基于技術指標和隨機森林的股價走勢預測算法
2021-11-15 15:31:38王惠瑩郝泳濤
現代計算機 2021年27期
王惠瑩,郝泳濤
(同濟大學電子與信息工程學院計算機科學與技術系,上海 201824)
0 引言
隨著我國人均可支配收入的提高,人民群眾的理財意識不斷增強,投資股票市場的熱情不斷高漲。股票投資的顯著特點是高風險、高收益,如何降低甚至規避投資失敗的風險,一直是社會各界人士關心的重點話題。
股票價格表現為一種十分不穩定的時間序列,它的走勢受多種因素的影響,例如經濟因素、政治因素和公司經營狀況等。縱觀股票市場的投資歷史,大眾投資者普遍使用基本面分析、技術分析和演化分析來預測股價走勢。近十年來,機器學習算法在金融時間序列預測方面取得長足的發展。Krauss等[1]分析了在統計套利背景下,使用集成深度神經網絡(DNN)、梯度增強決策樹(GBDT)、隨機森林(Random Forest)三種算法開發交易策略:每天買入若干只低估股票、賣出若干只高估股票,交易信號由預測每只股票超過日內收益中位數的概率生成。實驗發現每天買入、賣出10只股票時收益最高,日回報率可達0.45%。Fischer T et al[2]在此基礎上以長短期記憶神經網絡(LSTM)為例,研究深度學習算法在金融市場預測中的性能表現,發現日收益率提高到0.46%。Pushpendu Ghosh et al[3]采用Krauss et al[1]中的統計套利交易策略,引入關于開盤價的回報為特征,使用隨機森林和長短期記憶神經網絡分析在預測標普500成份股樣本外方向移動方面的有效性。實驗結果表明,扣除交易成本前,隨機森林和長短期記憶神經網絡的日回報率分別是0.54%和0.64%。
投資機構已經開始在股票交易中使用量化投資用于決策。與傳統投資策略相比,量化投資在系統性、準確性、及時性和分散化上有著明顯優勢。本文選取MACD、ADX、RSI、BB、FI五個技術指標,與下周股價走勢一起用于構建特征工程,建立一個基于隨機森林的股價走勢預測模型。
