面向隱私保護的關聯規則挖掘算法
2021-11-16 02:24:16范敏楊庚,2
信息安全研究 2021年11期
范 敏 楊 庚,2
1(南京郵電大學計算機學院 南京 210023)
2(江蘇省大數據安全與智能處理重點實驗室 南京 210023)(193474168@qq.com)
關聯規則挖掘(association rule mining, ARM)是一項基本的數據挖掘任務,它首先被應用于分析市場上的購物籃來發現購買習慣.其中最著名的例子就是“尿布和啤酒”的故事.也許很難想象這2個項目會有關聯,但是經過關聯分析,市場經理發現買尿布的人更有可能買啤酒.關聯規則被廣泛應用于各種領域,如電信網絡、市場購物籃分析的風險管理、衛生保健、Web使用挖掘等[1].最近的進展在科學和技術領域都產生了有爭議的影響.一方面,關聯規則挖掘能夠在海量數據中發現潛在的有用規則;另一方面,過度挖掘關聯規則會使敏感數據和用戶的機密信息面臨風險.因此,在保證數據安全和用戶隱私的前提下,開發保護隱私的關聯規則挖掘算法成為一個迫切需要解決的問題[2].
差分隱私[3]作為一種數據隱私保護技術,通過添加隨機噪聲來防止敏感信息的泄露.差分隱私模型是完全獨立于攻擊者的背景知識和計算能力的強隱私概念,已成為近年來的研究熱點.與傳統的隱私保護模式相比,差分隱私有其獨特的優勢.首先,模型假設攻擊者擁有最大的背景知識;其次,差分隱私具有完整的數學基礎,對隱私保護有嚴格的定義和可靠的定量評價方法.差分隱私是一種有效的隱私保護機制,它在保護用戶隱私的同時,保留了足夠的有用信息供數據分析使用.
差分隱私保護已在學術界和業界得到了廣泛注意和研究.滿足差分隱私的機制已經融合在數據分析的很多領域,如數據發布、數據挖掘、機器學習和深度學習[4-9].特別是Google和Apple在各自的產品(即Chrome和iOS)中設計和部署了差分隱私機制,以更好地保護用戶隱私[10].
目前已有多種滿足差分隱私的關聯規則挖掘算法被提出(如TF[11], PrivSuper[12]),但這些算法在如何平衡安全性和可用性方面仍顯不足,即在一定的隱私保護等級需求下,如何盡可能提高數據挖掘的可用性.從差分隱私保護的實現機制中我們發現,為了提高算法的可用性,對給定的隱私預算ε,降低全局敏感度是一種可行的方法.在關聯規則挖掘算法中,全局敏感度依賴于數據集中最長記錄的長度.因此,為了降低全局敏感度,多數算法使用截斷數據集中的長記錄來實現這一目標.但這樣做會影響截斷掉的集合及其子集的支持度,有可能會導致本來頻繁的項集變為不頻繁.針對這個問題,本文設計了一種事務分割的方法,并引入事務矩陣[13]減少數據庫的掃描次數,提出了一種滿足差分隱私的關聯規則挖掘算法.
1 相關工作
關聯規則挖掘問題最早由Agrawal等人[14]提出,并受到廣泛關注.有幾種著名的關聯規則挖掘算法,如Apriori算法[14]和FP-Growth算法[15].Apriori算法具有廣度優先搜索策略,結構直觀,且具有向下閉包性,算法效率高,本文也是基于Apriori算法進行差分隱私保護算法設計.
近年來,差分隱私模型在隱私保護中得到了廣泛的應用.Bhaskar等人[11]提出了一種基于截斷頻率的TF(truncated frequency)算法,該算法是一種發布top-k頻繁項集及其頻率的方法.TF算法由2個步驟組成:第1步,選擇要發布的k個項目集;第2步,在添加噪音后發布這些項目集的頻率.隱私預算ε在這2個步驟中平均分配.首先從不超過m個項集的所有項集中選擇k個項集,然后對這些選擇項集的頻率添加噪聲.對于較小的k值,這種算法效果比較好;但是對于較大的k值,準確性較差.主要原因是對于較大的k值,必須將大小限制m設置得更大.這將導致一個非常大的候選集,算法從中選擇top-k,這會導致選擇不準確.
