一種自適應權重學習的輕量超分辨率重建網絡
2021-11-12 01:57:08張宇浩程培濤張書豪王秀美
西安電子科技大學學報 2021年5期
張宇浩,程培濤,張書豪,王秀美
(1.西安電子科技大學 機電工程學院,陜西 西安 710071;2.西安電子科技大學 電子工程學院,陜西 西安 710071)
圖像超分辨率重建(Super-Resolution,SR)是計算機視覺領域中的一個重要研究方向,目的在于根據給定低分辨率圖像(Low Resolution,LR)恢復對應的高分辨率圖像(High Resolution,HR)[1]。近年來,基于深度卷積神經網絡(Convolutional Neural Networks,CNN)的圖像超分辨率重建方法取得了較好的效果,成為超分辨率重建領域的重要研究方向之一[2]。
文獻[3]在2014年將深度學習應用于超分辨率重建,提出了基于深度卷積神經網絡的圖像超分辨率重建方法(Super-Resolution Convolutional Neural Network,SRCNN)。在此之后,學者們圍繞設計更準確、更高效的超分辨率重建網絡展開了廣泛研究[4-17]。文獻[6]提出了一個用于圖像超分辨率重建的超深度卷積神經網絡(Super-Resolution using Very Deep convolutional networks,VDSR),利用全局跳躍連接加深網絡,將上采樣的低分辨率圖像逐元素添加到輸出的重建圖像中,提升了網絡性能。文獻[18]提出的拉普拉斯金字塔超分辨率網絡(Laplacian pyramid Super-Resolution Network,LapSRN)使用逐步上采樣、逐級預測殘差的方案來解決速度和精度問題。文獻[7]提出了增強型深度超分辨率重建網絡(Enhanced Deep Super-Resolution network,EDSR)和多尺度深度超分辨率重建系統(Multi-scale Deep Super-Resolution system,MDSR),這兩種方法刪除了前人方法中常用的BN層,使網絡中信息更新范圍更加靈活,從而極大地提高了性能。文獻[8]借鑒文獻[9]提出的密集連接網絡(DenseNet),提出了基于殘差密集連接的超分辨率重建網絡(Residual Dense Network for image super-resolution,RDN),在減小參數量的同時提高了性能,但密集連接網絡有更高的時間復雜度,導致推理時間過長。
注意力機制是使設備計算資源的分配更偏向于信息中最有表征意義的一種方法[20]。近些年來,注意力機制已經成功地應用于深度卷積超分辨率重建網絡,將網絡的操作重點引向含有更多信息的特征區域。注意力機制主要分為通道注意力機制與空間注意力機制,其中通道注意力機制的代表性工作是文獻[5]提出的基于殘差注意力的超分辨率重建網絡(very deep Residual Channel Attention Networks,RCAN)。它將通道注意力應用于超分辨率重建,通過通道之間的相互依賴自適應地調整通道特征,使得RCAN的重建結果在準確性和視覺效果上均超越了EDSR方法;但是該方法只提取了一階圖像特征,忽略了高階圖像特征,因而無法獲取局部區域以外的信息。針對此問題,文獻[21]提出了一個基于二階注意力的超分辨率重建網絡(Second-order Attention Network,SAN),利用二階的特征統計量自適應地細化通道間的特征。這種二階通道注意力機制更關注有用的高頻信息,提高了網絡判別能力。文獻[22]提出的深度殘差非局部注意力網絡(very deep Residual Non-local Attention Networks,RNAN)則是利用Non-local模塊[23]提取整個特征圖之間的空間相關性,實現更好的重建效果。文獻[24]提出的基于整體注意力的超分辨率重建網絡(Holistic Attention Network,HAN)結合了兩種注意力機制,從而捕獲更多有用信息,學習到不同深度、通道和位置之間信息的相關性。
