基于句法規則層次化分析的神經機器翻譯
2021-11-22 08:03:02張海玲邵玉斌杜慶治
小型微型計算機系統 2021年11期
張海玲,邵玉斌,楊 丹,龍 華,杜慶治
(昆明理工大學 信息工程與自動化學院,昆明 650500)
1 引 言
隨著信息時代的快速發展,自然語言處理(Natural Language Processing,NLP)的研究更加如火如荼.機器翻譯是借機器的力量將一種自然語言翻譯成另一種自然語言,是人工智能和自然語言處理領域的重要研究方向[1].機器翻譯研究一直在不斷的革新,從最初傳統的基于規則的機器翻譯,到基于統計的機器翻譯,再到目前主流的神經網絡機器翻譯(Neural Machine Translation,NMT).神經網絡機器翻譯是基于詞、短語和句子,使用一個非線性網絡找到語言之間的關系,實現自然語言之間的轉換[2],NMT因其翻譯性能突出,已成為當下工業界和學術界的研究熱點.目前在中文到英文的基于注意力機制的神經機器翻譯模型取得了令人矚目的成績,但仍然存在一些不足,其中一個很重要的原因是中文句式結構的復雜性和語義的多變性造成了翻譯效果不佳,如何利用語言學的知識增強翻譯模型的性能是一個值得深入的研究方向.
句子的構成總是依賴于句法結構,比如句子可分為主謂賓定狀補等成分,每種成分都會有對應的單詞,在句法的約束下這些成分才能構成完整、通順、流暢的句子.句法分析對語言是極其重要的.NMT在處理輸入源語言和輸出目標語言時,都采用序列化形式,往往忽略了語言中蘊含的句法結構知識[3].與其讓模型單獨依靠在訓練過程中學會隱型句式結構,不如通過更為顯性的方式將句法結構信息整合到模型中,強化翻譯模型.
本文針對NMT翻譯句式復雜的長句效果欠佳的問題,提出了一種基于句法規則層次化分析的神經機器翻譯方法,利用該句法層次化分析方式,對長度超過一定閾值的句子提取最長短語(Maximal-length Phrase,MP),再分別翻譯MP和句子框架,翻譯內容重新組合之后得到更高質量的譯文.該方法通過在句法分析上縮短句子長度、簡化句子結構的方式與神經機器翻譯學習能力強等優勢相結合,在一定程度上達到了增強NMT翻譯性能的目的.
2 相關研究
2.1 句法分析的應用
句法分析在自然語言處理中起著承上啟下的作用,其基本任務是在句子分詞之后,對輸入的文本進行分析得到句子的句法結構,識別出高層次的結構單元來簡化句子的描述,確定句子所包含的句法單位之間的依存關系,將成分使用樹狀或依存關系的形式表示出來.句法分析方法主要有成分句法分析、依存句法分析、深層文法句法分析等.句法分析應用較廣泛,如機器翻譯、文本校對、情感分析、信息抽取等.
在機器翻譯任務中,由于語種的特點,特別是漢語不具有諸如英語、法語等其他語言那樣嚴格意義的形態變化[4,5],漢語句式和語義復雜性造成翻譯效果不佳,這時句法分析模型就顯得尤為重要.機器翻譯大都是詞語級的模型,所包含的句法信息較少.句法是重要的關于句子結構的理論,將詞語級的翻譯模型擴展至基于句法的翻譯模型,是神經機器翻譯模型架構創新的重要體現.