受文獻[11]的啟發,Li等人[16]提出了PrivBasis算法,該算法避免從非常大的候選集中選擇top-k項集,并且引入了基集的概念.通過將輸入數據投影到人們所關心的少數選定維度上來應對高維性的挑戰.
給定事務數據集D,其中所有項的集合記為I,該算法主要步驟如下:1)計算λ,即k個最頻繁的項集所涉及的唯一項的數量;2)查找I中出現頻率最高的λ項構成F;3)查找F中出現頻率最高的項對的集合組成P,P中恰好包含出現在top-k項集中的項對;4)利用F和P構造B,B是一個具有較小寬度和長度的fk基集;5)得到候選項集C(B),并對其添加拉普拉斯噪聲,然后從C(B)中選擇噪聲支持度最高的k個項目集.該算法最關鍵的部分就在于基集的構造.
PrivBasis算法基于差分隱私生成頻繁項集,利用噪聲頻繁項集查找關聯規則,理論上可以確定高置信度規則,但實際上只有頻率很高的規則被保留,而大量頻率中等的規則被丟棄.Zhen等人[17]提出了能夠自適應設置支持度閾值,提取高置信度規則的算法,該算法設置多個支持度閾值,即針對每個項集中各個項的真實支持度來設置特定的最小支持度閾值,以此來減少候選項集的數量,提取能夠反映項目本身性質的規則,并利用隨機截斷和統一分區來降低數據集的維數.這2種方法都可以幫助降低查詢的敏感度,降低所需噪聲的規模,并提高挖掘結果的可用性.通過自適應地分配隱私預算來約束整體隱私損失,穩定了噪聲規模.其不足之處在于隨機截斷會引起部分信息丟失,從而導致挖掘結果不準確.
現有的差分隱私關聯規則挖掘算法大致可以分為2類:一類是需要挖掘頻繁項集,這是關聯規則挖掘的基本步驟.例如,TF算法[10]、PrivBasis算法[16].另一類是直接挖掘關聯規則,如HCRMine算法[18].我們的工作是基于第1類挖掘算法.
2 理論基礎
2.1 差分隱私
差分隱私允許對數據進行一般性的統計分析,同時以強有力的隱私保障保護個人數據.
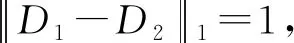
差分隱私提供了不可區分性的保證:差分隱私結果不會產生很多關于在計算結果時使用了2個鄰近數據集中的哪個數據庫的信息.
定義2.差分隱私.給定至多有1條記錄不同的任意2個鄰近數據集D1和D2,設有隨機算法M,PM為M所有可能的輸出構成的集合,及PM的任何子集SM,若算法M滿足式(1), 則稱算法M提供ε-差分隱私保護.
Pr[M(D1)∈SM]≤exp(ε)×
Pr[M(D2)∈SM],
(1)
其中參數ε稱為隱私保護預算,它定制了算法的隱私級別.ε越小,隱私保障越強,數據的可用性越差,同時也說明挖掘結果中注入了更多的噪聲;ε越大,隱私保護效果越差,數據的可用性更高,挖掘結果中注入噪聲更少.
拉普拉斯機制[19]和指數機制[20]是常見的噪聲疊加機制.拉普拉斯機制適用于在數值查詢結果中加入噪聲.它通過在精確結果中加入滿足拉普拉斯分布的隨機噪聲來實現差分隱私.在許多實際應用程序中,查詢結果是實體特性(例如一個方案或一個選擇).針對這種情況,McSherry等人[20]提出了指數機制,該機制適用于在非數值查詢結果中添加噪聲.這2種機制都是基于全局敏感度實現的.
定義3.全局敏感度.對于任意2個鄰近數據集D1和D2,定義任意函數F:D→n的全局靈敏度為
(2)
定義4.拉普拉斯機制.對任意函數F:D→n,算法M返回式(3),則算法M滿足ε-差分隱私.
(3)
其中,Δf為函數F的敏感度.
定義5.指數機制.給定數據集D,算法M滿足式(4), 則算法M滿足ε-差分隱私.
