基于知識圖譜的數字檔案服務模式探究
2021-12-01 09:51:27熊回香嚴舞月
知識管理論壇 2021年4期
熊回香 嚴舞月

摘要:[目的/意義]針對當前數字檔案服務質量智能化程度不足、服務內容單一等短板,設想構建數字檔案知識圖譜整體架構,達到數字檔案大數據的統計分析、數字檔案資源集成優化以及數字檔案整體服務水平提升的目的。[方法/過程]通過收集文獻分析數字檔案館的服務缺陷,體驗式調研各省市數字檔案館網頁服務水平,匯總各檔案館目前服務模式的不足,完善數字檔案知識圖譜架構流程,最終以流程圖的形式展示。[結果/結論] 知識圖譜能夠將多種類型的數字檔案文本轉化為計算機可理解的數據,提高計算機智能識別水平,同時圖譜所具備的動態時序性和針對性能夠按照時間節點提高檔案整合程度,同時基于用戶瀏覽檢索痕跡更新用戶數據,提升服務質量,并增強數字檔案館之間的合作交流以達到整合資源的效果,為更好地優化數字檔案服務提供有益參考。
關鍵詞:知識圖譜;數字檔案;檔案智能服務
分類號:G270
引用格式:熊回香, 嚴舞月. 基于知識圖譜的數字檔案服務模式探究[J/OL]. 知識管理論壇, 2021, 6(4): 204-212[引用日期]. http://www.kmf.ac.cn/p/254/.
1? 引言
由于語義技術的突出表現,許多領域都看到了語義網絡帶來的便利及其難以被取締的優勢,檔案界也開始對數字檔案的未來發展有了新的想法。同時隨著互聯網的發展,人與人、檔案與人的交流也愈發密切,檔案服務與語義網絡的結合已經在所難免。目前數字檔案資源的組織在語義方面尚處于初步嘗試階段,如何將數字檔案資源在語義層面組織起來,為用戶提供更為精準的服務,已成為當前檔案服務部門亟待解決的現實問題。基于當前數字檔案服務所存在的零散、復雜和智能化程度不夠等問題,本文提出將知識圖譜技術與數字檔案服務融合這一理念。知識圖譜作為一種新興語義處理模型,能夠將實體與實體連接起來,挖掘并展示實體間關系,提煉不同檔案核心詞,將檔案相關知識進行整合,促進數字檔案資源聚攏,提升用戶使用體驗,達到用戶輸入單一檔案知識點,便能通過知識圖譜來獲得其他相關檔案知識的效果,即圖譜自動實現相關內容擴展,減少檢索步驟,提高檢索效率,完善檢索內容,最終實現優化智能服務的目的。
2? 相關研究
知識圖譜是一種描繪實體之間關系的語義網絡,是人工智能重要研究領域——知識工程的主要表現形式之一。目前可獲取的相關知識庫資源包括國外的Freebase、Wikidata、DBpedia、YAGO等,國內有復旦大學公布的中文概念圖譜CN-Probase等。本文構建的知識圖譜架構不是泛化的通用知識圖譜架構,而是構建基于檔案的領域知識圖譜架構。不同于通用知識圖譜,領域知識圖譜能利用領域特有知識快速構建知識庫,如醫療知識圖譜、地理知識圖譜、軍事知識圖譜及農業知識圖譜等[1]。目前,知識圖譜的研究主要集中在針對已有元數據(EAD、Dublin Core等)的基礎上,探討元數據語義互操作以及映射關系[2]。例如,楊茜雅在企業檔案數據應用中引入語義本體概念實現檔案數據語義分析的流程,在此基礎上構建聯通電子檔案知識圖譜系統[3];雷潔等基于Protégé、OWL等技術構建計算機可理解的科研檔案知識圖譜語義模型[4];舒忠梅基于當下數字人文的發展背景,提出檔案時空本體模型及檔案數據抽取框架,構建檔案關聯數據知識圖譜,以可視化的形式展現[5];B. S. Balaji等采用語義對描述文檔進行解析,并構架云服務推薦系統[6]。
