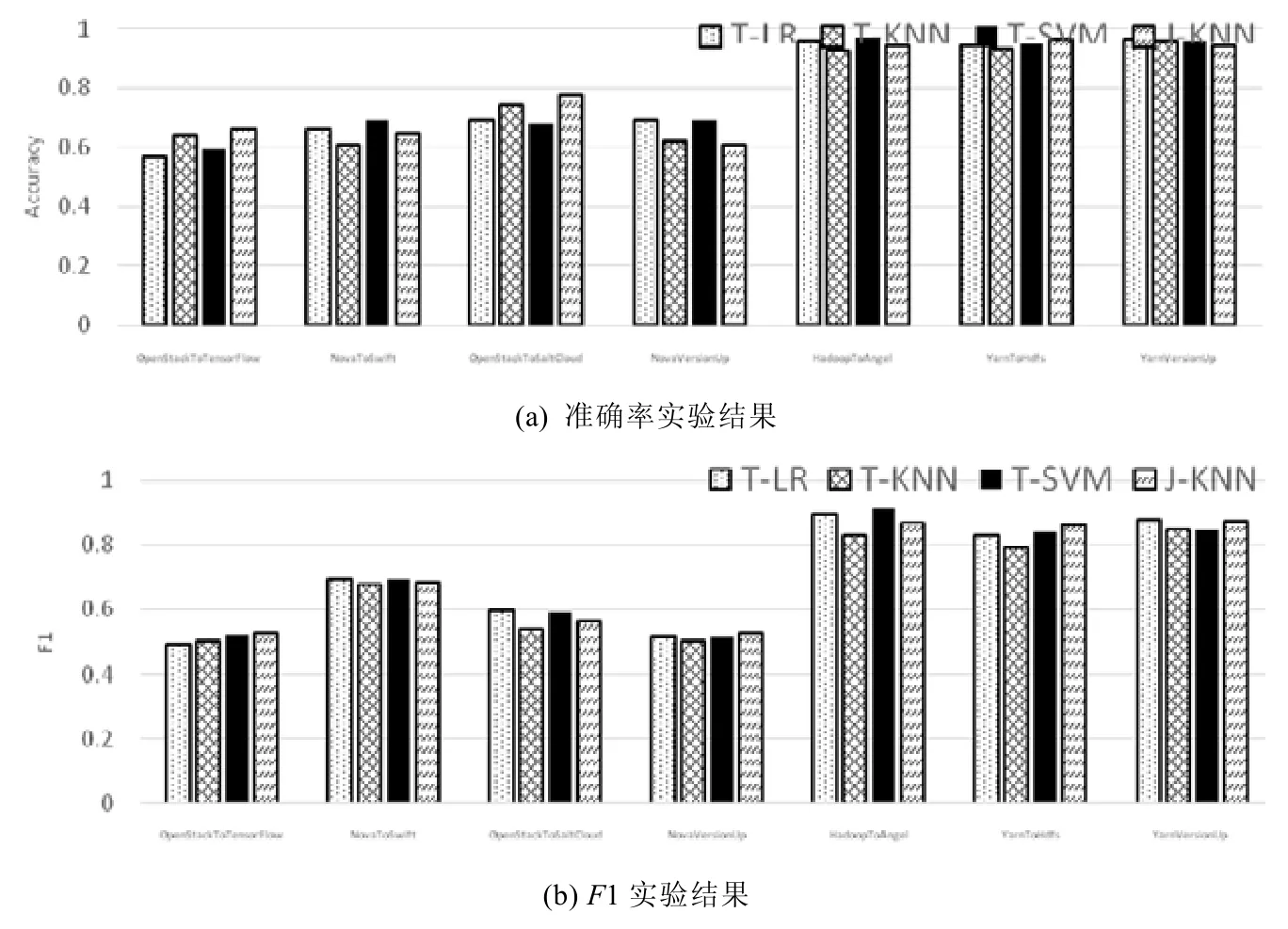
Fig.9 Experiment result of logging point decision models圖9 日志打印位置決策模型效果驗證
請讀者查閱表3 獲取詳細的實驗結果數值,其中,模型列列舉了實驗中使用的特征遷移模型和分類模型算法,其他列列舉了Java 和Python 組中不同場景的實驗結果.表中黑體部分代表每一個場景的實驗中的最優結果.