(4)
其中u為打分函數, Δu為打分函數的敏感度,r為輸出域O中的任一輸出項.指數機制的關鍵就在于打分函數的設置,分數越高,則輸出的概率越大.因此,對于同一數據集,不同的打分函數可能導致截然不同的挖掘結果.
2.2 關聯規則挖掘
關聯規則挖掘是一種常用的數據挖掘算法,旨在發現事務數據庫中項目集之間有趣的關系.關聯規則挖掘的概念具體描述如下:項集I={i1,i2,…,in}由n個不同的項組成,D={t1,t2,…,tm}稱為數據集,其中tk,k∈[1,m]稱為事務.1條規則是由2個不同的項集組成的,表示為X?Y,其中X,Y∈I,X稱為前提,Y稱為結論.例如超市中的1條規則{黃油,面包}?{牛奶},表示如果黃油和面包已經被同時購買,那么牛奶也會被購買.
從所有可能的規則中挑選出一些有用的規則,這些規則稱為關聯規則.為了能挑選出有用的規則,需要用到2個指標,分別是支持度和置信度,前者用于挖掘頻繁項集,后者用于從頻繁項集中發現關聯規則.
定義6.支持度.給定數據集D,項集X的支持度定義為:包含項集X的事務數與數據集D中的總事務數的比值.支持度用來表示項集在數據集中出現的頻率,可表示為式(5):
(5)
定義7.置信度.對于規則X?Y,其置信度為同時包含X和Y的事務數與包含X的事務數的比值.置信度用來表示規則的可信度,可表示為
(6)
3 基于雙重條件機制事務分割的關聯規則挖掘算法
一般算法通過截斷長事務以期降低全局敏感度,本文考慮到事務截斷會造成一定的信息損失,從而設計了一種基于雙重條件機制對長事務進行分割的關聯規則算法,即TS-ARM算法.TS-ARM算法由2大部分組成,分別是數據預處理和關聯規則挖掘.數據預處理也就是對長事務進行分割后生成新數據集的過程,3.1節將對預處理過程進行詳細的描述.3.2節則是利用3.1節的預處理結果挖掘關聯規則.
3.1 預處理
本文算法采用雙重條件對事務進行分割,首先確定一個事務長度閾值lmax,并按同樣的方法確定分割支持度閾值sup′,然后對超過這個閾值的事務進行分割處理.分割支持度閾值的設置保證了支持度較高的項都能被分到同一事務中,進而降低了預處理對挖掘結果產生的影響.關于這2個閾值的確定,具體操作過程詳見算法1:
算法1.確定最大事務長度閾值.
輸入:數據集D;
輸出:最大事務長度閾值lmax.
① FUNCTION(GetLenThreshold(D))
