基于改進KNN算法與SIR模型的輿情處理研究
2021-11-17 08:38:20肖思瑤楊澤來王家琪
計算機仿真 2021年5期
張 雷,肖思瑤,楊澤來,王家琪
(1.重慶交通大學數學與統計學院,重慶 400074;2.重慶交通大學信息科學與工程學院,重慶 400074)
1 引言
伴隨著全球移動互聯網絡的快速發展,網民數量爆炸式增長,輿情得以快速和廣泛的傳播。網絡輿情是社會輿情在互聯網空間中的映射,但網絡作為虛擬社會,同時也是完全開放的平臺,潛伏著各類人群和各種思潮[1], 因而網絡輿情相對其它輿情形態更為復雜,這種情況為輿情的調控帶來了新的挑戰[2]。一個有效的網絡輿情的檢測及調控機制可以更好的維持社會穩定、維護企業聲譽。對于輿情的檢測和調控涉及到輿情嚴重性劃分和對輿情進行合理有效干預兩個主要工作。同時,近年來各種智能算法在分類問題[3]、情感分析等任務上取得突破,這為重大輿情的發現和調控提供了新的手段。
對網絡輿情的嚴重等級判斷可以篩選出需要重點關注的對象,提高網絡輿情的調控效率。羅平等人將輿情按照負面情感大小將輿情分為四類[4];王寧等人綜合網絡輿情的各方面因素[5],將輿情分為“藍色”、“黃色”、“橙色”和“紅色”四類,并基于灰色系統理論對輿情進行預測。
綜合考慮網絡輿情的各個元素,準確的模擬網絡輿情,可以形象的討論各調控手段對網絡輿情的影響。Wang Y等人和姚翠友等人[6-7]基于元胞自動機,分別對網絡信息的傳播和輿情下個體之間的影響進行了研究;連淑娟等人[8]利用KNN算法在輿情模擬的基礎上,對輿情的擴散傾向進行預測;Tian R Y等人基于傳染病模型,模擬了社交網絡中謠言的傳播[9];Li S等人利用傳染病模型[10],準確的模擬了社交網絡中話題傳播中的行為特征。
Zhang L以及Zhao Y等人[11-12]的研究闡述了意見領袖對于輿情的影響,周曄等人的研究肯定了微博問政對于網絡輿論的積極影響[13],另外還有多個研究指出負面文章限流、敏感詞匯限制等方法可以有效干預輿情走向。
網絡輿情主要以文本形式體現,而文本情感分析技術可以從輿情中提取群眾的情感,用于判斷輿情的嚴重性。文本情感分析近年來取得了巨大突破,基于長短期記憶網絡的模型[14]、添加注意力機制的模型[15]都取得了很好效果。韓開旭等人[16]優化了卷積神經網絡的內部計算結構,基于分段卷積神經網絡進行文本情感極性分析,使得其精度相比一般模型有明顯提高;Google提出的BERT[17],大幅打破了SST-2情感分類任務的紀錄;百度于19年提出的ERINE模型[18]將中文文本情感極性分析的精度提升到95.4%。