上述方法顯著提高了重建性能,但是隨著網絡參數量的不斷增加,網絡的時間復雜度和空間復雜度也在逐步增大,導致這些方法無法應用于移動終端等輕量化場景。針對這一問題,文獻[25]提出的一種級聯殘差網絡(CAscading Residual Network,CARN)使用逐層逐塊的多級連接結構,使信息高效地傳遞,雖然減小了參數量,但是重建性能也大幅降低。文獻[26]提出了一種信息蒸餾網絡(Information Distillation Network,IDN),通過通道拆分策略,聚合當前信息與局部跳躍連接的信息,從而利用較小的參數量獲得了良好的性能。之后,文獻[27]又提出了信息多級蒸餾網絡(Information Multi-Distillation Network,IMDN),通過信息精細蒸餾模塊進一步改進了IDN,重復使用通道拆分策略,從而提取細粒度的圖像特征。IMDN在峰值信噪比和測試時間方面均有良好的表現,但其參數量大于VDSR[6]、IDN[26]和MemNet[28]等大多數輕量級重建網絡。
為了進一步減小網絡規模,文獻[29]提出了一種像素級注意力網絡(Pixel Attention Network,PAN),以極小的參數量取得了更好的重建結果,但其網絡結構中含有多個注意力模塊,需要為網絡設置苛刻的超參數和訓練策略,同時網絡的表征能力也有所下降,在相同數據集下訓練的效果略遜于其他方法。文獻[30]在此基礎上提出了一種基于attention in attention機制的重建網絡。此機制提升了重建能力,但網絡參數量從261 000增加至1 063 000。
為更好地平衡網絡參數量與性能,筆者提出了一種基于自適應權重學習的輕量化超分辨率重建方法。該方法基于像素級注意力網絡的整體框架,設計了一種堆疊多個自適應權重模塊(Adaptive Weight Block,AWB)的非線性映射網絡,每個模塊能夠提取到不同層級的特征信息。另外,引入了一種低參數量的自適應權重分配機制,將網絡分為注意力分支和無注意力分支。注意力分支用于增強有用信息,無注意分支用于學習其他信息。為了充分利用兩個分支提取的信息、增強高貢獻度信息并抑制冗余信息,利用自適應權重融合分支以動態方式分配兩個分支的權重,同時通過特定的卷積層拆分和融合兩條分支,大幅降低了注意力分支和無注意力分支的參數量,更好地與自適應權重分配機制結合,在保證網絡重建性能的同時,降低了網絡的參數量。
1 基于自適應權重學習的輕量化超分辨率重建網絡
1.1 網絡結構
筆者提出的基于自適應權重學習的輕量化超分辨率重建網絡由3個子網絡組成,即特征提取網絡、由多個自適應權重模塊構成的非線性映射網絡以及由上采樣模塊與3×3卷積層構成的重建網絡,其結構如圖1所示,特征提取網絡和重建網絡與PAN[29]方法保持一致,而文中提出的基于自適應學習的非線性映射網絡則是重建網絡的核心部分。
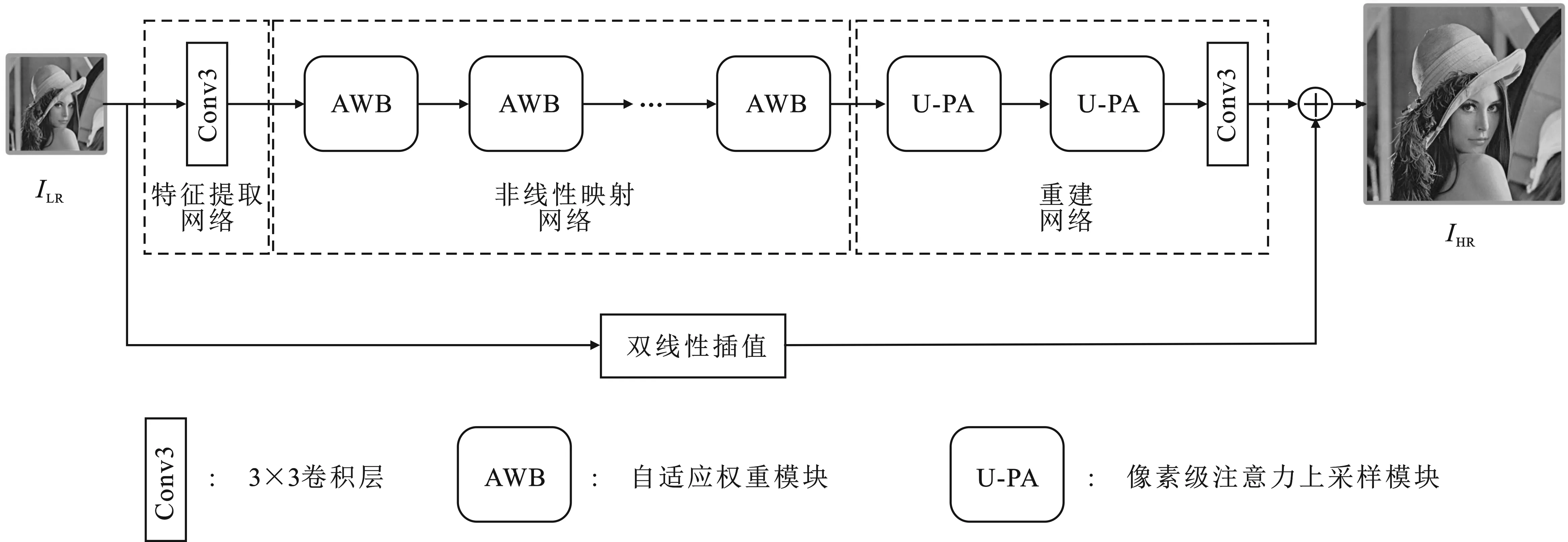
圖1 基于自適應權重學習的輕量化超分辨率重建網絡示意圖
