基于視覺檢測的語音導航抗干擾系統
2021-12-02 01:22:38任碧蕓劉寧董逸軒朱亦成劉微雪王晗
現代計算機 2021年28期
任碧蕓,劉寧,董逸軒,朱亦成,劉微雪,王晗
(南通大學交通與土木工程學院,南通 226019)
0 引言
隨著定位與導航技術的發展,車載導航設備被廣泛應用[1]。常見導航設備的人機交互系統可分為觸摸輸入式和語音輸入式。相較于觸摸輸入式導航設備,語音輸入式導航由聲音控制,操作更加方便。采用語音導航,司機可以解放雙手,在車輛行駛過程中通過語音對其交互控制,從而避免操作時潛在的駕駛危險[2]。然而,常見語音導航設備無法準確判定出聲音信號的來源;此外,車內外噪音也對其造成干擾[3]。利用視覺信息檢測司機嘴部說話狀態,進而控制語音導航的控制權限可以有效減少乘客語音和外部環境的干擾。現有方法通過相位空間分析嘴部區域整體像素值的變化特性來判斷嘴部說話狀態[8]。該方法可有效地減少光照對于像素值變化的影響。然而,該方法無法消除因為頭部移動引起的像素值變化,導致說話狀態的誤判。同時,對閉嘴音的說話狀態效果欠佳。
針對上述問題,本文設計開發一種基于視覺檢測的自適應語音導航抗干擾系統。系統由司機正面設置的攝像頭對臉部的主要特征點進行檢測。通過判定面部方向自動調整嘴部狀態判別函數的參數,對嘴部動作進行實時檢測,進而獲取語音信號開啟和關閉的時間控制信號,增強司機對語音導航的控制權限,減少車內外的噪音干擾。經過實際車載環境檢測,本系統準確性高、實時性能好,具有較好的應用前景。
1 基于視覺檢測的語音導航抗干擾系統
1.1 系統組成
系統的組成分為硬件組成和軟件組成兩個部分。系統硬件設備組成包括:司機面部監控攝像頭(羅技C270)、汽車駕駛系統、視頻采集卡、數據傳輸線及英偉達Jetson深度學習開發板。軟件系統按照不同的功能分為以下幾個模塊:傳感器連接模塊、人臉特征點提取模塊、唇部狀態識別模塊、語音信息匹配模塊、語音導航控制模塊。首先,人臉特征點提取模塊讀取駕駛員面部監測攝像頭中的圖像信息,進而采用HOG pyramid算法進行人臉檢測;再采用人臉對齊算法完成人臉特征點的提取,接著唇部狀態識別模塊對唇部進行定位并獲得唇部特征點,基于特征點建立數學模型,從而完成唇部狀態識別,判斷駕駛員張閉嘴情況,確定駕駛員的語音時間窗。最后,語音信息匹配模塊通過攝像頭內置的麥克風獲取語音信息,并將聲音信息與唇部狀態信息進行匹配,從而利用時間窗對司機聲音信號進行判斷、裁剪,為語音導航提供語音指令。如圖1所示。

圖1 語音導航抗噪聲干擾系統軟件部分流程
1.2 人臉檢測與特征點匹配
本文采用基于Dlib人臉識別的68特征點檢測方法,獲取嘴部面部標志的索引[4]。通過opencv對視頻流進行灰度化處理,檢測出人嘴的位置信息。人臉特征點檢測主要包括兩個關鍵算法:基于HOG Pyramid[5]的人臉檢測、基于回歸樹GBDT的人臉特征點匹配。前者用來檢測人臉區域的界限;后者是用來檢測固定區域內的特征點,并輸出這些特征點的坐標[3]。
特征點檢測主要使用一種基于回歸樹的人臉對齊算法(GBDT)[6],這種方法通過建立一個級聯的殘差回歸樹(GBDT)來使人臉形狀從當前形狀一步一步回歸到真實形狀。每一個GBDT的每一個葉子節點上都存儲著一個殘差回歸量,當輸入落到一個節點上時,就將殘差加到改輸入上,起到回歸的目的,最終將所有殘差疊加在一起,就完成了人臉對齊的目的,準確地定位出各個關鍵特征點。顯示的效果如圖2所示。