② [z1,z2,…,zn]←對D的事務長度按升序
排序;
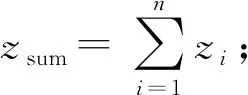
④z′=0,l=1;
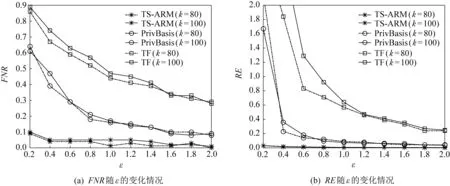
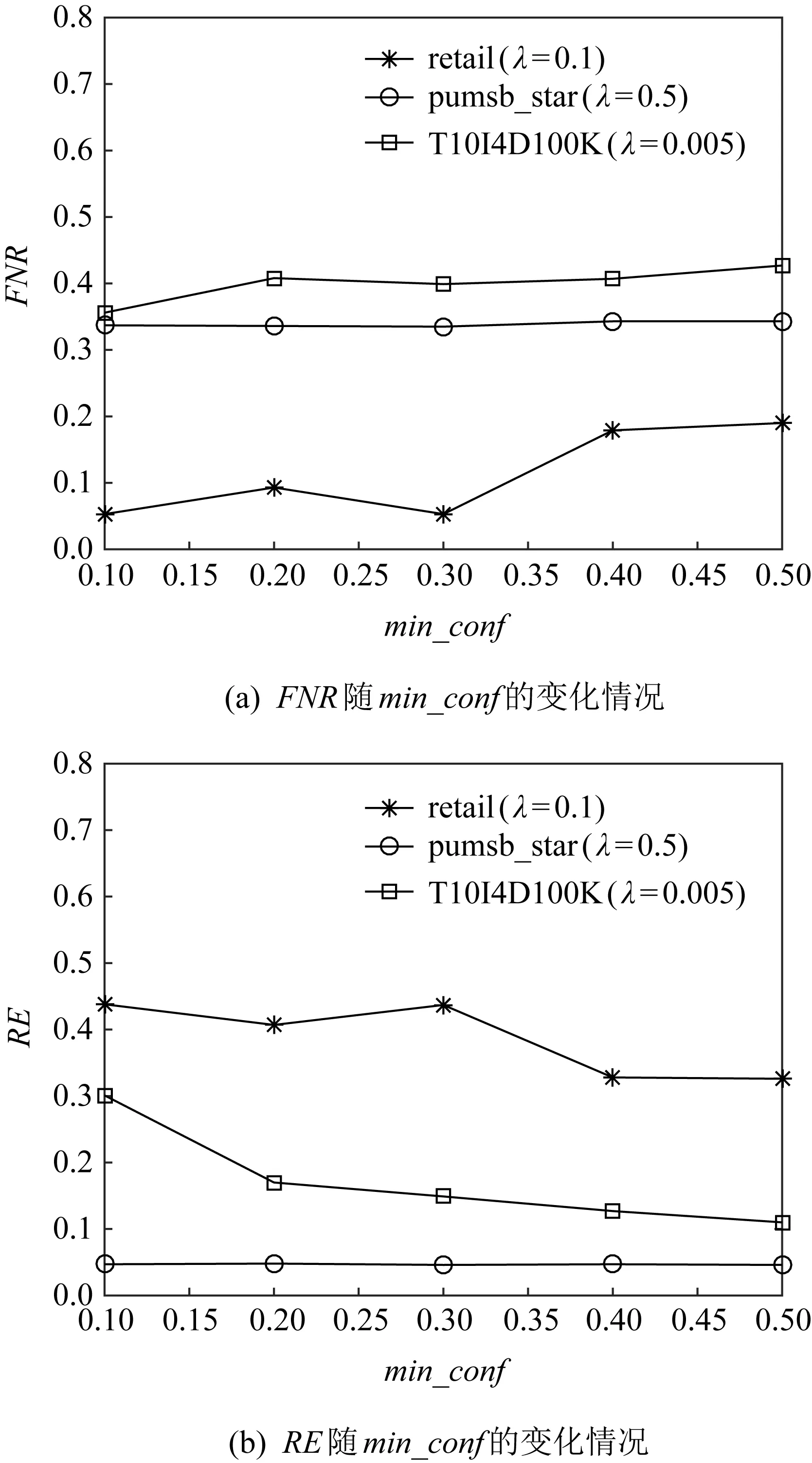
⑤ WHILEl ⑥z′=z′+zl; ⑦ IFz′>p×zsumTHEN ⑧lmax=zl; ⑨ END IF ⑩ END WHILE 算法1中p取值一般為0.85[21].算法1首先將所有事務的長度按升序排序,并按順序對所有的事務長度做累加,直到累加和大于所有事務長度綜合的0.85倍,記錄當前的長度lmax,將其作為最大事務長度閾值. 分割支持度閾值的選取與事務長度閾值的選取類似,其中p的取值為0.2.首先將各個項的支持度按降序排序,并按順序依次對支持度累加,直到累加和大于支持度總和的0.2倍,停止累加并記錄當前的支持度sup′作為分割支持度閾值. 確定這2個閾值后,就可以對數據集中超過事務長度的事務進行分割.在事務分割過程中,1個長事務有可能被分割為若干個短事務.1個長事務t的分割過程描述如下:1)使用指數機制依次從事務t中不放回地挑選出lmax個項作為1個新事務,打分函數為項的支持度;2)判斷事務t中剩余項的支持度是否大于sup′,若有,則繼續使用指數機制,從事務t中挑選1項添加到新事務中,直到事務t中剩余項的支持度都不大于sup′;3)返回步驟1),直到|t|=0.對于數據集中所有超過長度閾值分割的具體實現過程如算法2所示,最終返回對長事務分割后的數據集D′. 算法2.事務分割. 輸入:數據集D; 輸出:對長事務分割后的數據集D′. ① FUNCTION(SplittingLongTransactions(D)) ②lmax=GetLenThreshold(D); ③Tb=?,T′=?,D′=D; ④ FOR each transactiont∈D′ DO ⑤tlen=length(t); ⑥ IFtlen>lmaxTHEN ⑦Tb.add(t); ⑧D′.delete(t); ⑨ END IF ⑩ END FOR 中選取lmax個項; 按降序排序*/ TS-ARM算法采用事務矩陣[12]存儲數據集,可以有效減少存儲空間,并且后續進行頻繁項集支持度的計算都可以依賴事務矩陣計算完成,無需重復掃描數據庫.