綜上所述,對于輿情模擬,過往的研究已提出一些準確可行的模型,并通過定性分析,提出了多個輿情調控手段。然而,這些研究過于零散,對于重大輿情,不能構建一個完整有效的反應機制;同時,對于網絡輿情嚴重性的劃分研究以及各調控手段對網絡輿情的調控效果的研究,大多都是從定性的角度出發,鮮有研究進行定量分析。
對于這種現狀,本文提出了一種融合智能算法的輿情調控機制。首先基于KNN算法[19],配合文本情感極性分析技術,對網絡輿情的嚴重性進行劃分,然后對于嚴重的負面網絡輿情進行有效調控。為了探討調控手段的有效性,本文嘗試利用基于傳染病模型的仿真探討各干預手段對于網絡輿情的調控情況。
相較于以往的研究,本文的主要創新點總結如下:
1) 借鑒機器學習和數據科學的發展成果,提出了一套較為完整的重大網絡輿情發現及調控機制,為網絡輿情的處理提供了理論手段。
2) 以往研究大多從定性分析角度對輿情進行嚴重性劃分,本文利用融合文本情感分析的改進KNN算法定量的將網絡輿情按照嚴重性劃分等級,篩選出嚴重輿情,為輿情的調控集中力量。
3) 以往研究大多從經驗和定性角度分析輿情的調控手段,本文基于精細劃分的拓展SIR模型,對輿情的傳播機制進行仿真模擬,并定量研究各網絡輿情調控手段對于輿情的整體影響。從理論上探究了各調控手段的有效性和調控力度。
2 網絡輿情處理方法
首先利用情感極性分析配合KNN算法對網絡輿情進行嚴重性等級劃分,篩選出嚴重輿情,再對其進行相關調控。為了驗證相關調控手段的有效性,本文進一步基于拓展SIR傳染病模型,探究了調控手段有效性和調控力度。
2.1 輿情嚴重性劃分
本文借鑒王寧等人的研究將輿情按照嚴重性劃分為“藍色”、“黃色”、“橙色”和“紅色”,如表1,并借助網絡輿情的負面影響大小來描述輿情的嚴重性。

表1 網絡輿情的嚴重等級劃分
為判斷網絡輿情的負面影響大小,本文從網絡輿情中提取出三個指標,即“傳播時間”、“傳播規模”和“網民的情感”,通過融合文本情感分析利用該三個指標KNN算法進行輿情負面影響嚴重性分類。
2.1.1 特征提取
分類前先需要對輿情信息嚴重性特征進行提取。