圖2 人臉檢測及其特征點匹配結果
1.3 多角度自適應嘴部動作判定
1.3.1 嘴部狀態識別模塊
通過仔細觀察司機發音時嘴部特征點相對位置的變化,無論是張口音還是閉口音(O型嘴),特征點(51,53)之間的距離與特征點(51,59)之間的距離比值均會變小。因此,我們定義了判定是否發音的嘴部狀態判定公式,如式(1)所示。
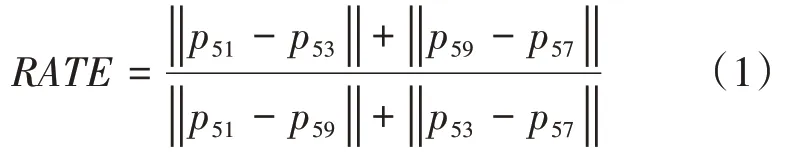
式中,RA TE代表著唇部上下邊緣峰點橫向距離與縱向距離的比值,pi代表著第i個特征點位置坐標|.|代表著兩個特征點之間的距離。公式與特征點對照關系如圖3所示。

圖3 本文提出的唇部發音狀態判定數學模型與特征點對應關系
為了準確確定上述判定方法的閾值,本文采用基于貝葉斯最小錯誤的決策方法:首先,我們將訓練閾值樣本集合分成發音和非發音這兩個類別;其次,利用正態分布分別擬合兩個類,獲取正態分布的參數;最后,利用基于最小錯誤的貝葉斯決策公式確定出最優的閾值。
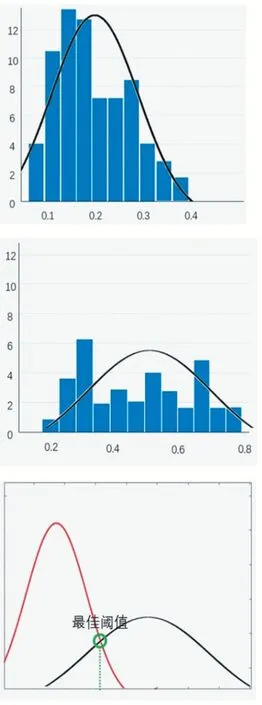
圖4 樣本正態分布擬合與最優閾值獲取
圖5給出了兩組“O型嘴”閉嘴音發音時,不同數學模型的狀態(說話/非說話)判定實驗結果實例。經過比較可知,傳統方法(MAR)發生誤判如黃色框所示,把閉嘴音識別成非說話狀態。相反,本文方法(RATE)對閉嘴音的判定較為準確、穩定。這說明上唇線峰點之間的距離對于“O型嘴”閉嘴音的狀態更加敏感。

圖5 不同嘴部狀態識別方法“閉嘴音”識別結果比較
1.3.2 多角度自適應閾值選擇方法
為了增強司機在轉頭側面下也能判定出嘴部是否發音的狀態,本文設計了一種基于面部方向檢測的自適應閾值條件方法,如圖6所示。

圖6 基于面部方向檢測的自適應閾值選擇方法
利用兩個嘴角的特征分別到最近臉頰特征點的距離之比r(下圖藍色線段所示)作為正面和側面的判定依據,如圖7所示。

圖7 基于特征點距離比例的司機正面、側面方向判定方法

根據上述依據,建立方向判定函數f(r)及其自適應閾值選擇數學模型RAT E(r)如下:

式中,r代表著兩個嘴角特征點(43,55)到相應臉頰特征點(4,32)的距離比值,a1,a2分別代表著正面時r的最小值和最大值。pi代表著第i個特征點。左右側臉下,嘴部狀態判定比較實驗結果如圖8表示,傳統MAR在右側沒有說話時發生誤判如黃色框標注所示,而本文方法較為準確、穩定。