而在數字檔案服務方面,以往用戶熟知的檔案服務方式多為被動服務,即被動調動和被動查看,導致各檔案文件之間多呈現孤立關系,用戶取用困難,操作繁瑣。目前國內大部分學者使用轉變服務模式、構建資源平臺等方法來解決該問題。例如,曹玲等對美國常青藤八所高校的數字檔案信息服務模式進行研究,將其分為運營方式、服務對象、服務方式三個模塊進行分析,提出基于我國檔案服務優化建議[7];王文強通過分析智慧服務和數字檔案館的利弊,轉變企業檔案信息服務模式,由“信息服務”向“知識服務”“智慧服務”模式優化[8];連志英基于對數字檔案信息用戶需求、用戶行為的分析,對數字檔案信息用戶進行分類及構建數字檔案信息用戶模型,并且根據用戶需求和用戶行為建設數字檔案信息資源及數字檔案信息服務平臺,用以提供相應的個性化數字檔案信息服務[9]。國外,大多是將數字檔案與文化遺產保護以及歷史應用相結合,也會相應探討一些關于數字檔案館建設的內容。例如,T. Hauswedell等考察了制度、知識、經濟、技術、實踐和社會因素的復雜相互作用,與主要報紙數字化計劃的公營和私營供應商進行了一系列半結構化的采訪并進行了分析,認為那些很少被突出或強調的因素的新興理解,從根本上塑造了數字文化遺產檔案的深度和范圍,應關注這些因素的在未來檔案發展中的潛在優點[10];C. H. Marcondes分析了檔案館等使用關聯數據技術的可行性及問題[11]。
綜合以上所述,目前針對數字檔案的服務大體上還處于一種針對服務內容和服務框架的構建,集中在對資源、數據、服務模式等的探討方面,實踐性研究較少。且能明顯感覺到當下各省市數字檔案的系統性管理和智能服務提供并不完備,目前國家正快速邁進智慧時代,隨著對語義網絡相關技術的逐步了解,學者也充分意識到語義技術的發展對于數字檔案服務效率以及服務質量的提升有著重要的影響。而知識圖譜所帶來的集成化和系統化可以很好地應對數字檔案零散化問題,并且通過整理推薦為用戶提供有針對性、全面性的服務。另外,基于數字檔案服務在各行各業的不同作用情況,本文考慮數字檔案的統一特征,通過語義關聯,聯結數字檔案實體,運用可視化圖表展示實體間關系,構建知識圖譜以推進數字檔案服務模式的升級。
3? 數字檔案服務模式現狀分析
3.1? 現有服務模式的局限
檔案服務是指檔案機構利用館藏優勢,指導用戶利用檔案、獲取檔案信息的過程[12]。
而現有衡量服務模式優劣的兩個重點包括檔案服務人員服務質量以及檔案服務機構智能化程度,在檔案服務人員服務質量方面,傳統的檔案服務模式多為被動服務,大多數企業或政府的檔案工作人員在檔案服務整體信息化程度不高的情況下,對檔案服務的認知不夠明確,其職能僅僅在于管理和保存紙質檔案,維護檔案信息安全等,而為用戶提供檔案檢索服務等更具有實際意義的工作不在其職責范圍內,將如何從數量龐大的檔案信息數據庫中查找所需檔案的難題留給了用戶自己。