1 隨機森林算法原理
隨機森林以決策樹為基學習器,在Bagging集成的基礎上,于生成決策樹的過程中引入隨機屬性選擇,基決策樹之間差異度的增加會導致最終集成的隨機森林泛化性能的提升。隨機森林的具體構造過程如下:
(1)假設有m個帶標簽的樣本,有放回地隨機選擇m個樣本組成采樣集,用采樣集訓練決策樹;
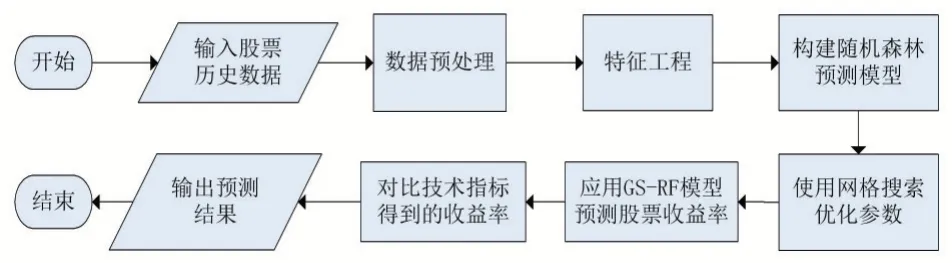
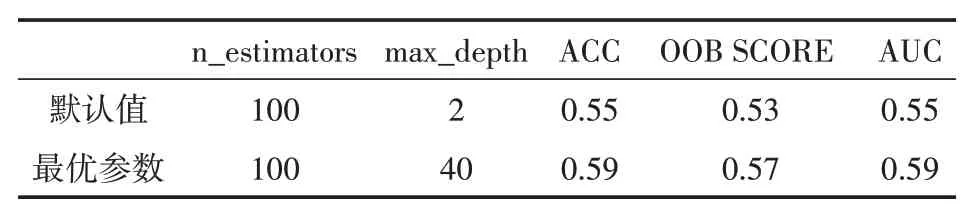
(2)分裂決策樹的結點時,從當前結點的屬性集合(假定含有d個屬性)中隨機選擇k個屬性作為候選屬性集(k (3)整個決策樹生成過程中每個結點都按照步驟(2)分裂,直至不能再分裂為止; (4)按照步驟(1)~(3)建立大量決策樹,這些決策樹就構成隨機森林了。 技術指標是從股票價格時間序列數據中計算出的重要參數,投資者廣泛使用技術指標檢測交易信號。本文使用的技術指標如下: MACD的計算公式: 其中,MACD=異同移動平均線,C=收盤價,EMAn=n天指數移動平均線。MACD低于SignalLine時生成賣出信號,反之,則生成買入信號。 ADX的計算方式比較復雜,涉及到價格正向移動距離+DM、價格負向移動距離-DM、真實波動幅度TR、正向方向性指數+DI和負向方向性指數-DI等中間變量。 首先,計算動向變化: 其中,high(t)表示今日最高價,low(t)表示今日最低價。 然后,計算真實波幅: 其中,close(t-1)表示昨日收盤價。 接下來,計算動向指數: 最終可計算出ADX值: +DM和-DM分別代表價格正向與負向的移動距離;+DI和-DI分別代表波動率修正后上漲和下跌趨勢。只要存在明顯趨勢,無論上漲還是下跌,DX值隨著趨勢強弱變動在0~100范圍內波動,ADX是DX的14天平均線。 RSI的計算公式: RSI以數字的方法衡量買賣雙方的力量對比,是一個經典的動量指標。 BB的計算公式: 其中,MA(close,m)表示收盤價的m日簡單移動平均,UB表示上軌線,LB表示下軌線。 