基于卷積神經(jīng)網(wǎng)絡的串行空時分組碼盲識別算法
2021-11-10 03:45:54張聿遠閆文君張立民
系統(tǒng)工程與電子技術 2021年11期
張聿遠, 閆文君,*, 張立民, 張 媛
(1.海軍航空大學航空作戰(zhàn)勤務學院, 山東 煙臺 264001; 2.海軍航空大學航空基礎學院, 山東 煙臺 264001)
0 引 言
多輸入單輸出(multiple input single output, MISO)系統(tǒng)以其對空間的有效利用,已成為無線通信領域內(nèi)的一項重要內(nèi)容。在MISO系統(tǒng)中,空時分組碼(space-time block code, STBC)類型識別作為信號盲識別中的一項關鍵技術,受到了越來越多的關注[1]。在通信偵查、頻譜感知等非協(xié)作通信條件下,信道和噪聲的先驗信息常常難以獲得,并且在實際通信過程中,信號還會受到來自敵方設備的電磁干擾。因此,尋求一種能夠在低信噪比和非協(xié)作條件下對STBC進行盲識別的方法,對確保作戰(zhàn)平臺在復雜環(huán)境下的鏈路通信順暢具有重要意義。
現(xiàn)有的STBC識別方法仍以傳統(tǒng)算法為主,鮮有深度學習技術在該領域的應用。傳統(tǒng)方法需對STBC特征進行提取,主要利用STBC的相關性,對計算得到的累積量進行假設檢驗以實現(xiàn)識別,包括基于二階統(tǒng)計特征的算法[1-4],和基于高階統(tǒng)計特征的方法[5-9]等。其中,基于二階統(tǒng)計特征的算法分別通過計算互相關矩陣[1],相關矩陣的誘導峰值[2]和二階循環(huán)統(tǒng)計特征的方法[3-4]進行識別,基于高階統(tǒng)計特征的方法常采用計算四階統(tǒng)計量[6-8]和循環(huán)累積量[9]的方法來完成識別。除了利用統(tǒng)計特征的識別方法外,文獻[10]提出了通過K-S(kolmogorov-smirnov)檢測的方法對STBC進行盲識別。以上算法只對4類STBC進行了討論,甚至其中文獻[1,2,4,10]只對最常用的空間復用(special multiplexing, SM)信號和阿拉莫提(Alamouti,AL)信號進行了分析,這是由于現(xiàn)有算法對STBC的識別建立在其相關性的基礎上,編碼矩陣長度相同的STBC具有相同的相關性,因而傳統(tǒng)算法無法對這類STBC進行區(qū)分。因此,對相關性分布一致的STBC進行識別仍是STBC識別領域的一個難點。
近年來,隨著深度學習技術在計算機視覺(computer vision, CV)領域的快速發(fā)展,通信領域的研究人員已經(jīng)開始將深度學習應用于通信信號處理等問題中。文獻[11]利用卷積神經(jīng)網(wǎng)絡(convolutional neural network, CNN)對正交頻分復用(orthogonal frequency division,OFDM)信號的自相關灰度圖像進行特征提取,以實現(xiàn)OFDM信號頻譜感知。在調(diào)制識別領域,文獻[12]創(chuàng)造性的將深度學習技術應用于通信信號調(diào)制識別,提出了一種基于CNN的調(diào)制識別方法,實現(xiàn)了包括模擬和數(shù)字調(diào)制在內(nèi)的多種調(diào)制方式,并在低信噪比下取得了較好的識別性能。文獻[13]引入卷積加長短時深度神經(jīng)網(wǎng)絡(cnvolutional long short-term deep neural networks, CLDNN),通過將多個時間步內(nèi)的信號特征進行融合,進一步提升了模型的識別精度。