另外,在檔案服務機構智能化程度方面,由于新時代“互聯網+大數據”的飛速發展,檔案服務走向主動和智能的模式,通過計算機設備與其他各種互聯網終端相連接,通過一定的技術方式向用戶提供各類檔案信息或產品的服務模式,逐漸成為數字檔案服務模式的主流,其中最具代表性的是數字檔案館和智慧檔案館。但目前數字檔案館的建設還處于起步階段,所提供的個性化服務極其有限,不僅智能化程度低,且操作復雜,難以形成整合型的服務進行推送。筆者對現有省市檔案館網站進行體驗式調查后總結發現,現有檔案館網站中雖然大多擁有開放檔案查詢服務,但基本依托用戶自主查詢,且對查詢關鍵詞要求較高,同時跳轉鏈接較多,查詢過程復雜,例如,登錄湖北省檔案館官網查詢某檔案,系統提示進入檔案信息網進行查詢,但并沒有提供對應鏈接。通過自行查找得到的檔案信息網鏈接,點擊得出結果則直接跳轉回湖北省檔案館主頁。因此可以看出,當前檔案館網站存在服務水平有限、集成化程度不高、操作復雜等局限性。
3.2? 基于知識圖譜的數字檔案服務模式的可行性分析
隨著語義網絡、神經網絡的發展,知識圖譜、圖數據庫、深度學習等相關技術也逐漸滲透到圖情檔研究領域,使得檔案數據語義描述與關聯、知識融合、信息可視化等成為可能。同時,伴隨智慧城市的建設推動,檔案服務也開始重視用戶需求并將服務方式逐漸向以用戶需求為中心轉移,諸如數字檔案館、智慧檔案館等,在處理檔案數據、調動檔案資源等方面尚存不足。基于知識圖譜的數字檔案服務通過對數字檔案資源的語義關聯和本體提煉,可以準確提取數字檔案資源的核心,并通過簡潔明了的可視化形式展現給用戶。
首先,檔案數據質量較高。相較于數量龐大且形式復雜的互聯網大數據,檔案數據都是真實事件記錄和數據保存,在入庫時已經經過篩選、分類和整理,對不同的數字檔案也有相應的規范格式和要求,這就為基礎檔案數據處理構建了良好的基礎;其次,知識圖譜的系統性能夠有效幫助整理零散的檔案。即運用圖映射、包裝器等工具,基于對數據深加工的需求,對數字檔案的結構進行清洗、變換和集成,使之變為計算機可以理解的結點,在此基礎上識別實體、連接實體、分析實體,對檔案實體進行語義關聯,連接成數字檔案知識圖譜。最后,知識圖譜的輸出模式能夠有效提升用戶體驗。圖譜將用戶搜索到的相關檔案以可視化的形式輸出,能夠更加清晰和便利地展現檔案間的聯系,同時圖譜的動態更新特性能夠及時修改用戶取向,使得服務更加智能。
4? 基于知識圖譜的數字檔案服務模式架構
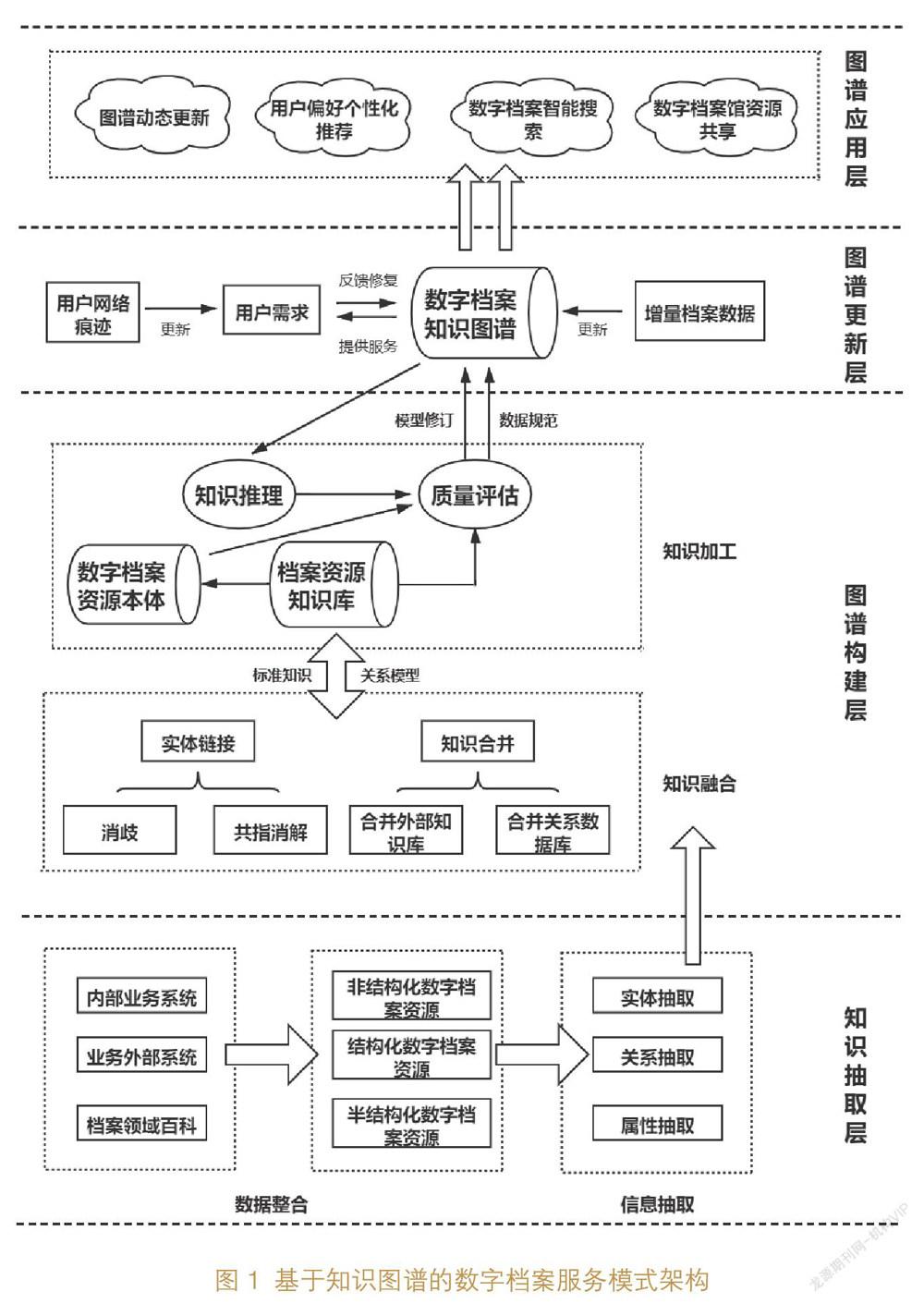
知識圖譜的構建通常有自頂向下和自底向上兩種模式[13],基于檔案的強領域性,本文選擇自底向上的構建形式,即通過迭代更新,從信息抽取到知識融合、知識加工,最后進行知識更新,從分析數據到輸出服務的模式。基于知識圖譜的數字檔案服務模式最終回歸于應用領域,將知識圖譜與數字檔案服務模式相結合的目的也是為了優化服務模式,因此依據知識圖譜理論、本體理論、智能代理技術、云計算技術以及個性化推薦技術,將數字檔案知識圖譜服務平臺梳理為4個層次:①知識抽取層。主要作用是將外部不同結構的數字檔案信息資源匯集起來,通過知識抽取層的結構化分類和分層,轉化成計算機可識別和理解的數據,規整數據使其達到標準化格式從而進入圖譜構建層。