將語言學知識融入機器翻譯,是眾多研究學者們一直在深入的任務.宋鼎新等人提出了一種融合句法短語的漢英統計機器翻譯方法[6],將得到的句法短語對與基于短語的統計機器翻譯系統相融合,使用加入短語表和使用新特征的方式證明句法短語對短語翻譯模型的改進作用,結果表明,在不同規模的訓練語料環境下,BLEU值分別提高0.56和0.62.盡管融合了句法短語知識,但統計機器翻譯的效果不如神經機器翻譯好.汪琪等人提出一種融入依存關聯指導的神經機器翻譯方法[7],通過在源端進行關聯性建模,融入依存關聯指導,以此加強源端單詞之間的關聯性,提高機器翻譯的性能,該方法僅考慮源端語句之間直接存在的依存信息,不考慮存在間接依存關聯的其他節點,并且不區分當前詞是與其有依存關系的子節點還是父節點.張學強等人提出一種基于最長名詞短語分治策略的神經機器翻譯方法[8],該方法識別并抽取句子中的最長名詞短語,利用分治法的思想進行翻譯,與基線系統相比BLEU值有一定的提升,緩解了神經機器翻譯對句子長度敏感的問題.但是該方法僅針對名詞短語結構,沒有考慮到其他類型的短語,結構比較單一,還需在句法上進一步擴充.
2.2 神經機器翻譯
機器翻譯的思想,最早提出的是基于規則的機器翻譯(Rule-based Machine Translation,RBMT).隨著統計學的發展,研究者通過對雙語文本語料庫的分析來生成翻譯結果,稱為統計機器翻譯(Statistical machine translation,SMT).2003年,Bengio等人提出了基于神經網絡的語言模型,改善了傳統 SMT 模型的數據稀疏性問題[9],為未來神經網絡在機器翻譯上的應用奠定了基礎.2013 年,Nal Kalchbrenner 和 Phil Blunsom 提出了端到端的“編碼器-解碼器”機器翻譯模型[10],該模型使用卷積神經網絡將源文本編碼成一個連續向量,然后再使用循環神經網絡作為解碼器將該狀態向量轉換成目標語言.使用深度學習方法獲取語言之間的映射關系,NMT 的非線性映射不同于線性的 SMT 模型,NMT使用了連接編碼器和解碼器的狀態向量來描述語義的等價關系.此外,循環神經網絡理論上能得到無限長句子的信息,從而解決長距離重新排序(Long Distance Reordering)問題[11].但是實際上梯度爆炸或消失問題[12]讓循環神經網絡難以處理長距依存(long distance dependency).2014 年,Sutskever I和Cho K等人提出了序列到序列的模型,可以將循環神經網絡用于編碼器和解碼器[13],并且還為NMT引入了長短時記憶(Long Short-Term Memory,LSTM),梯度爆炸或消失問題得到了控制,從而讓模型可以更好地捕獲句子中的長距依存.2017年Vaswani A等人提出了完全基于注意力的Transformer神經機器翻譯模型[14],更好地解決長距離依賴,翻譯性能獲得大幅度提升.
Transformer模型完全使用注意力機制對源端的目標端序列建模[15],它的主要特點在于僅通過自注意力機制計算輸入x=[x1,x2,x3,…,xm]和輸出y=[y1,y2,y3,…,ym]的表示,實現端到端的神經機器翻譯.該模型將句子中的每個詞和所有詞進行注意力計算,學習句子內部的依賴關系,捕獲句子的內部結構.其較少的訓練時間以及更好的翻譯效果使Transformer成為目前常用的模型.模型的整體結構如圖1所示.
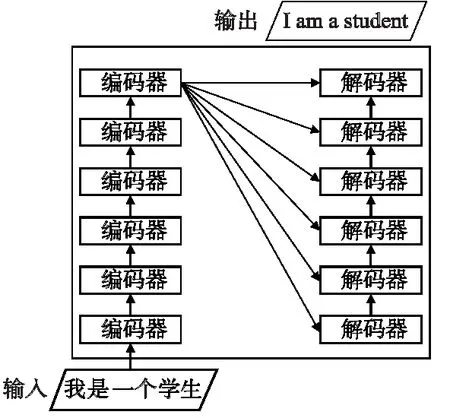
圖1 Transformer整體結構圖
Transformer模型分為編碼器和解碼器兩部分,都是多層網絡結構,其內部結構如圖2所示.
