基于LLVM的編譯鎖機制技術研究與實現
2021-11-15 11:48:10鞏令欽周清雷
計算機應用與軟件 2021年11期
鞏令欽 沈 莉 周清雷 胡 浩
1(鄭州大學信息工程學院 河南 鄭州 450000) 2(中國科學技術大學計算機科學與技術學院 安徽 合肥 230000) 3(無錫江南計算技術研究所 江蘇 無錫 214083)
0 引 言
底層虛擬機(LLVM)是一款開源的編譯器架構,目前已被蘋果、Google、Facebook等各大公司采用[1]。LLVM在重用GCC前端高級語言處理的同時,提供了獨特的編譯器后端移植架構[2]。為了充分挖掘處理器的計算潛力,并行處理技術的實現顯得尤為重要。軟件層面中,并行處理技術通過多線程技術和向量化進行實現,其中基于多線程的并行處理技術對處理器的操作系統環境改動最小[3]。
在多線程環境下,程序的執行由傳統的線性執行變為非線性執行。兩個或多個線程訪問相同的內存單元時,會造成系統內存的不一致性。由于多個線程共享同一塊內存,當內存訪問沖突時,將產生錯誤的執行結果,同一個進程內的其他線程也將受到影響[4]。嚴重的情況下將導致程序出現死鎖,造成系統資源浪費。并行計算的同步原語和多線程的調度的正確性都是基于原子指令實現的,原子指令的實現方式決定程序的正確性以及運行性能的好壞[5]。所以,如何保證多線程環境下對內存操作的原子性,保證訪問內存的正確性,是LLVM多線程編譯支持中的重要課題。
原子指令實現的關鍵是保證對內存操作的原子性。原子性規定了指令對內存單元修改的順序性。在對內存操作進行處理時,原子指令的讀操作和寫操作之間不能有其他指令對該內存單元進行修改[6]。除此之外,需要確保LLVM編譯器的指令調度不會破壞原子指令的順序性和完整性。
根據申威處理器的硬件特性,選擇使用鎖機制實現LLVM編譯器原子指令的編譯支持,對需要原子性訪問的地址空間加鎖。當編譯器進行原子指令的翻譯時,使用鎖指令實現原子指令的原子性。本文在申威處理器下基于LLVM編譯器對鎖機制進行研究與實現。在多線程環境下使用并行計算機基準測試集NPB進行測試,所有程序均通過自校驗。在16個線程下,Fortran語言程序平均加速比為11.91,最大加速比為15.73,C語言程序平均加速比為8.08,最大加速比為13.32。
1 相關工作
鎖機制是一種可以使所有共享訪問互斥進行的同步控制機制[7]。 鎖機制在X86和MIPS等架構中均有不同的實現方式。LLVM編譯器后端中,尚未有針對申威處理器架構的鎖機制的編譯支持。