文獻[14]以信號的實部和虛部數(shù)據(jù)、幅度相位數(shù)據(jù)和頻譜幅度等分別建立數(shù)據(jù)庫,基于CNN實現(xiàn)了工業(yè)、科學和醫(yī)學(industrial scientific medical, ISM)頻段的無線電干擾識別。文獻[15]在文獻[12]的基礎上,提出了基于VGG(visual geometry group)和ResNet網(wǎng)絡的深度CNN結構,將可識別的調(diào)制信號類型擴展到24種,并在通用無線電硬件平臺上實現(xiàn)了識別測試,在頻偏和多徑衰落的影響下取得了較好的識別性能。在雷達輻射源識別領域,現(xiàn)有算法常采用Choi-Williams分布(Choi-Williams distribution, CWD)時頻變換將時域信號變?yōu)闀r頻圖像,構建深度學習模型實現(xiàn)輻射源信號識別[16-19]。相對于傳統(tǒng)信號識別算法,深度學習算法具有無需人工提取特征、模型自學習能力強和數(shù)學分析較少等特點,但因信號的自身特征與視覺圖像在本質(zhì)上有較大區(qū)別,因此如何構建符合信號本質(zhì)特征的神經(jīng)網(wǎng)絡框架,是深度學習技術應用于通信信號處理問題的關鍵所在。
針對上述問題,本文提出一種基于CNN的串行STBC識別方法。首先將CNN應用于STBC識別問題中,給出了基本CNN(CNN basic, CNN-B)模型;然后在分析STBC信號相關性的基礎上,針對SM和AL信號在低信噪比下的混疊問題,設計了基于相關性的CNN(CNN based on correlation, CNN-BC)模型;最后將6類STBC數(shù)據(jù)集輸入模型進行訓練和測試,完成STBC識別。仿真實驗表明,該方法輸入的數(shù)據(jù)量較少,僅需少量帶標簽的數(shù)據(jù)即可獲得較好的識別性能,并且得益于GPU并行運算能力的提升,STBC識別過程可控制在微秒級別,具有較強的實時處理能力,非常適合于實際的工程應用。
1 信號模型
考慮采用ns個發(fā)射天線,1個接收天線的STBC通信系統(tǒng),則接收端的STBC信號為串行序列。若每組STBC需要傳輸?shù)姆枖?shù)為n,待傳輸?shù)姆栂蛄繛镾=[s1,s2,…,sn]T,用一組STBC傳輸n個符號所需的時間為L,則STBC碼[6]傳輸矩陣G的維數(shù)為ns×L,具體表示為
(1)
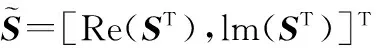
y(t)=HG(t)+b(t)
(2)
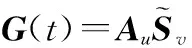
2 基于CNN的STBC識別
深度學習技術實現(xiàn)的難點在于設計適合的神經(jīng)網(wǎng)絡結構和預處理方法。在STBC識別領域,現(xiàn)有算法仍以傳統(tǒng)的特征提取算法為主,鮮有深度學習技術的應用,因此需要探索針對STBC的識別方法。考慮到在調(diào)制識別領域常采用信號的實部和虛部兩路作為訓練數(shù)據(jù),搭建CNN等神經(jīng)網(wǎng)絡模型實現(xiàn)調(diào)制識別[12-15],本文借鑒了該數(shù)據(jù)采集方法,并針對STBC自身特性設計出更加適合STBC識別的神經(jīng)網(wǎng)絡結構。
2.1 CNN
CNN作為一種典型的人工神經(jīng)網(wǎng)絡模型,其本質(zhì)是通過簡單的激活函數(shù)和深層的網(wǎng)絡結構對輸入樣本的特征進行提取,以實現(xiàn)對未知復雜函數(shù)的逼近。CNN的優(yōu)勢在于不需要對接收信號進行額外的處理,可自行提取接收端串行序列的時域特征,避免了傳統(tǒng)STBC識別算法復雜的特征提取過程,且不需要人工設計假設檢驗的閾值和相關參數(shù),避免了因調(diào)試經(jīng)驗不足而導致的識別誤差。