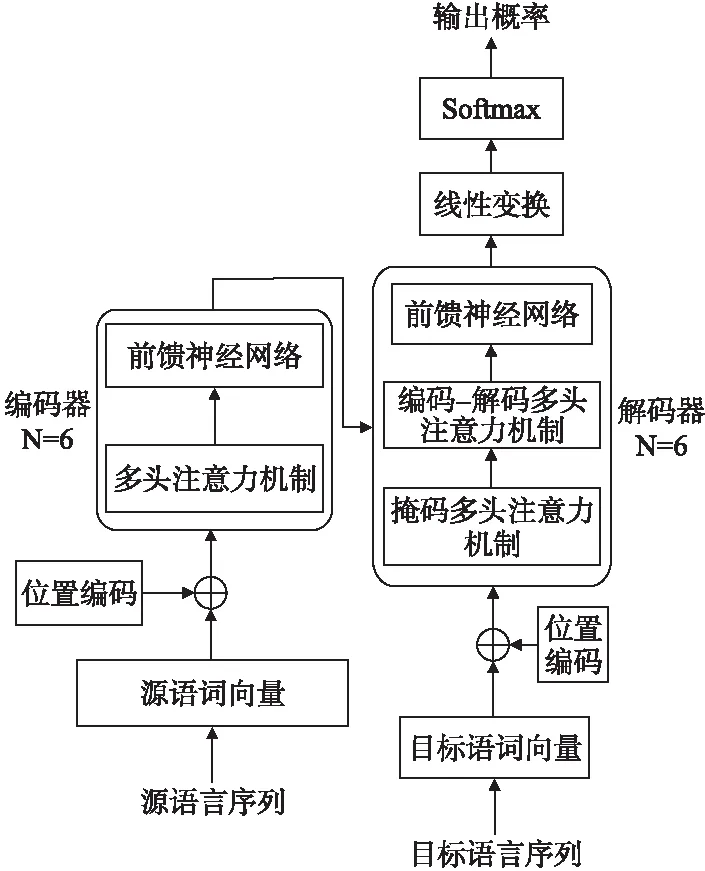
圖2 Transformer內部結構圖
編碼端由N個相同層組成,每一層有兩個子層,第1個子層是多頭注意力機制,第2個子層是前饋神經網絡.解碼端同樣也是由N個相同層組成,每一層有3個子層,第1個子層是掩碼多頭自注意力機制,第2個子層是編碼-解碼多頭注意力機制,最后一個子層是前饋神經網絡.
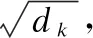
(1)
多頭注意力是指采用h個注意力操作表示輸入信息,將各個注意頭的級聯輸出乘以權重矩陣計算所得.如式(2)所示.
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
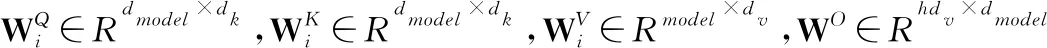
FFN(x)=max(0,xW1+b1)W2+b2
(3)
由于attention不包含位置信息,所以需要根據句子中詞的位置信息給詞嵌入添加位置編碼向量.為了讓模型能夠學習到相對位置信息,使用位置編碼生成固定位置表示,如式(4)所示.
(4)
已知三角函數公式如式(5)所示.

(5)
因此,PEpos+k可以表明PEpos的線性變換,如式(6)所示.
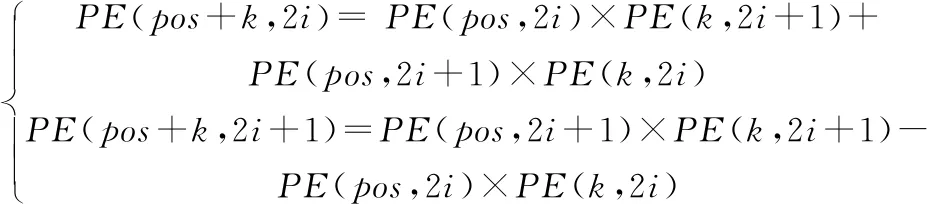
(6)
盡管目前主流的基于注意力機制的神經機器翻譯模型能有效捕獲長距離依賴,提升翻譯效果.但是中文句式結構的復雜性和語義的多變性對模型而言具有一定的挑戰性,這時利用語言學的知識增強翻譯性能就顯得至關重要.