圖1為事務矩陣的轉化示例.其中行對應數據集D中出現的所有項,列對應數據集D中的所有事務,若事務Tm中包含in,則將事務矩陣的第n行第m列置為1,否則置為0.得到事務矩陣G后,則可根據向量的運算規則,先對二進制向量“與”運算,再對各項進行求和,快速求得項集的支持度. 圖1 事務矩陣的轉化示例 在人們的日常生活中,對于奢侈品的消費次數可能占比較小,但其金額卻占了消費總金額的大部分,因此不能只設置1個最小支持度閾值來統計頻繁項集.考慮到算法的實用性,參考文獻[17]自適應設置項集的最小支持度閾值.項集支持度閾值的選取規則如下:選擇該項集中支持度閾值最小的項,將其閾值作為該項集的支持度閾值,對每個項集都設置1個支持度閾值.算法3則是實現為每個項設置1個最小支持度閾值. 算法3.為每個項設置最小支持度閾值. 輸入:數據集D、支持相關性ρ、允許MIS最小值λ; 輸出:每個項的最小支持度閾值i.MIS. ① FUNCTION(AssignMIS(D,ρ,λ)) ②G←根據D構建事務矩陣; ③I={i1,i2,…,in};/*數據集中包含的所 有項*/ ④ FOR each itemi∈IDO ⑤i.sup←通過計算G中各行中1的個數; ⑥i.MIS=max{ρ×i.sup,λ}; ⑦ END FOR ⑧S=sort(I);/*按MIS升序對I排序*/ ⑨ RETURNS. 算法4描述了TS-ARM算法的完整框架.對預處理、項集最小支持度閾值的設置、頻繁項集挖掘和關聯規則挖掘進行了實現. 算法4.TS-ARM算法. 輸入:數據集D、支持相關性ρ、允許MIS最小值λ、隱私預算ε; 輸出:所有關聯規則的集合及其置信度. ① 確定事務長度閾值lmax和分割支持度閾值sup′,使用ε1的隱私預算對數據集D預處理得到D′,其中ε1=0.6ε; ② 由D′構建事務矩陣G; ③ 掃描G得到頻繁1項集以及每個項的MIS,并刪除G中不頻繁1項對應的行; ④ 頻繁項集Lk自連接得到候選項集Ck; ⑤ 掃描G計算候選項集的支持度,并根據項集中各個項的MIS值為每個項集設置特定的最小支持度閾值; ⑥ 使用ε2的隱私預算為候選項集的支持度添加Laplace噪聲,并將噪音支持度與該項集的最小支持度閾值對比,生成噪音頻繁項集,其中ε2=0.4ε; ⑦ 根據各個項集的噪音支持度計算項集之間的置信度,并設置最小置信度閾值,查找出所有的關聯規則. 