運算資源受限環境下的目標跟蹤算法綜述
2021-11-12 14:52:22武哲緯周世杰劉啟和
計算機工程與應用 2021年21期
武哲緯,周世杰,劉啟和
電子科技大學 信息與軟件工程學院,成都610000
視覺目標跟蹤是一個開放的、有吸引力的研究領域,其現實需求大且應用范圍廣泛,包括自動駕駛汽車[1-2]、自動機器人[3-4]、無人機跟蹤[5]等諸多方面。在復雜的現實場景中,目標跟蹤場景的不適定性使得該問題更具有挑戰性,如目標(例如行人、車輛、建筑等多種目標)的不規則形變、運動方式(例如高速運動、瞬移等情況)的變化以及環境條件的變化(例如照明變化、背景干擾等場景)增加了目標跟蹤算法難度。
目標跟蹤方法的核心思想是根據跟蹤對象的特征在時空上完成跟蹤對象的匹配和位置預測。根據特征提取技術手段不同,可將目標跟蹤算法分為兩類:基于傳統手工特征的目標跟蹤方法與基于深度卷積的自動特征提取目標跟蹤方法。
基于傳統手工特征的目標跟蹤方法根據其工作方式可大致劃分為核方法[6-7]、光流法[8-9]與判別相關濾波方法[10-12],主要以CamShift算法[13]、MOSSE算法[10]、SRDCF算法[14]與CFLB算法[15]為代表。這些算法主要采用包括SIFT特征[16]、SURF特征[17]、HoG特征[18]、Color Name特征[19]等通過仿照人類的視覺特點來提取圖像中具有區分能力的手工特征。
傳統的目標跟蹤方法盡管能夠完成目標的視覺跟蹤任務,但是仍存在跟蹤精度相對較低,且存在邊界效應(Boundary Effect)的不足。
深度學習理論被提出以來,對計算機視覺任務起到了巨大的推動作用,基于深度學習的目標跟蹤算法越來越受到關注。根據其采用的主要網絡結構不同,基于深度學習的目標跟蹤方法可劃分為基于孿生網絡結構的跟蹤方法[20-22]、基于GAN網絡結構的跟蹤方法[23]、基于自定義網絡結構的跟蹤方法[24-26]與基于卷積-濾波結構的跟蹤方法[27-29],主要以SiamFC算法[20]、VITAL算法[23]、MDNet算法[25]與ECO算法[30]為代表。
相比于傳統方法,深度神經網絡在跟蹤精度方面有顯著提高,但龐大的網絡架構需要占用更多的計算資源。如在邊緣設備(例如機器人、無人機等)中,其電力供應有限、內存與計算性能相對低,導致基于深度學習的目標跟蹤算法電力消耗較大且無法實時跟蹤目標,進而限制了這類算法的應用。
目前,現存的基于深度神經網絡的目標跟蹤方法的綜述中缺少針對其在運算資源受限環境下的設計方式與表現的研究。因此,本次工作的主要動機是對運算資源受限環境下的目標跟蹤方法做出調研,分析現有方法存在的問題并總結其在跟蹤任務流程中的設計策略。
本文的主要貢獻如下:
(1)本次工作以邊緣設備運算資源受限的需求作為出發點,以基于深度學習的目標跟蹤方法為主,梳理了現有目標跟蹤方法在跟蹤任務不同環節中的設計策略,并系統性闡述各類代表性方法的原理、優點與不足。以便于研究者根據需求設計符合要求的跟蹤模型。
(2)梳理了已有的單目標跟蹤數據集,分析了其包含樣本的尺寸、數量以及樣本的疑難場景分布。供研究者們根據實際的場景與設備采用所需的數據集。此外,還系統性總結闡述了目標跟蹤任務的評價方法與評價指標。
(3)總結了近年來目標跟蹤方法在提升跟蹤效果上的方法思路,主要可分為輕量化與緊湊的骨干網絡架構、基于預定義錨框的RPN模塊與相關濾波與卷積特征的融合。
1 目標跟蹤方法
目標跟蹤任務的目標根據輸入的幀序列與序列首幀中的目標位置來判斷后續幀中的目標位置。
目標跟蹤算法根據流程,可以劃分為如圖1的架構,分為特征提取、特征匹配、目標位置預測的三個部分。

圖1 目標跟蹤模型流程圖Fig.1 Flow diagram of object tracking model
在給定幀序列的初始幀中,指定一塊區域作為跟蹤目標,并將其作為后續跟蹤的參考模板(該幀也可稱為模板幀);后續幀則為搜索圖像,每一次搜索操作都是在后續搜索圖像中進行搜索[20]。
特征提取模塊由基礎的卷積神經網絡組成,該部分旨在降低模板幀和搜索圖像的空間維度,并獲取二者的高層次特征表示。
特征匹配模塊旨在根據前一階段的輸出,以特定的搜索策略在搜索圖像中尋找目標的位置信息;目標位置預測模塊根據特征匹配的結果,細化輸出目標的位置信息。
1.1 傳統目標跟蹤方法
傳統的目標跟蹤方法主要可以分為光流法、核跟蹤方法與相關濾波方法。以下開始依次論述。
1.1.1 光流法
光流(Optical Flow)是空間運動物體在觀察成像平面上的像素運動的瞬時速度[31]。光流法是利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關系,從而計算出相鄰幀之間物體的運動信息的一種方法。光流法的應用基于如下三個基本假設:
(1)亮度恒定:圖像中目標的像素強度在連續幀之間不會發生變化。
(2)時間規律:相鄰幀之間的時間足夠短,以至于在考慮運行變化時可以忽略它們之間的差異。
(3)空間一致性:相鄰像素具有相似的運動。
在跟蹤過程中目標由于外界環境或自身運動導致其自身的視覺外觀產生變化,對于依賴目標外觀的光流法而言,其應對變化的魯棒性相對不足,且計算時需要遍歷每一個像素點,計算效率相對低下,不能滿足實時性要求。
1.1.2 核跟蹤方法