3 基于句法規則層次化分析的神經機器翻譯
近年來,神經機器翻譯飛速發展取得了令人矚目的成就,但目前的方法主要是從語料數據中自動學習翻譯知識,沒有在翻譯過程中充分融入語言學知識[16].除此之外,對于不同長度的句子,神經機器翻譯都使用固定維度的向量去表示,從而造成結構復雜的長句翻譯效果不佳.
針對以上問題,本文提出了基于句法規則層次化分析的神經機器翻譯,采用“句法分析——翻譯短語MP和句子框架——譯文重組”的方式進行.該方法旨在將復雜長句轉化為一個或多個攜帶子句信息的最長短語和一個維系主要信息的主干句子框架,分別翻譯之后重組譯句,從而提升翻譯效果.
3.1 句法規則層次化分析
句子s=[w1|t1,w2|t2,w3|t3,…,wi-1|ti-1,wi|ti,wi+1|ti+1,…,wn|tn],其中,S表示由n個詞元有序組合而成的句子.字符wi表示S的第i個詞元,詞元wi的詞性為ti.按照句法合成規則,將句子S通過迭代合成的方式得到最優結果.
3.1.1 句法規則庫的構建
對于句法規則的制定,采用計算所漢語詞性標記集[17],其共計99個(22個第1類,66個第2類,11個第3類).為了在規則制定中能夠實現有效性及合理性,即采用詞性標記集中的第1類標記作為規則需要.
根據對漢語句子組合信息的分析以及現代漢語語法研究對漢語句法的解讀[18,19],通過提煉出的詞性標記集和語言規則相結合的方式,實現句法合成規則庫的構建,如表1所示.
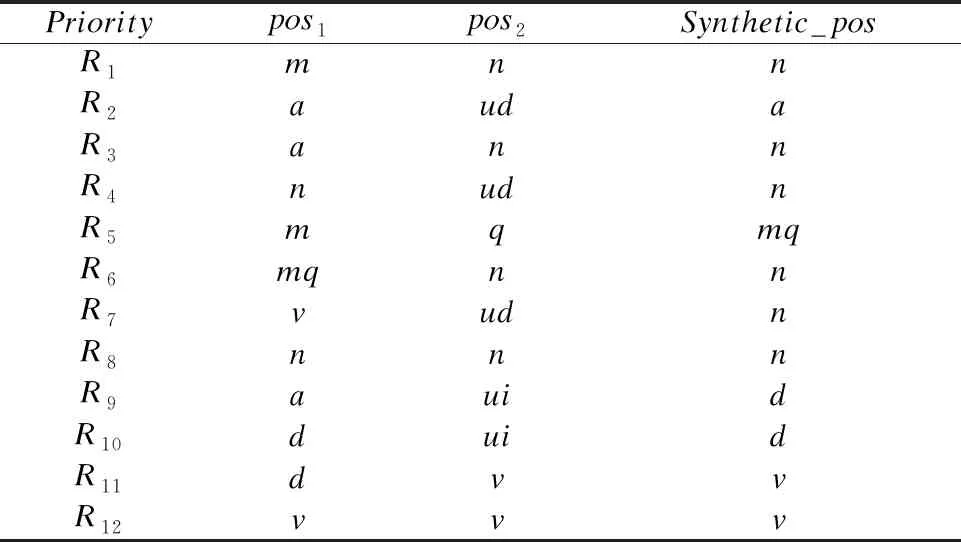
表1 句法合成規則庫
說明:
1)對標注好詞性之后的語料,進行詞性預處理.例如,將“nr”、“nsf”等第2類第3類詞性統一記為一類詞性“n”;
2)表1中第1列代表優先級,即每次迭代合成的順序;
3)表1中第2列pos1和第3列pos2表示句中兩相鄰詞分別對應的詞性;
4)句子迭代過程通過規則Ri(pos1⊕pos2→synthetic_pos)實現兩相鄰詞元結合得到第4列新詞性.