在X86架構的Linux內核中,提供了3種機制保證原子性,包括基本操作的原子性、總線鎖機制(Bus Locking)和Cache內部鎖機制。在基本操作的原子性中,X86處理器保證了對8位、16位、32位、64位共享內存讀寫的原子性。在總線鎖機制中使用LOCK#信號阻塞其他處理器的總線訪問請求。在Cache內部鎖機制中通過CPU直接使用Cache內部的鎖進行實現,Cache內部鎖可以保證整條cache line不會同時被多個原子指令修改[8]。X86架構提供原子操作的指令包括inc、xchg、xand等,通過對原子指令加入LOCK宏可以實現指令執行的原子性。
MIPS架構使用精簡指令集計算機(Reduced Instruction Set Computer,RISC)架構的指令集,未提供諸如X86架構支持的inc、xchg、xand等復雜原子指令。在MIPS架構中提供支持實現鎖機制的匯編指令鏈接加載(Load Linked,ll)以及條件存儲(Store Conditional,sc)[9]。ll指令的功能是原子性地讀取指定內存單元中的值,sc指令的功能是原子性地對內存單元進行修改。在ll指令和sc指令之間的匯編指令會被原子性執行[10]。MIPS架構通過ll指令和sc指令進行鎖機制的實現。 同時,Alpha、PowerPC和ARM等RSIC指令集架構均支持鏈接加載和條件存儲指令[11]。
LLVM編譯器中對X86和MIPS指令集均有相應的X86后端和MIPS后端進行編譯支持。申威處理器采用自主指令集,LLVM編譯器需要增加后端對申威架構的支持。相比于X86架構,申威處理器不提供LOCK宏及inc、xchg、xadd等復雜原子指令。相比于MIPS等RSIC指令集架構,申威處理器不提供鏈接加載和條件存儲作為基本的原子指令。由于申威處理器的硬件特性和指令集與MIPS架構和X86架構均有較大區別,所以無法使用X86架構或MIPS架構下鎖機制的實現方式作為LLVM編譯器申威架構后端鎖機制的實現方式。本文基于LLVM編譯器并結合申威處理器指令集特性提出了一種鎖機制的實現方式,保證了多線程環境下原子操作的原子性。
2 鎖機制的編譯支持策略
2.1 原子指令語義映射
LLVM編譯器架構分為高級語言前端、中間代碼優化器和后端代碼生成器三個部分。高級語言前端主要負責將高級語言轉化為LLVM IR,中間代碼優化器對LLVM IR進行優化,后端代碼生成器對IR進行降級和代碼生成操作。在鎖機制的實現過程中,前端對高級語言解析后將原子操作轉化為IR中的atomic關鍵字并傳遞給后端。IR降級的過程中,后端根據指令模板對偽指令的定義、原子操作類型和數據類型的區別,將atomic關鍵字降級為對應的偽指令并繼續進行后續編譯流程。在偽指令擴展Pass中對偽指令進行語義映射,最終生成匯編代碼。其過程如圖1所示。
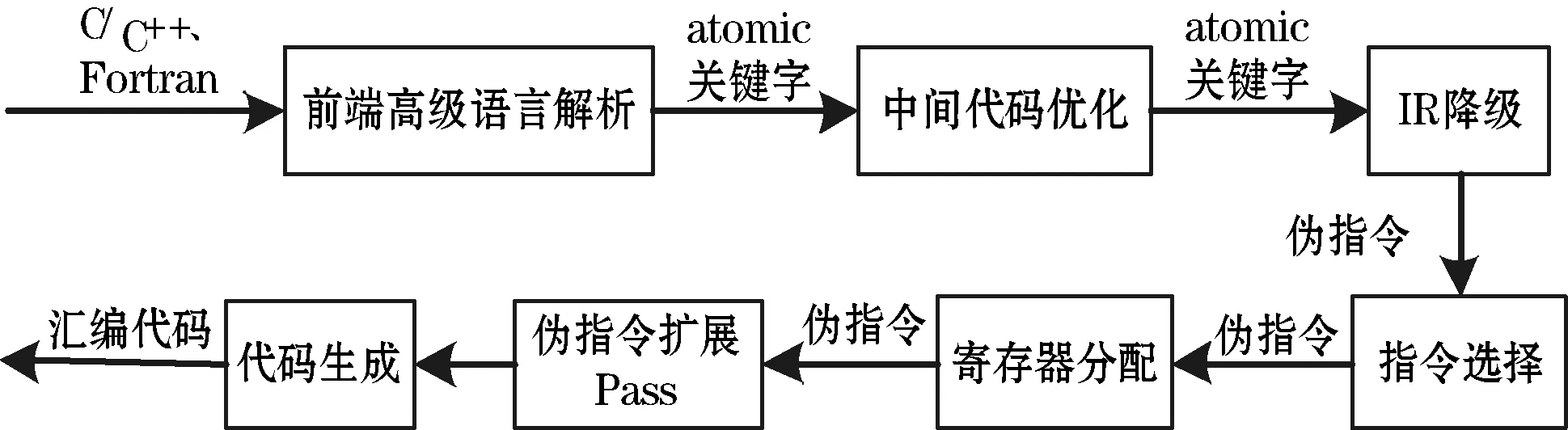