②圖譜構建層。這一層主要進行檔案知識抽取和本體構建,然后通過實體識別和本體對齊形成數字檔案資源知識庫。③圖譜更新層。該層主要分為兩個部分,包括收集用戶瀏覽痕跡對用戶個體數據庫進行更新,以及收歸新檔案對數字檔案資源庫進行更新。通過這兩方面的更新使得構建的數字檔案知識圖譜不是單一的、片面的,而是不斷完善的。④圖譜應用層。最終構建的數字檔案知識圖譜能夠為檔案服務帶來不同的應用效果,包括圖譜動態更新、用戶偏好個性化推薦、數字檔案智能搜索和數字檔案館資源共享。具體架構如圖1所示:
4.1? 知識抽取層
知識抽取層主要包括數據整合和信息抽取兩個部分。數據整合部分是對收集到的不同數字檔案數據進行整理和挑選,這些數據包括從不同行業內部業務系統中收集的、從檔案領域百科中整理出來的以及從業務外部系統承接的,不同形式和不同結構的數字檔案數據。而檔案數據包括各級各類檔案機構收集的具有檔案性質的數據記錄,包括各種數據形式的檔案資源,如各類數字檔案、多媒體檔案;亦包括檔案管理與利用過程中產生的數據,如檔案網站的瀏覽記錄、平臺日記、查閱服務數據、檔案統計數據等[14],而日常辦公使用的Word、PPT、Excel、PDF等數據是非結構化數字檔案資源[15]。基于當下數字檔案資源的結構化不統一的問題,筆者認為可以運用自然語言處理技術(NLP)以及包裝器等工具將這些非結構化資源進行統一調整、清洗和修正,包括運用詞典、統計和規則的方法對檔案數據進行分詞,再基于分詞結果進行清洗過濾,如去掉停用詞、去除單字,對分詞進行詞性標注等。同時還可以利用Word2vec等模型通過詞嵌入將檔案詞語從one-hot encoder形式的表示降維到較短的詞向量,使得計算機能夠更好地理解和分析數據,發現實體之間的語義關系。而信息抽取部分則是包括實體抽取、關系抽取和屬性抽取三個部分,其中,檔案實體抽取是運用規則與詞典、統計機器學習和面向開放域三種方式,從數字檔案資源中識別并提取實體;檔案關系抽取是指采取監督學習或遠程監督學習的方式,抽取實體間的關系,解決檔案資源實體間語義鏈接的問題;檔案屬性抽取是指對檔案資源實體的某些特征和性質進行抽取,也可以看作是實體與屬性值間的一種名詞性關系,具體流程如圖2所示:
4.2? 圖譜構建層
圖譜構建層分為知識融合和知識加工兩大部分。在大量非結構化檔案信息經過處理后,能夠獲得實體、關系以及屬性的相關信息,但這些結果可能包含大量的錯誤信息和冗余重復信息,數據之間的關系也不清晰,缺乏層次性和邏輯性,因此需要通過知識融合進行清洗和整合。知識融合包括兩個方面,其中實體鏈接是指將抽取到的實體與知識庫相聯結的程序,主要方法包括實體消歧和共指消解。實體消歧主要是解決同名實體出現歧義的問題,使用較多的方法主要為聚類法。而共指消解則是用于解決多個指向對應一個實體對象的問題,國外相關研究相對來說已經比較成熟,同時出現的實體相似性模型、上下文相似性模型能夠很好地解決這一問題。而知識合并是指將第三方的數據合并進數據庫,包括合并外部知識庫和關系數據庫兩個方面。