衡量差分隱私算法的性能,可以從隱私性和可用性2個方面進行分析. 定理1.若算法M在使用雙重條件機制分割處理后的數據集上滿足ε-差分隱私,那么算法M在原始數據集上也滿足ε-差分隱私. 證明.用r表示數據集的分割過程,由文獻[20]可知,對于鄰近數據集D1,D2,有: Pr[M(r(D1))∈SM]≤exp (ε)× 其中SM表示算法M可能輸出的任一結果. 證畢. 定理2.TS-ARM算法滿足ε-差分隱私. 證明.算法包含2個處理階段:預處理和關聯規則挖掘,在預處理階段使用指數機制對超過長度閾值的長事務進行分割,記分配的隱私預算為ε1,在頻繁項集查找階段,對支持度計數采用Laplace機制進行噪聲的添加,記分配的隱私預算為ε2. 關聯規則的挖掘主要依賴于頻繁項集,可以通過頻繁項集查找階段計算得到的噪音支持度來計算關聯規則的置信度,不涉及隱私泄露.因此,由差分隱私的串行性質及定理1可知,TS-ARM算法滿足ε-差分隱私,其中,ε=ε1+ε2. 證畢. 在隱私保護算法中,若算法滿足(δ,η)-可用性,則表示算法在理論上證明是可用的. 定義8.δ-相似性.給定數據集D和閾值λ,設S為一頻繁模式算法的輸出結果,若S滿足以下2個條件,則稱其滿足δ-相似性[19]. 1) 支持度大于(1+δ)λ的項集都屬于S; 2) 支持度小于(1-δ)λ的項集都不屬于S. 定義9.(δ,η)-可用性.對于差分隱私保護算法M,若其在給定數據集D上的輸出結果以大于1-η的概率滿足δ-相似性,則稱算法M滿足(δ,η)-可用性,其中δ,η∈[0,1][20]. 定理3.TS-ARM算法滿足(δ,η)-可用性. 證明.給定數據集D,設n為其項集域大小,由文獻[21]可知,若某算法滿足式(7)則可保證算法既滿足ε-差分隱私又滿足(δ,η)-可用性. (7) 其中(1-η)/η. 以pumsb_star[21]數據集為例,項集域大小為2 088,設閾值λ=400,設置η=0.7,δ=0.8,代入式(7)得ε≥0.964 3,即當ε≥0.964 3時,算法滿足(0.8,0.7)-可用性.因此,在隱私預算不變時,在算法中合理設置δ與η的值,總能使其滿足(δ,η)-可用性. 證畢. 本文實驗環境為Inter?CoreTMi5-8250UCPU @ 1.60 GHz,4 GB內存,Windows10操作系統,實驗采用Python語言進行編寫.