卷積層的作用是對輸入樣本的特征進行提取。基本過程是對上一層輸出的每一個樣本與本層的卷積核進行卷積運算,與偏置單元相加后代入激活函數(shù),作為本層的輸出樣本:
(3)

池化層的作用是減少網(wǎng)絡參數(shù),優(yōu)化訓練過程。CNN的待訓練參數(shù)主要集中在卷積層,利用池化層對卷積層輸出樣本進行降維,能夠在樣本數(shù)不變的情況下減少網(wǎng)絡參數(shù),加快模型收斂,池化過程可表示為
(4)

全連接層一般位于網(wǎng)絡的末端,將學習到的特征轉(zhuǎn)化為容易理解的結果形式,實現(xiàn)卷積層與輸出結果的過渡。最后一層全連接的單元個數(shù)與分類個數(shù)相同,且常采用Softmax激活函數(shù),以實現(xiàn)對網(wǎng)絡輸出特征的分類。卷積層與池化層學習到的高階復雜特征通過全連接層后,能夠?qū)⑵滢D(zhuǎn)化為易于理解的標簽類型形式,因此全連接層亦可理解為實現(xiàn)了“分類器”的作用。
2.2 CNN-B網(wǎng)絡結構
考慮到CNN在調(diào)制識別領域已取得的成果[12-15],本文設計的CNN對文獻[12]中的結構進行了參考。文獻[12]創(chuàng)造性地將深度學習技術應用到通信信號調(diào)制識別領域中,提出了一種基于CNN的調(diào)制識別方法,該方法能夠在低信噪比下有效識別包括模擬和數(shù)字調(diào)制在內(nèi)的多種調(diào)制信號,是調(diào)制識別領域的經(jīng)典網(wǎng)絡。本文對文獻[12]的網(wǎng)絡參數(shù)進行了如下調(diào)整:一方面,將全連接層D2的單元數(shù)設置為與待識別的STBC種類數(shù)相同,以適應網(wǎng)絡的輸出結果;另一方面,為了更好地對STBC進行識別,將卷積層C1和C2的卷積核個數(shù)分別增加為256個和80個,全連接層D1的單元數(shù)增加為256個。
調(diào)整參數(shù)后的基本CNN模型CNN-B如表1所示。輸入層由STBC信號的實部和虛部兩行組成,大小為2×128。模型中的C表示卷積層,D為全連接層,卷積層C1、卷積層C2與全連接層D1的激活函數(shù)均為線性整流函數(shù)ReLU,全連接層D2使用歸一化指數(shù)函數(shù)Softmax作為激活函數(shù),輸出6類STBC信號的識別結果。

表1 CNN-B模型結構
2.3 基于STBC相關性的CNN-BC網(wǎng)絡結構
本文采用的CNN-B網(wǎng)絡取得了較好的識別性能,并且將傳統(tǒng)算法能夠識別的4類STBC信號擴展到了6種,尤其是能夠?qū)崿F(xiàn)對具有相同編碼矩陣長度STBC的識別。在單接收天線下,編碼矩陣長度相同的串行STBC序列具有相同的相關性,因而利用相關性的傳統(tǒng)算法無法實現(xiàn)對這兩組信號的區(qū)分[1-10]。但是,CNN-B網(wǎng)絡在低信噪比下仍存在SM和AL信號混疊的問題,兩類信號的預測標簽與真實標簽產(chǎn)生了部分交叉。為進一步提升網(wǎng)絡識別性能,解決該混疊問題,本文基于STBC信號的相關性對CNN-B網(wǎng)絡結構進行了改進。
考慮長度為K(K為偶數(shù))的接收序列y=[y(0),y(1),…,y(K-1)],定義序列y在時延向量[0,1]下的二階時延相關函數(shù)為
R(l)=y(2l)y(2l+1),l=0,1,…,K/2-1
(5)
進一步可定義其二階統(tǒng)計量:
(6)
在時延向量[0,1]下,對于SM信號,以接受端第1個信號ySM(0)和第2個信號ySM(1)為例,由式(2)可知,這兩個連續(xù)時鐘信號可表示為
ySM(0)=h1s1+h2s2+b0
(7)
ySM(1)=h1s3+h2s4+b1
(8)