BB利用波帶顯示股價的安全高低價位,從而確定股價的波動范圍及未來走勢。 FI的計算公式: 其中,close(t)表示今日收盤價,vol(t)表示今日成交量。 FI用于指示上漲或下跌趨勢的力量大小。收盤價之差越大,力量越大;成交量越大,波動性越強。 除了上述5個技術指標,本文將下周股價走勢也作為一個特征用于模型訓練。 如果下一周股票收盤價大于當前收盤價,標記為1,反之則標記為0。 優化參數是提升模型泛化能力的重要手段。為了降低參數值隨機選擇的不確定性,本文構建了GS-RF模型,利用網格搜索優化決策樹的數量(n_estimators)、決策樹的最大深度(max_depth)和是否采用袋外誤差評估模型(oob_score)三個參數。具體步驟如下: (1)獲取股票歷史數據集,并進行數據預處理; (2)構建特征工程; (3)把數據分為訓練集和測試集,建立隨機森林預測模型; (4)結合網格搜索和隨機森林模型,確定最優參數組合,建立GS-RF預測模型; (5)使用GS-RF模型預測股票未來收益率; (6)對比使用技術指標的預測收益率,分析模型有效性。 圖1 實驗流程 本文實驗在英特爾i5 2.4 GHz四核八線程CPU,16GB RAM,Windows 10操作系統的計算機上進行,使用Python語言編程,應用pandas、numpy、tqdm、tushare、talib、sklearn等工具包。 測試參數優化能否提高模型的泛化能力,利用tushare工具包下載中國平安2012年1月1日至2021年7月1日的開盤價、收盤價、最高價、最低價以及成交量等歷史數據,共含2304個交易日。 按照3∶1的比例將數據拆分成訓練集(1728個交易日)和測試集(576個交易日),用訓練集訓練隨機森林預測模型;然后用網格搜索優化決策樹的數量、決策樹的最大深度和是否采用袋外誤差評估模型三個參數,設定評估指標是3折交叉測試集得分的平均值,最后用選出的參數組合構建GS-RF模型。 