核跟蹤方法的中心思想是沿與模板相似度最大的矢量方向不斷迭代候選目標框,并收斂于目標的真實位置。以MeanShift算法為例,該方法首先對目標外觀特征進行建模以得到關于目標特征的概率密度函數(也稱核函數),同樣地,對搜索圖像進行建模也可得到關于其特征表達的概率密度函數。通過梯度上升的方式迭代到相似度最高的位置,并將其作為跟蹤結果。但核函數方法在目標受到遮擋、模糊以及尺度變化時的表現不佳,Camshift算法[13]加入了尺度自適應機制以緩解尺度變化對跟蹤精度造成的影響。
但是由于核跟蹤算法存在對目標變化的魯棒性相對弱、對空間信息獲取不夠充分等不足,近年來對基于核的跟蹤方法的研究相對較少。
1.1.3 相關濾波方法
深度學習理論被提出之后相關濾波方法也結合深度特征進行了深入的研究,故單純的相關濾波方法被歸類為傳統方法,結合深度特征的相關濾波方法于1.2.4小節進行詳細闡述。在此僅對主要的傳統方法進行簡要介紹。
相關濾波方法也可稱為判別相關濾波(Discriminative Correlation Filter,DCF)方法,其理論發源于信號處理方面的研究。相關濾波方法的主要思想是通過最小化搜索圖像實際與預期的均方誤差來訓練一個濾波模板,利用該模板與搜索圖像采樣做相關運算,因兩相關信號的響應值大于兩不相關信號,故可通過最大化輸出響應得到待跟蹤目標的具體位置。其目標函數可以寫作[10]:

2014年,MOSSE算法[10]首次將相關濾波方法應用于目標跟蹤領域,通過多個樣本目標優化最小平方和誤差訓練更加魯棒的濾波器,并且實現濾波模板的在線更新以適應目標變化。此外還提出了使用峰值旁瓣比(Peak to Sidelobe Ratio,PSR)進行跟蹤置信度的評估。
CSK算法[32]在MOSSE算法的基礎上,為求解濾波模板的目標函數添加了正則化項來防止過擬合;其次,通過循環移位操作快速生成訓練正樣本;同時通過引入快速傅里葉變換(Fast Fourier Transform,FFT)來簡化計算,提高濾波模板的計算速度,以及引入核函數來進行預測。基于相關濾波的目標跟蹤算法以CSK算法為代表,其改進算法在傳統方法中占據主導地位。但是,CSK算法引入的循環移位操作和快速傅里葉變換同樣也帶來了邊界效應,邊界效應的存在讓跟蹤器只會過度關注于圖像中間位置,而處在圖像邊緣的目標難以被發現。
為了解決邊界效應所帶來的問題,研究者也從引入懲罰權重與強化特征表示兩方面展開了研究。SRDCF算法[14]與CFLB算法[15]采用加大搜索區域,同時對濾波模板進行約束來減少邊界效應的影響。SRDCF算法加入空域正則化機制,懲罰邊界區域的濾波器系數。懲罰權重滿足負高斯分布,對于越接近邊緣的區域賦予更高的懲罰權重。CFLB算法提出通過Mask矩陣的形式實現對背景信息的抑制。
在特征表示方面,也有研究者對CSK算法做出了改進。KCF算法[12]通過引入HoG特征來更好地描述目標形狀信息并與ColorName形成互補。SAMF算法[33]引入了多尺度檢測的方法,將濾波器在多尺度縮放的圖像上進行檢測,以同時檢測目標中心與尺度的變化。DSST算法[11]將目標跟蹤看成目標中心平移和目標尺度變化兩個獨立問題,首先通過訓練判別濾波器檢測目標中心平移,隨后通過MOSSE方法訓練另一個尺度相關濾波負責檢測目標尺度變化。
傳統跟蹤方法仍存在以下兩點不足:
(1)跟蹤精度相對較低,其深層次原因是無法魯棒地表達目標特征,外界環境或運動因素對目標特征的影響、背景對于目標特征表示的干擾都會導致跟蹤失敗的情況發生。
(2)判別相關濾波方法引入循環位移操作與快速傅里葉變換來循環生成訓練樣本與提高計算速度,但其也不可避免地引入了邊界效應,這導致了對快速運動目標檢測能力的降低。
1.2 基于深度學習的目標跟蹤方法
隨著深度學習理論的發展,深度神經網絡憑借其泛化性與特征表達的魯棒性走入了研究人員的視野。近年來的目標跟蹤領域的研究主要都集中在深度學習方面,由此可見基于深度學習的目標跟蹤方法具有重大潛力。
根據其采用的網絡結構可以將其劃分為孿生網絡結構、GAN網絡結構、自定義網絡結構與卷積-濾波結構。表1以年代為順序,列出了近年來具有代表性的基于深度學習的目標跟蹤方法,并著重體現其在適用場景、運算量、參數量與跟蹤速度等性能方面的表現。以下開始依次論述。

表1 (續)

表1 目標跟蹤網絡模型詳細信息Table 1 Details of object tracking model
1.2.1 孿生網絡結構
孿生神經網絡(Siamese Neural Network),是基于兩個人工神經網絡建立的耦合架構。孿生神經網絡以兩個樣本為輸入,輸出其嵌入高維度空間的表征,以比較兩個樣本的相似程度。狹義的孿生神經網絡由兩個結構相同,且權重共享的神經網絡拼接而成。
2016年,SINT算法[34]與SiamFC算法首先將孿生網絡結構應用于目標跟蹤技術的研究,并取得了長足的進步。前述兩方法奠定了基于孿生網絡結構的目標跟蹤方法的基本流程:
孿生網絡的一個分支提取目標特征,另一個分支提取搜索圖像的全局特征,最后通過互相關操作進行特征匹配生成目標位置的響應圖。
隨著基于孿生神經網絡的目標跟蹤理論的發展,研究者們主要從目標特征表示、特征匹配與位置預測兩個方面對跟蹤器的性能進行改進和提升,以下依次展開論述。
(1)目標特征表示
特征提取模塊主要采用預訓練的骨干網絡(例如:AlexNet[35]、VGG[36])ResNet[37]等),該部分主要承載著獲取模板幀與搜索圖像的特征的作用。