圖1 原子操作指令生成過程
編譯器對偽指令進行語義映射處理時,對每條偽指令映射的匯編代碼通過鎖指令進行加鎖。多線程環境下,并行的指令流水在遇到加鎖的匯編代碼時轉為串行執行。根據申威處理器的硬件特性,為8位、16位、32位和64位數據類型的數據設計不同的偽指令。每種數據類型的偽指令根據功能的不同可劃分為2種,分別為原子二元運算操作和原子比較并交換操作。原子二元操作包括原子加、原子減、原子與、原子交換、原子或、原子異或。對每條偽指令,在后端實現偽指令語義映射及鎖機制降級處理流程。其中,偽指令含義參考Linux內核中內建函數接口設計,不同數據類型的內建函數對應不同的偽指令。面向申威處理器的LLVM的偽指令的含義如表1所示。其中,n=8,16,32,64,分別表示8位、16位、32位、64位數據類型。
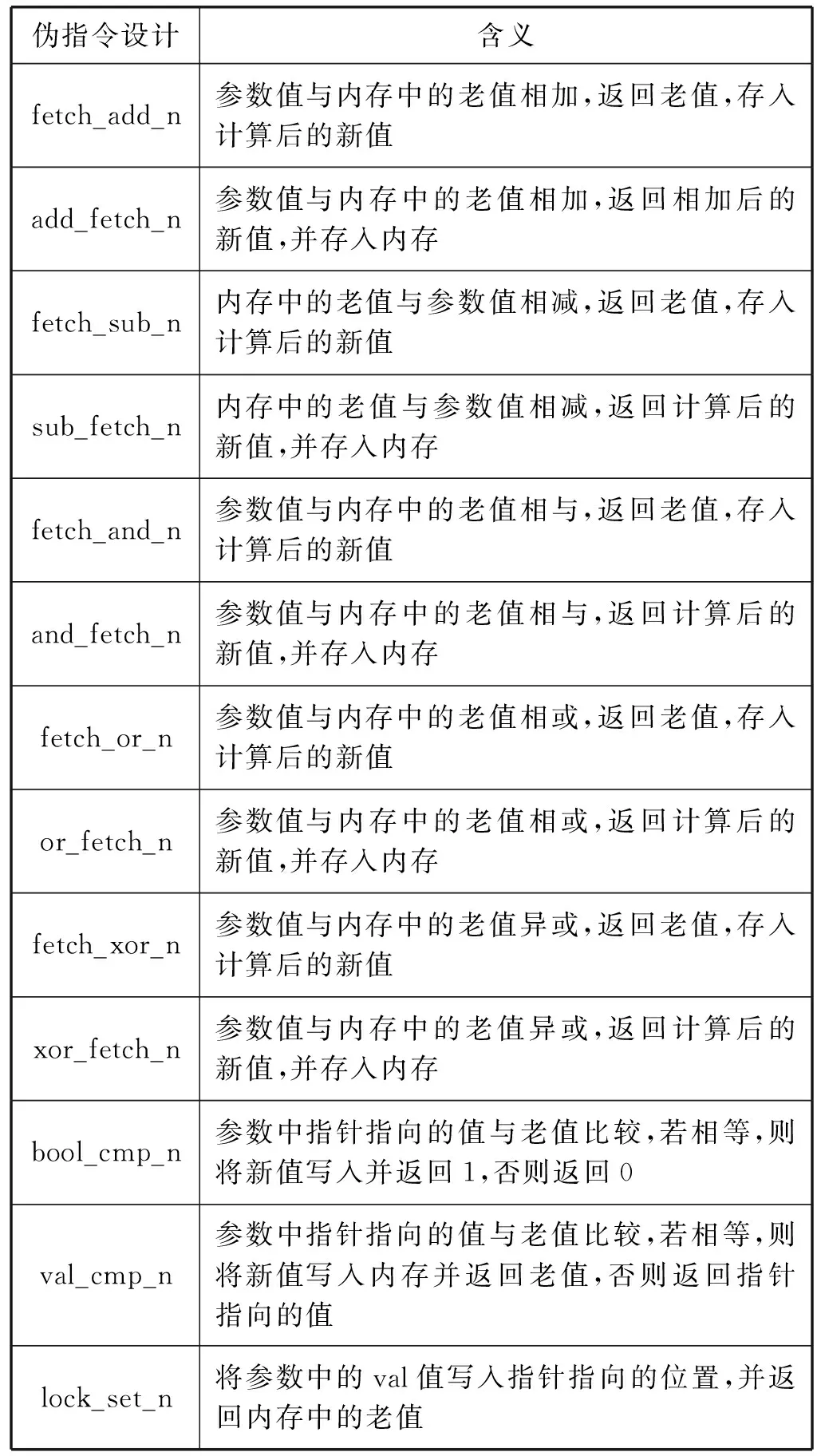
表1 偽指令設計及含義
在實現對每條偽指令的語義映射過程中,將加鎖的匯編代碼作為一個獨立的基本塊。該基本塊內的指令不參與指令調度。在設計鎖機制匯編基本塊時,需要考慮指令排布和寄存器的使用,以盡可能少地匯編指令實現鎖機制。基本塊的實現過程如圖2所示。

圖2 鎖機制基本塊的實現
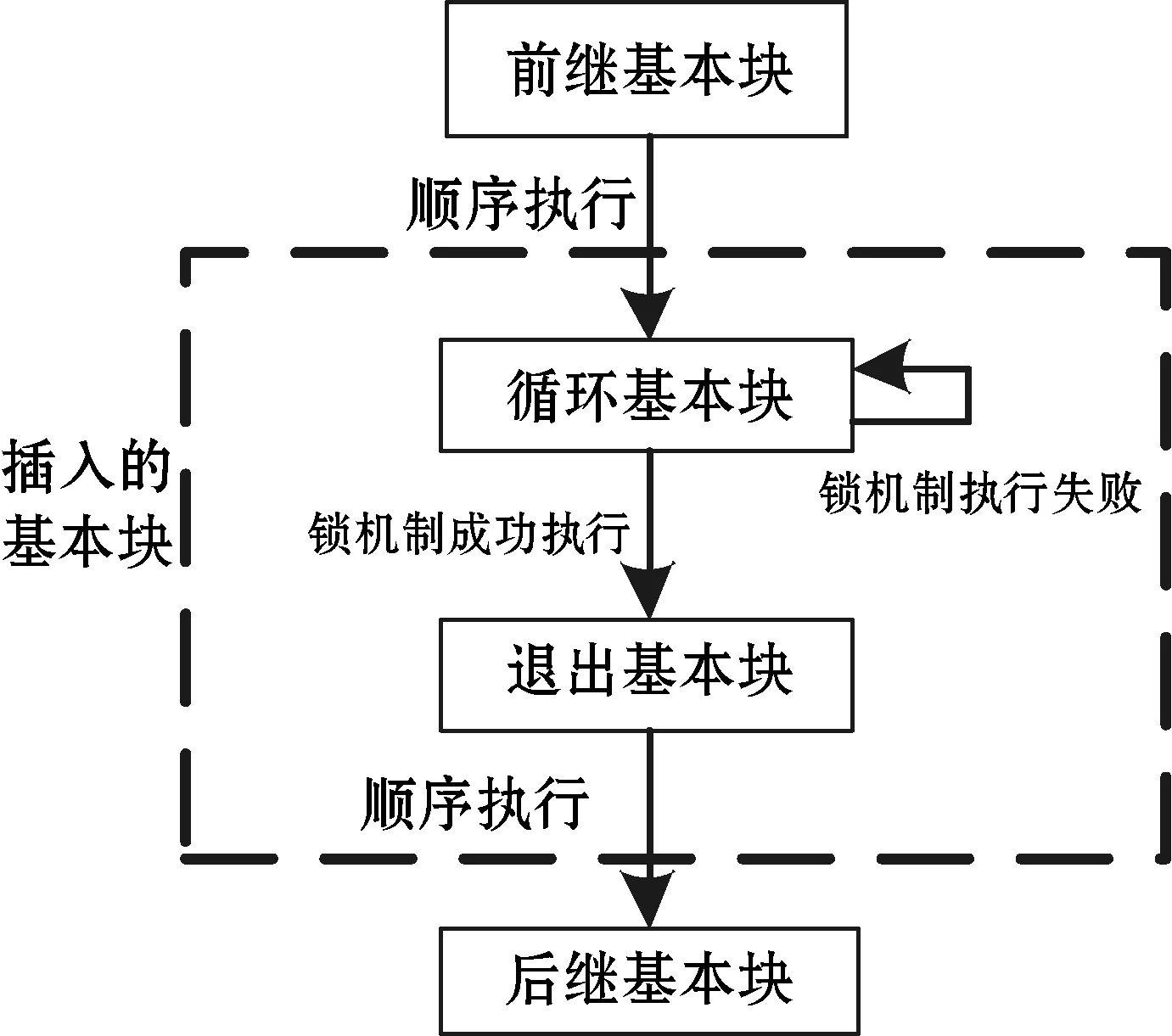
圖3 基本塊的插入
LLVM編譯器前端對高級語言解析后將原子操作轉化為IR中的atomic關鍵字并傳遞給后端。后端將atomic關鍵字轉換為偽指令后,對偽指令進行降級處理,實現原子指令的語義映射。
2.2 鎖機制數據處理
申威處理器中鎖機制需要支持8位、16位、32位和64位數據讀寫的原子操作。申威處理器對齊訪存最小粒度為4字節,32位數據和64位數據類型的地址不需要進行對齊處理。8位和16位的數據需要鎖機制對內存地址進行對齊處理后執行存取操作。鎖機制中對8位和16位數據類型處理包括對非對齊內存地址的對齊處理和保證非對齊地址中有效數據提取和寫回的正確性。
在鎖機制中,傳入的非對齊內存地址的對齊處理可以通過與立即數的與非操作實現。如需確保地址N字節對齊,則傳入的地址與立即數N-1進行與非操作。
非對齊地址中的有效數據的正確提取和寫回需要使用有效數據位拼接的方式實現。鎖機制中使用數據抽取操作,數據插入操作,數據屏蔽操作和數據按位或操作對數據進行處理。數據插入處理指將有效數據插入全零內存區域,確保存儲有效數據的內存單元中沒有臟數據位。數據插入處理如圖4所示。
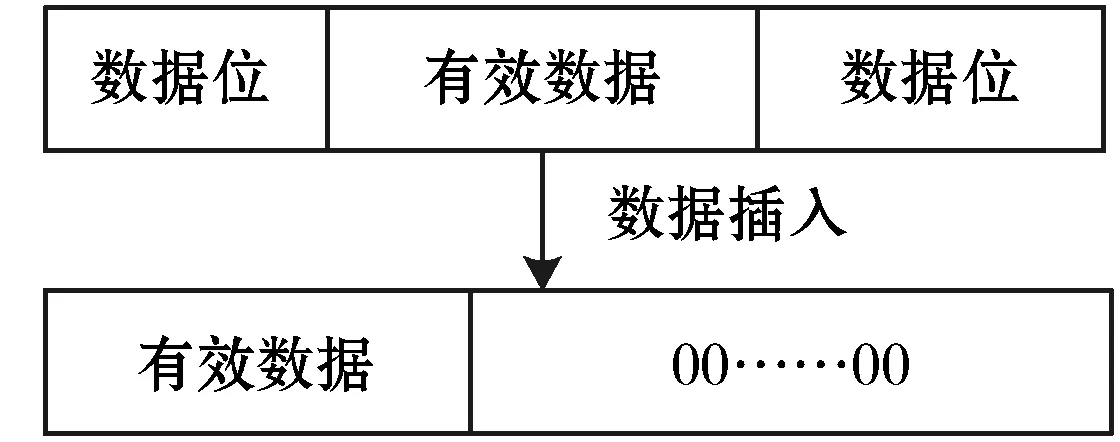
圖4 數據插入處理
數據插入操作處理在內存單元中,有效數據前后均有數據位的情況。數據插入處理在鎖機制算法中使用insert函數表示。