對于網絡輿情的傳播時間。可以借助從輿情開始時間到輿情發展到頂峰時間之間的時間間隔,用如下公式表示
Gu=Tpeak-Tbegin
(1)
其中Tpeak為輿情頂峰的時間,Tbegin為輿情開始時間。
對于網絡輿情的規模。多個指標可用于描述,本文選取如表2的三個指標描述網絡輿情規模。

表2 輿情規模的量化指標
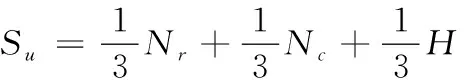
(2)
其中Nr,Nc,H分別為歸一化處理后的總閱讀數,總評論數和總熱度指數。
對于網民的情感。通過隨機抽取網絡輿情下網民的評論,基于文本情感極性分析深度學習算法可獲得文本的情感極性預測,將單個文本情感做如表3映射。

表3 情感與打分映射關系
2.1.2 嚴重性劃分
KNN算法即為k臨近算法,對于給定的數據,考慮在整體數據集中與該數據距離最近(即最相似)的k個數據,包含此k個數據最多的類別即判斷為給定數據的類別。
數據間的“距離”可以用數據歸一化后的歐氏距離來描述。即
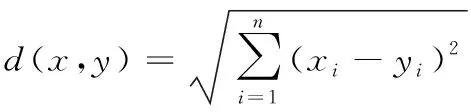
(3)
其中xi,yi分別為兩組數據中第i維的數據。
k值的選取對模型的精度影響較大,故實驗中要充分考慮各k值下的分類精度。
綜上,本文的嚴重性分類方法整體流程可以總結如圖1。
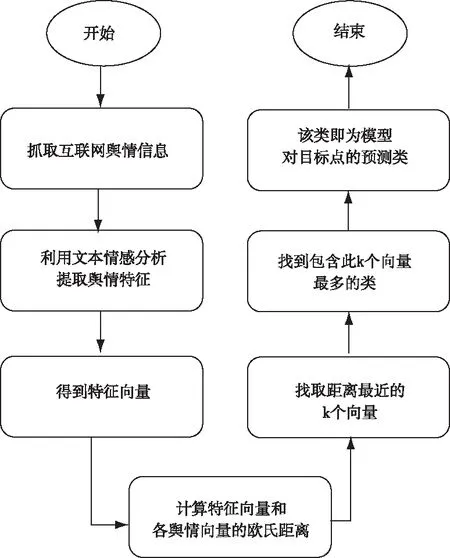
圖1 嚴重性分類流程圖
首先抓取互聯網輿情信息,利用文本情感分析等手段提取輿情特征,得到輿情特征向量,再計算訓練集中和待判斷點歐氏距離最小的k個數據,包含這些數據最多的類即為目標輿情的預測類。
2.2 調控方法有效性及調控力度探究
過往的研究從定性的角度分析了各調控手段對于網絡輿情的積極影響,如官方賬戶互動、負面文章限流、建立虛擬積極意見領袖、對于消極意見領袖封號限制和教育等手段。本文將輿情下的群眾精細劃分為六類,分析各類人群間的轉換關系以及調控手段對人群轉換的影響,從而構建拓展SIR模型,進行仿真,探討各手段對網絡輿情的影響。
2.2.1 模型準備
根據社交網絡的評論人群的特點,可將群眾分為六類,如表4展示。

表4 群眾分類
為界定群眾對于輿情的整體態度,本文利用Bad描述輿情的負面影響大小
Bad=i(t)+t(t)
(4)
分析各類人群間存在轉化關系如圖2所示。