在基于孿生網絡的跟蹤方法中,特征提取部分方面的設計思路主要可劃分為直接由骨干網絡獲取卷積特征、卷積特征與中間特征結合、卷積特征與其他信息融合與目標模板更新等思路。針對目標特征表示任務,各種網絡結構之間的簡要對比如表2所述。表中關于自定義網絡結構與卷積-濾波結構部分的詳細敘述見1.2.3小節與1.2.4小節。
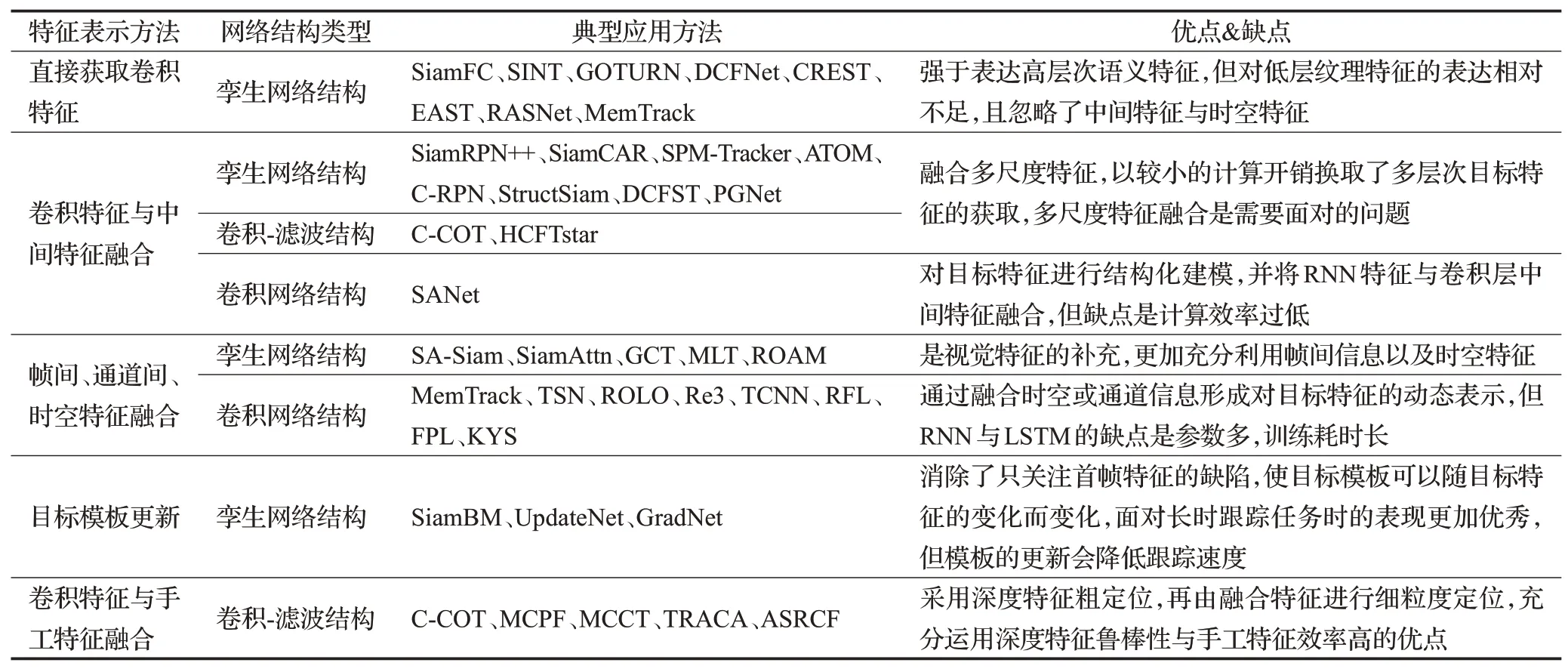
表2 目標特征表示方法優缺點的比較Table 2 Comparison of advantages and disadvantages of target feature extraction
直接通過骨干網絡獲取特征的思路將原始目標圖像或搜索圖像輸入骨干網絡,通過卷積計算后得到的結果作為目標以及搜索圖像的特征表示。使用此類方法的典型文獻包括SiamFC算法、SINT算法、GOTURN算法[38]、DCFNet算 法[39]、CREST算法[40]、EAST算法[41]、RASNet算法[42]、MemTrack算法[43]。該方法簡單直接,但在目標的尺度變化、旋轉等外觀狀態改變的情況下效果不佳。因為高層網絡具有更大的感受野,故對語義層面的信息具有更強的表征能力。但缺點在于其輸出的特征圖的分辨率更低,故缺乏幾何細節特征的表示。
為了獲取骨干網絡中間層所蘊含的對目標幾何特征信息的表示,研究者們采用了抽取卷積層之間的中間特征的方法。將中間特征與最終特征共同作為目標與搜索圖像特征的表示作為后續步驟的輸入。使用此類方法的典型文獻包括SiamRPN++算法[44]、SiamCAR算法[45]、SPM-Tracker算 法[46]、ATOM算 法[47]、C-RPN算法[48]、StructSiam算法[49]、DCFST算法[50]、PGNet算法[51]。相比于單純獲取最終特征圖的方法,采用中間特征可以增加較小的計算開銷的前提下獲取不同尺度下的特征圖,通過多尺度特征融合操作獲取不同層次的目標特征表示。相比于直接獲取特征方法而言,更加利用了低層網絡的小感受野、強幾何細節特征表達的優點。
除了關注視覺特征以外,由于跟蹤任務的幀與幀之間并非完全獨立的原因,故也不應忽略幀間以及通道間的信息。研究人員也在探索將幀間的時空信息、目標-背景的注意力機制與通道注意力機制等視覺以外的信息作為視覺特征的補充,以增強目標特征的表達。
例如,SA-Siam算法[52]采用語義分支與外觀分支分別過濾背景干擾與泛化目標外觀變化;SiamAttn算法[53]以Self-Attention模塊與Cross-Attention模塊分別增強上下文信息并融合補償兩個模塊之間的特征表示。此外,GCT算法[54]引入圖神經網絡結合時空特征以應對目標的特征變化。MLT算法[55]與ROAM算法[56]分別將元學習的方式應用在目標外觀特征的提取中以捕捉目標外觀的動態變化。
更新目標模板也是重要的研究方向。此前的跟蹤方法都是在視頻首幀指定目標位置,此后目標特征則不再更新,但隨著外界條件的變化或受目標自身運動的影響,目標的視覺特征也可能發生相應的變化。在此情況下根據第一幀的目標特征進行搜索將會導致不可避免的錯誤。SiamBM算法[57]使用線性融合的方式將初始幀與前序幀的預測結果融合;UpdateNet算法[58]采用專門的模板更新子網以自適應非線性的方式融合最新的目標特征;GradNet算法[59]旨在挖掘目標變化的梯度信息,以得到最優的目標特征表示。簡單的線性融合模板方式的缺點是初始特征所占的比重會以指數級降低,且誤差會以指數級增加;自適應非線性融合方式則可以自主學習目標變化,從而減小誤差對模板特征的污染,但其在目標被遮擋時仍會引入誤差因素;以梯度信息實現模板的更新在目標特征產生劇烈變化時,仍可以準確捕捉到特征位置。但是,模板更新策略由于需要在跟蹤任務執行的過程中重復計算、融合模板特征,往往會對跟蹤速度帶來較大影響。
(2)特征匹配與位置預測
特征匹配模塊通過特定的方式或策略,根據從特征提取模塊獲取的目標特征在搜索圖像中找到目標的位置。該模塊當前主流的設計策略有:區域建議網絡、匹配操作改進與位置預測改進等思路。
區域建議網絡(Regional Proposal Network,RPN)最早于目標檢測任務的Faster R-CNN算法[60]被引入。RPN網絡生成一系列預定義邊框,每個邊框位置代表可能存在目標的區域的預測。采用RPN方法的典型文獻包括SiamRPN算法、C-RPN算法、SiamRPN++算法、SiamMask算法、DaSiamRPN算法[61]、SPLT算法[62]。RPN網絡的引入可以大幅減少特征匹配階段的計算開銷,但是會引入額外的先驗知識(例如目標的縱橫比與錨框數量),額外先驗知識所導致的缺陷就是對于先驗知識沒有涉及到的形狀與形變的魯棒性較差,并且錨框數量的多少也直接決定了跟蹤性能。
為緩解由RPN網絡所帶來的局限性,研究人員又把思路放回到的Anchor-Free方法,例如SiamFC++算法[63]、OCEAN算法[64]與FCAF算法[65],Anchor-Free方法擺脫RPN網絡中預定義邊框帶來的先驗知識,回歸到以像素點為單位進行物體位置中心與邊框位置預測的計算思路中。