決策樹的數量的范圍:1 表2 參數優化前后實驗結果對比(訓練階段) 由表2可以得出,參數優化后的隨機森林預測模型的精度為0.59,袋外估計準確率得分為0.57,ROC曲線下方的面積為0.59。GS-RF模型在三個指標上的表現全面優于使用默認參數的隨機森林預測模型。 進一步驗證GS-RF模型在股價走勢預測中的有效性,用模型預測結果生成信號指導股票交易,與純技術指標的交易策略比較股票收益率。為了驗證模型的預測性能與泛化能力,將模型應用于中國平安、科大訊飛、華潤雙鶴、保利地產的累計收益率預測中,股票的時間范圍和屬性與實驗1里中國平安的數據集一致。模型訓練和測試后,對比分析實驗結果。實驗對比結果如圖2、圖3和表3、表4所示。 圖2 GS-RF模型與技術指標累計收益率的對比(訓練階段) 圖3 GS-RF模型與技術指標累計收益率的對比(測試階段) 表3 GS-RF與其他策略的收益率對比(訓練階段) 表4 GS-RF與其他策略的收益率對比(測試階段) 由圖2和表3可知,在訓練階段,使用默認參數的隨機森林模型的股票收益率不能穩定的勝過全部技術指標交易策略,甚至存在收益不如任何技術指標交易策略的情況。而GS-RF模型則全面優于技術指標交易策略,說明參數優化對提升模型性能是有效的。圖3和表4顯示在測試階段,應用GS-RF模型的收益率最高,并且長期來看,收益率總體為正、風險最小,進一步證明了該模型在預測預測股價走勢中的可行性和出色表現。投資者可以通過在股票持續上漲期間持倉,股價下跌期間平倉獲利。 本文提出了一種基于網格搜索算法改進的隨機森林股價走勢預測模型,即GS-RF模型。利用網格搜索算法對隨機森林模型進行參數優化,提高模型的預測精度和泛化能力。實驗發現本該模型在預測股價走勢上具有可靠性,能為投資者提供參考。未來會在指標選取、特征構造及算法優化上進一步完善,還將考慮公司經營狀況、市場指數、網絡輿情和國家政策等因素對股價走勢的影響。2 特征選擇
2.1 MACD(Moving Average Convergence Divergence,異同移動平均線)