而由假設3可知信號之間獨立同分布,即s1、s2、s3和s4相互獨立,故ySM(0)與ySM(1)獨立。同理,在計算相關函數(shù)RSM(l)時,該獨立性對任意的l成立,因此SM接收信號的二階統(tǒng)計量滿足:
CSM=0
(9)
對于AL信號,由式(2)可知,相同的連續(xù)兩個時鐘信號可表示為
yAL(0)=h1s1+h2s2+b0
(10)
(11)

CAL=m
(12)
式中:m為常數(shù)。由式(7)~式(12)可知,由于SM和AL信號編碼矩陣的不同,兩類信號在接收端展現(xiàn)出不同的相關性,進而導致其二階統(tǒng)計量的差異,其相關性分布如圖1所示。
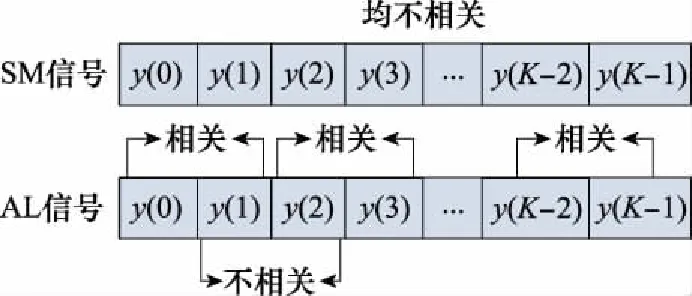
圖1 SM和AL信號相關性分布
由圖1可知,采用1×2維卷積核對STBC信號特征進行提取時,由于SM和AL相關性不同,其卷積得到的深層特征必然呈現(xiàn)出不同的規(guī)律。實際上,采用1×2維卷積核對接收序列y進行卷積的過程與計算其在時延向量[0,1]下的二階統(tǒng)計量是相類似的,傳統(tǒng)的特征提取算法在識別SM和AL信號時,也是通過計算其四階時延統(tǒng)計量實現(xiàn)識別的[6]。但對于時延τ>1的AL信號,其二階相關函數(shù)不再具備相關性,因此長度超過1×2維的卷積核不具有此區(qū)分優(yōu)勢。因此,本文借鑒了特征提取算法的識別原理,對CNN-B網(wǎng)絡進行了如下改進。
(1)將卷積層C1的卷積核大小改為2×1。由于輸入樣本為接收端信號的實部和虛部,而非接收序列y=[y(0),y(1),…,y(K-1)],因此需要首先將STBC信號對應的實部和虛部合并,再進一步根據(jù)相關性提取特征。
(2)將卷積層C2的卷積核大小改為1×2。根據(jù)SM和AL信號相關性分布的差異性,采用1×2維卷積核對C1層輸出特征進行卷積,得到更加符合STBC信號本質(zhì)的相關性特征。
(3)增加卷積核大小為1×2的卷積層C3。增加該層的目的是在C2層相關性特征的基礎上,進一步提取STBC信號的深層統(tǒng)計特征,強化CNN對信號本質(zhì)特征的映射能力。
CNN-BC模型如圖2所示,除卷積層部分改變外,網(wǎng)絡的其他部分不變。改進后的網(wǎng)絡借鑒了傳統(tǒng)的特征提取算法,結合STBC相關性對網(wǎng)絡結構重新進行了設計,更加符合STBC信號的本質(zhì)特征。
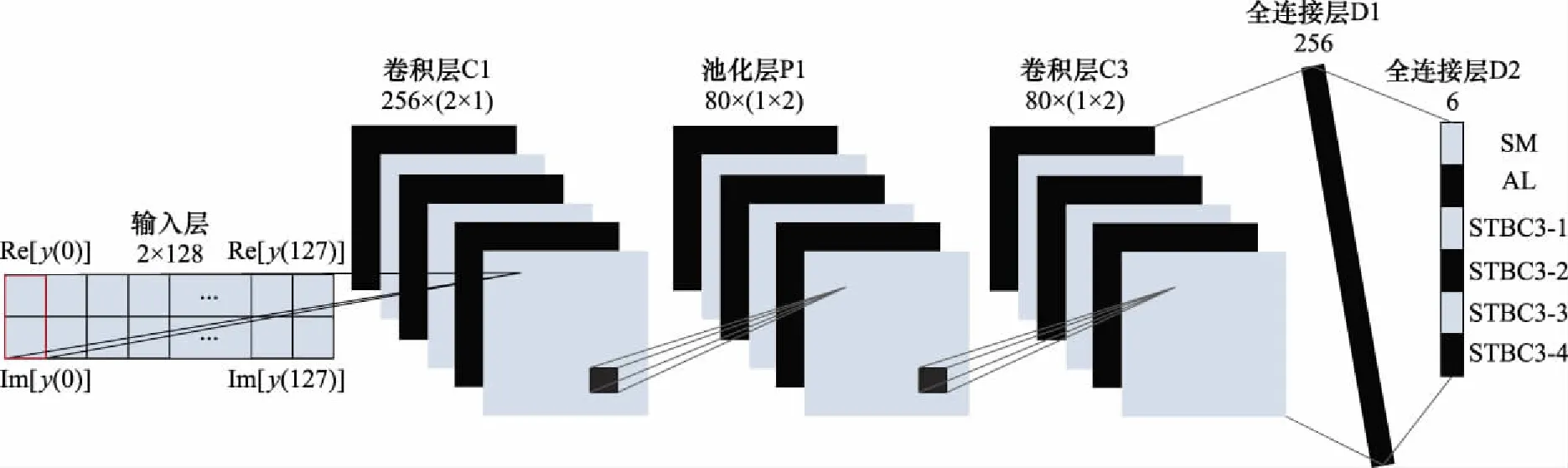
圖2 基于相關性的CNN-BC模型
2.4 CNN訓練過程
考慮一個有N層網(wǎng)絡的CNN模型,其訓練過程包括數(shù)據(jù)從第1層傳播到第N層的前向傳播階段和將誤差從第N層傳播到第1層反向傳播階段。具體過程如圖3所示,初始化網(wǎng)絡的權值;訓練數(shù)據(jù)經(jīng)過輸入層、卷積層、池化層和全連接層后輸出結果;計算輸出結果與目標值之間的誤差;當誤差大于期望值時,將誤差傳回網(wǎng)絡中,依次求得全連接層、池化層、卷積層和輸入層的誤差;根據(jù)誤差更新權值,重復初始化之后的過程。
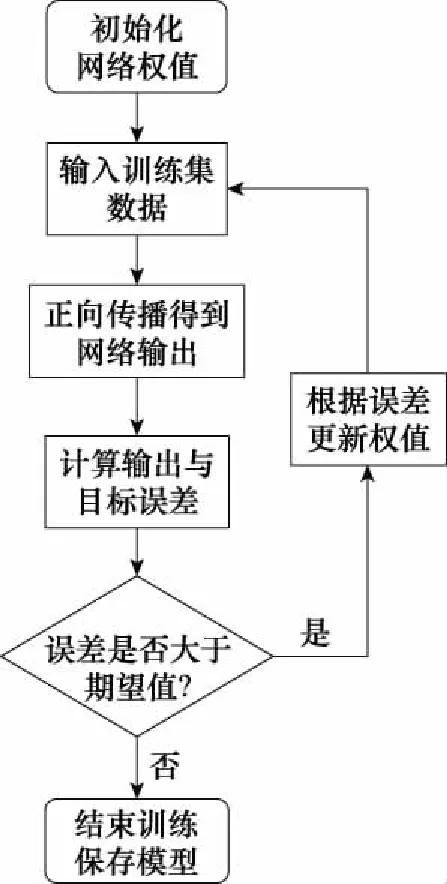
圖3 CNN訓練過程
考慮訓練樣本大小為m的訓練數(shù)據(jù){(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},其中x(i)(i=1,…,m)為STBC信號的輸入數(shù)據(jù),y(i)(i=1,…,m)為該類型STBC的標簽,記第k層的節(jié)點數(shù)為Sk,采用均方誤差作為損失函數(shù),則網(wǎng)絡訓練過程中的損失函數(shù)可表示為
(13)
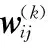
3 實驗結果與分析
