基于OPNET的片上網絡路由算法的建模與仿真
2021-11-17 06:35:52陳良昌劉召軍張彥軍
計算機仿真 2021年8期
關鍵詞:模型
陳良昌,劉召軍,張彥軍
(1.中北大學儀器科學與動態測試教育部重點實驗室,山西 太原 030051;2.中北大學電子測試技術重點實驗室,山西 太原 030051)
1 引言
隨著大規模集成電路和半導體技術的快速發展,在有限的空間中,可以放置越來越多的電子器件。這就使得越來越多的功能模塊可以集成在一塊芯片上,片上系統(System-on-Chip,SoC)的概念應運而生[1]。片上系統包含多個可以實現某一功能的知識產權核(Intellectual Property,IP),這些知識產權核通過總線的方式與處理器保持通信[2]。但由于總線帶寬的限制,IP核與處理器之間的通信會受到制約,產生一定的延時。片上系統所集成的IP核越多延時越高,集成電路芯片的工作效率就會受到很大的影響[3]。
為了解決總線通信中存在的這些問題,研究人員從計算機網絡受到啟發,提出了片上網絡(Network on Chip,NoC)這樣全新的通信架構[4]。文獻[5]介紹了片上網絡應用在集成電路上的依據與原理。與片上系統不同的是,IP核連接在路由節點上,路由節點間相互連接,形成一個網絡[6]。在片上網絡中,每個IP核在與處理器進行通信的時候,有很多條鏈路可以選擇。這樣就避免了數據傳輸過程中因帶寬不夠而造成的不必要等待,很好的解決了IP核與處理器之間通信的時延問題[7]。但是,在片上網絡的熱點區域很容易發生堵塞,所以片上網絡路由的研究成為當前片上網絡研究的一個重要方向[8]。
片上網絡路由算法的研究過程中,國外主要把算法分為兩種類型:確定性路由算法和自適應路由算法[9]。其中確定性路由算法是最簡單和最容易實現的路由算法。但是確定性路由算法由于其本身的局限性,在大量數據包進入網絡時,由于不能自主選擇路徑,存在平均延時較大,鏈路利用率不高等缺點。在自適應路由算法中,目前研究最簡單的是維序XY路由算法,MIT的RAW、Tile64以及Intel公司的Tera-Scale都采用這種算法進行NoC上的數據通信[10]。國內對片上網絡的研究較國外起步晚,主要研究是對原有的通用路由算法進行改進。本文路由算法采用兩種約束條件,提高了節點間數據路由的自適應性,大大提高了數據傳輸的端對端延時和鏈路利用率。
2 片上網絡路由算法
路由算法在很大程度上決定著片上網絡的各項性能。目前,片上網絡硬件搭建最普遍的是在二維拓撲結構下展開的。所以本文基于最典型的4×4 2D-Mesh結構對片上網絡的一種路由算法進行仿真。該路由算法通過兩個步驟的約束條件對數據包進行路徑的選擇。第一步,比較中間地址與目的地址的坐標;第二步,比較各個通道間鏈路利用率的大小。
各個節點的地址由(x,y)兩個參數表示,傳輸方向由E、S、W、N、L表示,分別代表東、南、西、北、本地五個傳輸方向,如圖1所示。節點源地址用(xs,ys)表示,目的地址用(xd,yd)表示,在數據包傳輸的過程中,地址是實時變化的,稱為中間地址,用(xm,ym)表示。

圖1 片上網絡各節點坐標
中間地址與目的地址的比較關系有以下8種情況。①當xm=xd且ym
之后,比較各個通道間的鏈路利用率,主要是對上一約束條件中有兩種路徑選擇的情況進行再次判斷,以確定數據傳輸的路徑。它通過比較兩條路徑上的鏈路利用率大小,選擇鏈路利用率小的路徑進行傳輸。路由算法具體流程圖如圖2所示。

圖2 路由算法流程圖
3 OPNET模型建立
3.1 網絡層
OPNET[11]-[13]的網絡層建模主要描述了模型的拓撲結構和數據傳輸的方式,本次建模是基于4×4 2D-Mesh結構建立的片上網絡數據傳輸模型。如圖3所示,由16個節點和24條鏈路構成。根據數據在網絡模型中傳輸的要求,鏈路采用全雙工鏈路。