在匹配操作改進方面,DaSiamRPN算法與SPLT算法采用了“先局部-后全局”的目標搜索策略。SiamRPN++算法、EAST算法與PGNet算法提出了新的互相關策略以減少匹配計算時的計算開銷。CGACD算法[66]通過孿生網絡對目標進行初步定位,再在目標ROI內進行角點檢測以精細定位。同樣地,SA-Siam算法、TADT算法、RASNet算法也注意到在跟蹤不同的目標時,響應強烈的通道也不盡相同,故上述方法采用通道注意力機制,根據不同目標激活不同特征通道。
在位置預測方面,孿生網絡的預測結果為由目標特征圖與搜索圖像特征圖經過互相關操作產生的響應圖而得到的分類置信度,或是根據全連接層通過回歸計算得到的目標位置坐標。在后續的研究中,研究者們也在分類分支與回歸分支之外,引入了新的分支來完成細化網絡對最終目標位置的輸出。SiamFC++算法加入了質量評估分支以評估該幀跟蹤結果的質量,根據評估結果調整預測邊框的具體位置。PrDiMP算法[67]通過對噪音與不確定性建模,并以概率回歸的方式預測目標位置,達到較高的準確度。CLNet算法[68]引入CLN子網,通過結合正負樣本的統計信息得到一個緊湊的目標特征表達,以重現正負樣本的分布來指導預測。
也有研究者提出了新的預測思路——SiamMask算法在預測分支中加入一個Mask預測分支,在預測的同時也能完成像素級的實例分割任務。D3S算法[69-70]在SiamMask算法的基礎上提出使用橢圓與最小二乘法細化目標邊框的輸出。
總體而言,匹配操作改進部分的研究旨在降低計算開銷與提升匹配精度,降低開銷主要體現在“先局部后全局”與“粗匹配-細匹配”的二階段匹配策略;提升匹配精度表現在關注匹配時的通道注意力機制。位置預測方面的研究則關注于對現有跟蹤結果的評估以指導下一次預測。
1.2.2 生成對抗網絡結構
生成對抗網絡(Generative Adversarial Network,GAN)至少由一生成器與一判別器組成。生成模型旨在擬合已有數據的數據分布以生成新的符合原分布的數據,判別器旨在判別數據的真偽性。生成器與判別器相互博弈的過程中,二者的水平不斷提高以達到訓練者的要求。
VITAL算法利用GAN網絡生成一個Mask以增強目標的特征,同時訓練一對目標變化魯棒的判別器以判別目標與背景。SiamGAN算法[70]提出了一個基于GAN網絡的路徑預測器,以預測目標被遮擋后的運動路徑。
基于GAN網絡的大部分工作將GAN運用在擴充與增強數據集,以緩解數據集中某一特殊場景數據少或正負樣本不平衡方面的問題(例如SINT++算法[71])。GAN網絡結構本身在跟蹤領域應用相對較少,因為GAN網絡模型龐大、訓練難以收斂且計算開銷大,在前向推理時難以達到實時性要求,故在運算資源受限環境下不推薦使用。
1.2.3 自定義網絡結構
除上述孿生網絡與生成對抗網絡結構之外,也有研究者提出了符合自己設計理念的,為跟蹤任務專門設計網絡結構的跟蹤網絡。這部分的工作主要可劃分為目標特征表示以及學習策略與模型更新兩部分,以下依次展開論述。
(1)目標特征表示
通過融合卷積特征或時空信息,基于CNN結構的跟蹤方法同樣也在構造魯棒的目標特征表示做出努力。各思路的簡要比較如表2所示。
TCNN算法旨在捕捉目標特征的動態變化,構造了一個以CNN模塊組成的樹狀結構,葉節點保存的目標最新的特征,根節點保存歷史特征,再通過線性加權的方式組合目標最終特征。
FlowTrack算法[72]通過融合歷史幀的光流與特征信息獲取當前幀中的空間注意力,并通過空間注意力對不同特征通道進行加權得到通道層面的目標注意力。KYS算法[73]不僅只傳播目標的特征信息,連同場景、相似物體等有助于判別目標位置的其他特征表示也一同被傳播。并將其映射到當前幀,結合目標外觀特征進行跟蹤預測。
SANet算法[74]通過RNN對目標特征進行結構化建模,以提升模型的鑒別相似物體的能力,以跳躍連接的方式將RNN特征與卷積層中間特征進行融合。類似地,MemTrack算法、TSN算法[75]、ROLO算法[76]、Re3算法[77]、RFL算法[78]都使用了LSTM模塊以結合時域與空域的信息來進行目標特征提取任務。FPL算法[79]在目標被遮擋時,通過建立背景運動模型并使用卷積-LSTM網絡進行目標軌跡預測。
采用RNN或LSTM結構的模型都存在著模型參數多、訓練時難以收斂、耗時長的缺點,并且由于其為時間序列模型,無法執行并行操作,故該類模型的跟蹤效率為精度所付出的代價相對高昂,在運算資源受限的場景下需要慎重考慮。
(2)學習策略與模型更新
同樣地,也有研究者們在模型的訓練方式或學習方式上做出了研究,例如將元學習、強化學習、集成學習等方式融入進模型的訓練過程,在有限的數據集上提升訓練效率或優化訓練效果。
DAT算法[80]以循環學習的方式計算Attention Map,并且將其作為訓練階段的正則項使模型學習到對外觀變化具有魯棒性的特征。STCT算法[81]與MDNet算法采用在線學習與離線訓練相結合的方式訓練模型,MDNet的共享層權重由跟蹤訓練集共同訓練,專用層由每個視頻序列單獨訓練,在跟蹤過程中使用在線微調的方式更新專用層參數,由于對跟蹤任務專門設計了共享層網絡結構,并且對重難點樣本進行挖掘,使得跟蹤精度與同時期算法相比相對較高。MDNet的局限性在于在跟蹤過程中在線對專用層權重進行微調,使得其跟蹤速度遠未達到實時跟蹤的要求。RT-MDNet算法[82]通過ROI對齊的方式在識別速度方面對其進行了改進。MAML-Tracker算法[83]引入了元學習方法,讓跟蹤器學習一個好的初始化權重,在少量訓練數據上經過少數更新即可收斂。ADNet算法[84]通過強化學習產生目標的動作序列,以控制目標BBox進行移動或尺度變換。模型更新方面UCT算法[85]通過引入峰值信噪比進行有效的模型在線更新,并且可以通過更換輕量化的骨干網絡以達到更高的速度。BranchOut算法[86]通過集成學習的方式,并行學習多個卷積分支的信息,但在模型更新期間,通過多重伯努利分布隨機篩選一部分分支進行模型更新,達到類似DropOut的效果以防止過擬合。