選取SM信號和5種常用的STBC檢測本文算法的識別性能,6種STBC的具體編碼方式如下。
(1)SM信號
發(fā)射天線數(shù)ns=2,碼率r=2,編碼矩陣長度為L=1,依次對信號進行傳輸,編碼矩陣的具體表示為
(14)
(2)AL信號
發(fā)射天線數(shù)ns=2,碼率r=1,編碼矩陣長度為L=2,則每組STBC可傳輸?shù)姆枖?shù)為n=2,編碼矩陣的具體表示為
(15)
(3)STBC3-1信號
發(fā)射天線數(shù)ns=3,碼率r=3/4,編碼矩陣長度為L=4,則每組STBC可傳輸?shù)姆枖?shù)為n=3,編碼矩陣的具體表示為
(16)
(4)STBC3-2信號
發(fā)射天線數(shù)ns=3,碼率r=3/4,編碼矩陣長度為L=4,則每組STBC可傳輸?shù)姆枖?shù)為n=3,編碼矩陣的具體表示為
(17)
(5)STBC3-3信號
發(fā)射天線數(shù)ns=3,碼率r=1/2,編碼矩陣長度為L=8,則每組STBC可傳輸?shù)姆枖?shù)為n=4,編碼矩陣的具體表示為
(18)
(6)STBC4信號
發(fā)射天線數(shù)ns=4,碼率r=1/2,編碼矩陣長度為L=8,則每組STBC可傳輸?shù)姆枖?shù)為n=4,編碼矩陣的具體表示為
(19)
本文仿真過程使用的STBC信號采用正交相移鍵控(quadrature phase shift keying,QPSK)調(diào)制方式,信道為頻率平坦的Nakagami-3衰落信道。在接收端每隔128個時鐘信號截取一段數(shù)據(jù),然后將128個信號的實部和虛部分別放在矩陣的第1行和第2行,得到2×128維矩陣作為一個輸入樣本。STBC數(shù)據(jù)集大小如表2所示,設置0~5的標簽分別對應6類待識別的STBC,信噪比選取-10~10 dB之間的整數(shù),每種STBC在給定信噪比下產(chǎn)生1 000個樣本,因而每種信號類型共有21 000個樣本,6類信號的總樣本數(shù)為126 000。在網(wǎng)絡訓練過程中,隨機抽取總樣本的50%作為訓練數(shù)據(jù),其余50%作為測試數(shù)據(jù)。

表2 STBC數(shù)據(jù)集
本文的仿真實驗在window10系統(tǒng)下運行,使用基于TensorFlow后端的keras深度學習框架進行模型搭建和訓練,硬件環(huán)境為core(TM)i7-9700K CPU,運行內(nèi)存16 GB,使用支持NVIDIA CUDA環(huán)境的RTX2080ti GPU對訓練過程進行加速。
3.1 CNN-BC網(wǎng)絡的設計與分析
考慮到CNN不同的網(wǎng)絡參數(shù)會對識別性能產(chǎn)生影響,因此本文對CNN-BC網(wǎng)絡的卷積核大小進行了分析。在圖2的基礎網(wǎng)絡結構上,通過改變卷積核維度,測試出適合于STBC信號識別的CNN參數(shù)。由于CNN-BC的C1層卷積核只有為2×1時才能利用信號的相關性,因此本文在設置參數(shù)時主要從C2層和C3層的卷積核大小來考慮,在給定C2層卷積核大小的情況下,分析識別準確率隨C3層卷積核維度的變化情況,實驗結果如圖4所示。圖4為-5 dB時CNN-BC網(wǎng)絡的識別性能。由該圖可知,在給定C2層卷積核大小的情況下,識別準確率隨C3層卷積核大小增加呈起伏變化,且C2層卷積核越大,準確率的波動程度越大,說明更長的卷積核維度并不能給網(wǎng)絡帶來更好的性能,反而導致網(wǎng)絡的魯棒性更差。從圖中可以看出,本文設計的CNN-BC結構識別性能在35種卷積核維度組合中性能最優(yōu),且所需的卷積核維度最小,網(wǎng)絡需優(yōu)化的參數(shù)最少。這說明利用1×2的卷積核提取STBC特征時可充分利用SM和AL信號的相關性差異,而其他尺度的卷積核則不具備這一特質(zhì),使得本文的CNN-BC網(wǎng)絡非常適合STBC信號的識別。