實驗采用4個數據集,分別是某零售商店的銷售數據retail、人口普查數據pumsb_star,以及IBM公司的數據生成器生成的2個模擬數據集T40I10D100K和T10I4D100K,這些數據集常被用于關聯分析[11,21].表1給出了上述數據集的幾種屬性,包括事務數量、項數、最大事務長度、平均事務長度. 表1 數據集的屬性描述 下面將在這4個數據集上進行實驗,并與TF[10]算法和PrivBasis[16]算法進行對比,以驗證本文提出算法的優越性. 在關聯規則挖掘之前,為了降低查詢的全局敏感度,首先要對數據預處理,即對長事務進行分割.表2為在不同的隱私預算下數據預處理后數據的最大事務長度: 表2 不同隱私預算下預處理后的事務長度 5.3.1 評價指標 為了驗證算法的可用性,采用拒真率(FNR)和相對誤差(RE)2個衡量指標. 定義10.拒真率(FNR).用于度量出現在F而沒有在F′的項集在F中所占的比例: F為真實頻繁模式集,F′為噪音頻繁模式集. 定義11.相對誤差(RE).用于衡量算法輸出結果中噪音項集支持度與真實支持度間的相對誤差,其定義為 其中F′為算法輸出結果的頻繁項集集合,A為F′中的任意項集,support′A為項集A在算法輸出結果中的支持度,即噪聲支持度,supportA為項集A的真實支持度. FNR和RE越小說明算法的可用性越高. 5.3.2 頻繁項集可用性 驗證頻繁項集可用性采用pusmb_star, T10I4D100K,T40I10D100K這3個數據集,并與TF[10]和PrivBasis[16]算法進行對比.為了更好地比較算法的性能,每個數據集分別設置2個k值,設定支持相關性ρ=0.15,并設置TS-ARM算法的λ值與PrivBasis和TF算法的最小支持度閾值相等,其中pusmb_star,T10I4D100K,T40I10D100K這3個數據集的最小支持度閾值分別設置為0.6,0.005,0.05. 由圖2、圖3、圖4均可以看出,3個數據集的FNR和RE都隨ε的增大而減小,并且在同等條件下,TS-ARM算法的FNR和RE均小于PrivBasis和TF算法,這是因為本算法采用分割縮短事務長度,將長事務分割為若干個短事務,數據庫中單個項的支持度不會產生影響,并且采用雙重條件機制,保證了支持度較高的項仍然被分到同一事務中,從而進一步降低了挖掘誤差. 