重建時首先利用特征提取網絡對低分辨率圖像提取淺層特征。該過程可表示為
xshallow=fshallow(ILR) ,
(1)
其中,fshallow(·)表示卷積核大小為3×3的卷積層,其作用是從輸入的低分辨率圖像ILR中提取特征;xshallow是提取的特征圖。為了盡可能輕量化網絡,此處僅使用了一個卷積層。
完成特征提取后,利用由多個堆疊的自適應權重模塊(AWB)組成的非線性映射網絡來學習有足夠表征能力的映射關系,該過程可表示為
(2)
其中,xn為第n個自適應權重模塊輸出的特征圖。
最后,利用重建網絡將特征上采樣到指定的高分辨率圖像大小。參考PAN[29]方法,重建網絡由兩個帶有像素級注意力機制的上采樣塊(Upsampling block with Pixel Attention,U-PA)和一個3×3卷積層構成。在網絡中同時引入了全局連接操作fbi對輸入ILR執行雙線性插值,將插值結果與重建網絡的輸出進行逐元素相加求和,最終可以得到:
ISR=frec(xn)+fbi(ILR) ,
(3)
其中,frec(·)表示重建網絡,ISR是網絡最終的輸出結果。
1.2 自適應權重模塊
自適應權重模塊堆疊而成的非線性映射網絡是LAWN網絡的核心部分,也是網絡中參數量占比最大的部分。自適應權重模塊的結構如圖2所示。與PAN方法不同,筆者提出的自適應權重模塊包含3個分支:注意力分支、無注意力分支和自適應權重融合分支。其中注意力分支與無注意力分支分別使用1×1卷積層作為分支首層,記作fbranch(·)。假設xn-1和xn分別為第n個自適應權重模塊的輸入和輸出,則對于給定輸入特征xn-1,有
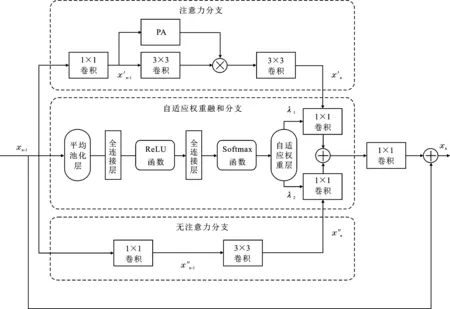
圖2 自適應權重模塊結構示意圖
x′n-1=f′branch(xn-1) ,
(4)
x″n-1=f″branch(xn-1) ,
(5)

注意力分支包含兩個3×3卷積層和一個1×1卷積層,其中在第1個3×3卷積層后加入了像素級注意力機制,該分支將x′n-1轉換為x′n。而在無注意力分支中,為了盡可能保證原始的無注意力信息,僅使用一個3×3卷積層進行特征映射,使用一個1×1卷積層進行通道重組,以便與自適應權重融合分支進行權重融合。
像素級注意力機制可以為不同通道分配不同的權重,因此筆者為每個自適應權重模塊都引入了注意力機制。但是并非所有注意力機制都可以提高網絡性能[30],網絡中仍然存在一些無效的、多余的參數。為了進一步增強特征表達能力,受文獻[31]的啟發,筆者提出了自適應權重融合分支作為模塊的第3分支,該分支利用加權求和分配注意力分支和無注意力分支的權重,自動舍去一些不重要的注意力特征以使兩個分支達到自適應平衡。注意力分支的輸出x′n和無注意力分支的輸出x″n分別傳入1×1卷積層提升通道數,然后乘以不同的權重λ1和λ2,并進行對應元素相加,最后傳遞到1×1卷積層輸出,與自適應權重模塊殘差相加,得到最終特征xn。
自適應權重模塊的框架受到了PAN方法的啟發,而二者的不同之處在于,筆者提出的自適應權重模塊利用1×1卷積層將兩個分支輸出特征(x′n與x″n)的通道數升至與xn-1相同的通道數;更為重要的是,利用自適應權重融合分支動態調整兩個分支的權重占比,進一步提高了網絡的表征能力,以上兩點使得LAWN網絡能夠在只增加極少參數量的前提下將自適應權重機制融入模塊內,提高了網絡表示的泛化能力。
2 實 驗
為了驗證筆者提出的基于自適應權重學習的輕量化超分辨率網絡的重建性能,選用了DRRN[9]、IDN[26]、CARN[25]、IMDN[27]和PAN[29]這5種輕量化超分辨率重建方法進行對比實驗。
