邊緣計算使能星地協同網絡下的服務部署機制
2021-11-28 01:30:07盧華段雪飛李斌
中興通訊技術 2021年3期
盧華 段雪飛 李斌



摘要:在移動邊緣計算(MEC)與星地協同網絡(STIN)融合的網絡架構中,針對衛星網絡和邊緣計算對時延與資源敏感的特點,以最大化用戶服務質量(QoS)為目標,提出基于強化學習的深度Q網絡(DQN)算法部署機制。將部署問題描述為一個馬爾可夫決策過程(MDP),并把衛星節點的狀態和部署行為分別建模為DQN中的狀態和動作。通過衛星的計算資源與衛星和用戶的通信時延給出獎勵值,在神經網絡中訓練以優化部署行為,進而實現最優部署策略,并對提出的算法做仿真。與其他算法對比的結果表明,在相同的優化目標條件下,DQN算法有較好的性能。
關鍵詞:邊緣計算;服務部署;強化學習
Abstract: In the network architecture of mobile edge computing (MEC) and satellite terrestrial integrated network (STIN), the satellite network and edge computing are sensitive to delay and resources. To maximize users quality of service (QoS), a deployment mechanism based on the reinforcement learning deep Q network (DQN) algorithm is proposed. The deployment problem is described as a Markov Decision Process (MDP). The state and deployment behavior of the satellite nodes are modelled as the state and action in the DQN. The reward value is given by the satellite computing resources and the communication delay between the satellite and the user. Training in the neural network to optimize the deployment behavior achieves the optimal deployment strategy. The proposed algorithm is simulated and compared with other algorithms. The result shows that under the same optimization target conditions, the DQN algorithm has better performance.
Keywords: edge computing; service deployment; reinforcement learning