據表1規則庫,實現由pos1,pos2匹配合成得到Synthetic_pos的具體流程如圖3所示.其中,POS_t是由句子S=[w1w2w3…wi-1wiwi+1…wn]獲取的詞性序列[w1_t,w2_t,…,wi_t,…,wn_t],對該序列從右至左依次獲取,規則庫按照自頂向下的方式對連續詞元的詞性進行匹配,合成新的hcc_t詞性,再對原詞性序列進行替換,直至遍歷完POS_t.
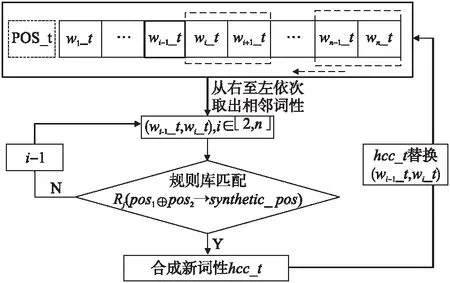
圖3 規則合成示意圖
3.1.2 層次化解析
在層次化語句分析過程中,利用分詞和詞性標注模型對中文句子進行處理,詞與詞之間用空格分開,每個詞元與其詞性之間用“|”分隔.例如,句子s=[中國|n人民|n政府|n給|v貧困|a的|ud農村|n家庭|n提供|v了|ul一筆|m現金|n補助|n]的層次化解析過程如圖4所示.

圖4 層次化解析示例
將整個層次化語句解析過程轉化為樹形結構格式,其可視化結果如圖5所示.
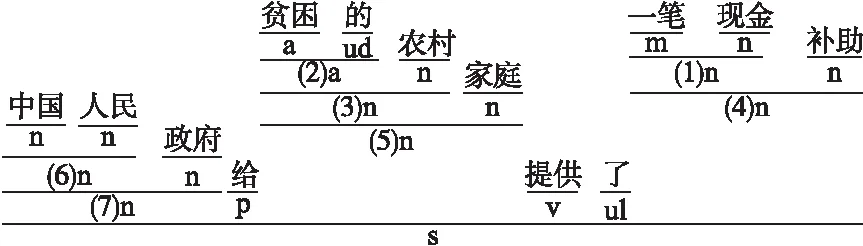
圖5 語句解析可視化示例
3.1.3 提取短語MP
句法規則層次化分析,可以對中文句子進行短語結構的識別.該方法的優勢在于可以隨時調整規則庫文件,從而更新得到最優合成方式,進一步提取出完整且符合要求的高質量最長短語MP.
該方法主要針對結構復雜的長句,考慮到短句子的譯文質量較好,所以只對長度超過一定閾值(L=20)且可以進行句法分析的句子進行短語提取.由于較短的MP對縮短句子長度,降低句子結構復雜度的影響較小,提取過程中過濾掉長度小于3的短語,以及需要過濾掉符號標點等特殊字符.
提取短語MP時,本文采用兩種方式在句子框架中保留特殊標記.
方法1:用MPi(i=1,2,3,…)代替最長短語本身保留在句子框架中,從而保證了短語和句子框架的對齊關系.
方法2:用最長短語的核心詞代替最長短語本身保留在句子框架中,從而保證了語言的流暢度和語義的完整性.這兩種方式都能縮減句式結構上的歧義帶來的消極影響,降低句子的復雜度,縮短翻譯句子的長度.