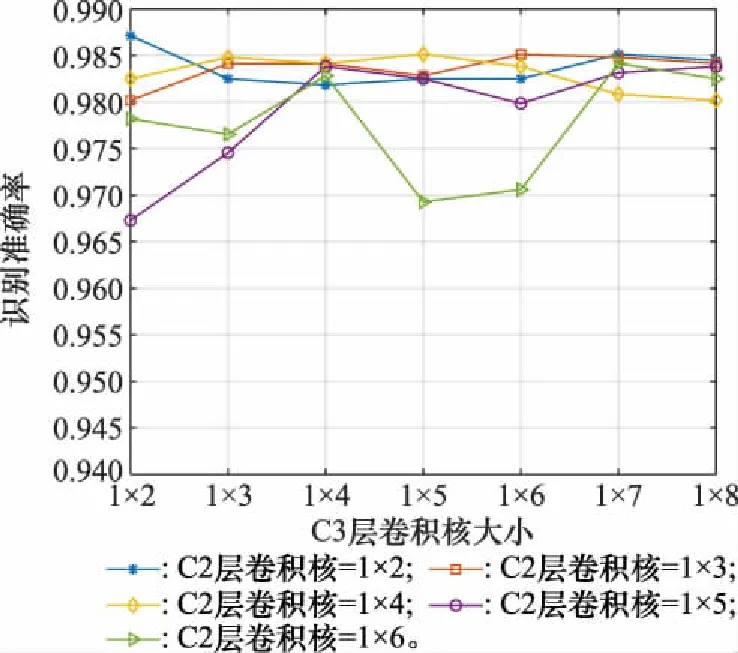
圖4 卷積核大小對識別性能的影響
圖5給出了不同樣本長度下的識別準確率,由該圖可知,隨著樣本長度的增加,CNN-BC網(wǎng)絡的識別性能進一步提升,在樣本長度為1 024時,模型在-8 dB下的準確率達到了98.7%,在低信噪比下識別性能優(yōu)異。樣本長度從128增加為256時性能提升明顯,但考慮到接收信號數(shù)僅為原來的一半,并且在實際電子偵察過程中,敵方平臺的通信時間往往很短,難以采集大量的數(shù)據(jù)用于訓練,因此本文仍選取樣本長度為128。本文的CNN-BC模型在較少信號數(shù)下仍能保持高識別率,十分適合于對短突發(fā)信號的處理,這對非協(xié)作通信下的STBC識別具有重要意義。
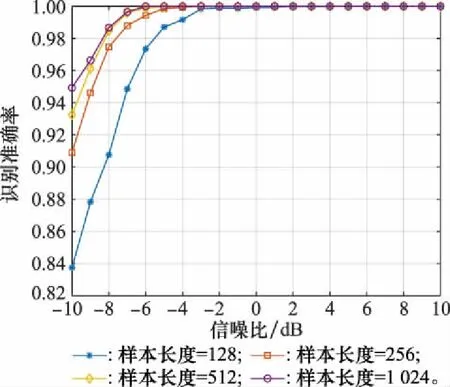
圖5 不同樣本長度對識別性能的影響
3.2 實驗參數(shù)對網(wǎng)絡性能的影響
為驗證本文模型的泛化性和有效性,本節(jié)對調(diào)制方式、信道條件和數(shù)據(jù)集劃分比例對網(wǎng)絡性能的影響進行分析,圖6給出了不同調(diào)制下的識別準確率圖像。從圖6中可以看出,CNN-BC模型在BPSK下的識別性能最優(yōu),-8 dB下達到了97.7%,低信噪比下識別性能優(yōu)異。算法性能隨調(diào)制方式復雜度的增加而逐漸被削弱,但在高階調(diào)制下仍能保持良好的識別性能。

圖6 不同調(diào)制方式對識別性能的影響
除引入的信道外,本實驗還分析了Nakagami信道參數(shù)m對性能的影響。由圖7可知,識別準確率隨Nakagami信道階數(shù)m的減小而有所下降,但仍能獲得較穩(wěn)定的識別性能。

圖7 不同Nakagami信道參數(shù)對識別性能的影響
圖8給出了本文網(wǎng)絡在不同訓練集劃分比例下的圖像。由該圖可知,不同比例下的識別準確率差別不大,識別性能均隨信噪比穩(wěn)步增加,樣本比例選取50%或80%均可。

圖8 不同樣本比例對識別性能的影響
3.3 CNN-BC模型泛化性驗證
為分析不同信道環(huán)境對模型的影響,進一步考察CNN-BC模型的泛化性和有效性,本文引入了較常用的塊衰落(block fading, BF)信道[21-23]和更接近真實信道的第3代合作伙伴計劃(3rd generation partnership project,3GPP)空間信道擴展模型(spatical channel model extend,SCME)[24-27]。由于BF信道增益在獨立衰落子塊內(nèi)保持不變,而不同衰落子塊的信道系數(shù)獨立同分布[21-23],本實驗采用了文獻[22]的平坦瑞利BF信道,將同一衰落子塊內(nèi)的信道系數(shù)設置為相同,各衰落子塊的衰落系數(shù)服從瑞利分布。3GPP/3GPP2組織發(fā)布的SCM[24]、SCME[25]均為標準的MIMO信道模型[26],并且更接近實際的衰落信道。仿真過程采用3GPP SCME信道定義的城區(qū)宏小區(qū)(urban macro-cell, UMA)場景,以模擬真實信道下的通信環(huán)境。BF信道、3GPP SCME信道和Nakagami信道三者綜合對比的準確率圖像如圖9所示。
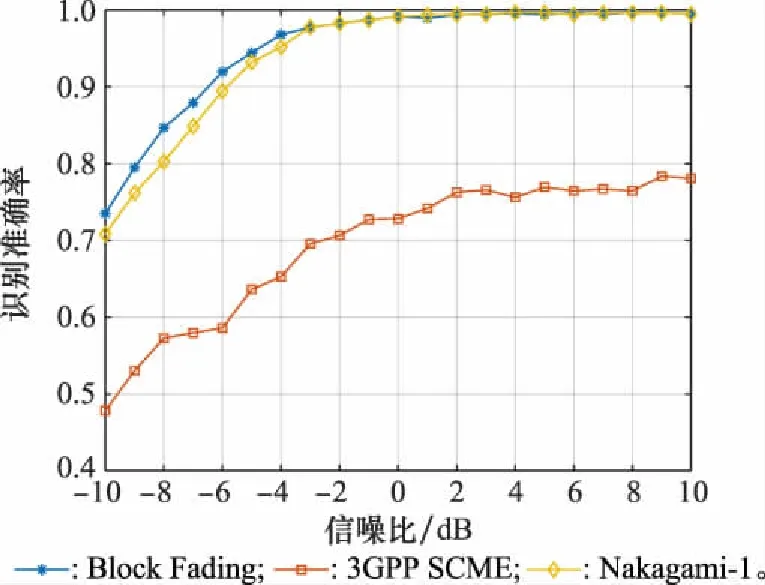
圖9 不同信道下的識別性能