圖3 網絡層模型圖
3.2 節點層
根據所連接的鏈路的個數的不同,建立三種類型的節點。主要區別在于發信機和接信機的數量不同和仲裁模塊接收來自各個方向的統計量的數量不同。其中node0、3、13、16節點模型如圖4(a)所示,node1、2、4、7、8、11、13、14節點的模型如圖4(b)所示,node5、6、9、10節點模型如圖4(c)所示。節點層的建模主要包括rcv模塊、xmt模塊、src模塊、queue模塊、dest_select模塊、arbiter模塊、proc模塊、fifo模塊和sink模塊。
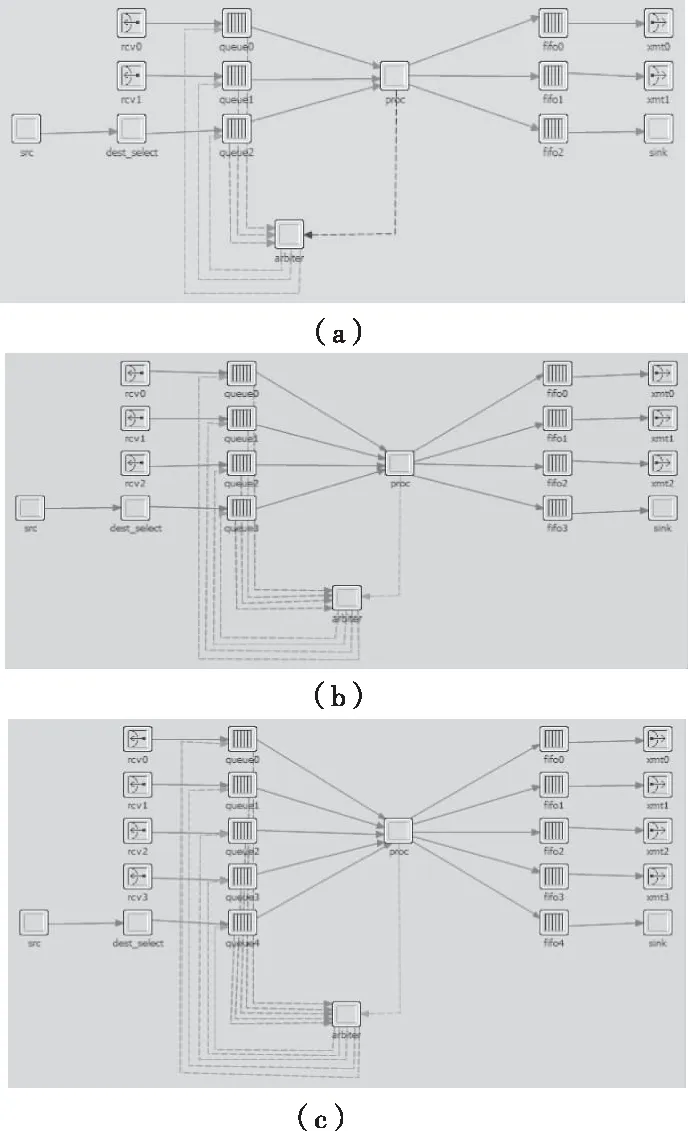
圖4 節點層模型圖
從各個方向傳輸到本節點的數據包,通過rcv模塊接收后傳輸到queue模塊進行存儲,數據包想要傳輸到proc模塊,需要經過arbiter模塊的仲裁。arbiter模塊收集來自queue模塊和proc模塊的統計量并進行分析,反饋給queue模塊一個統計量來控制queue模塊中的數據包傳輸到proc模塊中。proc模塊首先對數據包的中間地址進行更新,然后確定數據包的傳輸方向。之后將數據包傳輸到相應方向的fifo模塊中,fifo模塊再將數據包傳輸到xmt模塊發送出去。src模塊用來產生數據包,然后由dest_select模塊標定數據包的源地址和目的地址。sink模塊用來銷毀目的地址為本節點的數據包。
3.3 進程層
OPNET進程層通過構建狀態轉移圖和Proto-C語言編程,來模擬節點層各個模塊內部的工作狀態[14]。其中xmt模塊與rcv模塊分別為發信機模塊、接收機模塊,用來發送和接收數據包,無進程模型。src模塊使用OPNET提供的simple_source進程模型,fifo模塊使用acb_fifo進程模型,sink模塊使用sink進程模型。其余進程模型根據片上網絡路由方法的具體內容進行設計。
dest_select模塊的進程層模型如圖5所示。首先執行idle狀態的進入執行(Enter Executives)對本節點的地址進行設定,然后當有數據流到來時,觸發PK_ARRVL中斷,執行rout_pk()函數。將本節點的地址賦值給數據包源地址,并設置數據包的目的地址。