總體上看,學習策略與模型更新方面的研究主要在模型的訓練階段體現。離線的預訓練模型旨在大規模數據集上提取到通用的目標特征表示,但也容易收到因訓練數據不平衡與先驗假設導致的識別問題,通過離線訓練與在線訓練相結合的方式,在獲取通用特征表示的同時也完成對特定場景或目標的特征信息的學習。
1.2.4 卷積-濾波結構
卷積-濾波結構是深度特征與相關濾波方法的結合。相比于深度特征,手工設定特征計算速度快,特征的每一個維度具有可解釋性的特征表示,但手工特征面對目標變化與形變無法保證提取效果的魯棒性。基于CNN網絡的深度特征提取網絡通過構建網絡層次,在大規模監督數據集上進行網絡參數的訓練,以端到端的形式提取輸入圖像的特征。卷積特征的表達效果魯棒、泛化性強,但是也存在可解釋性較差與前向推理速度慢的問題。卷積-濾波結構通過結合二者的優點,努力實現跟蹤精度與速度的平衡。
該部分的工作可以歸為目標特征表示、計算方式與優化策略兩類,以下依次展開論述。
(1)目標特征表示
卷積-濾波結構的目標跟蹤方法在目標特征表示方面的思路大體一致,可劃分為手工特征與卷積特征的融合、中間特征與卷積特征的融合與空時特征與卷積特征的融合三部分。
手工特征與卷積特征融合方面,MCPF算法[87]首次采用多任務濾波方法進行多種特征(CN、HOG、CNN)特征的融合。MCCT算法[88]、TRACA算法[89]都設置了多個跟蹤器或編/解碼器,根據不同目標自主組合深度特征與手工特征。值得注意的是,MCCT算法設置了7個子跟蹤專家,分別組合代表低、中、高層的深度特征與手工特征生成融合特征進行跟蹤,并根據7個跟蹤器的結果進行評價與結果選擇,得到最后的結果。由于堆疊了多個跟蹤專家,使得其跟蹤速度相對緩慢,即使通過DCF結構設計以及樣本共享策略以優化性能,MCCT的跟蹤速度仍只有8 FPS,無法滿足實時跟蹤需求。ASRCF算法[90]在傳統DCF的基礎上增加了自適應空間正則項,通過深度特征估計目標定位,根據手工特征以估計尺度變化。
為了應對目標的尺度變化,C-COT算法通過整合多尺度的中間特征圖以訓練連續空間域上的卷積算子進行跟蹤,HCFTstar算法[91]使用不同尺度下的特征圖以捕捉目標位置表示,并且引入RPN網絡進行跟蹤失敗后的重檢測。SACF算法[92]以空間特征對齊的方式估計目標的變換,使預測的ROI區域具有正確的尺度與縱橫比。
CREST算法通過空域與時域層面的殘差學習比較當前幀與初始幀獲得目標的特征變化信息。
如1.1.3小節所述,相關濾波方法的循環位移操作引入了邊界效應,為了緩解邊界效應的影響,LMCF算法[93]融合結構化SVM的判別力與相關濾波算法高速特性,并且通過多峰前向檢測降低相似物體的干擾。DRT算法[94]與LSART算法[95]將目標區域等分為九宮格,通過賦予其不同的可靠性權重以降低跟蹤模板內無用區域中存在的冗余信息。
手工特征與深度特征的融合在跟蹤精度方面對比于僅采用手工特征的方法實現了超越;在跟蹤速度方面,某些方法比僅采用深度特征的方法也有所提升。深度特征與手工特征的融合是值得關注的研究方向,當遭遇目標丟失時的再檢測機制同樣也能很好地提升跟蹤方法的跟蹤表現。
(2)計算方式與優化策略
此方面的工作主要集中在通過對損失函數、計算方式的優化,提高計算速度與跟蹤精度。
計算速度提升方面,ECO算法通過因式分解卷積操作,減小冗余訓練數據,與降低在線更新頻率來提高跟蹤速度。RPCF算法[96]將ROI池化策略引入到相關濾波的方法中,并通過對濾波器目標區域的系數進行限制以達到簡化計算的目的。CFCF算法[97]針對基于跟蹤網絡的損失函數提出了高效的反向傳播算法以降低模型更新與訓練的時間。GFS-DCF算法[98]引入空域、時間、通道三方面正則項,以降低空間與通道維度的尺寸實現特征壓縮,時間平滑正則項對幀間估計提出了約束,共同提高跟蹤速度與精度。IBCCF算法[99]與MCPF算法都采用“粗匹配-細匹配”的二階段匹配策略,減少在無效區域的計算,并提高可能存在目標區域的注意力。
跟蹤精度的提高方面,deepSTRCF算法[100]與ARCF算法[101]引入正則化項捕捉目標特征的最新變化與壓制相似物體的干擾。AutoTrack算法[102]在STRCF算法的基礎之上,通過局部與全局的響應變化來自動更新時間與空間正則化,并且在更新過程中自動調整正則化項中的超參數以自適應環境與目標的變化。
相關濾波與卷積網絡的融合思路是成功的,特征融合策略不僅發揮了每種特征在表征方面的優勢,也能更好地為后續跟蹤步驟做出鋪墊;計算方式的研究在特征壓縮、特征匹配上的改進也對性能與精度帶來了提升。
1.2.5 小結
深度學習方法較大程度地提高了應對目標特征變化時的魯棒性與泛化性,但也存在共通性的缺點:
(1)跟蹤速度相對較低。隨著網絡模型的加深,算法的跟蹤精度得到了較大提升,但在速度方面的表現卻不盡人意。運算資源受限的設備在網絡中往往扮演數據采集、初步分析的底層角色,故其對于跟蹤速度的要求更高。