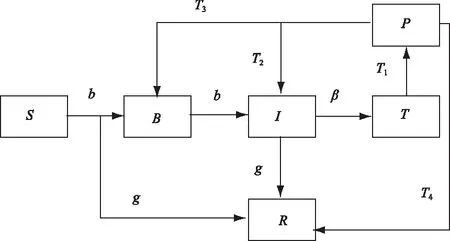
圖2 輿情中各人群轉化示意
其中,g為正面輿情傳播力度,b為負面輿情傳播者的傳播效率,β為負面領袖轉化率,r1為負面輿情領袖被封號隔離的速率,r2為負面意見領袖解封后成為I人群的概率,r3為負面輿情領袖解封后成為B人群的概率,r4為負面領袖解封后成為R人群的概率。
對各種調控手段對上述參數的影響進行分析,可以得到分級影響示意圖如圖3所示。可以觀察到,虛擬積極意見領袖數量Y與g、r3和r4正相關;官方賬戶互動程度W與g正相關;負面文章限流程度X與b負相關,與r2正相關;封號限制程度F與r1正相關,與b負相關;對負面意見領袖進行教育的程度J與r4正相關。
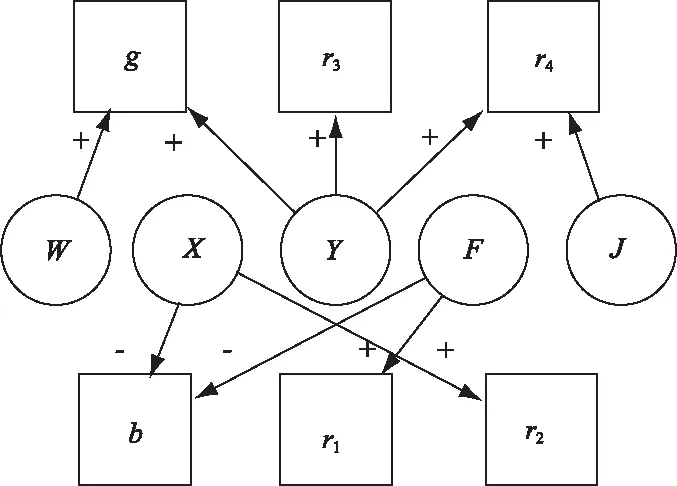
圖3 外加調控手段的分級影響
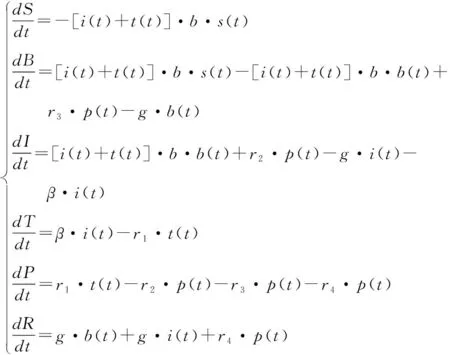
(5)
2.2.2 輿情的仿真模擬
基于SIR傳染病模型,對輿情下每一種人群的轉化率進行分析,可以得到如下的輿情傳播模型的動態微分方程。
以人群B為例,在Δt時間內,人群的變化為
N(Δt)B=N(S)+N(P)r3-N(B)R-N(B)t
(6)
其中,N(S)為S人群轉化而來的人數,N(P)r3為P人群以概率r3轉化來的人數,N(B)R為B轉化為R人群的人數,N(B)I為B轉化為I人群的人數。
整個過程中,從S轉化為B的總人數為
N·[i(t)+t(t)]·b·s(t)·Δt
(7)
單位時間內由P人群轉化為B人群的人數為P(t)·N·r3,則P人群以概率r3轉化為B的總人數為
N(P)r3=p(t)·N·r3·Δt
(8)
總結得到動態微分方程組如式(9)。且滿足
s(t)+r(t)+b(t)+i(t)+t(t)+p(t)=1
(9)
利用該微分模型,模擬輿情中各人群的變化情況,描述輿情的發展。進一步加以調控手段,觀察調控手段對于模型各變量的影響,即可探討輿情調控手段的有效性和調控力度大小。
3 實驗與分析
3.1 基于融合文本情感分析的改進KNN算法進行輿情嚴重性劃分
3.1.1 數據準備和預處理
利用合法數據抓取的手段,從微博平臺抓取72個輿情數據樣本,其中56個輿情數據樣本作為訓練集,16個作為測試集,并進行人工標注,抓取時注意數據集中四種嚴重程度的輿情數據占比相同。