通過知識融合,可以得到一系列基本的事實表達,但事實并不等于知識,因此需要進入知識加工階段。知識加工主要包括三方面內容:本體構建、知識推理和質量評估。數據在經過知識融合之后,識別實體已經變成標準化知識并且附有相關屬性關系,被歸入知識庫中。受現有技術限制,通過信息抽取的知識元素仍可能存在錯誤,因此在構建完整的檔案知識圖譜之前,需要進行質量評估,并且通過對知識的可信度進行量化,通過舍棄置信度低的知識來確保檔案知識圖譜內數據的質量。同時從已有的實體關系出發,經過計算機推理,發現新的實體關系,檔案知識圖譜網絡得到進一步完善和更新。而數字檔案資源本體,是經過組織的一種質量較高的知識表示模型,在知識圖譜的構建中本體主要可起到控制圖譜質量的作用,不一定會參與到圖譜建立的流程中,僅作為一種數據質量評估的參考資源庫,在檔案知識圖譜構建過程中充當輔助角色,同時幫助優化知識圖譜更新。
4.3? 圖譜更新層
圖譜更新層包括用戶需求更新和檔案資源更新兩大模塊,通過收集歸納新進檔案和用戶網頁瀏覽查詢痕跡等數據,保持圖譜的實時性,同時提高服務精準度,增強圖譜適配性。
在用戶需求更新方面,不同的用戶行為數據通過數據驅動自動對檔案資源進行本體構建,再經過質量評估方法與人工審核相結合的方法加以修正與確認。本體構建之后,對知識庫的數據來往以及反饋不斷進行修訂,同時,知識庫也收集用戶對知識庫的使用痕跡并不斷進行調整和更新,加入時間維度,利用時序分析技術和圖相似性技術,分析圖譜結構隨時間的變化和趨勢,從而掌握到關鍵信息,構建動態時序圖譜。
在檔案資源更新方面,運用知識圖譜中的知識推理板塊,如基于Tableaux運算能夠檢查某一本體的可滿足性,同時通過實例對本體進行檢測;而基于邏輯編程改寫可以根據特定的場景定制規則,以實現用戶自定義的推理過程;基于一階查詢重寫能夠高效地結合不同數據格式的數據源,同時關聯起不同的查詢語言;基于產生式規則可以控制系統的執行,通過制定一定的機制執行規則實現更好地前向推理等;另外,針對構建的知識庫進行質量評估也是確保知識圖譜內容正確可用的關鍵步驟,評估結束后需將符合標準的檔案資源數據導入檔案知識圖譜中。
4.4? 圖譜應用層
圖譜應用層是指通過完整的知識圖譜構建流程,將數字檔案館中不同的數字檔案資源進行集成和整理,形成檔案知識圖譜,輸出到應用層面,通過知識圖譜對數字檔案信息源的生成數據進行處理,將產出的結構化關聯數據用于深度學習算法訓練,得到能解決具體場景問題的研判模型,從而形成解決辦法產生價值的服務形式,包括基于關聯規則算法的圖譜動態更新、基于聚類算法的檔案用戶偏好個性化推薦、基于分類與預測算法的數字檔案智能搜索、基于整體優化的數字檔案資源共享等。
5? 基于知識圖譜的數字檔案服務模式優勢及應用
基于知識圖譜的數字檔案服務模式架構的構建始終立足于為用戶提供更有效、更方便、更智能的服務,通過對數字檔案的數據整理,結合知識圖譜構建流程,利用自然語言處理技術、實體識別、本體構建、關系抽取等關鍵技術,構建基于數字檔案知識圖譜的架構,能夠支撐數字檔案的智能性管理,提供動態檔案圖譜智能更新、自動分析用戶偏好、立足數字檔案內容的智能搜索以及數字檔案館資源共享。
5.1? 圖譜動態更新