(2)數據需求量大。深度模型的訓練依賴于大量的數據與超參數,現有的訓練樣本并不能完全重現應用場景中的樣本分布。并且單純依賴初始幀中的正樣本,也導致了正樣本匱乏的不足。樣本的不足進一步導致了泛化能力與場景遷移能力的不足。
表3 詳細描述了孿生網絡結構、GAN網絡結構、卷積網絡結構與卷積-濾波結構的目標跟蹤算法優缺點。
從表3可以看出,當前的研究工作基本圍繞著跟蹤速度與跟蹤精度兩個要點而展開。孿生網絡結構靈活度高,不僅可以與不同的骨干網絡(例如搭載VGG、ResNet、AlexNet等多種骨干網絡)、相關層、RPN網絡(例如SiamRPN算法與其改進方案)與評估分支(例如SiamFC++算法與CLNet算法)進行組合也可以與不同的搜索策略與學習方式進行互補。其次,孿生的網絡結構能夠以同樣的表征方式提取目標與搜索圖像的特征。通過對孿生網絡結構的進一步改進,現有的孿生網絡結構可以提供速度與精度上的統一。孿生網絡的缺陷在于僅僅使用預訓練的模型難以應對目標特征的改變,并且容易出現過擬合的問題,附加額外模塊進行在線更新與微調是解決的方向。

表3 基于深度學習的目標跟蹤技術簡要對比Table 3 Comparison of DL-based object tracking methods
GAN網絡結構能夠相對有效地解決數據分布不均勻與正樣本匱乏的問題。并且通過數據增強的方式進一步提升目標特征的魯棒性表示。如前所述,GAN方法的缺陷在于訓練困難且速度較低。
卷積網絡結構的突出特點是結構簡單。現有的基于深度學習的目標跟蹤方法大多數采用的是為分類任務所開發的骨干網絡,而跟蹤任務中并不需要為目標具體劃分類別,只需要完成“目標-背景”的二分類即可。故此方面,骨干網絡存在較大的冗余。卷積網絡發揮輕巧的特點,降低特征提取所耗費的計算開銷,能得到更高的跟蹤速度,并且通過引入其他的優化方式進一步提高跟蹤精度。
卷積-濾波結構旨在發揮卷積特征的語義表征能力與DCF方法的速度優勢,并且與手工特征相結合,故其在特征表示方面的速度表現要優于全卷積骨干網絡。相比于單純的深度模型,相關濾波算法有著更加扎實的理論支撐,所以在特征匹配與位置預測方面的改進工作的方向也更加明朗。
2 數據集與評價指標
跟蹤模型的訓練與改進都以數據集為基礎,模型的質量需要通過評估指標以進行評估。在本章中,將介紹用于訓練目標跟蹤模型的數據集、評估方法以及評估指標。
本文調研了目標跟蹤領域主要使用的數據集,并標注了其含有的視頻序列數量、分辨率、疑難場景等信息,具體闡述如表4所示。

表4 目標跟蹤數據集詳細信息Table 4 Details of object tracking datasets
2.1 目標跟蹤數據集
OTB2013[103]是于2013年提出的跟蹤數據基準,其由51個手工標注的視頻序列組成。2015年,作者將OTB2013數據集包含的視頻序列數量擴展至100個,此為OTB2015[104]數據集,其分辨率均為640×480。
同樣地,自2013年開始,VOT視覺跟蹤挑戰被提出,隨之而來的是每年更新細化的VOT系列數據集。VOT2013[105]數據集包含16個圖像序列,分辨率為320×240,VOT2014[106]與VOT2015[107]分別將圖像序列擴充至25與60個。且自2018年,VOT挑選出持續時間相對長的圖像序列組成了長時跟蹤數據集,分別為VOT-LT2018與VOTLT-2019。2020年,VOT2020[108]又進一步劃分為短時跟蹤集VOT-ST2020與長時跟蹤集VOT-LT2020,分別包含60與50個圖像序列。
除了RGB圖像,VOT數據集還提出了基于熱成像的視覺跟蹤數據集VOT-TIR系列數據集(包含VOTTIR2015[109]、VOT-RGBTIR2019與VOT-RGBTIR2020)與基于深度數據的視覺跟蹤數據集VOT-RGBD系列數據集(VOT-RGBD2019與VOT-RGB2020)。
2014至2015年,ALOV300++[110]數據集與囊括128個圖像序列的TColor-128[111]數據集被提出,ALOV300++數據集包含了315個圖像序列,更傾向于檢驗目標跟蹤算法在面對不同場景下的魯棒性。
2016年,NUS-PRO[112]數據集被公布,與之一同公布的還有源自于它的子集的BUAA-PRO數據集,NUS-PRO數據集由365個圖像序列組成,其目標類型主要為人體以及剛性物體。同年,由無人機視角捕獲畫面的UAV123[113]數據集被公布,其中囊括123個源自于無人機航拍畫面的圖像序列。并且也從中挑選出20個序列作為其另一專注于長時跟蹤數據集的版本(UAV20L數據集)。
2017年,在高幀率環境下的NfS數據集[114]被提出,其囊括了100個幀率達到240 Hz的圖像序列。同年,也是來自于無人機采集畫面的高分辨率DTB70[115]數據集被提出,其包含70個分辨率達到1 280×720的圖像序列。
2018年后,提出的數據集主要在長時跟蹤與大尺度方向做出改進。OxUxA[116]數據集主要針對長時跟蹤場景,提出了包含366個視頻序列的數據集,其平均時長達到140 s。TLP數據集[117]包含了50個同時滿足長時跟蹤與高分辨率的圖像序列,平均長度達到484 s。TrackingNet[118]數據集也由30 643個圖像序列組成,作者將其劃分為兩個子集,其中訓練集包含30 132個序列,測試集包含511個序列。