3.2 翻譯MP和句子框架
利用句法規則層次化分析算法,從同源數據語料中獲取得到最長短語,使用GIZA++開源工具訓練得到中英MP對齊語料.訓練神經機器翻譯模型可以采用如下方式.
Model-Ⅰ:將MP語料加入到原訓練語料中,擴展訓練語料,通過訓練得到既可以翻譯MP又可以翻譯句子的神經機器翻譯模型.
Model-Ⅱ:MP語料和原訓練語料分別訓練,得到兩個有針對性的翻譯模型:短語翻譯模型和句子翻譯模型.
3.3 譯文重組
將通過翻譯模型得到的MP譯文和句子框架譯文進行重新組合,即把MP譯文替換到句子框架譯文中的相應位置,從而得到最終譯文.由于提取短語時,在句子框架中保留特殊標記使用了兩種不同的方式,則重組過程分別為:1)使用第i個MP譯文替換句子框架中的特殊標記MPi;2)找到句子框架譯文與MP譯文關聯度最高的詞,該詞即為核心詞譯文,再用MP譯文替換句子框架的核心詞譯文.
3.4 整體流程描述
基于分治法的思想,將長句子翻譯分解為若干個規模較小的短句進行翻譯.即通過句法分析,分解得到短語部分和句子框架,再分別進行翻譯,最后重組譯文.本文采用了“句法分析——翻譯短語MP和句子框架——譯文重組”的方式,增加了語言學的知識,從而實現神經機器翻譯性能的提升.整體翻譯的流程如圖6所示.
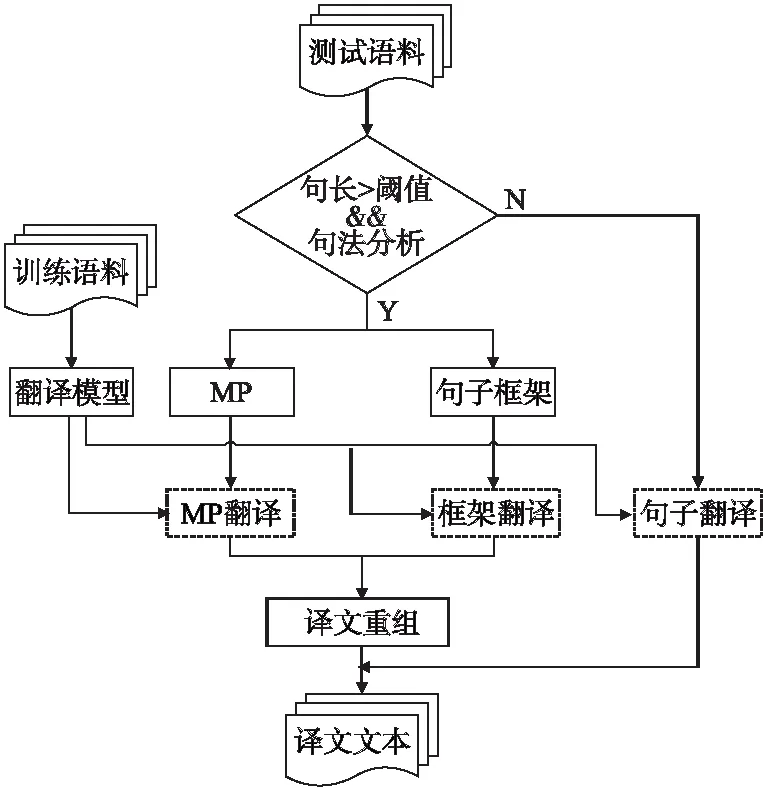
圖6 整體翻譯流程圖
據翻譯流程,表2給出了具體句子的翻譯示例.

表2 句子翻譯示例
4 實 驗
4.1 語料設置
本文實驗語料來源于全國機器翻譯研討會(CWMT)的中英雙語平行語料.其中,訓練數據集共900萬句,對原始訓練數據進行清洗、去重處理,實驗過程只隨機抽取600000句對語料作為訓練數據集.開發數據集和測試數據集各2000句對.