圖2 pumsb_star數據集的可用性隨ε的變化情況 圖3 T10I4D100K數據集的可用性隨ε的變化情況 圖4 T40I10D100K數據集的可用性隨ε的變化情況 5.3.3 關聯規則可用性 關聯規則挖掘結果的可用性驗證采用retail,pumsb_star,T10I4D100K這3個數據集.每個數據集設置不同的λ值,最小置信度閾值min_conf從0.1~0.5,間隔為0.1,支持相關性ρ=0.15,ε=0.6,分析FNR和RE的變化情況.由圖5可知,3個數據集的FNR和RE均在0.5以下,且FNR值隨min_conf的增大而增大,在min_conf>0.4后,其變化趨于平緩,RE的值隨min_conf增大而平穩減小.并且3個數據集的FNR和RE均在0.5以下,因此由于噪音頻繁項集而導致關聯規則產生的誤差也較低,并且較為穩定. 圖5 3個數據集的挖掘結果可用性隨min_conf的變化情況 本文提出了一種滿足差分隱私的關聯規則挖掘算法TS-ARM.在已有的多種事務截斷算法的基礎上,設計了一種雙重條件機制事務分割方法,基于分割長度閾值和分割支持度閾值對長事務進行分割.該算法的隱私性和可用性在理論上是可證明的,并通過實驗證明了算法的可用性.本文提出的分割算法會導致數據集的事務數量有所增加,下一步將考慮在控制事務數量的同時有效縮短事務長度.3.2 關聯規則挖掘

4 算法隱私與可用性分析
4.1 隱私性分析
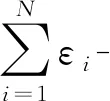
Pr[M(r(D2))∈SM],4.2 可用性分析
5 實驗結果與分析
5.1 實驗環境與實驗數據
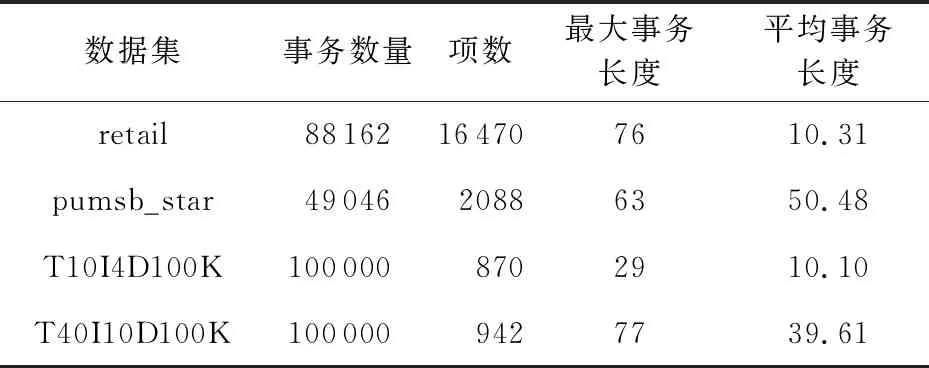
5.2 數據預處理結果分析
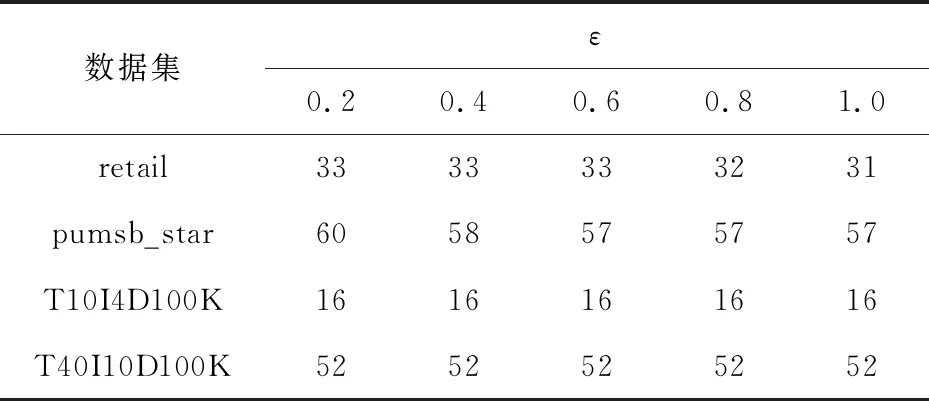
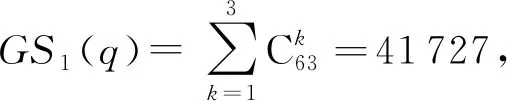
5.3 可用性分析

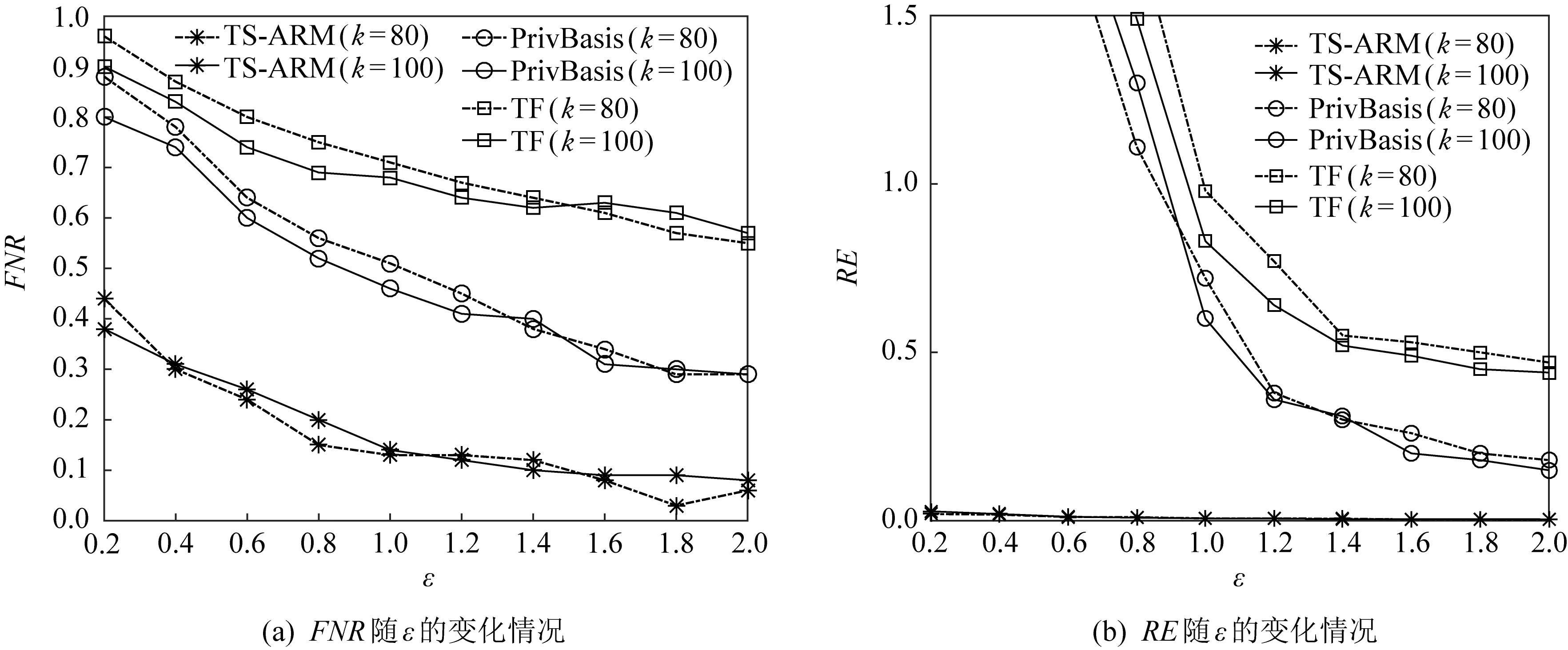
6 結束語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
當代陜西(2019年15期)2019-09-02 01:52:00
幸福(2018年33期)2018-12-05 05:22:42
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