主要從網絡上抓取到以下幾方面輿情數據:輿情的開始時間Tbegin和發展到頂峰的時間Tpeak;網絡輿情話題的總閱讀量Nr,總討論量Nc;百度指數提供的輿情熱度指數;隨機抓取的30條輿情評論文本。
對于文本的情感極性分析,為簡化實驗,本文借用百度基于ERNIE的文本情感極性分析接口。
3.1.2 模型的訓練結果和分析驗證
將56個訓練數據全用于訓練KNN模型,利用16個數據進行測試,因為數據量不夠充分,測試集的不同選取會帶來較大精度測量誤差,于是將原始72個數據隨機打亂,再構建測試集。
測量模型在不同亂序情況下,及不同k值下的精度如圖4,三維坐標系間中做出模型對于訓練集的聚類圖如圖5,其中Timenorm、Emonorm和Scalenorm皆為歸一化后的數據。
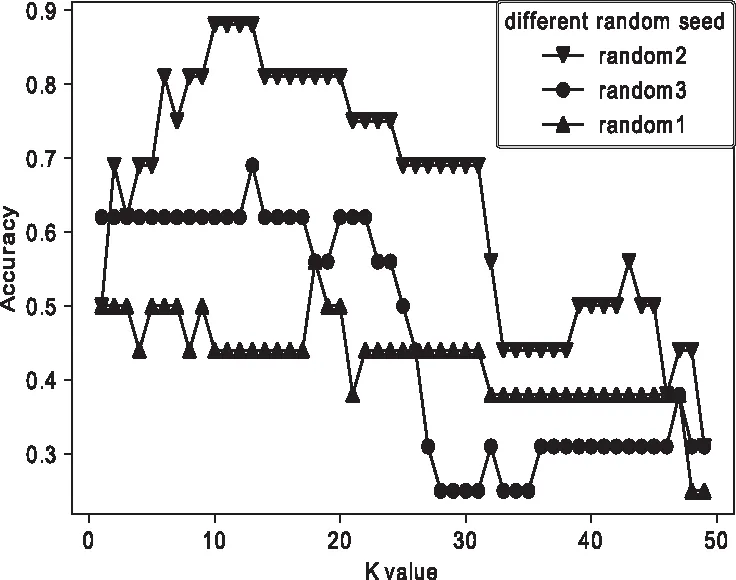
圖4 不同亂序情況下以及不同 k值下的模型精度
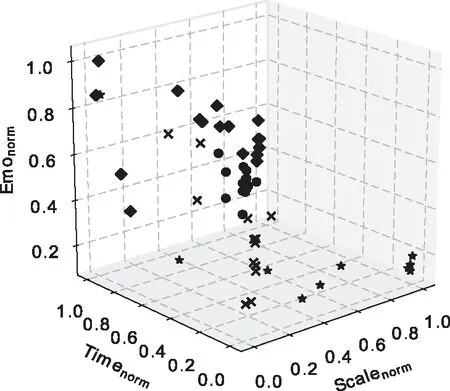
圖5 模型對于訓練集的聚類圖
由圖4可以觀察到,三種不同的測試集選取情況下,模型精度分別為88%、56%和69%。模型的精度最高可達88.0%,模型平均精度為71.0%。由圖5可以觀察到測試集明顯的聚類為4類,可以判定模型較好的取得了分類效果。綜上可以判斷在該數據量上,模型已達到不錯的輿情嚴重性劃分效果。
為測試模型的實際效果,本文嘗試利用本文模型對2020年8月的輿情“浙大通報努某某留校察看事件”進行嚴重性等級劃分。首先從新浪微博爬取到該輿情的閱讀量 1.6 億,討論數 10.4 萬,百度熱度指數5702,估算輿情從出現到輿情頂峰的持續時間為1天,并合法地隨機爬取了微博話題“#浙大通報努某某留校察看事件#”下的30條評論。通過情感極性分析接口得到每個評論樣本的情感正負,得到該30個文本的情感極性,其中4個正面文本,26個負面文本。
計算得到
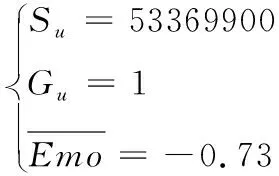
(10)
再將數據包裝為向量(53369900,1,-0.73)加入總樣本中,數據歸一化后得到(1.0,0.0,0.135)。
基于已訓練好的分類模型,對樣本進行類別判斷。得到該向量被判斷為第4類,即為該輿情屬于紅色重大輿情。而分析輿情本身,“浙大通報努某某留校察看事件”近幾日引起了互聯網上各種不好的評價,確實對單位有巨大的不利影響,需引起重點關注,應該立馬采取相關調控手段。