近年來,互聯網與通信技術都取得了長足進步。大數據、云計算等新興技術已經得到廣泛運用并成為當前的基礎性技術[1]。受益于5G的大規模使用,物聯網(IoT)、虛擬現實(VR)/增強現實(AR)/混合現實(MR)、高分辨率(4K/8K)視頻傳輸得到了進一步推廣。然而,以車聯網(IoV)、遠程醫療、高幀率游戲等為代表的要求響應速度快、時延超低、占用帶寬較大的應用,對現有網絡體系架構提出很大的挑戰。雖然5G的應用可以緩解部分需求,但是用戶與云計算中心通信產生的時延,以及海量數據傳輸對帶寬的占用,與云計算技術本身都是矛盾的。為了解決這些問題,我們需要在數據中心之外,讓計算、存儲、網絡延展到互聯網的邊緣,甚至到每個家庭的互聯網網關上,使服務更加靠近用戶。這種技術就是邊緣計算[2-3]。星地協同網絡雖然有著很好的發展前景,但也面臨著和上述云計算類似的高數據速率、低通信時延等挑戰。移動邊緣計算(MEC)技術的引入可以更好地保障用戶服務質量(QoS)。
關于邊緣計算中服務部署問題的研究有很多。文獻[4]將邊緣計算系統中的服務部署建模為一個多階段隨機規劃問題,設計了一個樣本平均近似(SAA)方法以估計多階段模型中資源函數的期望值,并提出貪心算法來解決基于SAA的并行算法中每個階段都需要解決的整數優化問題。針對把服務完全部署到本地的情況,文獻[5]將問題建模為非線性整數規劃問題,并采用元啟發式算法求出近似解。文獻[6]將服務部署問題建模為馬爾可夫決策過程(MDP),并設計了一種在線算法,同時證明該算法是成本最優的。文獻[7]同樣將服務部署問題建模為MDP,但采用強化學習中的Dueling-DQN算法(一種改進的DQN算法)進行求解。
不同部署問題的解決方案雖然有很大不同,但基本可以歸納為傳統算法和基于學習的方法。傳統算法一般將問題描述為規劃問題或優化問題,但通常由于問題的復雜性以及多目標約束的存在而變為非確定性多項式(NP)問題,使求解變得困難。而部署問題能夠容易地被建模為MDP過程,可采用強化學習中的QLearning或DQN等算法進行求解。
1服務部署模型與算法設計
1.1服務部署模型設計
這里,我們首先對研究問題做一些說明和假設:
(1)對于每個衛星,除運行軌跡不同外,其他完全相同;
(2)用戶請求的服務相同;
(3)用戶與衛星的距離用時延來描述;
(4)衛星的可用計算能力與中央處理器(CPU)、內存占用率成反比;
(5)衛星的CPU和內存消耗是線性的;
(6)服務在節點上并行計算;(7)衛星計算能力存在上限和下限。
為了使用強化學習算法解決服務部署問題,我們需要將其建模為MDP,具體過程如下:

公式(1)中,E表示邊緣節點集合,Ue表示服務部署在節點e上的用戶集合,proce表示在節點e上處理服務需要的時間(根據假設,相同節點上的proc相同),delayu,e表示用戶u與節點e的通信時延。需要說明的是,這里的delay不僅代表時延,還代表用戶與衛星的物理距離。因此,我們可將時延進行適當的放大,以擴大其在問題中的影響。
MDP是一個四元組

在本問題中,MDP中的動作是把服務部署在某個邊緣節點上。我們可以規定服務的部署順序。對于某個狀態集si而言,要部署的服務就是確定的。此時,動作數量與邊緣節點數量一致。本問題的MDP在狀態集si中執行一個動作a,隨后進入狀態集si + 1。
獎勵是決定算法最終效果的核心。在使用簡化狀態集時,我們顯然不能為狀態集si中的所有狀態設置同一個獎勵值。單純地為簡化狀態集中的每一個狀態而定義一個獎勵值也是不合理的。因此,在設置獎勵值時,我們要按具體狀態集來處理。
1.2基于服務部署模型的算法設計
當利用強化學習來求解MDP模型時,我們可以采用Q-Learning或DQN算法。在本問題中,即使我們采用簡化狀態集,隨著服務數量的增加,其規模也呈指數級增長,此時不宜采用Q-Learning算法進行求解。因此,本文中我們采用DQN算法。