圖5 dest_select模塊進程層模型
queue模塊的進程層模型如圖6所示。queue模塊與fifo模塊都為隊列模塊,不同的是進入queue模塊的數據包必須接受到來自arbiter模塊的傳輸命令后,才能移出隊列。首先執行init狀態進行一系列的初始化設定和統計量的定義,然后跳轉到wait狀態進行等待。當有數據流到來時觸發ARRIVAL中斷,跳轉到insert狀態,將傳輸來的數據包插入到隊列中去。當來自arbiter模塊的統計流到來時觸發FLOW_CONTROL中斷,跳轉到svc_start狀態。當統計流中有arbiter模塊反饋來的傳輸命令時,產生一個自中斷。此時觸發SVC_COMPLETION中斷,跳轉到svc_compl狀態,使數據包強制移出隊列,傳輸到proc模塊。當模塊處于wait狀態時,會產生統計流給arbiter模塊。表示模塊空閑,可以傳送數據包。
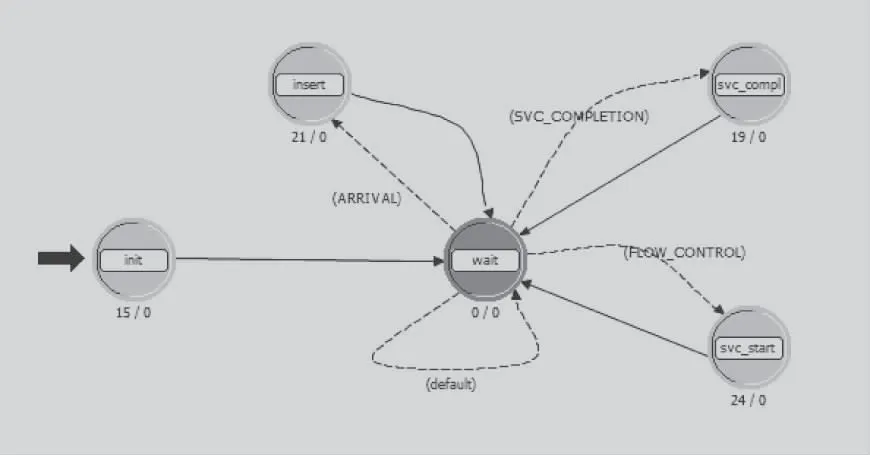
圖6 queue模塊進程層模型
proc模塊的進程層模型如圖7所示。首先執行init狀態的Enter Executives對本節點的地址進行設定,跳轉到idle狀態。當有數據流到來時,觸發PK_ARRVL中斷,執行rout_pk()函數。更新數據包的地址,并根據上述約束條件進行路徑選擇,確定數據包的傳輸方向。之后將數據包傳輸到相應方向的fifo模塊中,準備發送出去。當模型中無數據流的時候,會產生統計流給arbiter模塊。表示模塊空閑,可以接收數據包。
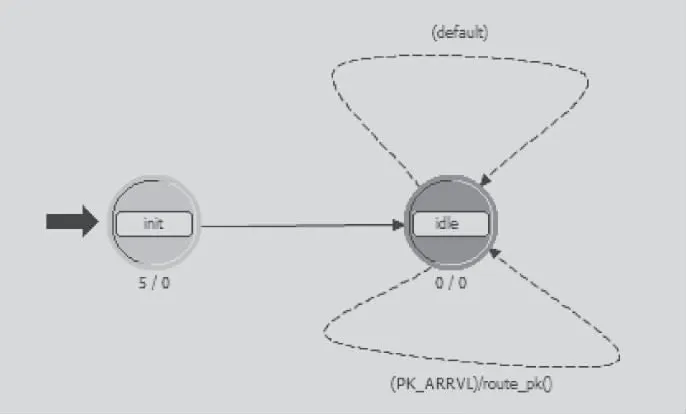
圖7 proc模塊進程層模型
arbiter模塊的進程層模型如圖8所示。Init狀態中對控制各個queue模塊的統計量進行設定,然后跳轉到idel狀態。當同時接收到某個queue模塊的空閑統計流和proc模塊的空閑統計流后,便會產生一個統計流傳送到相應的queue模塊中。若有多個queue模塊滿足條件,則隨機選擇一個queue模塊發送統計流。
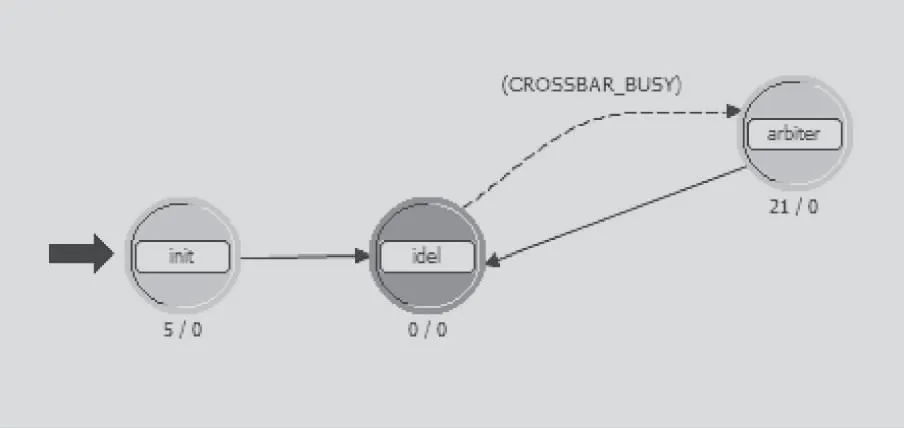
圖8 arbiter模塊進程層模型
4 仿真研究
經過以上三個層次的建模后,片上網絡模型已經搭建完成。基于該模型進行仿真,測試本模型數據傳輸的吞吐量和時延性能。比較網絡在正常狀態和繁忙狀態下的吞吐量,觀察在數據量較大的情況下,數據包選擇路徑的情況;將該路由算法與確定性路由算法的平均延時進行比較。在模型中設置7個節點產生數據包,相應的設置7個節點接收數據包。數據包具體的傳輸為node0到node10,node3到node9,node6到node12,node8到node1,node10到node4,node11到node2,node15到node7。
在節點層添加source interarrival time的參數值3和10,代表數據包產生的間隔分別為3s和10s。這樣來區分大量數據傳輸情況與正常數據傳輸情況。設置仿真時間長度為2000秒。實驗一的source interarrival time設置為3,實驗二的source interarrival time設置為10,其它條件都一樣。分別得出在數據包產生時間間隔為3s和10s時的各個鏈路的吞吐量如圖9和圖10所示。