2019年發布的GOT-10k[119]數據集包含10 000個圖像序列,大尺度目標跟蹤數據集LaSOT[120]包含1 400個圖像序列。
對于每一個圖像序列而言,其符合的具體場景有所不同,例如光照、遮擋、形變等干擾因素。近年來,數據集的開發者們也會為每一個視頻序列根據所處的環境打上特定的標簽,以評估模型對特殊條件下的性能與表現。同樣地,這些標簽也是目標跟蹤技術的難點和挑戰,各種疑難場景的具體闡述如表5所示。

表5 疑難場景詳細信息Table 5 Details of object challenge scenario
2.2 評價方式與評價指標
目標跟蹤模型的量化評估需要一系列指標加以指示。將總結目標跟蹤網絡的魯棒性評估方法與準確性評估指標。
2.2.1 魯棒性評估方法
(1)一次評估方法(One-Pass Evaluation,OPE)
最常用的評價方法為OPE方法,該方法指根據真實標注的位置初始化測試視頻序列的第一幀,然后根據結果計算跟蹤精度與成功率(計算方法在2.2.2節中詳細闡述)。
但是,OPE方法存在兩個缺點,一是跟蹤算法可能過度依賴于第一幀標定的初始位置,在視頻幀序列不同中間位置開始跟蹤可能會造成精度上的降低;二是大多數算法在遭遇跟蹤失敗(IoU為0)的情況下沒有重新初始化的機制。針對上述兩個問題,又提出了針對跟蹤魯棒性的評估方法。
(2)時間魯棒性評估(Temporal Robustness Evaluation,TRE)
該評估方法表示在整個圖像序列中,從時間序列上添加擾動,指定若干中間幀分別作為跟蹤算法的初始幀進行模型初始化,直至圖像序列結束,在此條件下根據結果計算跟蹤精度與成功率。
(3)空間魯棒性評估(Spatial Robustness Evaluation,SRE)
該評估方法旨在對空間角度為真實標注添加擾動,以檢驗跟蹤方法是否對錯誤初始化具有足夠的魯棒性,通過對真實標注框進行分別8次位置偏移與4次尺寸縮放,位置偏移包括4次水平與垂直方向的偏移以及4次角方向的偏移,偏移量為目標尺寸的10%;尺寸縮放由目標尺寸的80%以10%的步長逐步擴展到120%,綜合記錄上述12次偏移操作情況下的跟蹤精度與成功率取算術平均值,作為其在SRE體系下的評分。
(4)帶恢復的OPE評估(One-Pass Evaluation with Restart,OPER)
在OPE方法的基礎上,在跟蹤模型遭遇跟蹤失敗的情況時,重新根據真實標注初始化跟蹤模型,并在后續幀中繼續展開跟蹤。
(5)帶恢復的SRE評估(Spatial Robustness Evaluation with Restart,OPER)
同理。
2.2.2 準確性評估方法
(1)成功率(SuccessRate)
該指標表示,在給定一閾值T的情況下,計算模型預測位置邊框與目標真實位置邊框之間的IoU。若高于閾值T,則該幀計為跟蹤成功;否則為失敗。以此計算所有測試集中的平均成功比例。對于包含N幀的測試序列,測試結果與真實結果分別用Prei與GTi表示,則成功率的計算方法可寫作:
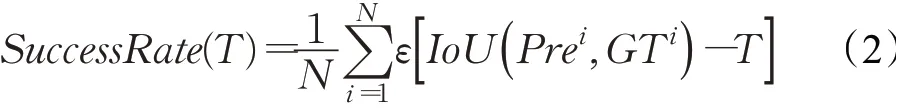
其中,ε(·)為階躍函數,記作:

通過繪制Success Rate(T)關于自變量閾值T的曲線圖,可以得到該模型的Success Plot。圖2則為OTB2015數據集(亦可稱為OTB100數據集)上,以OPE方法測試得到的各算法的Success Plot,以AUC指標作為各閾值下的評分。(2)精度(Precision)
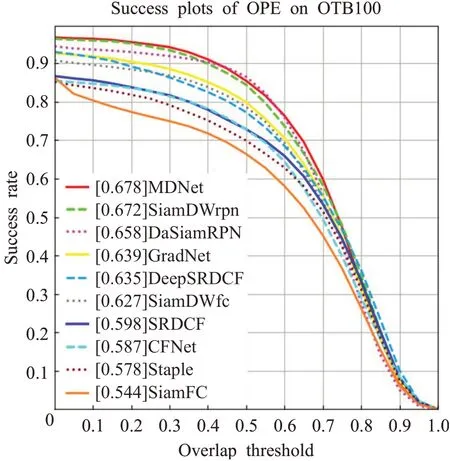
圖2 OTB2015數據集的Success Plot Fig.2 Success Plot on OTB2015 dataset
該指標表示,在給定一閾值T的情況下,計算模型預測位置與目標真實位置之間的中心位置誤差(Center Location Error,CLE)。若二者歐氏距離高于閾值T,則該幀計為跟蹤成功;否則為失敗。但是該指標在同樣IoU的情況下,在面對尺寸大小差距過大的目標時其CLE的差距十分明顯。歸一化精度在計算CLE時考慮目標尺寸因素,以歸一化的方式緩解由目標尺寸對絕對歐式距離的影響,以此計算所有測試集中的平均成功比例,可寫作:同樣地,通過繪制精度關于自變量閾值T的曲線圖,可以得到該模型的Precision Plot。
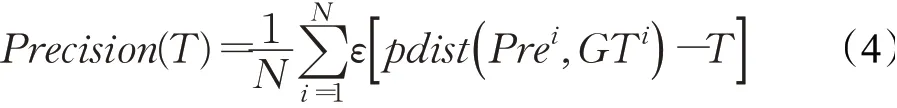
(3)曲線下面積(Area Under Curves)
該指標通過計算Success Plot或Precision Plot曲線與坐標軸所圍成的面積,以評估目標算法在不同閾值下的綜合表現。AUC的取值范圍為[0,1],數值越高,代表模型的跟蹤能力越強。可以如下表示:

(4)期望平均覆蓋面積(Expected Average Overlap)
該指標可以同時反映跟蹤的精度與魯棒性。無論跟蹤是否成功,EAO通過計算幀序列中的平均IoU得到。在遭遇跟蹤失敗的情況時,其IoU為記為0。則其可表示為:

3 適配運算資源受限環境下的改進方法
3.1 輕量化與緊湊網絡結構設計