算法的模型如圖1所示。操作環境輸入選擇的動作,并執行該動作,隨后進入下一狀態,同時反饋這一步的獎勵值和是否到達終止態等信息。這些信息會形成一條記錄被存入經驗回放區。當經驗回放區存儲一定數量的記錄后,神經網絡會從中隨機選取一些記錄來進行訓練,并更新相應的網絡參數,選擇基于當前網絡參數選出的價值最大的動作來讓環境執行。新的記錄生成后會被繼續存入經驗回放區。當經驗回放區的數據足夠多時,新記錄將逐漸代替舊記錄,以便于那些之前使用價值不大的的記錄不會再被學習。本文中,我們使用的神經網絡有兩個隱藏層。神經網絡通過反向傳播當前Q網絡與目標Q網絡的差值來優化參數。
獎勵值的計算方法可參照公式(2)。假設節點在最佳性能時處理一個服務消耗的時間為t0,則基本時間tbasic是所有已部署服務t0的簡單求和,如公式(3)所示:
公式(5)中,Rj代表當前獎勵值。γ為衰減因子(0≤γ≤1),表示后續獎勵值對當前Q值的影響。Q是目標Q網絡,ф(Sj)表示下一狀態的特征向量,Aj表示下一步動作,w為Q網絡中的狀態價值函數。
2實驗仿真與結果分析
2.1實驗環境及參數
實驗中,我們假定邊緣節點數量為9個,用戶(服務)數量n為20~50個,服務的最短執行時間t0為60 s。為了簡化問題,我們假設每個服務都會消耗節點10%的CPU。同時,節點CPU空閑率的下限為10%,即一個節點最多可以同時為9個用戶提供服務。如果部署服務多于9個就需要排隊等候。顯然,在一個節點部署過多服務,不僅會導致每個服務的計算時間變長,還會使需要等待的節點產生更多不必要的等待時延。在上文假設的服務數量下,這顯然不是最優策略。強化學習過程中的隨機選擇動作會導致這些策略被執行和學習,因此,我們要在算法中避免這種情況的發生,即如果采取某個動作后會進入需要排隊的狀態,就令這一動作無效且下一狀態仍為原狀態,同時給這次動作一個很低的獎勵值,以避免再次作出同樣的選擇。
用戶與衛星的時延是一個難以準確評估的參數。本文1.1節已經指出,時延可代表用戶與衛星的物理距離。為了在仿真中模擬現實情況,我們需要對其進行適當放大。經過調試,我們認為,時延分布在1~20 s之間是比較合理的。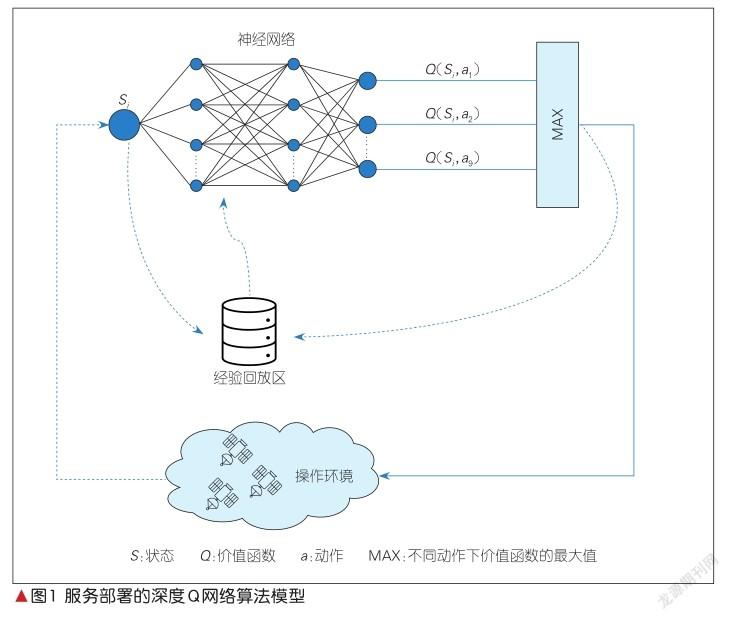
此外,本文同時設計了隨機部署算法、最短時延貪心算法、均勻部署算法3個參考算法[8]。我們分析了在不同服務數量條件下4個算法的性能。為了控制無關變量,這3個參考算法中每一個節點部署服務的數量均不會超過9個,且滿足如下條件:
(1)對于隨機部署算法,每次部署隨機選擇節點;
(2)對于最短時延貪心算法,每次部署選擇時延最小的節點;
(3)對于均勻部署算法,將服務平均部署到節點中。
2.2結果分析
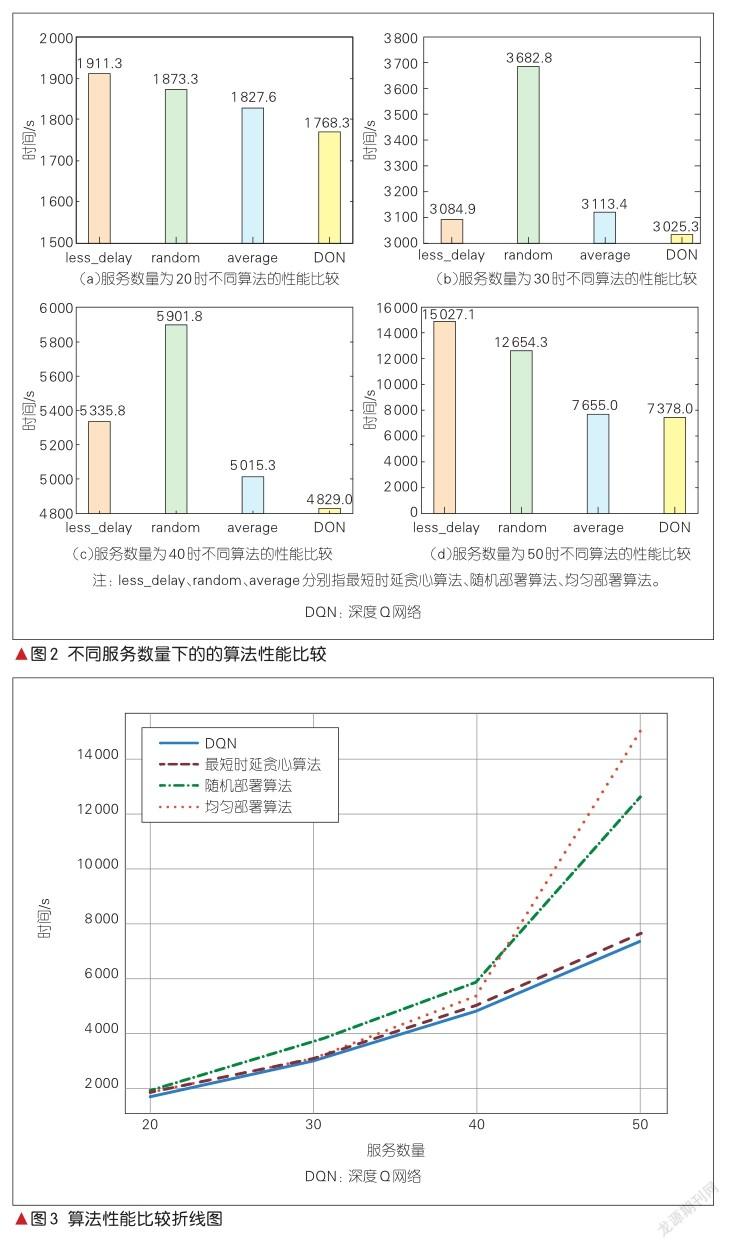
我們選擇服務數量n分別為20、30、40和50,并進行測試比較。得到的柱狀圖結果如圖2所示。其中,縱坐標表示每種算法處理時延與傳輸時延之和。為了直觀地顯示不同情況的算法結果,我們對縱坐標的范圍進行適當調整。圖3是將柱狀圖繪制成折線圖的結果。
由圖2和圖3可知,在不同服務數量的情況下,DQN算法的性能均優于另外3種算法。由于對問題作出的一系列假設使最優部署方案接近于均勻部署,因此仿真中的平均部署算法性能與DQN較為接近。在實際問題中,服務對CPU的影響沒有那么劇烈,平均部署算法與DQN的真實差距要大于仿真中的差距。此外,在算法設計中,時延對結果的影響小于節點計算能力對結果的影響。因此,基于時延的貪婪算法的性能并不出色,甚至在某些情況下要比隨機算法性能更低。
3結束語