3.2 基于拓展SIR模型的輿情仿真和調控方法研究
3.2.1 模型實現
為簡化實驗,初始化模型各初始變量:
S=950;B=40;I=10;T=0;P=0;R=0
(11)
假設各參數初始值為b=0.1;g=0.3;β=0.05;r1=0.05;r2=0.25;r3=0.25;r4=0.5。當時間t∈[0,40]時,得到結果如圖6 (a)所示;當時間t∈[0,1]時,得到結果如圖6 (b)所示。
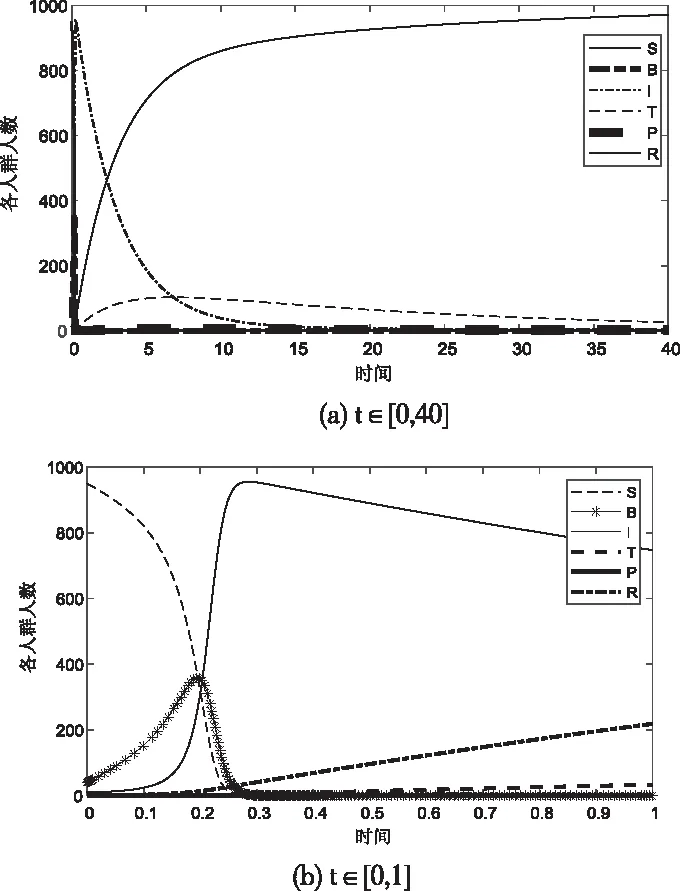
圖6 各人群人數隨著時間的變化
考察t∈[0,40]時,可以觀察到隨著時間t的增長,最終R人群數量最終會逼近總人數數量,其他人群數量趨近于0。最終群眾會對一個話題失去興趣,并不再傳播。這與實際情況是相符的。
考察t∈[0,1]時。結合實際考慮,輿情初期時,由于負面輿情的傳播,不知輿情者減少,S人群在最初階段總人數迅速減小,最終趨于0,和圖象中一致。后由于輿情的進一步傳播,部分負面輿情者成為傳播者,而在圖象中B人群在t=0.2左右出現一個高峰,B人群總人數因為轉化為I或R人群總人數初期階段減少,二者是一致的。I人群呈現迅速上升趨勢,隨后其總人數緩慢減少也和實際相符,人們剛得知負面輿情時容易被負面情緒感染,從而開始傳播輿情,后由于對該輿情市區興趣或本身冷靜的認識到了輿情的實際情況,便不再傳播負面輿情,并想向其他人群轉化,所以I人群在達到高峰后開始緩慢下降。
3.2.2 實驗結果
模型中有多個參數,b、g、β、r1、r2、r3和r4。
固定其它參數,觀察Bad關于各參數的變化規律,如圖7。
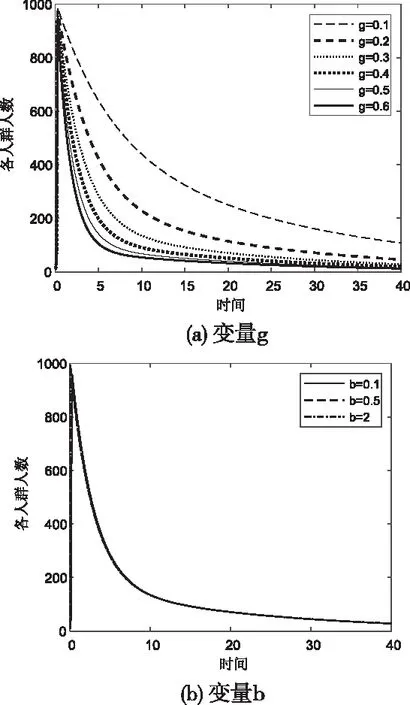
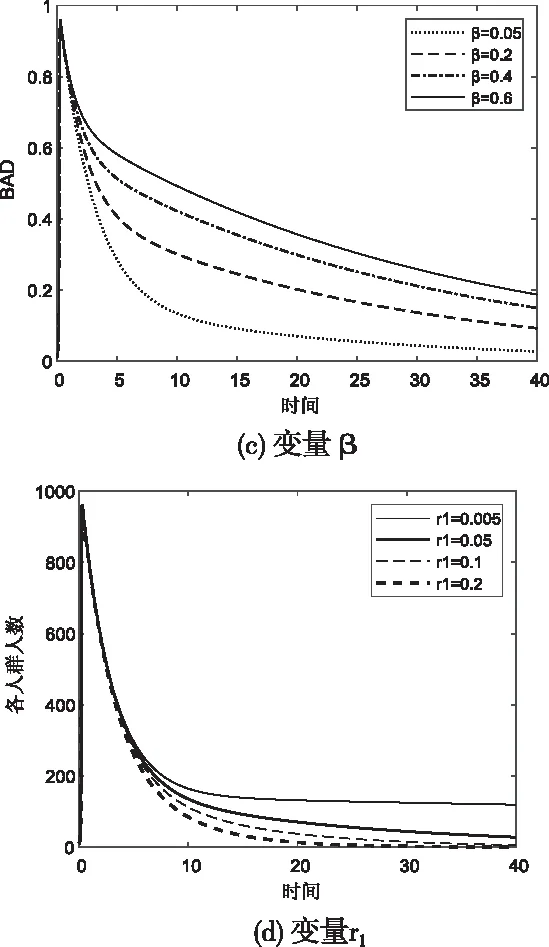
圖7 Bad關于變量g、b、β和r1的變化規律
假設所有被封號者最后都會解封,則有r2+r3+r4=1;若將r2與r3作為自由變量,則只需滿足r2+r3=0.5。
固定其它參數,觀察Bad關于變量r2的變化規律,結果如圖8 (a)。固定其它參數,觀察Bad關于變量r3的變化規律,結果仍如圖8 (a)。
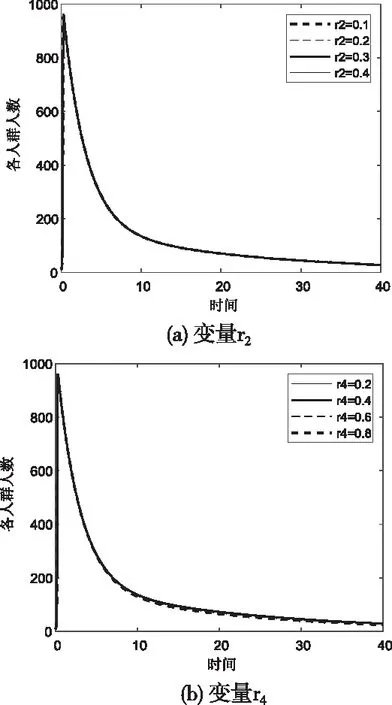