數據抽取處理指將有效數據抽取至全零內存區域,確保存儲有效數據的內存單元中沒有臟數據位。數據抽取處理在鎖機制算法中使用extract函數表示。數據抽取處理如圖5所示。
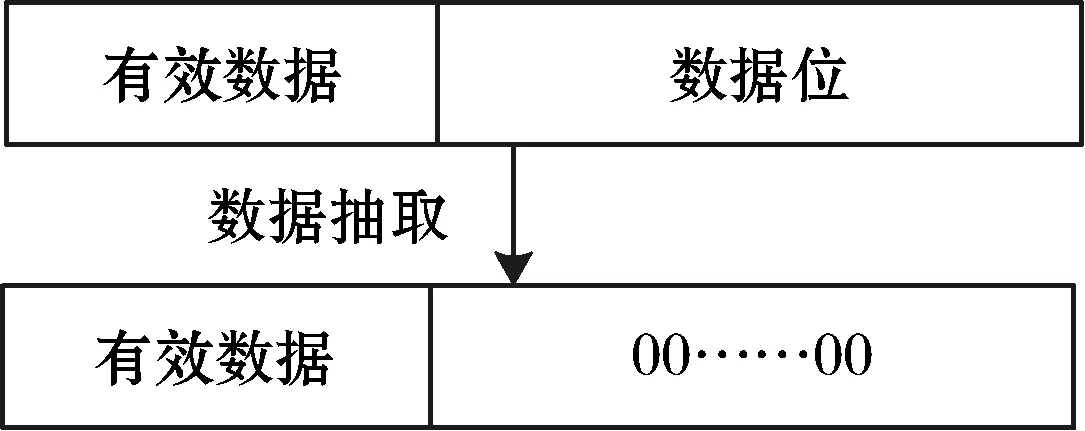
圖5 數據抽取處理
數據屏蔽處理指屏蔽內存單元中的有效數據,將內存單元中除有效數據外的數據位抽取至全零內存區域。確保有效數據寫回時內存單元的無關數據位的一致性。數據屏蔽處理在鎖機制算法中使用mask函數表示。數據屏蔽處理如圖6所示。
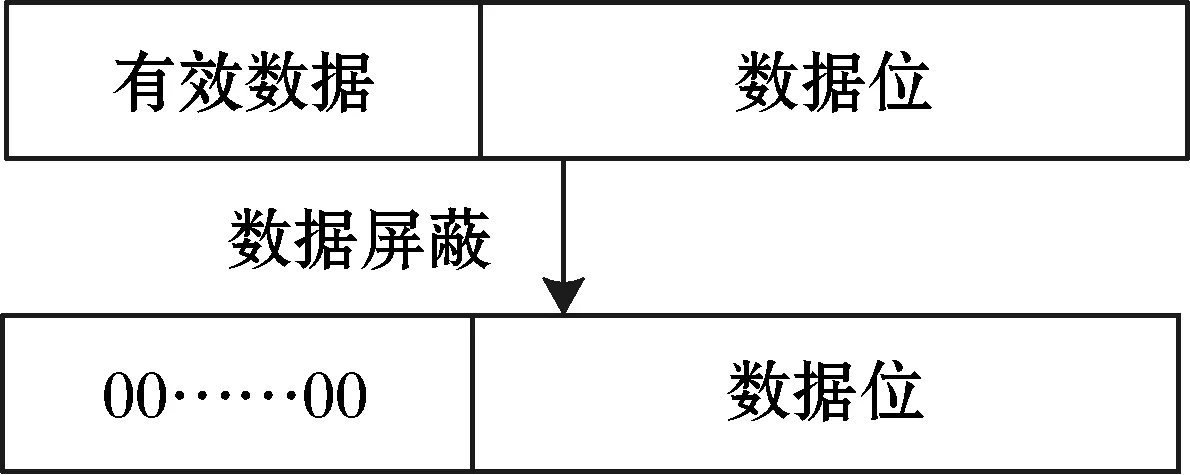
圖6 數據屏蔽處理
通過數據插入操作,數據抽取操作,數據屏蔽操作和數據按位或操作進行數據拼接操作,可保證非對齊內存地址中有效數據提取和寫入的正確性。數據拼接操作過程如圖7所示。
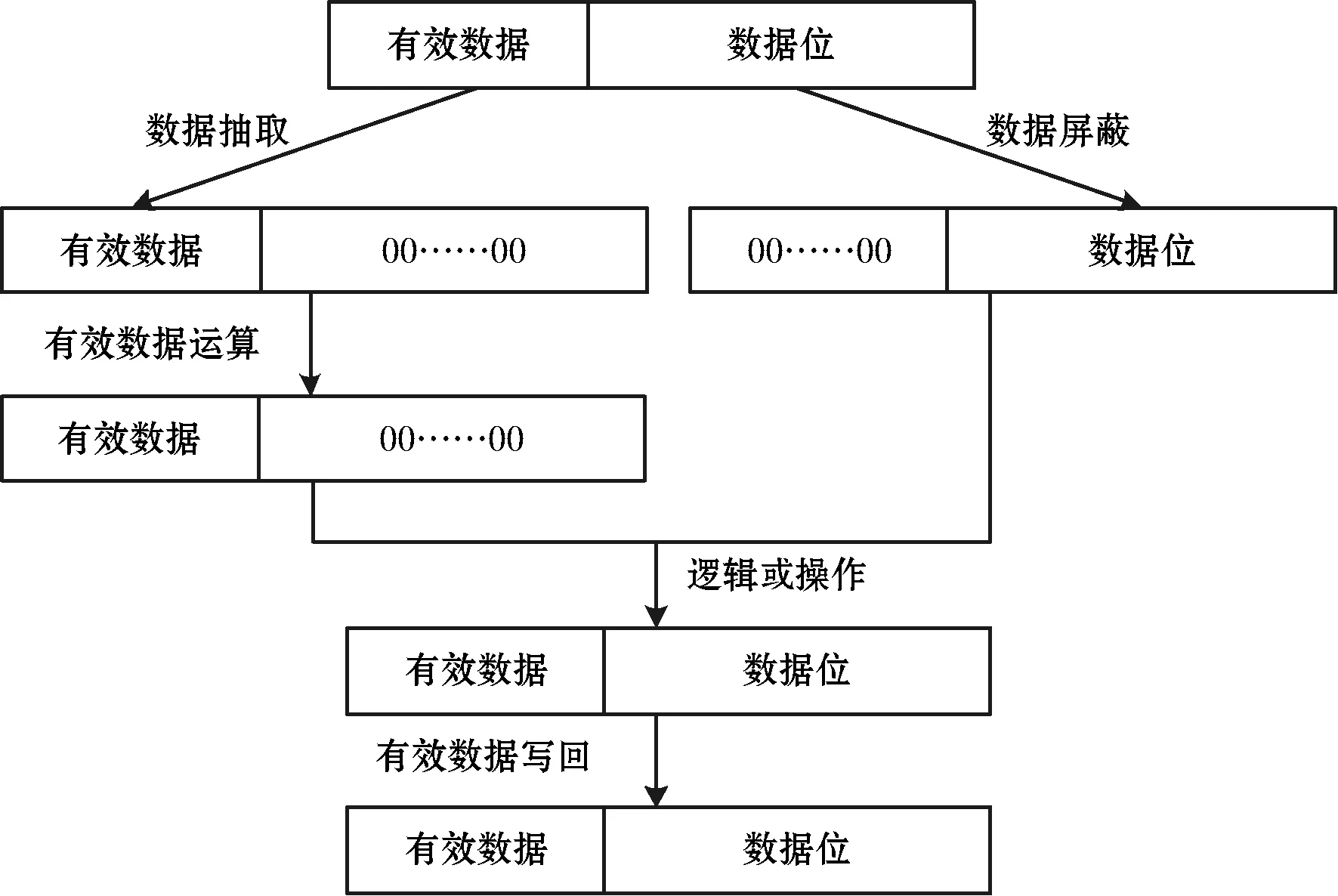
圖7 數據拼接操作
從對齊內存地址中取出數據后,使用數據抽取操作和數據屏蔽操作將有效數據和其余數據位抽取到全零區域中。然后使用抽取后的有效數據進行運算,將運算后的有效數據與抽取后的其余數據位進行按位或操作,得到完整的有效數據并寫回內存。
3 鎖機制編譯支持技術實現
3.1 32位和64位數據的鎖機制實現
在實現鎖機制的過程中,關鍵操作包括lock_load32、lock_load64、lock_store32、lock_store64、lock_read、lock_write和barrier。lock_load32操作表示在對齊鎖地址指向的內存單元中讀取4字節數據,lock_load64操作表示在對齊鎖地址指向的內存單元中讀取8字節數據。lock_store32操作對內存單元進行修改,執行4字節數據的原子寫操作,lock_store64操作執行8字節數據的原子寫操作。lock_write操作判斷是否獲取鎖。lock_read操作判斷鎖機制是否成功執行。barrier表示存儲器欄柵,編譯器在存儲器欄柵指令之前所有讀寫操作都執行后才可以執行存儲器欄柵指令之后的操作。
val_cmp_32表示32位數類型的原子比較并交換操作。以val_cmp_32偽指令為例,不需要鎖機制進行數據處理的32位數據類型的原子性比較并交換操作在鎖機制中的偽指令語義映射算法如算法1所示。
算法1val_cmp_32語義映射
輸入: new_val, old_val, lock_ptr。
輸出: res_val。
do{
insert(barrier)
lock_val ← lock_load32(lock_ptr)
res_val ← lock_val
cmp ← old_val == lock_val