隨著互聯網技術的不斷發展,檔案服務逐漸實現數字化,但目前的數字檔案服務現狀仍浮于表面,首先建設的是數字檔案的存儲與管理問題,對于優化數字檔案服務的內容沒有較多的探討。基于數字檔案的知識圖譜的構建,可以通過數字檔案本體之間的關聯關系,使得檔案內容被更加方便快捷地分解和分類,再通過圖譜關系梳理,使得檔案相關內容能夠產生聯結,在用戶檢索其一時將相關內容完整地推送出來。數字檔案管理不同于數字圖書的管理,由于檔案具有隱私性,因此新的數字檔案歸檔時需進行隱私性和公開性的衡量,從而導致在檔案入庫時程序更加繁瑣和復雜。基于語義關聯的知識圖譜的構建,可以使數字檔案文本入庫之時就通過識別本體創建鏈接,自動分類。而動態更新則是指圖譜的構建不是一成不變的,而是隨著檔案的增加和刪減而不斷變化和完善,可以通過加入時間、空間等維度,構建時間軸或空間軸來完善圖譜在不同時空的內容。圖譜的動態更新能夠有效提高檔案整理效率,同時便于不同類型檔案的規整,也能夠為檔案用戶提供最新內容。當前工程檔案是數字檔案收藏和管理的重點,如港珠澳大橋這類國家大型工程,其檔案擁有耗時長、總量大、部門多等特點,知識圖譜的動態更新特性能夠很好地跟上工程檔案歸檔需求,全程記錄歸納總結,自動分類整理,提供更加便利的服務。
5.2? 用戶偏好個性化推薦
《全國檔案事業發展“十三五”規劃綱要》明確指出,“要提高檔案公共服務能力,提升檔案服務的認知度和用戶滿意度”。檔案用戶面對當前繁雜無序的檔案資源,不僅需要自己提煉檢索語句,還需要處理復雜的檢索程序,導致增大檢索耗時,也會降低用戶檢索興趣,消減用戶檢索需求。同時,在通過圖譜提供個性化服務時,檔案用戶的需求會隨著用戶行為和瀏覽的檔案內容而產生實時變化,用戶需求的易變性、多樣性與數字檔案內容和類型多樣性的關聯,提高了檔案個性化服務功能預測用戶需求的難度。因此,針對用戶的動態行為反向推斷用戶檔案偏好對于提升數字檔案服務十分重要。基于前期知識加工對檔案數據的轉化,使用自然語言處理和機器學習方法對檔案資源中的實體進行概念提取、類及其等級體系的確定、類的對象屬性及數據屬性的確定,以及本體評價等過程,選取BERT和LSTM等多類深度學習模型[13]。預測系統不僅能夠根據用戶頁面停留時間以及瀏覽速度來衡量用戶偏好,并且能夠運用相關技術來識別用戶的自然語言,通過標準化處理轉化為計算機可識別語言,讓計算機能夠更好地識別用戶偏好,增加數字檔案服務的準確性。在預測用戶需求的同時,可以根據已收集到的用戶行為來為下次服務做鋪墊。例如,用戶對實時新聞以及檔案趣事感興趣,知識圖譜識別到關鍵詞后根據語義關聯會相應地推送實時趣事,以及與趣事產生聯系的一系列相關內容,若用戶對歷史檔案以及領域專家研究感興趣,則會推送相應學術資源等。
5.3? 數字檔案智能搜索