本文中,我們圍繞邊緣計算使能星地協同網絡中的服務部署問題展開研究,將服務部署問題建模為MDP過程,用DQN算法對模型進行求解,并提出詳細的算法步驟。我們通過設定基本參數,對算法進行仿真,并將DQN算法與隨機部署算法、時延優先貪婪算法、平均部署算法這3個參考算法進行性能比較,發現DQN算法是解決邊緣計算服務部署問題的一種有效算法。
參考文獻
[1] ZHAO J J, XU C Z, MENG T H. Big data-driven residents travel mode choice: a research overview [J]. ZTE communications, 2019, 17(3): 9-14. DOI: 10.12142/ZTECOM.201903003
[2]丁春濤,曹建農,楊磊,等.邊緣計算綜述:應用、現狀及挑戰[J].中興通訊技術, 2019, 25(3): 2-7. DOI: 10.12142/ZTETJ.201903001
[3]秦永彬,韓蒙,楊清亮.邊緣計算中數據驅動的智能應用:前景與挑戰[J].中興通訊技術, 2019,25(3):68-76.DOI:10.12142/ ZTETJ.201903010
[4] BADRI H, BAHREINI T, GROSU D, et al. A sample average approximation-based parallel algorithm for application placement in edge computing systems [C]//2018 IEEE InternationalConferenceonCloudEngineering(IC2E). Orlando, USA: IEEE, 2018:198-203
[5] CHENG Z X, LI P, WANG J B, et al. Just-intime code offloading for wearable computing[J]. IEEE transactions on emerging topics in computing, 2015, 3(1): 74-83
[6] WANG S Q, URGAONKAR R, ZAFER M, et al. Dynamic service migration in mobile edge computing based on Markov decision process[EB/OL]. [2021-04-06]. https://arxiv. org/abs/ 1506.05261
[7] ZHAI Y L, BAO T H, ZHU L H, et al. Toward reinforcement-learning-basedservicedeployment of 5G mobile edge computing with request-aware scheduling [J]. IEEE wireless communications, 2020, 27(1): 84-91. DOI: 10.1109/MWC.001.1900298
[8]嚴蔚敏,吳偉民.數據結構: C語言版[M].北京:清華大學出版社, 1997
作者簡介
盧華,廣東省新一代通信與網絡創新研究院網絡技術創新中心主任;研究方向包括5 G核心網、邊緣計算、新型網絡架構、軟件定義網絡、P 4可編程、虛擬化等。
段雪飛,廣東省新一代通信與網絡創新研究院網絡技術創新中心核心網部門負責人;研究方向包括5 G核心網架構、6 G網絡架構、空天一體化通信系統等。
李斌,中興通訊股份有限公司系統架構師;主要從事IP網絡相關技術的研究;曾獲國家科學技術進步獎二等獎。