flag ← lock_write(cmp)
if cmp is 0 then
break
else if flag is 1 then
lock_store32(new_val, lock_ptr)
end if
flag ← lock_read()
}while flag is 0
算法1是val_cmp_32偽指令語義映射后的邏輯的偽代碼。該算法將參數中指針指向的值與老值比較,若相等,則將新值寫入內存,并返回老值。若比較失敗,則不更改原內存地址中的值并返回參數指針指向的值。當lock_write(cmp)為1時,表示獲取寫鎖成功,否則跳出鎖機制處理。當lock_read()為1時表示鎖機制成功執行,否則重新執行該原子操作直至鎖機制成功執行。64位數據類型的比較并交換與此類似。
原子加、原子減、原子與、原子交換、原子或、原子異或操作均為二元操作,可以使用相同的處理流程。以原子加的add_fetch_32偽指令為例,鎖機制的實現如算法2所示。
算法2add_fetch_32語義映射
輸入: val, lock_ptr。
輸出: res_val。
do{
教育是未來的事業,兒童是民族的未來。教師要把一個不懂事的孩子培養成國家的棟梁,民族的脊梁,要付出畢生的精力。教師工作是平凡的,每天上課下課、備課、批改作業,為學生解惑排難;但教師的職業又是偉大的,教師要把兒童這個幼苗培育成參天大樹。古人說:“十年樹木,百年樹人。”說明創造物質是比較容易的,塑造人、鑄造人的精神是要經過幾代人的努力。因此,教師要滿懷對學生的真心關愛,以學生的發展為本,甘為人梯,樂于奉獻,用心靈和汗水一點一滴地滋潤學生的心田,把全部精力和滿腔熱情獻給教育事業。
insert(barrier)
lock_val ← lock_load32(lock_ptr)
lock_write(1)
res_val ← val + lock_val
lock_store32(res_val, lock_ptr)
}while lock_read() is 0
算法2是add_fetch_32偽指令語義映射后的邏輯的偽代碼。該算法將參數值與內存中的老值相加,返回相加后的新值,并存入內存。res_val是執行二元運算操作后的結果值。即將指針指向內存地址中的值與參數值執行二元運算操作,如原子加、原子減等6種二元運算操作。64位數據類型的二元運算操作與此類似。
3.2 8位和16位數據的鎖機制實現
val_cmp_8表示8位數據類型的原子比較并交換操作。以偽指令val_cmp_8為例,鎖機制中需要對數據進行處理的8位數據原子比較并交換操作的偽指令語義映射算法如算法3所示。
算法3val_cmp_8語義映射