檔案用戶使用傳統檔案檢索時,只有輸入準確的檔案關鍵詞搜索題名或內容,才能檢索到相關信息。這種服務模式對檢索語言精準性要求較高,甚至有時出現由于檔案用戶無法準確表達關鍵詞而搜索不到想要的檔案資源的情況。而基于知識圖譜的數字檔案服務模式,通過自然語言處理技術(NLP)能夠將用戶搜索時使用的自然語言自動轉化為計算機可以理解的語言,同時映射到數字檔案知識圖譜中不同的實體或屬性層級,通過結合實體間的關系來推送相應的數字檔案信息資源,提供體系化的檔案知識供用戶瀏覽。用戶使用自然語言進行檢索時也能精準反饋相應內容,提高檔案查詢的查準率和查全率,并且提供內容聯想服務,將相關內容統一且連貫地展現在用戶面前,減少用戶查詢次數和查詢步驟,提高檢索效率。“檔案潛在需求是未被喚醒或未被認識到的需求,主要包括檔案潛在用戶的需求及檔案現實用戶未表達出來的真實的需求”[16],這種智能內容搜索能夠幫助數字檔案館加深與用戶之間的聯系,通過相關內容集成推送的創新服務,吸引用戶瀏覽,同時幫助檔案館收獲更多潛在需求被挖掘的用戶,提升服務質量。
5.4? 數字檔案館資源共享
基于知識圖譜的數字檔案服務,將不同數字檔案館的資源聚集,通過云存儲、云計算等技術整合在一起,建立數字檔案知識圖譜,促進資源間的相互交流,不僅便捷地服務用戶,也給各大檔案館之間的交流架起橋梁。為了迎合當下信息資源相互溝通的大環境,檔案界資源交互也顯得尤為重要。基于知識圖譜的數字檔案服務模式,能夠將不同數字檔案館中的資源匯集,通過識別本體來進行語義聯結,再基于檔案領域關鍵詞將其自動歸類于不同行業,便于查找利用。知識圖譜模型的幫助使得不同數字檔案館之間的資源共享具有很強的可操作性。在服務用戶方面,資源的融合能夠帶來更豐富的檔案內容,達到減少檢索步驟的同時豐富檢索內容的目的。基于當下互聯網帶來的便利,很多信息都可以如實地通過互聯網檢索到,但由于檔案所具備的隱私性和個體性使得檔案檢索受限于地區資源。知識圖譜的資源共享所帶來的便利能夠很好地解決地區間的信息孤島,并且通過融合加深檔案館之間的創新合作,共同提升服務質量,讓檔案用戶真正了解檔案世界中豐富的內核,擴大檔案受眾群,使得民眾提高檔案利用意識,提升檔案利用價值。同時,數字檔案館在開展資源共享服務時也可依據定位需要選擇不同的機構來建立戰略聯盟。在選擇合作伙伴時,可選擇同一領域特長的數字檔案機構,從而加強某一領域檔案的館藏量,體現自身在某一領域的特色;也可以選擇不同領域特長的檔案機構,從而提高自身的綜合性[17]。通過與不同檔案館的合作,結合知識圖譜所帶來的溝通性和聯結性,能夠更好地促進數字檔案服務機構的資源交互,為數字檔案服務提供新的交流環境,推動數字檔案服務升級。
6? 結語
信息化時代,人們的信息行為、方式等各個方面都經歷著前所未有的改變。語義網、大數據及深度學習等技術的快速發展,為數字檔案的準確性和智能性服務提供了技術保障。本文提出一種基于知識圖譜的數字檔案服務模式,充分運用符合當代互聯網技術發展潮流的新型智慧技術來解決當下檔案服務所面臨的問題,針對當前數字檔案服務中存在的檢索語言難識別、檢索步驟繁雜、檢索內容單一等問題,通過創建知識圖譜架構,提出解決策略,不斷推進檔案服務發展以及檔案業務與新興技術的結合。但本研究僅針對數字檔案服務進行探討,仍存在浮于理論、難以實現等問題,未來將努力推進數字檔案知識圖譜的現實構建,并通過收集真實用戶反饋意見對該構想進行進一步完善,促使數字檔案服務有更深層的提升和優化。
參考文獻:
[1] 王電化, 錢濤, 錢立新, 等. 面向檔案的知識圖譜構建方法研究[J].湖北科技學院學報, 2020, 40(1):127-130.