圖8 Bad關于變量r2、r4的變化規律
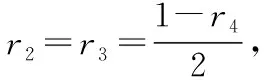
3.2.3 結果分析
通過上述實驗現象,可以觀察到:
在一個輿情周期內,Bad值對參數g、β最敏感,其次是r1與r4,而b、r2與r3的變化對產生的影響不大。結合本文2.2節部分中的模型,虛擬積極意見領袖數量度量指標Y和g、r3、r4正相關,官方帳戶互動程度W與g正相關,負面文章限流程度X與b正相關,與r2負相關,封號限制程度F與r1正相關、與b負相關,對負面輿情領袖進行教育程度J與r4呈正相關。
綜上,政府或企業對輿情進行干預時,應優先選擇措施Y(增加虛擬積極意見領袖數量)和W(加強官方賬戶互動),其次選擇措施J(對負面意見領袖進行教育)甚至F(對負面意見領袖封號),X(負面文章限流)需要搭配其余四種使用以求取得更好的輿情調控效果。
結合實驗結果,可以總結:對于互聯網輿情的處理,可以先利用融合文本情感分析的KNN算法篩選出嚴重輿情,繼而加大力度進行官方帳戶互動、增加虛擬的積極意見領袖,進一步還可以對負面輿情領袖進行封號教育,這三者對于網絡輿情調控的作用較為顯著。這種方法從定量分析的角度給網絡輿情處理提供了理論支持,是一種值得實踐的有效手段。
4 結語
本文提出了一種簡單有效的網絡輿情檢測和調控機制,借鑒基于深度學習的文本情感分析技術,對KNN算法進行改進,用于輿情的嚴重性劃分,并利用有效手段對嚴重輿情進行調控。同時,本文利用對人群精細劃分的拓展SIR模型模擬輿情的傳播,探究了調控手段的有效性和調控力度。綜上得到結論:
1) 本文提出的輿情嚴重性分級模型精度最高可達88.00%,對網絡輿情的處理有較大的意義。
2) 官方帳戶互動和虛擬積極意見領袖對輿情調控力度較大,同時,對輿情的消極意見領袖進行封號教育也能取得不錯效果。
3) 本文提出的仿真探究方法,為輿情調控手段的有效性探究提供了一定理論基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中國生殖健康(2020年5期)2021-01-18 02:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
光學精密工程(2016年6期)2016-11-07 09:07:19