輸入: new_val, old_val, lock_ptr。
輸出: res_val。
do{
insert(barrier)
lock_align_ptr ← nand(lock_ptr,7)
eff_new_val ← insert(new_val, lock_ptr)
ori_lock_val ← lock_load64(lock_align_ptr)
eff_lock_val ← extract(ori_lock_val, lock_ptr)
res_val ← eff_lock_val
cmp ← old_val == eff_lock_val
flag ← lock_write(cmp)
if cmp is 0 then
break
if flag is 1 then
other_lock_val ← mask(ori_lock_val,lock_ptr)
ret_val ← or(other_lock_val, new_val)
lock_store64(ret_val, lock_align_ptr)
end if
}while lock_read() is 0
算法3中,主體算法框架與4.1節類似,算法中主要新增對8位數據類型的有效數據和非對齊內存地址的處理。nand(lock_ptr,7)表示通過與立即數7進行與非操作,實現對地址進行8字節對齊處理。or表示數據按位邏輯或。該算法將參數中指針指向的值與老值比較,若相等,則將新值寫入內存,并返回老值,若不相等,則返回指針指向的值。16位數據類型的比較并交換與此類似。
原子加、原子減、原子與、原子交換、原子或、原子異或均為二元操作,可以使用相同的鎖機制處理流程。以偽指令add_fetch_8為例,鎖機制中需要對數據進行處理的8位數據原子加操作的偽指令語義映射算法如算法4所示。
算法4add_fetch_8語義映射
輸入: val, lock_ptr。
輸出: res_val。
do{
insert(barrier)
lock_align_ptr ← nand(lock_ptr, 7)
ori_lock_val ← lock_load64(lock_align_ptr)
lock_write(1)
eff_lock_val ←extract(ori_lock_val, lock_ptr)
ori_res_val ← val + eff_lock_val
eff_res_val ←insert(ori_res_val, lock_ptr)
other_lock_val ← mask(ori_lock_val,lock_ptr)
res_val ← or(other_lock_val, eff_res_val)