[2] 雷潔, 李思經, 趙瑞雪, 等. 面向科研檔案管理的知識圖譜構建與應用研究[J].數字圖書館論壇, 2020(5):8-15.
[3] 楊茜雅.中國聯通電子檔案數據挖掘與智能利用的研究[J]. 檔案學研究, 2018(6):105-109.
[4] 雷潔, 趙瑞雪, 李思經, 等.知識圖譜驅動的科研檔案大數據管理系統構建研究[J]. 數字圖書館論壇, 2020(2):19-27.
[5] 舒忠梅.數字人文背景下的檔案知識圖譜構建研究[J]. 山西檔案, 2020(2):53-60.
[6] BALAJI B S,? KARTHIKEYAN N K,? KUMAR R. Fuzzy service conceptual ontology system for cloud service recommendation[J]. Computers & electrical engineering,? 2018(69):435-446.
[7] 曹玲, 王榕, 顏祥林.分析與借鑒美國常青藤高校數字檔案信息服務模式[J]. 數字與縮微影像, 2013(3):30-34.
[8] 王文強.基于數字檔案館的企業檔案智慧服務模式探析[J]. 機電兵船檔案, 2019(4):76-78.
[9] 連志英.基于用戶需求的個性化數字檔案信息服務模式構建[J]. 檔案學通訊, 2013(5):49-53.
[10] HAUSWEDELL T,? NYHAN J,? BEALS M H,? et al. Of global reach yet of situated contexts: an examination of the implicit and explicit selection criteria that shape digital archives of historical newspapers[J]. Archival science,? 2020,? 20(2):139-165.
[11] MARCONDES C H. Interoperability between digital collections in archives, libraries and museums: potentialities of linked open data technologies[J]. Ciência da informa??o, 2016, 21(2): 61-83.
[12] 張衛東, 王萍.檔案用戶需求驅動的個性化服務模式研究[J]. 檔案學通訊, 2007(2):82-86.
[13] 劉嶠, 李楊, 段宏, 等.知識圖譜構建技術綜述[J].計算機研究與發展, 2016, 53(3):582-600.
[14] 趙躍.大數據時代檔案數據化的前景展望:意義與困境[J]. 檔案學研究, 2019(5):52-60.
[15] 李超.視頻偵查的知識圖譜構建研究[D]. 北京:中國人民公安大學, 2019(6):1-25.
[16] 楊靜.檔案潛在用戶研究[D]. 合肥:安徽大學, 2013:9.
[17] 趙宏育.如何做好檔案機構間的檔案交流[J]. 蘭臺世界, 2020(S1):12.
作者貢獻說明:
熊回香:研究內容指導;
嚴舞月:論文撰寫與修改。
Research on Digital Archives Service Mode Based on Knowledge Graph
Xiong Huixiang? Yan Wuyue
School of Information Management, Central China Normal University, Wuhan 430079
Abstract: [Purpose/significance] Aiming at shortcomings of the current service quality of digital archives, such as insufficient intelligence and single service content, this paper proposed to build an overall framework of knowledge graph of digital archives, so as to achieve statistical analysis of big data for digital archive, integration and optimization of digital archiving resources, and improvement on the overall service level of digital archives. [Method/process] By collecting literatures, service deficiencies of digital archives were analyzed. This paper investigated the web page service level of digital archives in various provinces and cities, summarized deficiencies of the current service mode of each archive, and improved the framework process of digital archives knowledge graph, finally the framework process was presented in the form of flow chart. [Result/conclusion] Knowledge graph can transform multiple types of digital archive text into data that computers can understand, and improve the level of computer intelligent identification. At the same time, dynamic timing and pertinence of the graph can improve the degree of? integration archives according to the time node, user data can be updated based on users retrieval trace to improve the service quality, enhance the cooperation and communication between digital archives to achieve the result of resources integration, and provide a useful reference to better optimize the digital archiving service.
Keywords: knowledge graph? ? digital archives? ? archive intelligence service