雙語MP數據集按照3.1.3節所述方式進行構建.本文隨機從訓練數據集中抽取100000句對中英雙語平行語料,然后利用句法規則層次化分析的方法提取短語,使用GIZA++開源工具訓練得到中英對齊MP語料359842句對,對該語料進行數據清洗,統一格式,刪除亂碼,統一全半角字符,去重等處理后得到162215句對中英對齊MP語料.實驗語料的相關信息如表3所示.
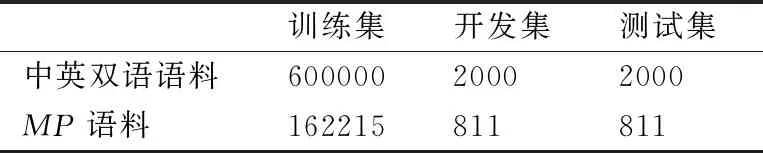
表3 實驗語料信息
實驗開發數據集和測試數據集語料信息如表4所示.

表4 驗證/測試語料信息
對于測試語料,同樣按照句法規則層次化分析的方式進行處理,測試語料句子的平均長度由 26.51個詞降低到句子框架的12.73個詞,極大程度上縮減了翻譯句子的長度.
4.2 系統設置
本文的翻譯系統,建立在基于完全注意力機制的Transformer神經機器翻譯模型上,采用的深度學習框架tensorflow,以python作為開發語言,操作系統為Linux,使用RTX2080ti X4訓練模型.表5給出實驗中神經網絡的主要參數設置和部分說明.
表5中,由于詞表大小對神經機器翻譯的影響較大,詞表不能包含所有的詞語,本文根據詞出現的頻率排序后獲取前32000個得到詞表,此表包含、、表示句子的開頭,表示句子的結束,未出現在詞表的詞統一用
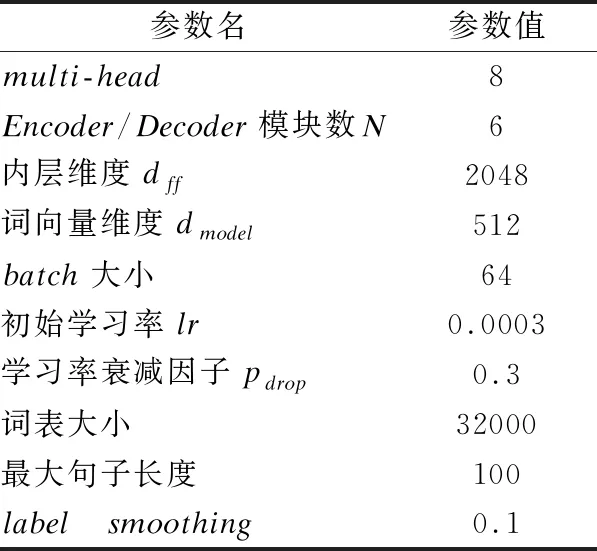
表5 模型參數設置
在訓練過程中,模型設置運行20輪,使用目前工作性能比較優秀的Adam優化器[20]進行參數更新,使用labelsmoothing平滑方式防止損失函數過擬合.
實驗采用目前機器翻譯研究中比較常用的BLEU(Bilingual Evaluation Understudy)[21]自動評價方法分析所述機器翻譯系統的性能,均使用大小寫不敏感的BLEU衡量測試集的翻譯質量.
4.3 實驗結果及分析
4.3.1 句法分析算法識別效果
本文采用基于句法規則層次化分析的神經機器翻譯方法來實現翻譯性能的提升,因此,通過句法分析方式能否成功提取MP就顯得尤為重要.本文從成功進行句法分析的句子中隨機抽取200句,對句中的MP進行人工標注,通過句法分析模型識別結果與人工標注結果對比,得到該句法分析模型識別MP的準確率、召回率和F值.如表6所示.