實驗中使用DIV2K[32]作為訓練數據集,DIV2K數據集包括800張高質量的RGB訓練圖像。在測試中,使用Set5[33]、Set14[34]、BSD100[35]和Urban100[36]這4個數據集作為測試數據集。采用峰值信噪比(PSNR)和結構相似性(SSIM)[37]作為客觀質量評價指標。所有值均在YCbCr通道中的Y通道上計算。
2.1 實驗設置
在MATLAB中使用雙3次插值對高分辨率圖像進行下采樣,同時使用90°、180°、270°旋轉以及水平翻轉進行數據增強,生成大小為64×64的低分辨率圖像作為訓練數據,batchsize設置為32,總迭代次數為1×106,使用Adam優化器對網絡進行訓練,參數分別為β1=0.9,β2=0.99,ε=10-8。初始學習率設置為1×10-3,每隔2×10-5次迭代衰減一半。硬件配置為Intel(R)Core(TM)i7-8700K CPU @ 3.70GHz處理器,GeForce RTX 3090顯卡,32GB內存,實驗是在Ubuntu18.04.5操作系統下進行的,運行庫版本為CUDA 11.2,開發環境為Pytorch 1.8。
2.2 實驗結果與分析
不同方法在Set5、Set14、BSD100和Urban100數據集上進行不同放大倍數重建結果的客觀質量評價如表1所示,其中×2、×3和×4表示超分辨率重建的放大倍數分別為2倍、3倍和4倍。
從表1可以看出,筆者提出的LAWN方法在大多數數據集上的性能優于其他方法,尤其在Set5數據集上×2和×3時重建結果的峰值信噪比相較于排名第2的方法分別提升了0.03 dB和0.06 dB。雖然在×4時的重建結果與第2名基本保持一致或略有升降,但參數量僅有其65%,證明文中方法在性能和網絡大小之間實現了更好的平衡。

表1 在Set5、Set14、BSD100和Urban100數據集上不同超分辨率重建方法的平均PSNR/SSIM
在主觀質量評價方面,圖3給出了不同方法對BSD100數據集中的圖像58 060進行2倍超分辨率重建的結果,從圖中可以看出,IDN、CARN、IMDN方法的重建結果無法正確重建出第3組黑條紋,PAN方法雖然可以重建出黑色條紋,但重建效果沒有LAWN方法的重建效果清晰。圖4給出了不同方法對Urban100中的圖像062進行3倍超分辨率重建的結果。從圖中可以看出,其他方法的重建結果會將窗戶豎向邊緣錯誤地重建為橫向邊緣,而LAWN可以正確地重建出窗戶的邊緣輪廓。圖5給出了不同方法對Urban100中的圖像093進行4倍超分辨率重建的結果,其他方法重建的圖片會將橫向條紋錯誤地重建為豎向條紋,而LAWN對條紋的重建結果最為準確,與原圖接近。

圖3 BSD100數據集中img_58 060的2倍超分辨率重建結果

圖4 Urban100數據集中img_062的3倍超分辨率重建結果
3 結束語
針對主流超分辨率重建網絡參數量過大而無法應用于移動終端等場景的問題,筆者提出了一種基于自適應權重學習的卷積神經網絡,以實現精確且輕量化的超分辨率重建。筆者構建了一種自適應權重模塊提取圖像特征,使用注意力分支和無注意力分支提取不同信息,并設計自適應權重融合機制動態分配網絡中兩個分支的權重,從而在保證網絡性能的前提下大幅度降低網絡的參數量。實驗表明,筆者所提出的方法相較其他主流輕量化超分辨率重建方法有明顯優勢。在后續研究中可以繼續探索該網絡在其他視覺任務中的應用。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