從圖9中可以看出,本文模型在3GPP SCME信道下的識別性能較差,但在低信噪比下,BF信道性能略優(yōu)于Nakagami-1信道,這是由于m=1時,Nakagami信道退化為瑞利衰落信道[28],而平坦瑞利BF信道較瑞利信道更穩(wěn)定,因此在低信噪比下略優(yōu)于Nakagami-1信道。由于3GPP SCME信道的衰落和噪聲干擾較強,為分析CNN-BC模型對復雜信道的適應性,本節(jié)進一步對該信道在樣本長度L為512和1 024時的性能進行了仿真,實驗結果如圖10所示。由圖10可知,通過增加樣本長度L的方法可有效地提升識別準確率,從而緩解因信道衰落導致的性能惡化問題。此外,得益于CNN-BC模型對STBC信號特征強大的自學習能力,其在低信噪比下較Nakagami-1信道更優(yōu),說明本文模型對實際衰落信道和強噪聲干擾環(huán)境具有良好的適應性,這對該模型的實際應用具有重要意義,由此驗證了CNN-BC網(wǎng)絡的泛化性和有效性。由于本文在單接收天線下進行,除增加樣本長度外,采用多接收天線也可改善實際衰落信道下的識別性能,是未來值得研究的方向之一。

圖10 3GPP SCME信道在不同樣本長度下的識別性能
3.4 不同網(wǎng)絡識別性能對比
本節(jié)對CNN-B、CNN-BC、FDSCF+CNN[29]和CNN-LSTM[30]共4種神經(jīng)網(wǎng)絡進行對比,綜合分析網(wǎng)絡的識別準確率、空間復雜度和時間復雜度等性能。其中,文獻[29]通過計算信號的頻域自相關函數(shù)(frequency domain self-correlation function, FDSCF),并將其作為樣本輸入CNN進行識別;文獻[30]將長短期記憶(long short-term memory, LSTM)層引入STBC識別,提出了一種利用CNN-LSTM提取空間和時序特征的識別方法,FDSCF+CNN和CNN-LSTM均為STBC識別領域的最新深度學習方法。
圖11給出了4種網(wǎng)絡的識別準確率圖像。由圖11可知,本文采用和改進的CNN-B與CNN-BC的識別性能較FDSCF+CNN和CNN-LSTM更優(yōu),性能增益明顯。CNN-BC在3種網(wǎng)絡中識別性能最優(yōu),-8 dB下的準確率仍達到了90%以上,性能較CNN-B網(wǎng)絡進一步得到提升,從而驗證了本文基于STBC相關性對CNN進行的改進的合理性。
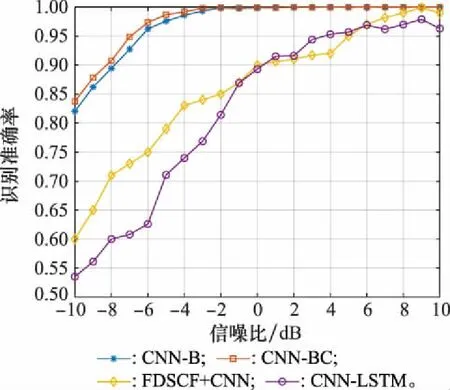
圖11 不同網(wǎng)絡識別準確率對比
圖12給出了3種信噪比下CNN-B網(wǎng)絡和改進后CNN-BC網(wǎng)絡的混淆矩陣。由圖12可知,改進后網(wǎng)絡對SM和AL信號的識別能力有較大提升,尤其是AL碼的識別精度有明顯改善,在-6 dB下的準確率增加了10%,信號混疊的現(xiàn)象明顯減弱,說明本文基于相關性的改進方法符合SM和AL信號識別原理,較原網(wǎng)絡更適合于STBC識別。考慮到在實際的工程應用中,SM和AL信號為STBC中最常用的編碼類型,因而提升其在低信噪比下識別性能具有重要意義。
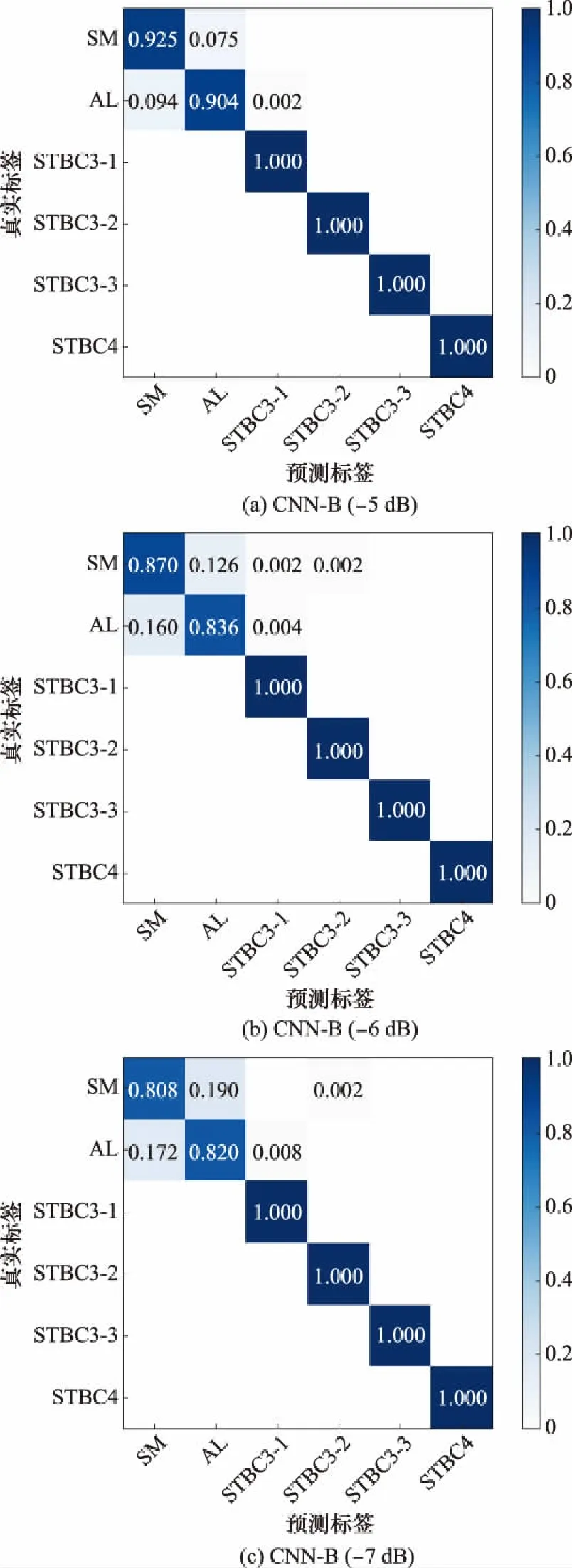
圖12 改進前后網(wǎng)絡在不同信噪比下的混淆矩陣對比
表3給出了4種網(wǎng)絡模型的復雜度對比。其中,空間復雜度是指網(wǎng)絡的待訓練參數(shù)量,時間復雜度從訓練總時間和識別耗時兩個角度考慮,其中的訓練總時間為網(wǎng)絡從開始訓練至收斂的總時間,識別耗時為63 000個測試樣本識別總耗時的平均值。
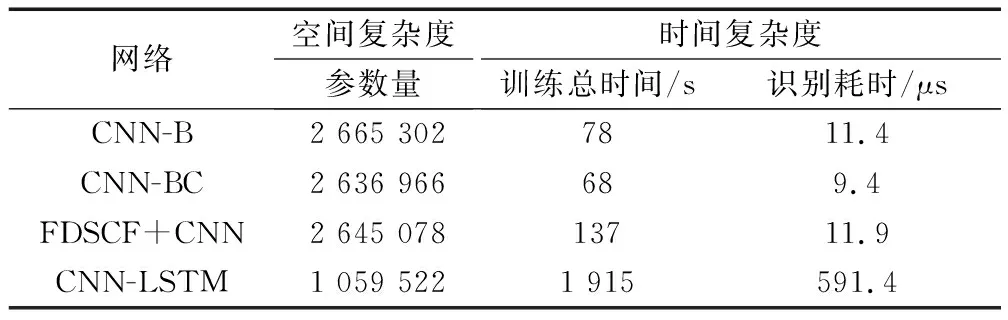
表3 不同網(wǎng)絡模型的復雜度對比