圖9 時間間隔為3s的各鏈路吞吐量

圖10 時間間隔為10s的各鏈路吞吐量
根據兩個實驗的吞吐量可以得出兩個實驗中數據包的傳輸路徑,如圖11和圖12所示。

圖11 時間間隔為10s的路徑圖
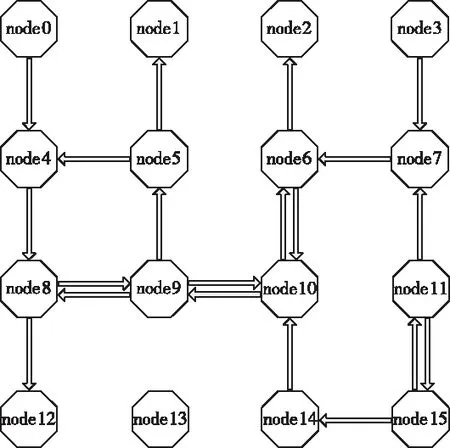
圖12 時間間隔為3s的路徑圖
可以看出,在包產生時間間隔為10秒的時候,節點node5,node6為熱點節點。當時間間隔變小,產生的數據量變多的時候,仿真模型會適當的避開熱點節點node5和node6,尋找新的路徑進行傳輸。表明該模型在遇到大量數據傳輸的時候,可以根據各節點的利用率,有效的選擇合適的路徑,避免了大量數據因選擇同一路徑而造成的擁堵。
對傳統的確定性路由算法進行建模,與本文所訴路由算法相比。在數據包傳輸的源地址與目的地址相同,產生數據包時間間隔為3s的條件下,查看仿真的端到端的平均延時,如圖13所示。起初的時候由于鏈路暢通延時很小,隨著數據包產生數量的增多,延時會迅速增加,之后產生包和銷毀包的數量達到動態平衡,故在曲線上顯示為一條直線。可以看出,與傳統的確定性路由相比,該路由算法平均延時小,傳輸速度快。

圖13 端到端平均延時
5 結語
本文提出了一種片上網絡路由算法,建立了一個基于4×4 2D-Mesh拓撲結構的片上網絡模型,并對該模型進行了網絡層、節點層、進程層的建模。對該模型在正常狀態和繁忙狀態下進行仿真,分別得出各個鏈路的吞吐量,在此基礎分析后得出數據包的傳輸路徑,進行比較。可以看出在大量數據包涌入網絡的時候,會根據各個節點的具體情況,選擇傳輸路徑。減少某些熱點節點的壓力,有效的避免了因數據量大而造成的延時增大或堵塞現象。與傳統的確定性路由相比,延時更小,效率更高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