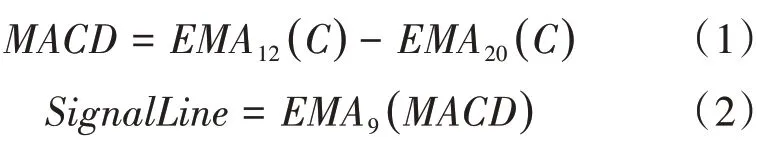
2.2 ADX(Average Directional Index,平均趨向指標)
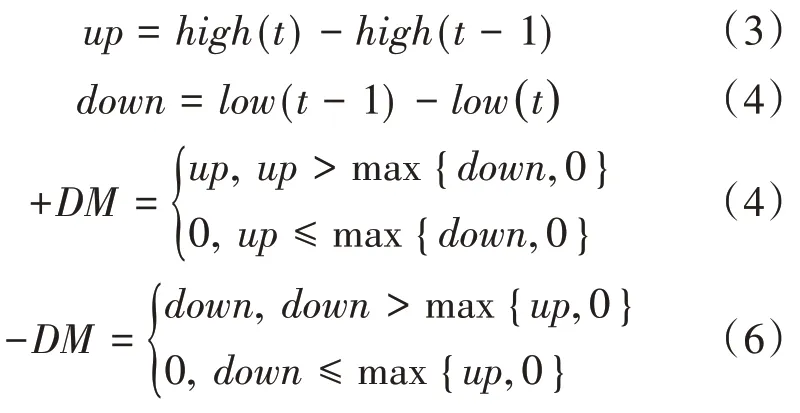
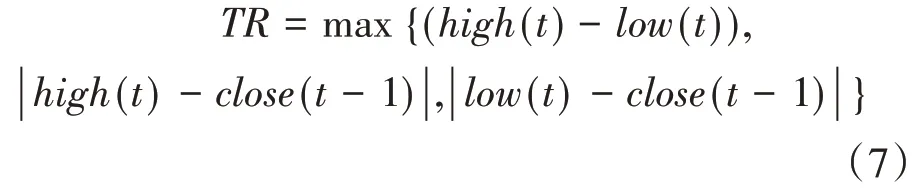

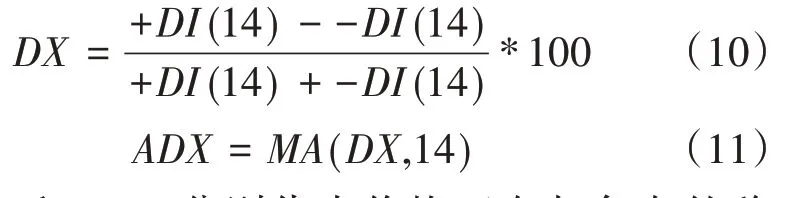
2.3 RSI(Relative Strength Index,相對強弱指標)

2.4 BB(Bolliger Bands,布林線指標)

2.5 FI(Force Index,強力指數指標)
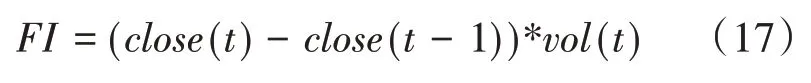
2.6 NWM(Next Week Move,下周股價走勢)
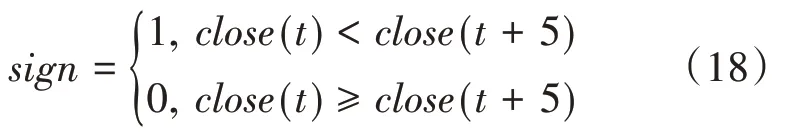
3 搭建GS-RF模型
4 實驗結果及分析
4.1 參數優化
4.2 收益率對比
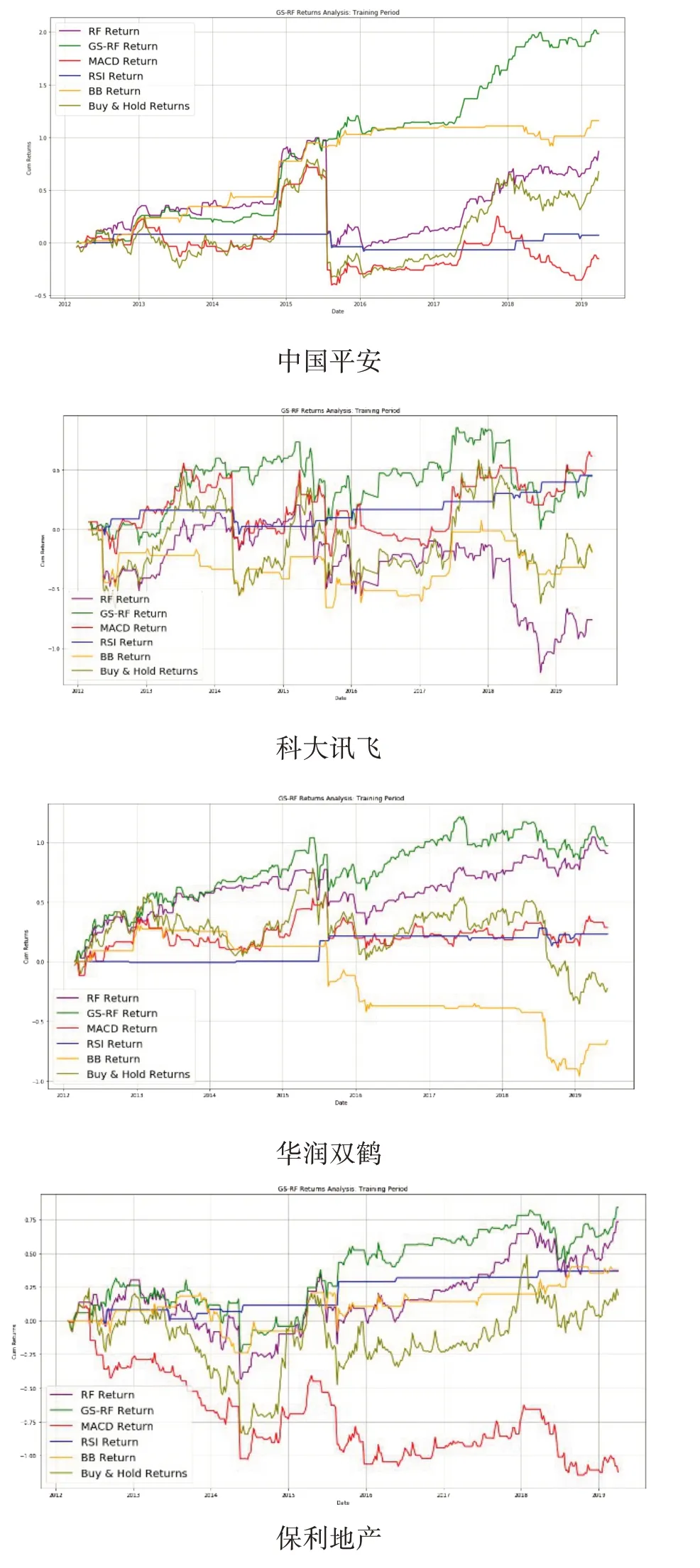
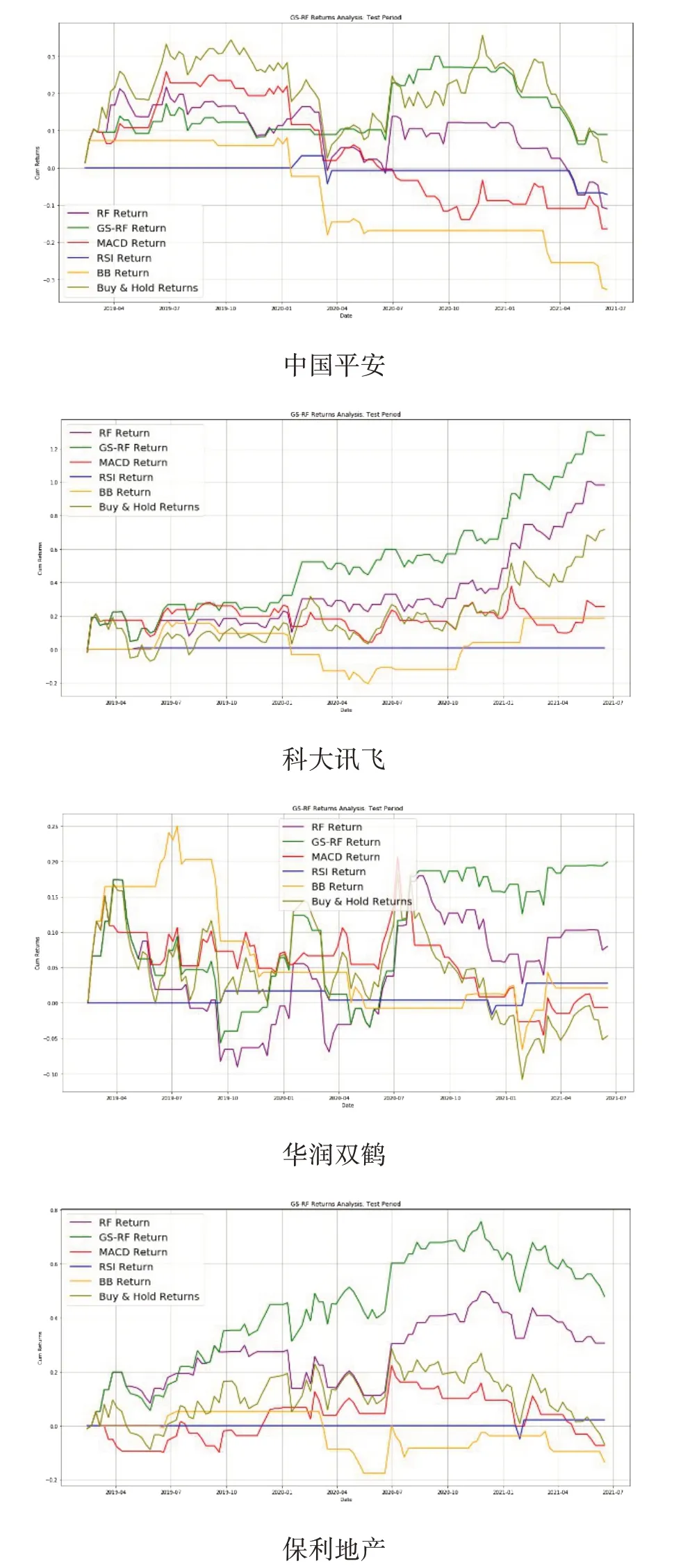
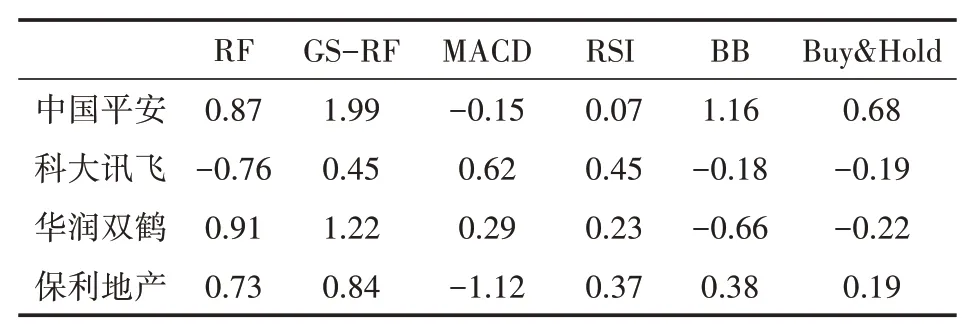

5 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42中學生數理化·中考版(2022年11期)2022-02-16 07:01:20中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50光學精密工程(2016年6期)2016-11-07 09:07:19發明與創新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55核科學與工程(2015年4期)2015-09-26 11:59:03