表6 MP識別結果
表6中,MP識別準確率達到了80.57%,表明該句法分析模型的加入不會對后續的句子翻譯過程造成消極影響.
4.3.2 翻譯性能分析
實驗以Transformer模型作為基準系統.按照2.2節所述方式得到兩種翻譯模型,Model-Ⅰ:MP語料加入到原語料得到既可以翻譯MP又可以翻譯句子的神經機器翻譯模型;Model-Ⅱ:MP語料和原語料分別訓練得到短語翻譯模型和句子翻譯模型.按照不同的標識方式進行譯文質量對比.結果如表7所示.

表7 翻譯結果對比
由表7可知,相比較于基線系統,Model-Ⅰ和Model-Ⅱ的翻譯性能都獲得了一定程度的提升.其中,Model-Ⅰ的MPi標識方式提升了0.21個BLEU值,保留MP核心詞方式提升了0.62個BLEU值;Model-Ⅱ的MPi標識方式提升了0.40個BLEU值,保留MP核心詞方式提升了0.95個BLEU值.
Model-Ⅱ的訓練語料分布較為均勻,訓練出的模型效果較好,即Model-Ⅱ翻譯性能優于Model-Ⅰ;在翻譯句子中保留MP核心詞的方式保證了句子的流暢性和語義的完整性,所以其翻譯性能優于MPi標識.
4.3.3 不同句長翻譯分析
本文提出的基于句法規則層次化分析的神經機器翻譯模型,主要針對長句的翻譯.為驗證本文模型的有效性,對測試集的句子按照不同長度劃分后進行翻譯實驗.以性能較好的Model-Ⅱ作為對比實驗.翻譯結果如圖7所示,橫坐標表示不同句長的分布情況,縱坐標表示譯文質量BLEU值.
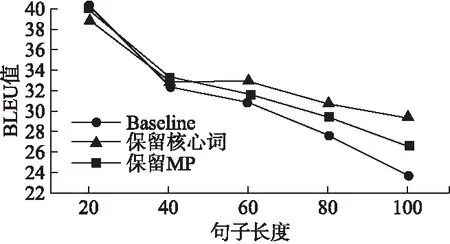
圖7 不同句長對應譯文的BLEU 值
由圖7的結果表明,總體譯文質量隨著句子長度的增加而逐漸降低.在句長小于20的句子翻譯中,Model-Ⅱ的譯文BLEU值相較于Baseline翻譯模型不但沒有提高,反而還有小幅度降低,這主要是由于在句法分析過程中造成了一定的損失,例如MP提取錯誤對翻譯造成了一定的干擾;句長在20-40區間內,Model-Ⅱ的譯文BLEU值比Baseline有小幅提升,之后隨著句子長度的增加,基于句法規則層次化分析的神經機器翻譯模型的翻譯效果較好,且保留了MP核心詞的方式的翻譯性能較優.
5 結束語
本文針對目前機器翻譯模型在翻譯復雜長句時效果不佳的問題,提出了一種基于句法規則層次化分析的神經機器翻譯方法.利用句法規則層次化分析算法從長句中提取短語MP,進一步分別翻譯MP和句子框架,最后對譯文重新組合.通過在一定程度上降低句子復雜度的方式來提升翻譯性能.實驗結果表明,相比于基線系統,BLEU值整體提高了0.95,并且復雜長句的翻譯優勢更加明顯,該方法給神經機器翻譯帶來了積極有效的影響,在利用語言學知識增強機器翻譯性能的研究中具有較好的參考價值.
實驗主要是利用了中文的語言學知識,來實現中英翻譯性能的提升,因此下一步可以考慮進行將本文方法遷移到中文到其他語言的神經機器翻譯實驗.由于中文本身的復雜性,語義多變性等特點,句法規則層次化分析提取MP的過程,會在翻譯時對句子語義完整性造成一定的損失,后續還應對目前方法做進一步擴充和完善.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
Coco薇(2017年11期)2018-01-03 20:59:57