lock_store64(res_val, lock_align_ptr);
}while lock_read() is 0
算法4是add_fetch_8偽指令語義映射后的邏輯偽代碼。該算法將參數值與內存中的老值執行二元運算操作,如原子加,返回二元運算操作后的新值,并存入內存。使用nand(lock_ptr,7)處理非對齊內存地址,使用insert操作、extract操作和mask操作實現有效數據位的提取和寫回。16位數據類型的二元運算操作與此類似。
4 實 驗
在申威1621處理器的LLVM編譯器上對鎖機制分別進行正確性測試和性能測試。LLVM編譯器版本為7.0,并行測試環境為16個CPU的并行環境。正確性測試使用Linux內核源碼中的內建函數進行測試。性能測試采用NPB(NAS Parallel Benchmark)測試集[12]。 NPB測試集為3.0版本的C語言NPB測試集和3.0版本的Fortran語言NPB測試集。
4.1 正確性測試
Liunx內核源碼中,通過一系列內建函數實現原子操作[13]。內建函數以及其完成的功能如表2所示。
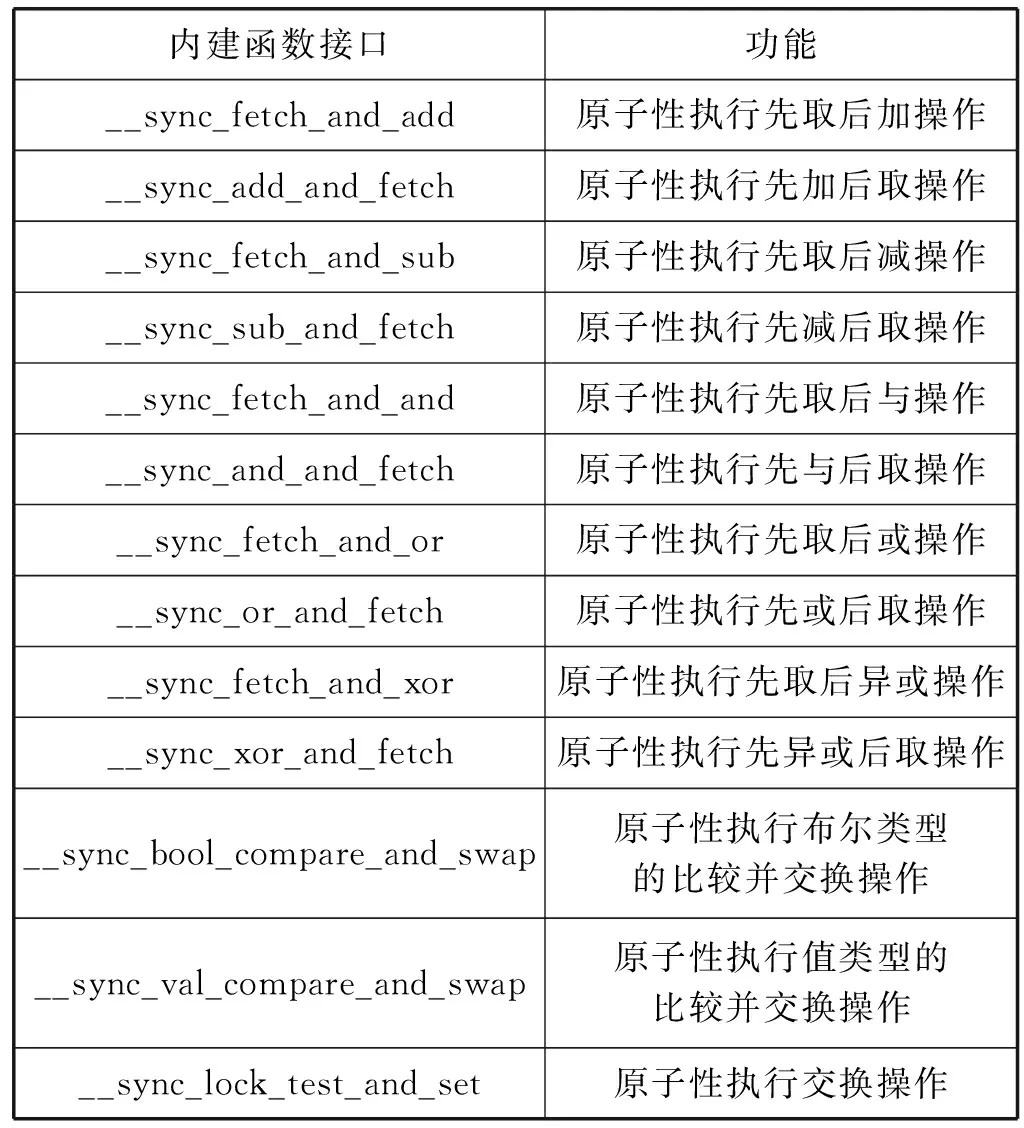
表2 Liunx內建函數功能
通過調用Linux內核中的13個內建函數并分別傳入8位、16位、32位、64位數據對LLVM中的鎖機制進行驗證。實驗結果如表3所示。
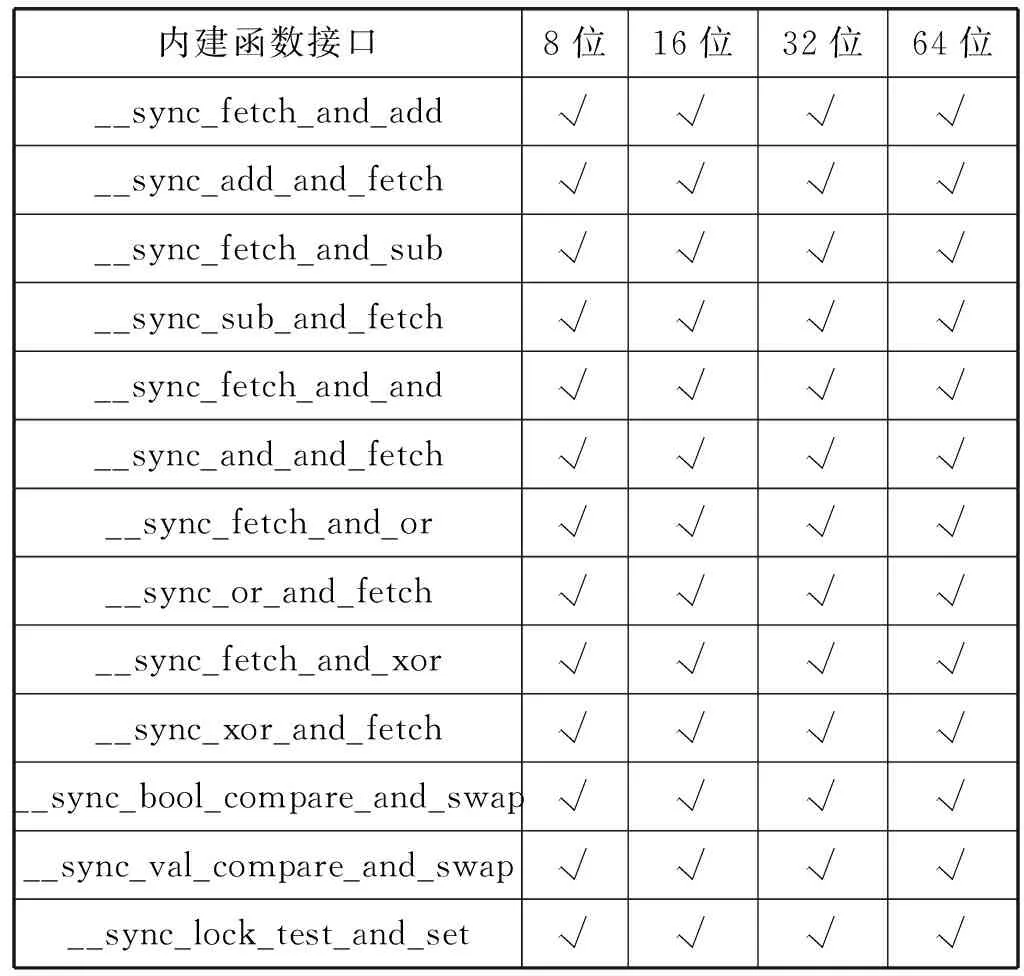
表3 功能測試結果
實驗結果表明LLVM編譯器鎖機制中新增52條偽指令均正確運行,執行結果與標準結果一致。在申威1621處理器的多線程環境下,LLVM編譯器可以正確通過鎖機制實現原子操作。
4.2 性能測試
NPB是NASA提供的,用于評估并行超級計算機性能的測試程序集,是并行計算機基準測試程序。其中共包含8道測試題目,分別為EP(Embarrassingly parallel)、MG(3D MultiGrid)、FT(Fast Fourier transform)、IS(Integer sort)、CG(Conjugate Gradient)、LU(Lower upper triangular)、SP(Scalar penta-diagonal)、BT(Block Tri-Diagonal)[14]。每題包含5種測試規模,分別為S、W、A、B、C。其中S類為樣例程序,W類通常用于工作站,A類通常是運行中等性能的工作站系統,B類運行于高端的工作站系統或者小型的并行系統,C類則用于超級計算系統[15]。選用B類規模進行測試,B類規模大小如表4所示。
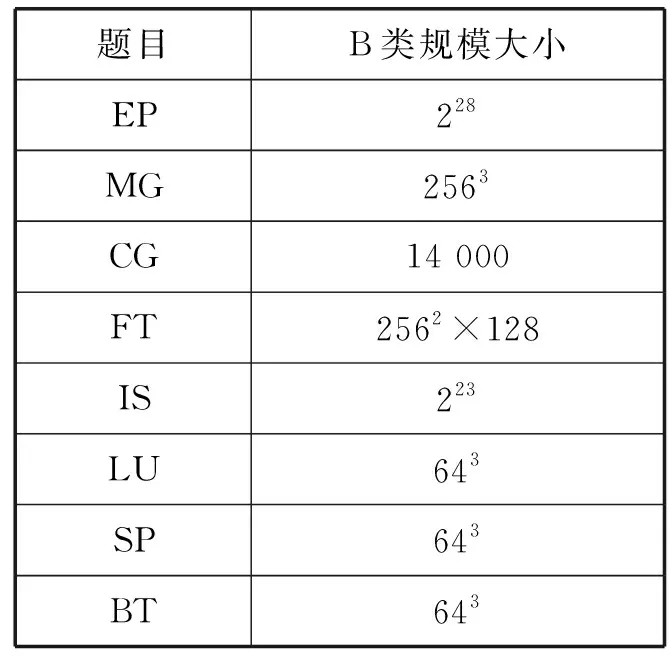
表4 B類規模大小