由表3可知,CNN-BC的卷積核維度較小,故參數(shù)量略小于CNN-B和FDSCF+CNN網(wǎng)絡,訓練總時間與識別耗時在4種網(wǎng)絡中也為最低。CNN-LSTM網(wǎng)絡的總參數(shù)量雖然最少,但受制于循環(huán)神經(jīng)網(wǎng)絡在訓練時需要利用多時間步的信息,其訓練和識別耗時較3種CNN網(wǎng)絡大幅增加,導致網(wǎng)絡的實時性較差,不適用于通信偵查等需對敵方信號快速精確識別的場景。整體來看,CNN-BC網(wǎng)絡的訓練和識別耗時最短,且識別準確率最高,在綜合考慮運算代價和模型精度的情況下,本文的CNN-BC網(wǎng)絡性能最優(yōu)。
3.5 不同方法識別性能對比
現(xiàn)有的串行STBC識別方法仍以傳統(tǒng)的人工提取特征的方法為主,鮮有利用深度學習技術對STBC進行識別的算法,因而本文選取采用特征提取方法的文獻[7-10]作為該節(jié)的對比算法。文獻[7]采用高階累積量進行STBC識別,文獻[8]和文獻[9]分別計算四階循環(huán)累積量和四階時延累積量,構建假設檢驗實現(xiàn)分類識別,文獻[10]通過計算經(jīng)驗累積分布函數(shù)之間的最大距離,利用K-S檢驗進行識別。由于傳統(tǒng)算法大多需要利用STBC的相關性實現(xiàn)識別,因而文獻[1-10]只能識別編碼矩陣長度不同的4類STBC,在理論上無法區(qū)分本文的STBC3-1與STBC3-2、STBC3-3與STBC4這兩組編碼方式。為更好地對不同識別方法的性能進行對比,本節(jié)實驗僅在編碼矩陣長度不同的SM、AL、STBC3-1和STBC3-3的4類STBC下進行,其余仿真條件不變,以驗證本文方法的優(yōu)勢,本文方法與文獻[7-10]算法的識別準確率對比如圖13所示。
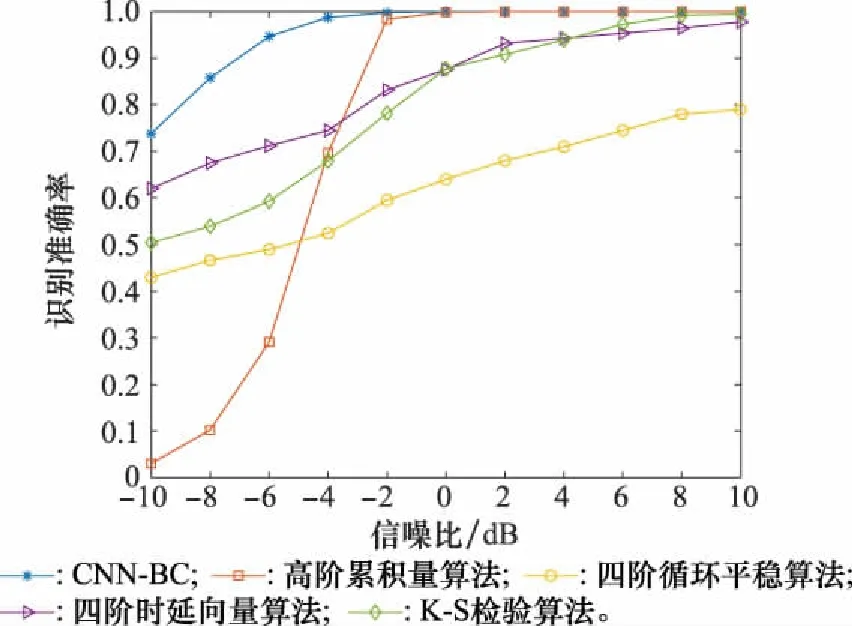
圖13 不同方法識別準確率對比
由圖13可知,本文的CNN-BC模型較其余3種算法的識別性能有明顯提升,低信噪比下(-6 dB)仍能達到94.7%的準確率,識別性能優(yōu)異。此外,本文方法不需要知道信道和噪聲的先驗信息,可實現(xiàn)特征自提取,適用于頻譜檢測等非協(xié)作通信情況。
從實時性分析的角度來看,雖然網(wǎng)絡訓練需要一定的時間,但得益于GPU并行運算能力的提升,神經(jīng)網(wǎng)絡大部分運算都能并行完成,可利用計算開銷換取計算速度,最終使CNN-BC模型的識別時間控制在微秒級別,如表3所示,完全可以滿足實時性處理的需求。基于CNN-BC網(wǎng)絡的識別方法可直接對STBC時域信號進行識別,無需進行人工特征提取,且識別性能明顯優(yōu)于傳統(tǒng)算法,具有較好的工程應用前景和研究價值。
4 結 論
本文提出了一種基于CNN的STBC識別算法,將深度學習技術應用于STBC識別領域,實現(xiàn)了信號特征自提取和編碼方式自動識別,解決了非協(xié)作通信條件下串行STBC的盲識別問題。仿真實驗表明:
(1)本文基于STBC的相關性設計的CNN-BC網(wǎng)絡非常適合于STBC識別。改進后的CNN-BC網(wǎng)絡識別性能得到明顯改善,解決了低信噪比下SM和AL信號的混疊問題,且具有更低的空間和時間復雜度,在綜合考慮運算代價和模型精度的情況下,本文方法的識別性能最優(yōu)。
(2)本文方法將可識別的4類STBC碼擴展到6類。利用STBC相關性的傳統(tǒng)算法在理論上無法識別6類STBC,但得益于CNN對信號特征強大的提取能力,本文方法能夠識別編碼矩陣長度相同的STBC3-1與STBC3-2、STBC3-3與STBC4這兩組編碼方式,進一步擴展了可識別的STBC類型。
(3)本文方法具有較強的實時識別能力。得益于GPU并行運算能力的提升,該方法對STBC的識別可控制在微秒級別,且無需人工提取特征,不需要知道信道和噪聲的先驗信息,可直接對接收端時域信號進行盲識別,非常適合于電子偵察等非協(xié)作通信情況,具有較高的工程和實際應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