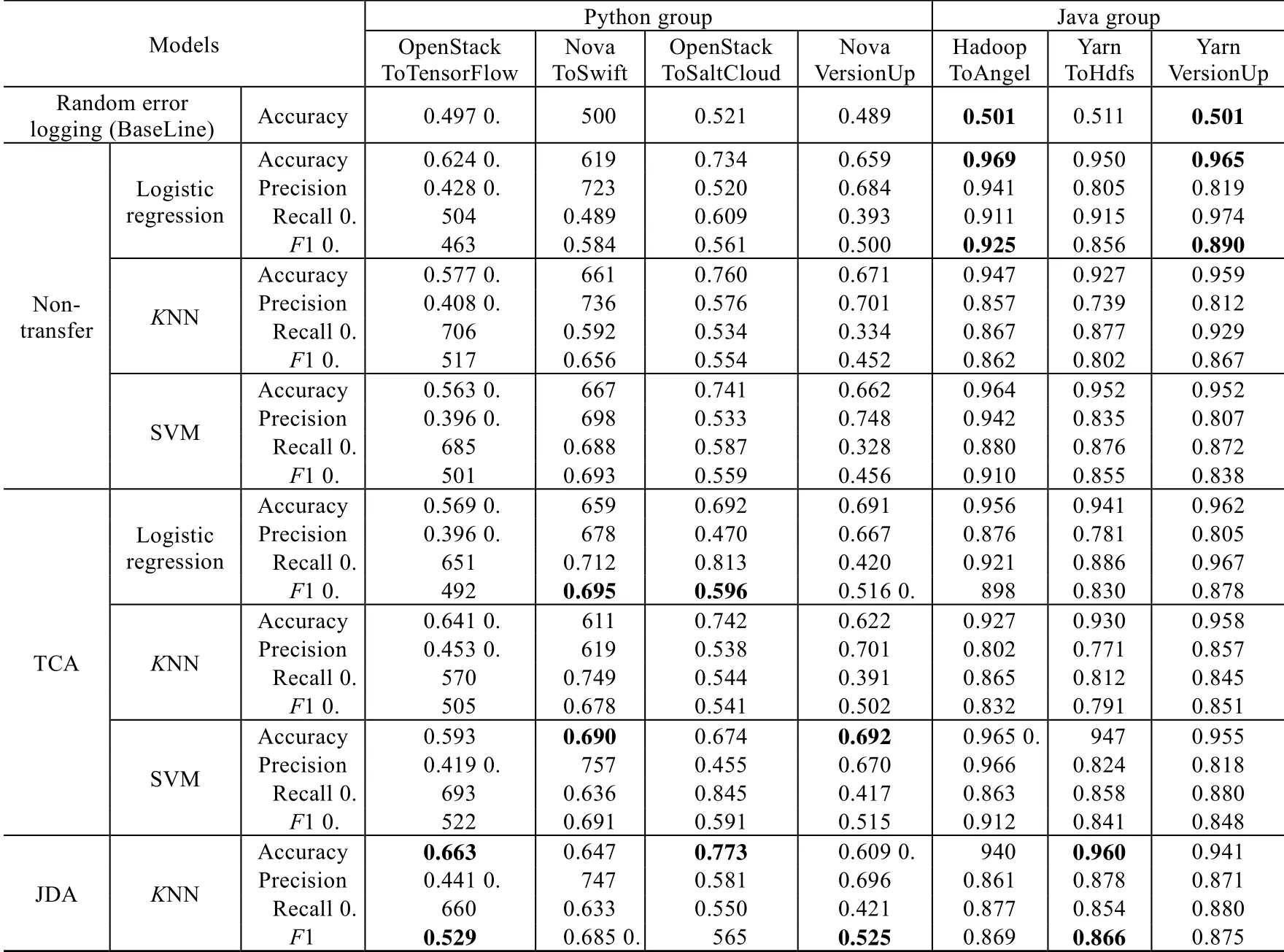
Table 3 Experiment results表3 實驗結果匯總
4.4 討論
本節討論實驗中涉及的可能影響實驗結果的因素.
?實驗選取了有限的5 個不同語言的不同項目,劃分3 個場景進行實驗,希望能夠在跨組件、跨軟件系統的日志打印位置決策問題上進行初步探索.未來工作中會加大實驗規模,以EcoSystem 為單位驗證并優化本文的方法.目前,已經收集了NPM 生態系統中21 個項目、NVIDIA 生態系統中14 個項目、Pytorch 生態系統下17 個項目、Apache 生態系統下152 個項目、Chrome 下13 個項目以及Eclipse下13 個項目,未來我們會在這些項目上對本方法進行實驗;
?在跨軟件系統決策場景實驗中,從Hadoop 不包含日志打印語句的383 9 72 個代碼塊中隨機抽樣出13 4 70 個代碼塊作為負樣本,使用共計26 94 0 個代碼塊作為測試集.在版本升級和跨組件決策場景實驗中,HDFS 組件110 396 個代碼塊中,4 242 個代碼塊包含日志打印語句,從106 154 個不包含日志打印語句的代碼塊中隨機采樣了4 242 個代碼塊作為負樣本,使用共計8 484 個樣本作為訓練集.對于深度學習模型而言,該量級的訓練數據過少,但是對于本文所使用的機器學習模型而言,這個量級的數據是可以訓練出有效的分類模型的;
?本文所述方法是一種針對所有代碼塊的通用日志打印位置決策方法,在根本目的上與現有工作有較大區別.如果僅對比特定代碼塊的日志打印決策效果對本文的方法不公平,如果對比所有代碼塊的日志打印決策效果則對相關工作不公平.未來,我們會修改相關工作(LogAdvisor 和LogOptPlus)使之支持Java 語言和Python 語言,并在特殊代碼片段的日志打印決策問題上進行定量的對比實驗.
5 總結與展望
本文主要研究軟件系統的日志打印位置決策問題,即:給定一段代碼,決策與這段代碼相關的日志打印位置.具體地,為了適用于不同的編程語言,并進行跨組件和跨軟件系統的日志打印位置決策,本文提出一種通用的自動化特征向量提取方法,通過構建程序層次樹,屏蔽編程語言與不同程序模塊實現細節的異構性,并提出一種基于遷移學習的日志打印位置決策模型,利用特征遷移技術挖掘不同軟件系統日志打印程序的共有特征空間,遷移有用信息削減特征差異.在未來的工作中,擬加大實驗規模,對本方法進行更加充分的驗證.另外,擬從特征生成和模型構建步驟優化現有方法,使之進一步支持跨編程語言不同軟件系統的日志打印位置決策,擬進一步研究如何利用深度學習技術(如深度遷移學習等)提升日志打印位置決策效果;與此同時,擬研究日志打印變量和常量的自動化決策方法,以實現完全自動化的日志打印語句撰寫.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