圖8 嘴部狀態判定比較實驗結果
1.4 視覺信息匹配與語音裁剪
視覺信息匹配與語音裁剪模塊的流程圖如圖9(a)所示。首先,對實時檢測出來的唇部狀態進行平滑濾波,去掉誤判帶來的時間不連續。其次,確定嘴部發音的時間起止時間,將其確定為時間窗口長度。最后,利用“時間窗”對聲波進行裁剪,輸出司機說話過程中的聲音信號作為語音導航的輸入命令語音。
為了保證視覺和語音信號的采樣充分,設計了基于全局標志位的跨線程控制模式:視覺檢測線程中,如果檢測到開始說話,令全局標志位值為1,開啟聲音采集控制信號;一旦檢測到開始停止說話,領全局標志位值為0。關閉聲音采集控制信號。在語音指令錄制線程中,始終掃描檢測全局位值的情況,根據標志位實時準確的錄制語音指令和采集聲音信號,原理如圖9(b)所示。
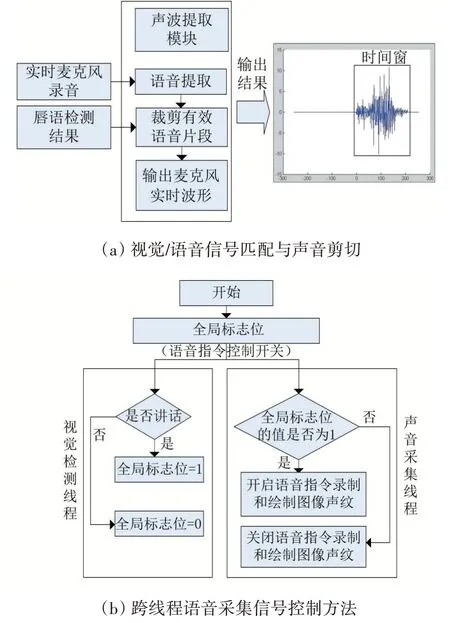
圖9 視覺匹配與聲音裁剪過程及其跨線程控制方法
2 實驗結果及其分析
2.1 實驗環境與數據介紹
圖10給出了本文系統的硬件設備及其配置圖:在司機頭部正前方設置面部表情監控攝像頭,實際車載環境中利用羅技攝像頭,利用英偉達開發板在模擬駕駛系統中做嵌入式計算支持。

圖10 基于視覺檢測的語音導航抗干擾系統硬件設備及其配置圖
為了驗證所提方法的效果,利用Python語言進行“基于視覺的語音導航抗干擾系統”軟件系統的開發,并且制作了人機交互界面如圖11所示。系統自動識別駕駛員的嘴部狀態來判斷駕駛員是否在說話,并將判斷結果在監控窗體內顯示出來,主界面由人臉檢測畫面、駕駛員聲音波形及環境聲音波形圖構成。

圖11 基于視覺檢測的語音導航抗干擾系統實時運行結果
2.2 評價方法與性能比較
表1給出了本系統中,關于嘴部狀態識別性能的評價指標及其結果。為了測試本系統的性能,我們組織多位同學,采集了近5000張樣本圖像,將采集的樣本進行最佳閾值訓練,并根據訓練的結果對傳統識別方法MAR和本文方法RATE進行實時測試。測試結果如表1所示:RATE識別正確率達到90.27%,提高8%;錯誤率達到7.73%,降低7%。性能得到明顯提高,經過濾波后能夠比較準確地確定出聲音信號的時間窗。
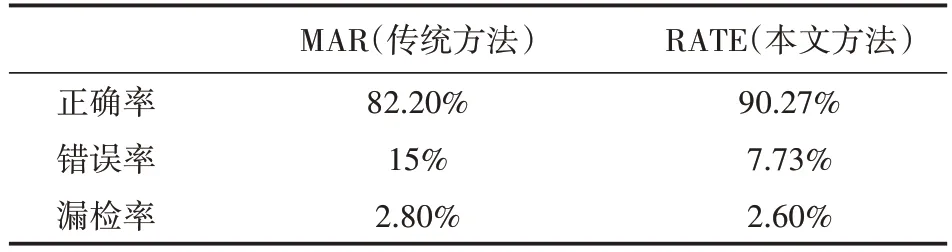
表1 嘴部狀態識別結果性能評價結果
3 結語
針對語音導航設備在噪音環境下無法識別出聲音的來源問題,本文設計開發了一種基于視覺檢測的語音導航抗干擾系統。該系統通過車內的攝像頭來對駕駛員的嘴部狀態進行檢測,判斷出駕駛員是否在說話。利用視覺檢測結果確定司機說話的時間窗,進而對聲音信號進行有效的裁剪、濾波;確定司機對語音導航系統的控制權限,減少車內外噪音對其產生的干擾。實驗表明,本系統有著較高的實時識別率,準確性高、實時性能好,對于頭部水平移動、兩側方向轉動、光照變化均有較好的魯棒性,并且系統成本較低、安裝方便快捷具有較好的市場應用前景。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