隨著研究的推進,深度神經網絡的層數也在進一步加深,由AlexNet的7層發展到VGG的16~19層,再到GoogleLeNet的22層。但網絡深度達到一定程度后,模型的精度會迅速下降,同時前向傳播的計算消耗也會增大。結合表1的結果,在跟蹤速度表現良好的算法(例如SiamFC算法、GradNet算法、RASNet算法、SiamRPN算法、SPM-Tracker算法、GOTURN算法、SiamFC++算法)中,絕大多數方法都采用了相對淺層的AlexNet作為骨干網絡。采用VGG的方法(例如TCNN算法、VITAL算法、MDNet算法、SANet算法、TSN算法、DAT算法)的速度表現相對不夠優秀。即使網絡層數的加深可以提高特征提取的效果與增強模型識別的泛化性能,但由此帶來的性能損耗相比增益而言,對于移動平臺而言仍然是得不償失。
緊湊結構設計方面,SiamRPN++算法與C-RPN算法采用了重復堆疊模塊的結構設計思路;SiamGAN算法與VITAL算法采用了GAN網絡模塊以增強跟蹤網絡在特殊條件下的魯棒性;TCNN算法采用了樹狀結構來組織CNN節點。上述工作加大了網絡的復雜程度,提高了精度,但在實時性方面也付出了代價——TCNN算法在NVIDIA GTX Titan X的環境下僅能達到1.5 FPS;SiamGAN算法在2塊NVIDIA GTX1080ti的環境下僅能達到29 FPS;VITAL算法在NVIDIA Tesla K40c運行環境下只能達到1 FPS的跟蹤速度,在運算資源受限的環境下的表現會更加緩慢。相比之下,結構簡單的方法(例如GOTURN算法、SiamRPN算法、SPM-Tracker算法)更能夠發揮速度優勢,達到在受限環境下實時跟蹤的目標。
3.2 基于預定義錨框的RPN模塊
RPN模塊包含兩個分支,分別為分類分支與回歸分支,旨在生成k個包含可能目標的邊框。RPN模塊第一次在跟蹤領域的應用是在SiamRPN算法中,隨后也衍生出了性能優秀的DaSiamRPN算法、SiamRPN++算法、SPM-Tracker算法。
但是,RPN網絡的性能依賴于預定義的超參數,例如生成錨框數k與建議框預定義尺寸。若生成錨框數k過大,則會對性能產生影響;k過小則會嚴重影響精度。并且,RPN網絡對于生成錨框的縱橫比做出了預定義,如果遇到形態變化劇烈的跟蹤目標,則會遭遇跟蹤丟失的情況。即RPN網絡的人為設置的超參數限制了跟蹤模型的速度與魯棒性,探索適合RPN網絡的超參數或者自動學習適合RPN網絡的超參數是值得探究的話題。
3.3 相關濾波方法與卷積特征的結合
在視覺跟蹤任務中,濾波器只對于跟蹤目標相似的區域產生高響應比信號。在深度學習方法被提出之前,目標跟蹤領域的工作主要集中在通過相關濾波方法進行跟蹤(例如MOSSE算法、CFT算法、KCF算法)。
隨著CNN結構的發展,研究者注意到卷積操作與相關濾波算法的相似性,故將二者結合起來以獲得更好的跟蹤性能。DCFNet算法、CFCF算法、C-COT算法、ECO算法、DeepSTRCF算法、UPDT算法都是運用基于CNN的骨干網絡提取特征。例如UPDT算法,通過骨干網絡提取深層語義特征獲取目標的魯棒性特征,再通過傳統的HoG與CN特征獲得目標特征的精確性特征,并將其分開訓練,再結合相關濾波算法以達到跟蹤精度與速度上的平衡。
4 總結與展望
本篇文章以運算資源受限場景為出發點,系統梳理了近年來基于深度學習的目標跟蹤網絡模型,為研究人員在模型設計策略、訓練數據集與網絡壓縮方法的選擇方面提供了便利。首先總結了網絡跟蹤模型的通用體系結構,并根據體系結構的不同模塊,介紹了現有網絡模型的設計策略;其次,詳盡總結了現有的目標跟蹤數據集,根據數據集發表的年份、涵蓋數據的特征進行了闡述,而且匯總了跟蹤方法的評價指標與計算方法;最后總結可用于運算資源受限環境下的模型改進策略。
目標跟蹤作為計算機視覺的重要組成部分,在許多熱門領域都有所應用。但是目標跟蹤技術領域仍然存在許多問題亟待深入系統的研究。同樣地,這些問題也指引著研究人員繼續探索的腳步,例如:
(1)實時跟蹤
邊緣設備的跟蹤場景決定了其對跟蹤算法實時性的高要求。除此之外,深度神經網絡的準確性也應當受到關注。在不顯著降低預測精度與訓練過程時間復雜度的前提下,壓縮模型的參數數量,降低模型拓撲結構的復雜度與計算開銷。當前已有研究者們在模型壓縮領域取得了重要的成果,將跟蹤算法與神經網絡模型壓縮技術結合(包括模型剪枝、權重量化與知識蒸餾等方法)或計算加速方法,根據具體使用場景的特點尋找到滿足不同種類邊緣設備需求的跟蹤方法。
(2)長時跟蹤
已有的跟蹤算法主要集中在短時跟蹤的場景,并達到了較高的跟蹤結果。但是,邊緣設備對長時跟蹤的需求同樣不容忽視。相比于短時跟蹤,研究者們對長時跟蹤方法的研究相對較少。并且已有跟蹤算法在面對長時跟蹤任務時的表現也有待驗證。長時跟蹤任務的主要挑戰是歷史幀中的錯誤會不斷累積,導致跟蹤效果會不斷下降;并且長時跟蹤訓練樣本也相對較少。因此,在跟蹤器表現降低時消除誤差或在全搜索圖像內進行重檢測的將會是有價值的研究方向。
(3)疑難場景的處理
在2.1節中列舉了跟蹤場景中存在的難點場景(例如光照變化、尺度變化、目標消失等)。現有的目標跟蹤方法無法在所有特殊條件下都表現良好的效果,根據“沒有免費的午餐”原則,也無法找到能夠適配所有條件的跟蹤算法。但是,構建合適的網絡結構以獲取目標的魯棒特征表示,仍然是研究者們需要持續研究的方向,在此基礎之上,結合具體的工作環境,選擇符合要求的訓練集,以最大限度地滿足任務要求的需求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