在LLVM編譯器中,C/C++語言采用clang作為前端對進行編譯處理,Fortran語言采用flang作為前端進行編譯處理。本文測試了C語言的NPB測試集和Fortran語言的NPB測試集,對16個線程下OpenMP庫的加速情況進行了對比。
面向申威1621處理器的LLVM編譯器對于C語言程序的并行加速比如表5所示,平均加速比為8.08,最大加速比為13.32。

表5 C語言程序NPB加速比
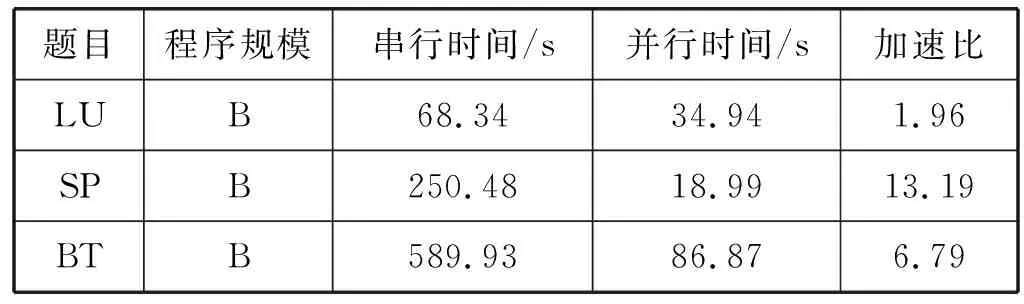
續表5
面向申威1621處理器的LLVM編譯器對于Fortran語言程序的并行加速比如表6所示,平均加速比為11.91,最大加速比為15.73。
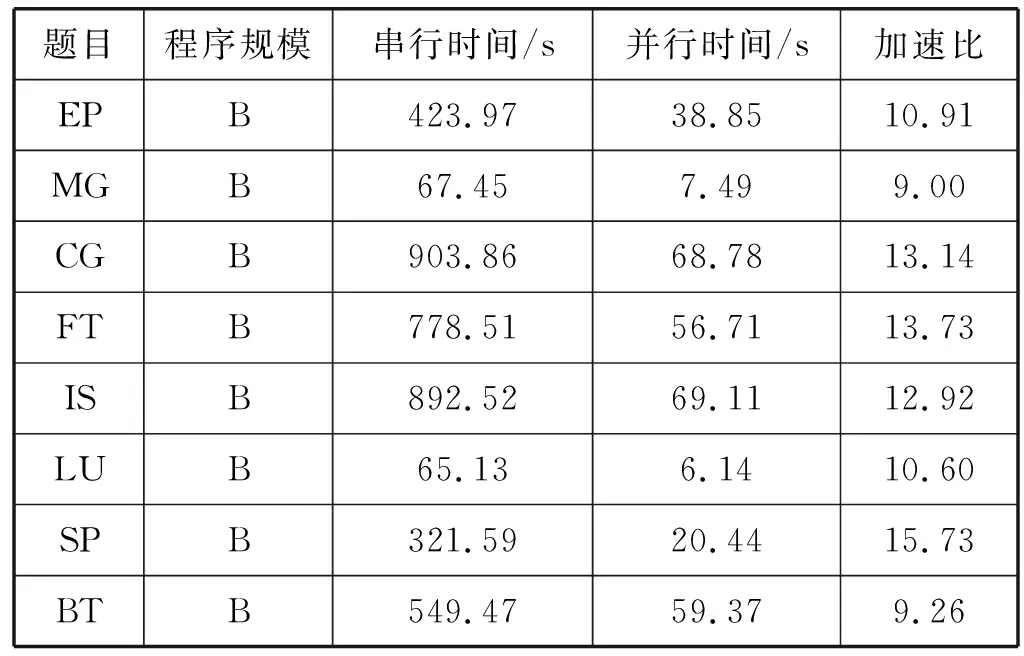
表6 Fortran語言程序NPB加速比
4.3 實驗結果分析
由功能性測試可知,鎖機制中52條偽指令均可完成對應的原子性操作。在基于申威1621處理器的LLVM編譯器上加入鎖機制后,可正確對內存進行原子性的讀寫操作,實現了8位、16位、32位、64位數據類型的原子加、原子減、原子與、原子交換、原子或、原子異或、原子比較并交換操作,保證了多線程環境下對內存訪問的一致性。
由性能測試可知,在加入鎖機制后,LLVM編譯器通過使用OpenMP庫,C語言版NPB測試集所有程序和Fortran語言版NPB測試集所有程序在16個線程的環境下均正確執行并自校驗通過。C語言版NPB測試集程序平均加速比為8.08,最大加速比為13.32。Fortran語言版NPB測試集程序平均加速比為11.91,最大加速比為15.73。
5 結 語
本文對鎖機制和原子指令進行了介紹,結合申威處理器的特性與LLVM編譯器的特點,針對鎖機制的具體實現進行了討論并介紹了52條偽指令及其算法實現。
通過本文對鎖機制的實現,LLVM編譯器可以正確穩定地在申威處理器下的多線程環境中運行,使得申威處理器的多核化優勢得到了利用和體現。下一步的工作將對鎖機制開銷進行進一步的分析并充分挖掘申威處理器并行計算的潛力。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
四川勞動保障(2021年9期)2022-01-18 05:11:08
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
文苑(2018年21期)2018-11-09 01:23:06
電信科學(2016年10期)2016-11-23 05:11:56
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
